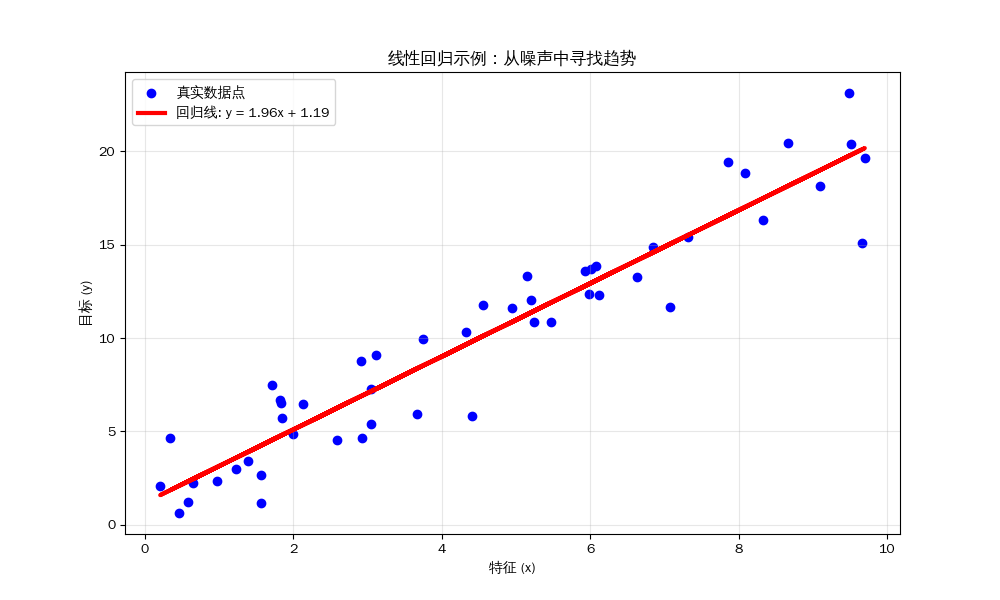
线性回归
线性回归(Linear Regression) 就是要在杂乱的数据点中,寻找一条“最契合”的直线,用来揭示变量之间的数量关系,并预测未来。
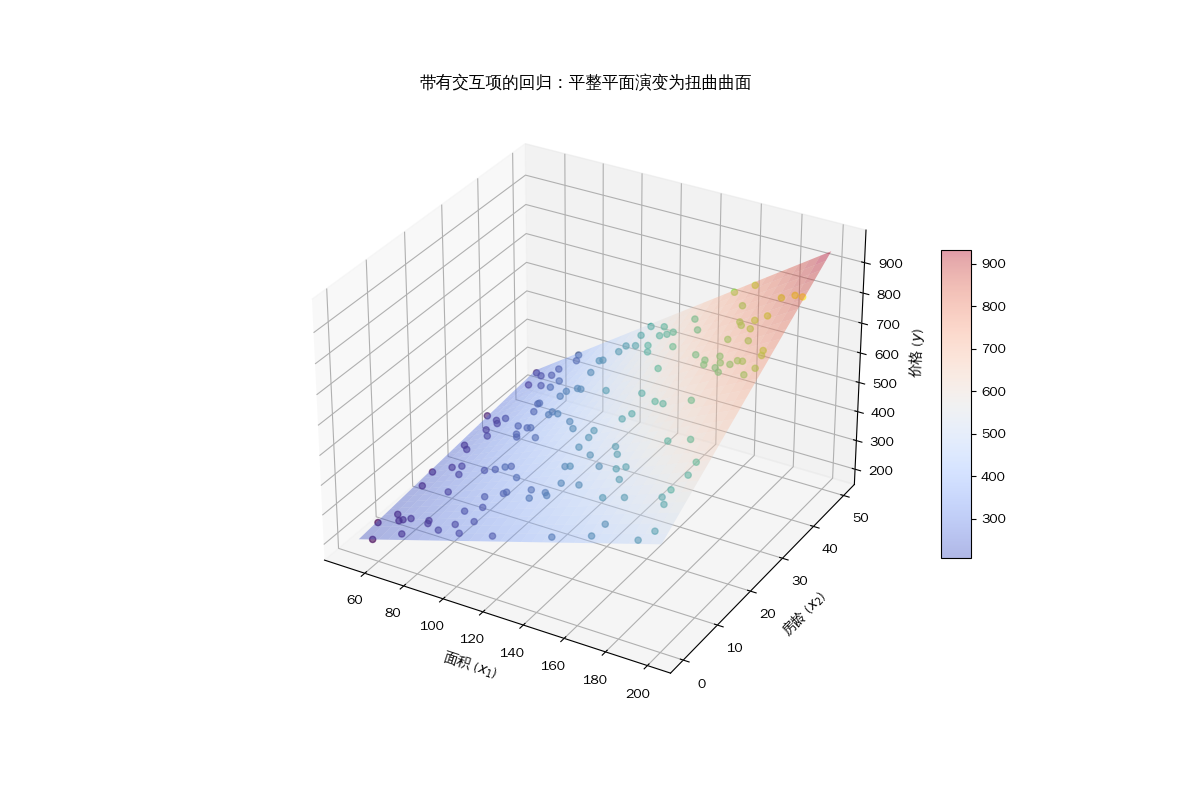
多元线性回归
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from mpl_toolkits.mplot3d import Axes3D
# 让图里的中文能正常显示(按顺序尝试多种常见中文字体)
plt.rcParams['font.sans-serif'] = [
'Noto Sans CJK SC', 'Source Han Sans SC', 'WenQuanYi Zen Hei',
'SimHei', 'Microsoft YaHei', 'PingFang SC', 'Heiti SC',
'Arial Unicode MS', 'DejaVu Sans'
]
plt.rcParams['axes.unicode_minus'] = False
# 1) 先造一批“示例房屋数据”
# 设置随机种子以保证结果可复现
np.random.seed(42)
# 生成 150 个样本的面积和房龄数据
n_samples = 150
# 面积在 50 到 200 平方米之间,房龄在 0 到 50 年之间
area = np.random.uniform(50, 200, n_samples)
age = np.random.uniform(0, 50, n_samples)
# 这里人为设定“价格生成规则”:
# 价格 = 面积影响 + 房龄影响 + (面积和房龄一起作用) + 常数 + 随机噪声
# 其中 area*age 就是“交互项”,表示两个因素叠加后的共同影响
price = 2 * area - 1 * age + 0.05 * (area * age) + 100 + np.random.normal(0, 10, n_samples)
