生成数据集
# 2024-03-05 15:00:00
# 这个脚本的目标:
# 用“已知真实参数”的方式,人工生成一份线性回归训练数据,
# 方便后续验证模型是否能把真实参数学回来。
import random
import torch
import matplotlib.pyplot as plt
from d2l import torch as d2l
plt.rcParams['font.sans-serif'] = [
'Noto Sans CJK SC', 'Source Han Sans SC', 'WenQuanYi Zen Hei',
'SimHei', 'Microsoft YaHei', 'PingFang SC', 'Heiti SC',
'Arial Unicode MS', 'DejaVu Sans'
]
plt.rcParams['axes.unicode_minus'] = False
# =========================
# 1) 生成模拟数据集
# =========================
# 线性回归的理想公式是:y = Xw + b
# 但真实世界通常会有测量误差,所以我们会再加一点随机噪声。
def synthetic_data(w, b, num_examples):
"""
生成线性回归用的模拟数据。
参数说明:
- w: 真实权重(例如 [2, -3.4])
- b: 真实偏置(一个标量)
- num_examples: 需要生成多少条样本
返回:
- X: 特征矩阵,形状是 (样本数, 特征数)
- y: 标签向量,形状是 (样本数, 1)
"""
# 第一步:生成输入特征 X
# torch.normal(0, 1, shape) 表示从均值0、标准差1的正态分布采样。
# 如果 w 有2个元素,说明每条样本有2个特征,所以 X 的列数是 len(w)。
X = torch.normal(0, 1, (num_examples, len(w)))
print("生成的特征 X 形状:", X.shape) # (num_examples, num_features)
print("前5条特征:\n", X[:5])
# 第二步:按线性关系计算“理想标签” y = Xw + b
# torch.matmul(X, w) 会做矩阵乘法:
# - X 形状: (num_examples, num_features)
# - w 形状: (num_features,)
# 结果是 (num_examples,)
y = torch.matmul(X, w) + b
print("计算的理想标签 y 形状:", y.shape) # (num_examples,)
print("前5条理想标签:\n", y[:5])
# 第三步:加入少量噪声,模拟真实数据的不完美性
# 噪声标准差设为 0.01,表示波动很小。
y += torch.normal(0, 0.01, y.shape)
print("加入噪声后的标签 y 形状:", y.shape) # (num_examples,)
print("前5条带噪声的标签:\n", y[:5])
# 最后把 y 变成二维列向量,便于后续训练代码统一处理。
# reshape((-1, 1)) 中:-1 表示“自动推断行数”,1 表示“单列”。
return X, y.reshape((-1, 1))
# =========================
# 2) 设置真实参数(地面真值)
# =========================
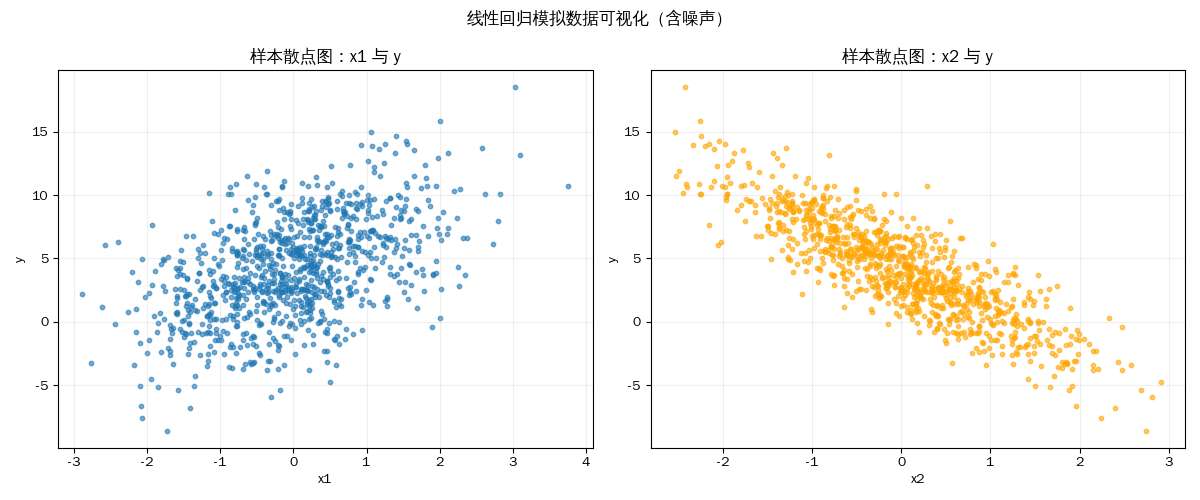
# 这里我们假设真实的线性关系是:y = 2*x1 - 3.4*x2 + 4.2 + 噪声
true_w = torch.tensor([2, -3.4])
# 真实的偏置(截距)
true_b = 4.2
# 生成 1000 条样本数据
features, labels = synthetic_data(true_w, true_b, 1000)
print("前5条特征:\n", features[:5])
print("前5条标签:\n", labels[:5])
# =========================
# 3) 可视化样本数据
# =========================
# 由于有两个特征(x1、x2),这里用两个散点子图分别看:
# - 左图:x1 与 y 的关系
# - 右图:x2 与 y 的关系
x1 = features[:, 0].detach().numpy()
x2 = features[:, 1].detach().numpy()
y = labels[:, 0].detach().numpy()
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
axes[0].scatter(x1, y, s=10, alpha=0.6)
axes[0].set_xlabel('x1')
axes[0].set_ylabel('y')
axes[0].set_title('样本散点图:x1 与 y')
axes[0].grid(alpha=0.2)
axes[1].scatter(x2, y, s=10, alpha=0.6, color='orange')
axes[1].set_xlabel('x2')
axes[1].set_ylabel('y')
axes[1].set_title('样本散点图:x2 与 y')
axes[1].grid(alpha=0.2)
plt.suptitle('线性回归模拟数据可视化(含噪声)')
plt.tight_layout()
plt.show()
读取数据集
# =========================
# 4) 定义一个小批量数据迭代器
# =========================
# batch_size 是每次训练时拿多少条数据来计算梯度和更新参数。
# features 是所有的输入特征,labels 是对应的标签。
def data_iter(batch_size, features, labels):
"""一个生成小批量数据的迭代器"""
# 先计算总共有多少条数据,然后生成一个打乱顺序的索引列表。
num_examples = len(features)
print("总样本数:", num_examples)
# 生成一个从0到num_examples-1的索引列表,并打乱它的顺序。
indices = list(range(num_examples))
random.shuffle(indices) # 打乱索引顺序
# 每次返回 batch_size 条数据,直到所有数据都被遍历完
for i in range(0, num_examples, batch_size):
# 通过索引列表获取当前批次的索引,然后用这些索引从 features 和 labels 中取出对应的数据。
batch_indices = torch.tensor(
indices[i: min(i + batch_size, num_examples)]
)
print(f"正在生成第 {i // batch_size + 1} 批数据,索引范围: {batch_indices[0].item()} - {batch_indices[-1].item()}")
# yield 语句会返回一个小批量的数据(特征和标签),并在下一次调用时继续从上次停下的地方执行。
yield features[batch_indices], labels[batch_indices]
batch_size = 10
for X_batch, y_batch in data_iter(batch_size, features, labels):
print("一个小批量的特征 X_batch 形状:", X_batch)
print("一个小批量的标签 y_batch 形状:", y_batch)
# break # 这里只看第一个小批量,后续训练代码会继续使用这个迭代器
拆分成小批量数据集
训练数据
features: [x1 x2 x3 x4 x5 x6 x7 x8 x9 x10]
labels: [y1 y2 y3 y4 y5 y6 y7 y8 y9 y10]
│
▼
生成索引
[0 1 2 3 4 5 6 7 8 9]
│
▼
打乱
[3 7 1 9 0 6 5 2 8 4]
│
▼
分批
Batch1 → [3 7 1 9]
Batch2 → [0 6 5 2]
Batch3 → [8 4]
│
▼
每次 yield 给模型训练
初始化模型参数
# =========================
# 5) 初始化模型参数(随机初始化)
# 这里我们用 torch.normal 从均值0、标准差0.01的正态分布中随机采样来初始化权重 w,偏置 b 则初始化为0。
w = torch.normal(0, 0.01, size=(2, 1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
| 参数 | 含义 |
|---|---|
| 0 | 均值 |
| 0.01 | 标准差 |
| size=(2,1) | 矩阵大小 |
| requires_grad=True | 允许自动求导 |
定义模型
# 定义模型
def linreg(X, w, b):
"""线性回归模型"""
return torch.matmul(X, w) + b
定义损失函数
# 定义损失函数(均方误差)
def squared_loss(y_hat, y):
"""均方误差损失函数"""
# y_hat 是模型的预测值,y 是真实标签。我们计算它们之间的差值,平方后除以2(这是为了在求导时更简洁)。
# reshape(y_hat.shape) 是为了确保 y 的形状和 y_hat 一致,避免广播机制带来的问题。
return (y_hat - y.reshape(y_hat.shape)) ** 2 / 2
定义优化算法
# 定义优化算法(小批量随机梯度下降)
# params 是一个列表,包含了我们需要更新的参数(在这里是 w 和 b)。lr 是学习率,batch_size 是每个小批量的大小。
def sgd(params, lr, batch_size):
"""小批量随机梯度下降"""
with torch.no_grad(): # 在更新参数时不需要计算梯度
# 对于每个参数,我们根据它的梯度来更新它的值。梯度是通过反向传播计算得到的,表示损失函数对于该参数的敏感程度。
for param in params:
# 更新参数:新值 = 旧值 - 学习率 * 梯度 / 批量大小
param -= lr * param.grad / batch_size # 更新参数
param.grad.zero_() # 清零梯度,为下一轮计算做准备
训练
lr = 0.03 # 学习率
num_epochs = 3 # 训练轮数
net = linreg # 模型
loss = squared_loss # 损失函数
for epoch in range(num_epochs):
# 一个 epoch = 把整个训练集完整看一遍
for X_batch, y_batch in data_iter(batch_size, features, labels):
# 1) 前向计算:模型给出预测值
# 2) 计算损失:预测与真实值差多少
l = loss(net(X_batch, w, b), y_batch)
# 3) 反向传播:根据损失自动计算 w、b 的梯度
l.sum().backward()
# 4) 用梯度下降更新参数
sgd([w, b], lr, batch_size)
with torch.no_grad():
# 每个 epoch 结束后,用全部训练数据评估一次平均损失
train_l = loss(net(features, w, b), labels)
print(f'epoch {epoch + 1}, loss {float(train_l.mean()):f}')
print("训练完成!")
