NVIDIA 产品矩阵图

AI 边缘硬件
| 名称 | 平台芯片 | 算力(TOPS) | 系统支持 | 网络接口 | 特色 / 适用场景 |
|---|---|---|---|---|---|
| Jetson Orin NX | NVIDIA Orin NX | 70–100 | Ubuntu + JetPack | 2× 千兆 + 可选 Wi-Fi | 强力推理 / 多模型并发 / 工业机器人 |
| Jetson Xavier NX | NVIDIA Xavier NX | ~21 | Ubuntu + JetPack | 千兆 ×1 + Wi-Fi 可选 | 中高算力需求,生态好 |
| RK3588 主板 | Rockchip RK3588 | ~6 | Android / Ubuntu / Debian | 双千兆 | 国产低成本,适合轻量化图像/文字识别 |
| 魔方派3(RUBIK Pi 3) | Qualcomm QCS6490 | ~30 | Android / Qualcomm Linux | 双千兆 | 商用安卓场景,语音+视觉并发应用 |
| HPM6850 模组主板 | 兆易创新 + NPU | 6~8 | RTOS / Linux Lite | 千兆 ×1 | 国产中低功耗边缘视觉任务 |
| RK3576 主板 | Rockchip RK3576 | ~12 | Android 14 / Linux | 双千兆 | RK3588 升级版,支持 LPDDR5 |
| 鸿鹄 920-AI 开发板 | 华为海思 + NPU | ~8–10 | LiteOS / HarmonyOS | 千兆 ×1 | IoT 视频类分析,国产化平台 |
NVIDIA Jetson Orin Nano
NVIDIA Jetson Orin Nano™ 开发者套件
NVIDIA Jetson Orin Nano™ 超级开发者套件是一款紧凑而强大的计算机,它重新定义了小型边缘设备的生成式 AI。它提供高达 67 TOPS 的 AI 性能,较上一代提升 1.7 倍,可无缝运行最流行的生成式 AI 模型,例如视觉转换器、大型语言模型、视觉语言模型等。它仅售 249 美元,凭借NVIDIA AI 软件和广泛的 AI 软件生态系统的支持,为开发者、学生和创客提供最经济实惠且易于访问的平台。现有的 Jetson Orin Nano 开发者套件用户只需升级软件即可体验性能提升,因此现在每个人都可以通过生成式 AI 解锁新的可能性。

Jetson Orin Nano 架构与规格
| 项目 | 说明 |
|---|---|
| CPU 架构 | 6 核 ARM Cortex-A78AE(64 位) |
| GPU 架构 | NVIDIA Ampere 架构 GPU(最多 1024 CUDA 核心) |
| AI 加速单元 | Ampere 架构 Tensor Core,支持 INT8 / FP16 / FP32 |
| 内存 | 最大 8GB LPDDR5,128-bit 带宽 |
| 算力(INT8) | 20 TOPS(4GB 版本) / 40 TOPS(8GB 版本) |
| 接口支持 | PCIe、USB 3.2、CSI 摄像头接口、GPIO、I2C、SPI 等 |
| 操作系统 | Ubuntu 20.04 + JetPack SDK |
| 开发支持 | TensorRT、CUDA、cuDNN、PyTorch、TensorFlow、ONNX 等 |
RK3588 vs Jetson Orin Nano AI 推理对比表
| 对比维度 | RK3588 | Jetson Orin Nano |