# 2) 组织模型输入:面积、房龄、交互项(面积*房龄)
interaction_term = area * age
X = np.column_stack((area, age, interaction_term))
# 3) 用线性回归拟合数据
model = LinearRegression()
model.fit(X, price)
# 4) 为画曲面准备网格点(把面积和房龄都切成很多小点)
area_range = np.linspace(50, 200, 30)
age_range = np.linspace(0, 50, 30)
Area, Age = np.meshgrid(area_range, age_range)
# 在每个网格点上,按训练出的公式计算预测价格
# 公式:y = w1*x1 + w2*x2 + w3*(x1*x2) + b
Price_pred = (model.coef_[0] * Area +
model.coef_[1] * Age +
model.coef_[2] * (Area * Age) +
model.intercept_)
# 5) 画 3D 图
fig = plt.figure(figsize=(12, 8))
ax = fig.add_subplot(111, projection='3d')
# 散点:真实样本点
ax.scatter(area, age, price, c=price, cmap='viridis', alpha=0.6, label='房产成交数据')
# 曲面:模型学到的价格变化趋势
surf = ax.plot_surface(Area, Age, Price_pred, cmap='coolwarm', alpha=0.4, antialiased=True)
ax.set_xlabel('面积 ($x_1$)')
ax.set_ylabel('房龄 ($x_2$)')
ax.set_zlabel('价格 ($y$)')
plt.title('带有交互项的回归:平整平面演变为扭曲曲面')
fig.colorbar(surf, ax=ax, shrink=0.5, aspect=10)
plt.show()
| 模型类型 | 方程形式 | 几何形状 | 变量关系 |
|---|---|---|---|
| 多元线性回归 | $y = \sum w_i x_i + b$ | 平面 (Hyperplane) | 变量之间互不相干,各自独立对结果做贡献。 |
| 带交互项的回归 | $y = … + w_{ij}(x_i x_j) + b$ | 扭曲曲面 (Warped Surface) | 变量之间存在协同或拮抗作用,一个变量的影响力取决于另一个变量。 |
多元线性回归
\[y = \sum_i w_i x_i + b\]带交互项的回归
\[y = \sum_i w_i x_i + \sum_{i,j} w_{ij} x_i x_j + b\]损失函数
损失函数是一个数学公式,用来计算模型的预测值 ($y_{pred}$) 与真实值 ($y_{true}$) 之间的差异
\[y = w_1 x_1 + w_2 x_2 + w_{12}(x_1 x_2) + b\]| 组件 | 物理意义 | 图形表现 | 机器学习中的角色 |
|---|---|---|---|
| 权重 (Weight, w) | 重要程度/斜率 | 决定直线的倾斜角度。 | 代表特征对结果的贡献强度与方向(正相关或负相关)。 |
| 偏置 (Bias, b) | 基础分/截距 | 决定直线在 Y 轴上的上下平移。 | 补偿预测值与真实值之间的整体系统性偏差。 |
在寻找最好的模型参数w和b之前,我们需要两个内容:
- 一种模型质量的度量方式
- 一种能够更新模型以提高模型预测质量的方法
