AI 开发框架
| 框架 | 核心特点 | 开发语言 | 主要应用场景 | 生态 / 社区 |
|---|---|---|---|---|
| PyTorch | 动态图,调试友好;2.0+ 编译器优化 | Python, C++ | 科研、生成式 AI、LLM、CV/NLP | 全球最活跃,Hugging Face 支持 |
| TensorFlow | 静态/混合图;成熟工业部署链 (TFX) | Python, C++, JS | 工业化生产、移动端、Web AI | 社区庞大,Google 官方支持 |
| JAX | 函数式编程,Autograd + XLA 高性能 | Python (C++) | 大规模模型预训练、科研、强化学习 | Google 内部主力,科研圈扩展快 |
| PaddlePaddle | 国产自研;动静统一,官方产业模型丰富 | Python, C++ | 本土工业应用、安防、推荐、OCR | 百度主导,中文社区活跃 |
| MindSpore | 昇腾硬件优化;全场景统一架构 | Python, C++ | 国产 AI 芯片、AI for Science、政务/能源 | 华为支持,国内大模型训练关键支撑 |
| MxNet | 高性能,动静混合图 (Gluon);轻量化 | Python, R, Scala | 云端部署、大模型训练 | 亚马逊支持,社区活跃度下降 |
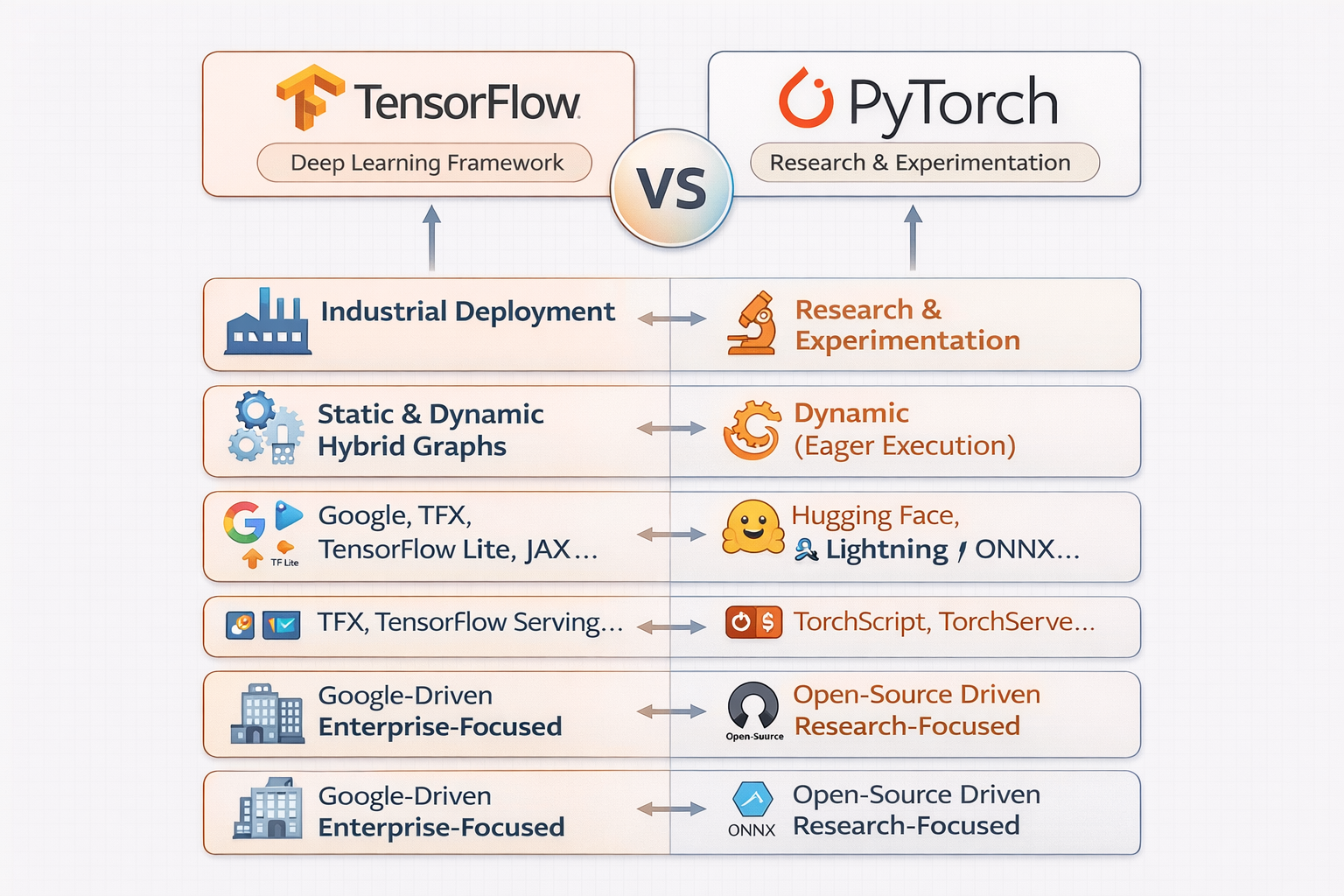
TensorFlow 和 PyTorch 是 主要竞争关系,尤其在科研 vs 工业落地领域有不同优势,但两者在生态上也能通过 ONNX、模型导出 等方式互通。
PyTorch 更强调科研灵活性和动态图调试,工业部署虽然可以(TorchScript + ONNX),但生态和工业化工具链不如 TensorFlow 完整。
TensorFlow
TensorFlow 主要由 Google 官方主导开发和维护,同时有全球开源社区协作
TensorFlow 适合工业场景的核心原因:
- 静态/混合图优化 → 高效、稳定推理
- 完整工业部署链 → TFX、Serving、Lite、JS
- 跨平台支持 → CPU/GPU/TPU/移动/边缘
- 企业级工具 → 版本管理、监控、分布式训练
- 社区和官方支持 → 稳定性和长期维护
安装
# 安装最新稳定版 TensorFlow CPU 版本
pip install tensorflow
查看版本
import tensorflow as tf
# 打印 TensorFlow 版本和可用 GPU 信息
print("TensorFlow 版本:", tf.__version__)