print("学到的权重 w:", w)
print("学到的偏置 b:", b)
print("真实的权重 w:", true_w)
print("真实的偏置 b:", true_b)
2D 动画显示模型训练过程
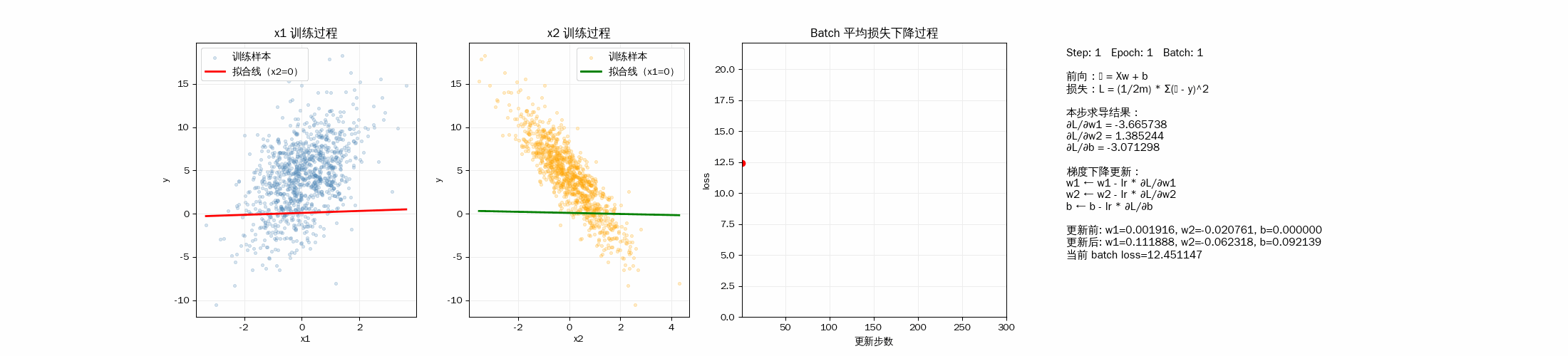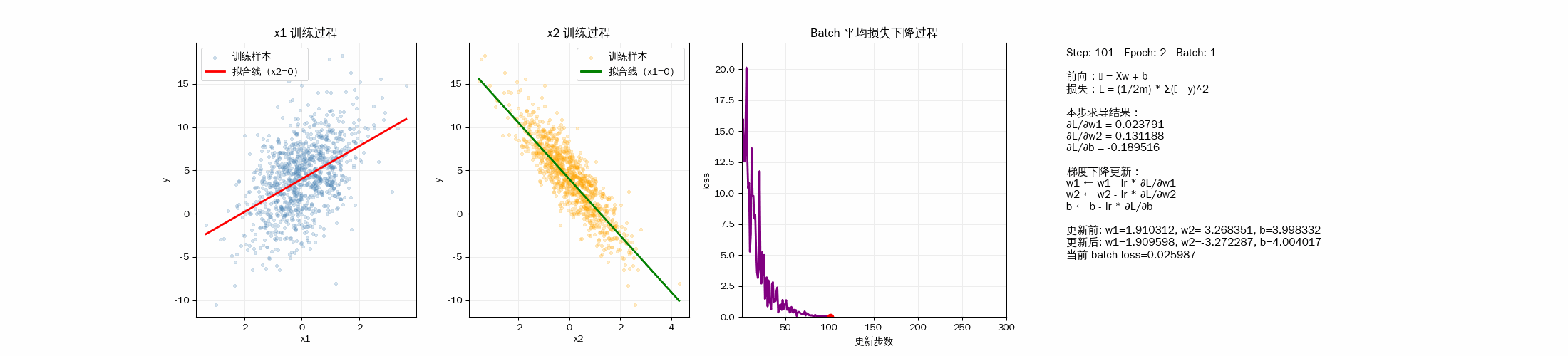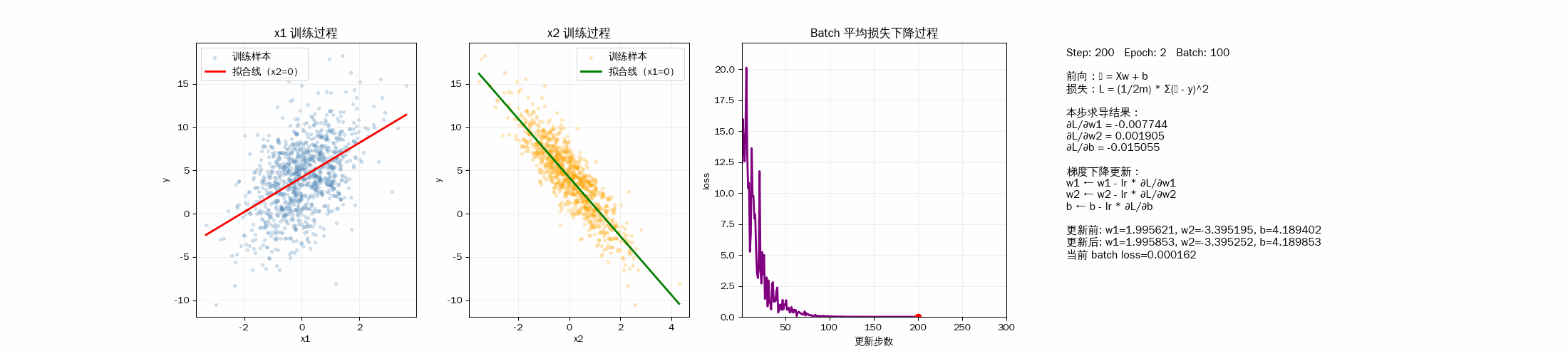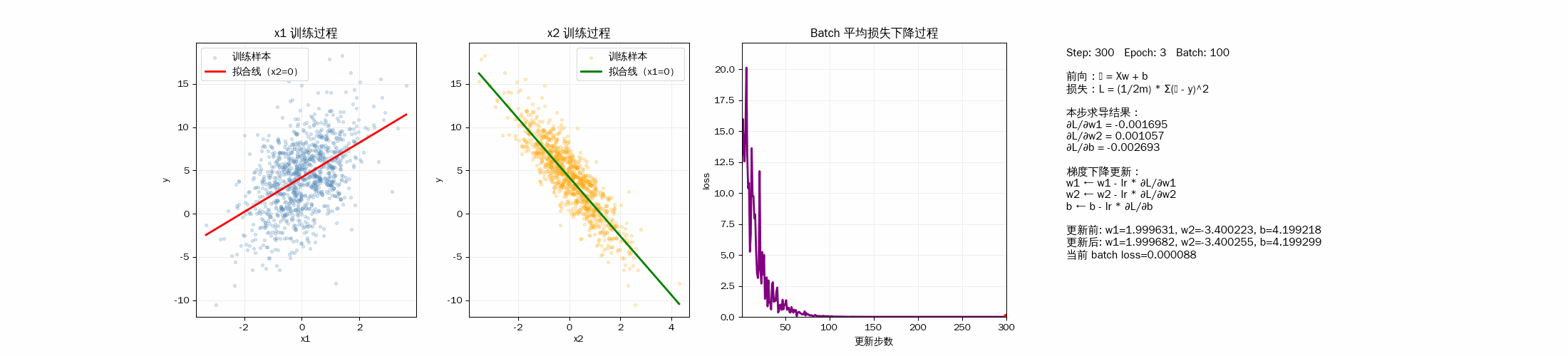
3D 动画显示样品拟合过程
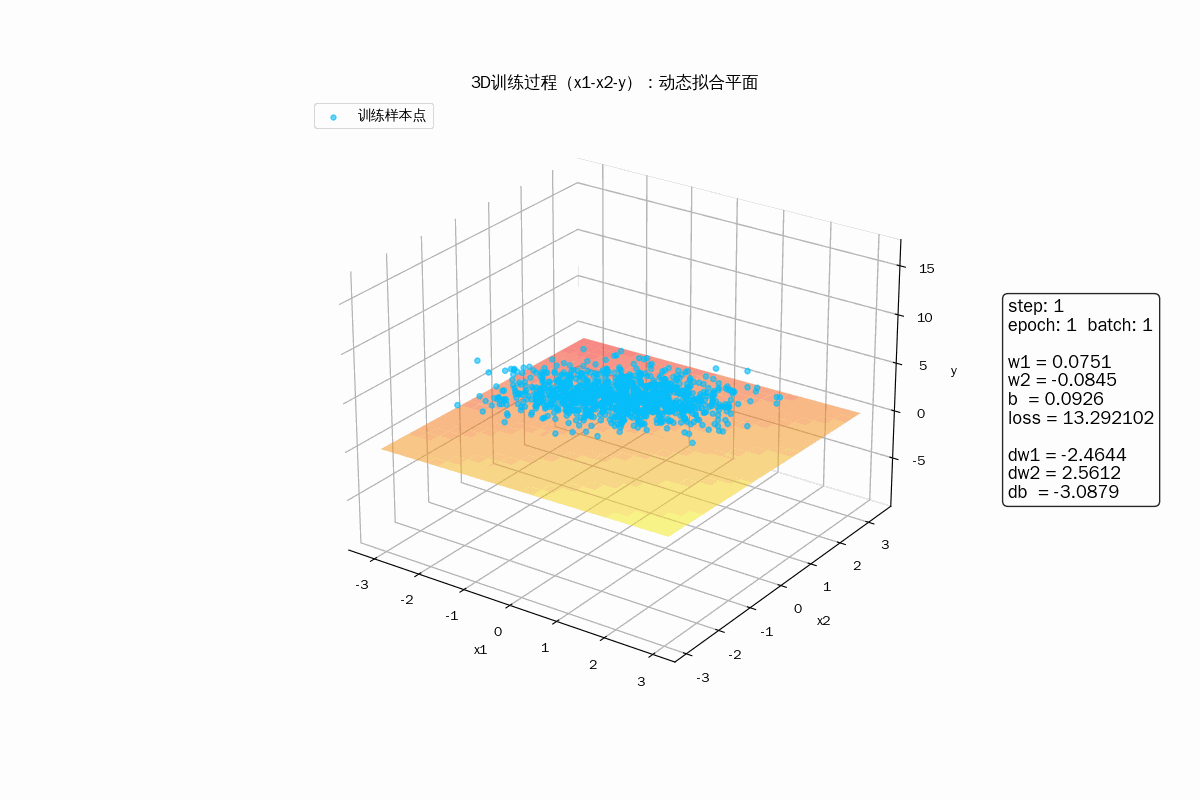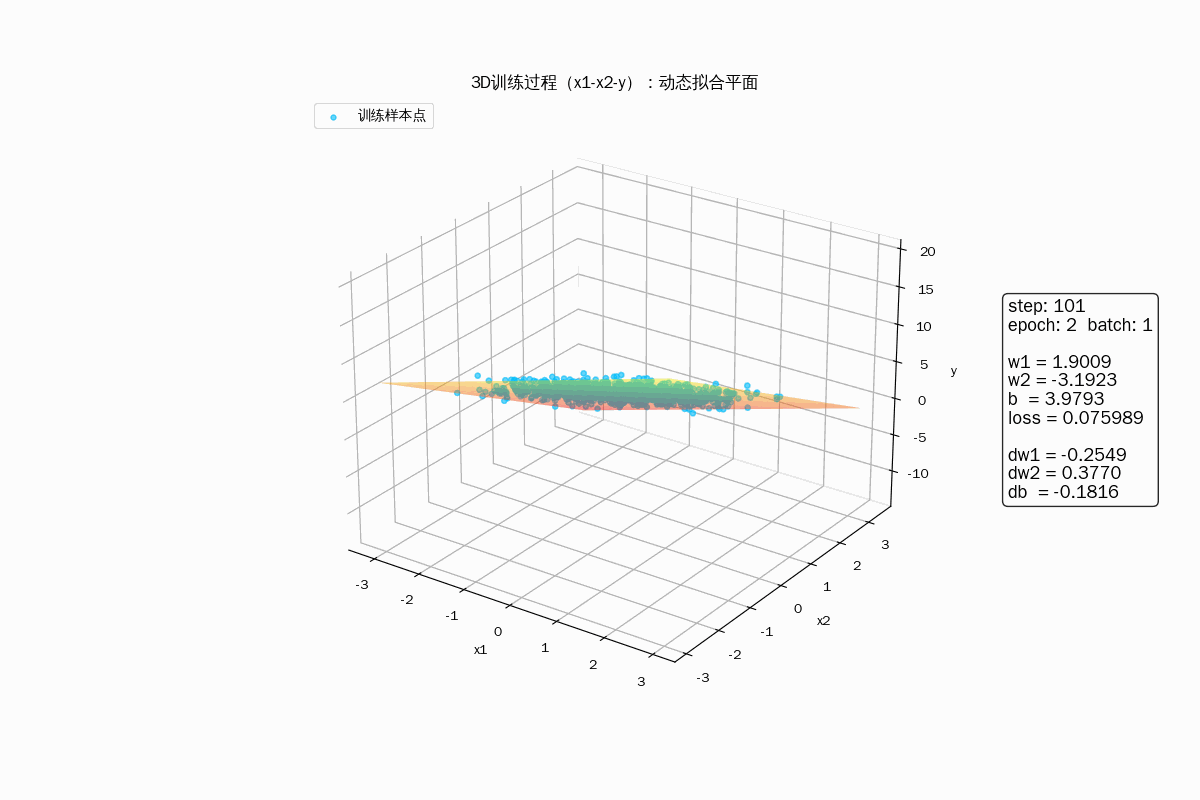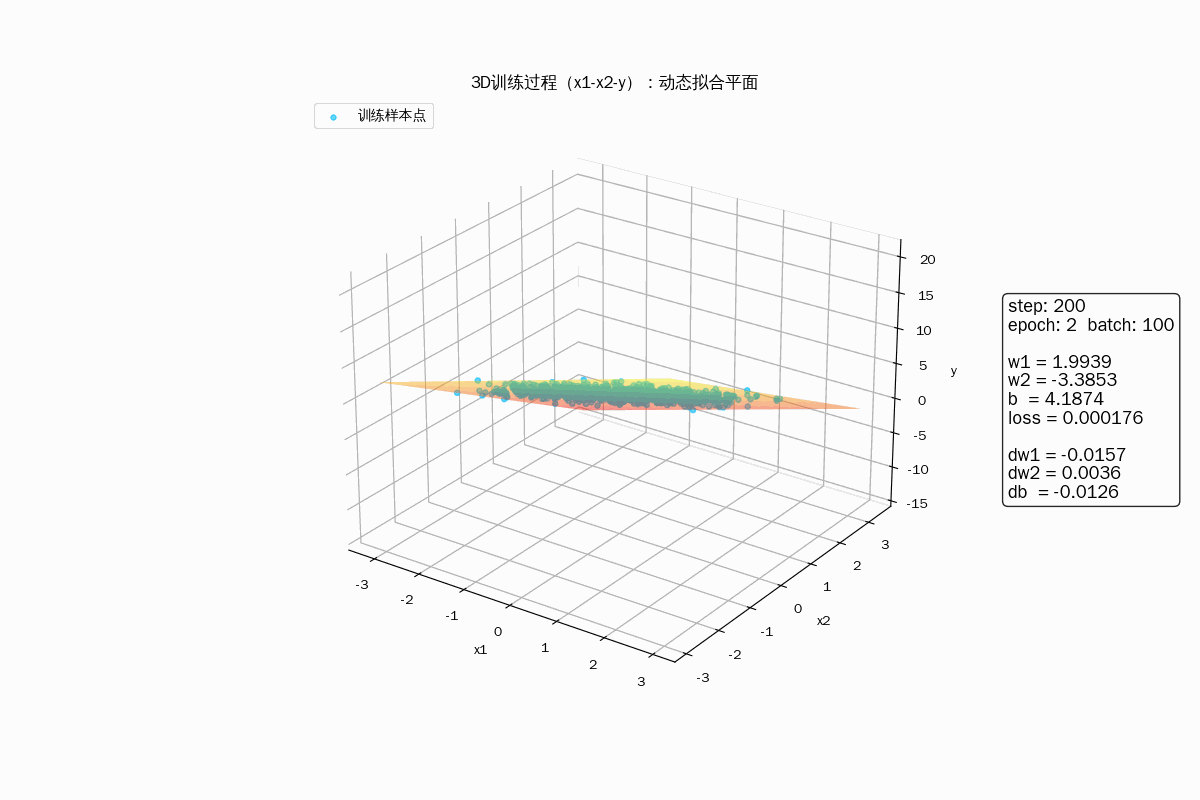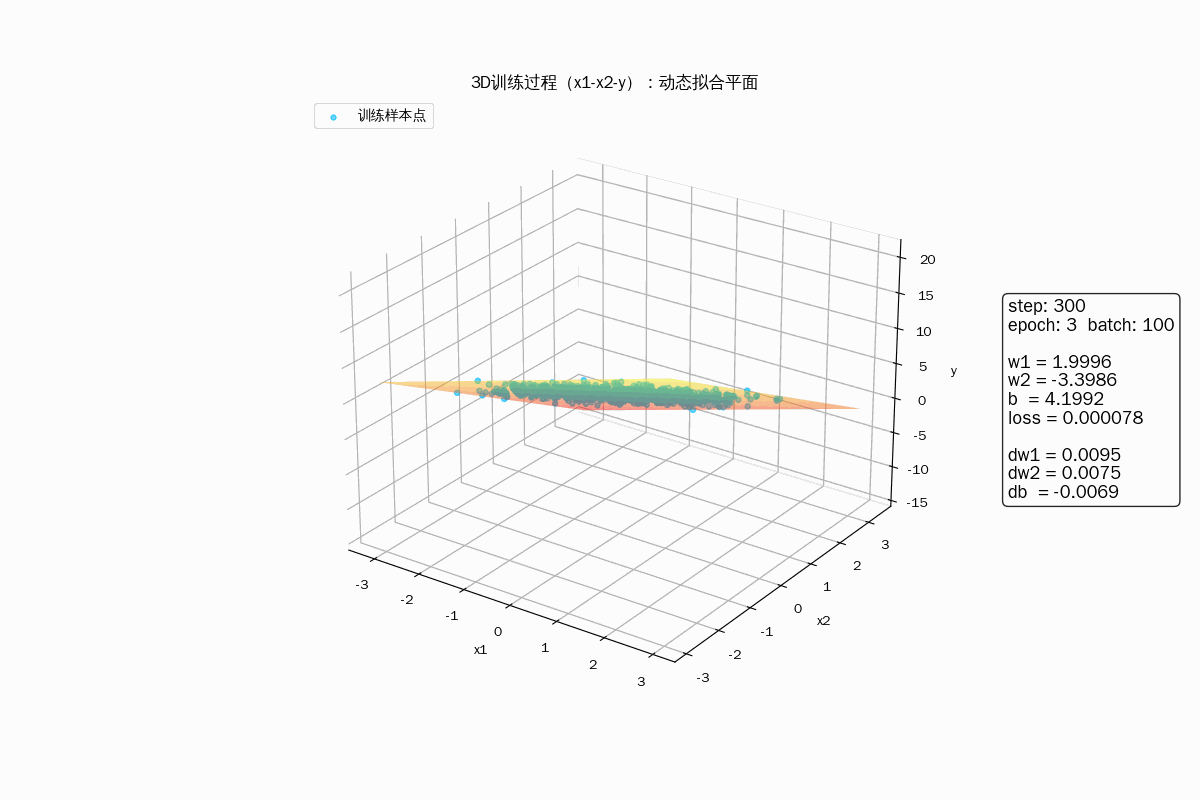
3D动画显示梯度下降过程
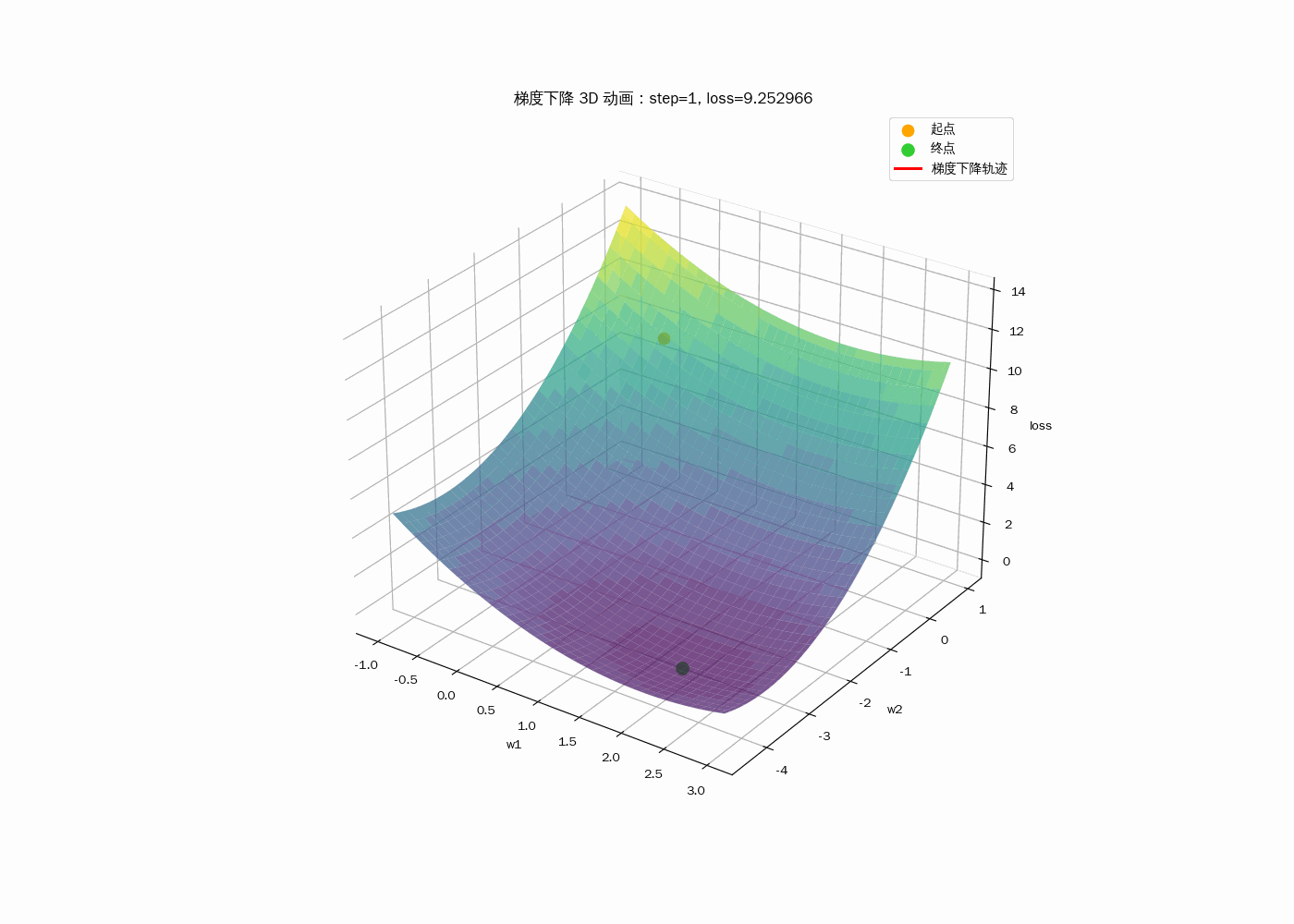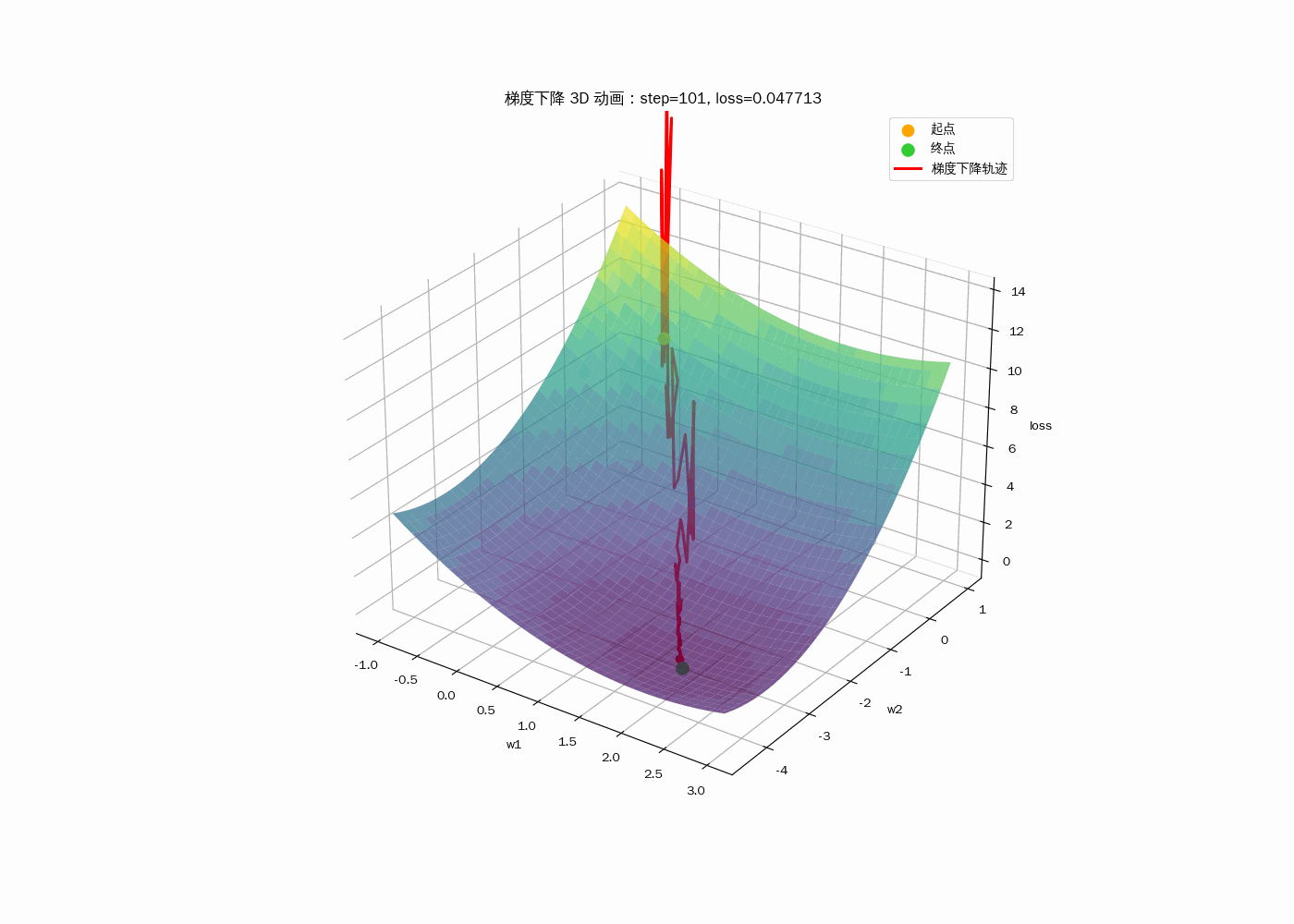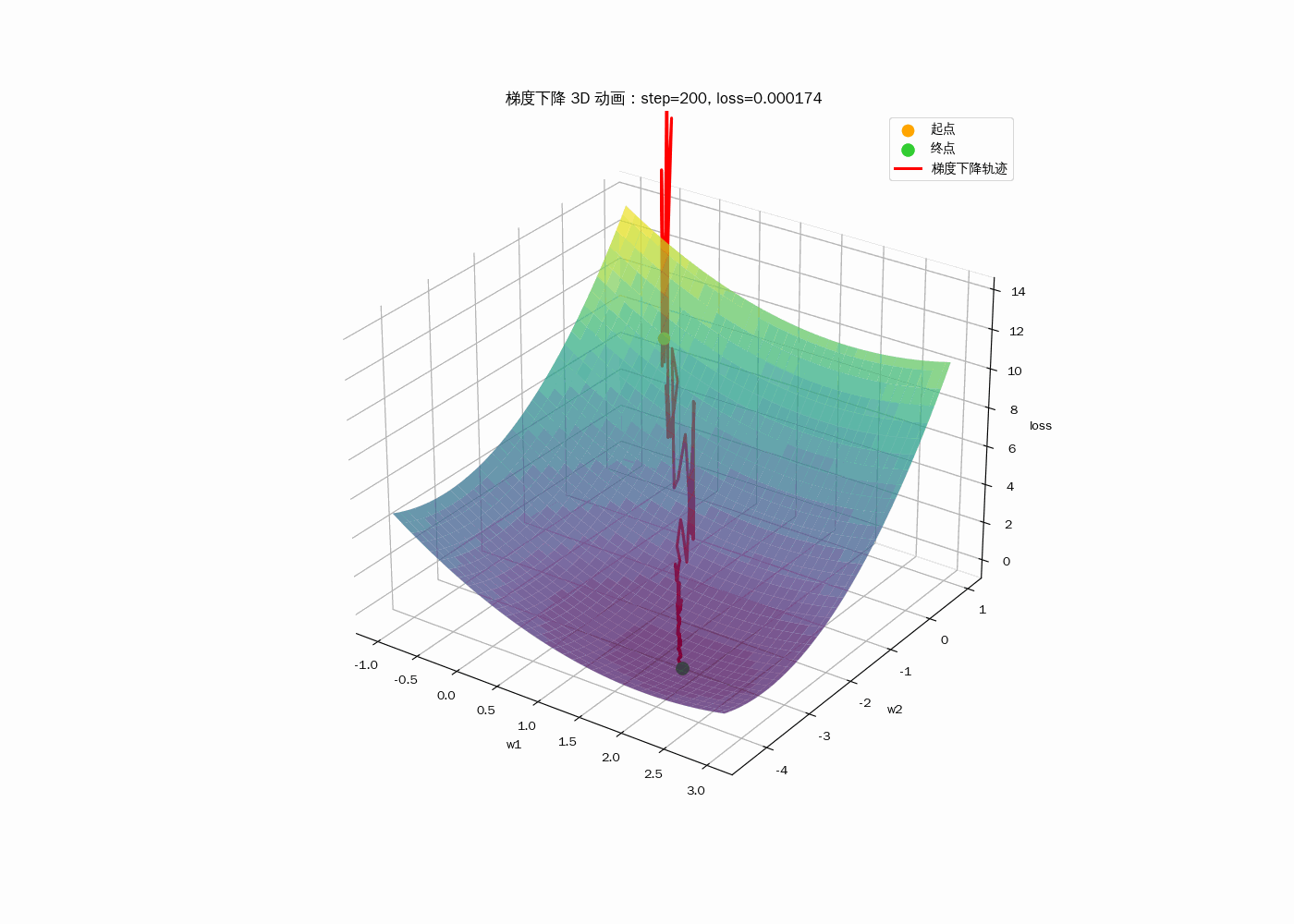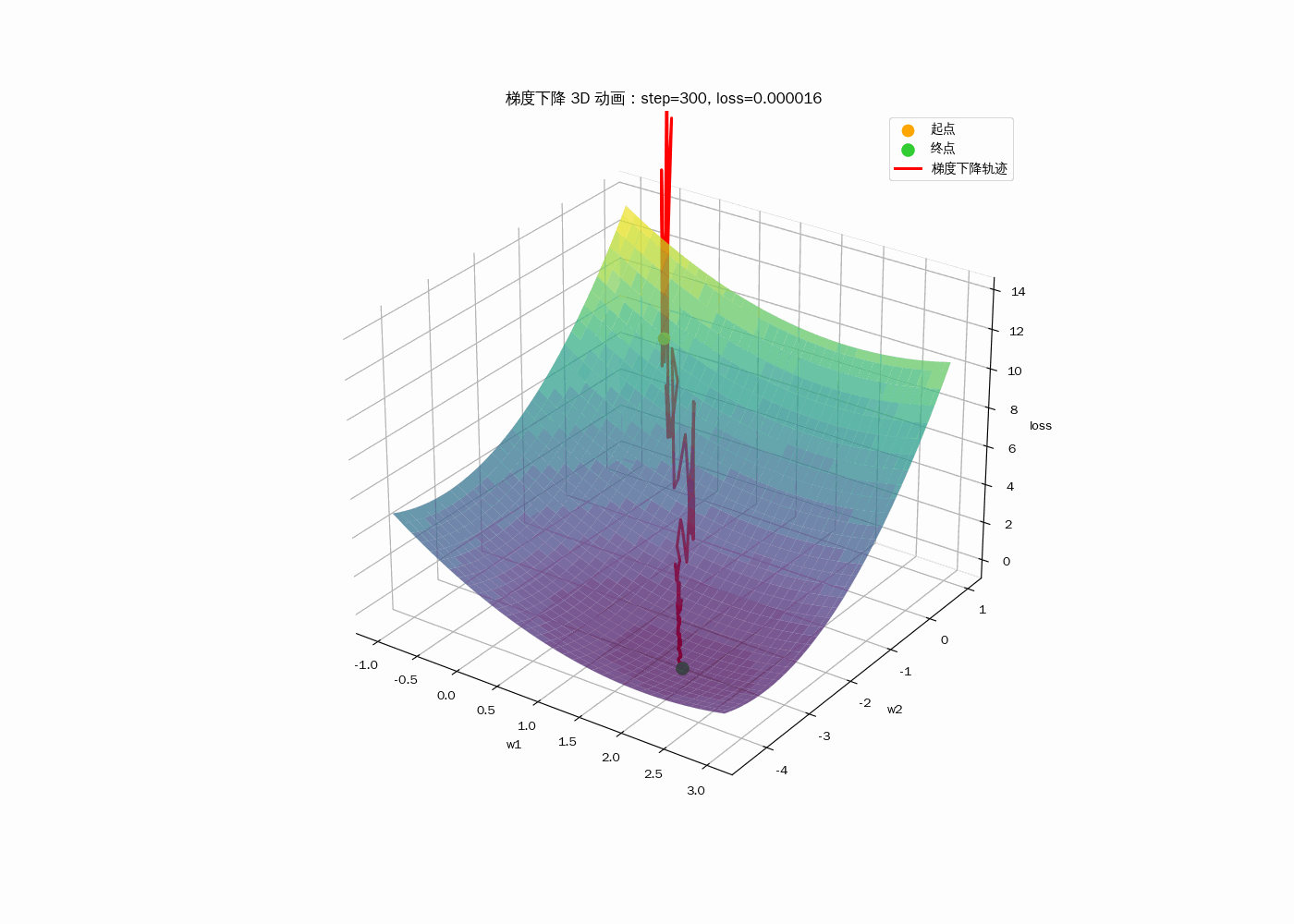
线性回归的简单实现
- 可以使用PyTorch的高级API更简洁地实现模型。
- 在PyTorch中,data模块提供了数据处理工具,nn模块定义了大量的神经网络层和常见损失函数。
import numpy as np
import torch
from torch import nn
from torch.utils import data
from d2l import torch as d2l
# =========================
# 1. 生成一份“可控”的线性回归样本数据
# =========================
# 真实参数(我们预先设定好),后面训练出的参数应该尽量接近它们。
true_w = torch.tensor([2, -3.4])
true_b = 4.2
