标量
import torch
x = torch.tensor(3.0) # 创建一个标量张量,值为3.0
y = torch.tensor(2.0) # 创建一个标量张量,值为2.0
z = x * y # 执行张量的乘法
print(z) # 打印结果,应该输出6.0
向量
x = torch.arange(4.0) # 创建一个包含0到3的向量
y = torch.tensor([2.0, 3.0, 4.0, 5.0]) # 创建一个包含4个元素的向量
z = x * y # 执行张量的乘法,逐元素相乘
print(z) # 打印结果,应该输出[0.0, 3.0, 8.0, 15.0]
print(x.shape) # 打印x的形状,应该输出torch.Size([4])
print(len(x)) # 打印x的长度,应该输出4
向量的长度通常称为向量的维度(dimension)
概念区分:向量的维度和张量的维度
| 对象 | 维度是什么意思 |
|---|---|
| 向量 | 有多少个元素 |
| 张量 | 有多少个轴(rank) |
矩阵
A = torch.arange(20).reshape(5, 4) # 创建一个包含0到19的矩阵,并将其重塑为5行4列
print(A) # 打印矩阵A
print(A.shape) # 打印矩阵A的形状,应该输出torch.Size([5, 4])
print(A.T) # 打印矩阵A的转置
print(A[0][0]) # 打印矩阵A的第1行第1列的元素,应该输出0
运行结果
tensor([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15],
[16, 17, 18, 19]])
torch.Size([5, 4])
tensor([[ 0, 4, 8, 12, 16],
[ 1, 5, 9, 13, 17],
[ 2, 6, 10, 14, 18],
[ 3, 7, 11, 15, 19]])
张量
| 类型 | 阶(rank) | 例子 |
|---|---|---|
| 标量 | 0阶张量 | 5 |
| 向量 | 1阶张量 | [1,2,3] |
| 矩阵 | 2阶张量 | [[1,2],[3,4]] |
| 更高维数组 | 3阶及以上 | (batch, channel, h, w) |
Y = torch.arange(16).reshape(2, 2, 2, 2) # 创建一个包含0到15的四维张量,并将其重塑为2块2行2列2深度
print(Y) # 打印四维张量Y
print(Y.shape) # 打印四维张量Y的形状,应该输出torch.Size([2, 2, 2, 2])
运行结果
tensor([[[[ 0, 1],
[ 2, 3]],
[[ 4, 5],
[ 6, 7]]],
[[[ 8, 9],
[10, 11]],
[[12, 13],
[14, 15]]]])
我们无法画出 4 维以上的真实几何空间,但可以用投影或编码方式表达它
| 方法 | 我的直观感觉 | 适用场景 | 优点 | 局限 |
|---|---|---|---|---|
| 平行坐标图 | 像一把被拨乱的琴弦 | 看变量间关系、分类分布 | 能同时展示多维 | 维度太多会“糊” |
| 分面热力图 | 像照片墙 | CNN特征图、矩阵数据 | 空间结构直观 | 维度必须可切片 |
| 动态切片 | 像CT扫描 | 体数据、时序数据 | 建立空间直觉 | 需要交互或动画 |
分面热力图
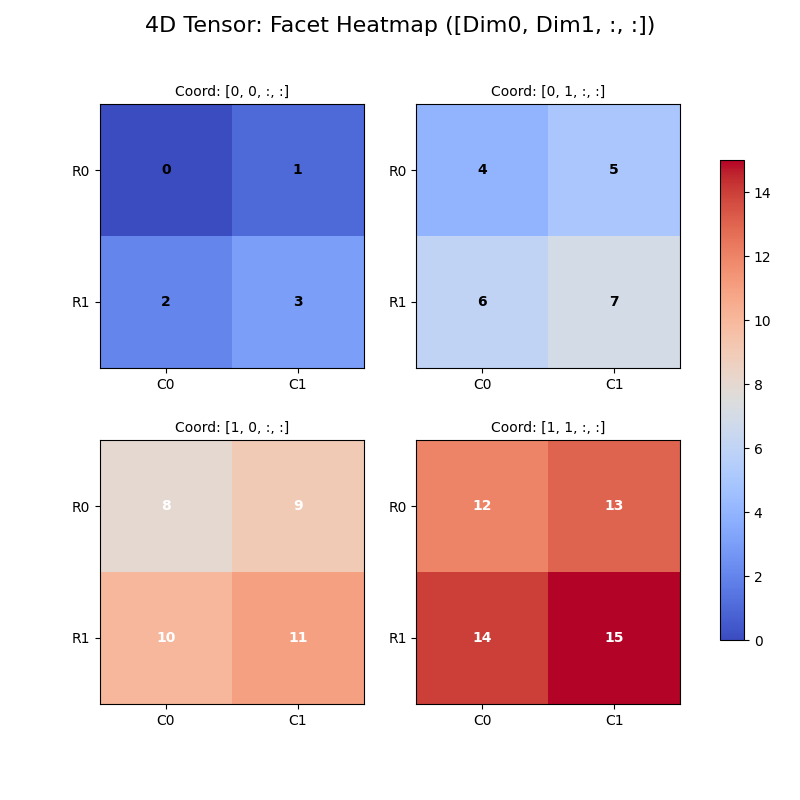
张量算法的基本性质
A = torch.arange(20).reshape(5, 4) # 创建一个包含0到19的矩阵,并将其重塑为5行4列
