分类问题
- 二分类 (Binary Classification)
- 多分类 (Multi-class Classification)
- 多标签分类 (Multi-label Classification)
独热编码(One-Hot Encoding)是深度学习和数据处理中一种极其常见的技术,主要用于将分类数据(Categorical Data)转换为机器学习模型能够理解的数值向量格式。
| 类别 | One-Hot 向量 |
|---|---|
| 猫 | [1,0,0] |
| 狗 | [0,1,0] |
| 鸟 | [0,0,1] |
网络架构
Softmax 回归(Softmax Regression)可以看作是一种单层神经网络
Softmax 回归(Softmax Regression),也常被称为多项逻辑回归(Multinomial Logistic Regression),本质上就是一个没有隐藏层的全连接神经网络。
输入层 输出层
(特征) (类别概率)
x1 ────────────────┐
│
x2 ────────────────┼──► z1 ──►
│ │
x3 ────────────────┘ │
│
x1 ────────────────┐ │
│ │
x2 ────────────────┼──► z2 ───┼──► Softmax ─► [P1,P2,P3]
│ │
x3 ────────────────┘ │
│
x1 ────────────────┐ │
│ │
x2 ────────────────┼──► z3 ───┘
│
x3 ────────────────┘
z1 = w11*x1 + w12*x2 + w13*x3 + b1
z2 = w21*x1 + w22*x2 + w23*x3 + b2
z3 = w31*x1 + w32*x2 + w33*x3 + b3
softmax 运算
Softmax 函数把一组任意实数(得分)转换成概率分布
假设神经网络最后一层的输出是一个向量 $z = [z_1, z_2, \dots, z_C]$,其中 $C$ 是类别的数量。Softmax 函数对每一个分量 $z_i$ 进行如下计算:
\[\text{Softmax}(z_i) = \frac{e^{z_i}}{\sum_{j=1}^{C} e^{z_j}}\]| 特性 | 说明 |
|---|---|
| 输出范围 | 0~1 |
| 概率和 | =1 |
| 用途 | 多分类 |
| 位置 | 网络最后一层 |
小批量样本的矢量化
单样本计算
x1 → Wx+b → softmax → y1
x2 → Wx+b → softmax → y2
x3 → Wx+b → softmax → y3
x4 → Wx+b → softmax → y4
小批量矢量化
X (4个样本)