# synthetic_data 会按照 y = Xw + b + 噪声 生成数据:
# - features: 形状 (1000, 2),表示 1000 条样本、每条样本 2 个特征
# - labels: 形状 (1000, 1),对应每条样本的标签
features, labels = d2l.synthetic_data(true_w, true_b, 1000)
# 打印第一条样本,直观看看数据格式。
print('features:', features[0], '\nlabel:', labels[0])
def load_array(data_arrays, batch_size, is_train=True):
"""构造一个PyTorch数据迭代器"""
# TensorDataset 会把多个张量按样本维度“打包”在一起。
# 这里 data_arrays 是 (features, labels)。
dataset = data.TensorDataset(*data_arrays)
# DataLoader 负责按 batch 取数据:
# - batch_size: 每个小批量的样本数
# - shuffle: 训练时通常打乱样本,提高随机性
return data.DataLoader(dataset, batch_size, shuffle=is_train)
# =========================
# 2. 构建小批量数据迭代器
# =========================
batch_size = 10
data_iter = load_array((features, labels), batch_size)
# =========================
# 3. 定义模型(单层线性网络)
# =========================
# 等价于 y_hat = XW^T + b,其中输入维度 2,输出维度 1。
net = nn.Sequential(nn.Linear(2, 1))
# 手动初始化参数:
# - 权重用均值 0、标准差 0.01 的正态分布初始化
# - 偏置初始化为 0
net[0].weight.data.normal_(0, 0.01)
net[0].bias.data.fill_(0)
# =========================
# 4. 定义损失函数与优化器
# =========================
# MSELoss: 均方误差,线性回归的常用损失。
loss = nn.MSELoss()
