机器学习中的关键组件
- 数据
- 模型
- 目标函数
- 优化算法
数据
数据基础单元
| 概念 | 含义 | 例子 | 类型 |
|---|---|---|---|
| 样本 (Sample) | 数据集中的最小观测单元 | 一张手写数字图片 | 观测单位 |
| 数据点 (Data Point) | 具体的数据记录,又称实例 (Instance) | 房价表格中的一行 | 存储单位 |
| 特征 (Feature) | 描述样本属性的输入变量 (Covariate) | 面积、房间数、像素值 | 输入变量 |
| 标签 (Label) | 样本要预测的输出目标 (Target) | 房价、数字类别 | 输出目标 |
| 特征向量 (Feature Vector) | 将特征组织成数学向量形式 | [面积, 房间数, 地段] |
输入形式 |
集合划分与分布
| 概念 | 含义 | 例子 | 作用 |
|---|---|---|---|
| 数据集 (Dataset) | 样本的集合 | MNIST 手写数字集 | 容器 |
| 训练集 (Training Set) | 用于模型学习规律的子集 | MNIST 60,000 张图片 | 模型学习 |
| 验证集 (Validation Set) | 用于调参和选择模型的子集 | MNIST 5,000 张图片 | 参数调优 |
| 测试集 (Test Set) | 用于最终评估模型泛化能力的子集 | MNIST 10,000 张图片 | 最终考核 |
| 独立同分布 (i.i.d.) | 样本相互独立且来自同一分布 | 随机抽取的房子假设 | 统计前提 |
| 数据分布 (Distribution) | 样本特征和标签的统计规律 | 房价分布或类别频率 | 数据特性 |
机器学习分类
- 监督学习
- 无监督学习
- 强化学习
| 学习类型 | 数据要求 | 目标明确性 | 算法复杂度 | 调试难度 | 总体难度 |
|---|---|---|---|---|---|
| 监督学习 | 高,需要标注好的数据 | 明确,有标签 | 中等,常用回归/分类算法 | 低,容易验证结果 | ⭐⭐ |
| 无监督学习 | 中等,不需要标签 | 间接,需要定义指标(如聚类距离) | 中等偏高,需选择合适模型 | 中等,结果解释困难 | ⭐⭐⭐ |
| 强化学习 | 低,需要环境可交互 | 目标是累积奖励,不直接明确 | 高,涉及策略优化、价值函数、探索/利用平衡 | 高,训练不稳定,易收敛慢 | ⭐⭐⭐⭐ |
监督学习
监督学习是一类机器学习方法,它依赖 带标签的数据 来训练模型,使模型学会从输入特征预测输出标签。
步骤
- 收集训练数据:包含输入特征 X 和对应标签 Y