│
│
矩阵乘法
│
▼
Z = XW+b
│
│
Softmax
│
▼
Y (4个预测)
为什么要矢量化?
- 并行化: GPU 可以同时对矩阵中的成千上万个元素进行加法和乘法。
- 缓存命中: 矩阵运算利用了计算机体系结构中的局部性原理,减少了内存访问开销。
- 库优化: 像 cuBLAS 和 MKL 这样的底层库对矩阵乘法(GEMM)做了极致的汇编级优化。
损失函数
Softmax 分类中:梯度 = 预测概率 − 真实概率
对数似然
对数(Logarithm) 是幂运算的逆运算。简单来说,如果你知道一个底数和它的幂结果,对数就是用来求“指数是多少”的。
如果 $a^x = N$ (其中 $a > 0$ 且 $a \neq 1$),那么数 $x$ 就叫做以 $a$ 为底 $N$ 的对数,记作:\(\log_a N = x\)
softmax及其导数
导数是我们softmax模型分配的概率与实际发生的情况(由独热标签向量表示)之间的差异
| 阶段 | 形式 | 物理意义 |
|---|---|---|
| 原始标签 | 狗 | 离散的类别名称 |
| 标签转换 (Target) | [0,1,0] |
真实概率分布(100%确定) |
| 模型输出 (Logits) | [1.2, 4.5, -0.8] |
模型给每个类别的“打分” |
| 模型预测 (Output) | [0.03, 0.96, 0.01] |
归一化后的概率 |
训练时真正比较的是什么
真实概率 VS 预测概率
真实:[0,1,0]
预测:[0.03,0.96,0.01]
计算交叉熵损失CrossEntropy Loss
几何理解
Softmax 概率分布和交叉熵损失(Cross-Entropy)的斜率(梯度)
样本空间
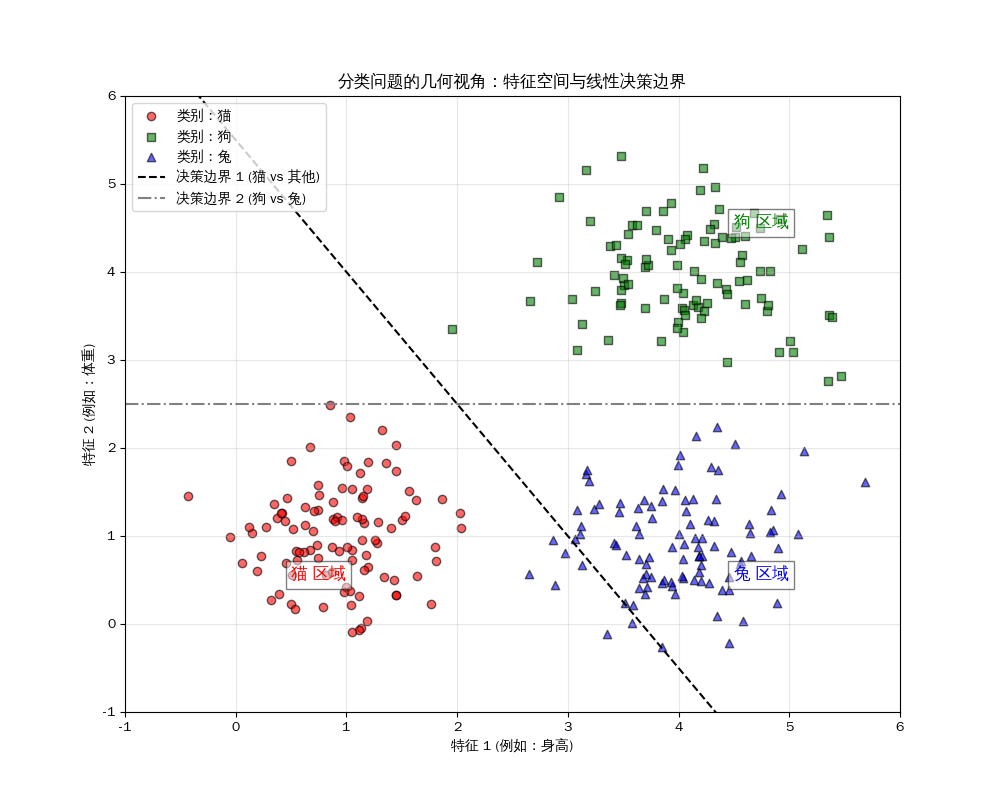
决策区域
要在样本空间中画出拟合后的模型,最直观的方法就是绘制“决策区域”(Decision Regions)
在几何上,这相当于让模型对平面上的每一个点都进行一次“面试”,看看模型把该点划归为哪一类。通过给不同类别的区域涂上不同的颜色,我们就能清晰地看到模型在空间中画出的“领土边界”。
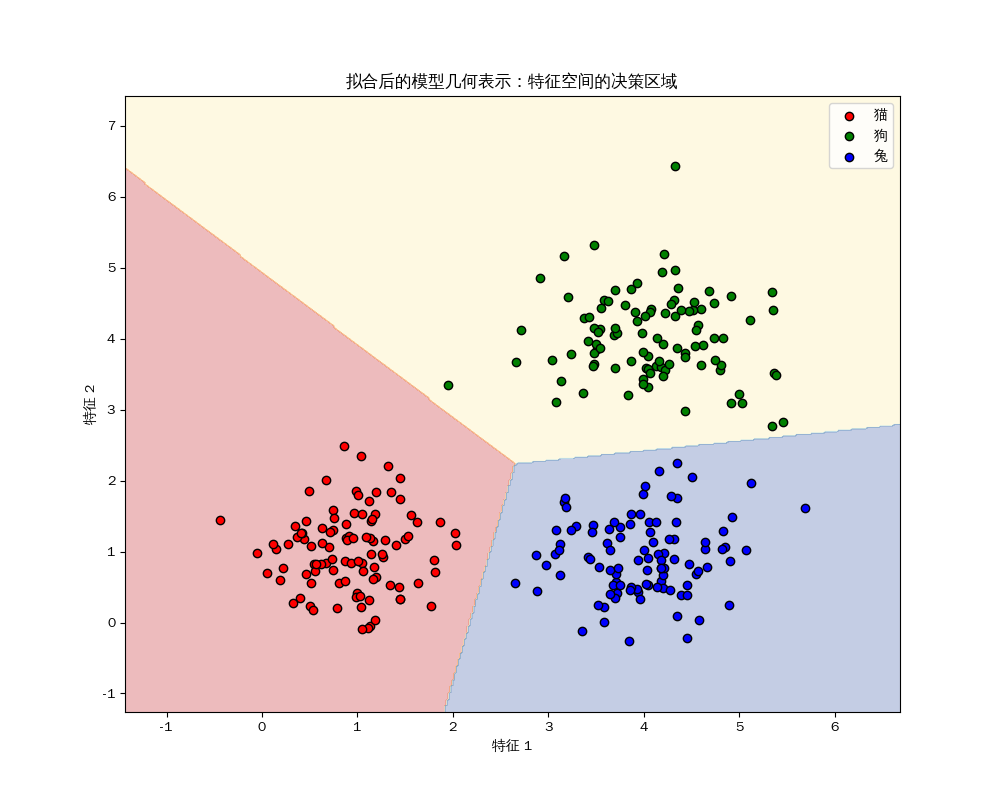
几何与代数的对应关系
当我们判断一个点属于“猫”还是“狗”时,本质是在比较:
\[z_{猫} > z_{狗}\]代入线性表达式:
\[(w_{猫1}x_1 + w_{猫2}x_2 + b_{猫}) > (w_{狗1}x_1 + w_{狗2}x_2 + b_{狗})\]整理后得到:
\[(w_{猫1} - w_{狗1})x_1 + (w_{猫2} - w_{狗2})x_2 + (b_{猫} - b_{狗}) > 0\]这就是一条标准直线方程 $Ax + By + C > 0$!