# SGD: 随机梯度下降,学习率设为 0.03。
trainer = torch.optim.SGD(net.parameters(), lr=0.03)
# =========================
# 5. 训练模型
# =========================
num_epochs = 3
for epoch in range(num_epochs):
# 每轮(epoch)会遍历全部小批量数据
for X, y in data_iter:
# 前向计算预测值,然后计算当前 batch 的损失。
# y.view(-1, 1) 用于把标签整理成 (batch_size, 1),与输出形状对齐。
l = loss(net(X), y.view(-1, 1))
# 梯度清零 -> 反向传播 -> 参数更新(标准训练三步)
trainer.zero_grad()
l.backward()
trainer.step()
# 在完整训练集上评估当前 epoch 的损失,仅用于监控,不参与梯度计算。
with torch.no_grad():
train_l = loss(net(features), labels.view(-1, 1))
print(f'epoch {epoch + 1}, loss {float(train_l):f}')
# =========================
# 6. 查看训练后的参数
# =========================
# 如果训练正常,w 和 b 应该接近 true_w、true_b。
w = net[0].weight.data
print('w:', w)
b = net[0].bias.data
print('b:', b)
超平面
增加一个x3 是否就是曲面了
\[y = w_1x_1 + w_2x_2 + w_3x_3 + b\]几何本质:每一个特征 $x_i$ 的次数都是 1 次。这意味着 $y$ 随着任何一个 $x$ 的变化速度(斜率)都是恒定的。
维度提升:
- 1 个特征 ($x_1$):是一条线。
- 2 个特征 ($x_1, x_2$):是一个面(你脚本里的 3D 平面)。
