浮点精度-FP4 FP8 FP16 FP32
用多少“位(bit)”来表示一个浮点数(Floating Point)
位数越小 →
- 占内存越少
- 计算越快
- 功耗越低
- 但精度也越差
| 类型 | 位数 | 精度 | 用途 |
|---|---|---|---|
| FP32 | 32bit | 高 | 传统训练 |
| FP16 | 16bit | 中 | 混合精度训练 |
| FP8 | 8bit | 低 | 推理优化 |
| FP4 | 4bit | 很低 | 大模型量化 |
为什么 AI 越来越低精度?
比如一个 7B 参数模型:
| 精度 | 占用 |
|---|---|
| FP32 | 28GB |
| FP16 | 14GB |
| FP8 | 7GB |
| FP4 | 3.5GB |
精度减半 = 显存减半
硬件设计和精度的关系
位宽越大,硬件成本越高
| 精度 | 电路面积 | 功耗 |
|---|---|---|
| FP32 | 1x | 高 |
| FP16 | 1/4 | 低很多 |
| FP8 | 1/16 | 极低 |
| FP4 | 1/64 | 非常小 |
Nvidia GPU 精度列表
| 架构世代 | 主要支持精度 |
|---|---|
| Ampere (2020) | FP16, BF16, TF32, INT8 |
| Hopper (2022) | FP16, BF16, TF32, FP8, INT8 |
| Ada / RTX 40/50 | FP16, BF16, TF32, INT8, SW-enabled FP8/FP4 |
| Blackwell (2025) | FP16, BF16, TF32, FP8, FP6, FP4, INT8 |
Rockchip RK3588 NPU 支持的精度
| 精度类型 | 是否支持 | 主要用途 |
|---|---|---|
| INT8 | ✅ 主力 | 推理核心格式 |
| INT16 | ✅ 支持 | 特殊算子 |
| FP16 | ✅ 支持 | 部分模型推理 |
| FP32 | ❌ 不支持硬件加速 | 只能 CPU 跑 |
| FP8 / FP4 | ❌ 不支持 | 无硬件单元 |
RK3588 NPU 的真正高性能路径是 INT8:
- 6 TOPS 是按 INT8 算的
- FP16 性能会下降
- 量化模型才能跑满 NPU
Nvidia 推理全面转向 FP4
| 特征 | Blackwell | Rubin |
|---|---|---|
| 晶体管 (全芯片) | 208B | 336B |
| 计算芯片数 | 2 | 2 |
| NVFP4 推理 (PFLOPS) | 10 | 50* |
| FP8 训练 (PFLOPS) | 5 | 17.5 |
| 软最大加速 (SFU EX2 运算/时钟/SM) | FP32: 16 FP16: 32 |
FP32: 32 FP16: 64 |
AI 推理往往受限于显存带宽(Memory Bound)。数据越小,单位时间内传输的“参数”就越多。FP4 让模型在读取权重时速度更快,直接提升了生成速度(Tokens per second)
FP4 是为了万亿级模型的大规模廉价推理而生的。它牺牲了一点点普适性,换取了极致的性价比
将高精度训练的大模型(通常为 FP32 或 BF16)转换为低精度推理(如 FP8 或 FP4),这个过程在 AI 工业界被称为量化(Quantization)
NVIDIA Rubin 平台带来的市场影响