print("可用 GPU:", tf.config.list_physical_devices('GPU'))
运行结果
TensorFlow 版本: 2.20.0
可用 GPU: [PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR
I0000 00:00:1772164609.724609 308356 gpu_device.cc:2020] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 4643 MB memory: -> device: 0, name: NVIDIA GeForce RTX 3070, pci bus id: 0000:07:00.0, compute capability: 8.6
案例
import tensorflow as tf
x = tf.range(12) # 创建一个包含12个元素的一维张量
print(x) # 打印张量的内容
print(x.shape) # 打印张量的形状
print(tf.size(x)) # 打印张量的元素总数
X = tf.reshape(x, (3, 4)) # 将一维张量重新形状为3行4列的二维张量
print(X)
Pytorch
PyTorch 主要由 Facebook(现 Meta Platforms) 主导开发和维护,同时有活跃的开源社区参与
Pytorch 和 CUDA 关系
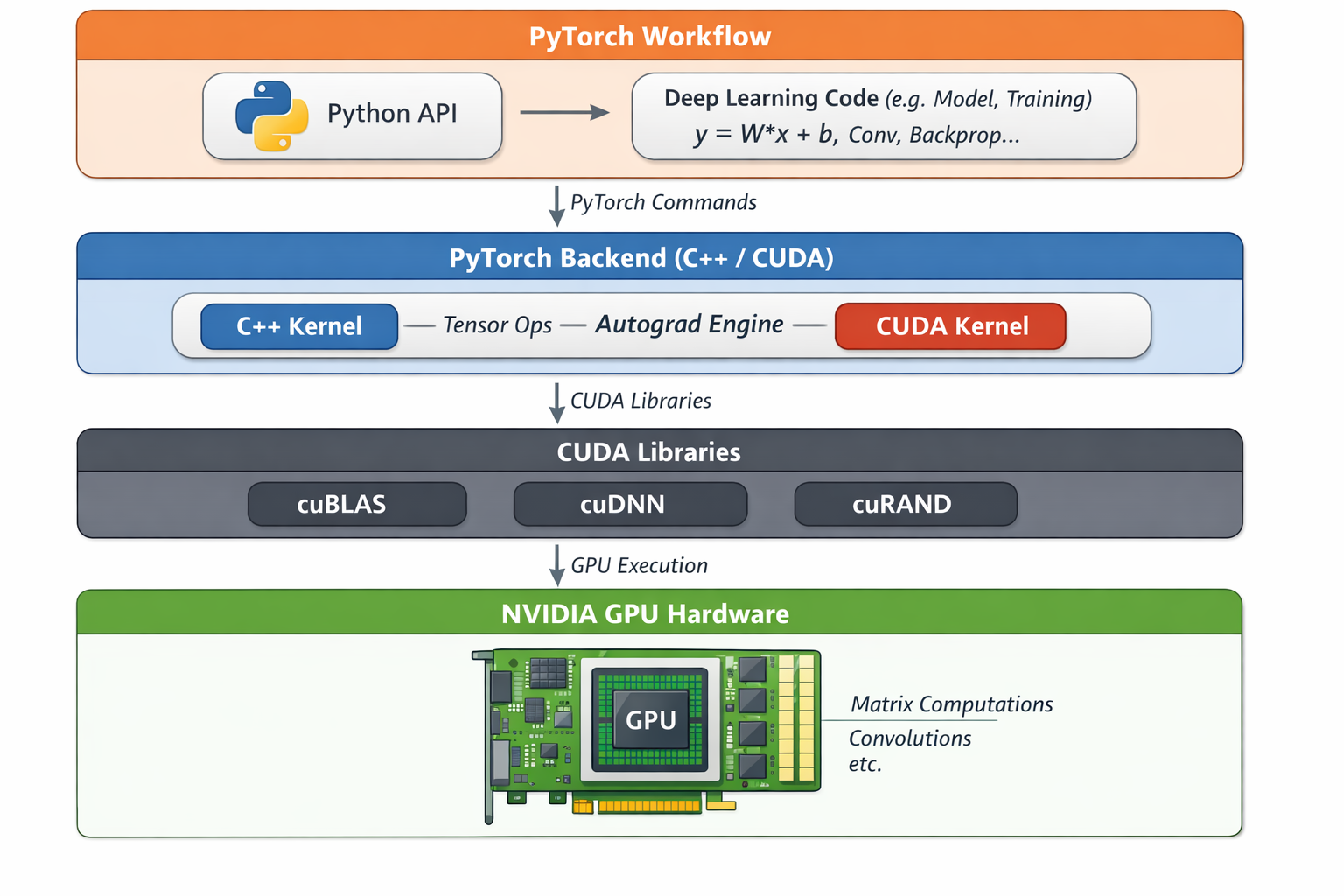
AMD的角色
| 框架 | 支持情况 | 说明 |
|---|---|---|
| PyTorch | 支持 AMD ROCm GPU | PyTorch 官方提供 ROCm 分支(pip install torch --rocm),可以在 AMD GPU 上运行训练和推理。 |
| TensorFlow | 支持有限 | TensorFlow 官方 GPU 版本主要针对 CUDA/NVIDIA,但社区有 AMD ROCm 分支(tensorflow-rocm),用于 AMD GPU。 |
入门
import torch
# 创建一个包含12个元素的一维张量
x = torch.arange(12)
# 打印张量的内容、形状和元素总数
print(x)
print(x.shape)
print(x.numel())
# 将一维张量重新形状为3行4列的二维张量
x = x.reshape(3, 4)
print(x)
x = torch.zeros((2, 3)) # 创建一个2行3列的全零张量
print(x)
x = torch.ones((2, 3)) # 创建一个2行3列的全一
print(x)
