概率
机器学习的本质是“从历史中寻找规律,并将其应用到未来”。如果一个模型只是记住了过去的数据,而不能对新情况做出判断,那它就只是一个“数据库”,而不是“智能”。
基本概率论
import torch
from torch.distributions import multinomial
from d2l import torch as d2l
# 构造一个“公平骰子”的概率分布:6 个面的概率都相同(每个面为 1/6)
# 向量计算形式:fair_probs = [1,1,1,1,1,1] / 6 = [1/6,...,1/6]
# 在代码里等价于:torch.ones(6) / 6
fair_probs = torch.ones(6) / 6
print(fair_probs)
# 从多项分布中采样 1 次(等价于掷 1 次骰子)
# 返回 one-hot 形式的结果张量,例如 [0, 0, 1, 0, 0, 0]
# a = multinomial.Multinomial(1, fair_probs).sample()
# print(a)
# 从多项分布中采样 1000 次(等价于掷 1000 次骰子)
# a = multinomial.Multinomial(1000, fair_probs).sample()
# 结果张量 a 中的每个元素表示对应面出现的次数,例如 [167, 169, 168, 164, 167, 165]
# 向量频率计算:a_prob = a / a.sum(),这里 a.sum() = 1000,所以就是 a / 1000
# print(a/ 1000)
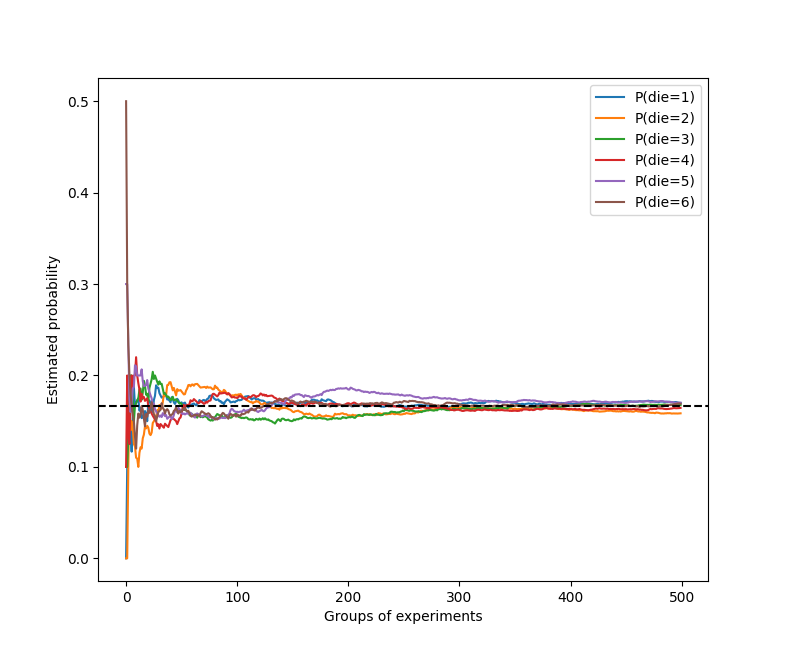
# 进行 500 组实验:每组掷 10 次骰子
# 形状为 (500, 6),每一行是该组实验里 6 个面的出现次数
# 向量视角:counts[g] 是第 g 组的 6 维计数向量,且 counts[g].sum() = 10
counts = multinomial.Multinomial(10, fair_probs).sample((500,))
print(counts)
# 沿着“组数”方向做累计和:第 t 行表示前 t+1 组实验的累计计数
# 向量累计:cum_counts[t] = counts[:t+1].sum(dim=0)
cum_counts = counts.cumsum(dim=0)
print(cum_counts)
# 将累计计数归一化为概率估计值
# cum_counts.sum(dim=1, keepdims=True) 得到每一时刻的总试验次数(10, 20, ..., 5000)
# estimates 的形状仍是 (500, 6),表示每个时刻对 6 个面的概率估计
# 向量归一化:estimates[t] = cum_counts[t] / cum_counts[t].sum()
# 代码一次性写法:estimates = cum_counts / cum_counts.sum(dim=1, keepdims=True)
estimates = cum_counts / cum_counts.sum(dim=1, keepdims=True)
# 设置绘图尺寸
d2l.set_figsize((6, 4.5))
# 分别绘制 6 条曲线:每条曲线表示某一面的概率估计随实验次数增加的变化
for i in range(6):
d2l.plt.plot(estimates[:, i].numpy(),
label=("P(die=" + str(i + 1) + ")"))
# 画出理论概率 1/6≈0.167 的参考虚线
# 参考线对应 y = 1/6 ≈ 0.1667
d2l.plt.axhline(y=0.167, color='black', linestyle='dashed')
d2l.plt.gca().set_xlabel('Groups of experiments')
d2l.plt.gca().set_ylabel('Estimated probability')
d2l.plt.legend()
# 在脚本模式下,需显式调用 show() 才会弹出图形窗口
d2l.plt.show()
运行打印
tensor([[5., 1., 0., 1., 2., 1.],
[2., 1., 2., 1., 2., 2.],
[1., 5., 1., 0., 1., 2.],
...,
[2., 2., 1., 2., 1., 2.],
[4., 0., 1., 1., 1., 3.],
[2., 1., 1., 2., 3., 1.]])