- Rubin 平台最核心的市场杀伤力在于:它通过 FP4 精度和 HBM4 内存,将 每百万 Token 的推理成本降低了 10 倍
由于智能体需要进行多步推理和自我反思,计算量是传统聊天机器人的数倍。Rubin 的出现让企业部署 24/7 全天候自主 AI 员工的成本从“不可承受”变为“极具性价比”。
- NVIDIA 已经完成了从“卖显卡”到“卖货架”的转型。Rubin 不是一张显卡,而是一个包含 Vera CPU、Rubin GPU、NVLink 6 网络、BlueField DPU 等六颗核心芯片的完整系统。
数据中心单位不再以“服务器”计,而是以 “机架”(Rack) 计。Rubin NVL72 这种整机柜方案将迫使亚马逊(AWS)、微软等云服务商加速淘汰旧有的风冷数据中心,向液冷、超高功耗密度的“AI 工厂”转型,这带动了万亿规模的基础设施翻新。
- Rubin 首次大规模采用 HBM4(带宽达 22 TB/s,容量 288GB,此前大模型的痛点在于“存不下”和“读得慢”。
Rubin 的超大内存和 HBM4 带宽让万亿参数模型可以在更少的节点间运行,极大地减少了网络延迟。这标志着 AI 计算从“算力受限”时代正式进入“带宽与内存受限”时代。
随机梯度下降法 SGD
Stochastic gradient descent 随机梯度下降法
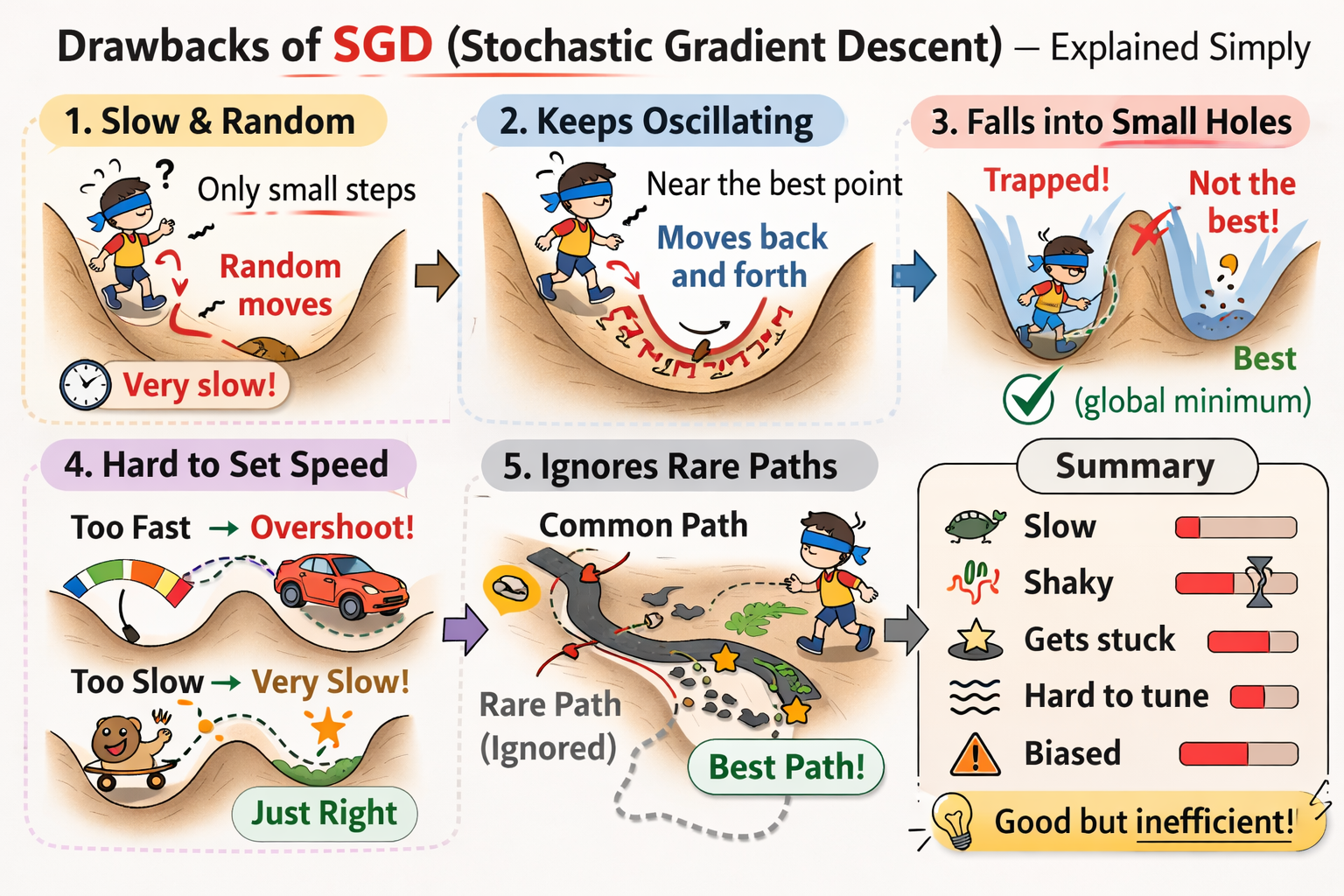
SGD 低效的根本原因是梯度的方向没有指向最小值的方向
卷积神经网络 CNN
Convolutional Neural Networks
CNN 就像一支“聪明的侦探队”,专门找图像里的重要特征,从小细节到整体结构,逐层分析,最后告诉你图片里有什么
CNN 本质上是一个深度神经网络,擅长处理图像、视频、语音等带有空间/局部结构的数据
大模型(Large Models),例如 GPT-4、PaLM、LLaMA 等,通常是 Transformers 架构,擅长处理序列数据(文本、代码、序列信号)
卷积神经网络和大模型的关系
| 方面 | CNN | 大模型(Transformer/GPT 系列) |
|---|---|---|
| 任务擅长 | 图像、局部特征识别 | 文本、序列数据、多模态 |
| 架构 | 卷积层 + 池化 + 全连接 | 自注意力(Self-Attention) + Feed Forward |
| 作用 | 提取局部空间特征 | 建模长程依赖 / 通用表示 |
| 在大模型中的角色 | 特征前置器(embedding/encoder) | 核心计算与生成能力 |
OpenCV 和 CNN 的关系
| 方面 | OpenCV | CNN |
|---|---|---|
| 功能 | 图像预处理、增强、可视化 | 特征提取和预测 |
| 是否智能 | ❌ 不智能,只是工具 | ✅ 自动学习特征 |
| 关系 | CNN 的输入通常先用 OpenCV 处理 | CNN 依赖 OpenCV 准备数据 |
| 举例 | 图像缩放、裁剪、去噪、颜色转换 | 图像分类、目标检测、分割 |
书籍推荐
作者李沐的经历
- 上海交大与 ACM 班 (2004 - 2011) 本科和硕士
- 百度时期 (2011-2012):曾担任百度高级研究员,参与早期的大规模机器学习系统研发
- 博士阶段 (2012-2017):前往 AI 殿堂 卡内基梅隆大学 (CMU) 攻读博士学位,师从机器学习泰斗 Alex Smola
- 亚马逊 (AWS) 首席科学家 (2017 - 2023)
- Boson AI (2023 - 2026 现状)