x = torch.randn((2, 3)) # 创建一个2行3列的随机张量,元素服从标准正态分布
print(x)
运算符
import torch
torch.set_default_device('cuda' if torch.cuda.is_available() else 'cpu') # 设置默认设备为GPU(如果可用)或CPU
x = torch.tensor([1.0, 2, 4, 8]) # 从Python列表创建一个张量
y = torch.tensor([2, 2, 2, 2]) # 从Python列表创建另一个张量
print(x + y) # 张量加法
print(x - y) # 张量减法
print(x * y) # 张量乘法(逐元素乘法)
print(x / y) # 张量除法(逐元素除法)
print(x ** y) # 张量幂运算(逐元素指数运算)
# e 是自然对数的底数,约等于2.71828
print(torch.exp(x)) # 计算张量的指数
X = torch.arange(12).reshape(3, 4) # 创建一个包含12个元素的一维张量,并重新形状为3行4列的二维张量
Y = torch.tensor([[1.0, 1.0, 1.0, 1.0], [2.0, 2.0, 2.0, 2.0], [3.0, 3.0, 3.0, 3.0]]) # 创建另一个3行4列的张量
print(torch.cat((X, Y), dim=0)) # 沿着第0维(行)连接张量
print(torch.cat((X, Y), dim=1)) # 沿着第1维(列)连接张量
print(X == Y) # 元素逐一比较,返回布尔张量
运算结果
tensor([ 3., 4., 6., 10.], device='cuda:0')
tensor([-1., 0., 2., 6.], device='cuda:0')
tensor([ 2., 4., 8., 16.], device='cuda:0')
tensor([0.5000, 1.0000, 2.0000, 4.0000], device='cuda:0')
tensor([ 1., 4., 16., 64.], device='cuda:0')
tensor([2.7183e+00, 7.3891e+00, 5.4598e+01, 2.9810e+03], device='cuda:0')
tensor([[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.],
[ 1., 1., 1., 1.],
[ 2., 2., 2., 2.],
[ 3., 3., 3., 3.]], device='cuda:0')
