Scaling Laws
Scaling Laws(规模定律): 当模型规模、数据量、计算量增加时,模型性能会按照可预测的数学规律提升
最早系统性提出这一规律的是 OpenAI 在 2020 年的论文《Scaling Laws for Neural Language Models》
规模定律正在失效
| 类别 | 核心问题 | 具体表现 | 本质原因 | 是否可通过继续堆算力解决 |
|---|---|---|---|---|
| 数学规律 | 幂律递减 | 算力增加10倍,性能只小幅提升 | α 很小(<1),边际收益递减 | ❌ 本质不可改变 |
| 数据瓶颈 | 高质量数据耗尽 | 新数据质量下降、重复率升高 | 人类高质量文本有限 | ❌ 难以根本解决 |
| 数据污染 | AI 训练 AI | 模型生成内容反向进入训练集 | 信息增量变小 | ❌ 需数据治理而非算力 |
| 架构上限 | Transformer 限制 | 长链推理弱、无世界模型 | 架构不是认知系统 | ❌ 需架构创新 |
| Benchmark 饱和 | 接近测试上限 | 提升 1% 需巨大成本 | 测试已接近人类平均 | ❌ 收益极低 |
| 物理限制 | 功耗墙 | GPU 功耗与散热接近极限 | 半导体物理限制 | ❌ 有物理上限 |
| 经济限制 | 成本爆炸 | 训练成本数亿美元 | 商业不可持续 | ❌ 市场不允许 |
| 系统效率 | 推理成本过高 | 延迟大、部署贵 | 模型过于庞大 | ❌ 需系统优化 |
| 智能本质 | 智能非单变量函数 | 算力增加不等于认知提升 | 缺少目标系统与记忆机制 | ❌ 需结构性突破 |
大模型发展阶段
| 维度 | 🔵 Scaling 阶段(2020–2023) | 🔴 后 Scaling 阶段(2024–以后) |
|---|---|---|
| 核心策略 | 堆参数、堆数据、堆算力 | 提升推理能力与系统设计 |
| 技术信条 | Bigger is better | Smarter is better |
| 性能提升方式 | 扩大模型规模即可提升 | 需要结构与算法创新 |
| 成本结构 | 成本高但可接受 | 成本增速远高于收益 |
| 数据依赖 | 大规模通用语料 | 高质量、结构化、专业数据 |
| 架构 | 纯 Transformer | 推理增强 + 工具调用 + Agent |
| 能力表现 | 语言流畅、知识广 | 复杂推理、多步规划 |
| 训练方式 | 一次性大规模预训练 | 小模型强化推理训练 |
| 商业模式 | 旗舰模型主导 | 分层模型 + 专用模型 |
| 主要瓶颈 | 资金与 GPU 数量 | 数据质量 + 架构效率 |
| 行业代表思路 | GPT-3、GPT-4 规模跃升 | Reasoning Models、Agent 系统 |
Anthropic CEO 在播客采访中说的瓶颈
| 层级 | 是否与 Scaling 相关 |
|---|---|
| 算力边际收益下降 | ✅ 是 |
| 数据质量问题 | ✅ 是 |
| Transformer 结构限制 | ✅ 是 |
| 推理深度不足 | ⚠️ 不完全是规模问题 |
| 对齐难度上升 | ❌ 与规模弱相关 |
| 可解释性问题 | ❌ 结构问题 |
核心观点: 智能的增长点从“训练时(Training-time)”转到了“推理时(Inference-time/RL)”
推理侧 Scaling
什么是推理侧 Scaling?
