AI 行业
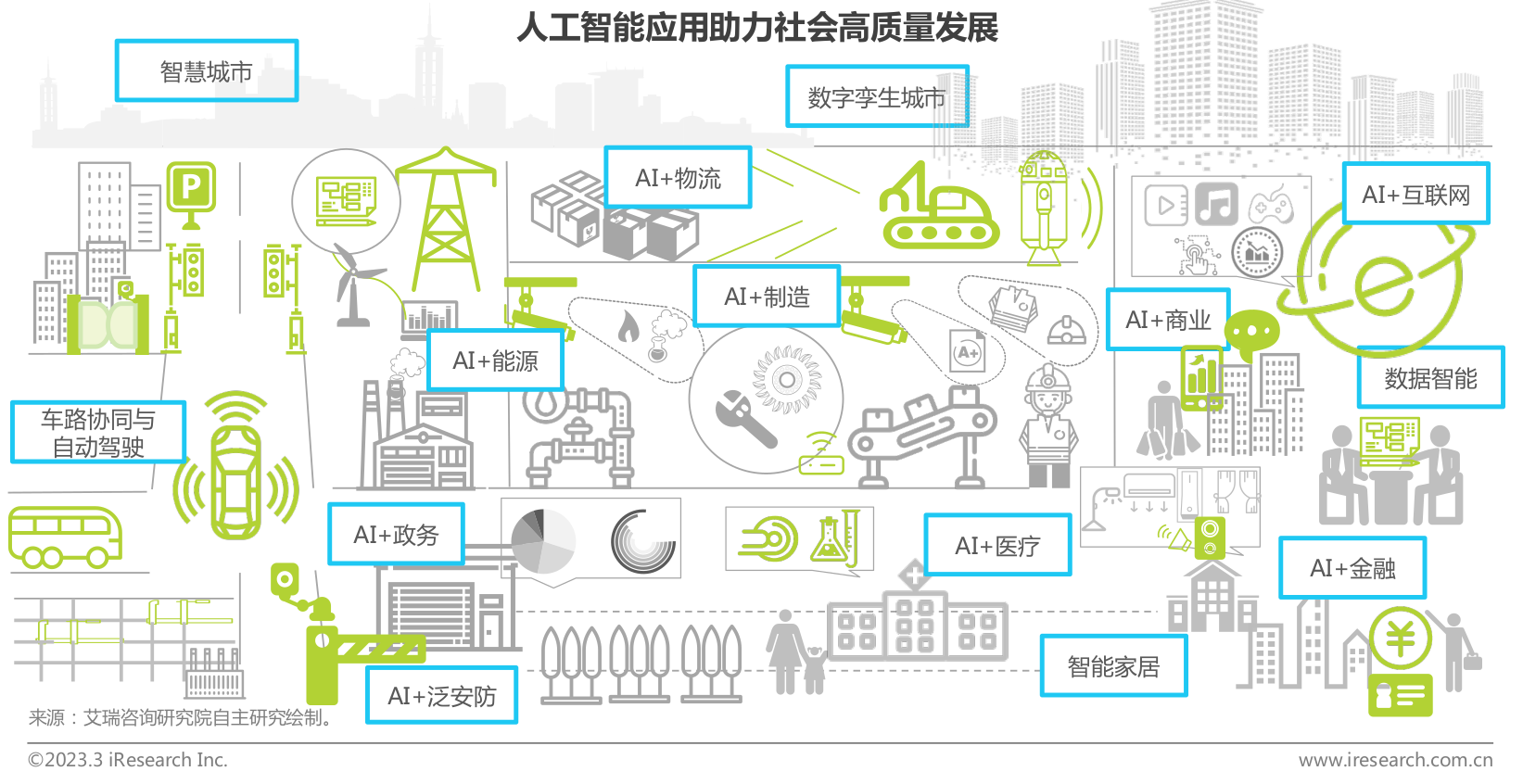
- 智慧城市
- 车路协同与自动驾驶
- AI+政务
- AI+泛安防
- AI+能源
- AI+物流
- AI+制造
- AI+商业
- AI+医疗
- AI+金融
- AI+互联网

人工智能模型
计算机视觉领域
- 目标检测:YOLO(You Only Look Once)系列(如YOLOv5)、SSD(Single Shot MultiBox Detector)、Faster R-CNN等。
- 图像分类:ResNet(Residual Network)、VGG(Visual Geometry Group)、Inception系列、EfficientNet等。
- 语义分割:FCN(Fully Convolutional Network)、U-Net、DeepLab系列等。
自然语言处理领域
- 大语言模型:GPT-3、GPT-4、BERT(Bidirectional Encoder Representations from Transformers)、RoBERTa、XLNet等。
- 问答系统:BERT-QA、ALBERT、T5等。
- 对话系统:DialoGPT、Meena、BlenderBot等。
强化学习-机器人
强化学习(Reinforcement Learning, RL)是一种机器学习的方法,它模拟了有机生命体在环境中的学习过程,通过不断的试错和反馈来优化行为策略。在强化学习领域中,有一个主体(通常称为智能体或代理人)与环境进行交互。 智能体通过执行动作(actions)来影响环境,并从环境中获得反馈,这种反馈通常表现为一种数值化的奖励(rewards)。