- 数据预处理:处理缺失值、噪声、归一化、特征选择等
- 选择模型:线性回归、逻辑回归、决策树、神经网络等
- 训练模型:用训练集更新模型参数
- 验证模型:用验证集调整超参数
- 评估模型:用测试集评估预测精度
- 部署预测:在新数据上预测输出标签
监督学习分类
| 任务类型 | 输出形态 | 是否结构化 | 难度 |
|---|---|---|---|
| 回归 | 数值 | 否 | ⭐ |
| 分类 | 离散标签 | 否 | ⭐ |
| 排序 | 分数 + 顺序 | 半结构 | ⭐⭐ |
| 推荐 | 用户-物品矩阵 | 半结构 | ⭐⭐⭐ |
| 序列学习 | 序列 | 结构化 | ⭐⭐⭐⭐ |
无监督学习
数据中不含有目标的学习为无监督学习
- 聚类问题
- 主成分分析问题
- 因果关系和概率图模型问题
- 生成对抗性网络
总结
| 类型 | 核心目标 | 代表方法 | 典型应用 | 难度 |
|---|---|---|---|---|
| 聚类 | 找分组 | K-means | 客户分群 | ⭐ |
| 降维 | 找主方向 | PCA | 数据压缩 | ⭐ |
| 概率模型 | 找变量关系 | 贝叶斯网络 | 风险分析 | ⭐⭐⭐ |
| 因果学习 | 找因果方向 | 因果图模型 | 政策评估 | ⭐⭐⭐⭐ |
| 生成模型 | 学数据分布 | GAN / VAE | 图像生成 | ⭐⭐⭐ |
| 自监督 | 自造标签学习 | 对比学习 / GPT | 大模型预训练 | ⭐⭐⭐⭐ |
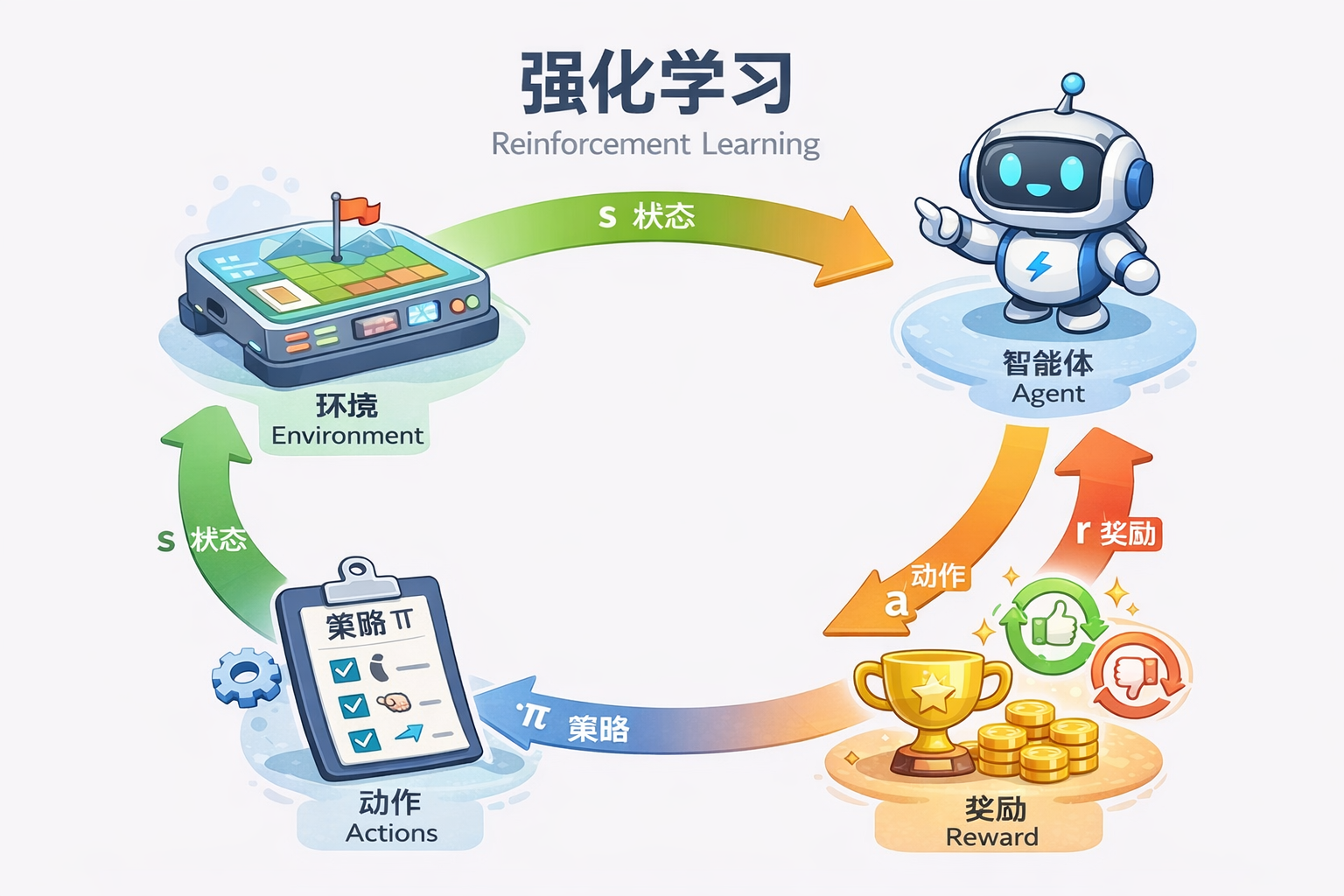
强化学习
强化学习(Reinforcement Learning, RL)是一种 机器学习范式,它与监督学习和无监督学习不同,核心在于 智能体(Agent)通过与环境交互来学习最优策略。简单来说,就是 “做对事情才能得到奖励,做错事情会受惩罚”。
| 名称 | 解释 |
|---|---|
| 智能体(Agent) | 做决策的主体,例如机器人、算法或程序 |
| 环境(Environment) | 智能体操作的世界,会根据智能体动作反馈结果 |
| 状态(State, s) | 当前环境的情况描述 |
| 动作(Action, a) | 智能体可以采取的行为 |
| 奖励(Reward, r) | 智能体执行动作后的反馈,正值鼓励、负值惩罚 |
| 策略(Policy, π) | 智能体选择动作的规则或函数 |
| 价值函数(Value Function, V) | 某状态或状态-动作对的长期回报预期 |
| 回报(Return, G) | 从当前状态开始,未来累积奖励总和 |
强化学习VS监督学习
| 维度 | 强化学习 | 监督学习 |
