前向传播 和 反向传播
前向传播(forward propagation或forward pass) 指的是:按顺序(从输入层到输出层)计算和存储神经网络中每层的结果。
反向传播(backward propagation或backpropagation)指的是计算神经网络参数梯度的方法。 简言之,该方法根据微积分中的链式规则,按相反的顺序从输出层到输入层遍历网络。 该算法存储了计算某些参数梯度时所需的任何中间变量(偏导数)。
计算图
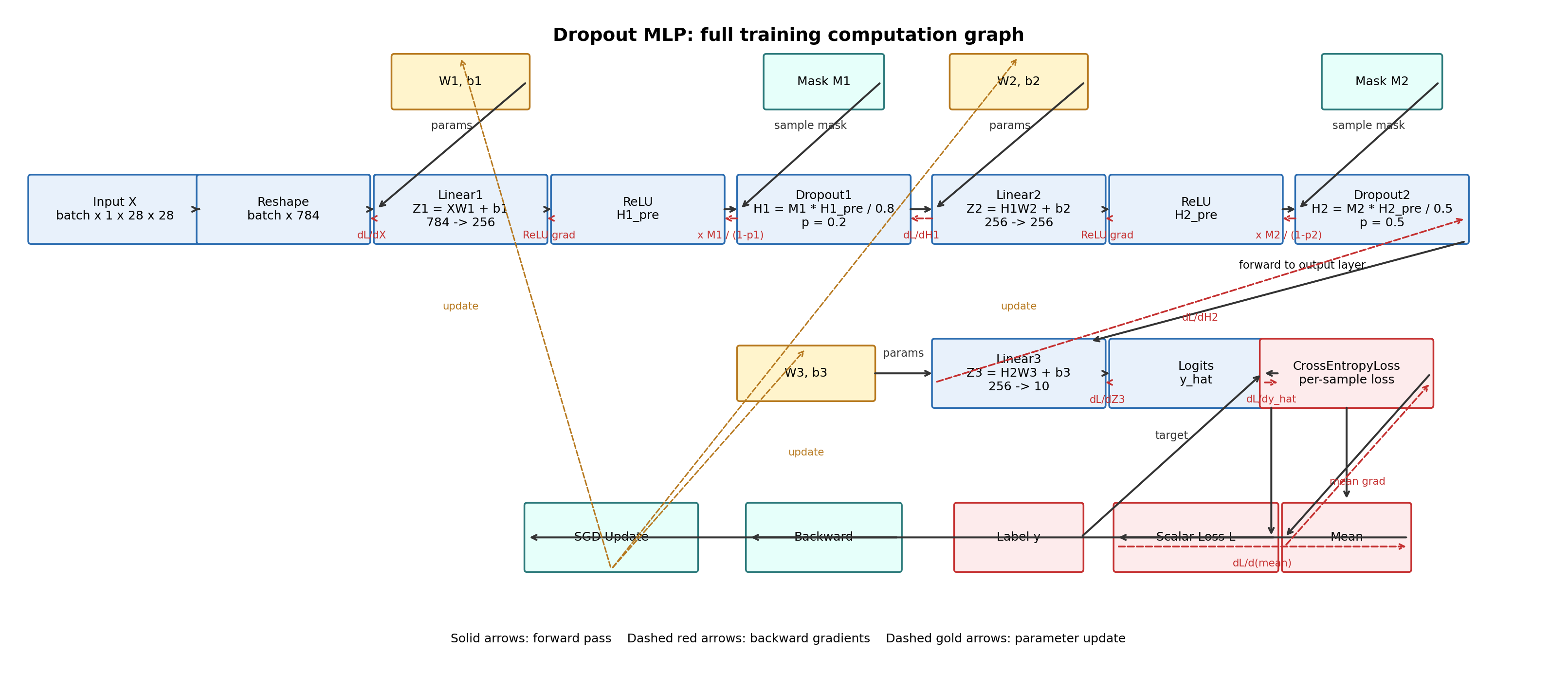
- 黑色实线:前向计算流(输入到损失)
- 红色虚线:梯度回传流(损失到各层)
- 金色虚线:优化器把梯度变成参数更新(SGD update)
反向传播每一段在传什么梯度
如果网络是:
x → L1 → L2 → L3 → L4 → Loss
梯度:
dLoss/dW1 = dL/dy × dy/dL4 × dL4/dL3 × dL3/dL2 × dL2/dL1 × dL1/dW1
dLoss/dW1 =
[dL/dy] (loss层)
× [dy/dL4 ← W4] (第4层参数 W4)
× [dL4/dL3 ← W3] (第3层参数 W3)
× [dL3/dL2 ← W2] (第2层参数 W2)
× [dL2/dL1 ← W1] (第1层参数 W1)
× [dL1/dW1 ← W1] (第1层参数 W1)
Loss 下降过程
- 假设:Loss=10
- 优化一步后:Loss=9.9
| 层 | 梯度特点 |
|---|---|
| 最后一层 | 梯度最大 |
| 中间层 | 逐渐减小 |
| 第一层 | 最容易变小 |
假设:
| 层 | 梯度 |
|---|---|
| W3 | 0.5 |
| W2 | 0.1 |
| W1 | 0.01 |
学习率:0.01
| 层 | 梯度 | 更新量 | 计算方式 |
|---|---|---|---|
| W3 | 0.5 | 0.005 | 0.01 × 0.5 |
| W2 | 0.1 | 0.001 | 0.01 × 0.1 |
| W1 | 0.01 | 0.0001 | 0.01 × 0.01 |
学习率
梯度告诉我们方向和强度,但它是一个变化率。如果我们直接把梯度加到权重上,步子可能太大(扯着跨)或者太小(纹丝不动)
\[W_{new} = W_{old} - \eta \cdot \frac{\partial L}{\partial W}\]- $W3$ 的梯度是 $0.5$。
- 如果 $\eta = 0.01$,变化量就是 $0.005$。
- 如果我们将 $\eta$ 调大到 $1.0$,变化量就变成了 $0.5$。
训练神经网络
第一轮
Epoch 1: 训练集打乱 → 切分 100 个 batch
Batch 1: [样本 432, 87, ..., 120] <-- mini-batch 梯度更新 ΔW1
Batch 2: [样本 901, 502, ..., 350] <-- mini-batch 梯度更新 ΔW2
Batch 3: [样本 10, 876, ..., 211] <-- mini-batch 梯度更新 ΔW3
...
Batch 100: [样本 9999, 23, ..., 1200] <-- mini-batch 梯度更新 ΔW100
参数更新顺序:
W ← W - η * ΔW1
W ← W - η * ΔW2
...
W ← W - η * ΔW100
Loss 在 epoch 1 结束时略微下降
第二轮
Epoch 2: 训练集再次打乱 → 切分 100 个 batch
Batch 1: [样本 1234, 88, ..., 4567] <-- mini-batch 梯度更新 ΔW101
Batch 2: [样本 901, 7, ..., 2222] <-- mini-batch 梯度更新 ΔW102
...