tensor([[ 0., 1., 2., 3., 1., 1., 1., 1.],
[ 4., 5., 6., 7., 2., 2., 2., 2.],
[ 8., 9., 10., 11., 3., 3., 3., 3.]], device='cuda:0')
tensor([[False, True, False, False],
[False, False, False, False],
[False, False, False, False]], device='cuda:0')
自然对数e
e ≈ 2.718,是连续增长的极限, 想象钱不停地复利增长,它就会变成 e 倍增长。

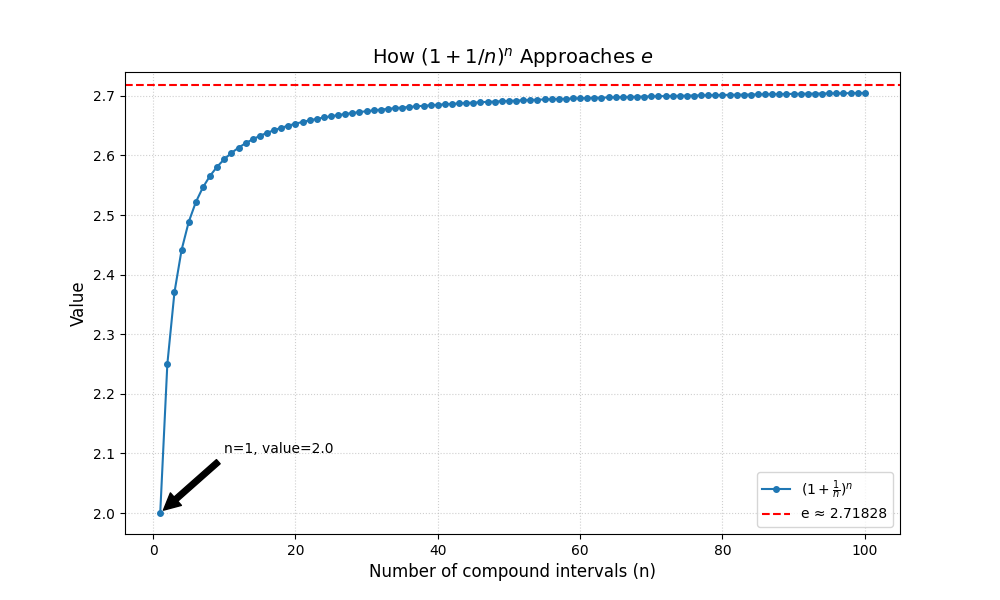
注意:任何数的 0 次幂都等于 1, 因为“乘 0 次”就是什么都没乘
增长有上限: 即使你把 100% 的利率拆分得再细(每微秒结算一次),你最终能得到的钱也不会超过初始资金的 2.71828 倍。$e$ 就是这个“自然增长率”的极限。平滑性: $e^x$ 是唯一一个在 $x=0$ 时斜率为 $1$ 且增长率始终等于当前值的指数函数。计算意义: 在 Python 中,np.exp(x) 比 2.718**x 更精确且运行更快,因为它是底层 CPU 针对指数运算专门优化过的。
无论 $x$ 取什么值,$e^x$ 的“高度”和“斜率”始终是同步的。
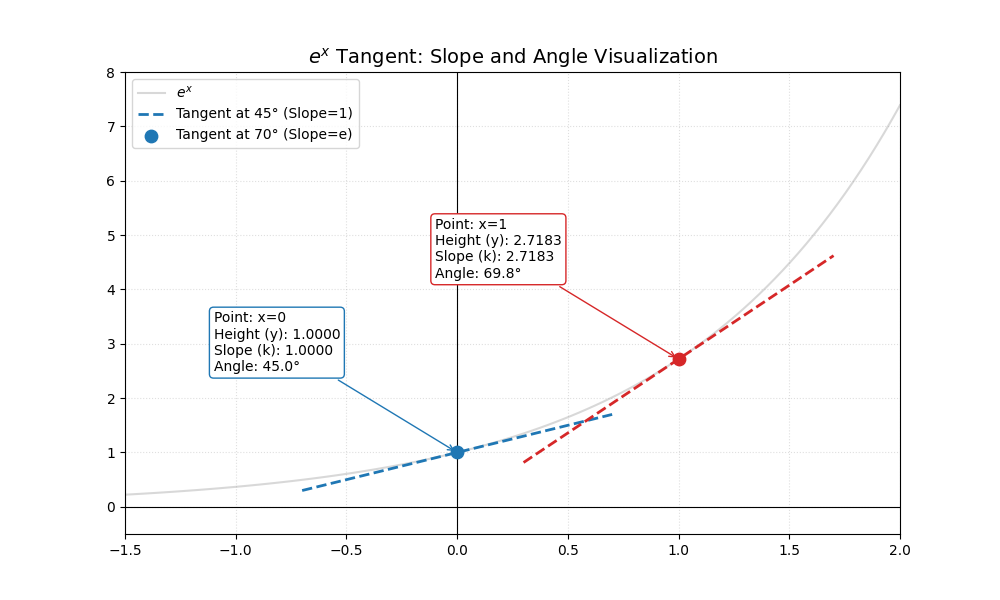
高度与斜率的统一:你会看到点 $(1, 2.7183)$ 的 $y$ 值,正好和红字标出的 Slope 一模一样。视觉验证:切线正好贴着红点而过。在数学上,这意味着在这一个瞬间,函数变化的“速度”和它当下的“规模”达成了完美的共振。
为什么人工智能中自然对数e很重要
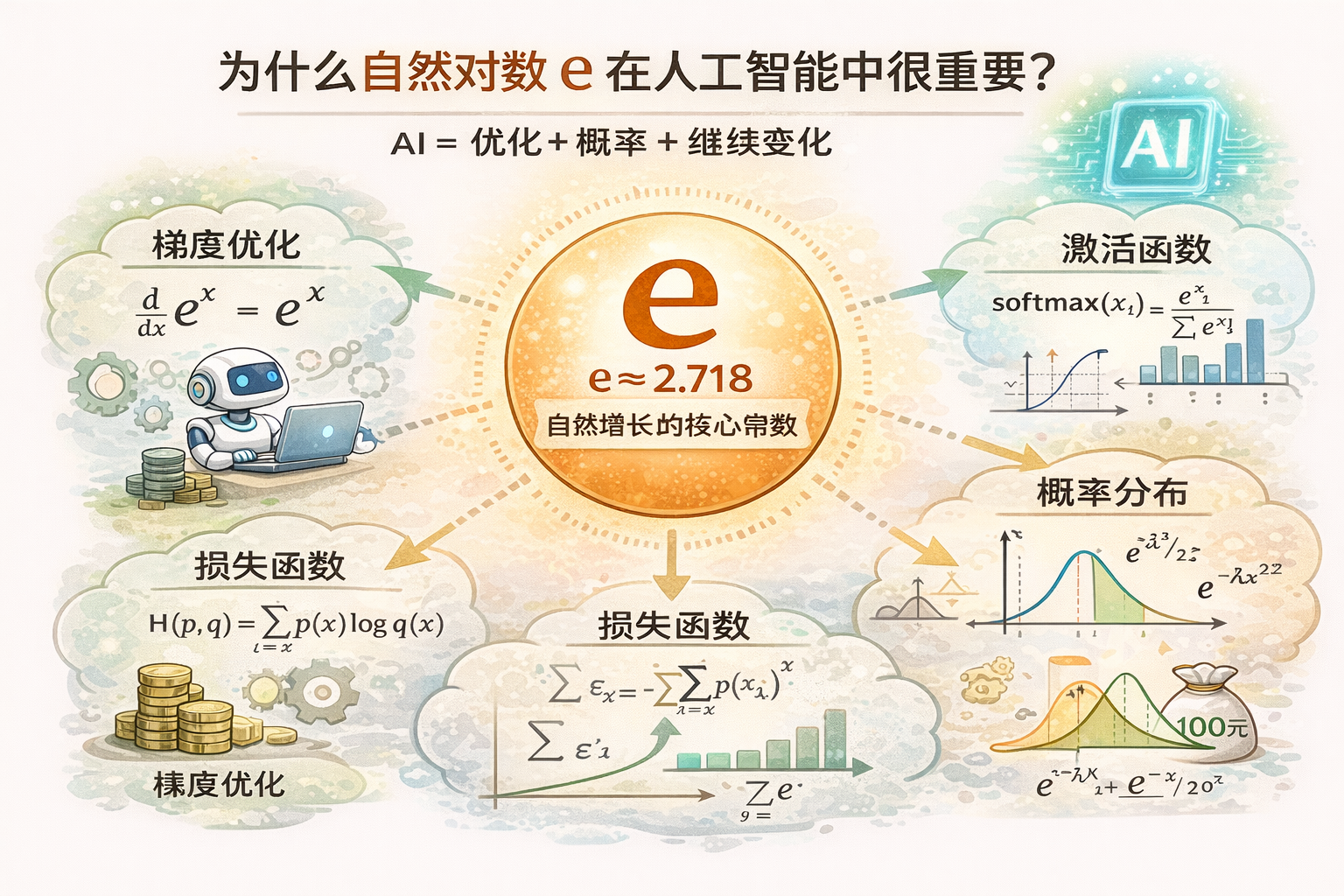
e 在 AI 中的角色就像是:
翻译官:把冷冰冰的数值变成概率。加速器:让复杂的求导运算变得轻而易举。裁判官:通过熵计算模型离真相还有多远。
指数和对数
| 运算 | 在问什么 |
|---|---|
| 指数 e^x | 连续增长到多少? |
| log(x) | 要增长多久才能到 x? |
广播机制
广播机制:当两个张量的形状不同时,PyTorch会自动扩展较小的张量以匹配较大的张量的形状,从而进行元素级别的操作。
规则如下:
对齐规则:如果两个张量的维度数不同,先在维度数较少的张量左侧补 1,直到两者的维度数相同。扩展规则:如果两个张量在某个维度上的大小不相同,只要其中一个的大小为 1,它就会被拉伸(复制)以匹配另一个的大小。冲突规则:如果两个张量在某个维度上的大小不相同,且两者的值都不为 1,则无法广播,抛出错误。
