查看系统中的python版本
lxg@lxg:~/code$ ls -al /usr/bin/python*
lrwxrwxrwx 1 root root 16 6月 3 2025 /usr/bin/python -> /usr/bin/python2
lrwxrwxrwx 1 root root 9 7月 28 2021 /usr/bin/python2 -> python2.7
-rwxr-xr-x 1 root root 3592536 12月 10 2024 /usr/bin/python2.7
lrwxrwxrwx 1 root root 10 11月 26 2024 /usr/bin/python3 -> python3.10
-rwxr-xr-x 1 root root 5937672 1月 8 14:52 /usr/bin/python3.10
NumPy
numpy 是 Python 里最重要的科学计算库之一,主要用来:
- 数组运算(比 list 快很多)
- 矩阵计算
- 数学运算(线性代数、随机数等)
- 深度学习底层计算(PyTorch、TensorFlow 都依赖它)
# 导入 Python 的 numpy 库,并把它起一个简写名字 np 使用
import numpy as np
def main():
# Create a 3x3 array of random floats between 0 and 1
array = np.random.rand(3, 3)
# Print the array
print("3x3 Array of Random Floats:")
print(array)
if __name__ == "__main__":
main()
NumPy 数组可以生成N维数组,数学上将一维数组称为向量, 二维数组称为矩阵,多维数组称为张量
| 名称 | 维度 | 例子 |
|---|---|---|
| 标量 | 0维 | 5 |
| 向量 | 1维 | [1,2,3] |
| 矩阵 | 2维 | [[1,2],[3,4]] 比如:表格 |
| 张量 | ≥3维 | 多维数组 比如:图片、视频、batch |
广播不同维度数组之间的计算
Python VS C++
| 项 | Python | C++ |
|---|---|---|
| 类型 | 解释型 | 编译型 |
| 语法 | 简单 | 复杂 |
| 开发效率 | 非常高 | 较低 |
| 执行速度 | 慢 | 非常快 |
| 内存控制 | 自动 | 手动 |
| 学习成本 | 低 | 高 |
| 适合人群 | 数据/AI/自动化 | 系统/性能/嵌入式 |
C++ 速度 = Python 的 10~100 倍
Matplotlib
Matplotlib 是 Python 最常用的数据可视化库,用来画图
| 函数 | 作用 |
|---|---|
| plt.plot() | 折线图 |
| plt.scatter() | 散点图 |
| plt.bar() | 柱状图 |
| plt.imshow() | 显示图像 |
| plt.title() | 标题 |
| plt.xlabel() | x轴 |
| plt.ylabel() | y轴 |
| plt.legend() | 图例 |
| plt.show() | 显示图 |
import numpy as np
import matplotlib.pyplot as plt
# 生成数据
x = np.arange(0, 6, 0.1)
y = np.sin(x)
# 创建图形
plt.plot(x, y)
plt.title("Sine Wave")
plt.xlabel("X Axis")
plt.ylabel("Y Axis")
plt.show()
运行后生成图形
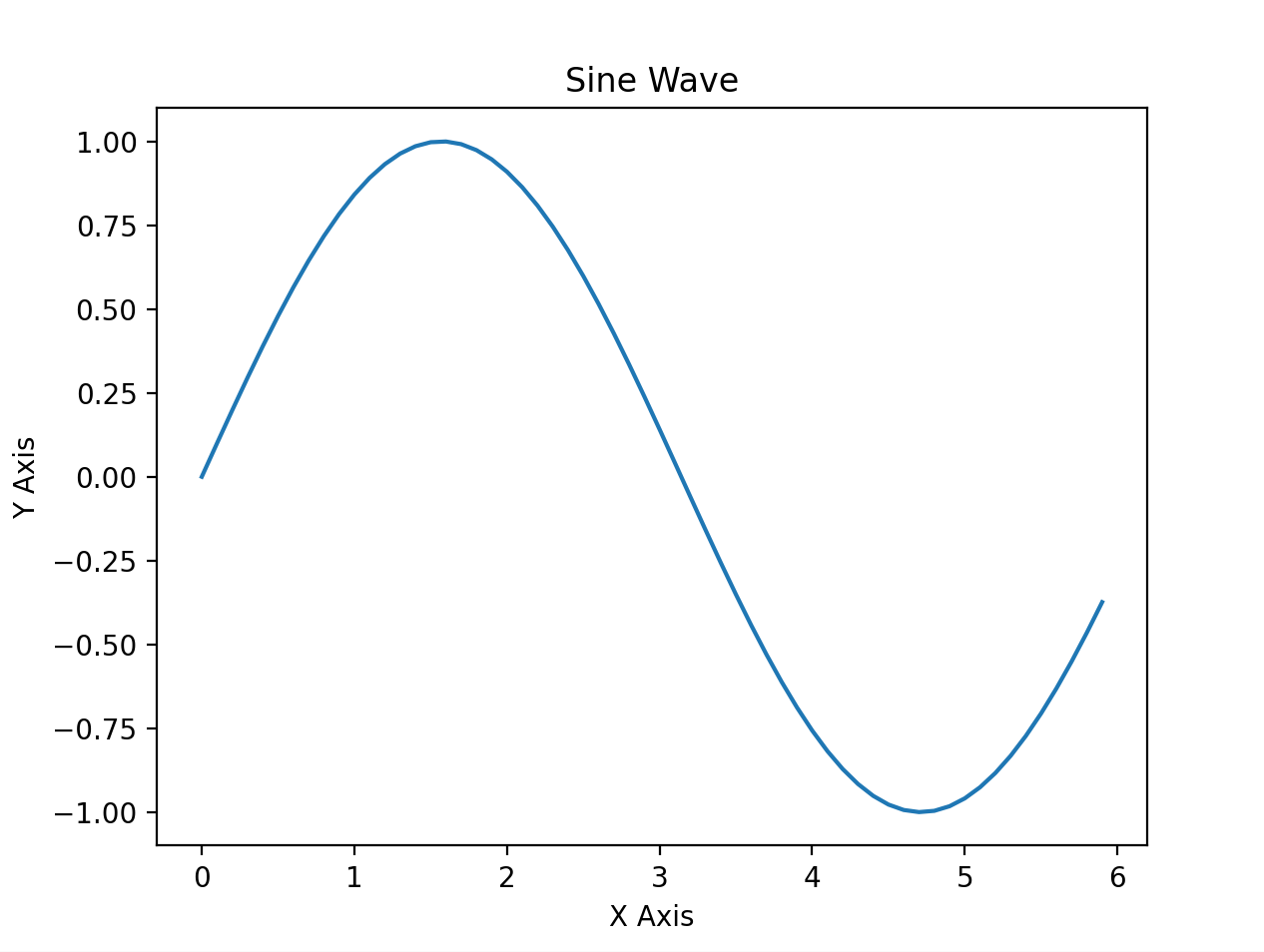
显示图像
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.image import imread
img= imread('car.jpg')
plt.imshow(img)
plt.show()
运行后显示结果
感知机
感知机就是一个“会加权判断的神经元”,深度学习的所有复杂神经网络都是由无数个感知机堆起来的
感知机的数学公式
y=f(w1x1+w2x2+...+wnxn+b)
| 符号 | 含义 |
|---|---|
| x1, x2, …, xn | 输入特征 |
| w1, w2, …, wn | 权重(代表每个特征的重要性) |
| b | 偏置(可以调整阈值) |
| f() | 激活函数,通常是阶跃函数(大于0就输出1,否则输出0) |
| y | 输出(1 或 0) |
权重相当于电流中的电阻, 电阻是决定电流流动难度的参数,电阻越低通过的电流越大。感知机则是权重越大,通过的信号就越大
简单逻辑电路
| x1 | x2 | y |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 0 |
| 1 | 0 | 0 |
| 1 | 1 | 1 |
感知机公式
y=f(w1x1+w2x2+b)
| 逻辑门 | 权重 w1 w2 | 偏置 b |
|---|---|---|
| AND | [1,1] | -1.5 |
| OR | [1,1] | -0.5 |
| NOT | [-1] | 0.5 |
表示 AND 门 并不只有一组权重和偏置,它有 无限组等价解,只要满足条件就行
训练就是在无数可能解中找到一组合适的 w 和 b,让训练数据分类正确
机器学习是确定合适的参数的过程,人要做的是思考感知机的构造,并把训练数据交给计算机
开源大模型开源的是什么
| 部分 | 内容 | 是否通常开源 |
|---|---|---|
| 模型权重(Weights) | 训练好的参数(神经网络里所有 w/b) | ✅ 有些开源(如 LLaMA 2、MPT、Falcon 等) |
| 模型架构(Architecture) | Transformer 层数、注意力机制、激活函数、网络拓扑 | ✅ 通常开源(论文 + 代码) |
| 训练算法 / 数据 /训练框架 | 优化器(Adam、LoRA)、训练策略、训练数据、并行技巧、混合精度 | ❌ 通常不开源或部分开源 |