均方误差 (Mean Squared Error, MSE)
\[J(w, b) = \frac{1}{n} \sum_{i=1}^{n} (y^{(i)} - \hat{y}^{(i)})^2\]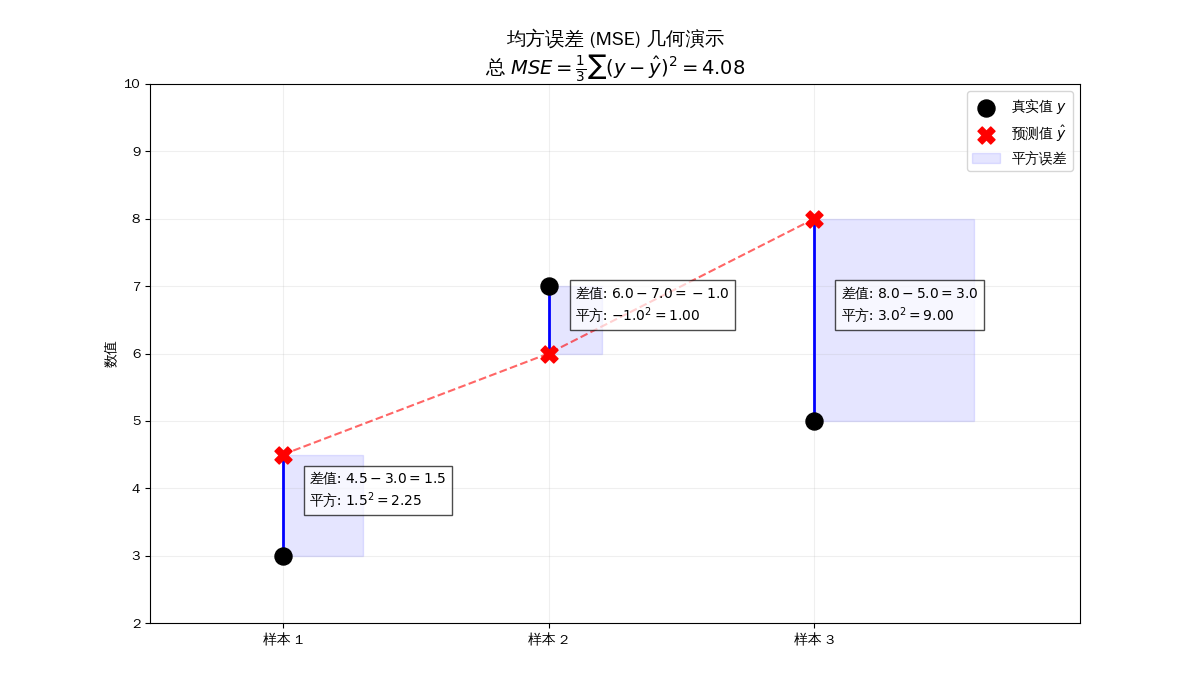
总 MSE 就是图中所有阴影正方形面积的平均值
- 视觉化“平方”:当你看到代码中画出的蓝色矩形(虽然为了美观做了比例调整),你会意识到 MSE 其实是在衡量误差围成的面积。
- 正向与负向:样本 1 预测高了(差值为正),样本 2 预测低了(差值为负)。通过公式中的平方,它们都变成了正数。
- 对异常值的敏感性:你可以试着在代码里把“样本 3”的预测值改成 15.0,你会发现公式里的平方项会从 9.0 瞬间爆炸到极大的数值,从而拉高整个 MSE。这就是为什么 MSE 会强迫模型去特别关照那些偏离太远的坏点
解析解
对于线性回归这种简单的模型,其实存在一种可以一步到位算出最优权重 $w$ 和偏置 $b$ 的数学方法。这个“标准答案”就被称为解析解(Analytical Solution),或者叫正规方程(Normal Equation)。
\[w = (X^T X)^{-1} X^T y\]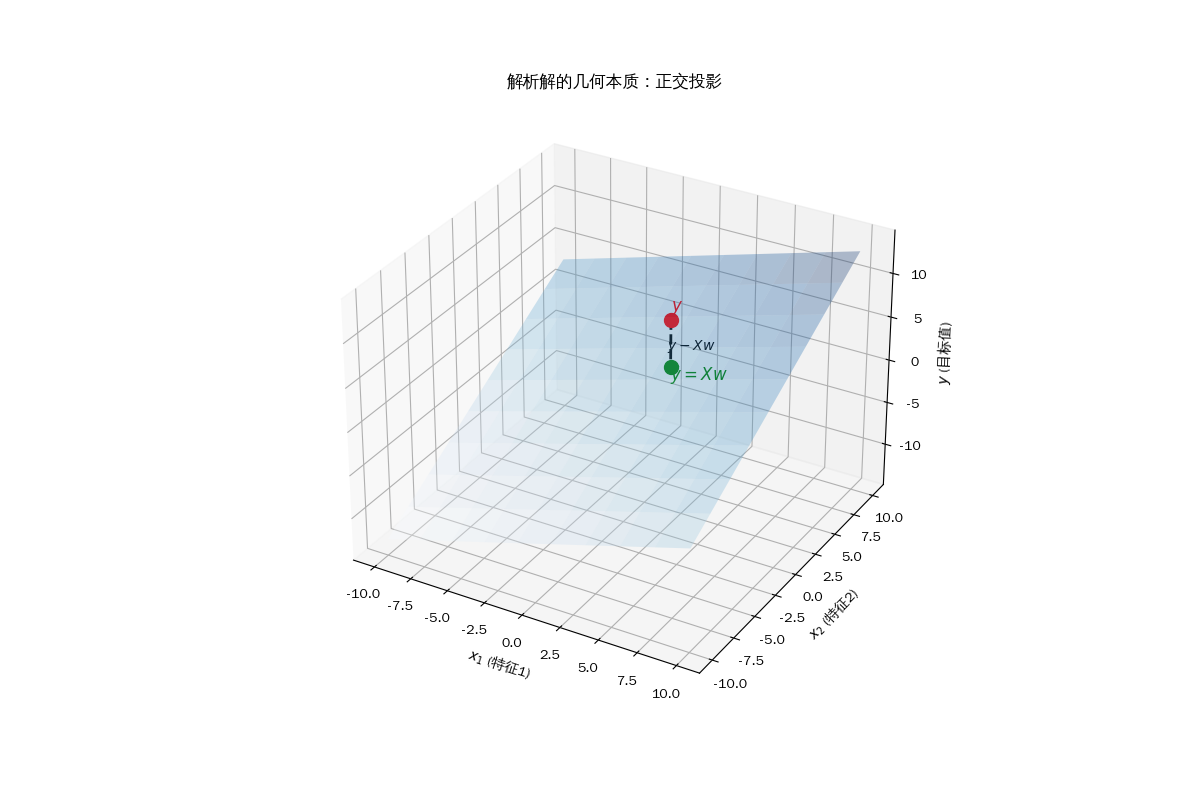
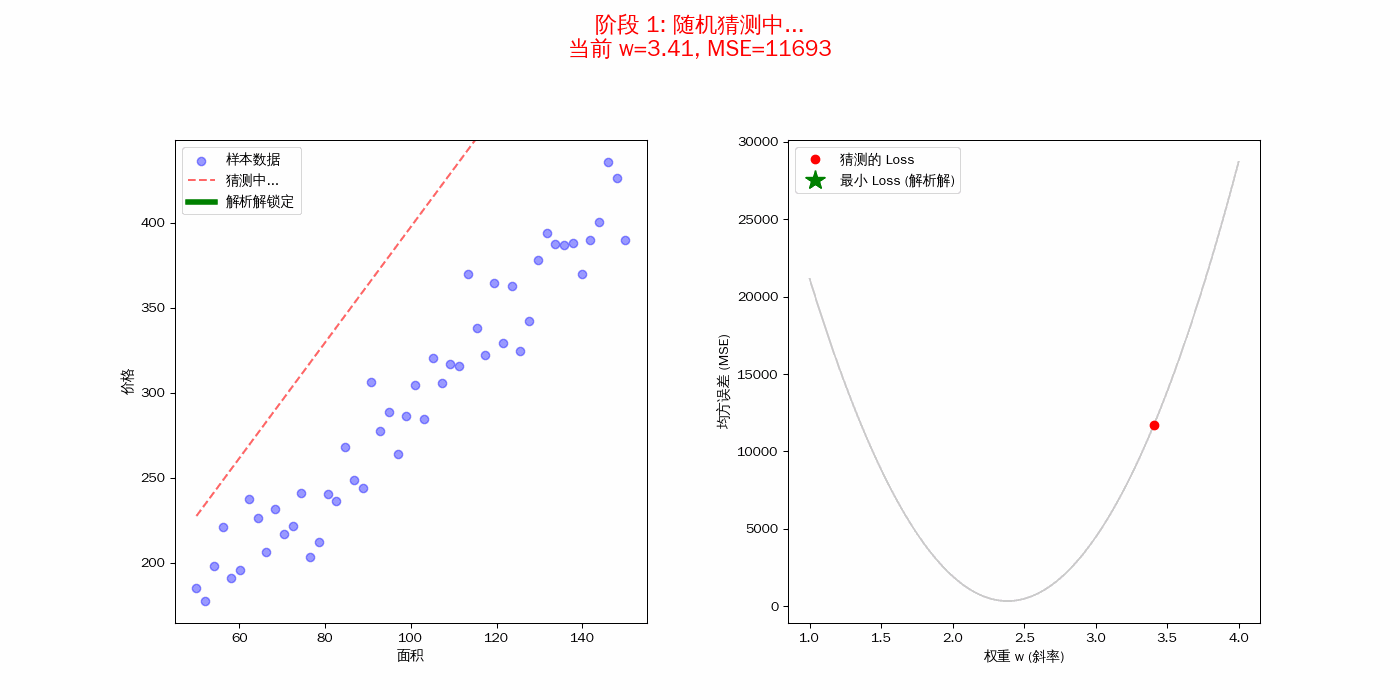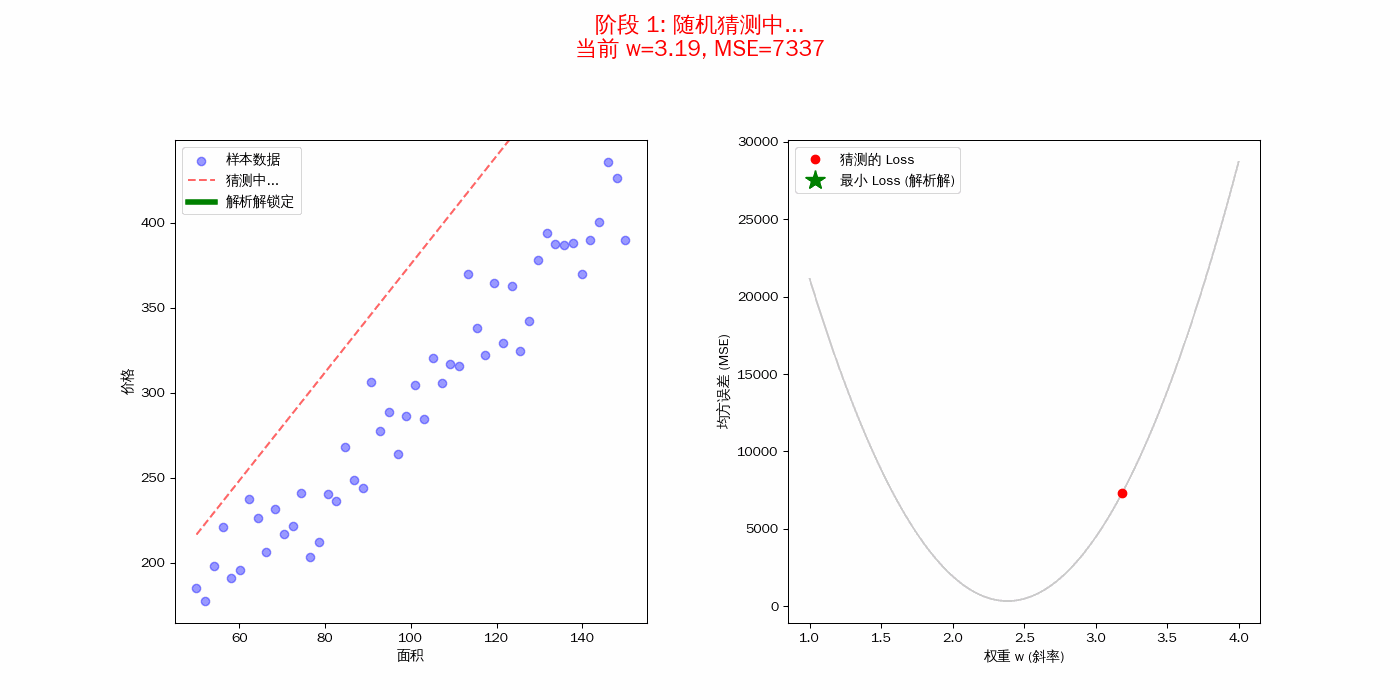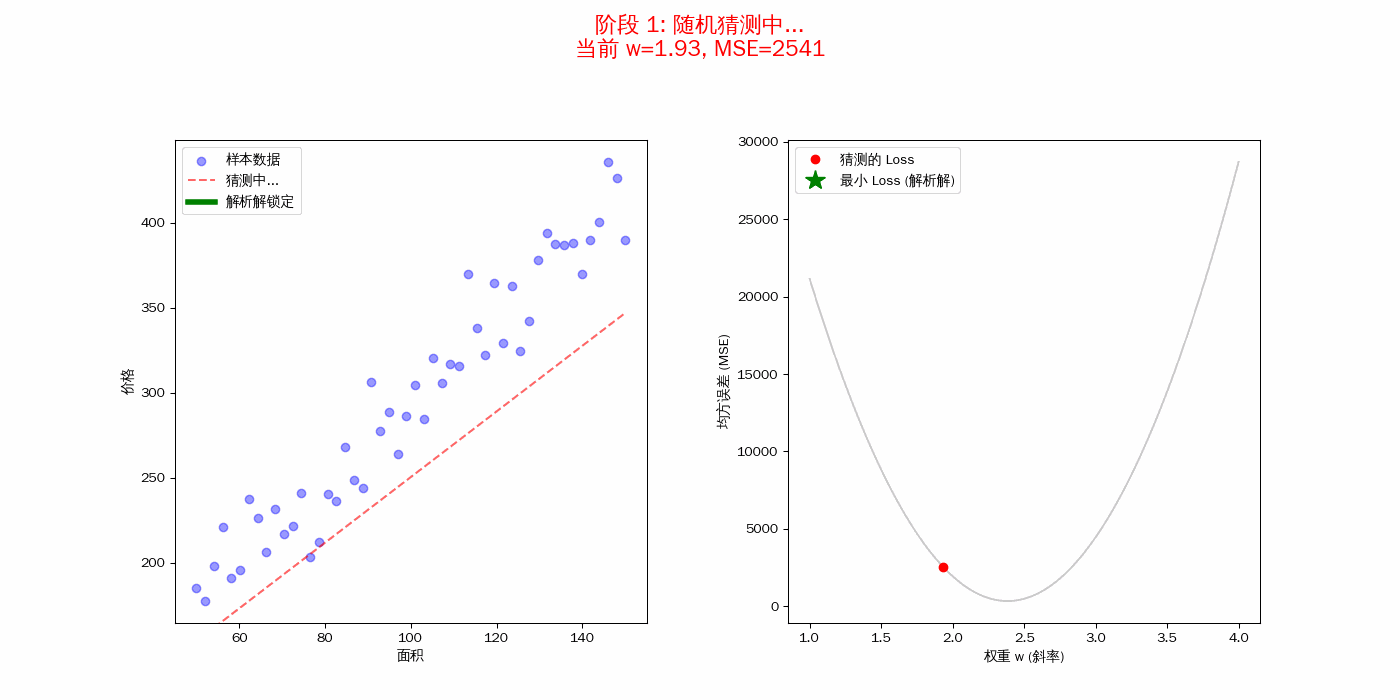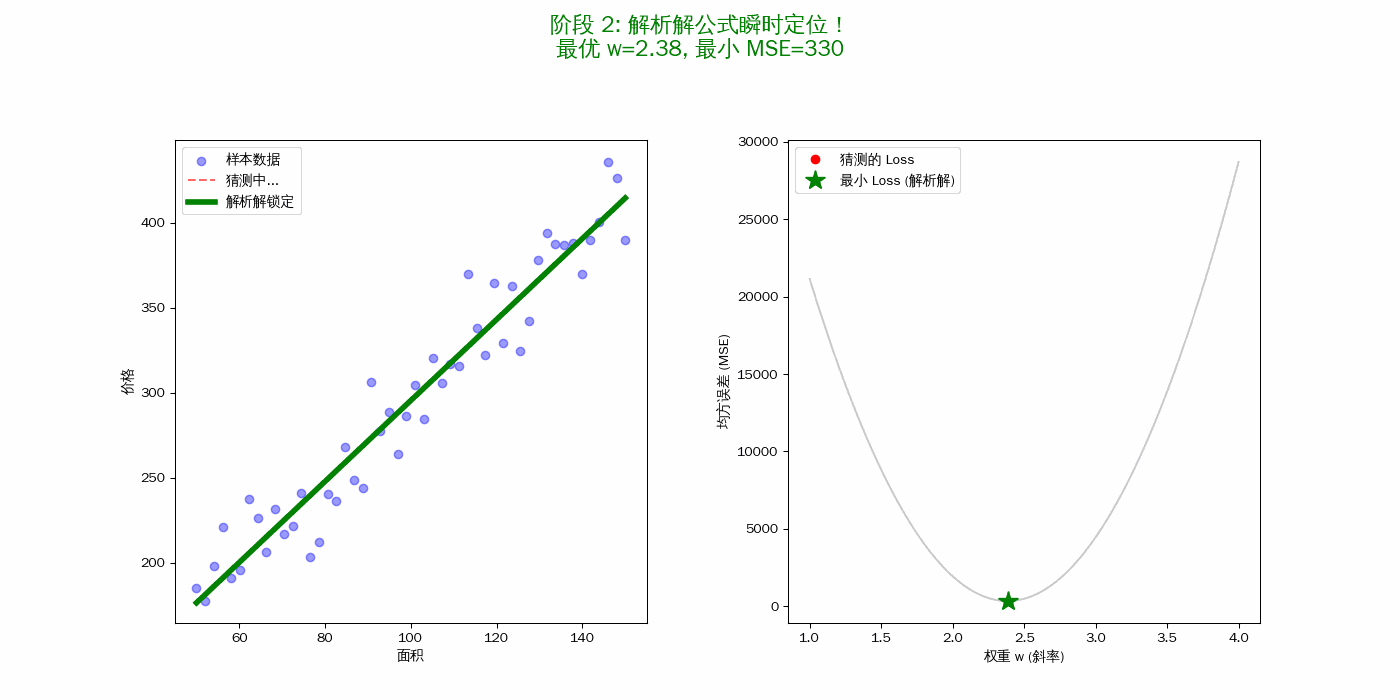
损失函数(MSE)的“形状”决定了结局
右图中的黑色曲线(抛物线)就是你的均方误差(MSE)。
- 每一个随机尝试的红点,都对应着这条曲线上的一个高度。
- 解析解的任务,就是不需要通过踩点,直接利用微积分算得这个“碗底”的横坐标。
