几何理解
在深度学习中,暂退法(Dropout) 是一种非常经典且高效的正则化技术
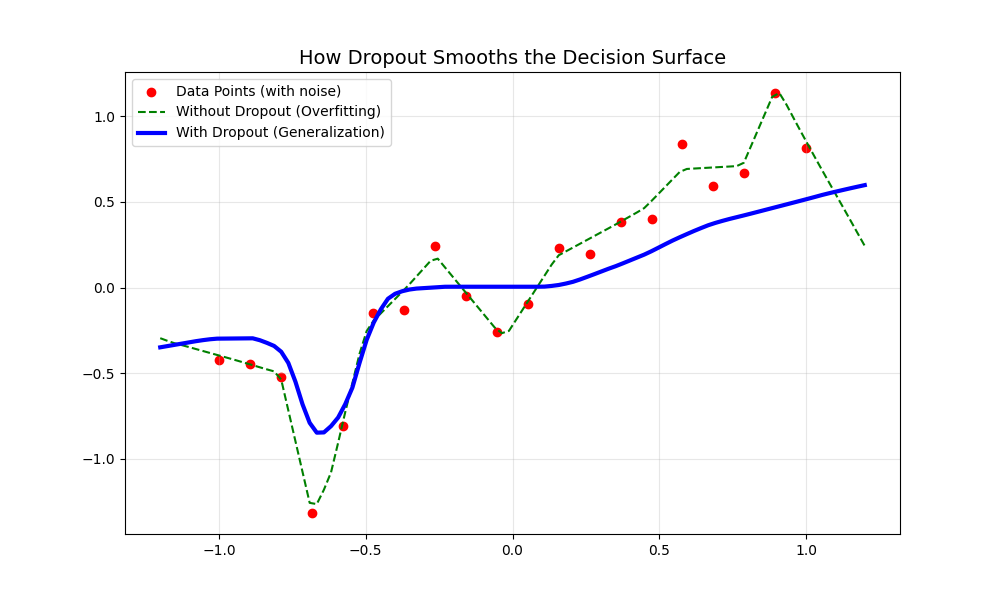
绿虚线(无 Dropout):你会发现它在数据点之间频繁地“上下跳跃”。在几何上,这意味着它的曲率(Curvature)非常大。它记住了每一个数据点的扰动,这在处理没见过的数据时表现会很差。
蓝实线(有 Dropout):虽然它没能 100% 穿过每一个点,但它的走势非常稳健、平滑。
- 几何理解:因为训练时随机丢弃了神经元,模型无法利用“特定路径”去死记硬背。它被迫学习一种“平均特征”。
- 结果:流形表面的褶皱被磨平了,剩下的就是数据中最核心的线性规律。
偏差-方差权衡(Bias-Variance Tradeoff)
线性模型(高偏差,低方差):
偏差(Bias):由于模型太简单(比如只能画直线),它对复杂规律有“成见”,根本学不会。方差(Variance):因为它简单,不管你换哪一批数据训练,它画出来的直线都差不多,表现很稳定。
神经网络(低偏差,高方差):
偏差(Bias):几乎可以模拟任何函数,只要给它数据,它能学会最精细的细节。方差(Variance):由于太灵活,它会把特定数据集里的随机噪声也当成规律记下来。换一批数据,它学出来的规律可能完全不同。
为什么深度网络能学到“特征交互”?
线性模型像是在做加法:$y = w_1 x_1 + w_2 x_2 + \dots$。每个特征的贡献是独立的。
而神经网络通过多层嵌套和激活函数(如 ReLU),实质上在做乘法或非线性逻辑判断:
- 第一层:检测是否包含“尼日利亚”。
- 第二层:检测是否包含“西联汇款”。
- 第三层(交互):如果(第一层=1 且 第二层=1),则输出“垃圾邮件”。
数学表达
对于输入 $x$ 和丢弃概率 $p$(即代码中的 dropout),输出 $h$ 的计算如下:
\[h = \begin{cases} 0 & \text{以概率 } p \\ \frac{x}{1-p} & \text{以概率 } 1-p \end{cases}\]为什么需要除以 $(1-p)$?