- 3 个特征 ($x_1, x_2, x_3$):是一个超平面(Hyperplane)。虽然我们的大脑很难想象四维空间,但在数学上,它依然是“直”的,没有任何弯曲。
多项式回归问题
要拟合这个函数 $y = w_1x_1^2 + w_2x_2 + b$,我们进入了三维空间(两个输入,一个输出)。这个函数在几何上是一个抛物面(Paraboloid)。
import torch
from torch import nn
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.animation import FuncAnimation
# 下面两行用于解决中文显示问题:
# - font.sans-serif:给 matplotlib 一组可用中文字体(按顺序尝试)
# - axes.unicode_minus=False:防止坐标轴负号显示成方块
plt.rcParams['font.sans-serif'] = [
'Noto Sans CJK SC', 'Source Han Sans SC', 'WenQuanYi Zen Hei',
'SimHei', 'Microsoft YaHei', 'PingFang SC', 'Heiti SC',
'Arial Unicode MS', 'DejaVu Sans'
]
plt.rcParams['axes.unicode_minus'] = False
# =========================
# 1. 生成 3D 抛物面数据
# =========================
# 目标:y = 1.0 * x1^2 + 0.5 * x2 + 2.0
x_range = np.linspace(-2, 2, 20)
x1_grid, x2_grid = np.meshgrid(x_range, x_range)
# 转为列向量以供模型使用
x1_flat = x1_grid.flatten().reshape(-1, 1)
x2_flat = x2_grid.flatten().reshape(-1, 1)
X_np = np.hstack([x1_flat, x2_flat])
# 真实标签
Y_np = 1.0 * (x1_flat**2) + 0.5 * x2_flat + 2.0 + np.random.normal(0, 0.1, x1_flat.shape)