为什么解析解是“静态”的?
在这个动画里,你会发现第一阶段红线在疯狂跳动,而第二阶段绿线出现后就一动不动。 这就是解析解的特征:它是数学上的必然结果。 只要你的 100 组数据($X, y$)不变,算出来的 $w$ 就是永恒不变的最优值。
解析解存在的问题
- 计算效率问题:特征越多,算得越慢
- 内存瓶颈问题:贪心的“内存吞噬者”
- 数值稳定性问题:当矩阵“塌陷”时
- 适用范围局限:只认 MSE 这一种标准
- 缺乏“增量学习”能力
“解析解是机器学习中的‘公式化真理’,它揭示了问题的数学本质。但在大数据和深度学习的战场上,我们往往需要放弃这种‘一次性的完美’,转而拥抱梯度下降这种‘渐进式的卓越’
随机梯度下降
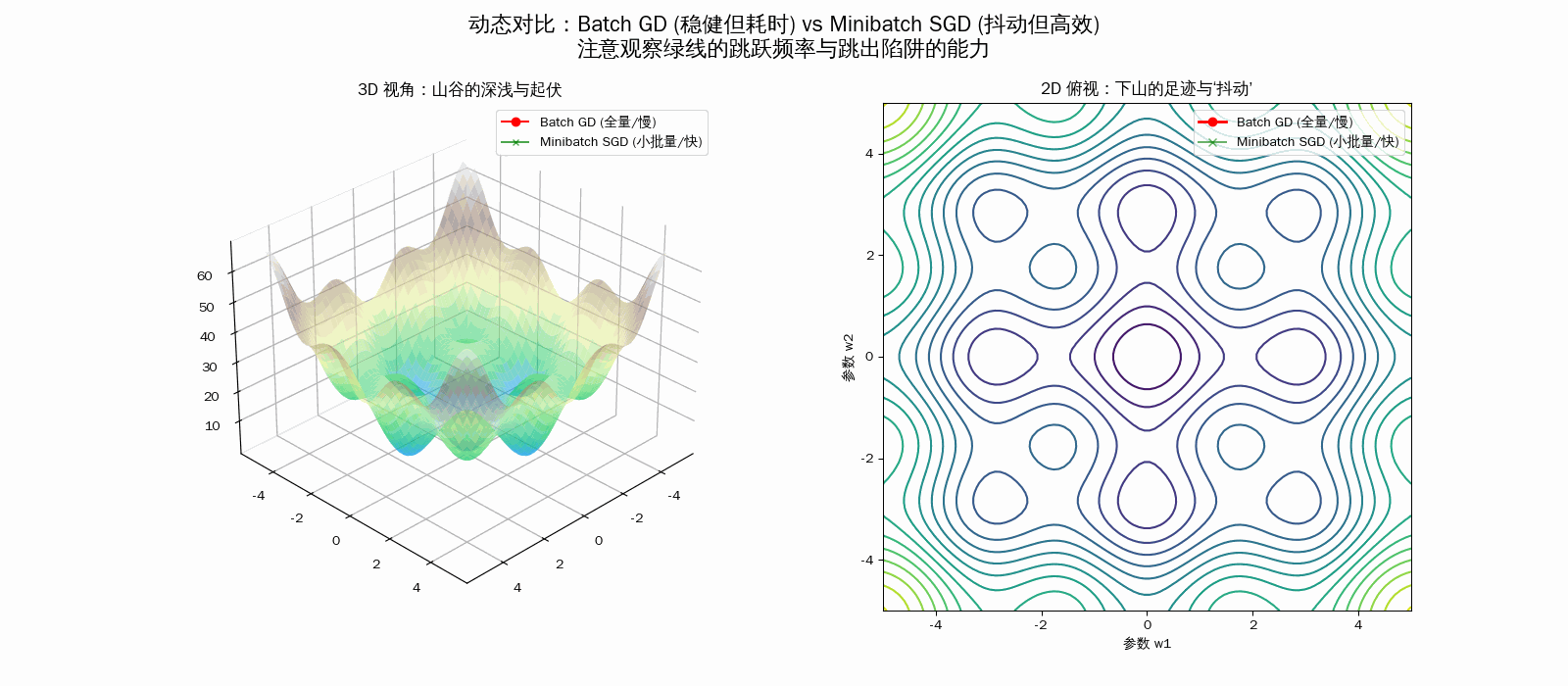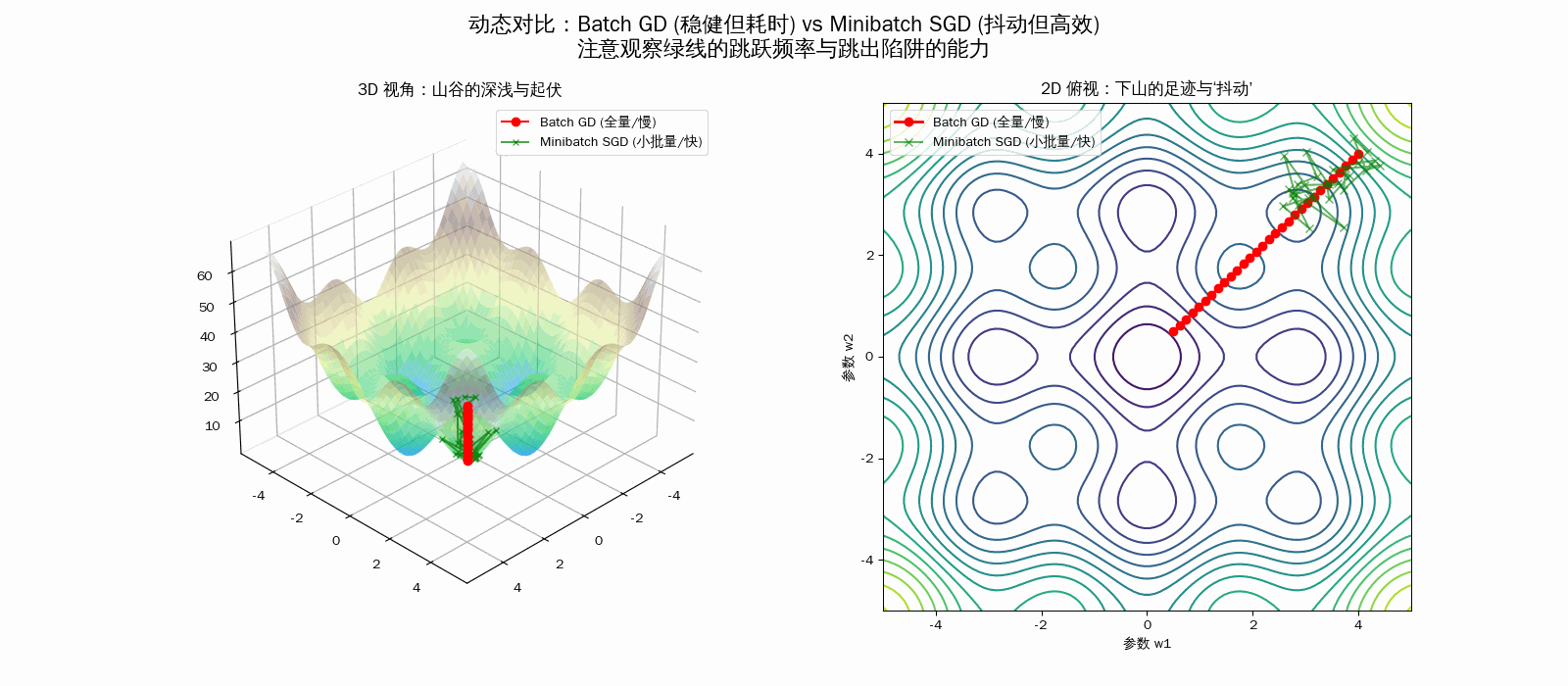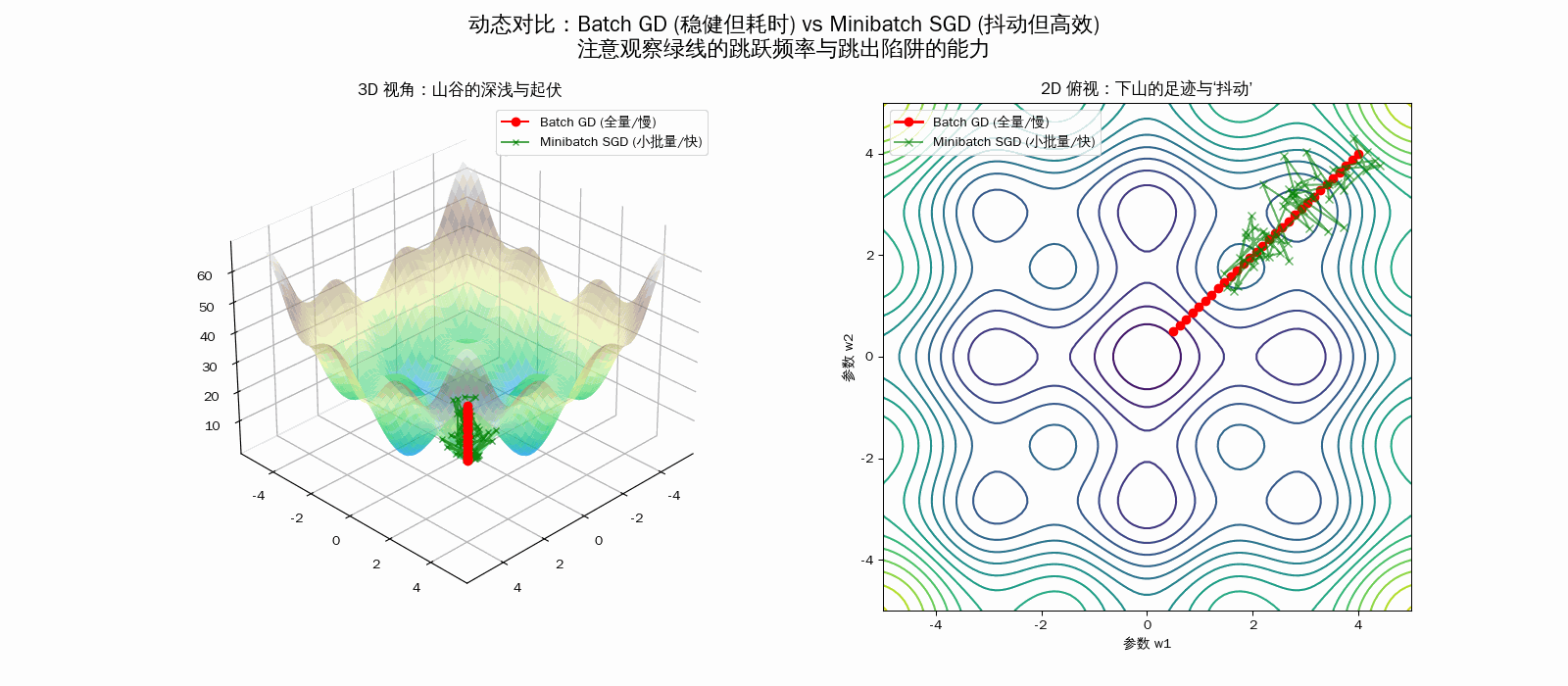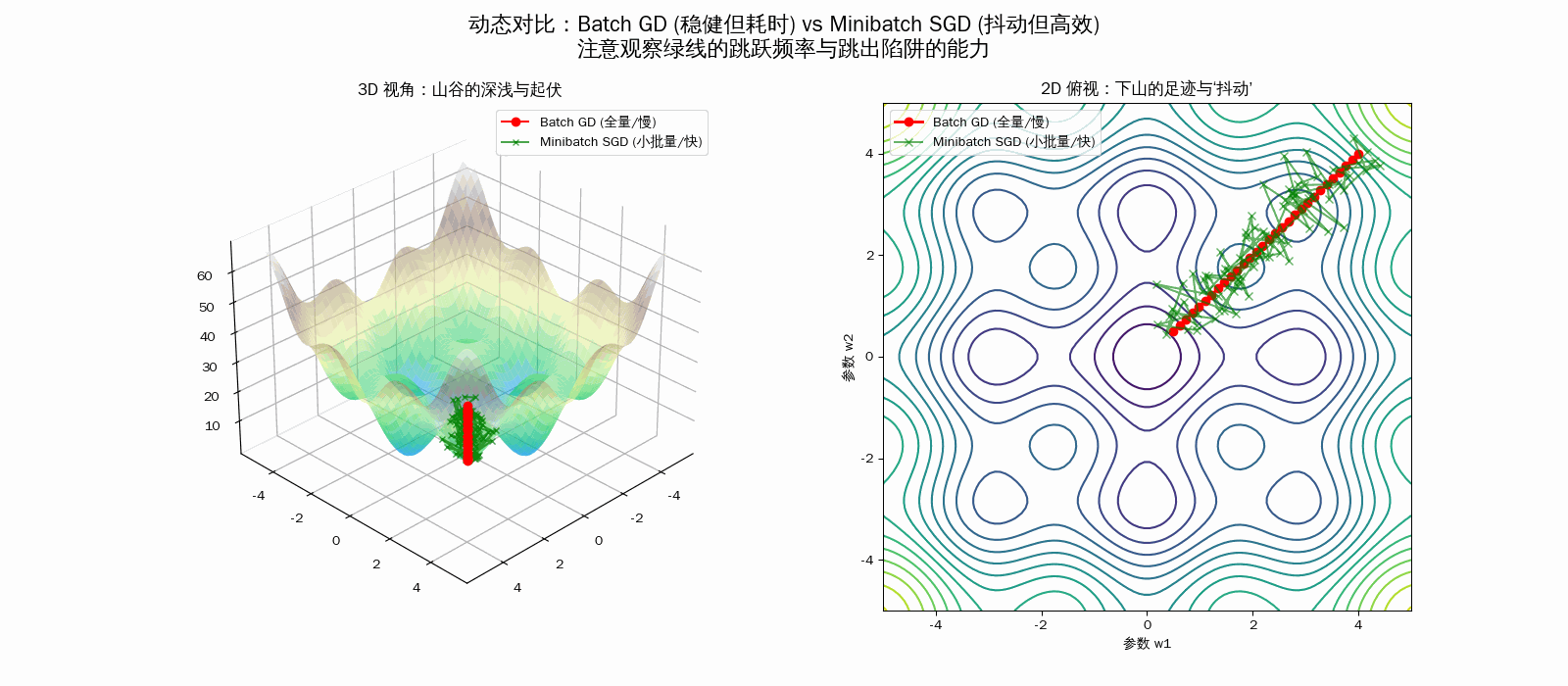
| 维度 | Batch GD (全量梯度下降) | Minibatch SGD (小批量随机) |
|---|---|---|
| 单步样本量 | 包含整个数据集的所有样本 | 随机抽取的小部分样本 (如 32, 64) |
| 动画轨迹 | 平滑直线:直奔当前感知的最低点 | 乱序抖动:像醉汉一样边走边晃 |
| 计算速度 | 极慢:单次更新需遍历全量数据 | 极快:单次更新仅需计算少量样本 |
| 硬件利用 | 内存压力大,难以处理超大规模数据 | GPU 友好,适合大规模并行计算 |
| 收敛特性 | 稳定收敛到导数为 0 的点 | 在最小值附近震荡,需配合衰减学习率 |
| 避障能力 | 容易困在微小的局部最小值(死板) | 随机噪声能帮助模型跳出浅坑(灵活) |
💡 为什么动画里的绿球(Minibatch SGD)能赢?