为了保持输出的期望值(平均值)和原始输入一致。
从零开始实现
import torch
from torch import nn
from d2l import torch as d2l
def dropout_layer(X, dropout):
"""执行 dropout"""
# dropout 概率必须在 [0, 1] 区间内
# 例如 dropout=0.2 表示有 20% 的神经元输出会被随机置 0
assert 0 <= dropout <= 1
# 边界情况 1:dropout=1
# 所有神经元都被丢弃,输出全 0(和输入形状一致)
if dropout == 1:
return torch.zeros_like(X)
# 边界情况 2:dropout=0
# 不做任何丢弃,直接返回原输入
if dropout == 0:
return X
# 生成与输入 X 同形状的随机掩码 mask:
# - torch.rand(X.shape) 会生成 [0,1) 的均匀随机数
# - 大于 dropout 的位置保留(值为 1),其余位置丢弃(值为 0)
# - 转成 float 后,mask 中元素只会是 0.0 或 1.0
mask = (torch.rand(X.shape) > dropout).float()
# 先用 mask 把一部分神经元输出置零,再除以 (1-dropout) 做缩放
# 这叫“反向 dropout(inverted dropout)”:
# 训练时做缩放,保证输出的期望值与不使用 dropout 时一致,
# 这样推理阶段就不需要再额外缩放。
return mask * X / (1.0 - dropout)
X = torch.arange(16, dtype=torch.float32).reshape((2, 8)) # 输入张量,形状为 (2, 8)
print('原始输入:\n', X)
print('丢弃概率为 0.0:\n', dropout_layer(X, 0.0))
print('丢弃概率为 0.5:\n', dropout_layer(X, 0.5))
print('丢弃概率为 1.0:\n', dropout_layer(X, 1.0))
运行结果
原始输入:
tensor([[ 0., 1., 2., 3., 4., 5., 6., 7.],
[ 8., 9., 10., 11., 12., 13., 14., 15.]])
丢弃概率为 0.0:
tensor([[ 0., 1., 2., 3., 4., 5., 6., 7.],
[ 8., 9., 10., 11., 12., 13., 14., 15.]])
丢弃概率为 0.5:
tensor([[ 0., 2., 4., 0., 0., 0., 12., 14.],
[ 0., 18., 0., 0., 24., 26., 28., 0.]])
丢弃概率为 1.0:
tensor([[0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0.]])
看你运行结果中 dropout = 0.5 的部分:
- 原始输入中的 1. 变成了 2.(因为 $1 / (1-0.5) = 2$)
- 原始输入中的 9. 变成了 18.(因为 $9 / 0.5 = 18$)
这正是补偿机制的体现:活下来的神经元“变强了”一倍,以弥补死掉的那一半神经元留下的空位。
期望值不变
# 用多次随机实验验证:反向 dropout 后,输出的期望值(均值)与输入均值接近
def check_expectation(X, dropout, trials=5000):
input_mean = X.mean().item()
output_means = []
for _ in range(trials):
output_means.append(dropout_layer(X, dropout).mean().item())
output_mean = sum(output_means) / trials
diff = abs(output_mean - input_mean)