就是模型在回答你之前,先在后台进行成千上万次的自我模拟、纠错和逻辑推演
通用大模型将像“基础科学”一样,由少数几家巨头(OpenAI, Anthropic, 阿里, 字节)维持,作为底层的语义和逻辑引擎;而碎片化的应用与垂直模型,则是各行各业真正的价值所在
Anthropic
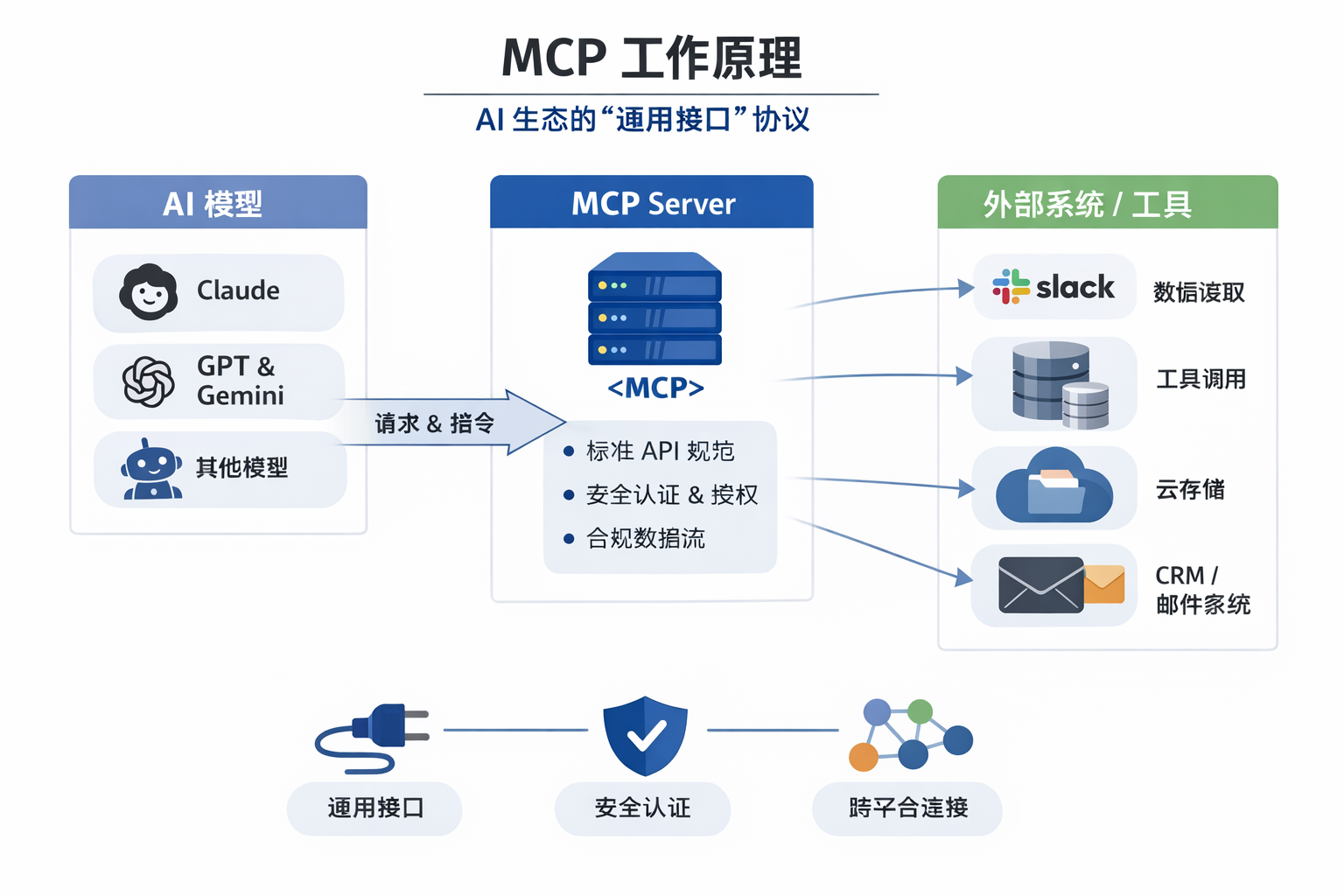
协议标准化的“破局者”:MCP 协议
为了应对 AI 能力的碎片化,他们在 2024 年底发布了 Model Context Protocol (MCP)
MCP 就像是 AI 界的“USB-C 接口“
2026 年,MCP 已成为行业事实标准。无论是 OpenAI 还是微软,都在兼容这个协议。Anthropic 通过制定标准,成功地将自己变成了“碎片化应用”之间的调度中心,而不是一个孤立的聊天框
MCP发展历史
| 时间 | 事件 | 关键意义 |
|---|---|---|
| 2023 下半年 | Anthropic 内部提出 MCP 概念 | 解决“大模型接入工具和数据碎片化”的问题,尝试定义统一接口 |
| 2023–2024 | 内部实验与原型开发 | Claude 系列模型开始支持通过 MCP 调用外部服务,如 Slack、Notion、数据库等 |
| 2024 年初 | 发布首个内部文档版本 | 对接外部开发者和企业,开始形成标准化思路 |
| 2024 下半年 | MCP 对外介绍 | 向开发者社区展示 MCP 如何统一大模型和工具的接入方式,类似“通用接口协议” |
