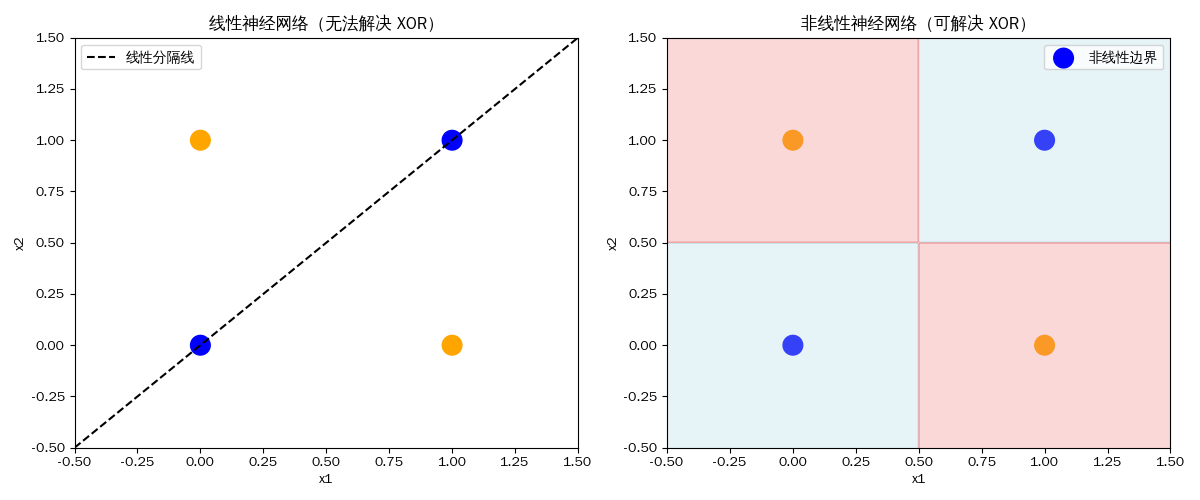
线性模型可能会出错
在网络中加入隐藏层
\[\begin{aligned} \mathbf{h}^{(1)} &= f_1(\mathbf{W}^{(1)} \mathbf{x} + \mathbf{b}^{(1)}) \\ \mathbf{h}^{(2)} &= f_2(\mathbf{W}^{(2)} \mathbf{h}^{(1)} + \mathbf{b}^{(2)}) \\ &\;\;\vdots \\ \mathbf{h}^{(L)} &= f_L(\mathbf{W}^{(L)} \mathbf{h}^{(L-1)} + \mathbf{b}^{(L)}) \\ \mathbf{y} &= g(\mathbf{W}^{(L+1)} \mathbf{h}^{(L)} + \mathbf{b}^{(L+1)}) \end{aligned}\]双层公式推导
\[\mathbf{y} = g\Big( \mathbf{W}^{(2)} \, f(\mathbf{W}^{(1)} \mathbf{x} + \mathbf{b}^{(1)}) + \mathbf{b}^{(2)} \Big)\]通用近似定理
隐藏层神经元作用:每个隐藏神经元依赖输入向量的所有分量,它可以捕捉输入之间的复杂非线性关系
单隐藏层宽网络:隐藏神经元很多,也能逼近任意函数,但训练困难,参数多,容易过拟合。
多隐藏层深网络:每层捕捉不同级别的特征,通过组合非线性激活,可以更高效地逼近复杂函数。
类比理解
| 神经网络 | 编程类比 |
|---|---|
| 单隐藏层宽网络 | C语言程序,功能强大,但要写好很困难 |
| 多层深网络 | 分层模块化编程,每层抽象特征,更容易实现复杂功能 |
几何直观:乐高积木原理
为什么简单的相乘、相加再加上一个 ReLU 就能拼出复杂的函数?你可以把它想象成用无限小的“乐高积木”去堆叠复杂的形状。
线性变换($Wx + b$):负责平移、旋转和缩放空间。非线性激活(ReLU):负责“折叠”空间。
当你把成百上千个神经元组合在一起时,它们实际上是在函数图像上产生了一个个“拐点”。
每一个隐藏层神经元其实都在定义一个“分段线性函数”:无数个这种带拐点的函数叠加在一起,就能拼凑出极其复杂的曲线,甚至在高维空间里勾勒出非常诡异的边界。
激活函数
神经网络中的激活函数(Activation Function): 激活函数让神经网络可以逼近非线性函数,否则多层线性网络等价于单层线性
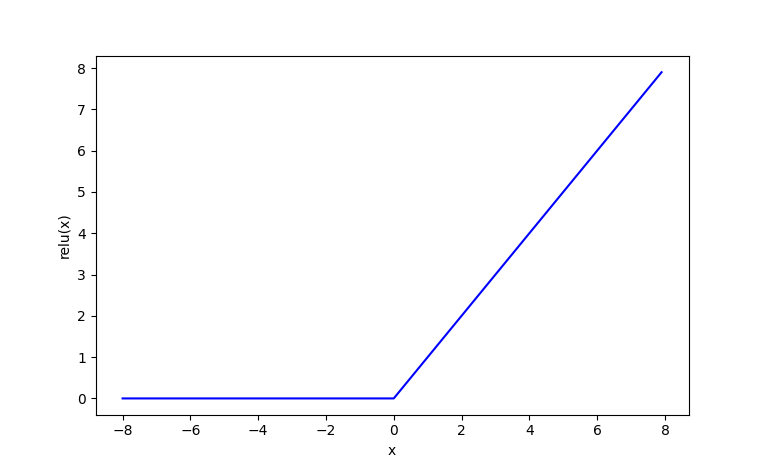
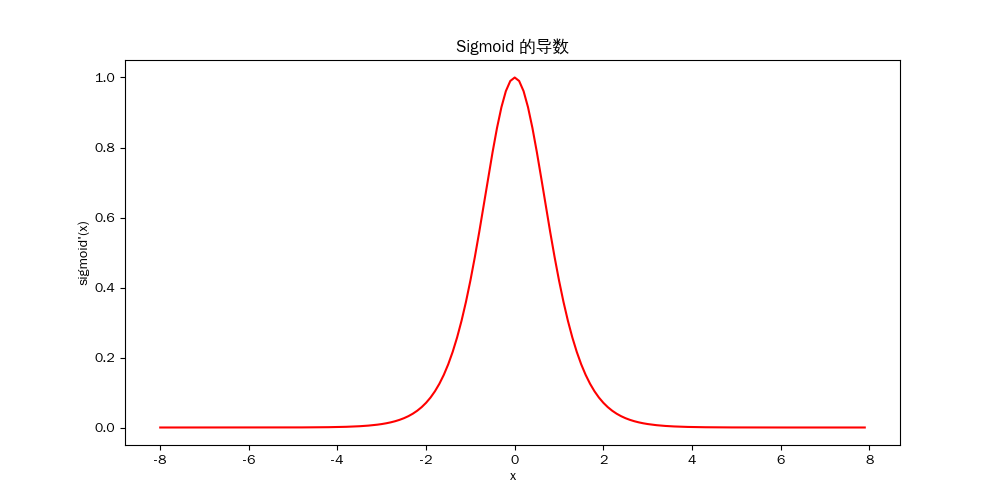
ReLU 函数
$\text{ReLU}(x) = \max(0, x)$