print(f"\n[期望值检验] dropout={dropout}")
print(f"输入均值: {input_mean:.4f}")
print(f"输出均值的经验期望(试验{trials}次): {output_mean:.4f}")
print(f"两者绝对差: {diff:.6f}")
check_expectation(X, dropout=0)
check_expectation(X, dropout=0.2)
check_expectation(X, dropout=0.5)
check_expectation(X, dropout=0.8)
check_expectation(X, dropout=1.0)
运行结果
[期望值检验] dropout=0
输入均值: 7.5000
输出均值的经验期望(试验5000次): 7.5000
两者绝对差: 0.000000
[期望值检验] dropout=0.2
输入均值: 7.5000
输出均值的经验期望(试验5000次): 7.5021
两者绝对差: 0.002094
[期望值检验] dropout=0.5
输入均值: 7.5000
输出均值的经验期望(试验5000次): 7.4755
两者绝对差: 0.024550
[期望值检验] dropout=0.8
输入均值: 7.5000
输出均值的经验期望(试验5000次): 7.5113
两者绝对差: 0.011250
[期望值检验] dropout=1.0
输入均值: 7.5000
输出均值的经验期望(试验5000次): 0.0000
两者绝对差: 7.500000
当 dropout = 1.0 时,意味着所有的神经元输出都会被丢弃(置为 0)。
定义模型
# =========================
# 下面开始定义一个多层感知机(MLP)用于分类任务
# =========================
# num_inputs: 输入特征维度(例如 Fashion-MNIST 的 28x28=784)
# num_outputs: 输出类别数(10 类)
# num_hiddens1/num_hiddens2: 两个隐藏层的神经元数量
num_inputs, num_outputs, num_hiddens1, num_hiddens2 = 784, 10, 256, 256
# 两层 dropout 概率:
# 第一层隐藏层后丢弃 20%
# 第二层隐藏层后丢弃 50%
dropout1, dropout2 = 0.2, 0.5
class Net(nn.Module):
# 这是一个“线性层 + ReLU + Dropout + 线性层 + ReLU + Dropout + 输出层”的网络
def __init__(self, num_inputs, num_outputs, num_hiddens1, num_hiddens2,
dropout1, dropout2):
super(Net, self).__init__()
# 保存 dropout 概率,forward 时会用到
self.dropout1 = dropout1
self.dropout2 = dropout2
# 第1层:输入维度 -> 第1隐藏层
self.linear1 = nn.Linear(num_inputs, num_hiddens1)
# 第2层:第1隐藏层 -> 第2隐藏层
self.linear2 = nn.Linear(num_hiddens1, num_hiddens2)
# 输出层:第2隐藏层 -> 类别数
self.linear3 = nn.Linear(num_hiddens2, num_outputs)
def forward(self, X):
# X.reshape(-1, self.linear1.in_features):
# 把输入展平到 [batch_size, 784] 的二维张量
H1 = torch.relu(self.linear1(X.reshape(-1, self.linear1.in_features)))
