AI数据中心结构示意图
┌─────────────────────────────────────────────┐
│ 用户 / 业务 │
│ Web / API / 推理请求 / 训练任务 │
└───────────────────────────▲─────────────────┘
│
│
┌───────────────────────────┴─────────────────┐
│ ⑥ 运维与安全层(DCIM) │
│ ┌────────────────────────────────────────┐ │
│ │ 功耗监控 | 温度监控 | GPU 健康 | 告警系统 │ │
│ │ 物理安全 | 网络安全 | 数据安全 | 权限管理 │ │
│ └────────────────────────────────────────┘ │
└───────────────────────────▲─────────────────┘
│
│
┌───────────────────────────┴─────────────────┐
│ ⑤ 软件与平台层(AI OS) │
│ ┌────────────────────────────────────────┐ │
│ │ 调度与编排 │ │
│ │ - Kubernetes / Slurm │ │
│ │ - GPU 虚拟化(MIG / vGPU) │ │
│ │ │ │
│ │ AI 框架 & 通信 │ │
│ │ - PyTorch / TensorFlow │ │
│ │ - DeepSpeed / Megatron │ │
│ │ - NCCL / MPI │ │
│ └────────────────────────────────────────┘ │
└───────────────────────────▲─────────────────┘
│
数据流 / 计算流 │
│
┌───────────────────────────┴─────────────────┐
│ ④ 网络与互联层 │
│ ┌────────────────────────────────────────┐ │
│ │ 计算网络 │ │
│ │ - InfiniBand / RoCE (200G/400G/800G) │ │
│ │ - Spine-Leaf / Fat-Tree │ │
│ │ │ │
│ │ GPU ↔ GPU / 节点 ↔ 节点 高速通信 │ │
│ └────────────────────────────────────────┘ │
└───────────────────────────▲─────────────────┘
│
│
┌───────────────────────────┴─────────────────┐
│ ③ 核心算力层 │
│ ┌────────────────────────────────────────┐ │
│ │ AI 服务器 │ │
│ │ - GPU: H100 / A100 / MI300 / 昇腾 │ │
│ │ - CPU: x86 / ARM │ │
│ │ - NVLink / NVSwitch │ │
│ │ │ │
│ │ 存储系统 │ │
│ │ - 本地 NVMe SSD │ │
│ │ - 分布式存储 / 并行文件系统 │ │
│ └────────────────────────────────────────┘ │
└───────────────────────────▲─────────────────┘
│
电力流 / 散热流 │
│
┌───────────────────────────┴─────────────────┐
│ ② 电力与散热系统(基础设施) │
│ ┌────────────────────────────────────────┐ │
│ │ 电力 │ │
│ │ - 变电站 / 市电 │ │
│ │ - UPS / PDU │ │