- 游戏AI:AlphaGo、AlphaStar、MuZero等。
- 机器人控制:DDPG(Deep Deterministic Policy Gradient)、TRPO(Trust Region Policy Optimization)、PPO(Proximal Policy Optimization)等。
语音识别与合成
- 语音识别:DeepSpeech、Wav2Vec 2.0等。
- 语音合成:Tacotron、WaveNet、MelGAN等。
推荐系统
DeepFM、Wide & Deep、DIN(Deep Interest Network)等深度学习模型应用于个性化推荐。
半监督学习与无监督学习
GANs(Generative Adversarial Networks,如BigGAN、StyleGAN,广泛应用在图像生成)、自监督学习模型(如MoCo、SimCLR,用于图像表征学习)。
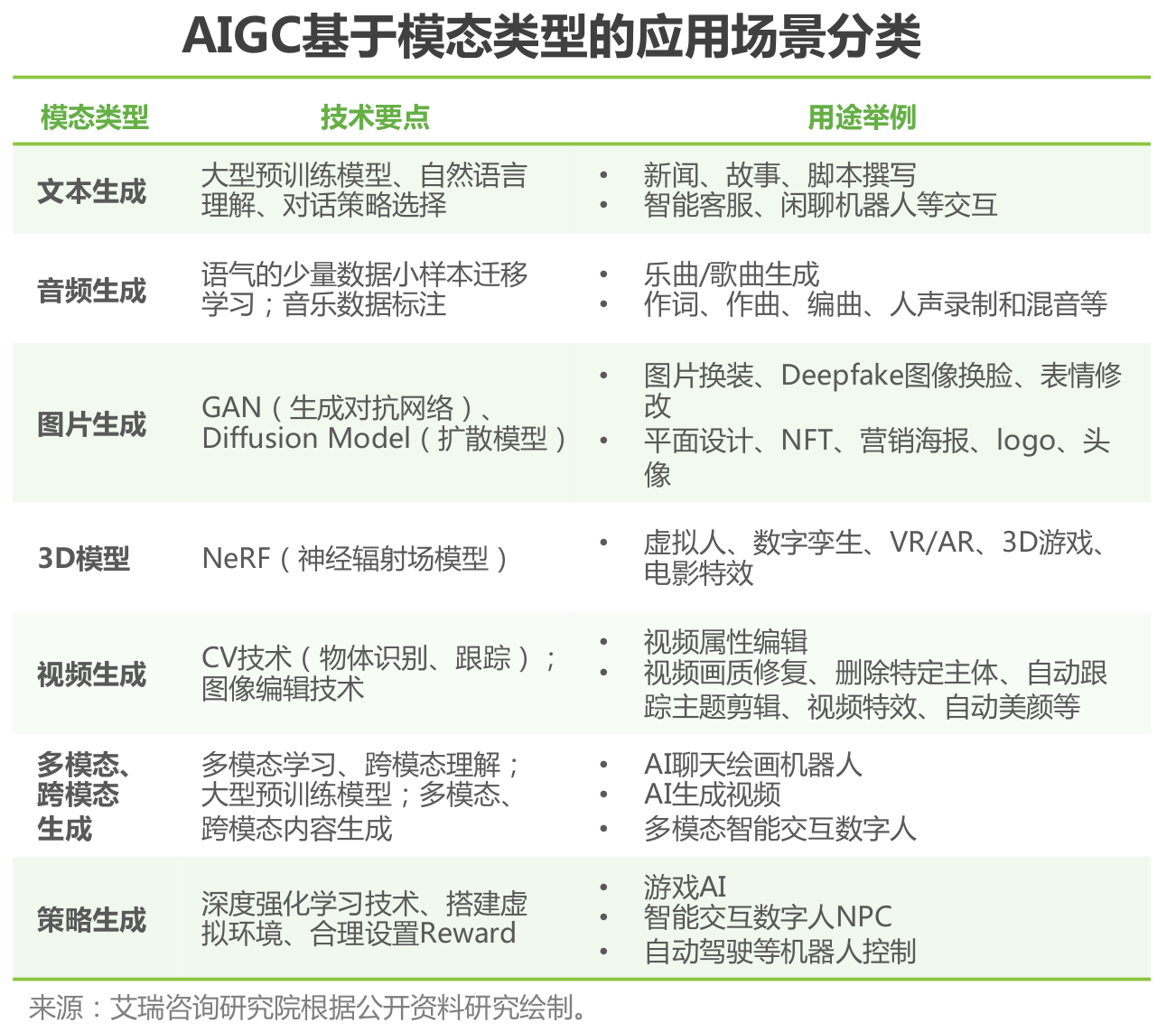
AIGC
AI芯片的场景和分类

训练芯片
- 主要作用:用于训练深度学习和机器学习模型,即通过反向传播算法调整模型参数的过程,使其能够在大量标记数据上学习和优化。
- 设计特点:训练芯片强调的是极致的计算能力,包括浮点运算能力和高带宽内存访问能力,因为训练过程往往涉及复杂的矩阵运算和大量的数据交换。
- 功耗和效率:由于训练任务对算力需求极高,训练芯片可能会消耗较高功率,而且在追求性能的过程中,对功耗的敏感性相对较低。
- 部署位置:训练芯片通常部署在云端的数据中心内,这些环境允许更大的散热空间和更高的能源供应。
推理芯片
- 主要作用:完成模型部署后的实时推理任务,即接收输入数据,通过已训练好的模型计算得出预测结果或做出决策。