# 第1个隐藏层后做 dropout
H1 = dropout_layer(H1, self.dropout1)
# 第2个隐藏层:线性变换 + ReLU
H2 = torch.relu(self.linear2(H1))
# 第2个隐藏层后做 dropout
H2 = dropout_layer(H2, self.dropout2)
# 输出层给出每个类别的打分(logits)
out = self.linear3(H2)
return out
# 实例化网络对象
net = Net(num_inputs, num_outputs, num_hiddens1, num_hiddens2, dropout1, dropout2)
print(net)
模型结构
输入层
784
│
▼
Linear(784 → 256)
│
▼
ReLU
│
▼
Dropout(0.2)
│
▼
Linear(256 → 256)
│
▼
ReLU
│
▼
Dropout(0.5)
│
▼
Linear(256 → 10)
│
▼
logits
| 层 | 参数 |
|---|---|
| 784→256 | 784×256 + 256 = 200960 |
| 256→256 | 256×256 + 256 = 65792 |
| 256→10 | 256×10 + 10 = 2570 |
总参数:≈ 269k
更接近论文/教材风格的 MLP 神经网络结构图
输入层 (784)
● ● ● ● ● ⋯ ●
x1 x2 x3 x4 x5 x784
\ | | | | /
\ | | | | /
\ | | | | /
\| | | | /
\ | | | /
\ | | | /
\ | | | /
\| | | /
\ | | /
\ | | /
\ | | /
\| | /
\ | /
\ | /
\ | /
\|/
第一隐藏层 (256)
● ● ● ● ⋯ ●
h1 h2 h3 h4 h256
ReLU
│
│
Dropout (p=0.2)
│
│
第二隐藏层 (256)
● ● ● ● ⋯ ●
g1 g2 g3 g4 g256
ReLU
│
│
Dropout (p=0.5)
│
│
输出层 (10)
● ● ● ● ● ⋯ ●
o1 o2 o3 o4 o5 o10
(logits)
训练和测试
def train_ch3_compat(net, train_iter, test_iter, loss_fn, num_epochs, optimizer):
"""兼容版 train_ch3:完成训练并返回过程指标。"""
# 用于记录每个 epoch 的指标,后续可用于画图
train_losses, train_accs, test_accs = [], [], []
# 逐轮训练
for epoch in range(num_epochs):
# 切换到训练模式(会启用 dropout 等训练行为)
net.train()
# 统计一个 epoch 内的损失总和、预测正确数、样本总数
loss_sum, acc_sum, n = 0.0, 0.0, 0
# 遍历一个 epoch 中的所有小批量
for X, y in train_iter:
# 清空上一步的梯度,避免梯度累计
optimizer.zero_grad()
# 前向计算预测值
y_hat = net(X)
# 计算每个样本的损失(因为 loss_fn 使用了 reduction='none')
l = loss_fn(y_hat, y)
# 反向传播:这里用 mean() 聚合后再求梯度,训练更稳定
l.mean().backward()
# 参数更新
optimizer.step()
# 累计该批次的总损失
loss_sum += float(l.sum())
# 累计该批次预测正确的样本数
acc_sum += float((y_hat.argmax(dim=1) == y).type(torch.float32).sum())
# 累计样本总数
n += y.numel()
# 计算该 epoch 的平均训练损失和训练准确率
train_loss = loss_sum / n