X = torch.tensor(X_np, dtype=torch.float32)
Y = torch.tensor(Y_np, dtype=torch.float32)
# =========================
# 2. 定义双层神经网络
# =========================
# 输入是 2 维 (x1, x2),隐藏层用 50 个神经元来拼凑复杂的曲面
model = nn.Sequential(
nn.Linear(2, 50),
nn.ReLU(),
nn.Linear(50, 1)
)
optimizer = torch.optim.Adam(model.parameters(), lr=0.02)
criterion = nn.MSELoss()
# =========================
# 3. 设置 3D 动画画布
# =========================
fig = plt.figure(figsize=(12, 8))
ax = fig.add_subplot(111, projection='3d')
def update(frame):
ax.clear()
# 梯度下降步骤
optimizer.zero_grad()
pred = model(X)
loss = criterion(pred, Y)
loss.backward()
optimizer.step()
# 绘图:原始数据点(蓝色散点)
ax.scatter(x1_flat, x2_flat, Y_np, color='royalblue', alpha=0.3, s=10)
# 绘图:AI 学习到的曲面(红色网格)
# 将预测结果重新变回网格形状
Z_pred = pred.detach().numpy().reshape(x1_grid.shape)
surf = ax.plot_surface(x1_grid, x2_grid, Z_pred, cmap='autumn', alpha=0.6, antialiased=True)
ax.set_zlim(0, 8)
ax.set_title(f"Epoch {frame}: AI 正在把平面折成抛物面\nLoss: {loss.item():.4f}")
ax.set_xlabel('x1')