- 设计特点:推理芯片的设计目标是追求低延迟、高能效比和低成本。它们注重单位能耗下的计算能力,以及如何快速响应请求,同时在满足性能要求的前提下尽量降低功耗。
- 功能优化:推理芯片的架构通常会针对特定的模型结构进行硬件级别的优化,以提高推理速度,减少不必要的计算资源浪费。
- 部署位置:推理芯片广泛应用于边缘计算设备、嵌入式系统、移动设备(如智能手机)、自动驾驶汽车和其他需要即时响应和低功耗运行的场景。
总结起来,训练芯片聚焦于高强度的计算密集型任务,适合离线训练阶段的大规模数据处理,而推理芯片则致力于在有限资源条件下快速且节能地执行模型推理,适用于在线实时应用和服务。
国内AI芯片厂商

| 厂商/系列 | 代表产品 | 类型 | 算力/工艺 (官方/公开数据) | 主要定位与应用 |
|---|---|---|---|---|
| 华为 昇腾 (Ascend) | 昇腾 910B / 910C / 310 | AI 训练/推理专用芯片 | 910B:7nm,FP16 算力 ~320 TFLOPS | 高端 AI 训练,已在政企/科研应用,配合 MindSpore 框架 |
| 壁仞科技 | BR100 / BR104 | 通用 GPU | BR100:7nm,FP32 算力宣称 1000+ TFLOPS | 国产通用 GPU,瞄准 NVIDIA A100 级别 |
| 摩尔线程 (MTT) | MTT S2000 / S3000 | 通用 GPU | 国产 GPU,显存 32GB GDDR6 | 图形渲染 + 中低端 AI 推理 |
| 寒武纪 (Cambricon) | 思元 270 / 370 | AI 加速卡 | 思元 370:BFP16 算力 256 TFLOPS | AI 推理 + 训练,已进入数据中心 |