"""ReLU 激活函数可视化示例。
绘制 ReLU(x) = max(0, x) 的函数图像,
直观展示其"负半轴归零、正半轴保持线性"的特性。
"""
# 导入 PyTorch,用于张量运算和自动求导。
import torch
# 导入 matplotlib 绑定图绑定,用于绑定图。
import matplotlib.pyplot as plt
# 在 [-8, 8) 区间以步长 0.1 生成等间距张量作为输入。
# requires_grad=True 使其支持自动求导(后续如需画导数图可直接用)。
x = torch.arange(-8.0, 8.0, 0.1, requires_grad=True)
# 计算 ReLU 激活值:当 x > 0 时输出 x,否则输出 0。
y = torch.relu(x)
# 先创建画布,再绑定图——这样所有绑定制操作都在同一个 Figure 上。
plt.figure(figsize=(5, 2.5))
# 绘制 ReLU 曲线。
# detach() 将张量从计算图中分离,numpy() 转为 NumPy 数组供 matplotlib 使用。
plt.plot(x.detach().numpy(), y.detach().numpy(), 'b-')
plt.xlabel('x')
plt.ylabel('relu(x)')
plt.show()
求导数
# 对 y 的所有元素求导,得到 dy/dx(ReLU 的导数),并保留计算图以便后续绘制导数曲线。
y.backward(torch.ones_like(x), retain_graph=True)
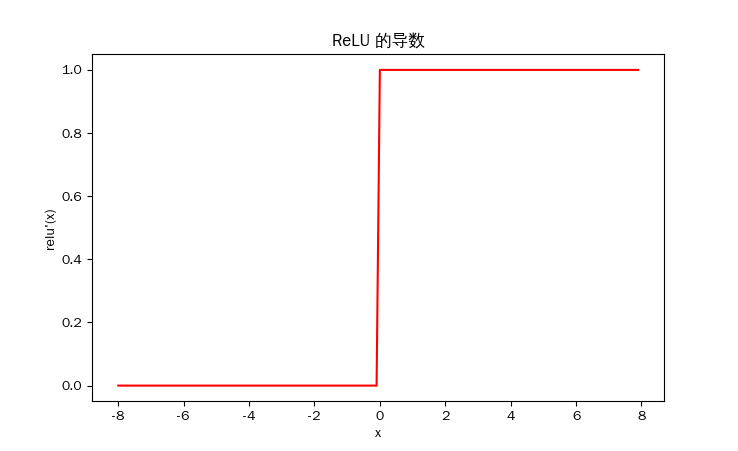
ReLU 的核心思想就是:让有用的信号顺利传递(梯度=1),让无用的信号关闭(梯度=0)
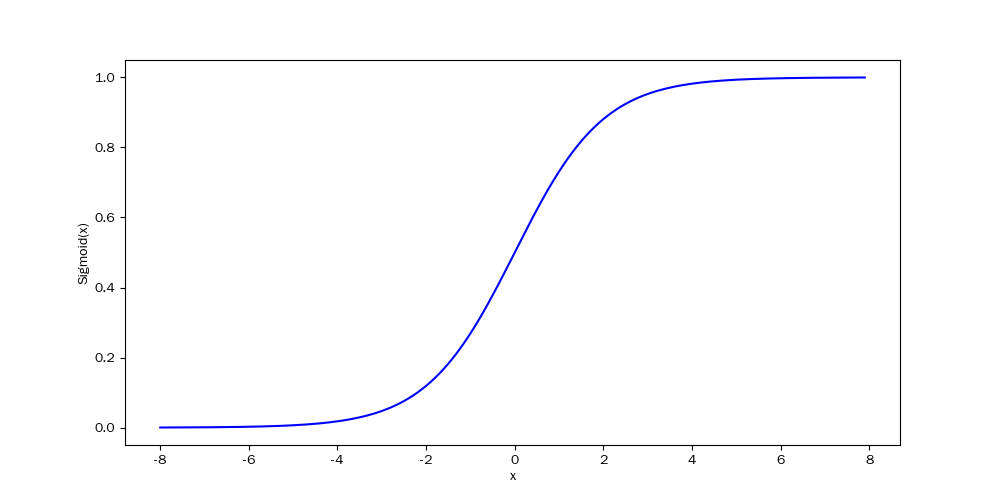
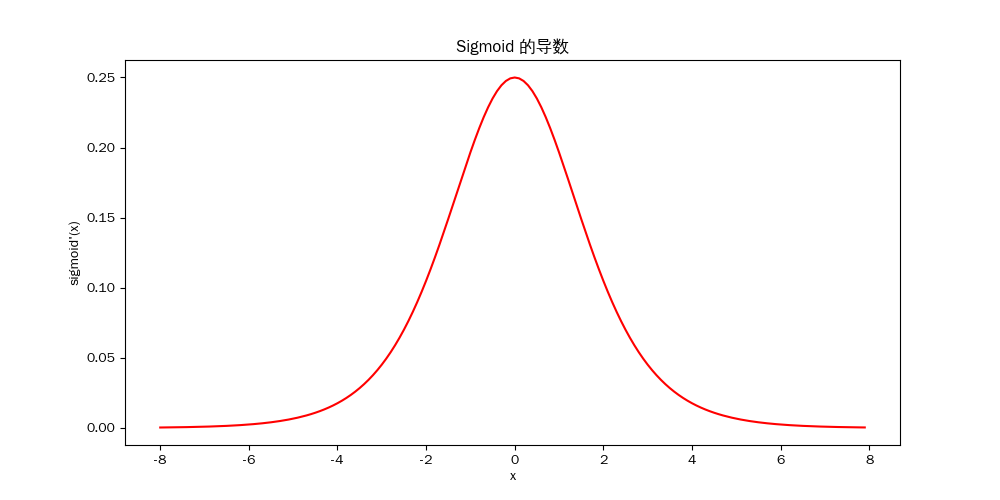
sigmoid函数
对于一个定义域在 R 中的输入, sigmoid函数将输入变换为区间(0, 1)上的输出。 因此,sigmoid通常称为挤压函数(squashing function): 它将范围(-inf, inf)中的任意输入压缩到区间(0, 1)中的某个值:
$\sigma(x) = \frac{1}{1+e^{-x}}$
y = torch.sigmoid(x)
y.backward(torch.ones_like(x), retain_graph=True)
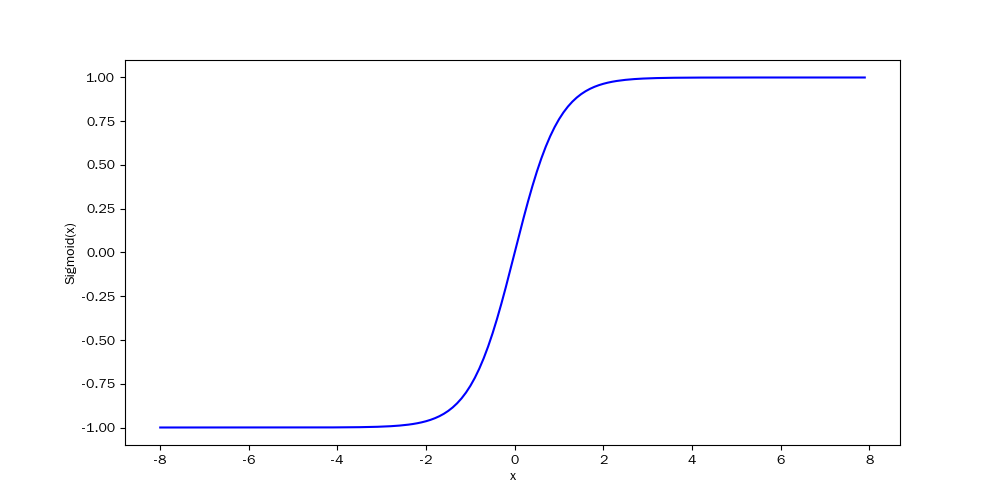
Tanh(双曲正切)函数
$\tanh(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}}$