|---|---|---|
| 架构类型 | ARM Cortex-A76 + A55 + 独立 NPU | ARM Cortex-A78AE + Ampere GPU + Tensor Core |
| 推理算力(INT8) | 6 TOPS | 20~40 TOPS(4GB/8GB) |
| AI 加速方式 | 专用 NPU 加速器 | GPU + Tensor Core 协同推理 |
| 支持精度 | INT8,部分支持 FP16 | INT8 / FP16 / FP32 全支持 |
| 模型格式支持 | RKNN(由 ONNX/TFLite 转换) | 原生支持 ONNX / TFLite / PyTorch / TF |
| 工具链生态 | RKNN Toolkit / rknpu2 | JetPack SDK / TensorRT / CUDA |
| 部署流程 | 需预转换、手动配置 RKNN | 可直接部署主流 AI 框架模型 |
| 性能表现(YOLOv5s) | 约 20–30 FPS | 约 90–120 FPS |
| 成本(主板) | ¥800–1200 | ¥1500–3500 |
| 适合场景 | 国产化部署 / 成本敏感应用 | 高性能 AI 推理 / 模型开发实验 |
RK3588 在 AI 推理领域的主要竞品
| 竞品名称 | 芯片厂商 | AI 算力(INT8 TOPS) | 架构类型 | 生态/框架支持 | 典型应用场景 |
|---|---|---|---|---|---|
| RK3588 | Rockchip | ~6 TOPS | ARM + 独立 NPU | RKNN Toolkit,支持 ONNX/TFLite | 边缘计算、智能监控、机器人 |
| Snapdragon 8cx Gen3 | Qualcomm | 15-20 TOPS | ARM + Hexagon DSP/NPU | Qualcomm SNPE,支持多框架 | 轻薄本、平板、边缘AI |
| MediaTek Dimensity 9200 | MediaTek | ~20 TOPS | ARM + APU | MediaTek APU SDK | 手机、智能设备 |
| NVIDIA Jetson Orin Nano | NVIDIA | 20~40 TOPS | ARM + GPU + Tensor Core | JetPack SDK,TensorRT | 工业AI、机器人、无人机 |
| Huawei Ascend 310 | 华为 | 16 TOPS | 专用 AI 加速器 | MindSpore,CANN | 云端和边缘AI |
CUDA 核心 和 Tensor 核心
-
图像预处理(Resize、Color Convert):
→ 使用 CUDA 核心(OpenCV GPU模块 或 NPP) -
深度神经网络推理(如 YOLOv8):
→ 使用 Tensor 核心(通过 TensorRT 推理加速)
📦 Jetson Orin Nano 核心参数概览
| 型号 | CUDA 核心数量 | Tensor 核心数量 | GPU 架构 | 最大 AI 性能 |
|---|---|---|---|---|
| Orin Nano 4GB | 512 | 16 | Ampere | 20 TOPS(INT8) |
| Orin Nano 8GB | 1024 | 32 | Ampere | 40 TOPS(INT8) |
🎯 作用对比:CUDA 核心 vs Tensor 核心(在 Jetson Orin Nano 上)
| 项目 | CUDA 核心 | Tensor 核心 |