| 燧原科技 (Iluvatar) | 天数智芯 T10/T20 | AI 加速卡 | 7nm,FP16 算力 >256 TFLOPS | 面向大模型训练,强调 CUDA 兼容 |
| 登临科技 (Enflame) | 云燧 T10/T20 | AI 加速卡 | 训练型 AI 芯片,百 TFLOPS 级 | 云端 AI 训练,适配深度学习框架 |
| 百度 昆仑 (Kunlun) | Kunlun 2 | AI 芯片 | 7nm,INT8 算力 256 TOPS | 百度云、文心大模型内部使用 |
| 阿里 含光 | 含光 800 | AI 芯片 | INT8 算力 78,000 OPS | 阿里云推理加速,推荐系统/视觉推理 |
中国 AI 芯片代工布局
| 厂商 | 芯片型号 | 代工厂(制程) | 应用场景 | 代工可行性 |
|---|---|---|---|---|
| 华为 | Ascend 310 / 910 | 中芯国际(16~28nm)、台积电(7~12nm,受限) | 云推理、大模型训练 | 台积电 7~12nm 不可用(美管制) |
| 阿里巴巴 | Hanguang 800 / Pro | 中芯国际(16nm) | 云推理、大规模服务 | 可用 |
| 旷视科技 | Sophon 系列 | 台积电(12~16nm)/ 中芯国际(16~28nm) | AI 训练/推理、视觉计算 | 台积电低端制程可用,高端需合规 |
| 比特大陆 | BM1680 / BM1880 | 台积电(12~16nm)/ 合作晶圆厂(16~28nm) | AI 推理、矿机算力 | 可用 |
| 地平线 | Journey / Matrix | 台积电(12~16nm)/ 国内晶圆厂(16~28nm) | 汽车 AI、边缘计算 | 可用 |