y = torch.tanh(x)
Pytorch d2l
Dive into Deep Learning
| 功能 | 说明 |
|---|---|
| 数据集加载 | 提供 Fashion-MNIST、MNIST 等常用数据集的快速加载器 |
| 迭代器 | 封装了 DataLoader,支持批量训练和数据预处理 |
| 可视化 | 绘制损失曲线、准确率曲线、样本图像等 |
| 模型辅助 | 提供训练函数、梯度检查、预测辅助等 |
d2l 与 PyTorch 的关系
- 《Dive into Deep Learning》作者: 李沐(Mu Li)、阿斯顿·张(Aston Zhang)、扎克·C·立(Zachary C. Lipton)等
- d2l PyTorch 版本:
- 由作者团队提供的 PyTorch 兼容工具集
- 方便实验、数据加载、训练辅助、可视化
- 注意: 不是 PyTorch 官方项目
# 导入 d2l 的 PyTorch 工具集合,用于快速加载数据集和训练辅助。
from d2l import torch as d2l
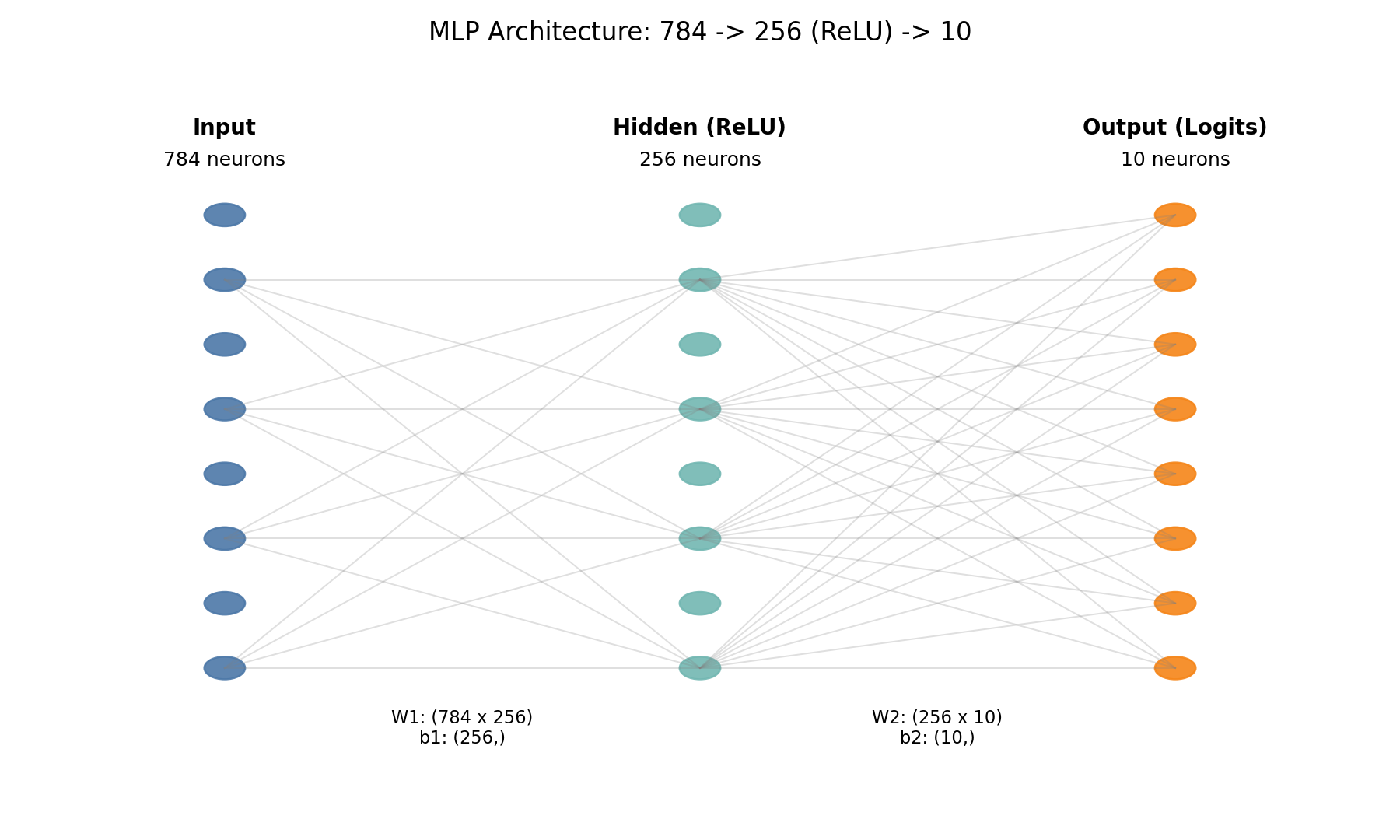
多层感知机的从零实现
"""Fashion-MNIST 多层感知机(MLP)手动实现示例。
本脚本从零开始搭建一个单隐藏层的多层感知机:
输入层(784) -> 隐藏层(256, ReLU) -> 输出层(10)
手动定义权重参数、前向传播和 ReLU 激活,不使用 nn.Module 封装。
"""
import torch
# 导入 PyTorch 的神经网络模块,这里主要用到 nn.Parameter 来标记可训练参数。
from torch import nn
# 导入 d2l 的 PyTorch 工具集合,用于快速加载数据集和训练辅助。
from d2l import torch as d2l
# 每个小批量(mini-batch)包含的样本数量。
batch_size = 256
# 加载 Fashion-MNIST 数据集,返回训练集与测试集的迭代器。
# 每次迭代返回 (X, y),X 形状为 (batch_size, 1, 28, 28),y 形状为 (batch_size,)。
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
num_inputs = 784 # 每张图像展平后的像素数量(28×28 = 784)
num_outputs = 10 # 分类类别数量(Fashion-MNIST 共 10 类服装)
num_hiddens = 256 # 隐藏层神经元数量(超参数,可调)