|---|---|---|
| 功能 | 处理通用 GPU 运算:图像处理、计算机视觉、视频解码等 | 处理 AI 推理(尤其是卷积、矩阵乘加) |
| 主要用途 | OpenCV 加速、图像预处理、视频转码、渲染等 | TensorRT、Deep Learning(PyTorch、ONNX) 推理 |
| 数据类型支持 | FP32(主)、FP16、INT32 | INT8、FP16、TensorFloat32(TF32) |
| 如何使用 | 用 CUDA/C++ 编写、OpenCV GPU 模块等 | 使用 TensorRT / DeepStream / PyTorch + TensorCore 支持 |
| 可控性 | 更灵活编程和调度 | 自动由框架调用加速,用户不直接编程 |
📦 Jetson Orin Nano 在物流分拣中心的应用
| 场景 | 作用 | 使用模块 |
|---|---|---|
| 📦 快递包裹识别 | 识别快递单、二维码、条码 | 摄像头 + Orin Nano + OCR模型 |
| 🎯 自动分拣引导 | 判断包裹目标区域或滑槽 | 目标检测模型(如 YOLO) |
| 🧠 尺寸/体积估算 | 结合深度摄像头进行体积判断 | Depth Camera + 推理 + OpenCV |
| 🏷️ 标签/面单缺陷检测 | 检测是否缺少或损坏 | 图像分类/检测模型 |
| 🤖 与PLC/机械臂协同 | 下发控制信号 | GPIO/串口/CAN 通信 |
| 🕸️ 边缘网关 + 云端协同 | 仅上传识别结果,降低网络压力 | MQTT/HTTP + 云平台 API |
国内高校学习AI常用平台
| 平台 | 主要特点 | 使用情况 |
|---|---|---|
| NVIDIA Jetson 系列 | 生态成熟,支持深度学习全套工具,适合视觉、机器人等课程 | 多数高校AI、机器人、嵌入式方向主力教学平台 |
| 华为昇腾(Ascend)系列 | 国产AI芯片,配合MindSpore框架,注重云边协同 | 部分重点高校及科研院所引入,尤其AI基础研究 |
| 寒武纪(Cambricon) | 国产AI芯片,强调神经网络推理,部分高校实验室使用 | AI芯片教学、国产软硬件实践项目 |
| 英特尔 Movidius + OpenVINO | 轻量级视觉AI加速,适合低功耗嵌入式实验 | AI视觉课题与低功耗设备教学 |
| Google Coral Edge TPU | 低功耗,适合TensorFlow Lite教学 | 部分高校做嵌入式AI入门 |
| 通用云平台(阿里云、腾讯云、华为云) | 云端AI训练与推理,配合线上教学 | 大量高校课程采用云端资源进行大规模模型训练 |
Jetson Orin Nano 学习必备技术基础清单
| 技术领域 | 是否必须 | 建议水平 | 说明 |
|---|---|---|---|
| Python 编程 | ✅ 必须 | 中级 | 用于调用 AI 框架、运行推理脚本、处理图像等 |
| Linux 操作系统 | ✅ 必须 | 中级 | Jetson 运行 Ubuntu;需掌握命令行、软件安装、权限管理等 |
| 深度学习基础 | ✅ 必须 | 入门-中级 | 了解 CNN、模型结构、推理与训练的区别,模型格式(如 ONNX)等 |
| AI 框架(PyTorch / TensorFlow) | ✅ 必须 | 入门 | 能使用基本框架加载模型并运行推理 |
| OpenCV / 图像处理 | 🟡 建议 | 入门 | 摄像头读取、图像预处理、可视化 |