|---|---|---|
| 数据来源 | 智能体与环境交互产生 | 事先标注好的训练数据 |
| 学习目标 | 最大化长期回报 | 最小化预测误差 |
| 特点 | 需要探索和试错 | 只需拟合已有数据 |
| 示例 | AlphaGo、机器人走路、Tesla FSD 自动驾驶 | 图像分类、语音识别 |
深度学习
以前的情况:领域割裂
| 应用领域 | 核心方法 | 特点 |
|---|---|---|
| 计算机视觉 (CV) | 图像处理、特征工程、SIFT/HOG | 每个任务都需要手工设计特征 |
| 语音识别 (ASR) | MFCC + HMM | 对语音信号处理经验依赖大 |
| 自然语言处理 (NLP) | 规则、n-gram、词袋模型 | 难以捕捉上下文语义 |
| 医学信息学 | 统计模型 + 手工特征 | 需要专业知识标注数据 |
每个领域都有自己的工具链、特征工程方法、算法库,几乎互不通用
深度学习的统一性
深度学习(尤其是神经网络、卷积网络、循环网络、Transformers)出现后:
| 特征 | 说明 |
|---|---|
| 端到端学习 | 输入 → 网络 → 输出,中间特征由网络自动学习 |
| 可迁移性 | 同一个网络结构(如 CNN 或 Transformer)可以处理图像、文本、音频等 |
| 表示学习 | 网络自动学习低维、高层次特征,减少手工特征依赖 |
| 多任务适配 | 一个模型可以训练多任务,如图像分类 + 对象检测 + 分割 |
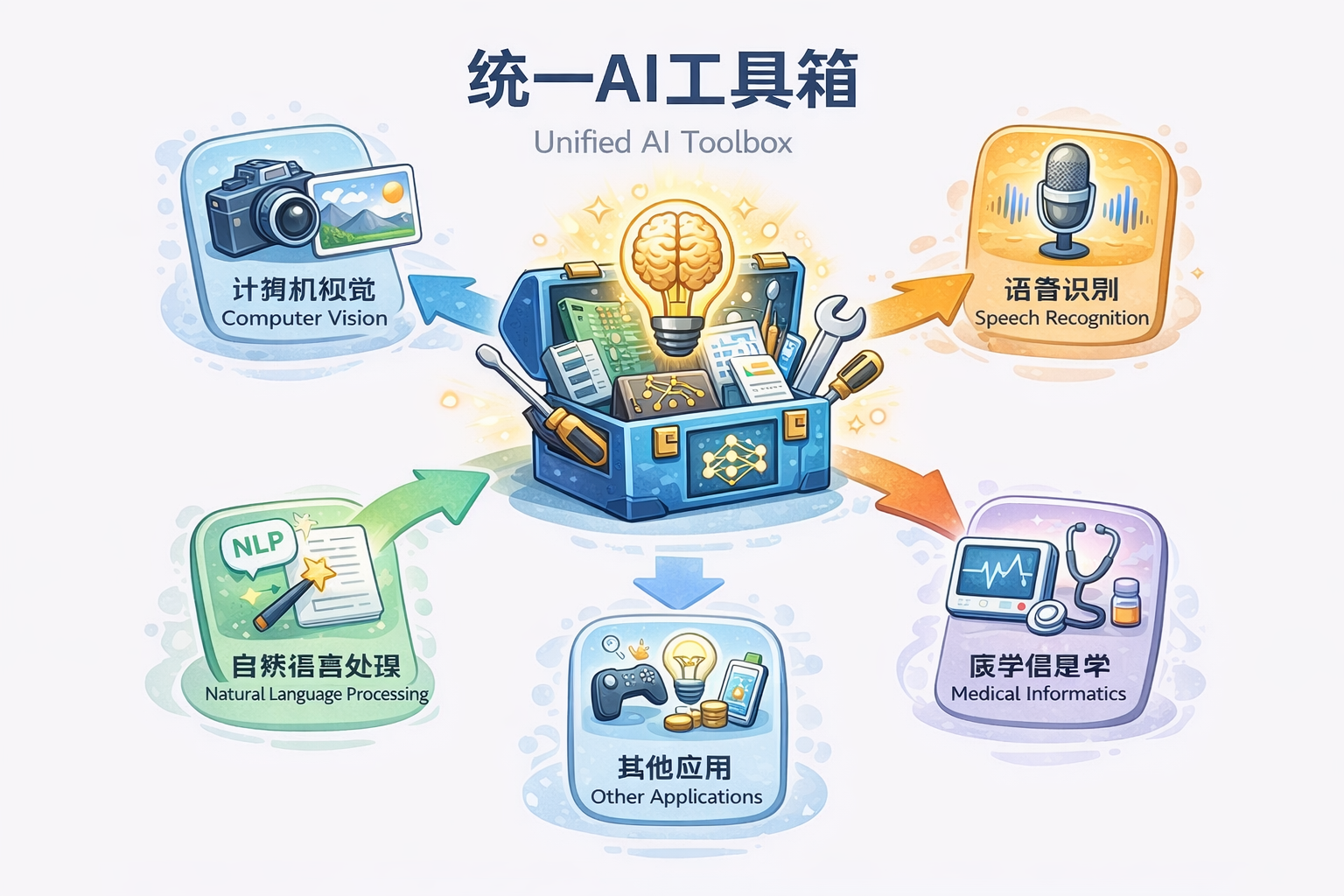
技术底层的统一:神经网络成为“通用语言”
计算方式的统一: 无论是处理图像、文字还是声音,底层全部转化成矩阵运算和张量(Tensor)的流动。优化目标的统一: 所有问题都转化成了“通过反向传播(Backpropagation)和梯度下降来最小化损失函数”。
特征工程的消失:从“人造特征”到“自动提取”
以前: 计算机视觉专家要手动设计“LBP特征”,语音专家要提取“梅尔频率倒谱系数”,医学专家要定义“肿瘤边缘曲率”。这种“手工特征”极度依赖专家经验,且跨领域完全不通用。现在: 深度学习实现了端到端(End-to-End)学习。你只需要把原始像素、原始音频采样点或原始文本丢进模型,神经网络会自动通过多层结构学习出最适合该任务的特征。
模型架构的跨界流动(以 Transformer 为例)
跨界范例: 最初为 NLP 设计的 Transformer 架构,现在被广泛用于计算机视觉(ViT)、语音处理以及蛋白质结构预测(医学信息学)。意义: 这种通用性意味着:一个在语音领域取得的数学突破,可能在几个月内就会大幅提升癌症筛查的准确率。
“多模态”时代的开启