# ===== 手动初始化模型参数 =====
# 网络结构: 输入(784) -> 隐藏层(256) -> 输出(10)
#
# W1: 输入层到隐藏层的权重矩阵,形状 (784, 256)
# 用均值 0、标准差 0.01 的正态分布初始化,防止初始输出过大。
W1 = nn.Parameter(torch.randn(num_inputs, num_hiddens, requires_grad=True) * 0.01)
# b1: 隐藏层的偏置向量,形状 (256,),初始化为全零。
b1 = nn.Parameter(torch.zeros(num_hiddens), requires_grad=True)
# W2: 隐藏层到输出层的权重矩阵,形状 (256, 10)
W2 = nn.Parameter(torch.randn(num_hiddens, num_outputs, requires_grad=True) * 0.01)
# b2: 输出层的偏置向量,形状 (10,),初始化为全零。
b2 = nn.Parameter(torch.zeros(num_outputs), requires_grad=True)
params = [W1, b1, W2, b2] # 将所有参数放在一个列表中,便于后续优化器更新
def relu(X):
"""ReLU 激活函数,输入张量 X,输出张量中每个元素为 max(0, x)。"""
return torch.max(input=X, other=torch.tensor(0.0))
def net(X):
"""定义前向传播函数,输入 X 形状为 (batch_size, 1, 28, 28)。"""
X = X.reshape(-1, num_inputs) # 将输入展平为 (batch_size, 784)
H = relu(X @ W1 + b1) # 隐藏层线性变换后应用 ReLU 激活,形状 (batch_size, 256)
return H @ W2 + b2 # 输出层线性变换,形状 (batch_size, 10)
loss = nn.CrossEntropyLoss() # 定义交叉熵损失函数,适用于多分类问题
num_epochs, lr = 10, 0.1 # 训练轮数和学习率
updater = torch.optim.SGD(params, lr=lr) # 定义随机梯度下降优化器,更新模型参数
def accuracy(y_hat, y):
"""计算一个批次中预测正确的样本数。"""
if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:
y_hat = y_hat.argmax(dim=1)
cmp = y_hat.type(y.dtype) == y
return float(cmp.type(y.dtype).sum())
def evaluate_accuracy(net, data_iter):