B = A.clone() # 创建矩阵A的一个副本,命名为B
print(A+B) # 打印矩阵A和B的元素逐个相加的结果
print(A*B) # 打印矩阵A和B的元素逐个相乘的结果
降维
A = torch.arange(20).reshape(5, 4) # 创建一个包含0到19的矩阵,并将其重塑为5行4列
print(A) # 打印矩阵A
A_sum_axis0 = A.sum(axis=0) # 沿着第0轴(行)求和,得到一个包含每列元素之和的向量
print(A_sum_axis0) # 打印沿着第0轴求和的结果
print(A_sum_axis0.shape) # 打印沿着第0轴求和结果的形状,应该输出torch.Size([4])
A_sum_axis1 = A.sum(axis=1) # 沿着第1轴(列)求和,得到一个包含每行元素之和的向量
print(A_sum_axis1) # 打印沿着第1轴求和的结果
print(A_sum_axis1.shape) # 打印沿着第1轴求和结果的形状,应该输出torch.Size([5])
print(A.mean()) # 打印矩阵A的元素平均值,应该输出9.5
print(A.sum()/A.numel()) # 打印矩阵A的元素平均值,应该输出9.5
运行结果
tensor([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15],
[16, 17, 18, 19]])
tensor([40, 45, 50, 55])
torch.Size([4])
tensor([ 6, 22, 38, 54, 70])
torch.Size([5])
点积
x = torch.arange(4, dtype=torch.float32) # 创建一个包含0到3的向量,数据类型为float32
print(x) # 打印向量x
y = torch.ones(4, dtype=torch.float32) # 创建一个包含4个元素的向量,所有元素的值为1,数据类型为float32
print(y) # 打印向量y
print(x.dot(y)) # 打印向量x和y的点积,应该输出6.0
运行结果
tensor([0., 1., 2., 3.])
tensor([1., 1., 1., 1.])
tensor(6.)
矩阵-向量积
x = torch.arange(4, dtype=torch.float32) # 创建一个包含0到3的向量,数据类型为float32
print(x) # 打印向量x
print(x.shape) # 打印向量x的形状,应该输出torch.Size([4])
A = torch.arange(20, dtype=torch.float32).reshape(5, 4) # 创建一个包含0到19的矩阵,并将其重塑为5行4列
print(A) # 打印矩阵A
print(A.shape) # 打印矩阵A的形状,应该输出torch.Size([5, 4])
# 5x4 的矩阵A和长度为4x1的向量x进行矩阵-向量乘法,得到一个长度为5x1的向量
print(torch.mv(A, x)) # 打印矩阵A和向量x的矩阵-向量乘积,应该输出一个包含5个元素的向量
运行结果
tensor([0., 1., 2., 3.])
tensor([[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.],
[12., 13., 14., 15.],
[16., 17., 18., 19.]])
tensor([ 14., 38., 62., 86., 110.])