train_acc = acc_sum / n
# 在测试集上评估准确率(函数内部会切到 eval 模式)
test_acc = evaluate_accuracy(net, test_iter)
# 保存本轮指标,用于后续可视化
train_losses.append(train_loss)
train_accs.append(train_acc)
test_accs.append(test_acc)
# 打印当前 epoch 的训练过程信息
print(f"epoch {epoch + 1}/{num_epochs}, "
f"train loss {train_loss:.4f}, "
f"train acc {train_acc:.4f}, "
f"test acc {test_acc:.4f}")
# 返回三条曲线数据:训练损失、训练准确率、测试准确率
return train_losses, train_accs, test_accs
# 训练配置:
# num_epochs: 训练轮数(完整遍历训练集的次数)
# lr: 学习率(每次参数更新的步长)
# batch_size: 每个小批量的样本数
num_epochs, lr, batch_size = 10, 0.5, 256
# 交叉熵损失(分类任务常用)
# reduce='none' 表示先保留每个样本的损失,后续由训练函数再做聚合
loss = nn.CrossEntropyLoss(reduce='none')
# 加载 Fashion-MNIST 训练集和测试集迭代器
# train_iter: 训练数据迭代器
# test_iter: 测试数据迭代器
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
# 随机梯度下降优化器,负责根据梯度更新网络参数
trainer = torch.optim.SGD(net.parameters(), lr=lr)
# 使用 d2l 提供的通用训练流程:
# 每轮会执行训练、在测试集评估,并输出训练损失/训练准确率/测试准确率
train_ch3_compat(net, train_iter, test_iter, loss, num_epochs, trainer)
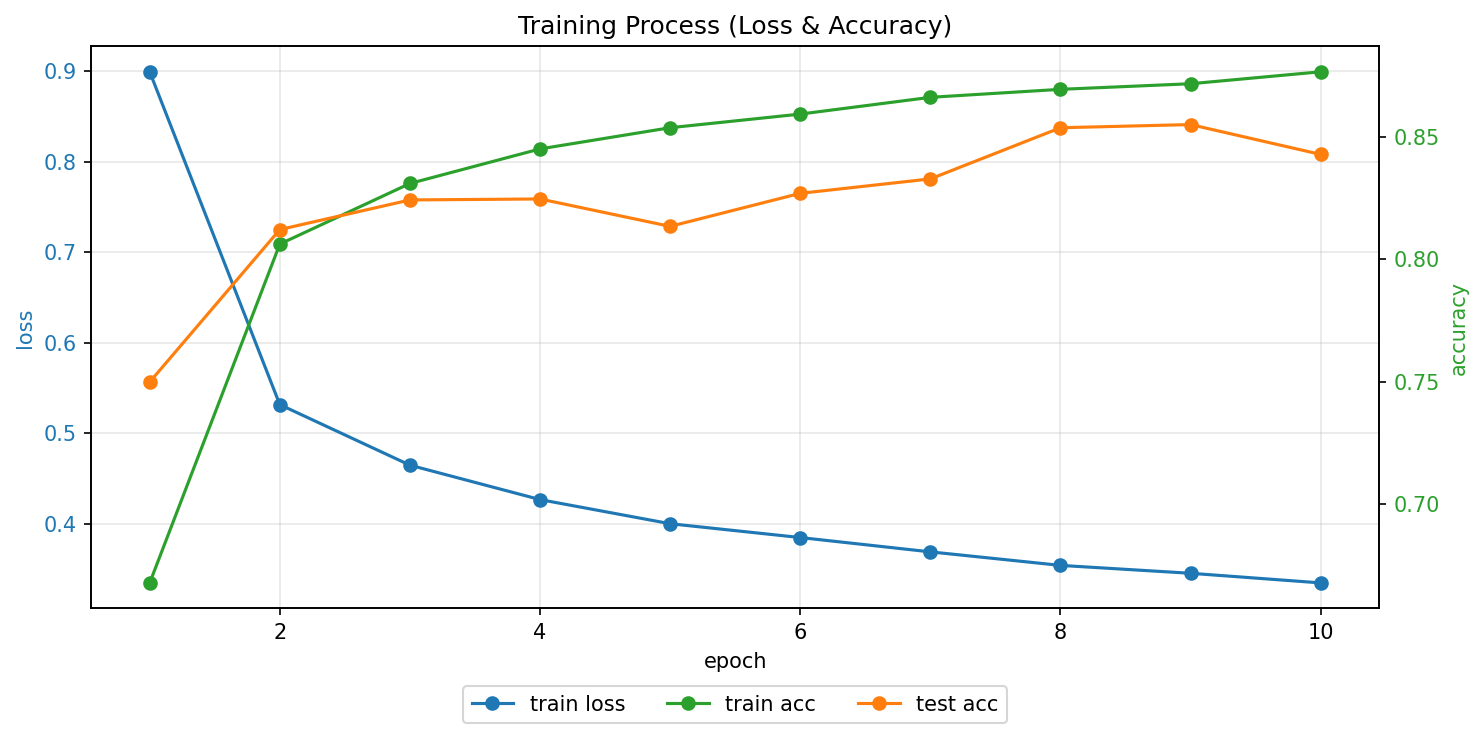
训练过程曲线
Dropout 本质
原始完整网络(没有 Dropout)
输入层 隐藏层1 隐藏层2 输出层
● ● ● ● ● ● ● ● ● ● ● ● ● ●
\ | | / |\ |\ |\ | |\ |\ |\ | | |
\| |/ | X| X| X| | X| X| X| | |
/| |\ |/ |/ |/ | |/ |/ |/ | | |
/ | | \ ● ● ● ● ● ● ● ● ● ●
- 所有神经元都参与计算
- 某些神经元会形成“依赖关系”
- 模型可能只依赖少数几个特征
第一次训练(Dropout 随机关闭部分神经元)
Dropout = 0.5 随机关闭一部分神经元
输入层 隐藏层1 隐藏层2 输出层
● ● ● ● ● X ● X ● ● X ● ● ●
\ | | / |\ |\ |\ | | |
\| |/ | X X| | X | | |
/| |\ |/ |/ |/ | | |
/ | | \ ● X ● X ● ● X ● ● ●
X 表示:该神经元被关闭
784 → 128 → 128 → 10
第二次训练(新的子网络)
输入层 隐藏层1 隐藏层2 输出层
● ● ● ● X ● ● X ● X ● ● ● ●
\ | | / |\ |\ | |\ | |
\| |/ | X| | | | |
/| |\ |/ | | | | |
/ | | \ X ● ● X ● X ● ● ● ●
又是完全不同的网络
如果训练 10000 step
实际训练的是:10000 个不同的子网络, 但它们:共享参数
Dropout 的真正本质
Dropout ≈ 模型集成 (Ensemble)
model1
model2
model3
...