解释: * 这是最关键的一步。我们不只看单个人的结果,而是把大家的结果累加起来。
第 1 行是第 1 个人的结果(共掷 10 次)。
第 2 行是第 1 + 第 2 个人的结果(共掷 20 次)。
...
第 500 行是所有 500 个人的结果总和(共掷 5000 次)。
tensor([[ 5., 1., 0., 1., 2., 1.],
[ 7., 2., 2., 2., 4., 3.],
[ 8., 7., 3., 2., 5., 5.],
...,
[820., 809., 864., 835., 817., 835.],
[824., 809., 865., 836., 818., 838.],
[826., 810., 866., 838., 821., 839.]])
解释: * 把累计次数换算成百分比。比如掷了 100 次,其中“点数 1”出现了 15 次,那此时的估计概率就是 $15/100 = 0.15$。随着总次数(分母)从 10 变成 5000,这个百分比会越来越稳定。
tensor([[0.5000, 0.1000, 0.0000, 0.1000, 0.2000, 0.1000],
[0.3500, 0.1000, 0.1000, 0.1000, 0.2000, 0.1500],
[0.2667, 0.2333, 0.1000, 0.0667, 0.1667, 0.1667],
...,
[0.1647, 0.1624, 0.1735, 0.1677, 0.1641, 0.1677],
[0.1651, 0.1621, 0.1733, 0.1675, 0.1639, 0.1679],
[0.1652, 0.1620, 0.1732, 0.1676, 0.1642, 0.1678]])
概率论公理
一个概率空间由三部分组成
| 符号 | 含义 |
|---|---|
| (\Omega) | 样本空间(所有可能结果) |
| (\mathcal{F}) | 事件集合(σ-代数) |
| (P) | 概率测度 |
Kolmogorov 三大公理
| 公理编号 | 名称 | 数学表达 | 含义 | 直观理解 |
|---|---|---|---|---|
| 1 | 非负性 | (P(A) \ge 0) | 任意事件概率不为负 | 概率不能是负数 |
| 2 | 规范性(归一性) | (P(\Omega)=1) | 整个样本空间概率为 1 | 所有可能结果加起来是 100% |
| 3 | σ-可加性(可列可加) | 若 (A_i) 两两互斥: (P(\bigcup_{i=1}^{\infty}A_i)=\sum_{i=1}^{\infty}P(A_i)) |
互斥事件概率可累加 | 不重叠事件可以直接相加 |
随机变量
| 维度 | 离散随机变量 | 连续随机变量 |
|---|---|---|
| 取值 | 有限或可数 | 不可数(区间) |
| 概率表示 | 概率质量函数 PMF | 概率密度函数 PDF |
| 单点概率 | 可以 >0 | 必为 0 |
| 求和方式 | 求和 Σ | 积分 ∫ |
| 分布函数 | 阶梯函数 | 连续函数 |
| 典型分布 | 二项分布、泊松分布 | 正态分布、均匀分布 |
- 离散随机变量:可数取值,用“概率”描述
- 连续随机变量:不可数取值,用“密度”描述
处理多个随机变量
联合概率 和 条件概率
| 概念 | 数学表示 | 含义 | 直观理解 |
|---|---|---|---|
| 联合概率 | (P(A \cap B)) | A 和 B 同时发生 | 两个条件都满足 |
| 条件概率 | (P(A \mid B)) | 在 B 已发生下 A 发生 | 缩小样本空间 |
贝叶斯定理
贝叶斯定理的哲学:学习的本质
新知识 = 以前的认知 + 新观测到的数据
- 如果你的先验极其强大(比如你坚信太阳明天会升起),那么微小的新证据很难改变你的想法。
- 如果你完全没有经验(先验很薄弱),那么新证据会瞬间左右你的判断。
案例解释
频率派 VS 贝叶斯派