│ │ - 30–80kW / 机柜 │ │
│ │ │ │
│ │ 散热 │ │
│ │ - 冷通道 / 热通道 │ │
│ │ - 冷板液冷 / 浸没式液冷 │ │
│ │ - CDU / 冷水机组 │ │
│ └────────────────────────────────────────┘ │
└───────────────────────────┬─────────────────┘
│
│
┌───────────────────────────┴─────────────────┐
│ ① 物理机房与土建 │
│ 机柜 | 机房 | 地板承重 | 电网接入 │
└─────────────────────────────────────────────┘
NVIDIA Rubin

| 影响领域 | 主要变化 |
|---|---|
| 算力架构 | 单位算力密度更高 → 改变机架规划与预算 |
| 网络层 | 引入更高带宽互联和机柜级互联设计 |
| 存储 | AI 上下文缓存、新存储层需求增加 |
| 能源 ∕ 散热 | 高功率密度 → 增强液冷与能量管理设计 |
| 采购策略 | 延长规划周期 → 优先 Rubin 兼容设备 |
Vera CPU 使用自家设计的 88 核 “Olympus” 核心,且具备完整的 Armv9.2 架构兼容性(full Arm® compatibility)。这意味着它既遵循 Arm 指令集架构(ISA),也兼容现有支持 Arm 的软件生态
| 维度 | 变化 |
|---|---|
| 单卡功耗 | ⬆️ |
| 单卡性能 | ⬆️⬆️ |
| GPU 数量 | ⬇️ |
| 总能耗 | ↘︎ / 持平 |
| 单任务成本 | ⬇️⬇️ |
效率提升
在 AI 数据中心里,效率 ≠ 单卡 FLOPS / W,而是这 4 个层次叠加的结果:
1️⃣ 模型训练效率(多久能训完一个模型) 2️⃣ 推理吞吐效率(同样请求量,用多少机器) 3️⃣ 系统效率(GPU 是否经常“等数据 / 等通信”) 4️⃣ 数据中心效率(算力 / 电力 / 制冷 / 网络的整体匹配)
👉 Rubin 的提升,主要集中在 2 / 3 / 4,而不是单纯榨芯片。
对数据中心来说,训练是一次性投入,推理是长期成本
美国的AI数据中心投资
| 公司 / 项目 | 近期投资(亿 USD) | 电力消耗 / 能力规模(估计) | 用途 |
|---|---|---|---|
| 微软 (Microsoft) | ~400 | 单个大型 AI 数据中心 ~200–500 MW | Azure AI 训练/推理 & 自研芯片(Maia 200)基础设施建设 |
| 谷歌 (Google / Alphabet) | ~750 | 多个数据中心合计 数百 MW – 1 GW | Google Cloud AI 训练/推理、TPU 集群、多区域扩建 |
| 亚马逊 (AWS) | ~160 | AWS 超大 AI 部署 100–500 MW/园区 | AWS AI 服务训练与推理、Trainium / Inferentia 芯片部署 |
| Meta Platforms | ~230 | 数据中心园区 100–300 MW+ | 社交 AI 模型训练、推荐算法推理、大模型 LLaMA 训练 |
| OpenAI (Stargate) | ~50 | 单个 Stargate 级别目标 500 MW – 数 GW+ | 自主训练/推理集群,支持 ChatGPT/GPT 系列大模型 |
| NVIDIA × CoreWeave | ~20 | 目标 5 GW 容量(2030 规划) | GPU 平台建设、AI 训练云基础设施、面向企业客户提供算力 |
中国的AI数据中心投资
| 公司 / 项目 | 近期投资(亿 USD) | 电力消耗 / 能力规模(估计) | 用途 |
|---|---|---|---|
| 阿里巴巴(Alibaba / 阿里云) | ~120–150 | 多个云+AI园区累计 数百 MW 级 | 通义大模型算力池扩建、云 + AI 数据中心建设、海外扩容、硬件采购与生态建设 |