import torch
a = torch.arange(3).reshape(3, 1) # 创建一个包含0, 1, 2的一维张量,并重新形状为3行1列的二维张量
print(a)
b = torch.arange(2).reshape(1, 2) # 创建一个包含0, 1的一维张量,并重新形状为1行2列的二维张量
print(b)
print(a + b) # 广播机制:a的每一行都加上b的每一行,结果是一个3行2列的张量
# a = [[0], [1], [2]] # 形状为(3, 1) 维度数为2
# b = [[0, 1]] # 形状为(1, 2) 维度数为2
# a 扩展为 [[0, 0], [1, 1], [2, 2]] # 形状为(3, 2)
# b 扩展为 [[0, 1], [0, 1], [0, 1]] # 形状为(3, 2)
# a + b = [[0+0, 0+1], [1+0, 1+1], [2+0, 2+1]] = [[0, 1], [1, 2], [2, 3]] # 形状为(3, 2)
运行结果
tensor([[0],
[1],
[2]])
tensor([[0, 1]])
tensor([[0, 1],
[1, 2],
[2, 3]])
索引和切片
import torch
X = torch.arange(12).reshape(3, 4) # 创建一个包含12个元素的一维张量,并重新形状为3行4列的二维张量
print(X) # 打印张量的内容
print(X[0]) # 打印第一行
print(X[1]) # 打印第二行
print(X[2]) # 打印第三行
print(X[-1]) # 打印最后一行(与X[2]相同,因为-1表示最后一个元素)
print(X[:, 0]) # 打印第一列
print(X[:, 1]) # 打印第二列
print(X[:, 2]) # 打印第三列
print(X[:, 3]) # 打印第四列
print(X[1, 2]) # 打印第二行第三列的元素
访问规则
| 语法 | 含义 | 结果形状 |
|---|---|---|
X[i, j] |
获取第 i+1 行,第 j+1 列的单个元素 | 标量 (0D) |
X[i] |
获取第 i+1 行的整行 | 向量 (1D) |
X[:, j] |
获取第 j+1 列的整列 | 向量 (1D) |
X[-1] |
获取最后一行 | 向量 (1D) |
节省内存
X = torch.arange(12).reshape(3, 4) # 创建一个包含12个元素的一维张量,并重新形状为3行4列的二维张量
Y = torch.arange(12).reshape(3, 4)
before = id(Y) # 获取张量a的内存地址