- 时间效率:虽然绿球在动画里看起来在走弯路(抖动),但在现实世界中,红球计算 1 步的时间,绿球已经跑了 100 步了。
- 跳出陷阱:在 3D 的非凸地形中,全量梯度(红球)太“老实”,遇到小坑就停。而小批量的随机噪声(绿球)相当于给球加了一个“微小震动”,让它有机会跳过局部最优,找到全局最优。
全量梯度下降 (Batch GD) 的现实困境
| 困境维度 | 表现描述 | 产生的后果 |
|---|---|---|
| 内存溢出 (OOM) | 必须将整个数据集一次性载入内存或显存。 | 面对 TB 级别的数据,硬件成本将不可想象。 |
| 计算冗余 | 数据集中往往存在大量相似样本(如 100 万张猫的照片)。 | 为了算一个梯度去重复遍历相似数据,极其低效。 |
| 更新频率极低 | 只有遍历完所有数据后才能更新一次参数。 | 训练大型模型可能需要数小时才能看到一次进度。 |
| 陷阱困守 | 梯度路径过于“死板”,缺乏随机性。 | 极其容易卡在平滑的局部最小值或鞍点处。 |
并行计算特性对比
| 特性 | 单样本 SGD (Size=1) | Minibatch SGD (Size=32~256) | Batch GD (Size=All) |
|---|---|---|---|
| 并行度 | 极低,无法利用 GPU 优势 | 高,完美适配 GPU 架构 | 极高,但受限于显存容量 |
| 计算吞吐量 | 慢 (系统开销占比高) | 极快 (吞吐量与延迟的最佳平衡) | 慢 (数据搬运成本溢出) |
| 显存占用 | 极低 | 适中 | 极高 (容易导致 OOM) |
多个 Nvidia GPU 的协同作战
- 分发 (Broadcast):将相同的模型参数发送到所有 GPU 上。
- 计算 (Compute):
- 每块 GPU 获得一部分数据(子批次)。
- 各自执行前向传播(Forward)和反向传播(Backward)。
- 产出局部梯度 (Local Gradients)。
- 聚合 (All-Reduce):
- 核心通信环节。利用 Nvidia NCCL 库,所有 GPU 互相交换梯度。
- 最终每块 GPU 都拥有了全量数据的平均梯度。
- 同步 (Step):所有 GPU 根据相同的平均梯度更新权重,确保下一轮开始前模型依然一致。
AI 数据中心连接图
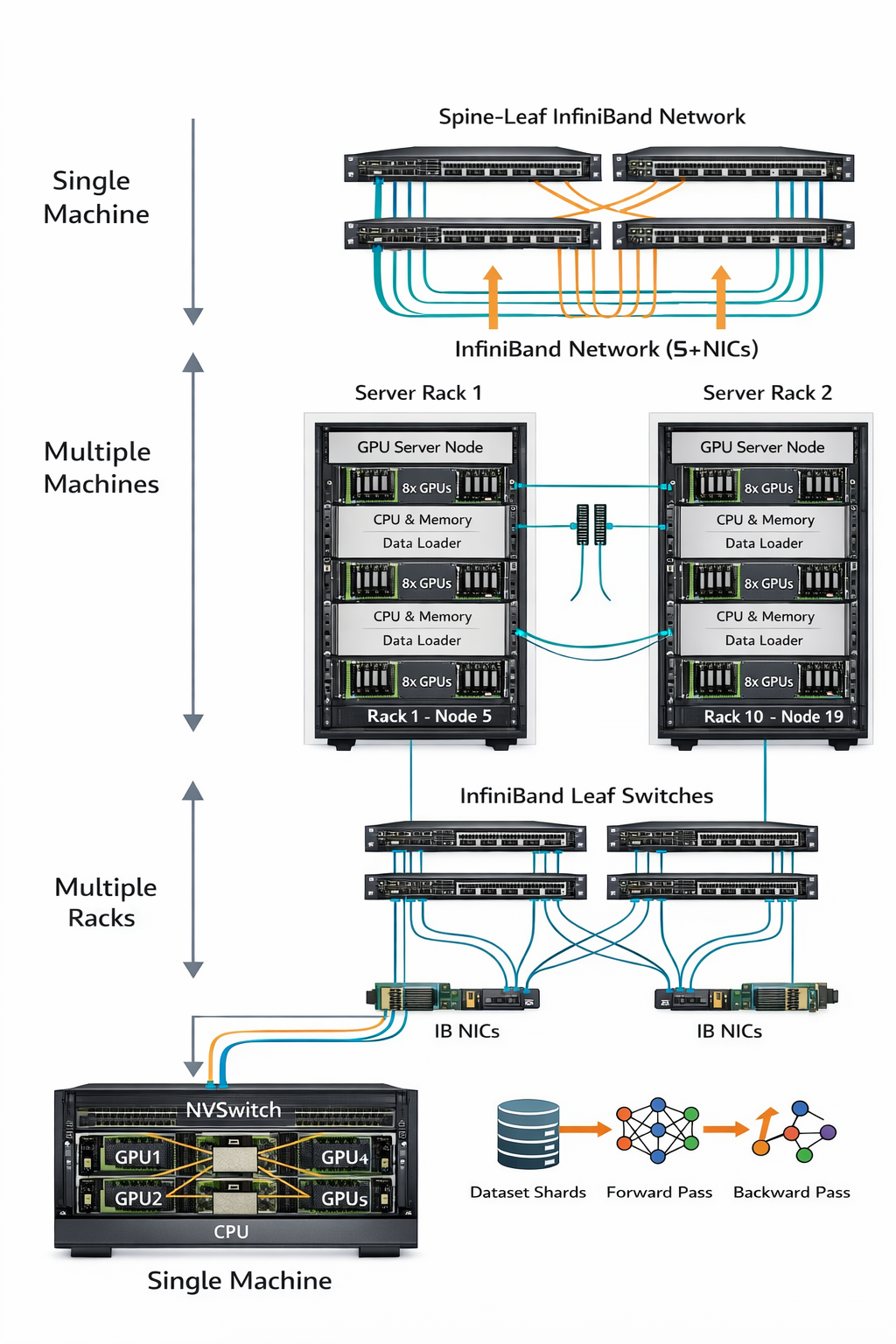
单机
┌───────────────────────┐
│ 单台服务器 │
│ │
│ GPU0 ── NVLink ── GPU1
│ │ ╲ ╱ │
│ │ ╲ ╱ │
│ GPU2 ── NVSwitch ── GPU3
│ │ ╱ ╲ │
│ │ ╱ ╲ │
│ GPU4 ── NVLink ── GPU5
│ │
│ │ │
│ PCIe │
│ │ │
│ CPU │
│ │ │
│ IB 网卡 │
└───────────────────────┘
| 通信路径 | 技术 | 特点 |
|---|---|---|
| GPU ↔ GPU | NVLink / NVSwitch | 极高带宽 |
| GPU ↔ CPU | PCIe | 中等带宽 |
| 服务器 ↔ 外部 | InfiniBand 网卡 | 跨机通信 |
多机(同一机架内)
┌─────────────── 机架 ───────────────┐
┌────────────┐ ┌────────────┐
│ 服务器 A │ │ 服务器 B │
│ (8 GPUs) │ │ (8 GPUs) │
└──────┬─────┘ └──────┬─────┘
│ │
│ InfiniBand │
└────────┬────────────┘
│
┌───────────┐
│ Leaf 交换机 │
└───────────┘
- 每台服务器通过 IB 网卡接入 Leaf 交换机
- 服务器之间通过 IB 交换机互联
- NCCL 在此层构建跨节点 Ring
多机架(数据中心级)
┌─────────────── Spine 交换机 ───────────────┐
│ │ │
┌───────┴───────┐ ┌───────┴───────┐ ┌───────┴───────┐
│ Rack 1 │ │ Rack 2 │ │ Rack 3 │
│ │ │ │ │ │
│ [Leaf] │ │ [Leaf] │ │ [Leaf] │
│ │ │ │ │ │ │ │ │
│ Servers... │ │ Servers... │ │ Servers... │