| 腾讯(Tencent / 腾讯云) | ~80–100 | 若干数据中心 数十–百 MW 级 | AI 云平台扩展、AI 推理/服务支撑、AI 产品与算力供给 |
| 百度(Baidu / 百度智能云) | ~40–50 | 相对较小,数十 MW 级 | 智能云与 LLM 平台、自动驾驶/AI 服务基础设施 |
| 字节跳动(ByteDance / Volcano Engine) | ~100–160 | 新建及扩展中 数十–百 MW 级 | AI 计算资源采购、GPU 机房扩容、海外基础设施建设 |
| 华为(Huawei / 华为云 & Atlas AI 平台) | ~80–120 | 国内多地数据中心 几十 – 上百 MW 级 | 云 + AI 算力平台(Atlas / ModelArts)、国产 GPU / AI 芯片(昇腾系列)部署、企业和行业 AI 推理/训练 |
| 中国运营商 & 地方智算中心 | ~50–80+ | 多个区域项目 百 MW 级 | 东数西算枢纽、运营商智算中心建设 |
| 国产算力产业投资(政策 / Big Fund) | ~50–70 | 不直接体现在单体中心,支持能效与算力扩容 | 国家补贴、AI 计算力券、电力/算力生态扶持 |
中美对比
| 对比维度 | 美国 | 中国 |
|---|---|---|
| 主要芯片 | NVIDIA H100 / A100、TPU 等高能效 GPU / AI 加速器 | 华为昇腾(Ascend)、寒武纪(Cambricon)、曙光等国产芯片 |
| 性能功耗比(算力/Watt) | 高,单卡 FP16/Half 精度算力高,优化成熟 | 相对低,尤其在大规模训练和推理时功耗偏高,PUE 外加芯片效率损耗明显 |
| 液冷/散热优化 | 液冷、沉浸式冷却普及,高密度 GPU 散热效率高 | 目前大部分风冷,液冷推广中,散热效率略低 |
未来NVIDIA Rubin带来的影响
| 指标 | 现状 | Rubin 发布后 |
|---|---|---|
| 单卡算力功耗比 | 高(H100/A100) | 更高(Rubin 高能效) |
| 数据中心 PUE | 1.1–1.2 | 可能进一步优化到接近 1.1 |
| 算力密度 | 高 | 更高(单位空间容纳更多 GPU) |
| 投资回报效率 | 较高 | 更高(同样电力成本下可训练更多模型) |
折旧问题
| 特征 | 中国 | 美国 | 说明 |
|---|---|---|---|
| 数据中心建设速度 | 快速扩建 → “先建后用” | 稳健扩建 → 按需扩容 | 中国很多 AI/云算力园区提前建设,等待市场和算力需求爆发 |
| 利用率 | 初期低,部分空置 | 高,按订单/客户需求扩容 | 中国部分新建园区 GPU/服务器未满负载,甚至出现空机柜 |
| 投资驱动力 | 政策扶持 + 市场预期 + 企业竞争 | 市场需求 + ROI | 中国“东数西算”、地方政府补贴加速建设 |
| 风险 | 高 → 高资本支出 + 低初期利用率 | 中 → 投资谨慎、ROI 可控 | 空置意味着早期投资折旧压力大,单位算力成本高 |
| 策略倾向 | 抢占算力和区域布局 → 先建中心 | 先评估 ROI → 再建中心 | 中国企业和地方政府倾向激进布局 |
AI 训练和推理
AI 训练通常强调 高吞吐量(throughput) 与 大规模矩阵计算;
AI 推理则更强调 低延迟、高并发 和 能效:
- 在推理中,尤其是像 快速响应用户查询 的场景下,内存访问延迟、带宽和缓存局部性比纯算力更关键。
- 传统的 Nvidia GPU 采用 外部高带宽内存(HBM),在大规模推理时的延迟和数据搬运开销相对较高,这会影响模型响应速度。
现代一些新型 AI 芯片(比如 Cerebras WSE、大量 SRAM 集成芯片、Groq 架构等)通过更大的片上内存、更低延迟的数据访问来优化推理性能,这对某些实时性要求更高的任务来说可能更有优势