几何真相:它是空间的“势力范围”划分
在三分类问题中,模型并不是直接画出三条线,而是为每个类别准备了一个得分函数(在 3D 特征空间里,它们是三个斜面):
- $z_{猫} = w_{11}x_1 + w_{12}x_2 + b_1$
- $z_{狗} = w_{21}x_1 + w_{22}x_2 + b_2$
- $z_{兔} = w_{31}x_1 + w_{32}x_2 + b_3$
是三条线吗?
严格来说,在三分类的二维特征空间里:
- 对于每一对类别,都存在一条潜在的边界线(猫 vs 狗,狗 vs 兔,兔 vs 猫)。
- 但最终展现出来的,通常是一个“Y”字形的交汇点。
- 在这个交点处,三类得分完全相等($z_{猫} = z_{狗} = z_{兔}$),模型在这里最“纠结”。
训练过程
训练到底在训练什么?
通过交叉熵损失函数求导出的梯度,模型在不断微调 $W$ 和 $\mathbf{b}$ 的数值:
- 改变 $W$:是在旋转特征空间中那三条分界线的角度。
- 改变 $\mathbf{b}$:是在平移这些分界线的位置。
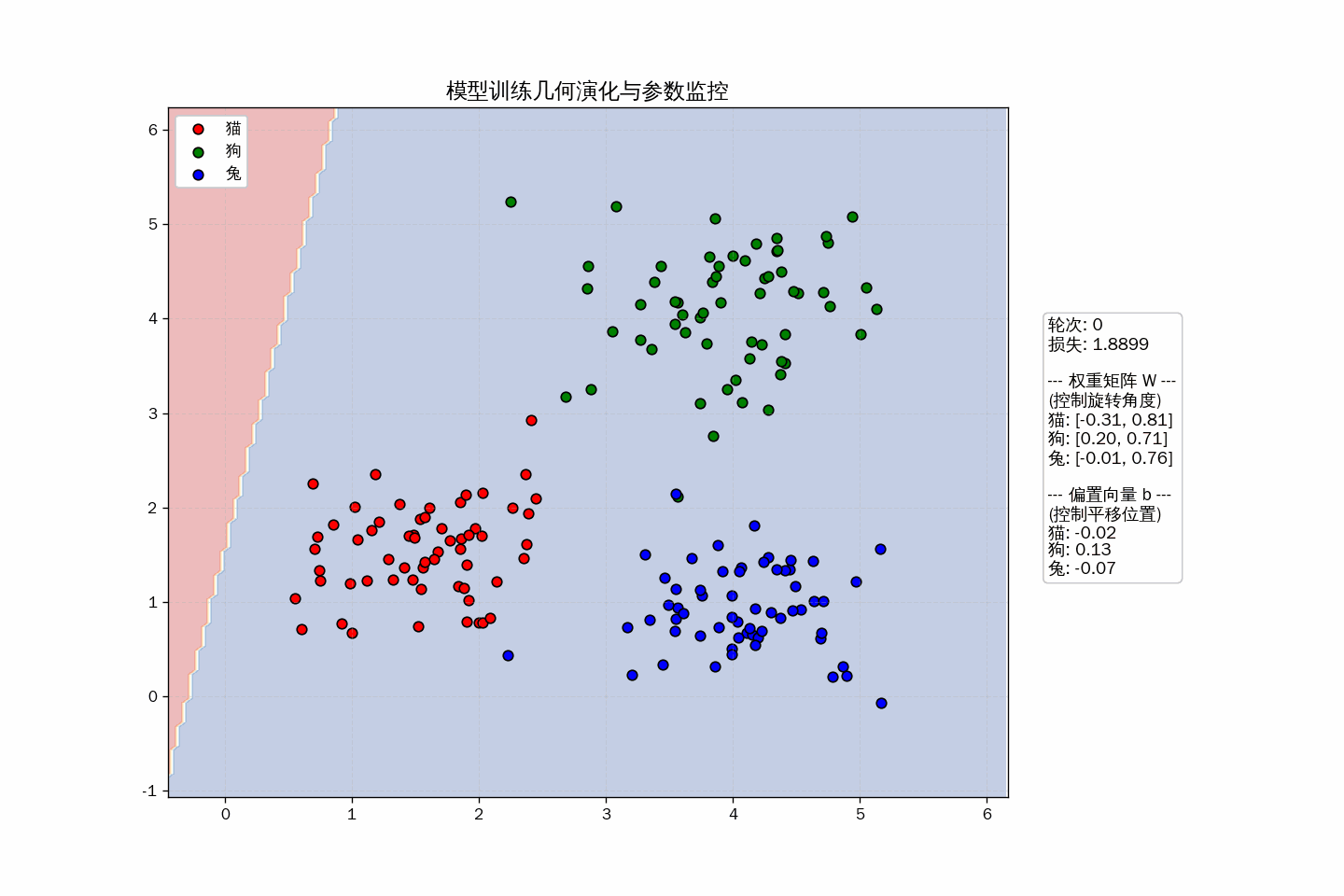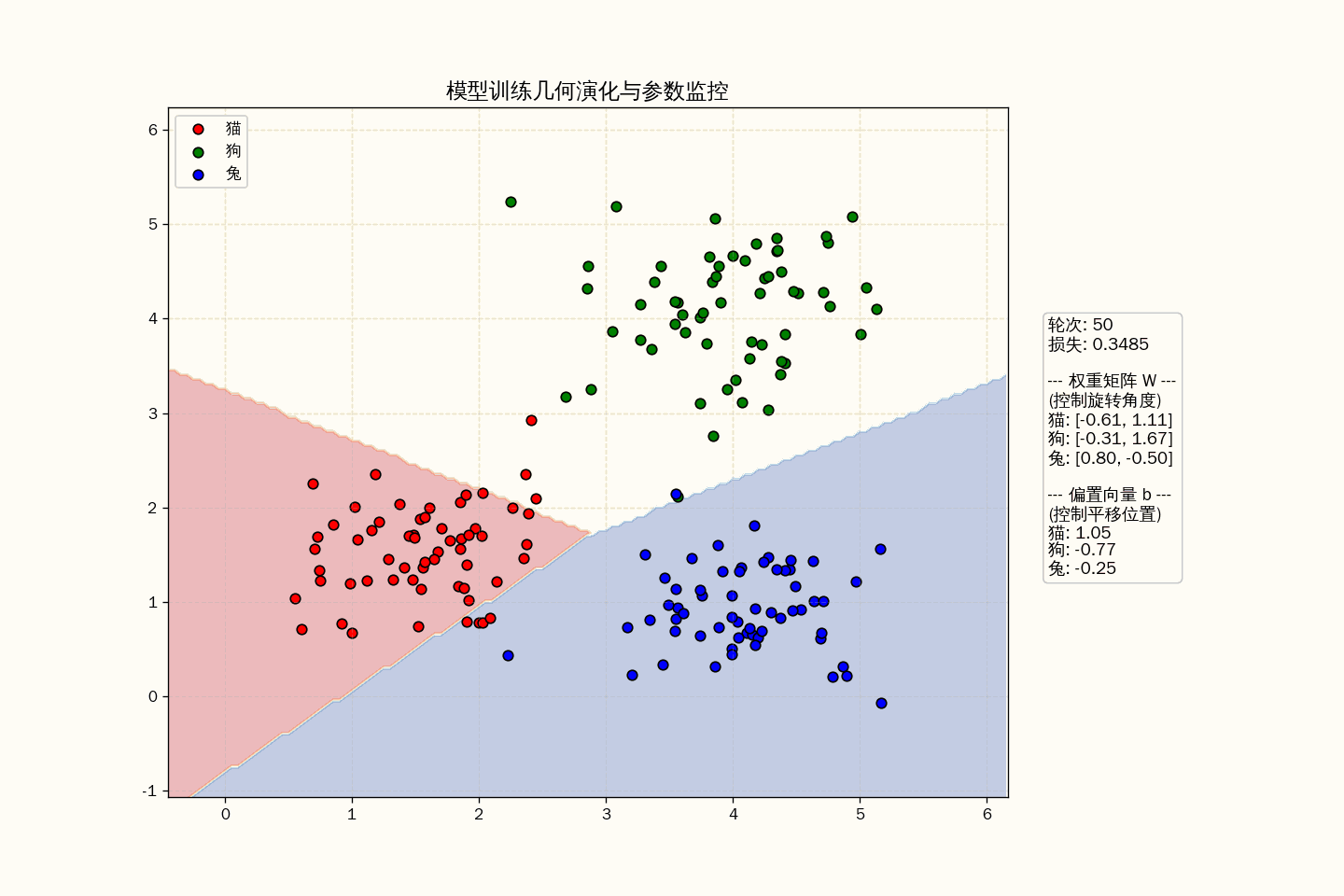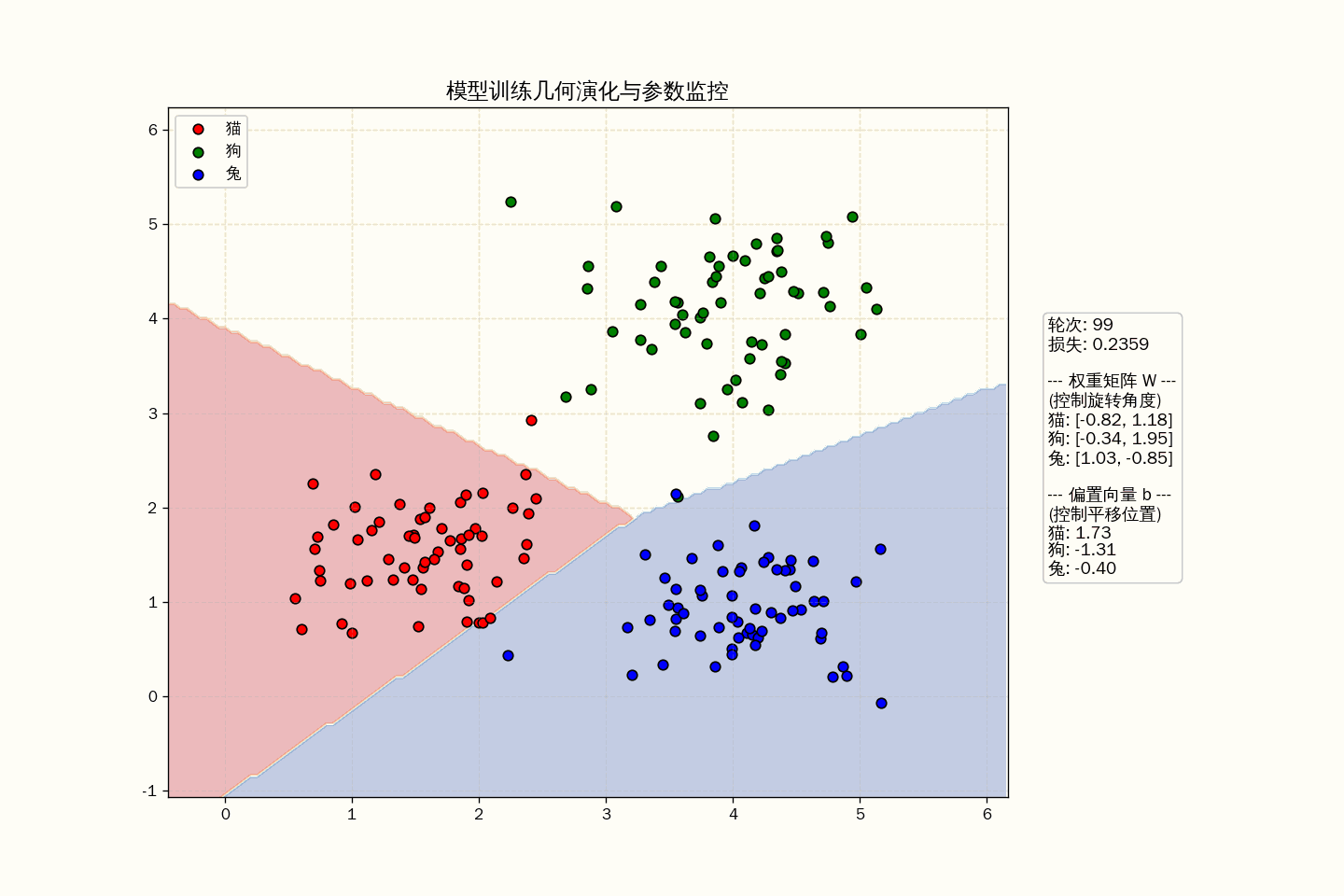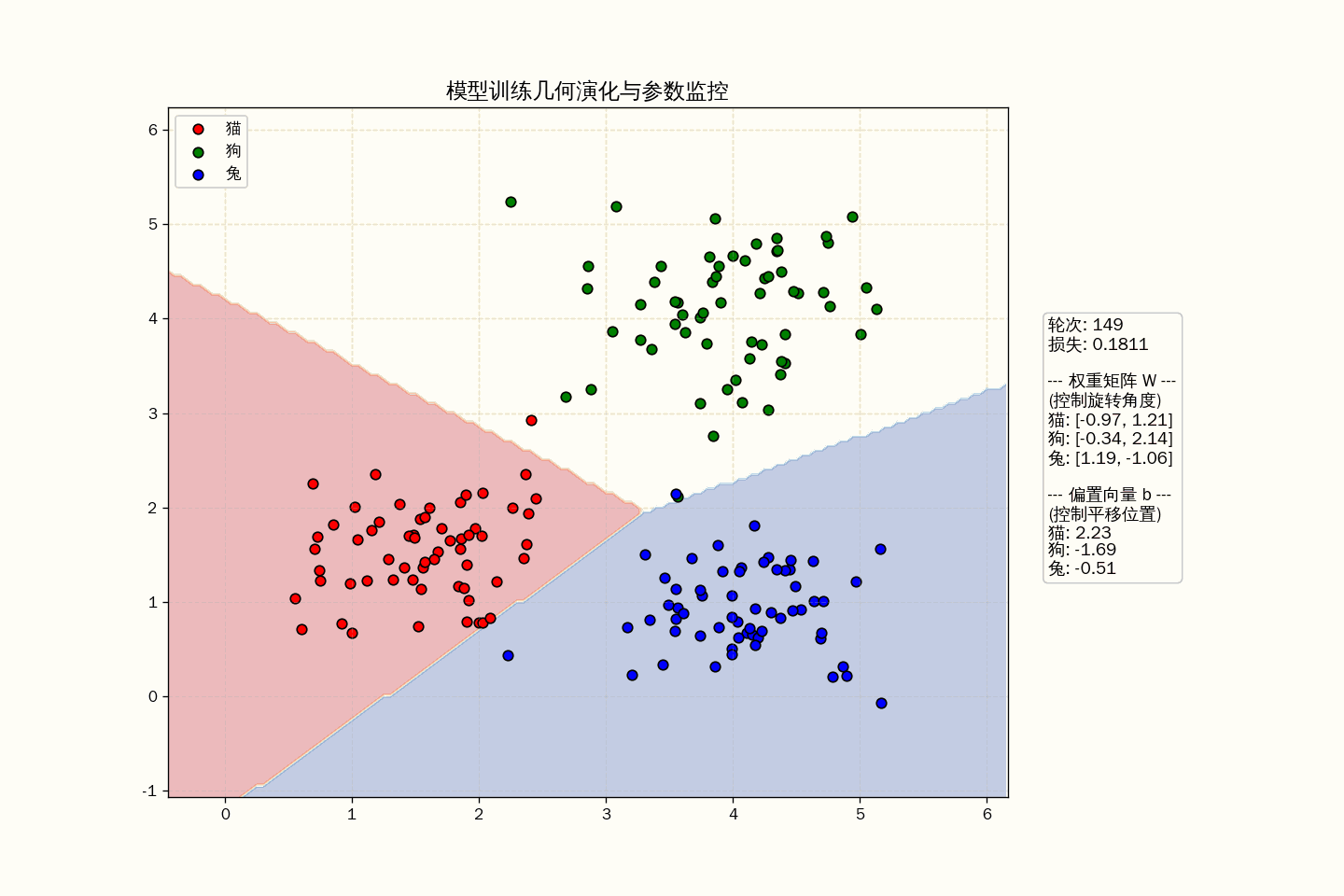
在动画中,你可以观察到以下三个关键的几何演化:
- 旋转(Weights $W$):权重矩阵的每一列其实是对应类别的“法向量”。当 $W$ 改变时,分类边界线在特征空间中旋转,寻找最能区分点群的角度。
- 平移(Bias $b$):偏置项决定了决策边界的“门槛”。即便旋转角度对了,如果偏置不对,边界线也会因为“领土分配不均”导致 Loss 居高不下。
- 势能(Loss $L$):你可以把 Loss 想象成一种“重力势能”。模型在训练时,就像一个小球在地形图中沿着最陡峭的坡度(梯度)向下滑动,直到进入那个能完美隔离点群的“峡谷”。
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.animation as animation
from matplotlib import font_manager as fm
# ==========================================
# 1. 中文显示设置
# ==========================================
# 中文显示设置(自动选择可用中文字体,避免乱码)
candidate_fonts = [
'Noto Sans CJK SC', 'Source Han Sans SC', 'WenQuanYi Zen Hei',
'SimHei', 'Microsoft YaHei', 'PingFang SC', 'Heiti SC',
'Arial Unicode MS', 'DejaVu Sans'
]
available_fonts = {f.name for f in fm.fontManager.ttflist}