└───────────────┘ └───────────────┘ └───────────────┘
- Leaf 连接服务器
- Spine 连接各个 Leaf
- 实现全互联低阻塞网络
Vera Rubin
Vera Rubin 并不是“只是 GPU + 机箱”,而是一个完整的自家计算体系,包括 CPU、GPU、互联总线、网络、DPU 等核心部件基本由 NVIDIA 自己设计或主导整合。
在 AI 基础设施层面 NVIDIA 的角色从“芯片供应商”提升到了“完整系统方案供应商”
| 维度 | Blackwell / Grace Blackwell | Vera Rubin |
|---|---|---|
| GPU 性能 | 强大 | 更强(更高 PFLOPS) |
| CPU 性能 | 良好 | 更高(自研 Vera) |
| 内存 | HBM3e | HBM4(更高带宽) |
| 互联 | NVLink 旧版 | NVLink 6 / 更强互联 |
| 系统规模 | Rack 级别 | 整个平台级协同 |
| 性能 / 功效 | 优秀 | 更高、更节能 |
| 安全 & 平台能力 | 有限 | 机密计算集成更全面 |
矢量化加速
在训练我们的模型时,我们经常希望能够同时处理整个小批量的样本。 为了实现这一点,需要我们对计算进行矢量化, 从而利用线性代数库,而不是在Python中编写开销高昂的for循环。
import math
import numpy as np
import time
import torch
from d2l import torch as d2l
class Timer: #@save
"""记录多次运行时间。"""
def __init__(self):
self.times = []
self.start()
def start(self):
"""开始计时。"""
self.tik = time.time()
def stop(self):
"""停止计时并将时间记录在列表中。"""
self.times.append(time.time() - self.tik)
return self.times[-1]
def avg(self):
"""返回平均时间。"""
return sum(self.times) / len(self.times)
def sum(self):
"""返回时间总和。"""
return sum(self.times)
def cumsum(self):
"""返回时间的累积和。"""
return np.array(self.times).cumsum().tolist()
n = 10000
a = torch.ones(n)
b = torch.ones(n)
c = torch.zeros(n)
timer = Timer()
timer.start()
for i in range(n):
# c[i] = a[i] + b[i] # 逐元素计算,效率较低 平均时间: 0.05079 秒
c = a + b # 直接使用向量化操作,效率更高 平均时间: 0.05079 秒
timer.stop()
print(f'平均时间: {timer.avg():.5f} 秒')
对比cpu核心, cuda核心 和 Tensor核心的计算差异
| 计算单元 | 计算方式 | 并行模式 | 完成 4×4 矩阵乘需要 |
|---|---|---|---|
| CPU核心 (SIMD) | 向量寄存器并行计算 | SIMD | 需要多条向量指令 |
| CUDA Core | 每线程计算一个标量 | SIMT | 需要很多线程协作 |
| Tensor Core | 专用矩阵运算单元 | 矩阵硬件计算 | 1 条指令即可完成 |
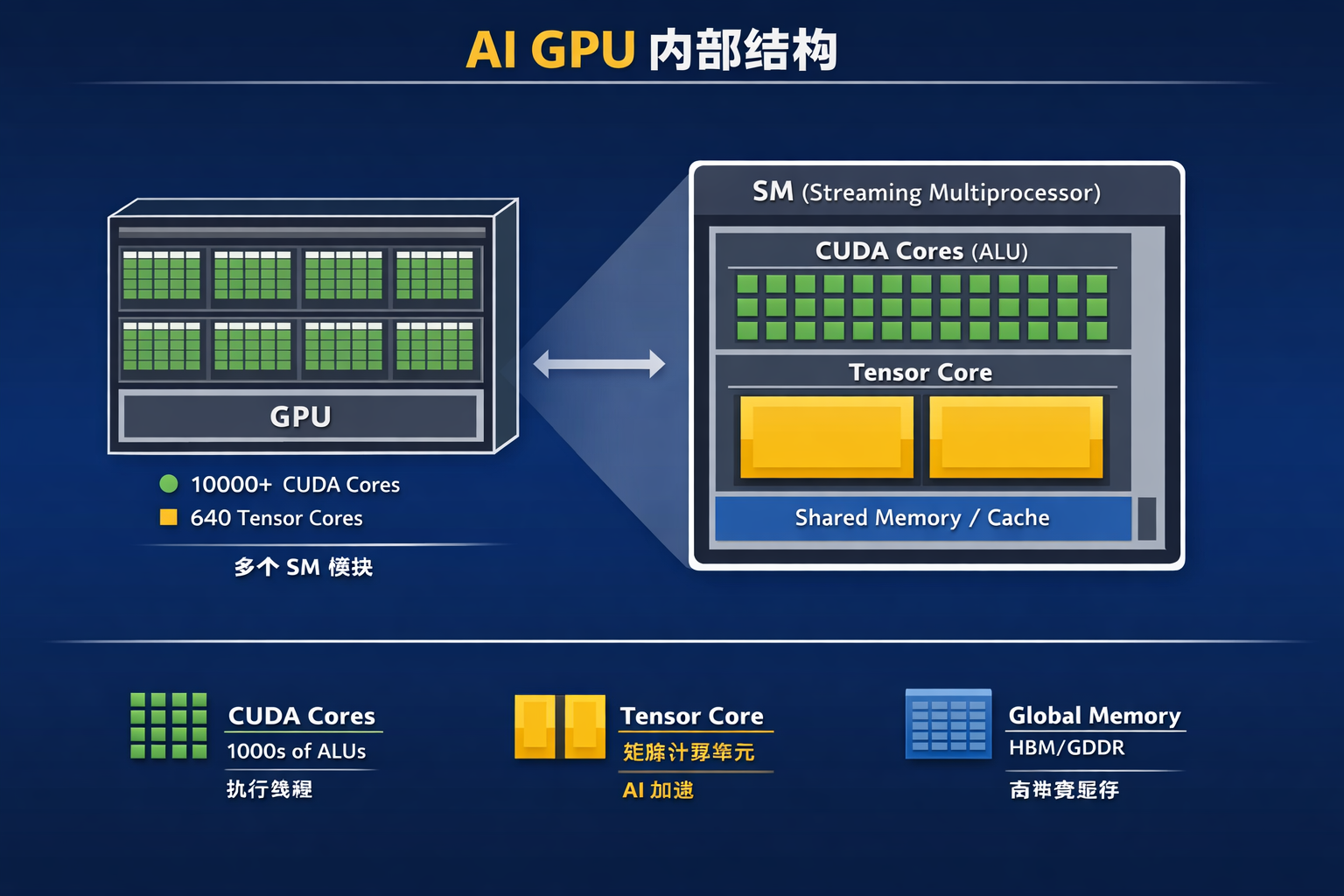
Tensor 核心(Tensor Core)是专为 AI 设计的“超级自动化设备”。它不再关注单个“砖块”(标量),而是直接处理一整块“预制墙板”(矩阵)。
- CUDA 核心:计算 $4 \times 4$ 矩阵乘法需要进行 64 次乘法和 48 次加法
- Tensor 核心:只需要一条指令,直接吞入两个 $4 \times 4$ 矩阵,吐出结果
正太分布和平方损失
正态分布(Normal Distribution),也常被称为高斯分布(Gaussian Distribution),是概率论和统计学中最重要的连续概率分布。
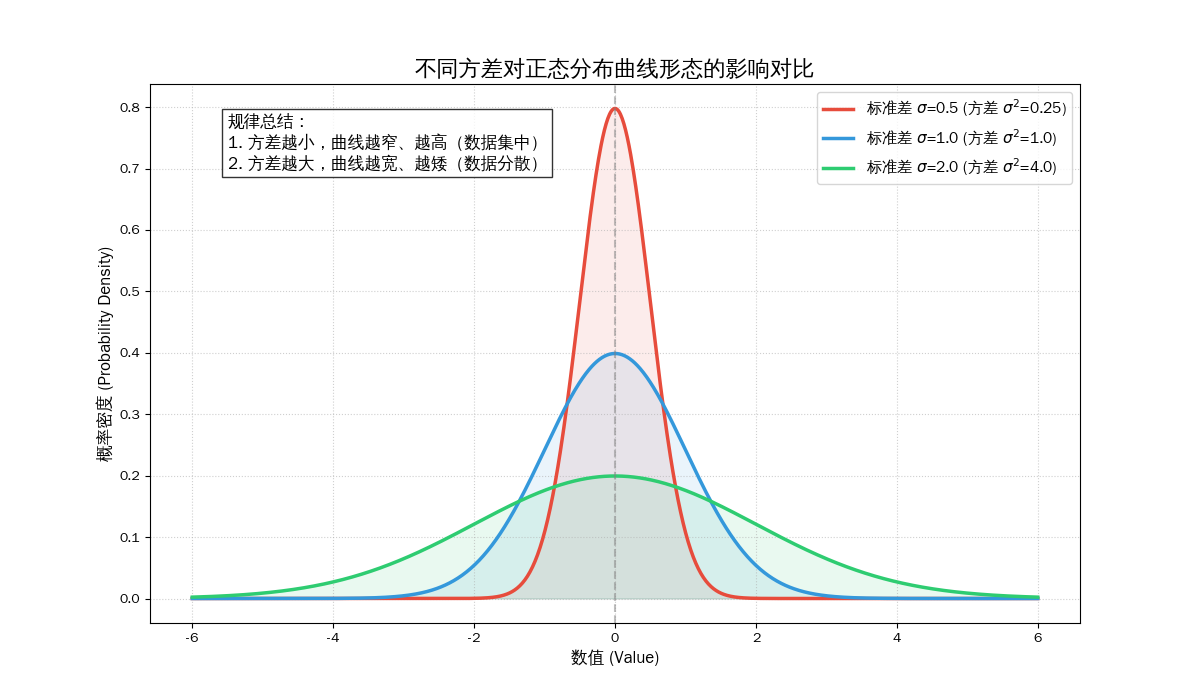