矩阵-矩阵乘法
A = torch.arange(20, dtype=torch.float32).reshape(5, 4) # 创建一个包含0到19的矩阵,并将其重塑为5行4列
print(A) # 打印矩阵A
print(A.shape) # 打印矩阵A的形状,应该输出torch.Size([5, 4])
B = torch.ones(4, 3) # 创建一个包含4个元素的向量,所有元素的值为1,数据类型为float32
print(B) # 打印矩阵B
print(B.shape) # 打印矩阵B的形状,应该输出torch.Size([4, 3])
print(torch.mm(A, B)) # 打印矩阵A和B的矩阵乘积,应该输出一个包含5行3列的矩阵
运行结果
torch.Size([5, 4])
tensor([[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]])
torch.Size([4, 3])
tensor([[ 6., 6., 6.],
[22., 22., 22.],
[38., 38., 38.],
[54., 54., 54.],
[70., 70., 70.]])
注意: 矩阵乘法不满足交换律
范数
范数(Norm)就是数学家为向量发明的一把“尺子”。 在日常生活中(也就是 3 维及以下的物理世界),我们默认两点之间的直线距离就是长度。但在高维数据空间里,“长度”可以有不同的计算规则。范数,就是定义这些规则的统称
L1 范数
u = torch.tensor([3.0, -4.0]) # 创建一个包含两个元素的向量,值分别为3.0和4.0
print(torch.abs(u).sum()) # 打印向量u的元素的绝对值之和,应该输出7.0
L2 范数
u = torch.tensor([3.0, 4.0]) # 创建一个包含两个元素的向量,值分别为3.0和4.0
print(torch.norm(u)) # 打印向量u的L2范数,应该输出5.0
u = torch.tensor([3.0, -4.0]) # 创建一个包含两个元素的向量,值分别为3.0和4.0
print(torch.norm(u)) # 打印向量u的L2范数,应该输出5.0
Frobenius范数
u = torch.ones((4,9)) # 创建一个包含4行9列的矩阵,所有元素的值为1
print(u) # 打印矩阵u
# 计算方式:每行的元素之和为9,每行的平方和为9,所以L2范数为sqrt(9) = 3,矩阵有4行,所以总的L2范数为sqrt(3^2 + 3^2 + 3^2 + 3^2) = sqrt(36) = 6
print(torch.norm(u)) # 打印矩阵u的L2范数,应该输出6.0