"""在给定数据集上计算整体准确率。"""
correct, total = 0.0, 0
with torch.no_grad():
for X, y in data_iter:
correct += accuracy(net(X), y)
total += y.numel()
return correct / total
def train_ch3(net, train_iter, test_iter, loss_fn, num_epochs, updater):
"""替代 d2l.train_ch3:执行训练并打印每轮指标。"""
for epoch in range(num_epochs):
train_loss_sum, train_acc_sum, count = 0.0, 0.0, 0
for X, y in train_iter:
updater.zero_grad()
y_hat = net(X)
l = loss_fn(y_hat, y)
l.backward()
updater.step()
# 统计本轮训练损失与准确率。
train_loss_sum += float(l) * y.numel()
train_acc_sum += accuracy(y_hat, y)
count += y.numel()
train_loss = train_loss_sum / count
train_acc = train_acc_sum / count
test_acc = evaluate_accuracy(net, test_iter)
print(
f'epoch {epoch + 1:02d}: '
f'train loss={train_loss:.4f}, train acc={train_acc:.4f}, test acc={test_acc:.4f}'
)
def predict_ch3(net, test_iter, n=6):
"""替代 d2l.predict_ch3:展示前 n 个样本的真实标签与预测标签。"""
X, y = next(iter(test_iter))
trues = d2l.get_fashion_mnist_labels(y)
preds = d2l.get_fashion_mnist_labels(net(X).argmax(dim=1))
titles = [true + '\n' + pred for true, pred in zip(trues, preds)]
d2l.show_images(X[0:n].reshape((n, 28, 28)), 1, n, titles=titles[0:n])
train_ch3(net, train_iter, test_iter, loss, num_epochs, updater) # 训练模型并评估性能