chinese_font = next((f for f in candidate_fonts if f in available_fonts), 'DejaVu Sans')
plt.rcParams['font.sans-serif'] = [chinese_font, 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
# ==========================================
# 2. 生成模拟样本数据 (三分类)
# ==========================================
np.random.seed(42)
n_samples = 60
cat = np.random.multivariate_normal([1.5, 1.5], [[0.3, 0.1], [0.1, 0.3]], n_samples)
dog = np.random.multivariate_normal([4.0, 4.0], [[0.4, 0.1], [0.1, 0.4]], n_samples)
rabbit = np.random.multivariate_normal([4.0, 1.0], [[0.3, 0], [0, 0.3]], n_samples)
X = np.vstack([cat, dog, rabbit])
y = np.array([0]*n_samples + [1]*n_samples + [2]*n_samples)
Y_onehot = np.eye(3)[y]
# ==========================================
# 3. 全局模型参数
# ==========================================
W = None
b = None
learning_rate = 0.2
# 动画与导出配置
total_frames = 150
interval_ms = 50
save_gif = True
gif_path = 'pytorch/demo_0306_training.gif'
def reset_model():
global W, b
# 随机初始化 W (2特征 x 3类别), b (3类别)
W = np.random.randn(2, 3) * 0.5
b = np.random.randn(1, 3) * 0.1
def softmax(z):
e_z = np.exp(z - np.max(z, axis=1, keepdims=True))
return e_z / e_z.sum(axis=1, keepdims=True)
# ==========================================
# 4. 设置绘图布局
# ==========================================
# 增加子图宽度,以便在右侧留出空间显示参数
fig = plt.figure(figsize=(12, 8))