| 2025 年 | 开放标准化推进 | MCP 协议向 Linux 基金会捐赠,确立开放、社区治理路线 |
| 2025–2026 | 社区生态扩展 | 更多大模型厂商和工具开发者开始支持 MCP,实现模型与外部系统的无缝连接 |
| 未来趋势 | 进一步演进 | 可能加入更复杂的权限控制、数据安全、跨平台兼容和模型协作能力,成为 AI 基础设施标准之一 |
“代理化” (Agentic AI) 的实战标杆:Computer Use
2026 年的报告显示,Claude 在“复杂端到端任务执行”上的成功率(SWE-bench 等指标)持续领先,这让它在自动化办公领域几乎没有对手
极致的“企业级信誉”与“专注力”
当 OpenAI 忙着做视频生成(Sora)、搜索(SearchGPT)和社交时,Anthropic 始终死磕“代码、逻辑、长文本”这三个核心生产力维度。
截至 2026 年初,Anthropic 约 85% 的收入来自 B 端企业(而 OpenAI 超过 60% 仍依赖 C 端订阅)。这种“深挖洞、广积粮”的垂直化策略,让它在企业数字化转型这个最赚钱的碎片化市场里扎根最深
Anthropic 护城河
| 维度 | 复制难度 | 为什么难以复制? | 通俗理解 |
|---|---|---|---|
| 技术层 (Constitutional AI) | 中等 | 虽然原理公开,但微调出一套既“守规矩”又不“死板”的权重,需要极高的工程积淀 | 别人能学理论,但要让模型既安全又灵活,需要大量经验和工程能力 |