predict_ch3(net, test_iter) # 在测试集上进行预测,展示结果
单层 Softmax
- 权重 $W$: $784 \times 10 = 7,840$
- 偏置 $b$: $10$
- 总计: 7,850 个参数。
单隐藏层 MLP
- 第一层 ($W_1, b_1$): $784 \times 256 + 256 = 200,960$
- 第二层 ($W_2, b_2$): $256 \times 10 + 10 = 2,570$
- 总计: 203,530 个参数。
MLP 的参数量增加了约 26 倍。这带来的直接后果是
- 更强的拟合能力:能记住更复杂的图像模式(如衣服的褶皱、袖口特征)。
- 更高的过拟合风险:如果数据量不足,MLP 可能会死记硬背训练集。
- 计算开销:训练时间会比 Softmax 长,但对于现在的 GPU 来说这点差异几乎可以忽略。
决策边界的表现
Softmax 回归: 它的决策边界是直线(或超平面)。它假设“T恤”和“裙子”可以通过在像素空间切一刀来完美区分。
MLP: 它的决策边界可以是复杂的曲线。对于 Fashion-MNIST 这种类内差异大的数据集(比如不同款式的裙子),MLP 能更好地捕捉这些细微的非线性变化。
训练表现预估 (Fashion-MNIST)
在相同的学习率和迭代次数下,你通常会观察到:
- 训练损失 (Train Loss):MLP 的下降速度通常比 Softmax 快,最终 Loss 更低。
- 准确率 (Accuracy):
- Softmax 通常在 83%-85% 左右遇到瓶颈。
- 单隐藏层 MLP (256 神经元) 很容易达到 87%-89%。
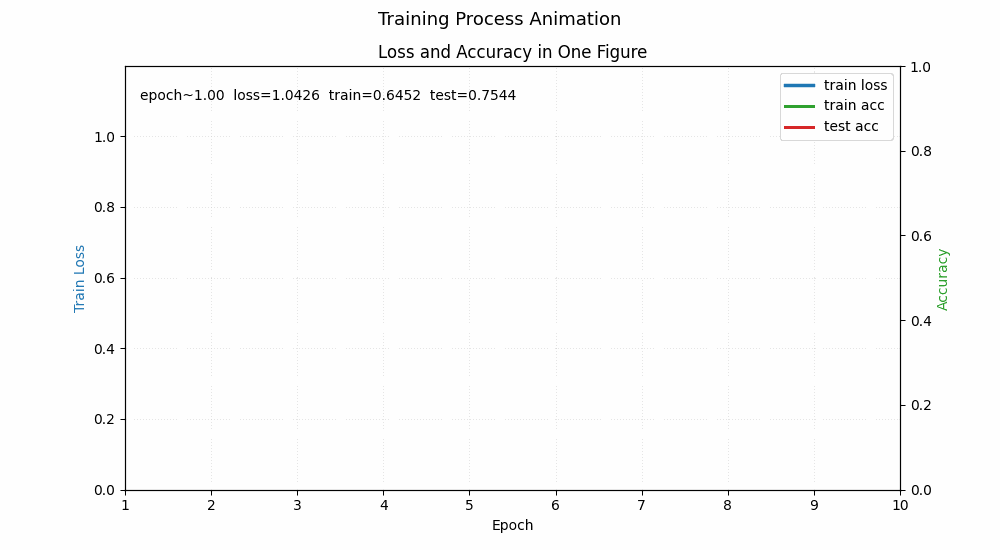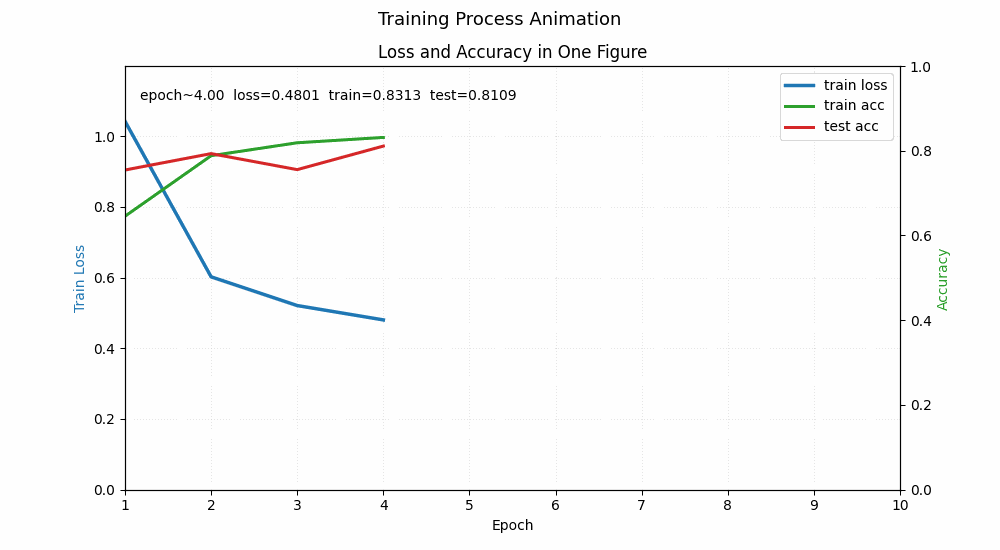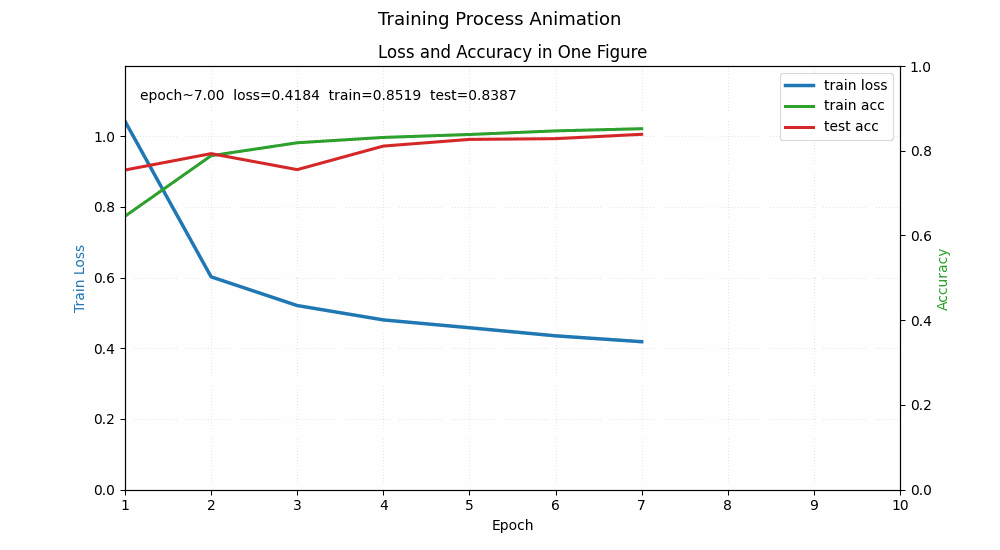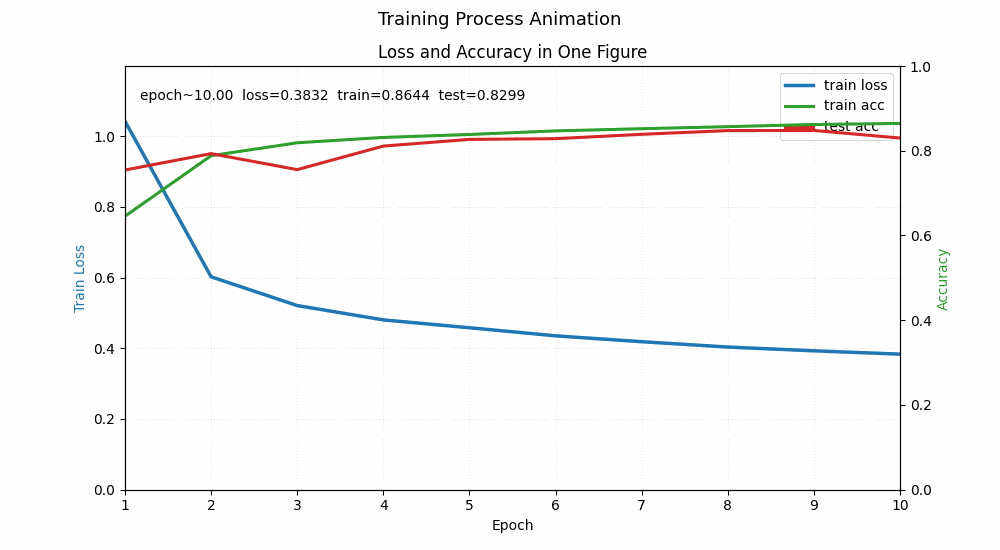
单层和双层模型对比
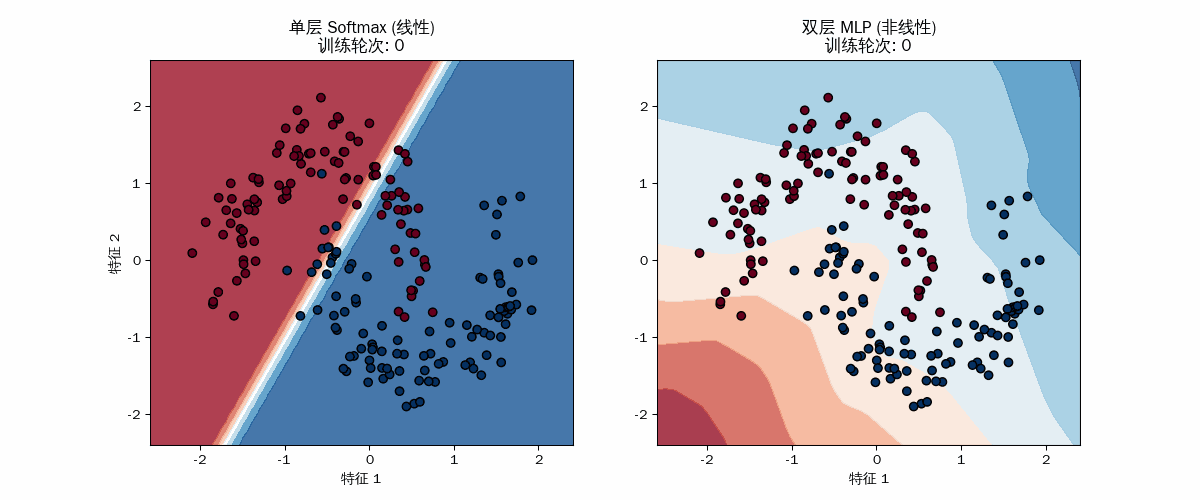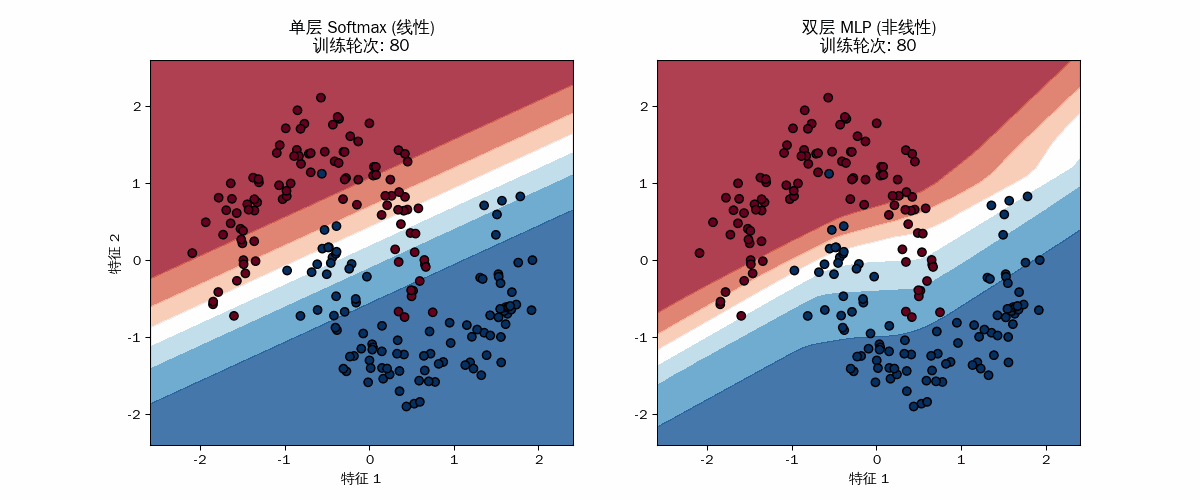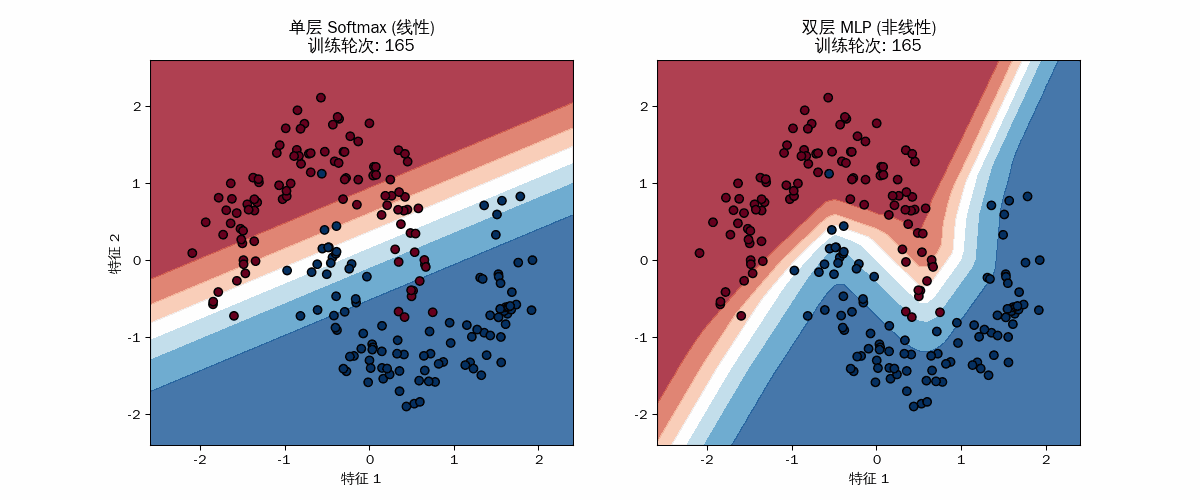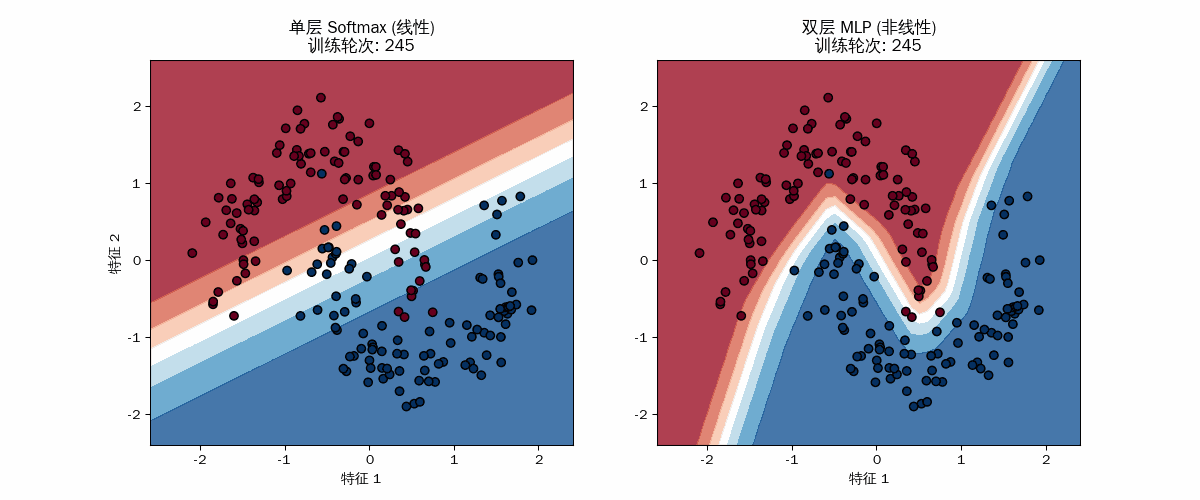
线性模型的“无奈”
你会发现左图的直线在训练初期会剧烈抖动,试图找到一个能同时切开两个月牙的位置。但随着训练进行,它最终会卡在一个尴尬的位置(通常是中间横切)。
几何限制:它的自由度只有 $W$(斜率)和 $b$(截距)。
MLP 的“折叠与进化”
右图的边界初期也是模糊的,但很快它就开始弯曲。