ax.set_ylabel('x2')
ax.set_zlabel('y')
return surf,
# =========================
# 4. 启动动画
# =========================
ani = FuncAnimation(fig, update, frames=100, interval=50, repeat=False)
plt.show()
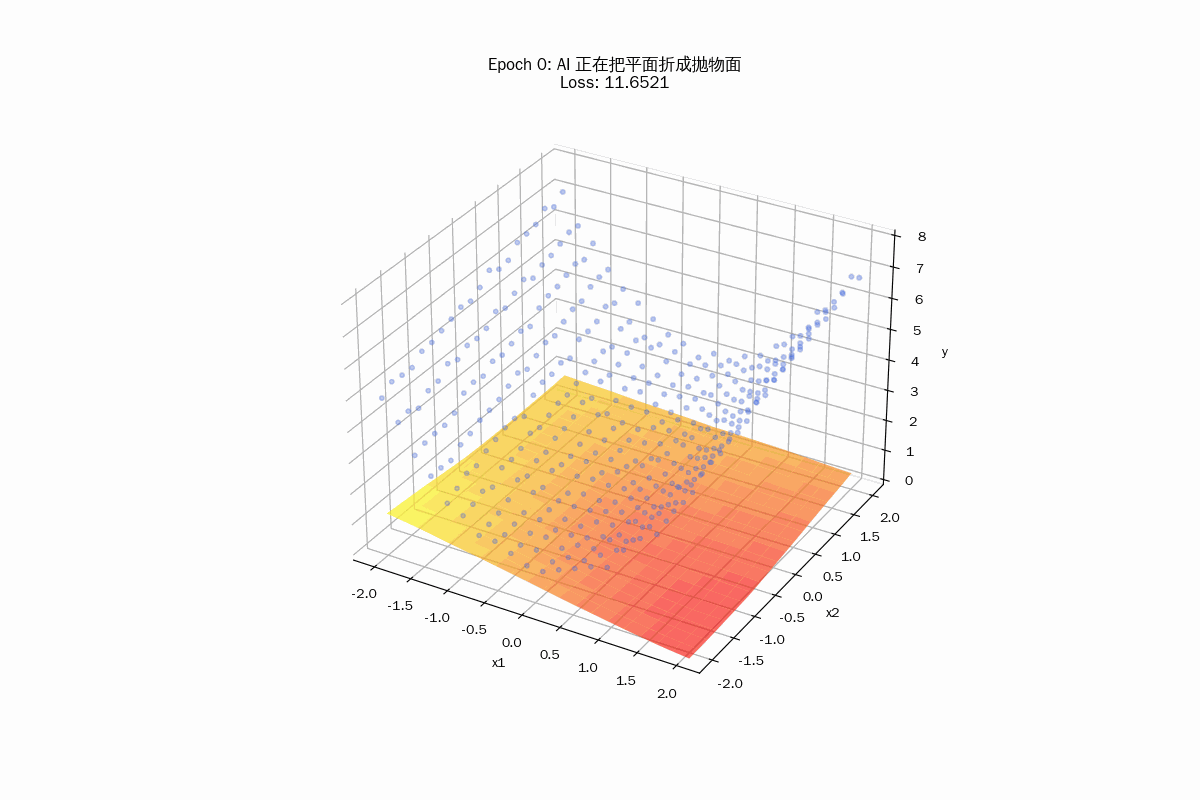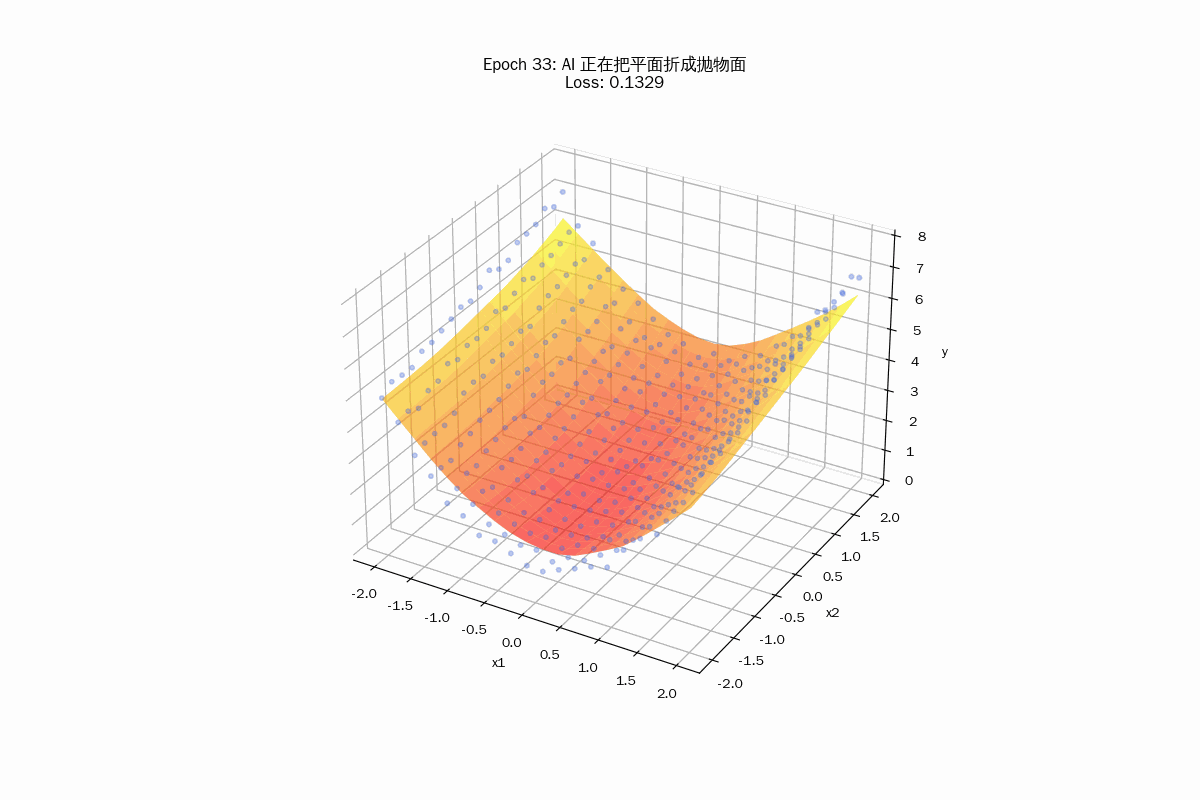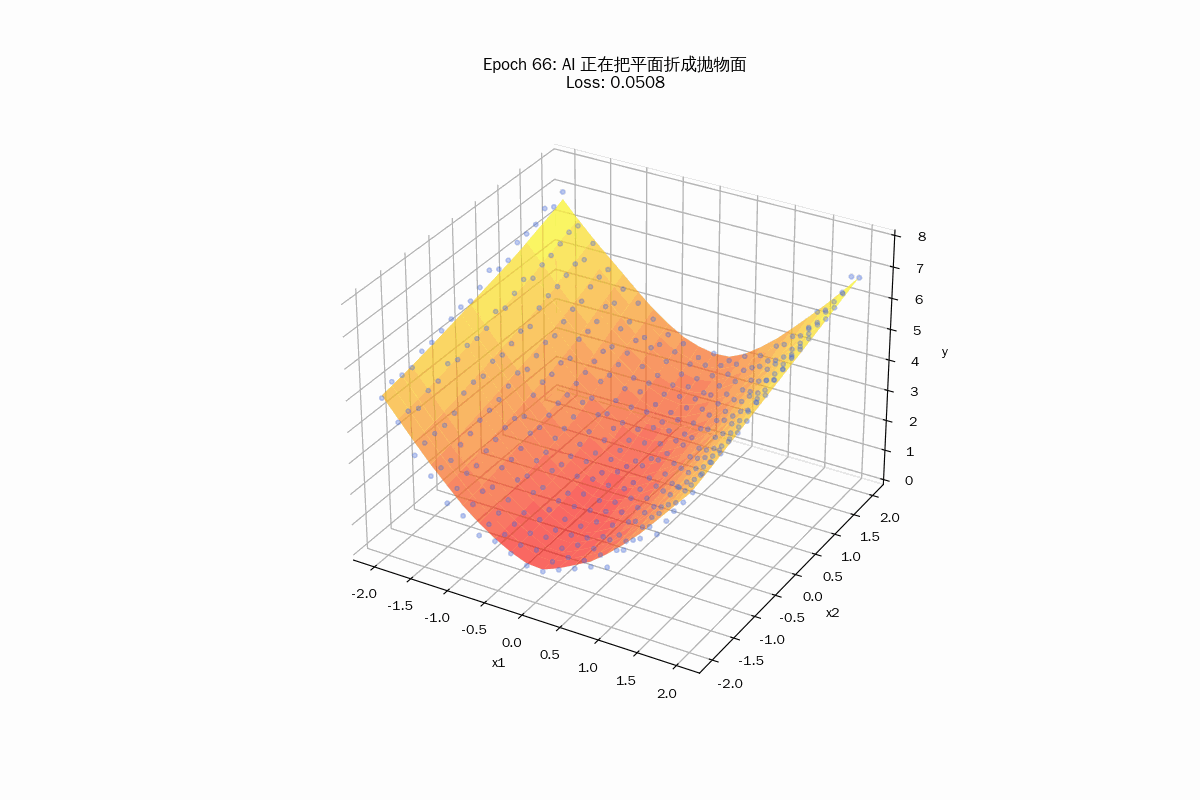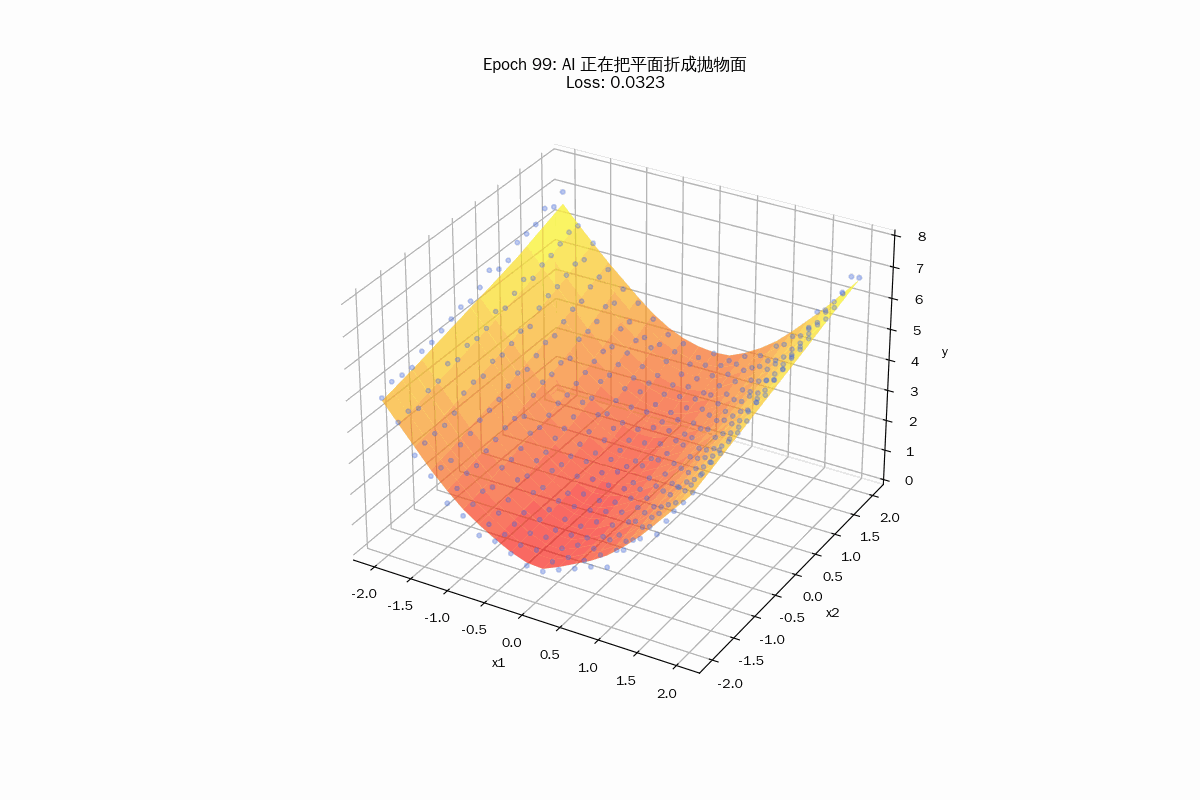
这里的梯度下降在做什么?
你可以把这个过程想象成“塑形”:
- 初始状态(一张平纸):
由于神经网络初始权重是随机的,你会看到红色的面几乎是一个平躺在 3D 空间里的平面。
- 梯度下降(折纸工):
- 计算误差:AI 发现这个平面离蓝色的“碗状”数据点太远了。
- 反向传播:它计算出隐藏层那 50 个神经元中,每一个神经元的直线(或者叫“切面”)应该如何移动。
- 更新权重:ReLU 激活函数在不同的坐标点产生“折痕”。
- 最终形态(分段拼接曲面):
随着 Epoch 增加,你会发现红色的平面开始向下弯曲,最终形成一个平滑的、贴合散点的碗状。
重点: 这种弯曲其实是由 50 个微小的、倾斜角度不同的平面碎块拼接而成的。
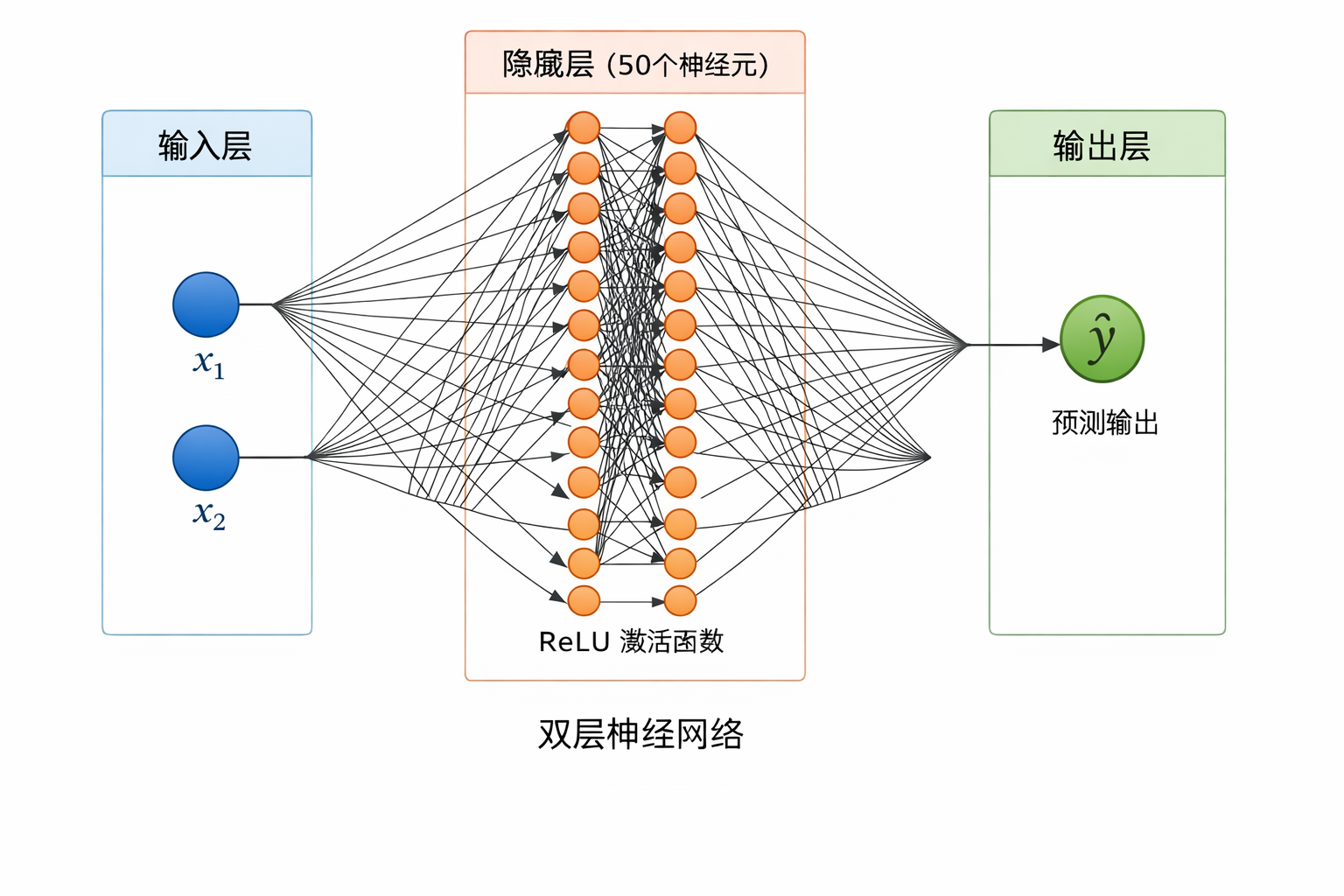
| 阶段 | 数学表达 | 几何意义 |
|---|---|---|
| 输入 | (X=[x_1,x_2]) | 3D 空间中的一个点 |
| 隐藏层 | (h = ReLU(W_1X + b_1)) | 生成 50 个不同方向的“折痕平面” |
| 输出层 | (y = W_2h + b_2) | 将这些折痕加权组合成最终曲面 |
神经网络万能逼近定理(Universal Approximation Theorem)
代码中的 50 个隐藏层神经元其实是一个 人为选择的超参数(Hyperparameter),不是由数学公式直接计算出来的。通常通过 经验 + 实验调参 来确定。