| 特性 | 传统统计学(频率派) | 贝叶斯派 |
|---|---|---|
| 概率的含义 | 概率 = 长期重复实验的频率 | 概率 = 主观信念的强度 |
| 参数 | 参数是固定但未知的常数 | 参数是随机变量(有分布) |
| 核心思想 | 依赖大量重复实验 | 先验 + 数据 → 后验 |
| 数据地位 | 数据是随机的 | 数据是已知事实 |
| 参数地位 | 参数固定不变 | 参数随信息更新 |
| 结论形式 | 点估计 + 置信区间 | 后验分布 + 可信区间 |
| 推断方式 | 最大似然估计 (MLE) | 贝叶斯更新 |
| 结果解释 | “若重复实验95%会覆盖真值” | “参数有95%概率在区间内” |
| 是否用先验 | 不使用 | 必须使用 |
| 小样本表现 | 不稳定 | 可结合先验更稳定 |
AI 中使用的差异
| 维度 | 频率派 (Frequentist) - 深度学习主流 | 贝叶斯派 (Bayesian) - 决策与推断核心 |
|---|---|---|
| 对概率的理解 | 客观频率:概率是长期重复试验中事件出现的极限频率。 | 主观信念:概率是根据现有证据对某件事发生的信心程度。 |
| 模型参数 $\theta$ | 固定常数:参数是唯一的、确定的,只是我们暂时不知道。 | 随机变量:参数不是一个值,而是一个概率分布。 |
| 训练目标 | 找最优点 (MLE):寻找一组让当前数据出现概率最大的参数。 | 找分布 (Posterior):寻找参数在已知数据下的完整概率分布。 |
| 先验知识 | 不重要/不使用:完全由数据说话(正则化仅作为某种约束)。 | 至关重要:必须提供初始假设(Prior),再通过数据更新。 |
| 对待不确定性 | 无法直接量化:模型通常只给出一个确定的预测值。 | 天然量化:能告诉你预测结果的置信区间(知道自己不知道)。 |
| 数据量需求 | 大数据依赖:数据越多越准,数据少时极易过拟合。 | 小数据友好:即使只有几个样本,结合先验也能做出合理推断。 |
| 典型应用 | 图像识别、语音转文字、大语言模型 (LLM)。 | 自动驾驶定位、临床药物试验、金融风险控制、超参数优化。 |
本质理解
这种使用场景的差异,直指人工智能领域最核心的本质冲突:“感知(Perception)”与“推理(Inference)”的对立统一
归纳 vs 演绎 (Induction vs Deduction)
- 深度学习的本质是“极致的归纳”: 它像是一个看了成千上万场球赛的观众,虽然不懂物理定律,但只要球飞过来,他就能凭直觉(模式识别)判断落点。它强调的是从海量数据中淬炼规律。
- 贝叶斯的本质是“严谨的演绎”: 它像是一个物理学家,手里握着公式(先验/模型),根据当前的观察不断修正参数。它强调的是在已知逻辑框架下处理偏差。
统计相关性 vs 因果逻辑性
- 深度学习: 它是相关性的王。它不关心“为什么这组像素是猫”,它只关心“当这组像素出现时,标签通常是猫”。所以它在处理非结构化数据(图像、声音)时无敌,但在逻辑严密的推理中会产生“幻觉”。
- 贝叶斯: 它是因果和结构的守护者。它强制要求你定义变量之间的关系(先验)。这种结构化的思维让它在面对“如果…会怎样”(干预分析)时表现得比深度学习更理性。
这种应用场景的差异说明了:没有任何一种单一算法能完美模拟人类智能。
- 人类的大脑: 既有视觉皮层这种类似“深度学习”的快速、直觉化感知系统;又有前额叶这种类似“贝叶斯”的慢速、逻辑化决策系统。
- 现代 AI 的趋势: 正在尝试将两者结合。用深度学习做感知层(看清路在哪)。用贝叶斯/逻辑系统做决策层(判断即使摄像头坏了,车也不该撞墙)。
特斯拉自动驾驶是典范
| 维度 | 深度学习 (摄像头识别) | 贝叶斯 (轨迹规划/融合) |
|---|---|---|
| 角色 | 感知层:眼睛看到什么。 | 决策层:大脑推测发生了什么。 |
| 对待错误 | 过拟合:如果见过太少斜着的红灯,可能认不出来。 | 鲁棒性:哪怕暂时看不清,也能靠之前的经验(先验)补全。 |