几何表现:你可以看到颜色区域(概率分布)像橡皮泥一样被拉伸、弯曲,最终形成一个类 “S” 形的口袋,将蓝点包裹进去。数学本质:每一轮 partial_fit 都在调整那 20 个隐藏神经元的权重。每个神经元负责平面上的一个“折痕”,20 个折痕共同组合成了这种复杂的非线性边界。
Fashion-MNIST 单层和双层对比
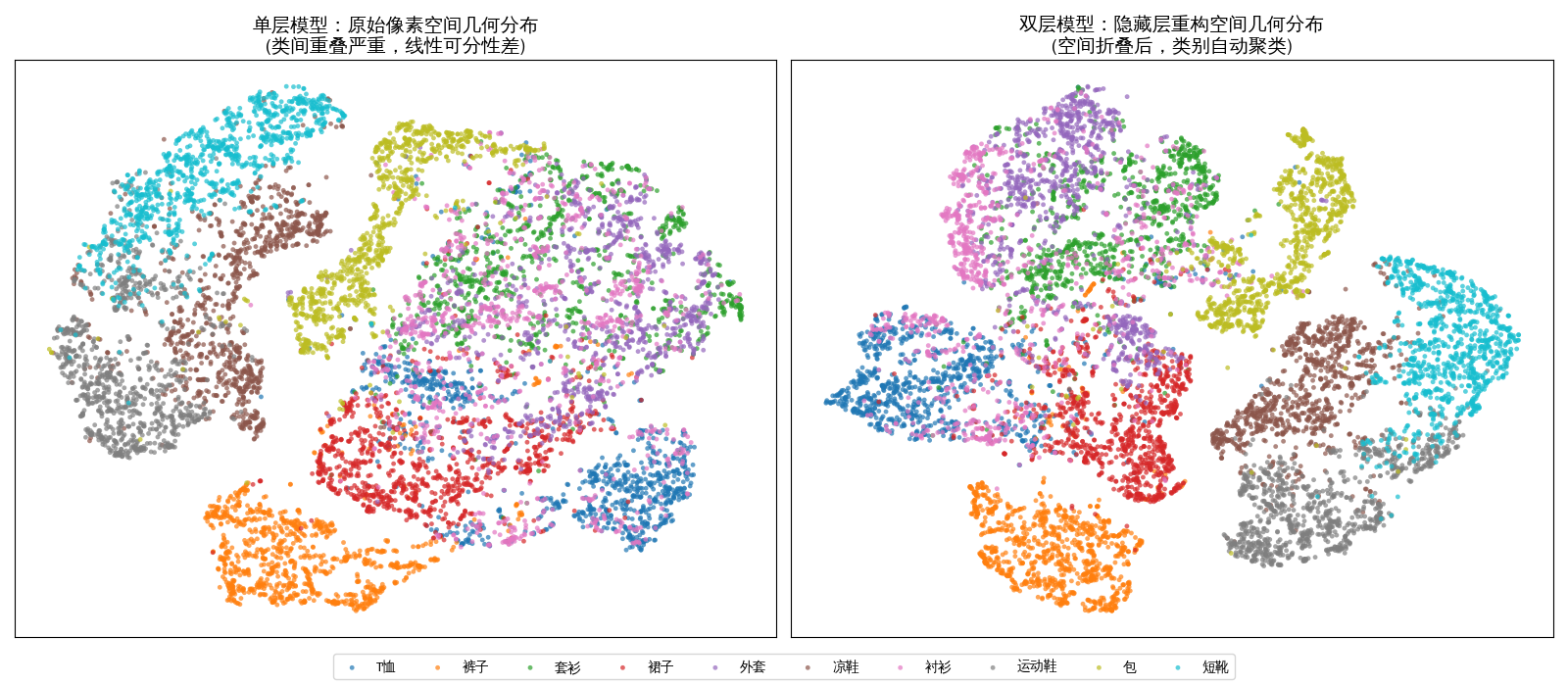
左图 (线性视角):数据点像一团乱麻,尤其是“外套”和“套衫”,因为在线性像素空间它们距离太近。右图 (非线性视角):你会发现聚类(Clustering)现象非常明显。这是因为隐藏层的权重 $W_1$ 将空间进行了“非线性扭曲”,把原本混杂的衣服按特征自动分堆了
双层的空间折叠过程
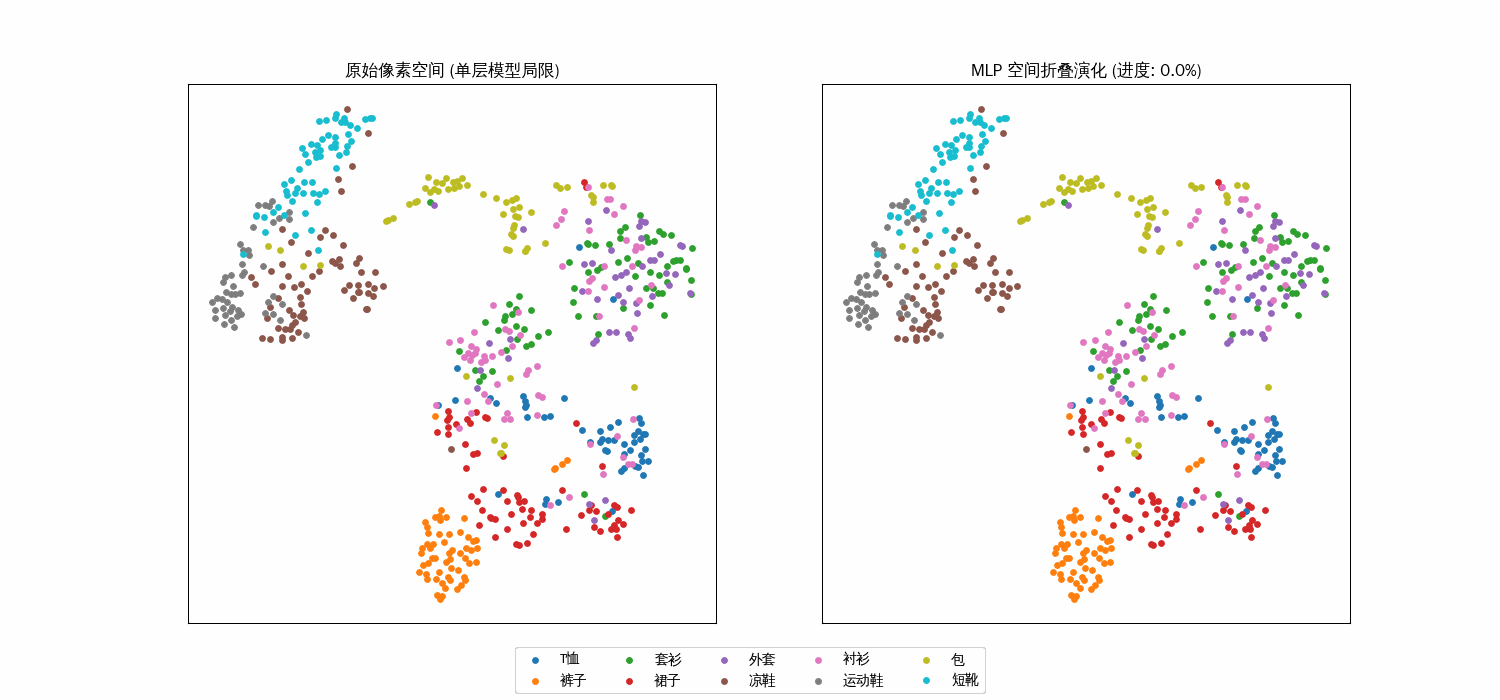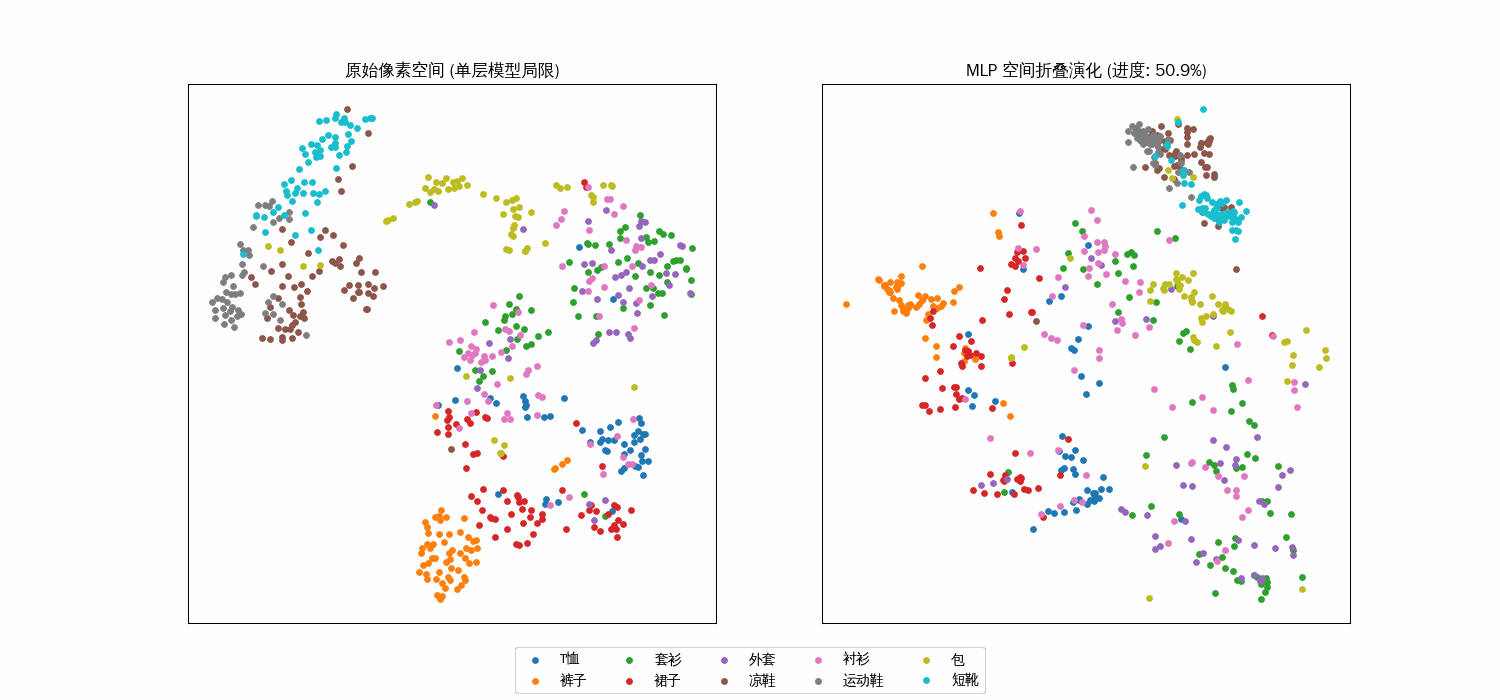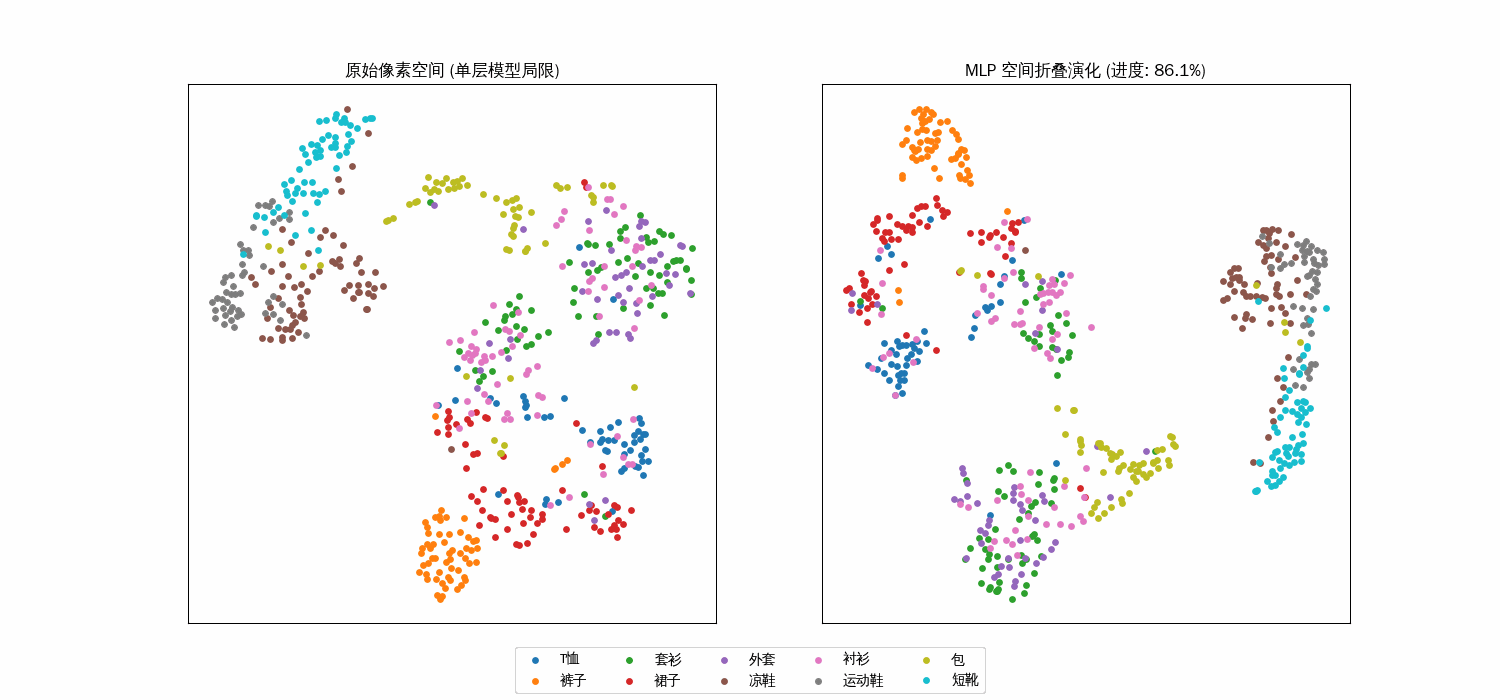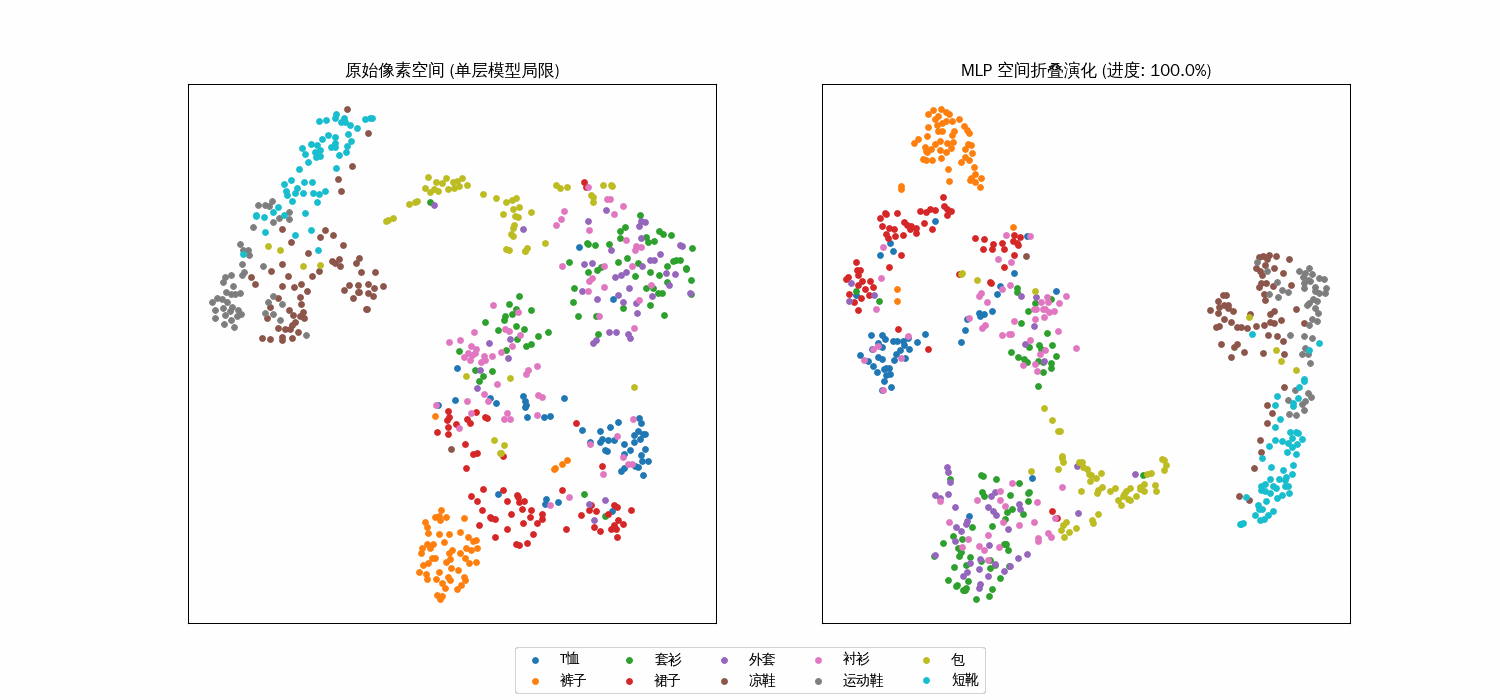
从“混沌”到“秩序”:类间的分离度
在左侧的原始像素空间(单层模型视角)中,你会发现不同颜色的点(代表不同种类的衣服)是高度交织在一起的。
几何现状:例如“衬衫”、“T恤”和“外套”,它们的像素分布极其相似。在 784 维的空间里,它们离得非常近。线性局限:单层 Softmax 只能在这些乱成一团的点之间画“直线”来切分。因为点本身就重叠,所以无论直线怎么摆放,总会切错。动画表现:你会看到点几乎不怎么移动,或者只是微小的平移,说明模型无法改变数据的本质分布。
右侧的隐藏层特征空间(双层 MLP 视角)中
聚类效应:随着动画演化(即 $\alpha$ 趋向 1),原本混杂在一起的点开始像受到了引力一样,向各自的中心靠拢,形成了一个个独立的簇(Clusters)。空间拉伸:模型通过权重矩阵 $W_1$ 将那些容易混淆的类别“拉开”了距离。
核心数学机制:空间折叠 (Space Folding)
这个动画展示的其实是 ReLU 激活函数在几何上的威力。
折痕(Crease):隐藏层中的每一个神经元都相当于在 784 维空间中划出了一道“折痕”。折叠(Fold):ReLU 函数会将所有负值部分压缩(折叠)到零。就像你在折纸时,把不需要的部分叠到背面去。投影:当你有 256 个神经元时,相当于对原始空间进行了 256 次复杂的折叠。折完之后,原本在 2D 投影上重叠的点,在折叠后的高维空间里其实已经各就各位了。
过拟合的原因
模型复杂度过高(“杀鸡用牛刀”)
如果你的网络层数太深、隐藏层神经元太多,而问题本身很简单,模型就会利用其强大的拟合能力去“硬背”数据。
几何表现:模型原本只需要画一条平滑的曲线,但因为它参数太多,它会画出一条极其扭曲、绕过每一个数据点的“锯齿线”。