向量的常见范数
| 范数类型 | 计算方式 | 物理直觉 / 形象比喻 | 特点 |
|---|---|---|---|
| L1 范数 | 所有分量的绝对值相加 | 🏙 曼哈顿距离:走街区的总路程 | 容易产生稀疏解,对异常值不太敏感 |
| L2 范数 | 每个分量平方后求和,再开方 | 📏 欧式距离:两点之间的直线距离 | 平滑、稳定、最常用 |
| Lp 范数 | 绝对值的 p 次方求和后再开 p 次方 | 🎛 可调节规则:p 越大越强调大的分量 | L1 和 L2 的推广形式 |
| L∞ 范数 | 取绝对值最大的那个分量 | 👀 切比雪夫距离:只看最显眼的那个数 | 控制最大误差、最坏情况分析 |
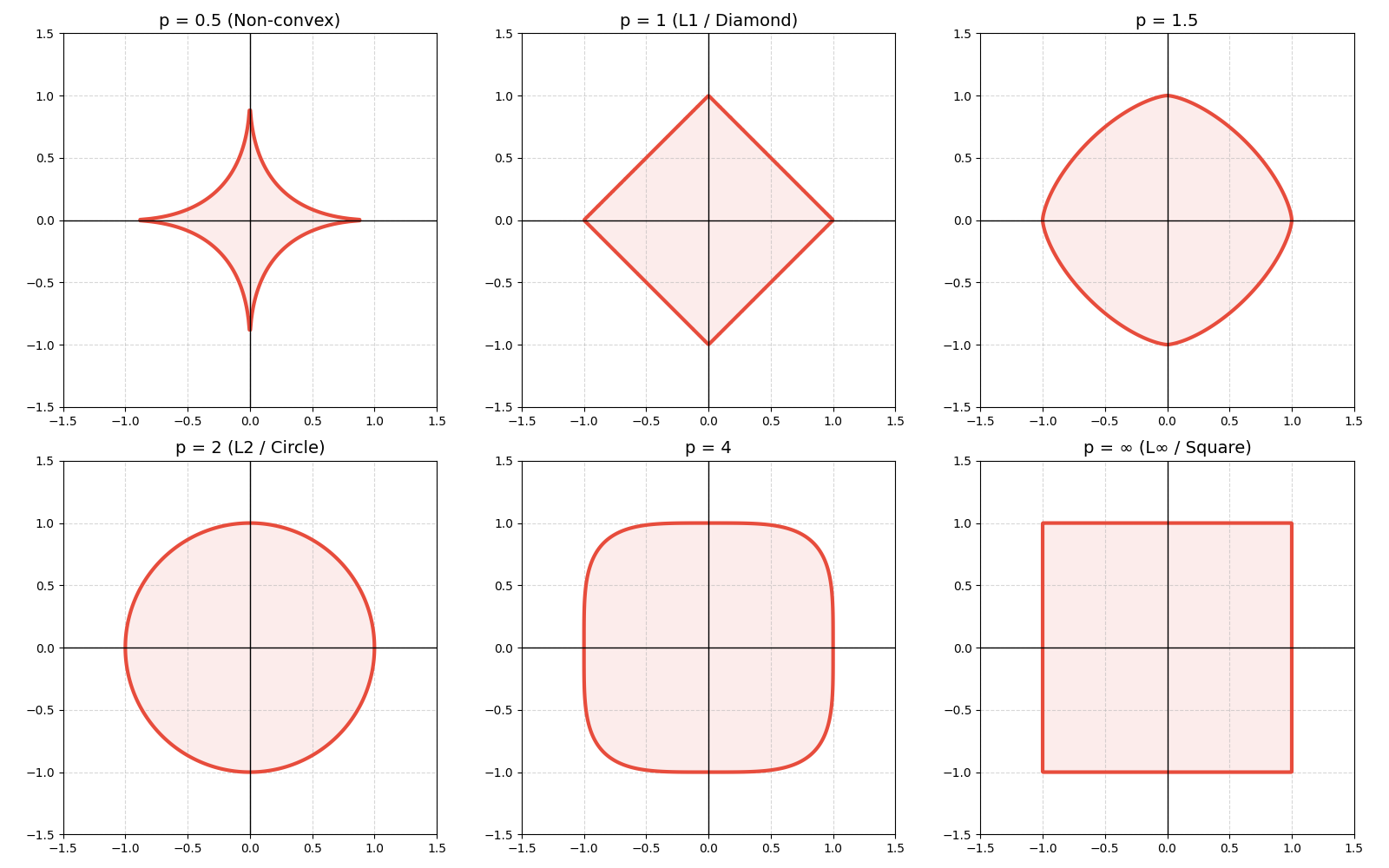
矩阵的常见范数
| 范数 | 别名 | 计算核心 | 关注点 / 物理直觉 |
|---|---|---|---|
| Frobenius 范数 | F-范数 | 所有元素平方后求和再开方 | 衡量矩阵整体“重量”或“能量” |
| 1-范数 | 列和范数 | 每一列绝对值求和,取最大那一列 | 哪一列最重;对列方向的最大拉伸 |