Y = Y + X # 执行张量加法,结果赋值给Y
after = id(Y) # 获取张量a的内存地址
print(before == after) # 打印内存地址是否相同,应该是False,因为Y被重新赋值了一个新的张量
Y[:] = Y + X # 执行张量加法,并将结果直接存储在Y原来的内存地址中
after = id(Y) # 获取张量a的内存地址
print(before == after) # 打印内存地址是否相同,应该是True,因为Y的内容被修改了,但内存地址没有改变
Y += X # 执行张量加法,并将结果直接存储在Y原来的内存地址中(这是Y[:] = Y + X的简写)
after = id(Y) # 获取张量a的内存地址
print(before == after) # 打印内存地址是否相同,应该是True,因为Y的内容被修改了,但内存地址没有改变
转换为其他python对象
将深度学习框架定义的张量转换为NumPy张量(ndarray)很容易,反之也同样容易。 torch张量和numpy数组将共享它们的底层内存,就地操作更改一个张量也会同时更改另一个张量。
A= X.numpy() # 将PyTorch张量转换为NumPy数组
print(A) # 打印NumPy数组的内容
print(type(A)) # 打印A的类型,应该是numpy.ndarray
print(type(X)) # 打印X的类型,应该是torch.Tensor
B = torch.tensor(A) # 将NumPy数组转换回PyTorch张量
print(B) # 打印转换回来的PyTorch张量
print(type(B)) # 打印B的类型,应该是torch.Tensor
a = torch.tensor([3.0]) # 创建一个包含单个元素3.0的张量
print(a) # 打印张量a的内容
print(a.item()) # 使用item()方法获取张量a中的单个元素的
数据预处理
创建数据集
import os
# 创建一个名为"data"的目录,如果已经存在则不会抛出异常, 路径是相对于当前文件所在目录的上一级目录
os.makedirs(os.path.join(".", "data"), exist_ok=True)
# 定义数据文件的路径,位于上一级目录的"data"文件夹中,文件名为"house_tiny.csv"
data_file = os.path.join(".", "data", "house_tiny.csv")
with open(data_file, 'w') as f: # 以写入模式打开数据文件
f.write('NumRooms,Alley,Price\n') # 写入CSV文件的表头