训练数据量太少(“见识太短”)
如果模型见过的样本太少,它会把某些“偶然特征”当成“必然规律”。
例子:如果你只给模型看过 3 张红色的裙子,它可能会认为“只要是红色的就是裙子”,从而忽略了形状特征。几何表现:在降维空间里,由于点太稀疏,模型可以轻易地在这些点周围画出“包围圈”,而没有意识到这些点之间其实应该有其他类别的空间。
训练轮次(Epoch)过多(“书呆子”)
训练时间越长,模型对训练集的损失(Loss)就越低,但这种低损耗有时是靠“背诵”换来的。
数据中存在过多噪声(“被带偏了”)
如果你的 Fashion-MNIST 标签里,有一部分明明是“包”却被错误标成了“衬衫”,强大的模型会试图去解释这个错误。
训练大模型的经验科学
如果说传统的软件工程是建筑学(每一块砖怎么摆都有精确的蓝图),那么训练大模型更像是材料学或生物实验(你把各种成分丢进反应炉,在极高温高压下等待某种奇迹的发生)
大模型训练之所以被称为工程问题,是因为它需要解决“理想数学模型”与“真实物理世界”之间的巨大摩擦。
数学:告诉你 $y = f(x)$ 应该收敛。现实:显卡断电了、内存溢出了、数据里混进了乱码、浮点数精度不够了。
突发性损失尖峰 (Loss Spikes)
这是所有大模型工程师的噩梦。模型可能已经平稳训练了两周,一切看起来都很完美,突然之间,Loss 曲线毫无征兆地像火山爆发一样冲向无穷大(NaN)
不可解释性:从数学上很难立刻定位是哪一个 Batch 的哪一张图片或哪一段话导致了梯度的剧烈抖动。经验的价值:老练的工程师会通过观察梯度范数(Gradient Norm)的微小变化,预判“崩盘”的到来。他们积累了一套“急救措施”,比如回退到前一个 Checkpoint,并跳过那段有毒的数据,或者临时调低学习率。
智能的“涌现” (Emergence)
大模型的智能并不是线性增长的。在训练的前期,它可能看起来像个复读机,只会胡言乱语。但当计算量(FLOPs)跨过某个神秘的阈值时,它会突然表现出逻辑推理、代码编写甚至幽默感。
不可解释性:目前数学上还没有完美的理论能解释为什么 100 亿参数的模型没有的能力,在 130 亿参数时会突然出现。经验的价值:经验决定了你是否敢在模型表现平平的前期“拿钱坚持下去”。很多团队因为缺乏经验,在黎明前的黑暗里觉得模型练废了,提前关机,从而错过了“涌现”的时刻。
超参数的“玄学”组合
神经网络里有无数的旋钮:学习率、Batch Size、权重衰减、热身步数(Warmup steps)等等。
不可解释性:这些参数之间存在极其复杂的非线性耦合。换了一批数据,原来的最优参数可能就失效了。经验的价值:这被称为“调参直觉”。顶尖工程师脑子里有一张隐形的“地图”,他们能根据当前模型在验证集上的细微表现(比如某种词性的预测错误率偏高),直觉般地判断出是哪个“旋钮”拧得不对。