| ∞-范数 | 行和范数 | 每一行绝对值求和,取最大那一行 | 哪一行最强;对行方向的最大影响 |
| 谱范数 | 算子2-范数 / L2-范数 | 取矩阵的最大奇异值 | 矩阵在某个方向上的最大放大能力 |
矩阵范数案例一
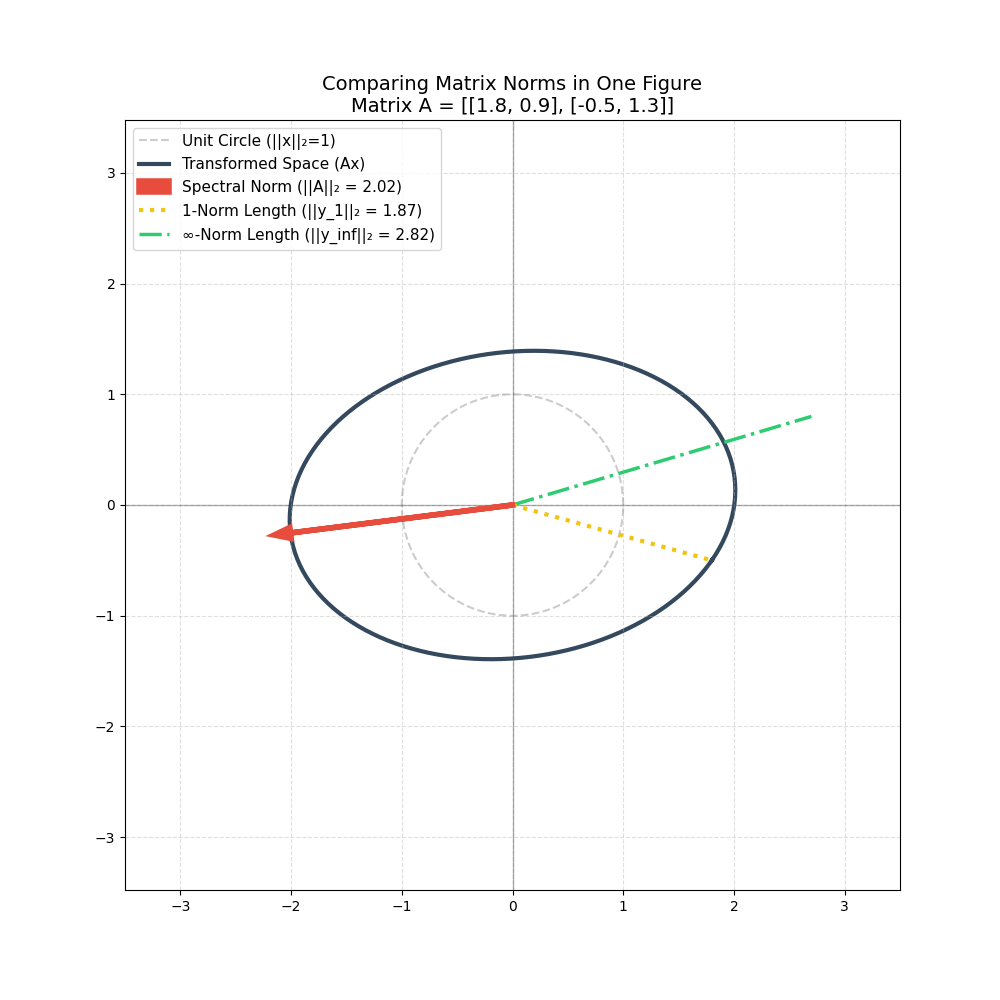
| 范数名称 | 算式演示 | 结果 | 对应图形理解 |
|---|---|---|---|
| 1-范数 | max(1.8+0.5, 0.9+1.3) | 2.30 | 轴向(基向量方向)的最大拉伸 |
| ∞-范数 | max(1.8+0.9, 0.5+1.3) | 2.70 | 行方向的最大整体影响 |
| 谱范数(L2) | 最大奇异值 | 2.03 | 椭圆长轴的绝对长度(最大拉伸方向) |
| Frobenius 范数 | 所有元素平方求和再开方 | 2.45 | 矩阵整体的“能量”规模 |
矩阵范数案例二
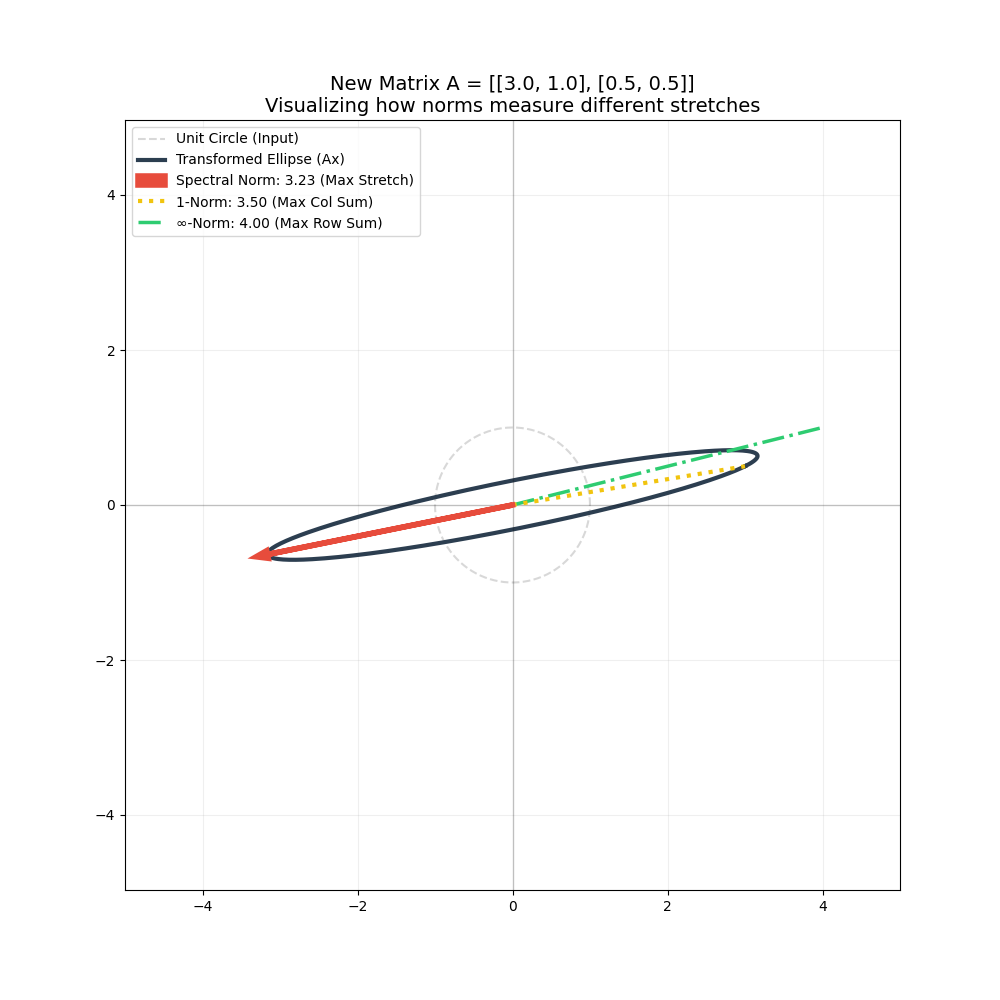
范数在深度学习中的作用
在深度学习中,范数(Norm)不仅仅是数学上的“长度”,它更是我们控制模型“性格”和“体态”的工具。
如果把模型训练比作捏泥塑,范数就是那双时刻修正形状的手,防止泥塑坍塌(梯度消失)或变得过于臃肿(过拟合)。
0
次点赞