| 紫光展锐 | AI SoC | 中芯国际(16~28nm)/ 国内晶圆厂(16~28nm) | 智能手机、边缘计算 | 可用 |
| 壁仞科技 | BR100 / BR104 | 台积电(7~12nm) | 数据中心 AI 训练、推理 | 可用(非敏感企业,合规通道) |
| 摩尔线程 | MTT / MTT-A100 | 台积电(7~12nm) | 数据中心 AI 训练、推理 | 可用(非敏感企业,合规通道) |
边缘计算
边缘计算是在靠近物或数据源头的网络边缘侧,通过融合网络、计算、存储、应用核心能力的分布式开放平台,就近提供边缘智能服务。简单点讲,边缘计算是将从终端采集到的数据,直接在靠近数据产生的本地设备或网络中进行分析,无需再将数据传输至云端数据处理中心
许多边缘计算设备采用的是定制化的Linux发行版,比如Ubuntu Core、Debian、Yocto Project等,这些系统可以通过裁剪内核和组件来适应资源有限的边缘设备。
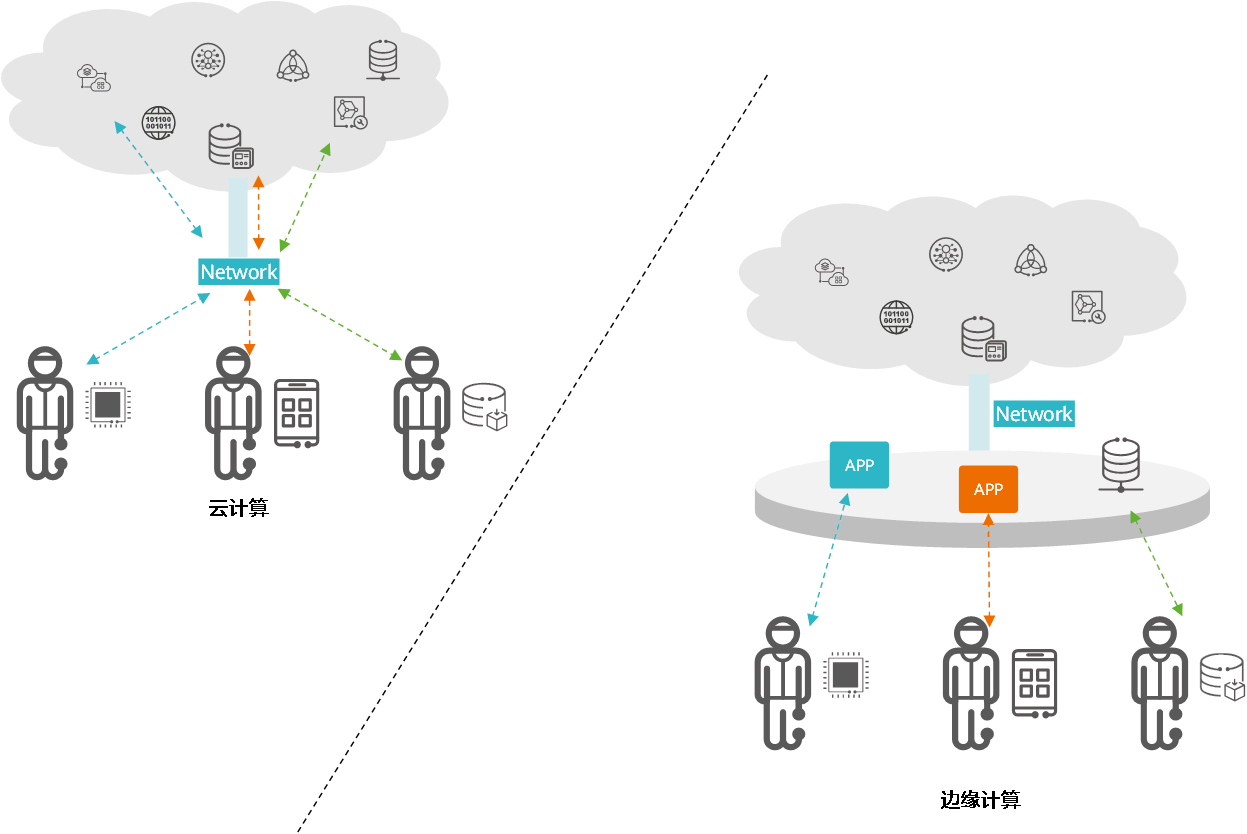
边缘计算 VS 云计算
边缘计算的概念是相对于云计算而言的,云计算的处理方式是将所有数据上传至计算资源集中的云端数据中心或服务器处理,任何需要访问该信息的请求都必须上送云端处理。
因此,云计算面对物联网数据量爆发的时代,弊端逐渐凸显:
- 云计算无法满足爆发式的海量数据处理诉求。随着互联网与各个行业的融合,特别是在物联网技术普及后,计算需求出现爆发式增长,传统云计算架构将不能满足如此庞大的计算需求。
- 云计算不能满足数据实时处理的诉求。传统云计算模式下,物联网数据被终端采集后要先传输至云计算中心,再通过集群计算后返回结果,这必然出现较长的响应时间, 但一些新兴的应用场景如无人驾驶、智慧矿山等,对响应时间有极高要求,依赖云计算并不现实。