| 品牌层 (Trust Asset) | 极高 | Anthropic 创始人从 OpenAI 离职带着安全理念,这种“出身论”在金融和政府客户中形成强信誉背书,广告换不来 | 创始人的声誉和理念形成了难以复制的信任资产,客户愿意相信他们的模型安全 |
| 生态层 (Multi-Cloud) | 高 | Anthropic 可在 AWS 和 Google Cloud 之间部署,而 OpenAI 深度绑定微软,非 Azure 客户可能担心供应商锁定 | 灵活的云生态让企业客户更容易接入,不受单一厂商绑定限制 |
发展方向对比
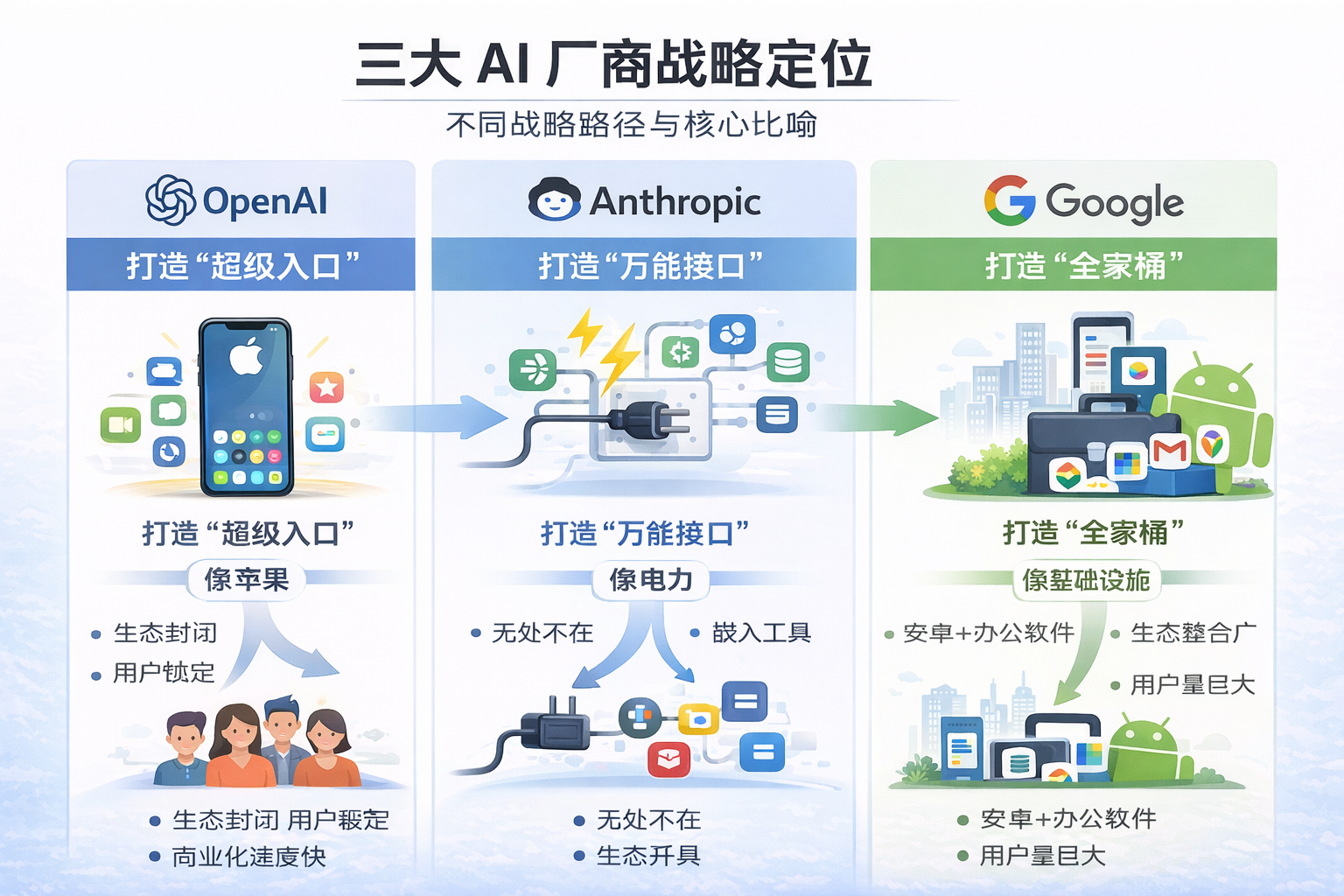
其他厂商(如 OpenAI、Google)在 B 端受挫或进展较慢,主要是因为 Anthropic 解决了企业最头疼的三个问题:
- 法律与合规: Anthropic 始终坚持“激进透明”的安全对齐,这让它成为了受监管行业(金融、医疗、国防)的首选。
- 多云/多芯战略: 相比于死磕微软 Azure 的 OpenAI,Claude 深度整合在亚马逊 AWS 和 Google Cloud 中,让大企业能灵活选择,不被单一云商“锁死”。
- MCP 协议的标准化: 通过主导发布 Model Context Protocol (MCP),Anthropic 成功让企业内部的旧数据库(ERP, CRM)变成了 AI 随时可调用的工具。
大模型的可解释性
为什么大模型不可解释?