高斯分布(正态分布)不仅仅是一个数学公式,它更像是宇宙的一种“底层底层逻辑”。它揭示了在一个充满随机性和混乱的世界中,秩序是如何自动产生的。
- 高斯分布最直观的本质是:极端的个体总是少数,平庸的群体才是大多数。
宇宙在大尺度上是不喜欢“极端”的,它有一种向中心靠拢的强大惯性
- 中心极限定理:混乱中的秩序-整体的规律与个体的分布无关
虽然我们无法预测单个分子如何运动,但我们可以极其精确地预测由无数分子组成的空气压力。它是从微观混乱跨越到宏观秩序的“桥梁”。
- 最大熵与最小偏见: 在信息论中,高斯分布代表了在已知方差的情况下,不确定性最大的分布
在 AI 训练中,我们用高斯分布初始化参数,本质上就是承认我们对最优权重一无所知,给模型留下最大的探索空间,而不赋予它任何人为的倾向。
虽然世界在微观上是随机、碎片化且不可控的,但在宏观上,这种随机性会受到一种无形的统计力量的约束,最终汇聚成那条优美的、对称的钟形曲线。
从线性回归到深度网络
线性回归可以看作一个单层神经网络。在深度学习框架(例如 PyTorch 或 TensorFlow)中,它其实就是最简单的神经网络模型。
| 概念 | 线性回归 | 单层神经网络 |
|---|---|---|
| 输入 | 特征向量 x | 输入层 |
| 参数 | 权重 w、偏置 b | 权重 W、偏置 b |
| 计算公式 | y = wx + b | y = Wx + b |
| 结构 | 没有隐藏层 | 只有输出层 |
| 激活函数 | 没有 | 恒等函数 f(x)=x |
| 训练方法 | 最小二乘 / 梯度下降 | 反向传播 + 梯度下降 |
生物学
| 维度 | 生物神经网络(大脑) | AI 神经网络 |
|---|---|---|
| 基本单元 | 神经元 (Neuron) | 人工神经元 |
| 连接方式 | 突触 (Synapse) | 权重 (Weight) |
| 信号形式 | 电脉冲 + 化学信号 | 数值(浮点数) |
| 计算方式 | 脉冲触发 | 数学函数 |
| 学习机制 | 突触可塑性 | 梯度下降 + 反向传播 |
| 结构复杂度 | ≈860亿神经元 | 通常百万到万亿参数 |
| 并行性 | 极强 | 依赖硬件并行(GPU) |
| 能耗 | ≈20W | 训练模型可达数MW |
| 容错性 | 非常强 | 较弱 |
| 可解释性 | 几乎未知 | 数学可描述 |
如果说生物神经网络是“进化的奇迹”,追求的是在极低功耗下保证生存和繁衍;那么 AI 神经网络就是“工程的暴力美学”,追求的是在海量算力支撑下逼近数学上的最优解。
现代 AI(Transformer)其实已经和“神经网络”越来越不像了。
Transformer 足够简单(全是矩阵乘法)、足够暴力(支持大规模并行)、足够包容(什么数据都能吃)。它不再试图教计算机如何像人一样理解世界,而是让计算机用自己的数学逻辑,在海量数据中自发地构建出一套理解世界的坐标系。
AI 的回答 100% 是基于统计的。 它没有意识,没有灵魂,也没有对世界的真实体验。它只是通过海量的算力,把人类所有的文本变成了一个复杂的概率图谱。当你向它提问时,它就在这张图谱上顺着概率最高的路径,为你跑出一段文字。
目前解决AI 幻觉的方案
- RAG(检索增强生成):给 AI 配一本“开卷考试”的字典
将 AI 从“凭记忆考试”转变为“开卷考试”。既然是看着资料说话,胡说八道的概率就大大降低了
- RLHF(基于人类反馈的强化学习):找“老师”给 AI 批改作业
通过人类的价值观和事实标准,修正 AI 纯粹的统计概率。
- 多重 Agent 辩论:让 AI 自己“审稿”
模仿人类社会的“审稿制度”,利用模型自身的推理能力进行自我纠错(Self-Correction)。
- 知识图谱(Knowledge Graph)结合:给统计逻辑加上“硬约束”
用符号逻辑的确定性来修补神经网络的随机性
- 提示词工程(Prompt Engineering):明确边界
研究发现,当 AI 慢下来一步步推导时,它更容易发现自己逻辑中的漏洞。
anthropic 如何消除幻觉的
宪法人工智能 (Constitutional AI):给 AI 一本“道德准则”
宪法中明确规定了“诚实”和“不确定性”。如果模型不确定,宪法会引导它承认自己不知道,而不是强行预测概率。这从底层减少了统计学上的“瞎编”。
更加漫长的上下文窗口与注意力优化
当模型能够“看清”全场数据时,它就不需要靠“统计直觉”去猜中间的信息,从而降低了幻觉。
强调“元认知能力”:承认无知
这种“不确定就闭嘴”的策略,极大地提升了用户对它的信任度
独特的预训练配方:数据质量高于数量
数据清洗:他们对训练数据进行了极其严苛的过滤,剔除掉逻辑混乱、自相矛盾的低质内容