Batch 100: [样本 7890, 3456, ..., 12] <-- mini-batch 梯度更新 ΔW200
参数更新顺序:
W ← W - η * ΔW101
W ← W - η * ΔW102
...
W ← W - η * ΔW200
Loss 在 epoch 2 结束时进一步下降
每个 batch:
- 只计算当前 batch 的梯度
- 更新一次参数
- Loss 会略微下降
每轮 epoch:
- 训练集重新随机打乱
- batch 样本不同 → 梯度方向略有差异
- 参数经过多次 batch 更新 → 收敛
整个训练:
经过多轮 epoch → 模型在全量训练集上学习到完整特征
内存需求
神经网络训练需要更多显存的核心原因是 为了反向传播,需要保存前向传播的中间激活值,而这些中间值随着层数和 batch size 增长而线性增加。
模型参数量
双隐藏层 MLP + Dropout 的完整训练流程,输入是 Fashion-MNIST(28×28=784),两个隐藏层各 256 个神经元,batch_size=256。 我们可以估算训练该模型所需的 主要内存(显存/内存)开销,重点考虑 前向传播中间激活 + 参数 + 梯度。
| 层 | 输入维度 | 输出维度 | 参数量 | 占用内存(float32) |
|---|---|---|---|---|
| Linear1 | 784 | 256 | 784×256 + 256 = 200,960 | 200,960×4B ≈ 0.77 MB |
| Linear2 | 256 | 256 | 256×256 + 256 = 65,792 | 65,792×4B ≈ 0.25 MB |
| Linear3 | 256 | 10 | 256×10 + 10 = 2,570 | 2,570×4B ≈ 0.01 MB |
总参数量:≈ 269,322 参数占用内存 ≈ 1.03 MB(float32
前向传播激活量
| 层 | 输出形状 | 元素个数 | 占用内存 |
|---|---|---|---|
| 输入 X | [256, 784] | 256×784 = 200,704 | 0.77 MB |
| H1 | [256, 256] | 256×256 = 65,536 | 0.25 MB |
| H2 | [256, 256] | 256×256 = 65,536 | 0.25 MB |
| 输出 out | [256, 10] | 256×10 = 2,560 | 0.01 MB |
激活值总计 ≈ 1.28 MB
梯度存储
| 层 | 参数数 | 梯度数 | 内存 |
|---|---|---|---|
| Linear1 | 200,960 | 200,960 | 0.77 MB |
| Linear2 | 65,792 | 65,792 | 0.25 MB |
| Linear3 | 2,570 | 2,570 | 0.01 MB |
Dropout mask
- dropout1 = 0.2 → H1 mask 256×256 → 65,536 元素 → 0.25 MB
- dropout2 = 0.5 → H2 mask 256×256 → 65,536 元素 → 0.25 MB
总 mask 内存 ≈ 0.5 MB
总计
| 部分 | 内存(MB) |
|---|---|
| 参数 | 1.03 |
| 梯度 | 1.03 |
| 激活值 | 1.28 |
| Dropout mask | 0.50 |
| 总计 | ≈ 3.8 MB |
估算训练ChatGPT需求
| 项目 | 数值 / 说明 | 单卡假设显存 | 估算 GPU 数量 |
|---|---|---|---|
| 模型参数 | 1T 参数 × FP16 → 2 TB | 80 GB/卡 | 25 张(仅参数) |
| 梯度 | 1T 参数 × FP16 → 2 TB | 80 GB/卡 | 25 张(仅梯度) |
| 优化器状态 | Adam 动量 + 二阶累积 → 4 TB | 80 GB/卡 | 50 张(仅优化器) |