神经网络的 层数(depth) 和隐藏层神经元数一样,也是 超参数(Hyperparameter),通常通过 经验 + 任务复杂度 + 实验调参 来确定,而不是直接计算出来的。
隐藏层不同数量神经元的拟合差异
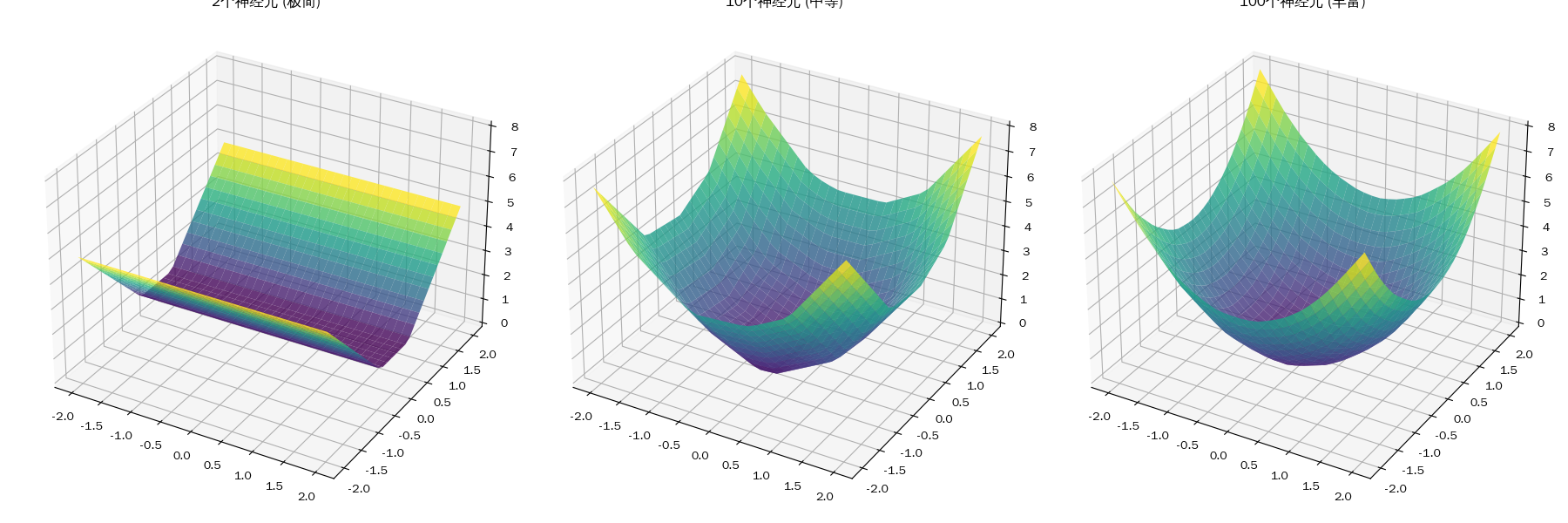
不同隐藏层数量的差异
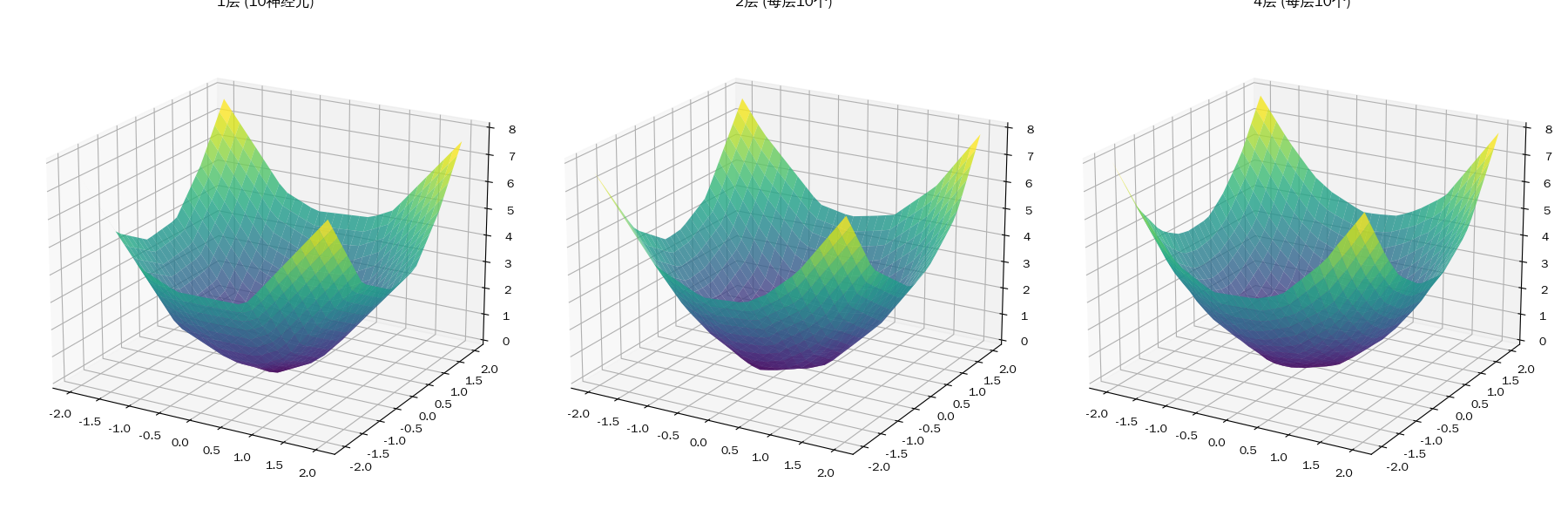
神经网络两个核心超参数:宽度 vs 深度
| 超参数 | 形象类比 | 核心价值 | 过度的代价 |
|---|---|---|---|
| 宽度 (Width) | 画笔的粗细 | 并行记忆能力。更多神经元意味着模型可以同时捕捉更多特征细节(特征分辨率更高)。 | 过拟合(死记硬背)。模型不再学习规律,而是记住每个样本(包括噪声),泛化能力下降。 |
| 深度 (Depth) | 逻辑推理的层级 | 层级抽象能力。每一层都是对上一层的抽象,从低级特征逐渐形成高级语义。 | 训练困难。梯度消失或梯度爆炸,导致网络难以收敛。 |
宽度的副作用:内存与“贪婪”
当你增加宽度时,GPU 的显存占用是呈平方级增长的。
- 好处:它能更快地收敛,因为它有足够的“空间”去容纳各种特征的组合。
- 副作用:它太“贪心”了。如果宽度远超数据复杂度,它会通过极其复杂的“折痕”去绕过每一个噪声点,形成过拟合(Overfitting)。
深度的副作用:计算延迟与“训练崩塌”
当你增加深度时,虽然参数量可能没变,但计算延迟(Latency)会增加。
- 好处:它是“非线性杠杆”。用极少的参数,通过多次折叠,就能产生比宽网络复杂得多的函数。
- 副作用:梯度消失。在 16 层或更深的网络中,底层的参数可能完全收不到更新信号,模型就像一个“植物人”,无论你怎么训练,它的底层逻辑都是随机的。
什么是开放权重
| 类别 | 内容 | 状态 | 意义 |
|---|---|---|---|
| 使用层 | 权重、配置、分词器、推理代码 | 完全开放 | 让你能跑、能用、能微调。 |
| 构造层 | 深度、宽度、残差结构、激活函数 | 完全透明 | 让你能研究、能看懂它的身体构造。 |
| 源头层 | 原始数据集、数据清洗算法 | 严格保密 | 厂商的核心竞争力,决定了模型“性格”的来源。 |
| 过程层 | 训练日志、每一步的学习率曲线 | 很少开放 | 训练过程的“黑匣子”,外界难以完美复原。 |
0
次点赞