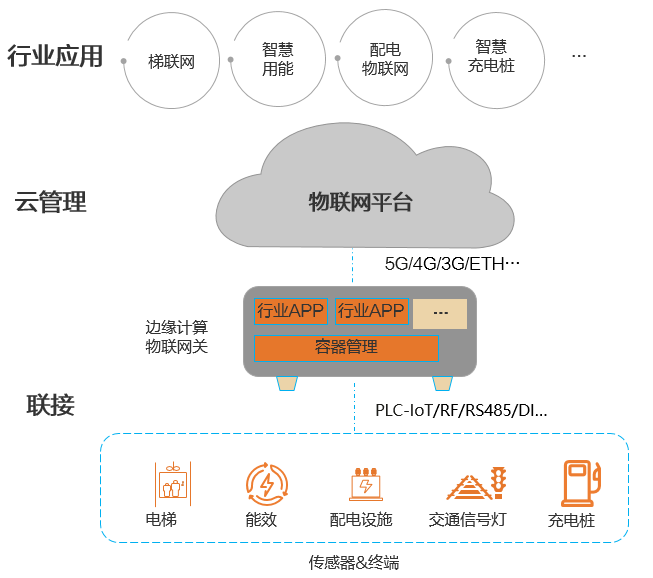
端边云协同的计算机视觉产品架构
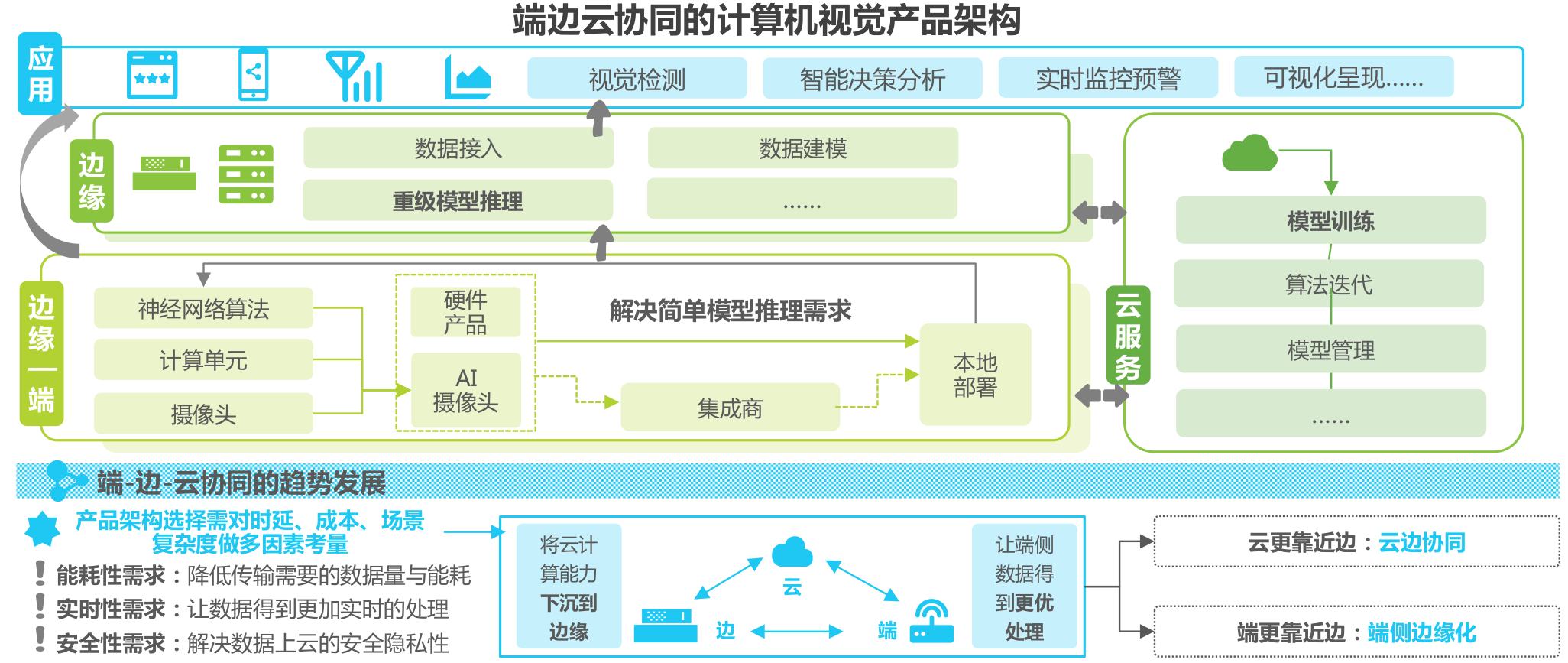
工业相机
工业相机与普通相机(如消费级数码相机或手机相机)的主要差异体现在以下几个方面:
性能指标
- 分辨率:工业相机通常提供更高的分辨率,以满足精密测量和检测的需求。
- 帧率:工业相机的帧率远高于普通相机,可达每秒几十至上百帧,适合快速运动物体的捕捉和连续监测。
- 快门速度:工业相机快门时间可以极短,能抓拍高速运动物体的瞬间细节。
- 灵敏度与动态范围:工业相机通常具有更高的灵敏度和更大的动态范围,能够在弱光环境或强对比度条件下捕捉到清晰的图像。
稳定性与可靠性
- 工业相机设计时注重连续工作时的稳定性与可靠性,能在严苛的工业环境中长时间稳定运行,而普通相机往往不适应这样的工作强度和环境条件。
- 工业相机的温度范围更宽,抗震、抗冲击能力强,且接口耐用。
- 输出格式与数据处理:工业相机通常输出未经压缩的原始数据(Raw Data),可以直接用于后续的图像处理和分析,无需经过JPEG等格式压缩带来的信息损失。工业相机往往配备GPIO接口,便于与其他设备联动,进行触发拍摄或状态反馈。
接口与控制
- 工业相机通常使用Camera Link、GigE Vision、USB3 Vision、CoaXPress等标准化工业接口,支持实时图像传输和远程控制。
- 普通相机主要使用USB、Wi-Fi、蓝牙等消费级接口,设计上更侧重于用户友好和便携性。
应用场景
- 工业相机主要用于机器视觉、工业检测、医疗影像分析、科研实验、交通监控、自动化生产线等专业领域。