| Jetson 平台知识 | 🟡 建议 | 可学习 | JetPack SDK、CUDA、TensorRT、硬件接口配置等 |
| 嵌入式开发基础 | 🟠 可选 | 初步了解 | GPIO、I2C、SPI 等,适用于机器人、自动化等场景 |
| C++ 编程 | 🟠 可选 | 初步了解 | 如果使用 C++ 示例或对性能有要求时可选 |
| 模型优化知识(TensorRT / INT8 / FP16) | 🟠 可选 | 可后学 | 部署到产品中时提升推理速度、降低功耗 |
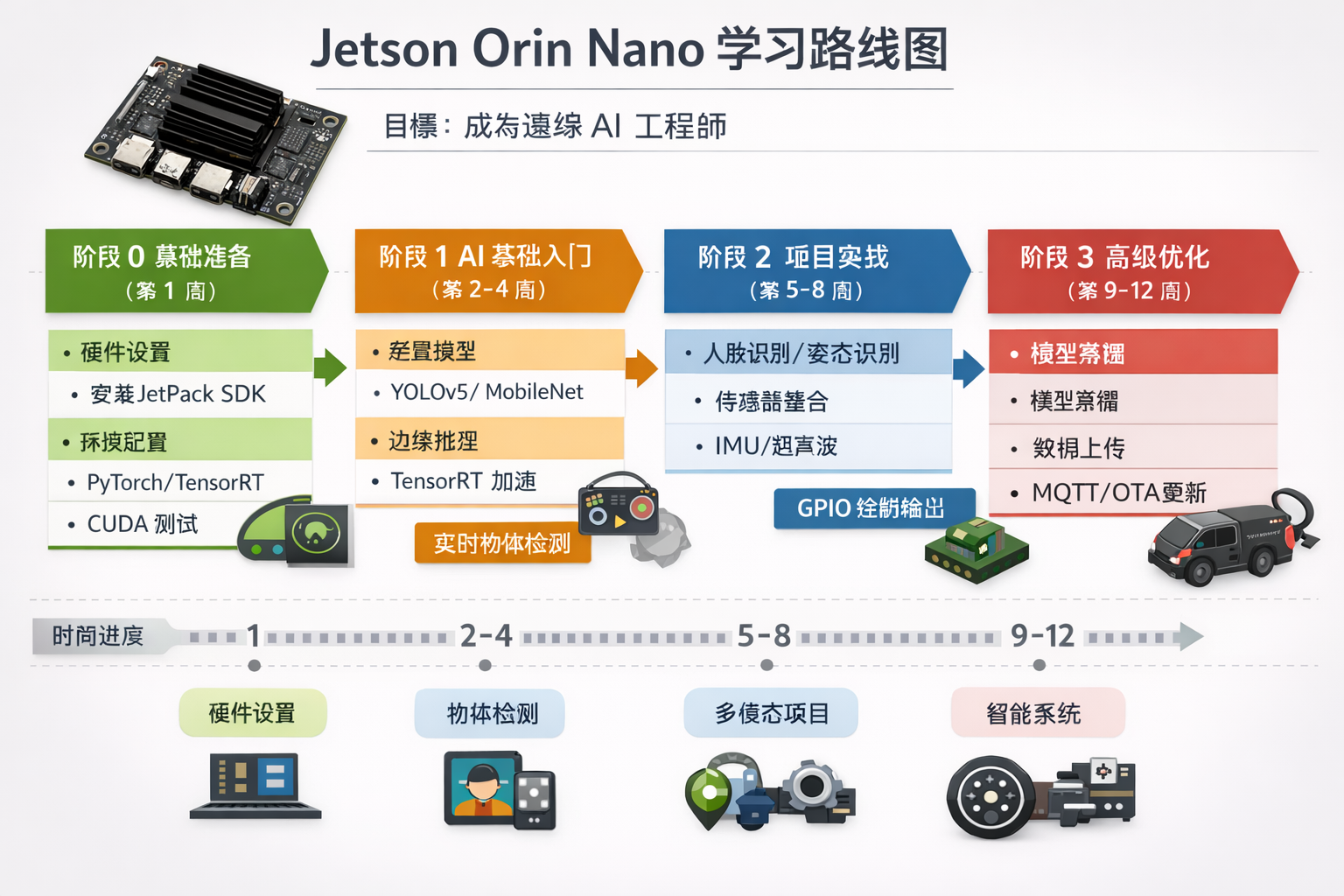
学习路线图
查看显卡
本机
$ nvidia-smi
Sat Jan 31 16:59:19 2026
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 580.126.09 Driver Version: 580.126.09 CUDA Version: 13.0 |
+-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 3070 Off | 00000000:07:00.0 On | N/A |
| 30% 42C P8 27W / 180W | 1453MiB / 8192MiB | 33% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| 0 N/A N/A 2089 G /usr/lib/xorg/Xorg 774MiB |
| 0 N/A N/A 2211 G /usr/bin/gnome-shell 112MiB |
| 0 N/A N/A 516258 G ...rack-uuid=3190708988185955192 521MiB |
+-----------------------------------------------------------------------------------------+
服务器
xt@xt-2288H-V5:~$ nvidia-smi
Sat Jan 31 17:00:47 2026
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 590.48.01 Driver Version: 590.48.01 CUDA Version: 13.1 |
+-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 3090 Off | 00000000:3B:00.0 Off | N/A |
| 32% 29C P8 24W / 350W | 11MiB / 24576MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
| 1 NVIDIA GeForce RTX 3090 Off | 00000000:86:00.0 Off | N/A |
| 42% 29C P8 15W / 350W | 11MiB / 24576MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| 0 N/A N/A 6377 G /usr/lib/xorg/Xorg 4MiB |
| 1 N/A N/A 6377 G /usr/lib/xorg/Xorg 4MiB |
+-----------------------------------------------------------------------------------------+
0
次点赞