DeepSeek开源程度
| 项目 | 权重是否开源 | 架构/代码是否开源 | 训练数据/算法是否开源 |
|---|---|---|---|
| Qwen 系列 | ✅ 多版本权重 | ✅ 推理 + 架构代码 | 部分或未完全开源 |
| DeepSeek 系列 | ❗ 部分权重开源 | ✅ 部分基础代码 | ❌ 多数训练数据与细节不开源 |
垂直领域大模型的训练方法
- 利用 通用大模型的预训练知识(语言、视觉、常识)
- 再用垂直领域数据进行微调,让模型在专业领域表现更好
通用大模型(预训练):
┌───────────┐
│语言/视觉/常识│
└───────────┘
│
▼ 微调 / LoRA / 指令调优
垂直领域大模型(专业知识):
┌─────────────┐
│医疗/法律/工业│
└─────────────┘
Anthropic 垂直模型是怎样训练的
┌───────────────────────────────┐
│ 1️⃣ 通用大模型(开源/预训练) │
│ - 已学通用语言/知识 │
│ - 可直接推理 │
└─────────────┬─────────────────┘
│
▼
┌───────────────────────────────┐
│ 2️⃣ 数据收集与标注 │
│ - 企业内部文档、FAQ、对话 │
│ - 高质量标注:问题 → 答案 │
│ ⚠ 数据成本高 │
└─────────────┬─────────────────┘
│
▼
┌───────────────────────────────┐
│ 3️⃣ 微调/定制训练 │
│ - 全量微调:成本高,效果佳 │
│ - LoRA/Adapter:小数据低成本 │
│ - 调整权重适应行业任务 │
│ ⚠ 算力成本高 │
└─────────────┬─────────────────┘
│
▼
┌───────────────────────────────┐
│ 4️⃣ 模型评估与优化 │
│ - 验证准确率、召回率、延迟 │
│ - 推理优化:量化/剪枝/多卡并行 │
│ ⚠ 工程/硬件成本 │
└─────────────┬─────────────────┘
│
▼
┌───────────────────────────────┐
│ 5️⃣ 部署与监控 │
│ - 企业服务器或云端部署 │
│ - 实时监控模型性能 │
│ - 数据更新 → 定期微调 │
│ ⚠ 人才与维护成本 │
└───────────────────────────────┘
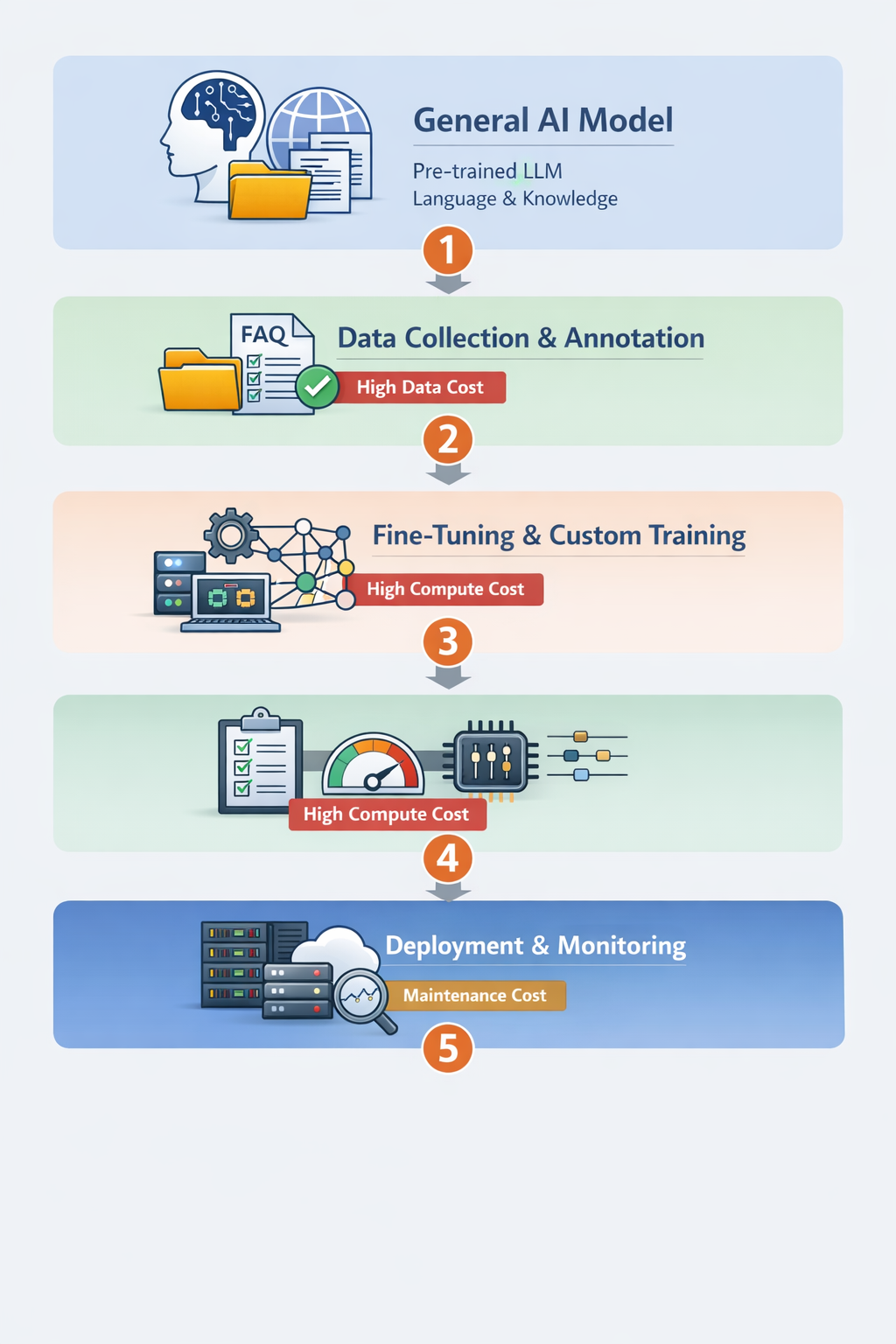
OCR 和 LLM 图像识别的差异
| 特性 | OCR | LLM 图像识别/多模态模型 |
|---|---|---|
| 主要任务 | 文字识别 | 图像理解 + 语言生成 |
| 输入 | 图像 | 图像 + 可选文本提示 |
| 输出 | 文本(字符级) | 文本(句子/回答) |
| 精度关注 | 字符级精度 | 场景理解和语言表达 |
| 技术 | CNN/RNN/Transformer | 图像编码器 + LLM |
| 应用场景 | 扫描文档、票据、证件 | 图像问答、图像描述、视觉推理 |
OCR VS LLM 训练流程
OCR LLM
------ -----
手工标注图片 ──► 训练集 原始文本/图像 ──► 自动生成训练任务
│ │
▼ ▼
OCR 模型 LLM 模型
│ │
▼ ▼
图片 → 文字 提示 → 回答/生成文本
感知机无法解决XOR问题
感知机的局限性就在于它只能表示一条直线分割的空间, 对于非线性空间,需要使用曲线分割,如下图:
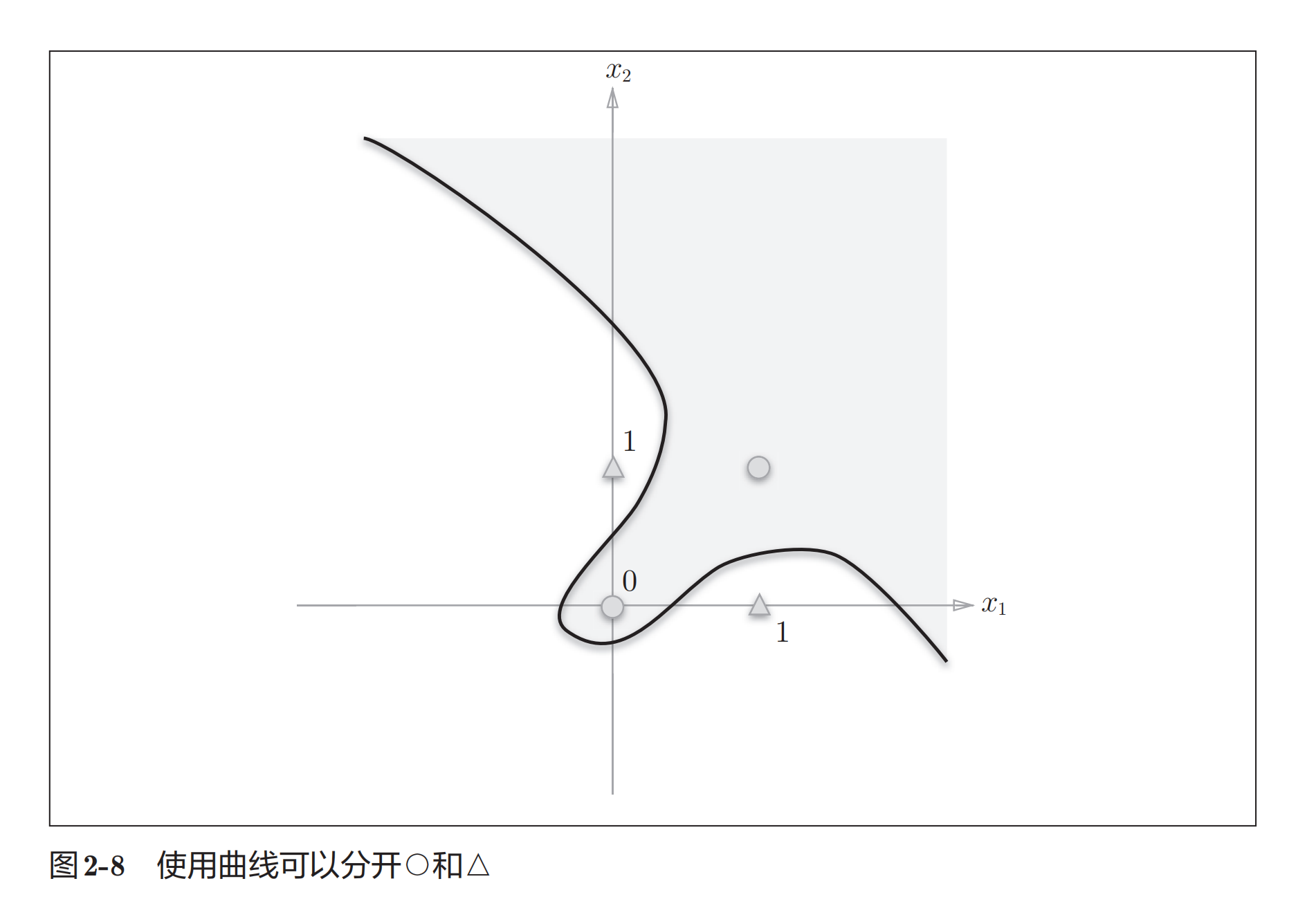
多层感知机
逻辑门是计算机最基本的构建块,CPU、算术逻辑单元(ALU)、寄存器等都是由大量逻辑门组合而成的
无限神经元 + 无限层 + 循环记忆 → 可以模拟图灵机 → 理论上可以实现计算机
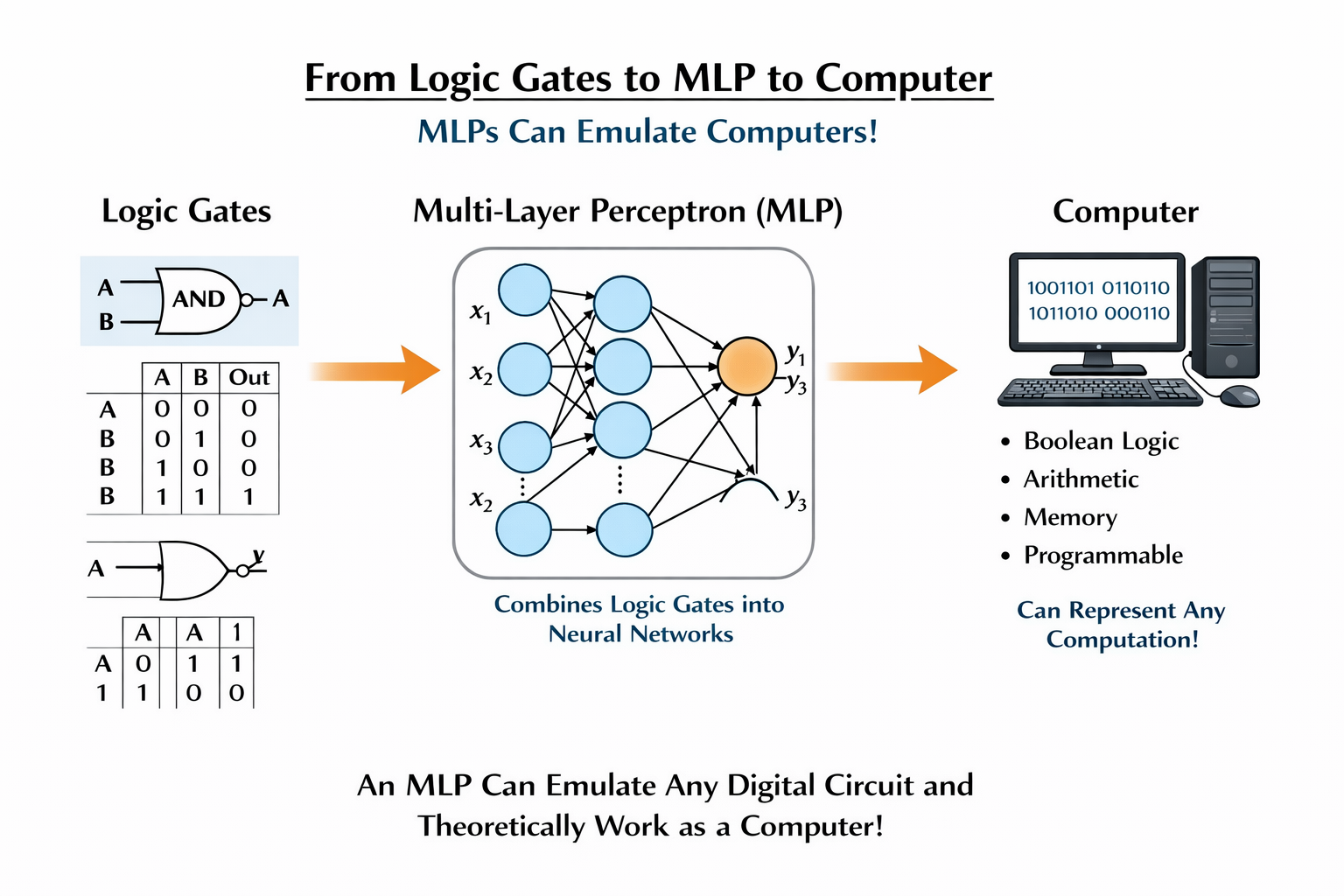
神经元
线性函数: 输出值是输入值大常数倍 非线性函数: 函数是曲线
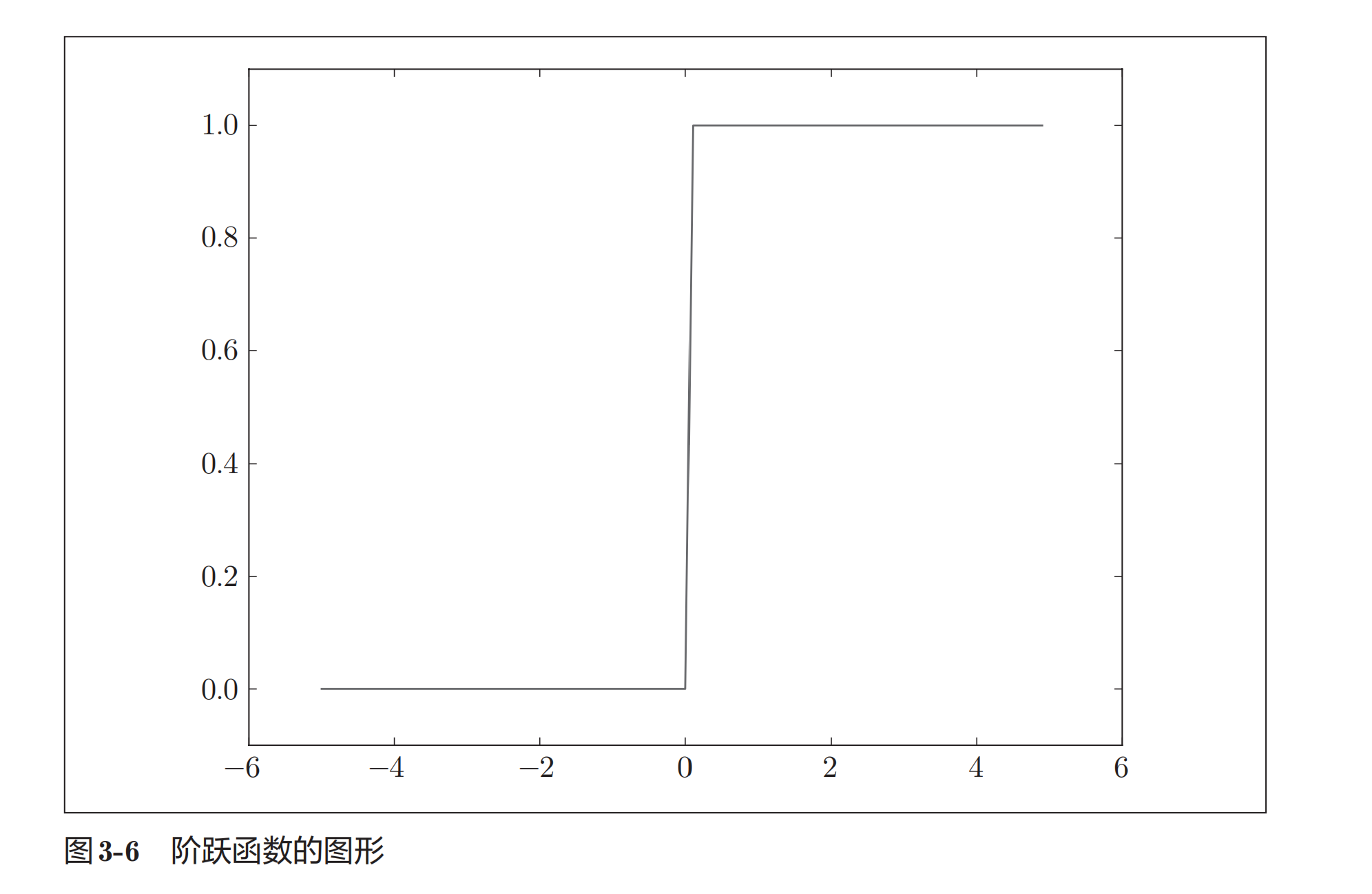
激活函数-阶跃函数
阶跃函数
import numpy as np
import matplotlib.pyplot as plt
def step_function(x):
return np.array(x > 0, dtype=np.int32)
x = np.arange(-5.0, 5.0, 0.1)
y = step_function(x)
plt.plot(x, y)
plt.ylim(-0.1, 1.1)
plt.title("Step Function")
plt.xlabel("X Axis")
plt.ylabel("Y Axis")
# plt.grid()
plt.show()
Sigmoid 函数
import numpy as np
import matplotlib.pyplot as plt
def sigmoid(x):
return 1 / (1 + np.exp(-x))
x = np.arange(-10.0, 10.0, 0.1)
y = sigmoid(x)
plt.plot(x, y)
plt.ylim(-0.1, 1.1)
plt.title("Sigmoid Function")
plt.xlabel("X Axis")
plt.ylabel("Y Axis")
# plt.grid()
plt.show()
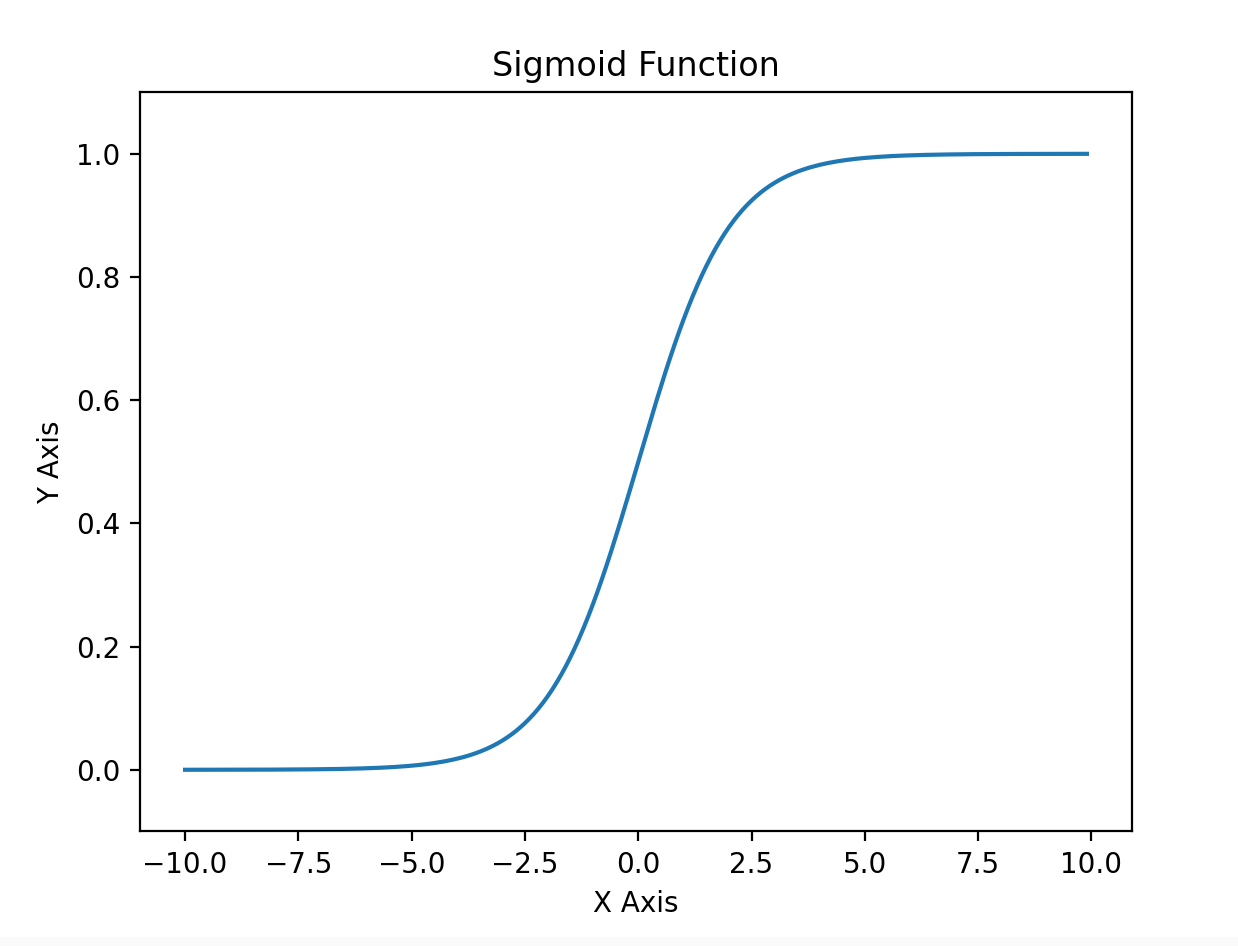
阶跃函数 = 数字电路 Sigmoid = 模拟电路
深度学习其实是“可微分计算机”,它不是在执行逻辑,而是在优化函数
多维数组的计算
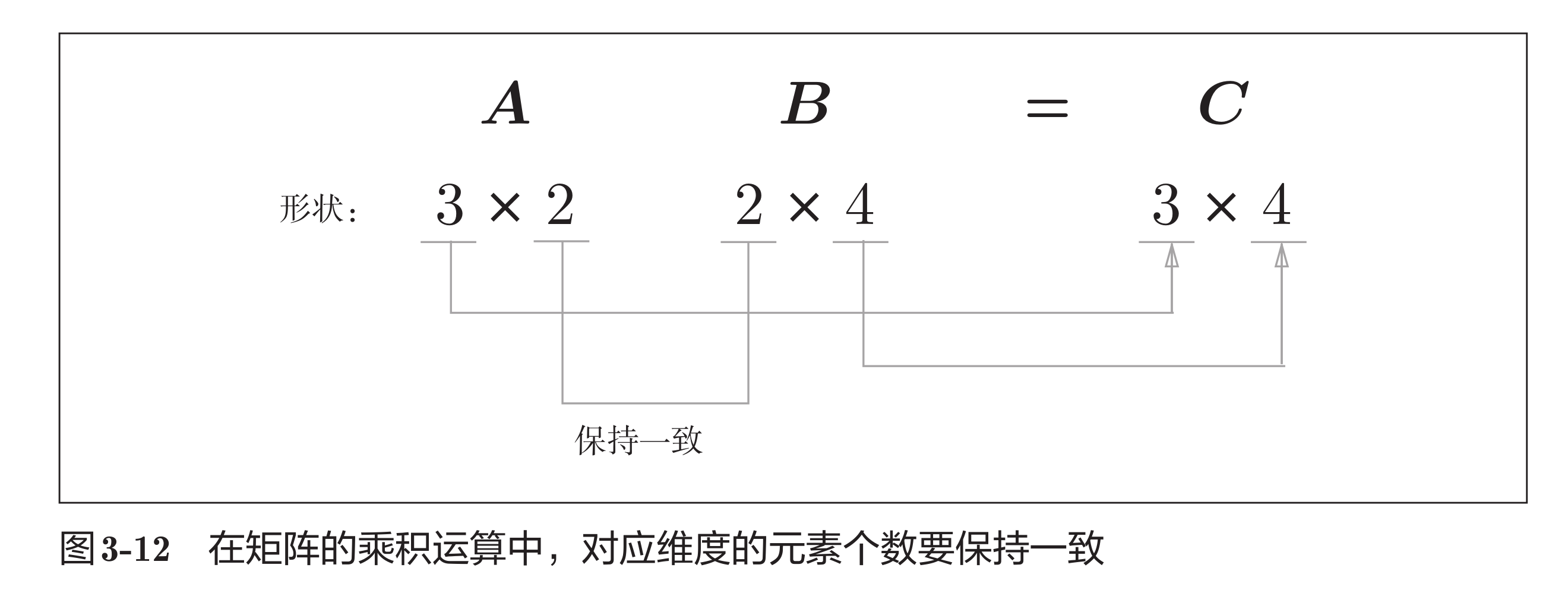
矩阵乘法
import numpy as np
a = np.array([[1, 2, 3], [4, 5, 6]])
print(a.ndim) # 输出数组的维度
print(a.shape) # 输出数组的形状
print(a.dtype) # 输出数组中元素的数据类型