ax = fig.add_subplot(111)
plt.subplots_adjust(right=0.75) # 给文字留出空间
# 参数文本区域只创建一次,更新时仅改文本,减少闪烁。
param_box = fig.text(
0.78,
0.5,
'',
fontsize=11,
verticalalignment='center',
fontfamily=chinese_font,
bbox=dict(boxstyle='round', facecolor='wheat', alpha=0.2),
)
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.05), np.arange(y_min, y_max, 0.05))
grid_points = np.c_[xx.ravel(), yy.ravel()]
# ==========================================
# 5. 动画逻辑
# ==========================================
def update(frame):
global W, b
if frame == 0:
reset_model()
ax.clear()
# --- 训练步骤 (梯度下降) ---
logits = np.dot(X, W) + b
probs = softmax(logits)
error = probs - Y_onehot
dW = np.dot(X.T, error) / X.shape[0]
db = np.mean(error, axis=0)
W -= learning_rate * dW
b -= learning_rate * db
# --- 几何绘制 ---
Z_logits = np.dot(grid_points, W) + b
Z_class = np.argmax(Z_logits, axis=1).reshape(xx.shape)
ax.contourf(xx, yy, Z_class, alpha=0.3, cmap=plt.cm.RdYlBu)
ax.scatter(cat[:, 0], cat[:, 1], c='red', edgecolors='k', s=40, label='猫')
ax.scatter(dog[:, 0], dog[:, 1], c='green', edgecolors='k', s=40, label='狗')
ax.scatter(rabbit[:, 0], rabbit[:, 1], c='blue', edgecolors='k', s=40, label='兔')
loss = -np.mean(np.sum(Y_onehot * np.log(probs + 1e-9), axis=1))
# --- 实时参数显示 ---
param_text = (
f"轮次: {frame}\n"
f"损失: {loss:.4f}\n\n"
f"--- 权重矩阵 W ---\n"
f"(控制旋转角度)\n"
f"猫: [{W[0,0]:.2f}, {W[1,0]:.2f}]\n"