以前: 给图像写描述需要先用 CV 识别物体,再用 NLP 生成句子,两套系统互不理解。现在: AI 可以直接在同一个高维空间里理解“猫”的图片、“Cat”这个单词以及猫叫的声音。这就是为什么现在的 GPT-4o 或类似的大模型可以同时看图、听音、说话。
通用 AGI VS 垂直 AGI
通用 AGI (General AGI) 追求的是像人类一样在所有领域都能达到平庸或良好的水平;而 垂直 AGI (Vertical AGI) 追求的是在特定领域(如法律、医学、工业架构)达到超越顶尖专家的水平。
| 阶段 | 关键词 | 核心逻辑 | 法律行业比喻 |
|---|---|---|---|
| 深度学习统一性 | 地基 | 所有 AI 问题都可以用同一种神经网络解决 | 所有人都在用法学院同样的教科书,学习方法统一 |
| 垂直 AGI 转向 | 建房 | 针对特定行业进行高精度深度定制和私有化部署 | 针对房产纠纷或知识产权纠纷的资深专法律师,提供专业化解决方案 |
边缘侧的效率问题
深度学习(DL): 即使是 2026 年优化后的轻量化模型,在推理时依然需要进行数以亿计的浮点运算。在边缘设备上,这会导致发热、降频和电池骤减。传统监督学习(SL): 很多传统算法的推理过程只是简单的线性代数运算或分支判断。
“特征工程”的主动权回归
深度学习的统一性:代价是“黑盒化”,它自动提取特征,但需要海量数据来抵消特征中的噪声。边缘 AI 的痛点:在边缘端,数据通常是稀疏的(Small Data)。传统监督学习的优势:它依赖人工特征工程。
“冷启动”与“即时反馈”
深度学习:需要巨大的标注数据集来“喂饱”多层神经网络。传统监督学习:在边缘侧,如果你只需要处理特定的小任务(例如:识别某种特定的方言证言,或者特定格式的报销单),传统的监督学习只需要几十个高质量样本就能达到 90% 的准确率。
特斯拉端到端自动驾驶算法的发展历史
| 时间 | 硬件/版本 | 算法特点 | 是否端到端 | 主要功能 |
|---|---|---|---|---|
| 2014–2016 | Autopilot 1.0 | Mobileye + 规则 | ❌ | 高速公路车道保持、巡航 |
| 2016–2019 | Autopilot 2.0–2.5 | 自研 CNN 感知 + 规则规划 | ❌ | 高速公路、周围车辆识别 |
| 2019–2021 | FSD Beta early | CNN + LSTM 视频处理 | ⚠️ 部分 | 车道保持、低层控制 |
| 2021–2023 | FSD Beta mid | 多模态 CNN + Transformer | ⚠️ 加强 | 低层控制 + 规划辅助 |