print(a.size) # 输出数组中元素的总数
# 矩阵乘法
# 1 2 3
# 4 5 6
# 乘以
# 7 8
# 9 10
# 11 12
b = np.array([[7, 8], [9, 10], [11, 12]])
c = np.dot(a, b)
print(c) # 输出矩阵乘法的结果
# 2 x 3 乘以 3 x 2 得到 2 x 2 矩阵
# 58 64
# 139 154
# 矩阵乘法不支持交换律
d = np.dot(b, a)
print(d) # 输出矩阵乘法的结果
# 3 x 2 乘以 2 x 3 得到 3 x 3 矩阵
# 39 54 69
# 49 68 87
# 59 82 105
# 矩阵乘法的行数和列数必须匹配,否则会报错
神经网络的内积
x = np.array([1, 2])
print(x.shape) # 输出数组的形状
y = np.array([[1, 3, 5], [2, 4,6]])
print(y.shape) # 输出数组的形状
z = np.dot(x, y) # 1 x 2 乘以 2 x 3 得到 1 x 3 矩阵
print(z) # 输出矩阵乘法的结果
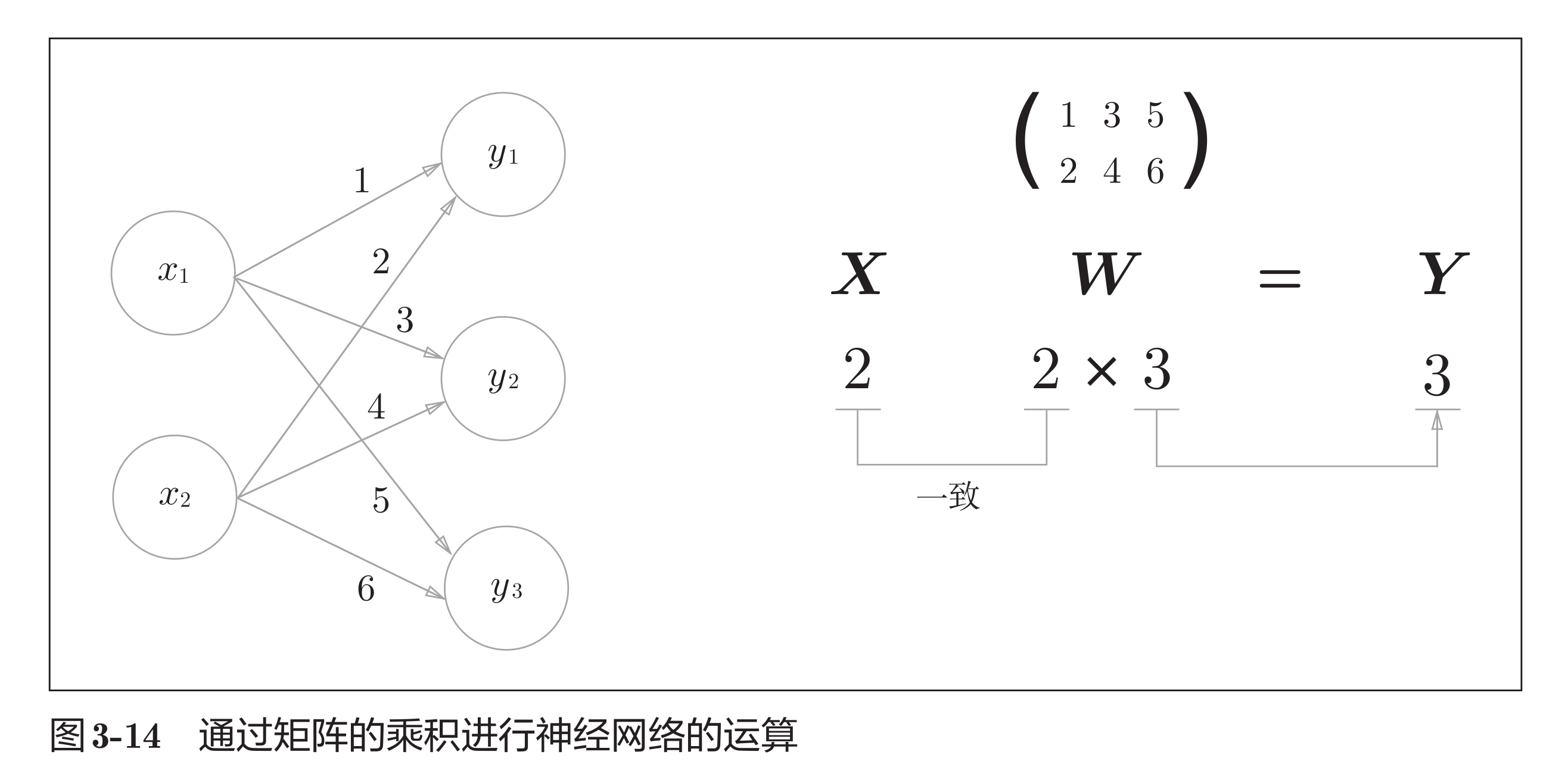
多层神经元之间传递
import numpy as np
import matplotlib.pyplot as plt
def sigmoid(x):
return 1 / (1 + np.exp(-x))
X = np.array([1.0, 0.5]) # 输入层的输入
W1 = np.array([[0.1, 0.3, 0.5], [0.2, 0.4, 0.6]]) # 输入层到隐藏层的权重
B1 = np.array([0.1, 0.2, 0.3]) # 隐藏层的偏置
print("X shape:", X.shape) # (2,)
print("W1 shape:", W1.shape) # (2,3)
print("B1 shape:", B1.shape) # (3,)
A1 = np.dot(X, W1) + B1 # 计算隐藏层的加权和
Z1 = sigmoid(A1) # 计算隐藏层的输出
print(A1) # 输出隐藏层的加权和 [0.3 0.7 1.1]
print(Z1) # 输出隐藏层的输出 [0.57444252 0.66818777 0.75026011]
# 第二层(隐藏层到输出层)
W2 = np.array([[0.1, 0.4], [0.2, 0.5], [0.3, 0.6]]) # 隐藏层到输出层的权重
B2 = np.array([0.1, 0.2]) # 输出层的偏置
A2 = np.dot(Z1, W2) + B2 # 计算输出层的加权和
Z2 = sigmoid(A2) # 计算输出层的输出
print(A2) # 输出输出层的加权和 [0.4 0.8]
print(Z2) # 输出输出层的输出 [0.59868766 0.68997448]
# 第三层(输出层到最终输出)
W3 = np.array([[0.1, 0.3], [0.2, 0.4]]) # 输出层到最终输出的权重
B3 = np.array([0.1, 0.2]) # 最终输出的偏置
A3 = np.dot(Z2, W3) + B3 # 计算最终输出的加权和
Z3 = sigmoid(A3) # 计算最终输出
print(A3) # 输出最终输出的加权和 [0.42336002 0.78658716]
print(Z3) # 输出最终输出 [0.60451623 0.68621873]
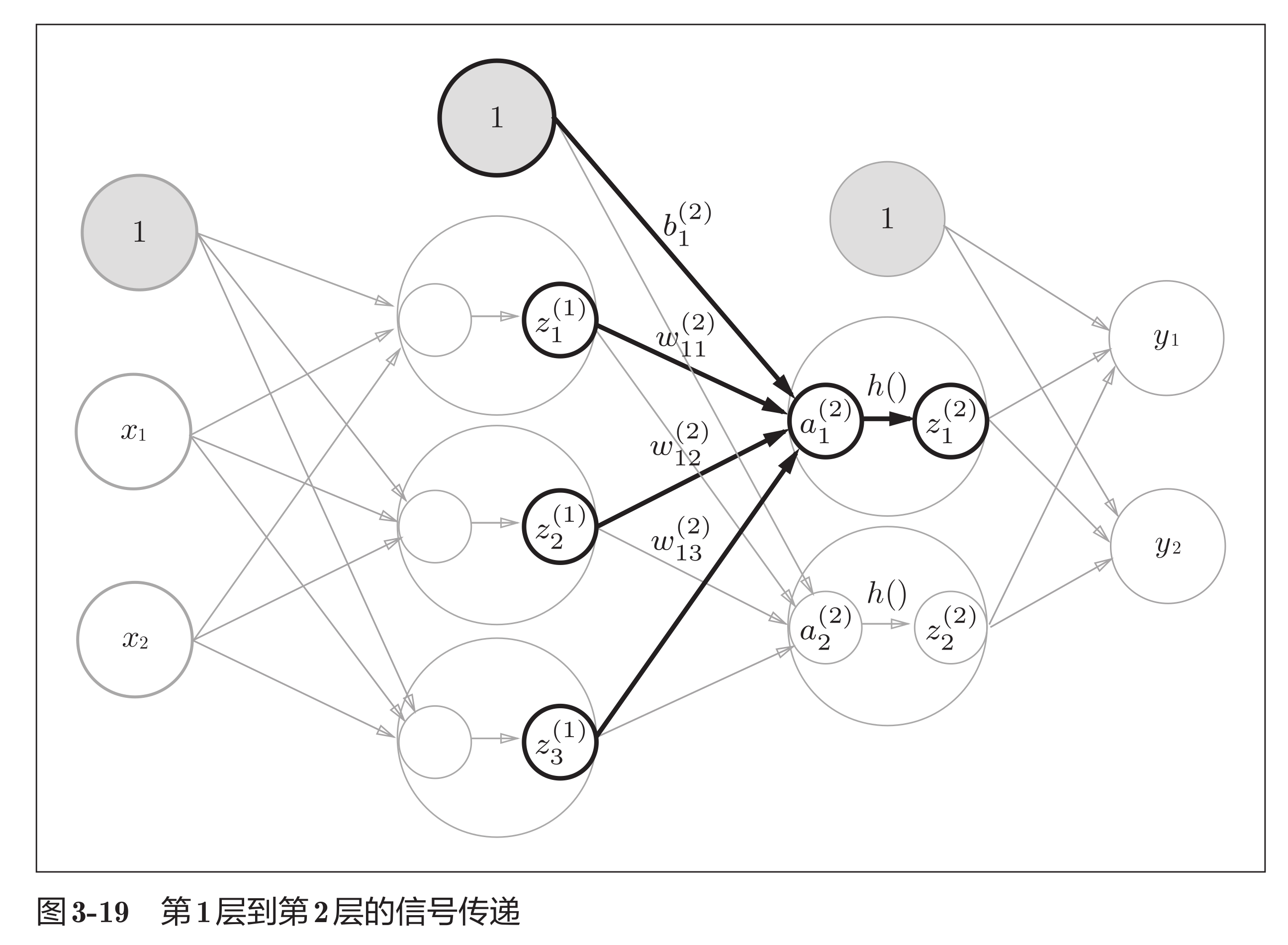
封装
import numpy as np
import matplotlib.pyplot as plt
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def init_network():
network = {}
network['W1'] = np.array([[0.1, 0.3, 0.5], [0.2, 0.4, 0.6]])
network['b1'] = np.array([0.1, 0.2, 0.3])
network['W2'] = np.array([[0.1, 0.4], [0.2, 0.5], [0.3, 0.6]])
network['b2'] = np.array([0.1, 0.2])
network['W3'] = np.array([[0.1, 0.3], [0.2, 0.4]])
network['b3'] = np.array([0.1, 0.2])
return network
# 前向传播函数
def forward(network, x):
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
z2 = sigmoid(a2)
a3 = np.dot(z2, W3) + b3
return a3
network = init_network()
x = np.array([1.0, 0.5])
output = forward(network, x)
print("Final output:", output) # 输出最终结果
机器学习的问题大致可以分为分类问题和回归问题
- 分类问题是数据属于哪一个类别问题。比如图像中人大性别
- 回归问题是根据输入预测一个(连续的)数值的问题。比如根据图像预测某个人大体重的问题
softmax 函数
把一组“任意数值”变成“概率分布”
def softmax(a):
c = np.max(a)
exp_a = np.exp(a - c) # 防止溢出
sum_exp_a = np.sum(exp_a)
y = exp_a / sum_exp_a
return y
| 对比 | Sigmoid | Softmax |
|---|---|---|
| 作用 | 单个输出变概率 | 一组输出变概率 |
| 关系 | 彼此独立 | 彼此竞争 |
| 用途 | 二分类 / 多标签 | 多分类(只能选一个) |
| 输出和 | 不等于1 | 必定=1 |
为什么模型不用直接输出概率?