f.write('NA,Pave,127500\n') # 写入第一行数据,表示房间数量未知,巷道为铺装,价格为127500
f.write('2,NA,106000\n') # 写入第二行数据,表示房间数量为2,巷道未知,价格为106000
f.write('4,NA,178100\n') # 写入第三行数据,表示房间数量为4,巷道未知,价格为178100
f.write('NA,NA,140000\n') # 写入第四行数据,表示房间数量未知,巷道未知,价格为140000
print(f"CSV 文件创建成功:{data_file}")
读取数据集
import pandas as pd
data = pd.read_csv(os.path.join(".", "data", "house_tiny.csv")) # 从CSV文件中读取数据,并存储在一个DataFrame对象中
print(data) # 打印DataFrame对象的内容
print(data.shape) # 打印DataFrame对象的形状,即行数和列数
print(data.dtypes) # 打印DataFrame对象中每列的数据类型
处理缺失值
inputs, outputs = data.iloc[:, 0:2], data.iloc[:, 2] # 将DataFrame对象的前两列作为输入,第三列作为输出
inputs = inputs.fillna(inputs.mean(numeric_only=True)) # 将数值列中的缺失值(NA)替换为每列的平均值
print(inputs) # 打印处理后的输入数据
print(outputs) # 打印输出数据
转换为张量格式
X = torch.tensor(inputs.to_numpy(dtype='float32')) # 将输入数据转换为PyTorch张量,数据类型为float32
y = torch.tensor(outputs.to_numpy(dtype='float32'))
print(X) # 打印输入张量
print(y) # 打印输出张量
运行结果
NumRooms Alley
0 3.0 Pave
1 2.0 NaN
2 4.0 NaN
3 3.0 NaN
NumRooms Alley_Pave Alley_nan
0 3.0 True False
1 2.0 False True
2 4.0 False True
3 3.0 False True
tensor([[3., 1., 0.],
[2., 0., 1.],
[4., 0., 1.],
[3., 0., 1.]])
tensor([127500., 106000., 178100., 140000.])