f"狗: [{W[0,1]:.2f}, {W[1,1]:.2f}]\n"
f"兔: [{W[0,2]:.2f}, {W[1,2]:.2f}]\n\n"
f"--- 偏置向量 b ---\n"
f"(控制平移位置)\n"
f"猫: {b[0,0]:.2f}\n"
f"狗: {b[0,1]:.2f}\n"
f"兔: {b[0,2]:.2f}"
)
# 在绘图区外侧显示文字(复用已有文本对象,中文显示更稳定)
param_box.set_text(param_text)
ax.set_title("模型训练几何演化与参数监控", fontsize=14, fontfamily=chinese_font)
ax.legend(loc='upper left', prop={'family': chinese_font, 'size': 10})
ax.set_xlim(x_min, x_max)
ax.set_ylim(y_min, y_max)
ax.grid(True, linestyle='--', alpha=0.3)
# ==========================================
# 6. 启动动画
# ==========================================
ani = animation.FuncAnimation(
fig,
update,
frames=total_frames,
interval=interval_ms,
repeat=True,
repeat_delay=1500,
)
# 支持导出 GIF。PillowWriter 生成的 GIF 默认可循环播放。
if save_gif:
fps = max(1, int(1000 / interval_ms))
print(f'使用字体: {chinese_font}')
print(f'开始保存 GIF: {gif_path}')
ani.save(gif_path, writer=animation.PillowWriter(fps=fps), dpi=120)
print(f'GIF 保存完成: {gif_path}')
plt.show()
Softmax + CrossEntropy 计算图
前向传播 → 计算损失 → 反向传播 → 更新参数 → 再前向传播
输入特征 X
(Input Features / 样本特征)
每一行代表一个样本
例如:
X = [身高, 体重]
X = [像素1, 像素2, ...]
│
│
▼
线性变换 (Linear Layer)
z = XW + b
W : 权重矩阵 (feature → class)
b : 偏置向量
作用:
将输入特征映射为每个类别的“打分”
例如:
z = [2.3, 1.1, -0.7]
│
│
▼
logits z
(每个类别的原始得分)
logits 的特点:
• 可以是任意实数
• 不需要和为1
• 仅代表“相对偏好”
例如:
猫 2.3
狗 1.1
兔 -0.7
│
│
▼
Softmax
p_i = exp(z_i) / Σ exp(z_j)
Softmax作用:
1 把任意实数转成概率
2 概率范围 (0,1)