神经网络先输出“打分”,是因为打分是自然的、好学的、稳定的。概率是“比较后的结果”,适合最后一步再算。
特征 → 打分(logits) → softmax → 概率 → 决策
手写数字识别
MNIST数据集
url_base = 'https://storage.googleapis.com/cvdf-datasets/mnist/'
key_file = {
'train_img':'train-images-idx3-ubyte.gz', # 60,000 训练图像
'train_label':'train-labels-idx1-ubyte.gz', # 60,000 训练标签
'test_img':'t10k-images-idx3-ubyte.gz', # 10,000 测试图像
'test_label':'t10k-labels-idx1-ubyte.gz' # 10,000 测试标签
}
- train_img + train_label → 用于训练模型
- test_img + test_label → 用于评估模型
- 图像是 28×28 灰度图,标签是 0~9 数字
- 都是 gzip 压缩的 IDX 格式,需要解压和解析才能使用
minst.pkl文件的生成过程
┌───────────────────────────┐
│ 原始手写数字扫描图像 │
│ (灰度扫描,每张不定尺寸) │
└─────────────┬─────────────┘
│
▼
┌───────────────────────────┐
│ 数据预处理 & 统一尺寸 │
│ - 裁剪 & 缩放到28×28 │
│ - 灰度化 (0~255) │
└─────────────┬─────────────┘
│
▼
┌───────────────────────────┐
│ 保存为 IDX 二进制文件 │
│ - 图像文件 (IDX3): │
│ train-images-idx3-ubyte │
│ t10k-images-idx3-ubyte │
│ - 标签文件 (IDX1): │
│ train-labels-idx1-ubyte │
│ t10k-labels-idx1-ubyte │
│ - 文件头+连续二进制数据 │
└─────────────┬─────────────┘
│
▼
┌───────────────────────────┐
│ gzip 压缩 (.gz) │
│ - train-images-idx3-ubyte.gz │
│ - train-labels-idx1-ubyte.gz │
│ - t10k-images-idx3-ubyte.gz │
│ - t10k-labels-idx1-ubyte.gz │
└─────────────┬─────────────┘
│
▼
┌───────────────────────────┐
│ 解压 .gz 文件 │
│ → 得到原始 IDX 二进制文件 │
└─────────────┬─────────────┘
│
▼
┌───────────────────────────┐
│ 解析 IDX 文件 → NumPy 数组 │
│ - 图像: (num_samples,28,28)│
│ - 标签: (num_samples,) │
└─────────────┬─────────────┘
│
▼
┌───────────────────────────┐
│ 可选数据处理 │
│ - 归一化 (0~1) │
│ - 展平 (28*28 → 784) │
│ - one-hot 编码标签 │
└─────────────┬─────────────┘
│
▼
┌───────────────────────────┐
│ 保存为 mnist.pkl │
│ - Python 字典 pickle 文件 │
│ {train_img, train_label, │
│ test_img, test_label} │
└───────────────────────────┘
数据推理
import sys, os
import pickle
import numpy as np
import gzip
from PIL import Image
# MNIST数据保存路径
save_file = "./mnist.pkl"
#
def _change_one_hot_label(X):
T = np.zeros((X.size, 10))
for idx, row in enumerate(T):
row[X[idx]] = 1
return T
def load_mnist(normalize=True, flatten=True, one_hot_label=False):
"""读入MNIST数据集
Parameters
----------
normalize : 将图像的像素值正规化为0.0~1.0
one_hot_label :
one_hot_label为True的情况下,标签作为one-hot数组返回
one-hot数组是指[0,0,1,0,0,0,0,0,0,0]这样的数组
flatten : 是否将图像展开为一维数组
Returns
-------
(训练图像, 训练标签), (测试图像, 测试标签)
"""
# 判断mnist.pkl文件是否存在
with open(save_file, 'rb') as f:
dataset = pickle.load(f) # 载入数据集
# 进行数据处理
if normalize:
for key in ('train_img', 'test_img'):
dataset[key] = dataset[key].astype(np.float32)
dataset[key] /= 255.0
# one-hot编码
if one_hot_label:
dataset['train_label'] = _change_one_hot_label(dataset['train_label'])
dataset['test_label'] = _change_one_hot_label(dataset['test_label'])
# 展开为一维数组
if not flatten:
for key in ('train_img', 'test_img'):
dataset[key] = dataset[key].reshape(-1, 1, 28, 28)
# 返回训练数据和测试数据
return (dataset['train_img'], dataset['train_label']), (dataset['test_img'], dataset['test_label'])
def img_show(img):
pil_img = Image.fromarray(np.uint8(img))
pil_img.show()
# 读入MNIST数据集
(x_train, t_train), (x_test, t_test) = load_mnist(flatten=True, normalize=False)
img = x_train[0]
label = t_train[0]
print(label) # 输出标签
print(img.shape) # 输出图像形状(784,)
img = img.reshape(28, 28) # 将一维数组形状转换为二维数组形状(28, 28)
print(img.shape) # 输出图像形状(28, 28)
img_show(img) # 显示图像
神经网络的输入层有784个神经元(28x28)算出, 输出层有10个神经元,对应10个阿拉伯数字
推理实现
# 获取MNIST数据集
def get_data():
(x_train, t_train), (x_test, t_test) = load_mnist(flatten=True, normalize=False)
return (x_train, t_train), (x_test, t_test)
# 学习到大权重参数
def init_network():