| 2023–2026 | FSD v11 | 大模型多模态端到端 | ✅ | 城市复杂场景自动驾驶 |
特斯拉机器人的算法演进历史
| 时间 | 阶段 | 核心算法 | 感知 | 控制 | 特点 |
|---|---|---|---|---|---|
| 2021 | Demo原型 | 低阶控制 + PID | 简单摄像头 | 预定义动作 | 展示步行、抬手,演示性质 |
| 2022 | 感知与控制融合 | CNN + Transformer + MPC | 摄像头 + IMU | PID + MPC | 动作序列生成,动态抓取,部分端到端 |
| 2023 | 多模态端到端 | Transformer + 时序网络 | 摄像头 + IMU + 力觉 | 高层动作直接预测 | 室内搬运,端到端控制,降低手工控制设计 |
| 2024–2026 | 强化学习+仿真训练 | 大模型端到端 + RL | 多模态传感器融合 | 端到端 + 强化学习优化 | 高度自适应,多任务搬运、装配、协作 |
特斯拉护城河
Dojo 算力集群: 许多公司还在租用云算力,而特斯拉拥有自主设计的 Dojo 超算集群。这让它训练端到端模型的成本比用 Nvidia 芯片的公司低 30%-40%。垂直一体化: 机器人的电机、减速器、执行器全是特斯拉自研,这就像苹果自研芯片一样,能把性能和功耗压榨到极致。Sim-to-Real 的对齐度: 特斯拉的仿真系统已经能让虚拟环境下的训练结果以 95% 以上的成功率直接迁移到真实物理世界。
小企业自动配送小车的研发路径建议
硬件底座:NVIDIA Jetson + ROS 2 Humble/Jazzy
不要尝试自研底层,直接使用 NVIDIA Isaac ROS 提供的加速包。2026 年的 Isaac ROS 4.x 版本已经内置了大量的端到端推理插件(NITROS),能直接衔接 ROS 2 的通讯节点。
Isaac ROS 4.x 是 NVIDIA 推出的最新一代、针对 ROS 2 环境深度优化的加速计算库套件。
软件架构:VLA 模型 + 模仿学习(Imitation Learning)
不要重头训练:使用开源的机器人大模型(如 OpenVLA 或 Octo)作为基础模型(Foundation Model)。微调(Fine-tuning):只需采集约 500-1000 段小车在特定场景(如某产业园、校园)的示范数据进行 LoRA 微调。这比从零训练端到端模型节省 99% 的算力成本。
安全兜底:ROS 2 Nav2 叠加层
建议策略:让端到端模型输出“期望路径”,但必须经过一个经典的 Nav2 (Navigation Stack) 碰撞检测层。如果端到端模型指挥小车撞墙,传统的超声波/激光雷达规则层必须拥有最高否决权直接刹停。