3 概率总和 = 1
例如:
logits
[2.3,1.1,-0.7]
softmax →
p =
[0.70 , 0.24 , 0.06]
│
│
▼
预测概率 p
p = [p1, p2, p3 ... pk]
含义:
p1 = 是猫的概率
p2 = 是狗的概率
p3 = 是兔的概率
模型预测类别:
argmax(p)
│
│
▼
Cross Entropy Loss
L = - Σ y_i log(p_i)
y 是 one-hot 标签
例如真实标签:
狗
y =
[0 , 1 , 0]
Loss 只关注真实类别:
L = -log(p_dog)
如果
p_dog = 0.9
loss ≈ 0.1
如果
p_dog = 0.1
loss ≈ 2.3
说明:
预测越错
loss越大
│
│
▼
损失 Loss
训练目标:
最小化 Loss
min L(W,b)
────────────────────────────────
反向传播
(Backward)
────────────────────────────────
│
▼
∂L / ∂p
= -y / p
含义:
Loss 对概率 p 的变化敏感度
如果真实类别概率很小
p 很小
梯度就很大
→ 强烈惩罚错误预测
│
▼
Softmax
梯度继续向前传播
通过链式法则
Chain Rule
│
▼
∂L / ∂z = p - y
这是一个非常重要的结果
梯度 =
预测概率 − 真实概率
例如:
p = [0.2,0.6,0.2]
y = [0,1,0]
p - y =
[0.2,-0.4,0.2]
含义:
猫概率太高 → 降低
狗概率太低 → 提高
兔概率太高 → 降低
│
▼
Linear Layer
z = XW + b
梯度继续传播到参数
计算:
∂L/∂W
∂L/∂b
公式:
∂L/∂W = Xᵀ (p - y)
∂L/∂b = p - y
│
▼
参数更新
梯度下降:
W_new = W - η ∂L/∂W
b_new = b - η ∂L/∂b
η = 学习率
作用:
让预测更接近真实标签
────────────────────────────────
完整训练循环
────────────────────────────────
输入 X
↓
Linear
↓
Softmax
↓
CrossEntropy
↓
Loss
↓
反向传播
↓
更新参数
↓
重复 N 次
Loss 会逐渐下降
模型预测越来越准
信息论的角度理解交叉熵
AI 的本质是在不确定性中寻找规律,而信息论则为这种“寻找”提供了度量衡和极限边界。
目标函数:AI 学习的本质是“熵减”
决策树:纯粹的信息增益博弈
生成式 AI(LLM/Diffusion):预测即压缩
OpenAI 的首席科学家 Ilya Sutskever 曾提出过一个著名观点:“完美的预测等价于完美的压缩。”
信息量
信息量(Self-Information):越惊讶,信息越多
信息论之父香农认为,信息的本质是“消除不确定性”。
- 一个必然发生的事件(如:太阳升起)不包含信息。
- 一个极不可能发生的事件(如:今天中大奖)一旦发生,信息量巨大。
数学上,信息量 $I(x)$ 定义为概率的负对数:
\[I(x) = -\log p(x)\]直觉理解:概率越小,发生的“惊讶程度”越高,信息量就越大。
信息熵(Entropy)
信息熵(Entropy):平均的惊讶程度
信息熵 $H(P)$ 是一个系统(分布 $P$)中所有可能事件产生的信息量的期望值。
\[H(P) = -\sum_{i} p(x_i) \log p(x_i)\]它是描述一个系统所需的最小平均编码长度。在这个分布下,没有比熵更短的方式能描述这些信息了。
交叉熵(Cross-Entropy)
交叉熵(Cross-Entropy):认知偏差的代价
现在,假设世界是按照分布 $P$(真实分布)运行的,但你的大脑里却认为它是按照分布 $Q$(预测分布)运行的。
当你用错误的认知 $Q$ 去为真实发生的事件 $P$ 编码时,平均每个事件需要的编码长度就是交叉熵:
\[H(P, Q) = -\sum_{i} p(x_i) \log q(x_i)\]- $p(x_i)$:事件真实发生的频率。
- $-\log q(x_i)$:你基于错误预测而分配的编码长度。
这就解释了为什么模型训练要最小化交叉熵: 你的预测 $Q$ 越接近事实 $P$,你描述这个世界时产生的“惊讶感”就越少,编码长度就越接近物理极限(信息熵)。
信息论在通信中的应用
信源编码:数据压缩(Data Compression)
核心逻辑: 既然熵是描述信息的最小平均长度,那么任何高于熵的表示都是“废话”。
- 应用: 你的手机通话、视频通话(Zoom/微信)、视频点流(Netflix/B站)。
- 信息论视角: 视频原始数据极大,但帧与帧之间有大量重复。通过 预测编码 和 变换编码(如 DCT),我们去掉了冗余信息,只传输“不确定性”最高的部分(即熵)。
- 结果: 让你能用有限的流量看高清视频。
香农公式:信道容量(Channel Capacity)
这是通信行内最著名的公式:
\[C = B \cdot \log_2\left(1 + \frac{S}{N}\right)\]- $C$:信道容量(最大传输速率)。
- $B$:带宽(管子的宽度)。
- $S/N$:信噪比(信号比杂音强多少)。
行业意义: 它划定了物理极限。无论你的 5G 或 6G 技术多先进,你永远无法突破这个公式算出来的上限
信道编码:纠错与鲁棒性(Error Correction)
在物理传输中,由于干扰,1 可能会变成 0。信息论提出了“信道编码定理”:只要传输速率低于信道容量,总能找到一种编码方式,使误码率趋近于零。
应用:
- Turbo 码(4G 的核心)。
- LDPC 码(5G 数据信道的核心)。
- Polar 码(极化码)(5G 控制信道的核心)。
信息论视角: 这相当于在传输信息时加入了一定比例的“精妙废话”(冗余位)。即便路上洒了一点水,接收端也能根据这些废话把原来的水还原出来。
现代通信的黑科技:MIMO 与多用户检测
现代基站(如 5G 基站)有几十甚至上百根天线。
空间复用: 信息论证明了,如果在空间中增加独立的天线路径,信道容量 $C$ 就不再是关于对数的增长,而是关于天线数量的线性增长。
物理直觉: 相当于把原来的单车道公路改造成了“立体高架桥”,效率成倍提升。