with open("sample_weight.pkl", 'rb') as f:
network = pickle.load(f)
return network
# 预测函数
def sigmoid(x):
# 数值稳定的 sigmoid 实现,避免在 np.exp 中出现溢出
x = np.clip(x, -500, 500)
return 1.0 / (1.0 + np.exp(-x))
# 前向传播中的softmax函数
def softmax(a):
c = np.max(a)
exp_a = np.exp(a - c) # 防止溢出
sum_exp_a = np.sum(exp_a)
y = exp_a / sum_exp_a
return y
# 预测函数
def predict(network, x):
# 神经网络中的权重
W1, W2, W3 = network['W1'], network['W2'], network['W3']
# 神经网络中的偏置
b1, b2, b3 = network['b1'], network['b2'], network['b3']
# 前向传播
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
# 前向传播
a2 = np.dot(z1, W2) + b2
z2 = sigmoid(a2)
# 前向传播
a3 = np.dot(z2, W3) + b3
y = softmax(a3)
return y
# 测试预测函数
(x_train, t_train), (x_test, t_test) = get_data()
# 使用测试集进行评估
x, t = x_test, t_test
network = init_network()
accuracy_cnt = 0
for i in range(len(x)):
y = predict(network, x[i])
p = np.argmax(y) # 取得预测结果
if p == t[i]: # 预测正确
accuracy_cnt += 1 # 统计正确次数
print("Accuracy:" + str(float(accuracy_cnt) / len(x))) # 输出正确率
几个概念
- 识别精度:图别的识别率
- 正规化:比如将图像的各个像素值除以255, 将数据的值限定在0.0 ~ 1.0 的范围内
- 预处理:对神经网络的输入数据进行某种既定转换
批处理
输入数据和权重参数的形状(省略了偏置)
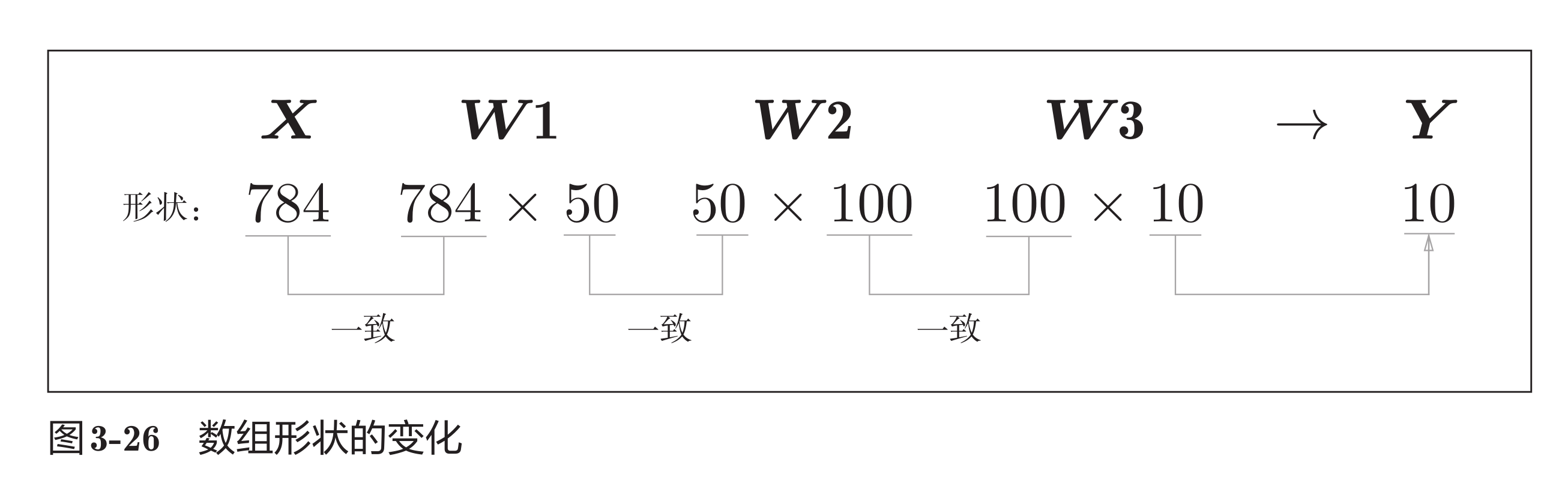
输入一个由784个元素(28x28像素的数组)的一维数组后,输出一个有10个元素的一维数组
(x_train, t_train), (x_test, t_test) = get_data()
# 使用测试集进行评估
x, t = x_test, t_test
# print(x.shape) # (10000, 784)
# print(t.shape) # (10000,)
network = init_network()
batch_size = 100 # 每次处理的样本数量(一次送入模型预测100张图片)
accuracy_cnt = 0 # 用于累计预测正确的样本数
# 使用批处理方式对数据集进行评估
# 从第0个样本开始,每次步进 batch_size(100)
for i in range(0, len(x), batch_size):
# 取出当前批次的数据,例如第0~99张图片、第100~199张图片……
x_batch = x[i:i+batch_size]
# 使用训练好的网络进行预测
# 输出 y_batch 通常是每个样本属于各类别的概率(或得分)
y_batch = predict(network, x_batch)
# np.argmax(axis=1) 表示:
# 在每一行(每张图片的预测结果)中,取概率最大的类别索引
# 即模型最终预测的类别标签
p = np.argmax(y_batch, axis=1)
# 将预测结果 p 与真实标签 t[i:i+batch_size] 进行比较
# p == t[...] 会得到一个布尔数组(True/False)
# np.sum(...) 统计预测正确的数量
accuracy_cnt += np.sum(p == t[i:i+batch_size])
print("Accuracy:" + str(float(accuracy_cnt) / len(x))) # 输出正确率
神经网络的学习
学习是指从训练数据中自动获取最优权重参数的过程。学习的目的就是以损失函数为基准,找出能使函数的值达到最小的权重参数
学习的方式
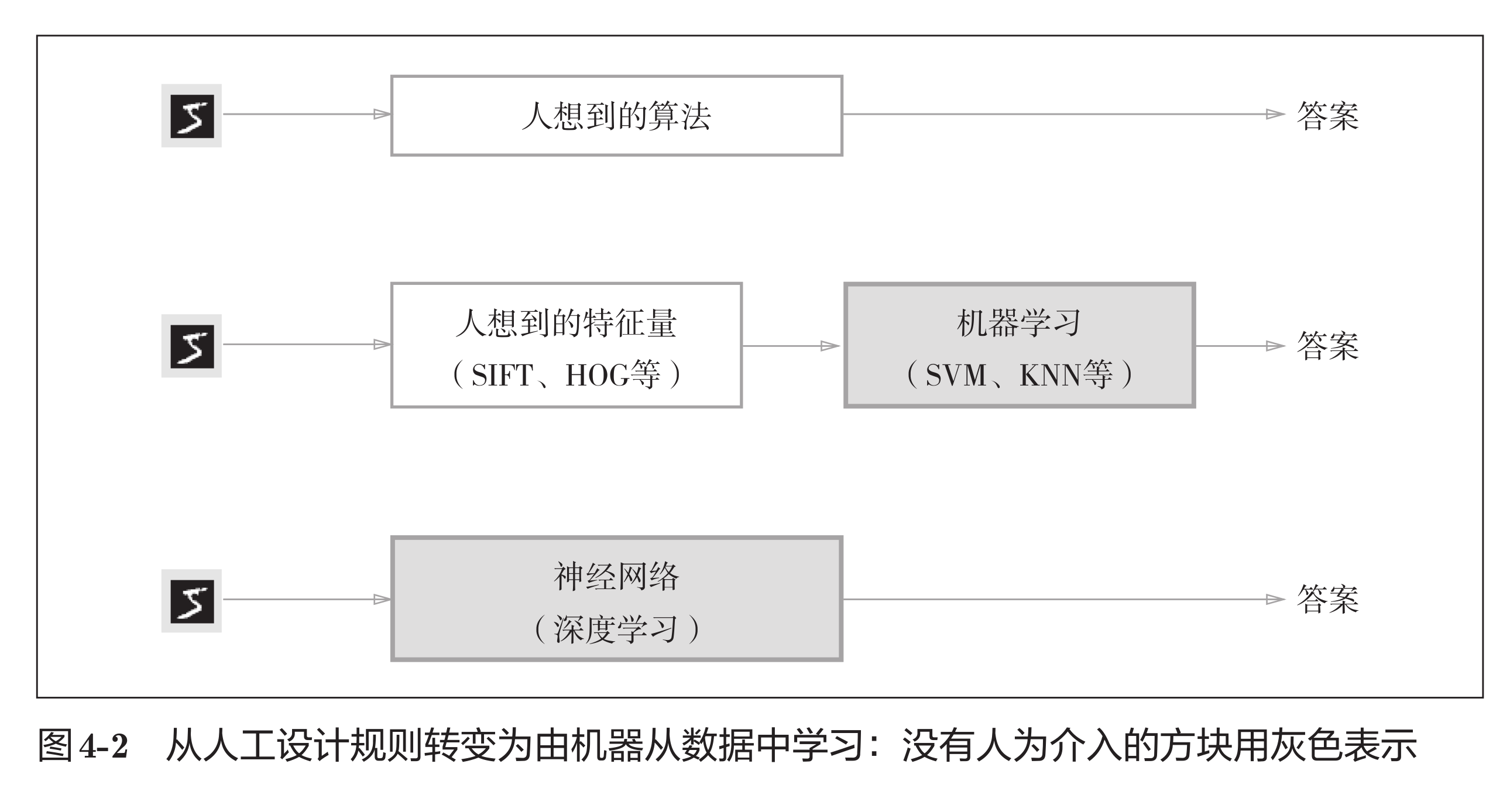
| 对比项 | 传统机器学习(基于特征量) | 深度学习(Deep Learning) |
|---|---|---|
| 特征获取 | 人工设计特征(Feature Engineering) | 自动从数据中学习特征 |
| 模型结构 | 浅层模型(如SVM、决策树、逻辑回归、KNN) | 深层神经网络(CNN、RNN、Transformer等) |
| 数据需求 | 少量数据即可 | 大量数据才有效 |
| 训练成本 | 低 | 高(需要GPU/TPU) |
| 表达能力 | 有上限,难以处理复杂模式 | 极强,可拟合复杂非线性关系 |
| 复杂任务适应性 | 受限,如图像、语音、NLP难度大 | 擅长图像识别、语音、文本、生成任务 |
| 可解释性 | 高,可追踪每个特征贡献 | 低,黑盒性质强 |
| 鲁棒性 | 对噪声/变化敏感 | 对噪声和复杂变化鲁棒性强 |
| 工程门槛 | 中等 | 高,需要算力和深度学习框架 |
| 典型应用 | 信贷风控、传感器数据分析、预测建模 | 图像识别、语音识别、OCR、自动驾驶、生成式AI |
| 优势场景 | 小数据、可解释、嵌入式/低算力 | 大数据、复杂模式、自动特征学习 |
深度学习有时也称为端到端机器学习,获得泛化能力是机器学习的最终目标
几个概念
- 训练数据(监督数据)
- 测试数据
- 泛化能力
- 过拟合:只对某个数据集推理有效
损失函数
损失函数是表示神经网络性能的指标
神经网络训练本质只有一件事:最小化损失函数
常见损失函数
| 分类 | 损失函数 | 用途 | 使用频率 |
|---|---|---|---|
| 回归 | MSE | 数值预测 | ⭐⭐⭐⭐⭐ |
| 回归 | MAE | 抗异常值 | ⭐⭐⭐⭐ |
| 回归 | Huber | MSE+MAE折中 | ⭐⭐⭐ |
| 分类 | Cross Entropy | 多分类 | ⭐⭐⭐⭐⭐ |
| 分类 | Binary CrossEntropy | 二分类 | ⭐⭐⭐⭐⭐ |
| 分类 | Focal Loss | 类别不平衡 | ⭐⭐⭐⭐ |
| 分割 | Dice Loss | 医学图像 | ⭐⭐⭐⭐ |
| 分割 | IoU Loss | 目标分割 | ⭐⭐⭐ |
| 检测 | Smooth L1 | 目标框回归 | ⭐⭐⭐⭐ |
| 检测 | GIoU/CIoU | YOLO/检测 | ⭐⭐⭐⭐ |
| NLP | CTC Loss | 语音/OCR | ⭐⭐⭐ |
| NLP | KL Divergence | 分布对齐 | ⭐⭐⭐ |
数据标注
MNIST 属于 监督数据集, 每张图片都有:标签(0~9)
监督数据 = 带答案的数据集 训练数据 = 从监督数据中拿出来专门用来训练的那部分
标签(监督数据)是谁做的?
- 人工标注
- 半自动标注
- 模型标注
- 自监督生成
AI最贵的成本 = 数据标注,甚至比算力还贵
chatgpt 的数据是如何标注的
阶段1:预训练(几乎没有人工标注)
自监督学习(self-supervised):文本本身就是标签
数据来源:
- 网页文本
- 书籍
- 论文
- 代码
- Wikipedia
- 公共论坛
任务
给一句话,让模型预测下一个词