推理芯片的发展
| 硬件类型 | 优势 | 典型代表 |
|---|---|---|
| 通用 GPU | 灵活、软件成熟 | Nvidia GPU(Blackwell/Rubin) |
| 推理优化 GPU | 更高推理效率 | Rubin CPX / 未来硅片 |
| 专用推理 ASIC | 极端低延迟/低功耗 | TPU / SRAM‑based ASIC |
| 边缘 NPU | 超低功耗设备推理 | 低功耗 AI 加速器 |
Google TPU
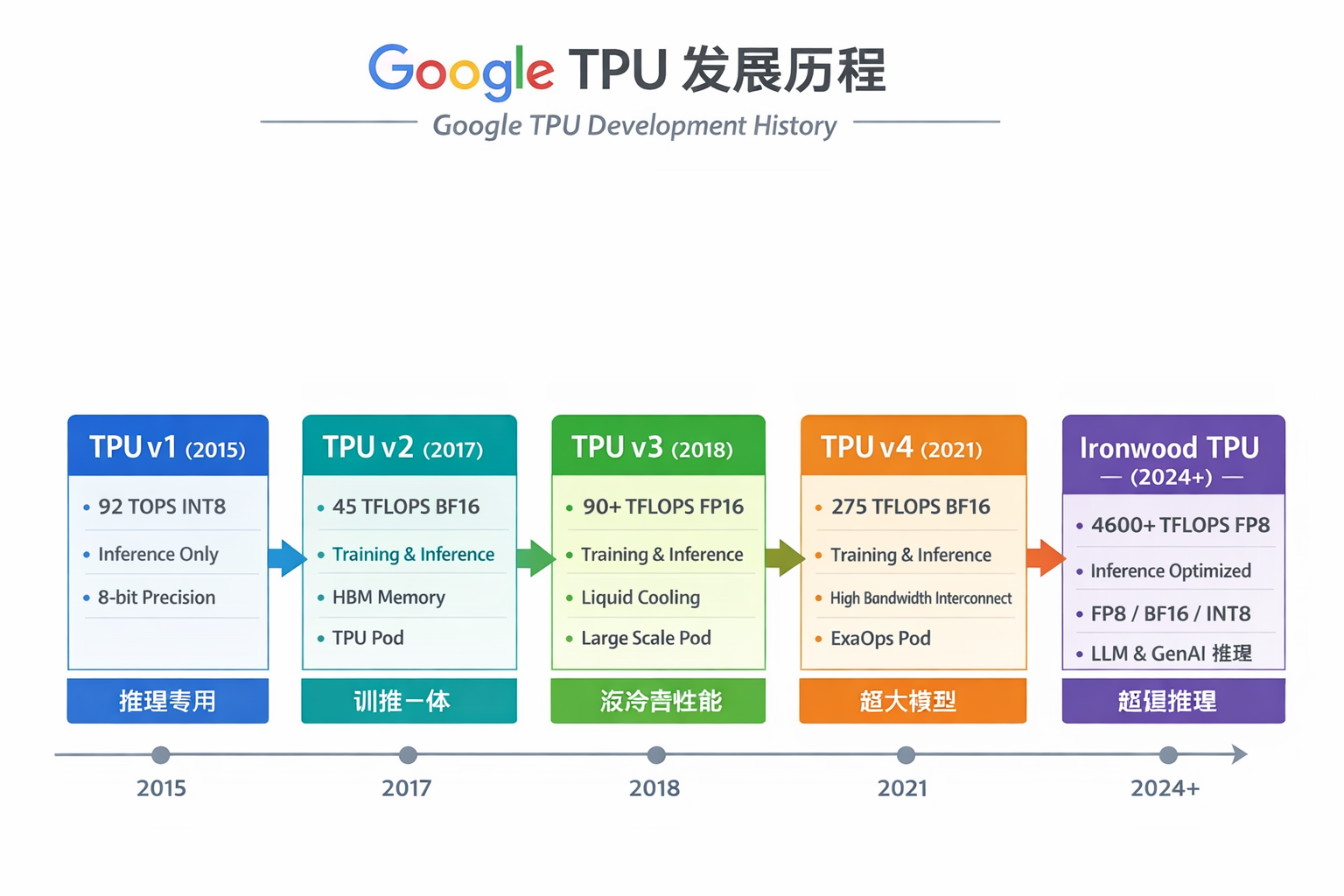
制程
| TPU 版本 | 制程 / 工艺 | 备注 |
|---|---|---|
| TPU v1 | 28nm CMOS | 推理专用,功耗较高 |
| TPU v2 | 16nm FinFET | 支持训练,能效提升,采用高带宽 HBM 内存 |
| TPU v3 | 16nm / 14nm FinFET | 性能更高,引入液冷方案,Pod 扩展能力强 |
| TPU v4 | 7nm FinFET | 更高的算力和带宽,支持大规模训练和推理 |
| Ironwood TPU(TPU v5 推理优化) | 5nm / 4nm FinFET(最先进制程) | 专注推理优化,FP8 / INT8 / bfloat16 支持,高能效大模型推理 |
对比
| 维度 | Google TPU(Inference‑optimized) | Nvidia Rubin(Rubin CPX / Rubin GPU) |
|---|---|---|
| 芯片类型 | ASIC(专用 AI 推理 /训练加速器) | 基于 GPU 架构的推理优化加速器(GPU 变体) |
| 设计目标 | AI 推理大规模、高能效 | 超大上下文推理 & 多模态应用推理优化 |
| 基本架构 | 专用矩阵/张量单元 + 大带宽 HBM | GPU + Tensor Cores + 大内存设计 |
| 推理优势 | 设计上专注于张量运算密集型(矩阵乘加) | 在处理超长上下文、生成任务上有优化 |
| 计算能力 | 单芯片高 FP8 TFLOPS,大规模 Pod 可达数十 ExaFLOPS | 单芯片高 NVFP4 petaFLOPS,机架级别可达 ExaFLOPS |
| 内存与带宽 | 大规模 HBM 内存 + 高带宽 | GDDR7 内存,成本与带宽平衡 |
| 上下文处理能力 | 非常适合大规模矩阵运算 + 并行推理 | 专门优化百万 token 及多模态前置处理 |
| 生态与软件支持 | TensorFlow / JAX 优化 | CUDA + Triton / Dynamo / TensorRT 支持 |
| 可用性 | 仅 Google Cloud 提供 | 企业/数据中心可采购或租用硬件 |
| 优势方向 | 性能/能效比、海量推理扩展性 | 复杂上下文推理、生成任务支持 |
| 适合任务类型 | 大规模批量推理、云端通用 AI | 超长上下文、生成视频/代码、交互推理 |
| 定制化与扩展性 | 可扩展至超大规模 Pod | 灵活,可与 GPU 共享计算/推理负载 |
ASIC架构
Application-Specific Integrated Circuit
| 架构类型 | 定义 | 设计目标 | 可编程性 |
|---|---|---|---|
| ASIC(Application-Specific Integrated Circuit) | 专用集成电路 | 针对特定任务(如 AI 推理、加密、网络处理)做极致优化 | 低:功能固定或半可编程(FPGA 型 ASIC 可部分定制) |
| ARM | 精简指令集处理器(RISC) | 低功耗、高能效,适合移动设备和嵌入式系统 | 高:通用 CPU,可运行操作系统和各种软件 |
| x86 | 复杂指令集处理器(CISC) | 高性能通用计算,适合桌面、服务器 | 高:通用 CPU,可运行广泛软件,支持向下兼容 |
0
次点赞