model10000
最后相当于:把很多模型平均
集成学习本身就是防止过拟合最强的方法之一
有无dropout的对比
权重分布直方图
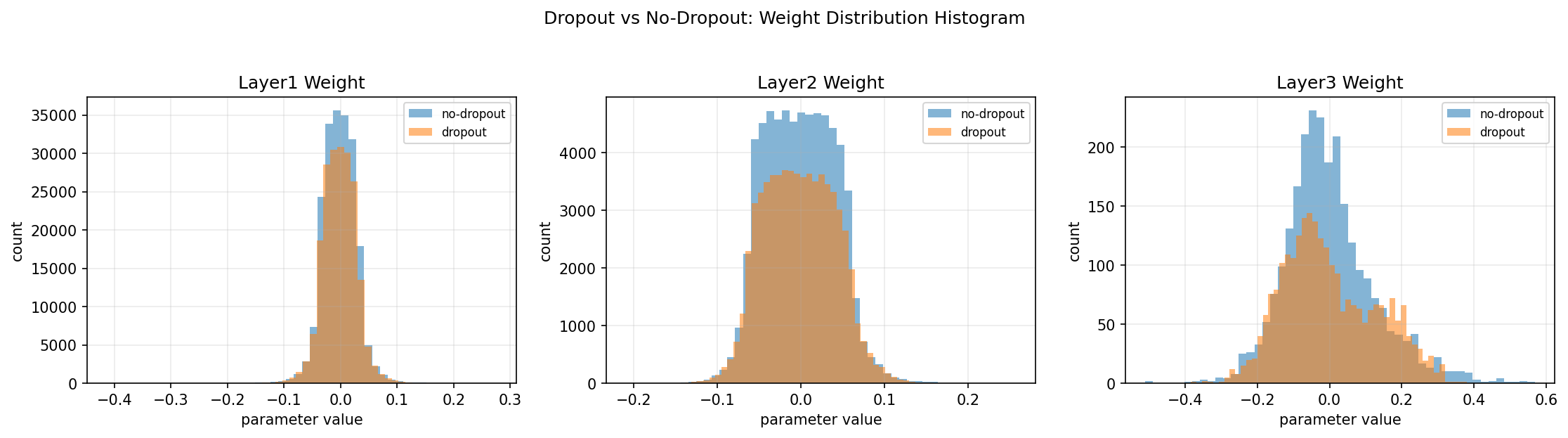
Layer1 Weight
dropout 让参数 稍微更分散, 但差异 非常小
这是正常的,因为 第一层通常受 dropout 影响最小
Layer2 Weight
这一层的差异开始稍微明显:
- dropout 分布 略微更平
- no-dropout 更集中
Layer3 Weight(最明显)
三层你可以看到:
- dropout 右尾更长
- 分布 更宽
说明:
- 最后一层更依赖上层特征
- dropout 造成 特征不稳定
- 权重需要 补偿
总结
| 观察 | 含义 |
|---|---|
| 均值几乎相同 | dropout 保持期望 |
| 分布略微更宽 | dropout 引入噪声 |
| 高层差异更大 | 特征不稳定传播 |
Activation Sparsity Plot(激活稀疏度图)
一层神经元的输出有多少是 0(或接近 0)
什么叫 “稀疏”(Sparsity)
假设某一层有 1000 个神经元输出:
[0, 0, 0.3, 1.2, 0, 0.8, 0, 0, 0.5 ...]
如果:
- 600 个是 0
- 400 个非 0
稀疏(sparsity) = 600/1000 = 0.6
也就是 60% 的神经元没激活
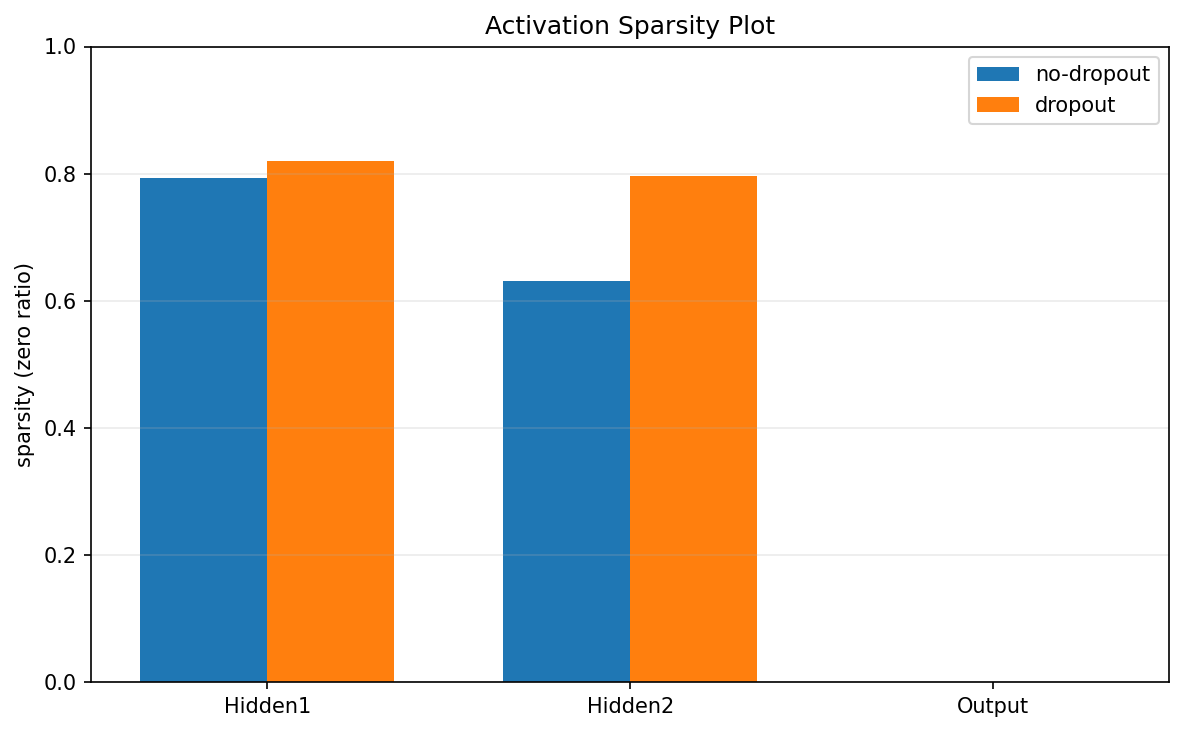
Hidden1 层
| 模型 | sparsity |
|---|---|
| no-dropout | ≈ 0.79 |
| dropout | ≈ 0.82 |
- 本来就有 79% 神经元为 0
- dropout 让它增加到 82%
Hidden2 层(差异更明显)
| 模型 | sparsity |
|---|---|
| no-dropout | ≈ 0.63 |
| dropout | ≈ 0.80 |
这是 非常典型的 Dropout 现象,Dropout 让网络中更多神经元不参与计算
为什么 Output 层没有?
Output 层通常: Softmax/Sigmoid 这些函数:几乎不会产生 0
简洁实现
import torch
import os
import matplotlib.pyplot as plt
from torch import nn
from d2l import torch as d2l