阶段2:监督微调(SFT)
开始出现“人工标注”
- 人类写高质量问答
- 人类修改模型回答
阶段3:RLHF(真正关键)
人类给回答打分,训练一个奖励模型
| 回答 | 人类评分 |
|---|---|
| A | 好 |
| B | 一般 |
| C | 差 |
真正昂贵的是这里,OpenAI、Anthropic、Google 都花巨资在这一步
原因:
- 需要高质量人工评审
- 需要专家
- 需要大量对比数据
训练一个垂直行业 GPT 的完整数据流程
原始行业数据
↓
数据清洗 & 结构化
↓
任务设计(问答 / 推理 / 生成)
↓
自监督预训练 / 继续预训练
↓
监督微调(SFT)
↓
偏好对齐(RLHF / AI Feedback)
↓
评测 & 安全过滤
↓
上线 + 数据闭环
| 环节 | 成本占比 |
|---|---|
| 数据清洗 | 40% |
| 标注 & SFT | 30% |
| RLHF | 20% |
| 训练算力 | 10% |
不是算力最贵,是数据
- 美国 AI 公司:花钱买高质量数据 → 自动化清洗 → 高效训练 → 快速迭代
- 中国 AI 公司:数据自己整合 → 人工清洗和标注 → 成本低但耗时 → 闭环能力有限
均方误差 MSE
均方误差: MSE, Mean Squared Error
模型每预测错一点,就扣分;错得越离谱,扣分越狠, 用于数值预测
公式
MSE = 平均(预测值 - 真实值)²
- 均方误差用于回归问题,分类用会导致梯度消失或者收敛慢
- 交叉熵直接基于概率 → 对分类问题优化更有效
交叉熵误差
cross entropy error
交叉熵就是一个衡量模型“自信对不对”的分数
- 预测越接近真实 → 惩罚越少
- 预测越偏离真实 → 惩罚越大
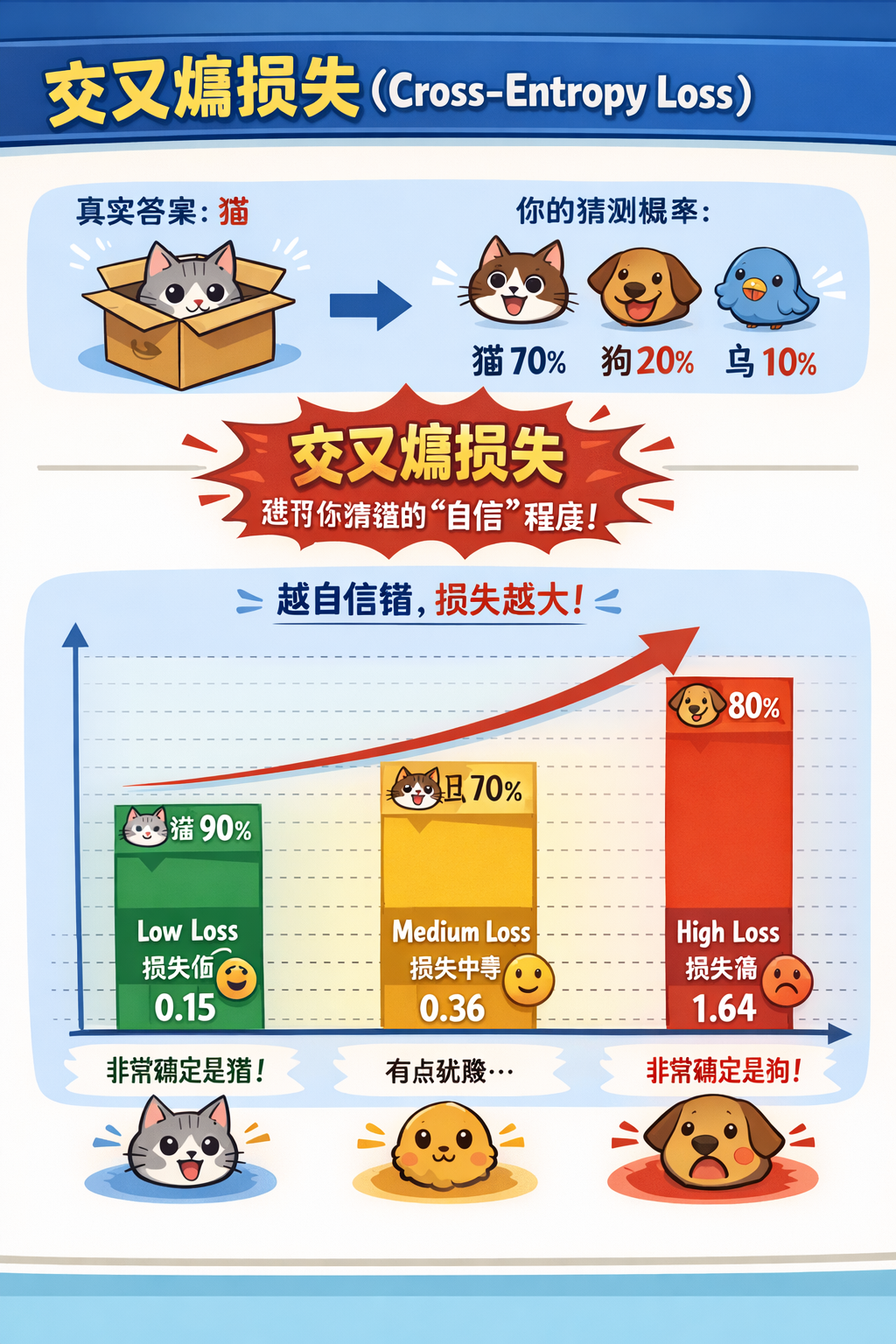
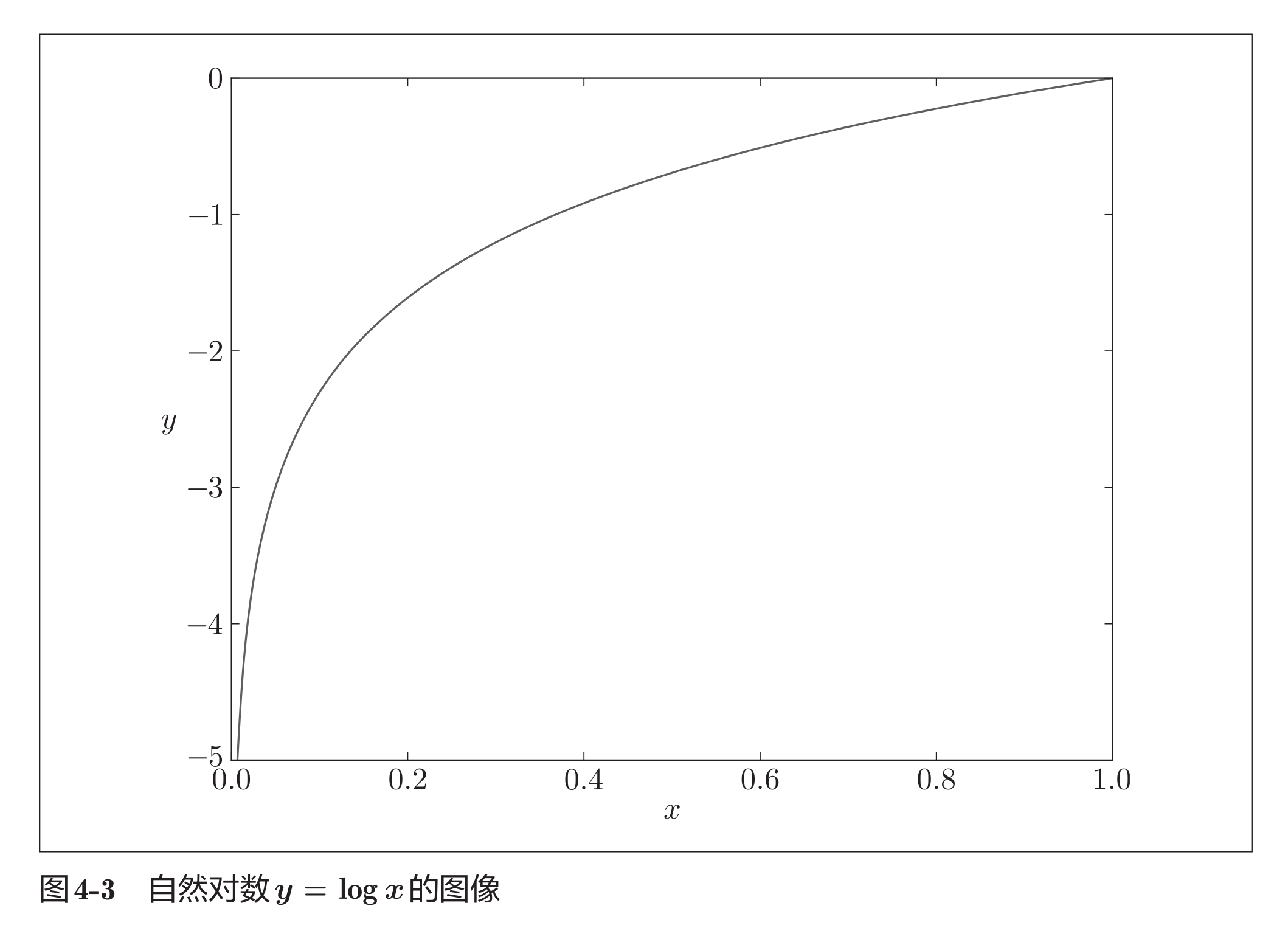
函数图像
mini-batch 学习
Mini-batch 学习 = 每次训练使用部分样本(比如 32、64、128 张图片)
- 梯度计算:用这一小部分数据计算梯度
- 更新模型参数
- 循环遍历所有数据
优势
- 减少内存占用–>不必一次性加载全部训练数据
- 加快训练速度–>可以利用 GPU 并行处理 mini-batch
- 梯度噪声有益–>小幅度噪声可以帮助模型跳出局部最优
def _change_one_hot_label(X):
T = np.zeros((X.size, 10)) # 1️⃣ 创建一个全零矩阵,行数 = 标签数量,列数 = 10(类别数)
for idx, row in enumerate(T):
row[X[idx]] = 1 # 2️⃣ 对应行 X[idx] 的位置设为 1
return T # 3️⃣ 返回 one-hot 编码后的矩阵
# 对应上面的 X
array([[0., 0., 0., 1., 0., 0., 0., 0., 0., 0.], # 类别 3
[1., 0., 0., 0., 0., 0., 0., 0., 0., 0.], # 类别 0
[0., 0., 0., 0., 1., 0., 0., 0., 0., 0.], # 类别 4
[0., 1., 0., 0., 0., 0., 0., 0., 0., 0.]]) # 类别 1
_change_one_hot_label(X) 的作用就是把整数标签数组 X 转换成 one-hot 编码矩阵,用于神经网络训练时计算损失
import sys, os
import numpy as np
from mnist_demo import load_mnist, init_network, predict
(x_train, t_train), (x_test, t_test) = load_mnist(flatten=True, normalize=False, one_hot_label=True)
print(x_train.shape) # (60000, 784)
print(t_train.shape) # (60000, 10)
train_size = x_train.shape[0]
batch_size = 10
# 从训练数据中随机抽取batch_size个样本
batch_mask = np.random.choice(train_size, batch_size)
# 选取对应的样本
xbatch = x_train[batch_mask]
# 选取对应的标签
tbatch = t_train[batch_mask]
def cross_entropy_error(y, t):
"""
计算交叉熵误差(Cross-Entropy Loss)
参数:
y : np.ndarray
神经网络输出的预测概率(Softmax 输出),形状为 (batch_size, 类别数)
t : np.ndarray
真实标签,one-hot 编码,形状为 (batch_size, 类别数) 或一维标签
返回:
float
平均交叉熵损失值
"""
# 如果 y 是一维数组(单个样本),则将其扩展为二维数组
# 这样可以统一处理单样本和批量样本的情况
if y.ndim == 1:
t = t.reshape(1, t.size) # 将真实标签从 (类别数,) 转为 (1, 类别数)
y = y.reshape(1, y.size) # 将预测概率从 (类别数,) 转为 (1, 类别数)
# 获取批量样本的数量
batch_size = y.shape[0]
# 计算交叉熵误差
# 公式:L = -1/N * Σ Σ t_ij * log(y_ij)
# 1e-7 是为了避免 log(0) 出现数值错误
# t * np.log(y + 1e-7) 是逐元素相乘,只保留真实标签对应位置的 log 概率
# np.sum() 对所有样本和类别求和
loss = -np.sum(t * np.log(y + 1e-7)) / batch_size
return loss
为什么要设定损失函数
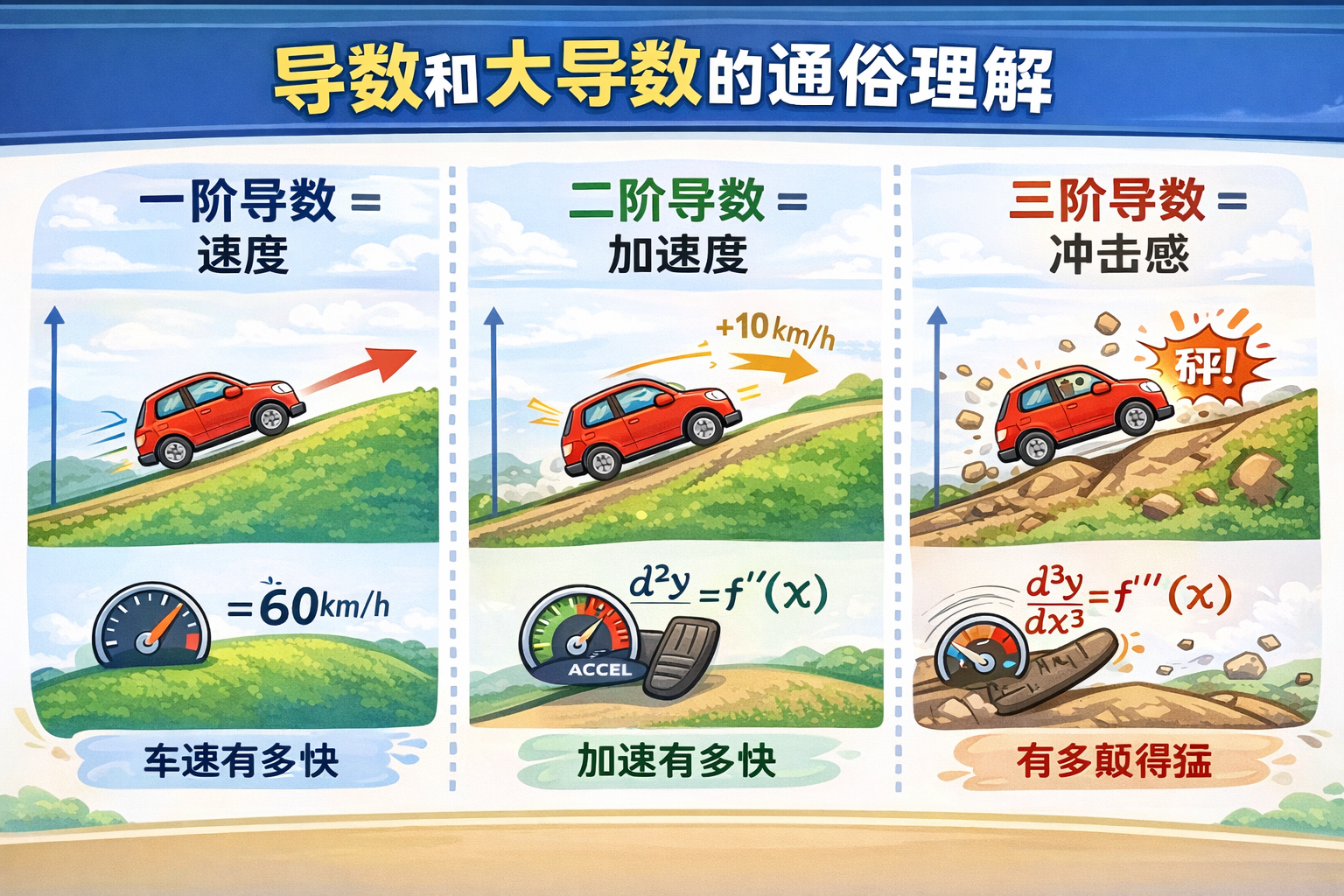
导数的概念
| 阶数 | 含义 | 通俗比喻 |
|---|---|---|
| 一阶 | 函数变化率 | 速度 / 坡度 |
| 二阶 | 函数变化率的变化率 | 加速度 / 坡度变化快慢 |
| 三阶 | 二阶变化率 | 加速度变化率 / 冲量 |
| n阶 | n-1 阶变化率的变化率 | 曲线更高阶变化 |
通俗理解导数
导数就是曲线上某一点的斜率
- 一阶导数:你在山坡上,坡有多陡
- 二阶导数:坡度变化快不快(弯曲)
- 三阶导数:弯曲的变化快不快(颠簸感)
在神经网络的学习中,寻找最优参数(权重和偏置)时, 要寻找使损失函数的值尽可能小的参数, 需要计算参数的导数
参数的导数是指参数的调节方向
| 概念 | 比喻 | 作用 |
|---|---|---|
| 参数 | 旋钮 | 可调节,控制输出 |
| 损失函数 | 拼图评分 | 告诉你离目标有多远 |
| 参数导数 | 每个旋钮的调节方向 | 指示顺/逆、调多少 |
| 梯度 | 全部旋钮的调节指南 | 指示最优更新方向 |
| 精度 | 拼图是否完成 | 只看结果,不指导调整 |
数值微分
数值微分:利用微小的差分求导数的过程称为数值微分 解析性求导:是不含误差的真的导数
| 对比项 | 数值微分 | 解析求导 |
|---|---|---|
| 精度 | 近似 | 精确 |
| 计算成本 | 很高 | 低(推导后) |
| 是否需要公式 | 不需要 | 必须有数学表达式 |
| 是否适合神经网络训练 | ❌ 不适合 | ✅ 必须使用 |
| 用途 | 验证梯度是否正确 | 实际训练 |
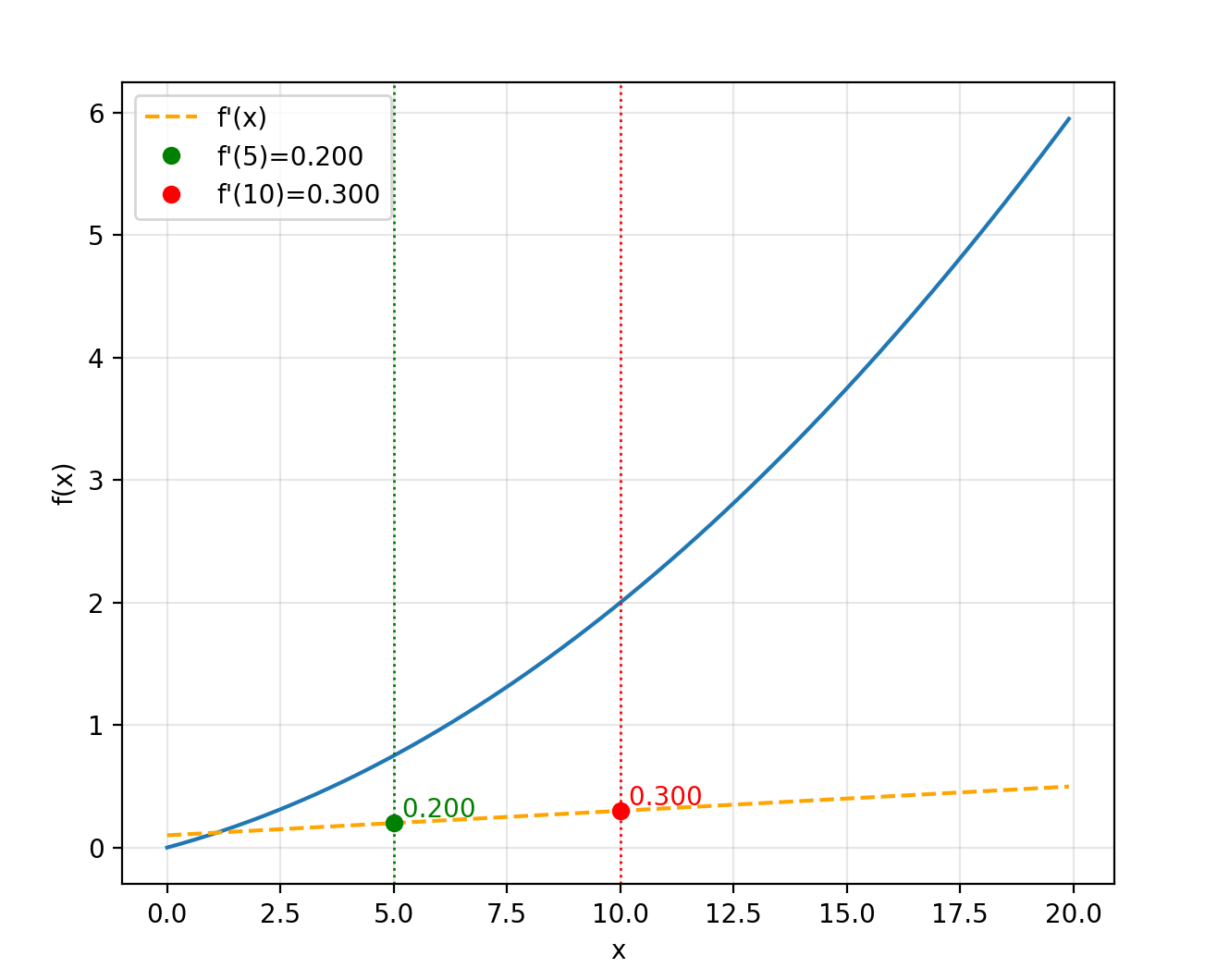
import numpy as np
import matplotlib.pylab as plt
def funcion_1(x):
return 0.01 * x ** 2 + 0.1 * x