- 普通相机则更多应用于日常生活摄影、旅行拍照、社交媒体分享、影视制作等领域。
图像传感器
工业相机常常采用逐行扫描的图像传感器,更适合快速读取和处理数据,减少运动模糊现象。
定制化与模块化
工业相机可以根据具体应用需求进行高度定制,如镜头接口、特殊滤镜、特定光谱响应等,并且设计上倾向于模块化,易于集成到自动化生产线或大型系统中。
AIGC
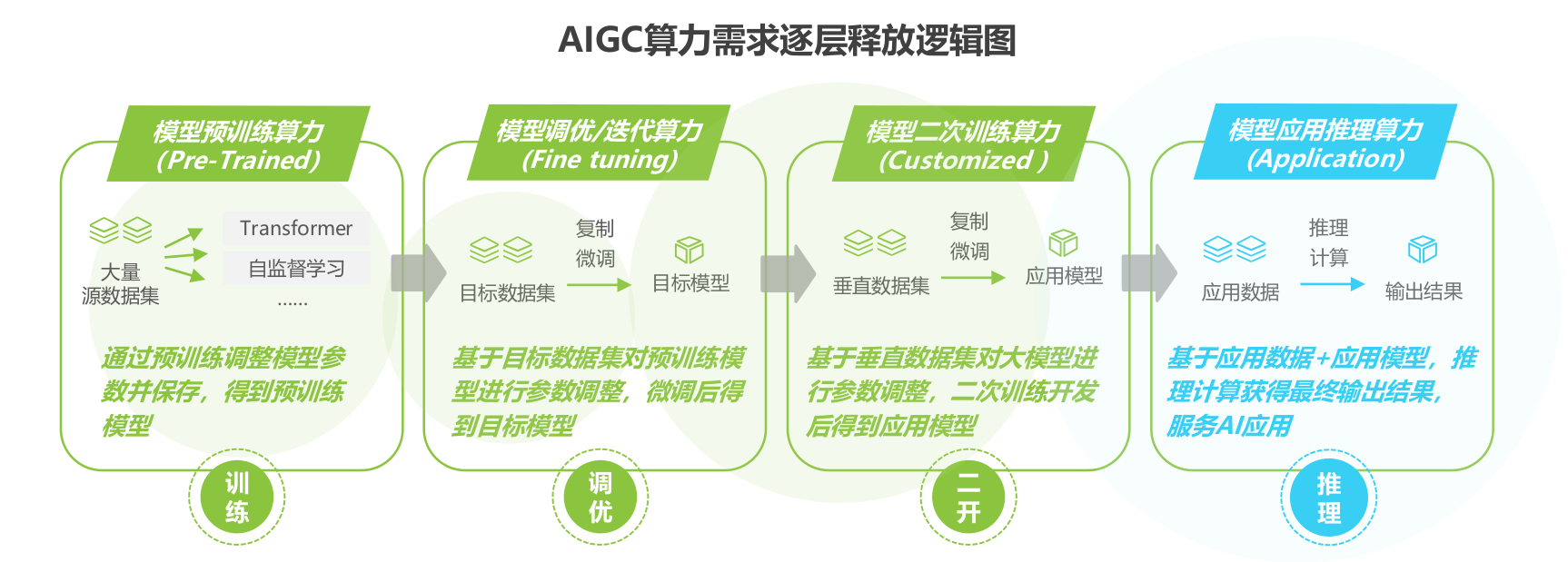
AIGC算力需求逐层释放逻辑图
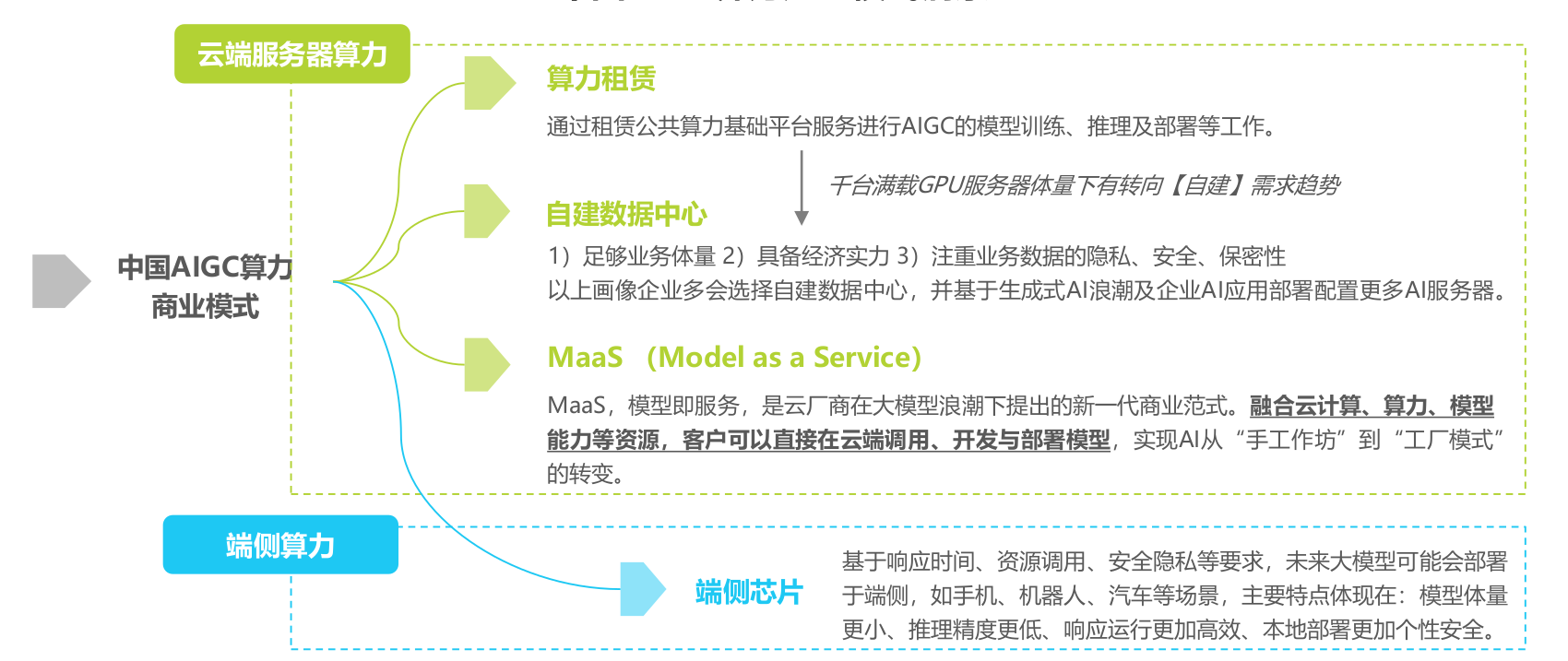
中国AIGC算力产业模式洞察
强大的英伟达

阿里通义千问

美国AI大模型
| 模型/公司 | 类型 | 特点 | 可用性 |
|---|---|---|---|
| GPT 系列(OpenAI) | 通用大语言模型 | 支持多轮对话、代码生成、总结、翻译等 | ChatGPT、API |
| Claude(Anthropic) | 通用大语言模型 | 强调安全性和可控性 | Claude AI 平台、API |
| Gemini(Google DeepMind) | 通用大语言模型 | 集成搜索能力,适合知识问答 | Google Workspace 集成、API |
| Mistral / Mixtral | 开源大语言模型 | 高效推理,偏向科研和开发 | Hugging Face |
| LLaMA 系列(Meta) | 开源大语言模型 | 可本地部署,支持微调 | Hugging Face、Meta 发布 |
| Code LLM(如 Codex、CodeGeeX) | 代码生成模型 | 专注于编程辅助 | GitHub Copilot、API |