大模型的行为是由数千亿个参数共同作用的结果。
- 神经元叠加(Superposition): 就像一个人的大脑里,同一个神经元可能既负责识别“猫”,又负责处理“微积分”和“幽默感”。这种特征的高度纠缠,让外界很难通过观察某个神经元的激活就断定模型在干什么。
- 涌现的不可控性: 当模型规模大到一定程度,它会自发学会一些人类从未教过的技巧(比如下棋或写漏洞代码)。我们知道它学会了,但不知道它是通过哪条逻辑路径学会的。
稀疏自编码器(Sparse Autoencoders, SAEs)
SAE 的作用就像是一台“光谱分析仪”。它能把那些纠缠在一起的神经元激活,还原为人类能理解的“特征(Features)”
尽管有 SAE 这种工具,顶级科学家(如 Neel Nanda)在 2026 年的共识依然是:没有任何一种工具能完全解释大模型
“不可解释性”是大模型与生俱来的“基因缺陷”
如果 AI 无法解释其动作背后的因果逻辑,它就永远无法获得物理世界需要的“最高信用等级”。这也解释了为什么 2026 年的智谱、OpenAI 等公司虽然模型越来越强,但在涉及工业生产、自动驾驶等领域时,依然显得步履维艰。
特斯拉的自动驾驶模型可解释性
特斯拉正在联合行业推动一种新的监管逻辑:“功能安全”优于“逻辑透明”
传统的工业机器人需要工程师写死每一行坐标代码。而 2026 年领先的工厂(如 Tesla Gigafactory 或小米黑灯工厂)正在引入 VLA(Vision-Language-Action,视觉-语言-动作) 模型。
2026 企业使用AI的方式
Anthropic 的成功证明了:企业并不真的需要模型“住在”自家的机房里,他们需要的是“数据不泄露”和“结果可审计”的法律与技术双重保障。
| 部署模式 | 适用对象 | 典型特征 | 通俗理解 |
|---|---|---|---|
| Claude for Teams | 中小企业、创业公司 | 简单易用,按月订阅,SaaS 模式 | 就像用 SaaS 办公软件一样,开箱即用,免运维 |
| Amazon Bedrock 托管 | 绝大多数 500 强企业 | IAM 权限集成,利用现有云配额,数据不跨云 | 企业级云服务,安全、稳定,数据严格在单云内管理 |
| MCP Hybrid(混合模式) | 金融、医疗、制造业 | 数据本地保留,AI 仅作为“外挂大脑”访问 | 企业数据不出本地服务器,AI只提供计算和分析能力 |
| Sovereign Cloud(主权云) | 政府、国防、大型国企 | 物理隔离专属算力区域,符合 GDPR 2.0 | 高度安全隔离环境,适合极端敏感或合规要求高的场景 |
虚拟私有云(VPC)
公共云(AWS、阿里云、Google Cloud)上拥有一个逻辑隔离的、完全属于自己的网络空间,像自己在云里开了一片“独立小区”,只有你能管理
核心架构:模型“入驻”而非“访问”
- 环境托管: AWS(通过 Bedrock 服务)或 Google Cloud(通过 Vertex AI)会在你的虚拟私有云(VPC)边界内,为你划出一个专属的“模型推理区”。
- 计算资源隔离: 运行模型(如 Claude 3.5/4)的 GPU 算力是由云厂商提供的,但这些算力在逻辑上只为你一家公司服务。
- 流量不出网: 你的业务数据、员工提问、私有文档都通过 AWS PrivateLink 或 GCP Service Directory 传输。这意味着流量始终在云厂商的内部骨干网流动,不经过公共互联网。
数据处理的“三不”原则
- 不参与训练: 你在 VPC 环境内输入的所有数据,都被锁死在你的租户(Tenant)里。云厂商和 Anthropic 都在法律和技术层面保证,绝不会用这些数据来迭代他们的下一个基础模型。
- 不保留日志: 企业可以配置“零保留(Zero Retention)”策略。模型处理完请求后,内存会立即清空,云端不存储任何对话历史。
- 不跨域访问: 即使是 Anthropic 的工程师,如果没有你的授权,也无法看到你的 VPC 内部发生了什么。
对比物理隔离
| 维度 | VPC 托管模式 (AWS/GCP) | 纯本地机房部署 (On-Prem) | 通俗理解 |
|---|---|---|---|
| 部署速度 | 分钟级,直接调用预置好的模型 | 月级,需要采购 H100/H200 芯片,搭建算力集群 | 云上开箱即用,本地要先买硬件、安装环境 |