# =========================
# 下面开始定义一个多层感知机(MLP)用于分类任务
# =========================
# num_inputs: 输入特征维度(例如 Fashion-MNIST 的 28x28=784)
# num_outputs: 输出类别数(10 类)
# num_hiddens1/num_hiddens2: 两个隐藏层的神经元数量
num_inputs, num_outputs, num_hiddens1, num_hiddens2 = 784, 10, 256, 256
# 两层 dropout 概率:
# 第一层隐藏层后丢弃 20%
# 第二层隐藏层后丢弃 50%
dropout1, dropout2 = 0.2, 0.5
net = nn.Sequential(
# 把输入从 [batch, 1, 28, 28] 展平为 [batch, 784]
nn.Flatten(),
# 第1层全连接:784 -> 256
nn.Linear(num_inputs, num_hiddens1),
# 非线性激活,提升模型表达能力
nn.ReLU(),
# 第1个 dropout 层,训练时随机失活一部分神经元
nn.Dropout(dropout1),
# 第2层全连接:256 -> 256
nn.Linear(num_hiddens1, num_hiddens2),
# 第2层激活函数
nn.ReLU(),
# 第2个 dropout 层
nn.Dropout(dropout2),
# 输出层:256 -> 10,对应 10 个类别的 logits
nn.Linear(num_hiddens2, num_outputs)
)
def init_weights(m):
"""初始化模型参数"""
# 仅对线性层做初始化;偏置沿用 PyTorch 默认初始化
if type(m) == nn.Linear:
# 用标准差为 0.01 的正态分布初始化权重
nn.init.normal_(m.weight, std=0.01)
# 对网络中每个子模块执行初始化函数
net.apply(init_weights)
# 使用随机梯度下降优化器,学习率设为 0.1
trainer = torch.optim.SGD(net.parameters(), lr=0.1)
# 训练入口(取消注释后可直接训练)
# d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)