美国算力租赁企业
| 平台名称 | GPU 类型与价格(按小时计费) | 适用场景 | 特色与优势 |
|---|---|---|---|
| AWS EC2 | NVIDIA T4:$0.425 A100:$2.99 H100:$98.32(8x) |
企业级训练与推理 | 全球基础设施,支持多种实例类型与区域选择 |
| Google Cloud | T4:$0.35 P4:$0.60 V100:$2.48 P100:$1.46 |
机器学习与深度学习 | 灵活定价,支持长期承诺折扣,适合多种工作负载 |
| Azure | 定价需联系销售团队 | 企业级 ML 服务 | 与 Microsoft 生态系统集成,适合大规模部署 |
| CoreWeave | 定价需联系销售团队 | 高性能 AI 计算 | 提供最新 NVIDIA GPU,优化 AI 工作负载 |
| Lambda Labs | H100:$3.79 A100:$3.09 V100:$2.30 |
AI 云服务与模型训练 | 提供多种 GPU 配置,适合大规模训练与推理 |
| Paperspace | RTX 4000:$0.56 V100:$2.30 A100:$3.09 H100:$5.95 |
ML/AI 工程师与研究人员 | 提供多种 GPU 实例,支持按小时计费 |
| Genesis Cloud | H100:$2.19 A100:$2.19 V100:$1.99 |
高性能计算与 AI 工作负载 | 提供高性价比 GPU 实例,适合大规模训练 |
| RunPod | H100:$1.99 RTX 4090:$0.34 RTX 6000:$5.00 |
AI 工作负载与推理 | 提供多种 GPU 配置,支持按需计费与快速部署 |