数据处理
原始数据 (图片/文本/表格)
│
▼ 清洗
│
▼ 格式转换
│
▼ 归一化 / 标准化
│
▼ 数据增强 (可选)
│
▼ 转换为张量
│
▼ 送入模型训练
| 阶段 | 数据类型 | 可否计算 |
|---|---|---|
| 原始数据 | 文件、字符串、混合类型 | ❌ 不可 |
| 清洗/归一化后 | 数值列表、数组 | ❌ 部分可,但效率低 |
| 张量化 | Tensor (PyTorch/TensorFlow/JAX) | ✅ 可直接并行计算,送入 GPU |
VS code 虚拟环境报错处理
报错信息
lxg@lxg:~/code/AI/demo_01$ /home/lxg/code/AI/demo_01/.venv/bin/python /home/lxg/code/AI/demo_01/pytorch/demo_5.py
Traceback (most recent call last):
File "/home/lxg/code/AI/demo_01/pytorch/demo_5.py", line 18, in <module>
import pandas as pd
ModuleNotFoundError: No mod
修改方案
# 1. 激活你的虚拟环境
source .venv/bin/activate
# 2. 在虚拟环境中安装 pandas
pip install pandas
# 3. 再次运行你的程序
python pytorch/demo_5.py
如何切换会全局环境
- 打开 VS Code
- 右下角点击当前显示的 Python 版本
- 弹出 Interpreter 列表
- 选择你系统全局的 Python,例如 /usr/bin/python3 或 Windows 的 C:\Python310\python.exe
如何理解GPU中的张量核心和CUDA核心
CUDA 核心(普通 GPU 核心)
- NVIDIA GPU 上的基础计算单元
- 功能类似 CPU 核心:能做加法、乘法、逻辑运算
- 优势在于数量巨大,几千个核心可以同时处理大量线程
- 适合并行计算,但每个核心处理单次操作速度和精度跟 CPU 差不多
张量核心(Tensor Core)
- 从 NVIDIA Volta 架构开始引入(V100、Turing、Ampere、Hopper)
- 专门为深度学习矩阵运算(特别是 FP16、BF16、INT8)优化
- 一个张量核心可以同时计算 4×4 或 16×16 矩阵乘法(大规模矩阵乘法 / 累加)
- 在 AI 训练中用来加速 矩阵乘法 + 累加 (GEMM),例如:
对比
| 核心类型 | 功能 | 优势 | 使用场景 |
|---|---|---|---|
| CPU 核心 | 通用计算 | 单核强,串行效率高 | 控制逻辑、数据预处理、小规模矩阵计算、I/O操作 |
| CUDA 核心 | 通用浮点/整数运算 | 高并行,适合大规模矩阵计算 | GPU 上的大规模并行运算,如卷积、图像处理、并行仿真 |
| Tensor Core | 专门矩阵乘法累加 | 超高吞吐量,专为深度学习优化 | AI训练/推理加速:卷积神经网络、Transformer、全连接层、矩阵乘加运算 |
Nvidia Tensor核心演进
| 架构 (Codename) | 代表型号 (Data Center) | CUDA 核心数 | Tensor Core 数量 | Tensor Core 世代 | 关键技术飞跃 (Key Leap) |
|---|---|---|---|---|---|
| Volta (2017) | V100 (SXM2) | 5,120 | 640 | 1st-gen | 诞生:专为矩阵乘法设计,加速 FP16 训练 |
| Turing (2018) | T4 (推理卡) | 2,560 | 320 | 2nd-gen | 推理加速:引入 INT8/INT4,开启 AI 推理新时代 |
| Ampere (2020) | A100 (SXM4) | 6,912 | 432 | 3rd-gen | TF32:让 FP32 代码无需修改即可享受 Tensor 加速 |
| Hopper (2022) | H100 (SXM5) | 16,896 | 528 | 4th-gen | Transformer Engine:支持 FP8,专为大模型优化 |
| Hopper (升级) | H200 | 16,896 | 528 | 4th-gen | 内存飞跃:核心数未变,HBM3e 带宽翻倍 |
| Blackwell (2024) | B200 | ~35,840 | ~1,120 | 5th-gen | FP4 & 双芯:引入 4位浮点,单卡推理性能爆炸 |
0
次点赞