def numerical_diff(f, x):
h = 1e-4 # 0.0001
return (f(x + h) - f(x - h)) / (2 * h)
x = np.arange(0.0, 20.0, 0.1)
y = funcion_1(x)
plt.xlabel("x")
plt.ylabel("f(x)")
plt.plot(x, y)
a = numerical_diff(funcion_1, 5) # 0.2
b = numerical_diff(funcion_1, 10) # 0.3
print(a)
print(b)
# 计算并绘制数值导数
y_diff = numerical_diff(funcion_1, x)
plt.plot(x, y_diff, color="orange", linestyle='--', label="f'(x)")
# 在 x=5 和 x=10 处画竖线、标记导数值并注释数值
plt.axvline(5, color='green', linestyle=':', linewidth=1)
plt.axvline(10, color='red', linestyle=':', linewidth=1)
plt.plot(5, a, 'o', color='green', label="f'(5)={:.3f}".format(a))
plt.plot(10, b, 'o', color='red', label="f'(10)={:.3f}".format(b))
plt.text(5, a, ' {:.3f}'.format(a), color='green', va='bottom')
plt.text(10, b, ' {:.3f}'.format(b), color='red', va='bottom')
plt.legend()
plt.grid(alpha=0.3)
plt.show()
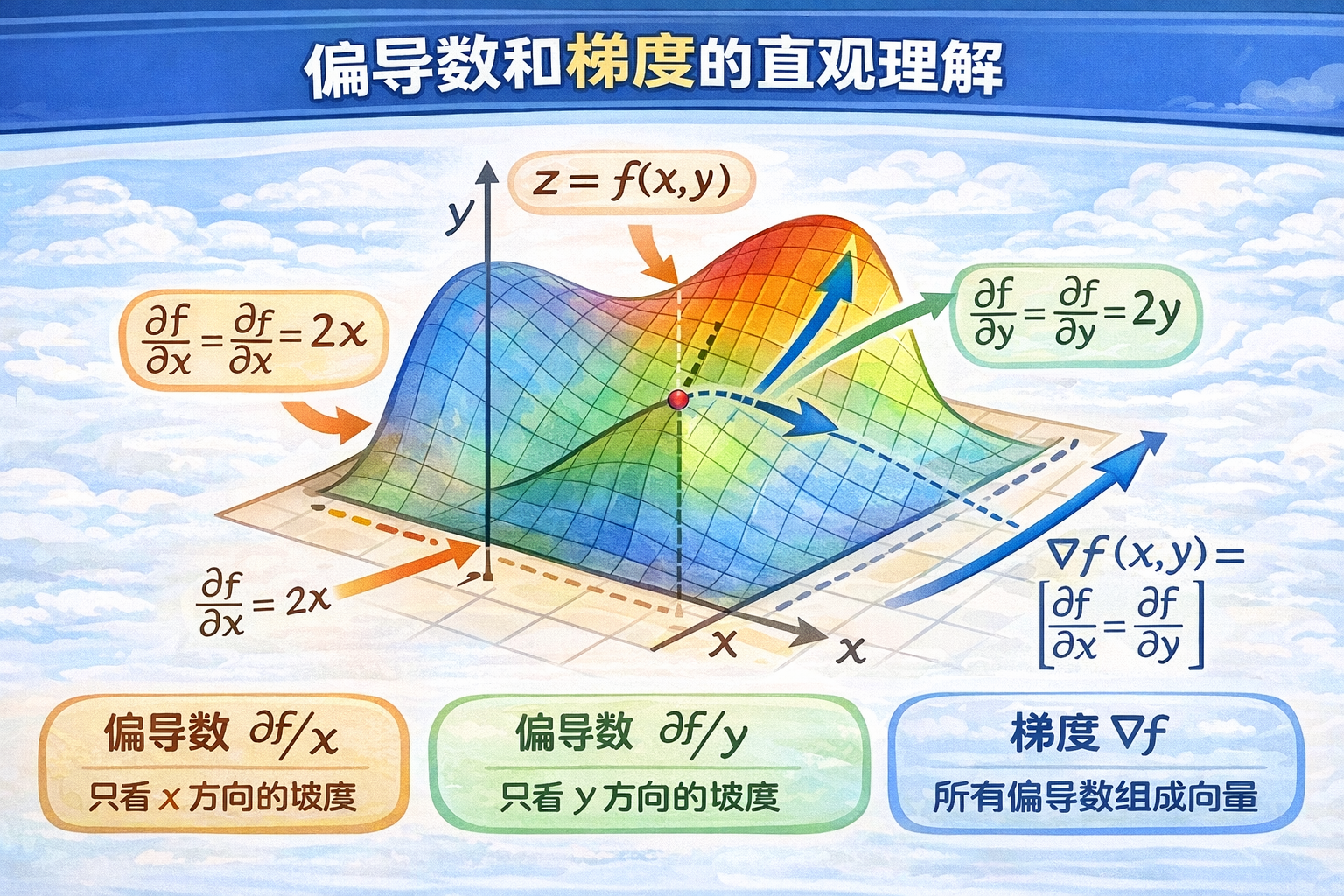
偏导数 和 梯度 gradient
偏导数:固定其他变量,只看某一个变量变化时,函数的变化率
| 名称 | 含义 | 比喻 |
|---|---|---|
| 偏导数 ∂f/∂x | 多变量函数只看 x 的变化率 | 只沿 x 方向看坡度 |
| 偏导数 ∂f/∂y | 多变量函数只看 y 的变化率 | 只沿 y 方向看坡度 |
| 梯度 ∇f | 所有偏导数组成向量 | 指向坡度最大的方向 |
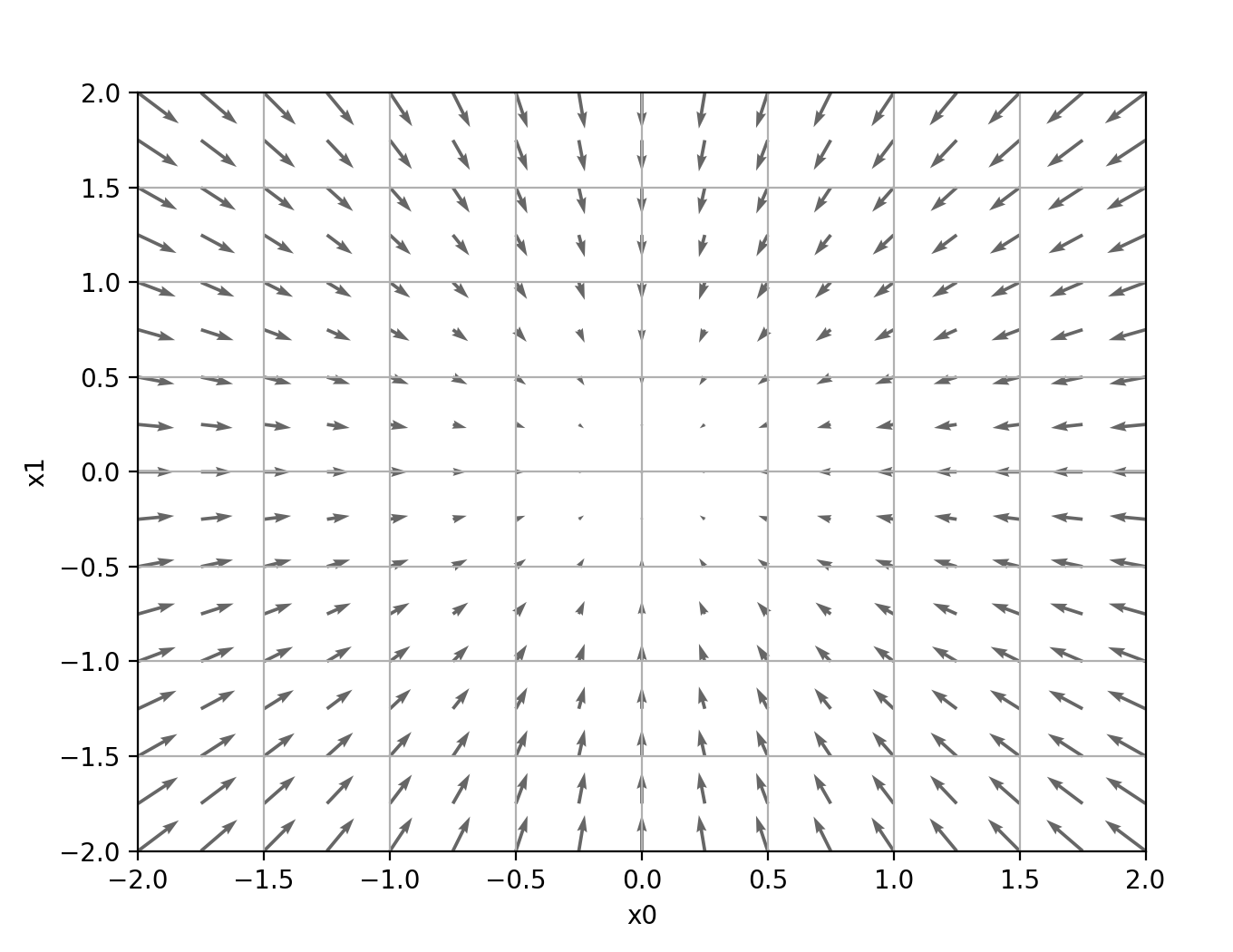
# coding: utf-8
"""
绘制简单二维函数的数值梯度(偏导)可视化。
本模块实现了使用中心差分法计算数值梯度的工具函数,并绘制函数
f(x) = x0^2 + x1^2 的梯度场(使用箭头图)。图中绘制负梯度以表示
最陡下降的方向,便于观察优化方向。
用法(直接运行脚本):
python3 gradient_2d.py
脚本会在区间 [-2,2]x[-2,2] 上建立网格,计算每个网格点的梯度,并
用箭头表示 -∇f(下降方向)。
"""
import numpy as np
import matplotlib.pylab as plt
from mpl_toolkits.mplot3d import Axes3D
def _numerical_gradient_no_batch(f, x):
"""对单个点(向量)x 计算数值梯度。
使用中心差分近似对每一维进行求导:
grad_i = (f(x + h*e_i) - f(x - h*e_i)) / (2*h)
参数
-----
f : callable
接受 numpy 数组 `x` 并返回标量 f(x) 的函数。
x : numpy.ndarray
表示 R^n 中单点的 1 维数组。
返回
----
grad : numpy.ndarray
与 `x` 形状相同的 1 维数组,包含在点 `x` 处近似得到的偏导数值。
"""
h = 1e-4 # 有限差分使用的步长(较小但不宜过小)
grad = np.zeros_like(x)
# 遍历每个维度,计算对应的偏导数
for idx in range(x.size):
tmp_val = x[idx]
# f(x + h*e_i)
x[idx] = float(tmp_val) + h
fxh1 = f(x)
# f(x - h*e_i)
x[idx] = tmp_val - h
fxh2 = f(x)
# 中心差分公式
grad[idx] = (fxh1 - fxh2) / (2 * h)
# 恢复原始值以便计算下一维
x[idx] = tmp_val
return grad
def numerical_gradient(f, X):
"""对输入 X(批量或单点形式)计算数值梯度。
若 `X` 为 1 维数组(单点),返回该点的梯度向量。若 `X` 为 2 维数组,
则对 `X` 的每一行分别计算梯度并返回。
注意:本函数保留了示例中使用的接口:以 `np.array([X_flat, Y_flat])`
(形状为 (2, N))调用时,会返回与之对应形状的梯度数组。
"""
if X.ndim == 1:
return _numerical_gradient_no_batch(f, X)
else:
grad = np.zeros_like(X)
# 对 X 的每一行(或每个向量)计算梯度
for idx, x in enumerate(X):
grad[idx] = _numerical_gradient_no_batch(f, x)
return grad
def function_2(x):
"""简单测试函数:f(x0,x1) = x0^2 + x1^2。
可接受单个 1 维点 `x`(形状 (2,)),也可接受每行表示一个点的 2 维数组,
分别返回标量或标量数组。
"""
if x.ndim == 1:
return np.sum(x ** 2)
else:
# If x is shape (N, 2), sum across axis=1 to produce N values
return np.sum(x ** 2, axis=1)
def tangent_line(f, x):
"""返回给定 1 维点 `x` 处切线的 lambda 表达式。
该辅助函数计算点处的梯度(斜率),并构造一阶线性近似(切线),
主要用于一维示例展示。
"""
d = numerical_gradient(f, x)
print(d)
y = f(x) - d * x
return lambda t: d * t + y
if __name__ == '__main__':
# 在区域 [-2, 2] x [-2, 2] 上生成规则网格
x0 = np.arange(-2, 2.5, 0.25)
x1 = np.arange(-2, 2.5, 0.25)
X, Y = np.meshgrid(x0, x1)
# 将网格坐标展开为点列表。展开后 X 和 Y 为长度为 N 的 1 维数组。
X = X.flatten()
Y = Y.flatten()
# 为 numerical_gradient 准备输入。此处的约定是传入一个 2xN 的数组,
# 其中第 0 行为所有 x 坐标,第 1 行为所有 y 坐标,numerical_gradient
# 将对每一行计算对应的偏导。
grad = numerical_gradient(function_2, np.array([X, Y]))
# 将负梯度 (-∇f) 绘制为箭头。对于 f(x)=x^2,-∇f 指向原点(极小值点),
# 绘制负梯度有助于直观展示最陡下降的方向。
plt.figure()
plt.quiver(X, Y, -grad[0], -grad[1], angles="xy", color="#666666")
plt.xlim([-2, 2])
plt.ylim([-2, 2])
plt.xlabel('x0')
plt.ylabel('x1')
plt.grid()