| 算力消耗 | GPU 暴力计算:并行处理几百万个像素点。 | 逻辑计算:快速更新概率矩阵(卡尔曼滤波等)。 |
| 反馈形式 | “我看它是行人的概率是 99%”。 | “根据历史,我推测行人 0.5 秒后会出现在路口”。 |
两者冲突时的处理
| 场景 | 深度学习(感知)说… | 贝叶斯(规划)说… | 最终决策 |
|---|---|---|---|
| 遮挡场景 | 前方没车(因为看不见)。 | 根据惯性,车一定在遮挡物后。 | 减速/保持预警 |
| 光线反差 | 前方是空地(误认)。 | 激光/超声波检测到障碍物。 | 紧急制动 |
| 目标抖动 | 瞬间识别出是树,瞬间是人。 | 轨迹不符合生物运动逻辑。 | 维持原路径并预警 |
在特斯拉的系统中:
- 深度学习是“激进”的:它总想给万物贴标签。
- 贝叶斯逻辑是“保守”的:它总是在评估风险。
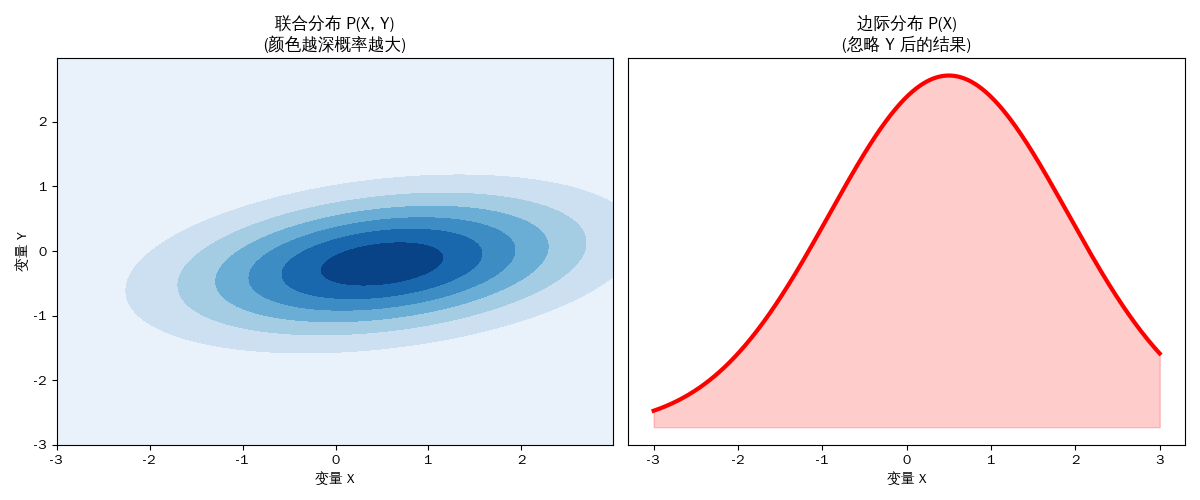
边际化
在概率论和机器学习中,边际化(Marginalization)听起来像个高大上的词,但其实它的本质就是“消除噪声”或“忽略次要信息”
边际化 = 把你不关心的变量“加掉 / 积掉”。
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import multivariate_normal
# 中文显示设置(常见 Linux/Windows/macOS 字体回退)
plt.rcParams['font.sans-serif'] = [
'Noto Sans CJK SC', 'Source Han Sans SC', 'WenQuanYi Zen Hei',
'SimHei', 'Microsoft YaHei', 'PingFang SC', 'Heiti SC',
'Arial Unicode MS', 'DejaVu Sans'
]
plt.rcParams['axes.unicode_minus'] = False
# 1. 创建联合分布数据 (X 和 Y)
x, y = np.mgrid[-3:3:.01, -3:3:.01]
pos = np.dstack((x, y))
# 设定均值和协方差(让 X 和 Y 有相关性)
rv = multivariate_normal([0.5, -0.2], [[2.0, 0.3], [0.3, 0.5]])
# 2. 绘图
fig = plt.figure(figsize=(12, 5))
# 左图:联合分布 (就像从正上方俯瞰那团云)
ax1 = fig.add_subplot(121)
ax1.contourf(x, y, rv.pdf(pos), cmap='Blues')
ax1.set_title('联合分布 P(X, Y)\n(颜色越深概率越大)')
ax1.set_xlabel('变量 X')
ax1.set_ylabel('变量 Y')
# 右图:边际化过程
# 我们通过在 Y 轴上积分来得到 X 的边际分布
x_axis = np.linspace(-3, 3, 500)
# 简化模拟:边际分布依然是高斯分布
margin_x = np.exp(-(x_axis - 0.5)**2 / (2 * 2.0))
ax2 = fig.add_subplot(122)
ax2.plot(x_axis, margin_x, color='red', lw=3)
ax2.fill_between(x_axis, 0, margin_x, color='red', alpha=0.2)
ax2.set_title('边际分布 P(X)\n(忽略 Y 后的结果)')
ax2.set_xlabel('变量 X')
ax2.set_yticks([]) # 边际分布只看形状
plt.tight_layout()
plt.show()
边际化本质上是在做信息的丢弃与聚焦:将复杂的、多维的世界通过“压扁”的方式,转化为我们关心的单一维度。
期望和方差
0
次点赞