| 维护成本 | 极低,云厂商负责模型更新和负载均衡 | 极高,需要专门 AI 运维团队 | 云厂商帮你打理,本地得自己请运维 |
| 性能 | 极高,可动态调用数千张 GPU | 受限于本地物理服务器数量 | 云上可按需扩容,本地算力有限 |
| 数据安全性 | 等同金融级云安全 | 理论最高,但受物理资产管理影响 | 云上安全标准高,本地如果管理不好也有风险 |
正如硅谷的一句名言:“Trust, but verify(信任,但要验证)”。对于大多数 B 端企业来说,云端 VPC 提供的“受控信任”比完全封闭但落后的自建机房更具商业价值
美国厂商对比
| 厂商 | 核心 B 端战略 | 代表产品/协议 | 核心信任背书 | 典型适用行业 | 通俗理解 |
|---|---|---|---|---|---|
| Anthropic | 极致合规与安全,将 AI 定义为可审计、守法律的“专业雇员” | MCP 协议、Claude Enterprise | 创始人的安全基因、PwC 审计认证 | 金融、医疗、审计、法律 | 走“安全第一”路线,让企业放心用 AI,合规和可审计是核心卖点 |
| OpenAI | 生态整合与行动力,利用微软全家桶,将 AI 变成能操作系统的 Agent | OpenAI Frontier、GPT-5 Pro | 微软生态、顶尖咨询公司代理 | 互联网、咨询、快消、泛创意 | 走“超级入口+Agent”路线,让 AI 能直接在企业生态中行动 |
| 云原生一体化,利用 Vertex AI 基建优势,主打“数据不动,模型动” | GDC (分布式云)、Gemini 3.5 | Google Cloud 金融级安全隔离 | 零售、教育、政务、跨国企业 | 数据留在本地,AI 上云跑,企业不用搬数据,安全合规 | |
| xAI | 垂直集成与重工业 AI,利用物理世界数据和极致算力 | Enterprise Vault、Grok 工业版 | SpaceX/Tesla 工业实战经验 | 能源、航天、高端制造、物流 | 高端工业场景,AI 结合物理环境和算力,解决重工业难题 |
| Meta (Llama) | 主权 AI 与开源底座,赋予企业完全“物理拥有权”,不依赖云厂商 | Llama 4 (Open-weights) | 社区透明度、自研硬件集成 | 国防、本国主权 AI 项目、科研 | 企业自己掌握模型和权重,不依赖第三方云,实现完全可控 |
| Mistral | 区域主权与高能效,欧洲企业的“合规避风港”,避免地缘政治风险 | Mistral Compute | 欧盟合规 (GDPR 2.0) | 欧洲政府机构、欧洲金融机构 | 专注欧洲市场,合规安全高,降低地缘政治风险 |
中国厂商
收入结构的本质不同:项目制 vs 订阅制
Anthropic 的 B 端收入之所以被推崇,是因为其 ARR(年度经常性收入) 极高,主要靠标准化云端 API 订阅。而中国市场呈现以下反差:
- “项目制”泥潭: 中国的大客户(银行、能源、政府)极其强势,倾向于“私有化部署+定制开发”。这导致像 智谱 AI(2026 年 1 月刚在港股上市)虽然 B 端收入占比高达 85%,但很大一部分是靠“重人力”的交付换来的,而非高毛利的纯 Token 订阅。
- 客单价瓶颈: 智谱 2025 年上半年的营收约为 6.85 亿元人民币,虽然已是国内初创公司翘楚,但与 Anthropic 2025 年 140 亿美元 的营收规模相比,仍有数十倍的量级差距。
“价格屠夫” DeepSeek 的降维打击
API 价格战: DeepSeek 走的是极致的“性价比”路线,其 Token 价格仅为传统大厂的十分之一甚至更低。这导致中国 B 端市场的 Token 单价被迅速“自来水化”。
影响: 当大家都觉得 AI 应该像自来水一样便宜时,国内很难再长出一个像 Anthropic 那样靠“智力溢价”卖出高价 Token 的公司。
巨头的强力“内卷”挤压
在硅谷,OpenAI 与云厂商(微软)是合作关系;而在中国,华为、阿里、百度 既是模型厂商,又是云厂商。
- 华为盘古的统治力: 在重工业、政务和能源领域,华为凭借其“昇腾算力+盘古大模型+本地化堆栈”的闭环,几乎垄断了最高价值的 B 端合同。
- 初创公司的生存空间: 对于初创公司来说,如果不接入大厂的生态(如进入阿里通义或百度文心的智能体市场),很难独立拿到超大型企业的订单。
风险一:陷入“利润沙漠”的内卷陷阱
风险二:智力的“低位平庸”