# 说明:当前图中未添加带标签的图例元素,调用 legend() 会为空,
# 因此注释掉以避免警告;若后续添加带标签的图元,则可启用 legend().
plt.draw()
plt.show()
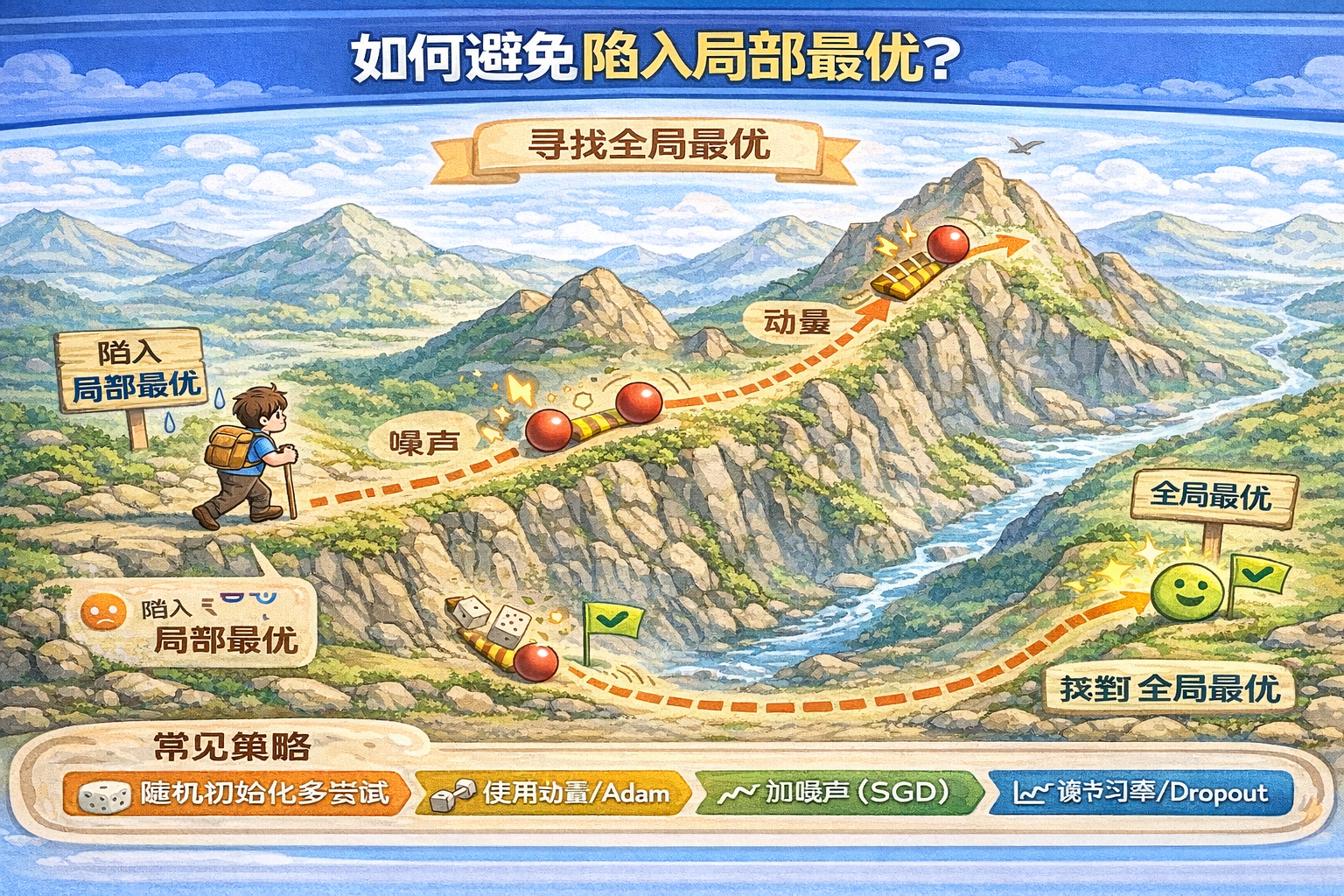
梯度下降法
机器学习的主要任务是在学习时寻找最优参数。同样地,神经网络也必须在学习时找到最优参数(权重和偏置)
这里说的最优参数是指损失函数取最小值时的参数。但是损失函数很复杂,参数空间庞大,我们不知道它在何处取得最小值。
通过巧妙的使用梯度来寻找函数的最小值的方法就是梯度法
鞍点:函数的极小值、最小值
局部最优(local minimum)和全局最优(global minimum)
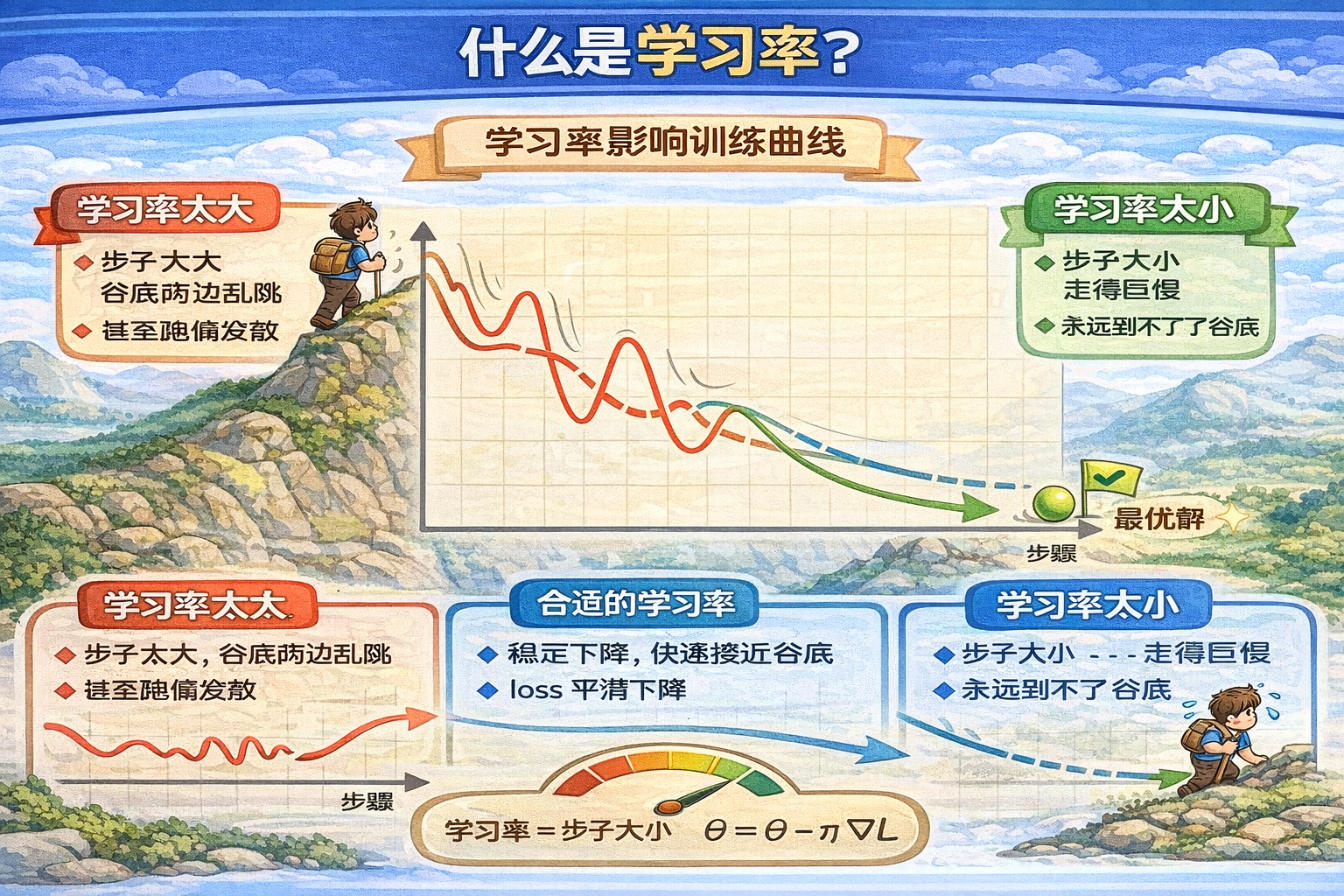
学习率
每次沿着坡往下走,你迈多大的一步
- 梯度 = 告诉你往哪走(方向)
- 学习率 = 决定你走多远(步长)
如果:
- 步子太大 → 可能直接跨过谷底
- 步子太小 → 很久都走不到谷底
# coding: utf-8
"""梯度下降法的实现与可视化。
本模块演示了梯度下降优化算法的基本原理:通过沿负梯度方向迭代更新参数,
最终使目标函数收敛到最小值附近。脚本会绘制优化过程中参数的轨迹。
"""
import numpy as np
import matplotlib.pylab as plt
from gradient_2d import numerical_gradient
def gradient_descent(f, init_x, lr=0.01, step_num=100):
"""使用梯度下降法优化目标函数。
通过计算目标函数的数值梯度,沿负梯度方向迭代更新参数,直到达到
指定的迭代步数。记录每一步的参数值以便后续绘制优化轨迹。
参数
-----
f : callable
目标函数,接受 numpy 数组并返回标量。
init_x : numpy.ndarray
初始参数值,维数为问题的维度。
lr : float,可选
学习率(步长),控制每步的更新幅度。默认值为 0.01。
step_num : int,可选
迭代步数。默认值为 100。
返回
-----
x : numpy.ndarray
最终优化得到的参数值。
x_history : numpy.ndarray
所有迭代步骤的参数值,形状为 (step_num, dim),可用于绘制优化轨迹。
"""
x = init_x
# 存储每次迭代的参数值以便后续绘制
x_history = []
for i in range(step_num):
# 记录当前参数值
x_history.append( x.copy() )
# 计算目标函数在当前点的梯度(数值方法)
grad = numerical_gradient(f, x)
# 沿负梯度方向更新参数:x_{k+1} = x_k - lr * ∇f(x_k)
x -= lr * grad
# 返回最终参数和完整的优化轨迹
return x, np.array(x_history)
def function_2(x):
"""目标函数:f(x0, x1) = x0^2 + x1^2。
这是一个简单的凸函数,在原点 (0, 0) 处达到全局最小值 0。
"""
return x[0]**2 + x[1]**2
# ============ 主程序 ============
# 设置初始参数值
init_x = np.array([-3.0, 4.0])
# 设置学习率和迭代步数
lr = 0.1 # 较大的学习率使收敛更快
step_num = 20 # 迭代 20 步
# 执行梯度下降优化
x, x_history = gradient_descent(function_2, init_x, lr=lr, step_num=step_num)
# ============ 绘制结果 ============
# 绘制坐标轴参考线(x=0 和 y=0 轴)
plt.plot( [-5, 5], [0,0], '--b')
plt.plot( [0,0], [-5, 5], '--b')
# 绘制优化过程中的参数轨迹点
plt.plot(x_history[:,0], x_history[:,1], 'o')
# 设置图的范围和标签
plt.xlim(-3.5, 3.5)
plt.ylim(-4.5, 4.5)
plt.xlabel("X0")
plt.ylabel("X1")
# 显示图像
plt.show()
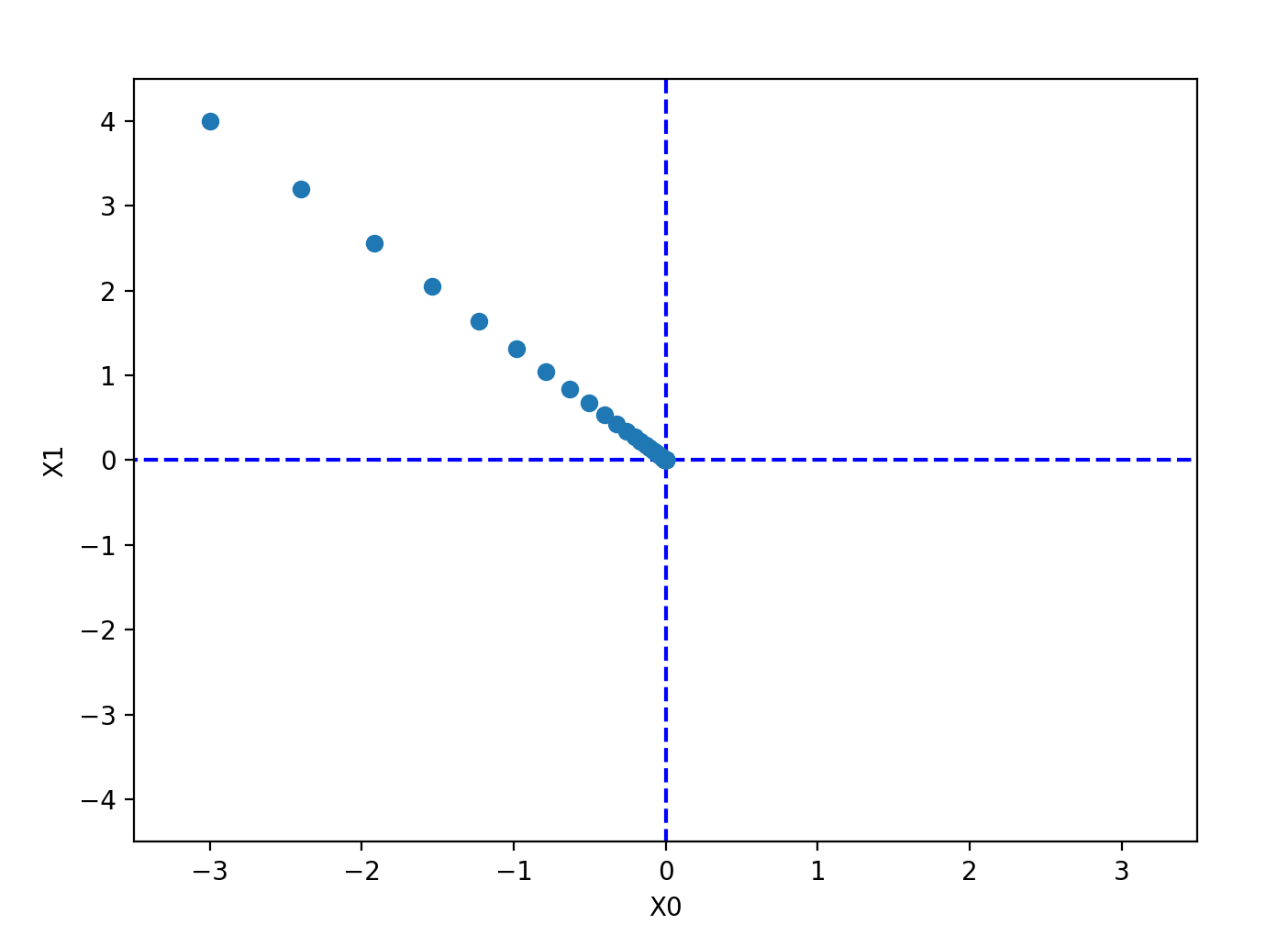
概念总结
| 概念 | 本质 |
|---|---|
| 梯度 | 告诉往哪走 |
| 学习率 | 决定走多远 |
| 梯度下降 | 找谷底的方法 |
| 损失函数 | 山谷形状 |