| 前向激活 | batch=16, seq=2048, 96 层 → 720 GB | 80 GB/卡 | 9 张(仅激活) |
| 显存峰值总和 | 参数+梯度+优化器+激活 ≈ 8.7 TB | 80 GB/卡 | ≈218 张 |
实际 OpenAI 训练可能使用 几百到上千张 GPU/TPU,保证效率、冗余和容错
估算推理ChatGPT需求
| 场景 | 显存需求 | 单卡显存 | 估算 GPU 数量 |
|---|---|---|---|
| 训练 ChatGPT‑5.3 | 8.7 TB | 80 GB | 218 张 |
| 推理单模型 | 2.016 TB | 80 GB | 26 张 |
| 推理全球一千万用户同时在线 | — | 80 GB | 100,000 张(理论峰值) |
各云计算厂商推理卡
| 厂商/平台 | 硬件类型 | 特点 / 推理优势 |
|---|---|---|
| TPU(v4/v5) | 专为矩阵运算优化,FP16/BF16,吞吐高,低延迟 | |
| Meta(Facebook) | Cerebras CS-2 | 超大芯片,支持大模型全片并行,推理吞吐量极高 |
| Amazon / AWS | Inferentia / Trainium | 针对深度学习推理优化,FP16/BF16,低功耗高吞吐 |
| Alibaba | 含光 800 / X-Dragon | 低功耗,针对大规模推理优化(电商推荐、Chat) |
| Baidu / PaddlePaddle | 昆仑 AI 芯片 | 推理优化,支持分布式推理流水线 |
数值稳定性和模型初始化
梯度消失
import torch
from d2l import torch as d2l
# 这个小案例用于可视化:
# 1) sigmoid 函数本身的曲线
# 2) sigmoid 对输入 x 的导数曲线(梯度)
#
# 理论上:
# sigmoid(x) = 1 / (1 + exp(-x))
# d(sigmoid)/dx = sigmoid(x) * (1 - sigmoid(x))
#
# 下面通过 autograd 自动求导来得到梯度,并与 sigmoid 曲线画在同一张图上。
# 构造输入区间 [-8, 8),步长 0.1。
# requires_grad=True 表示后续需要对 x 求梯度,PyTorch 会跟踪计算图。
x = torch.arange(-8.0, 8.0, 0.1, requires_grad=True)
# 对每个 x 计算 sigmoid 值,得到向量 y。
y = torch.sigmoid(x)
# 触发反向传播,计算 y 对 x 的梯度。
#
# 注意:y 是向量,不是标量;对向量直接 backward 时,需要提供一个与 y 同形状的“外部梯度”。
# 这里传入全 1 向量 torch.ones_like(x),等价于对 y 的所有分量求和后再反传:
# y.backward(torch.ones_like(x)) <=> (y.sum()).backward()
# 结果会写入 x.grad。
y.backward(torch.ones_like(x))
# 绘制两条曲线:
# - sigmoid(x)
# - grad = d(sigmoid)/dx
#
# x.detach().numpy():把张量从计算图中分离,再转成 numpy 用于绘图。
# y.detach().numpy():同理,绘制函数值。
# x.grad.numpy():绘制由 autograd 求得的梯度值。
d2l.plot(x.detach().numpy(), [y.detach().numpy(), x.grad.numpy()], 'x', 'y',
legend=['sigmoid', "gradient"], figsize=(4.5, 2.5))
# 显示图像窗口。
d2l.plt.show()
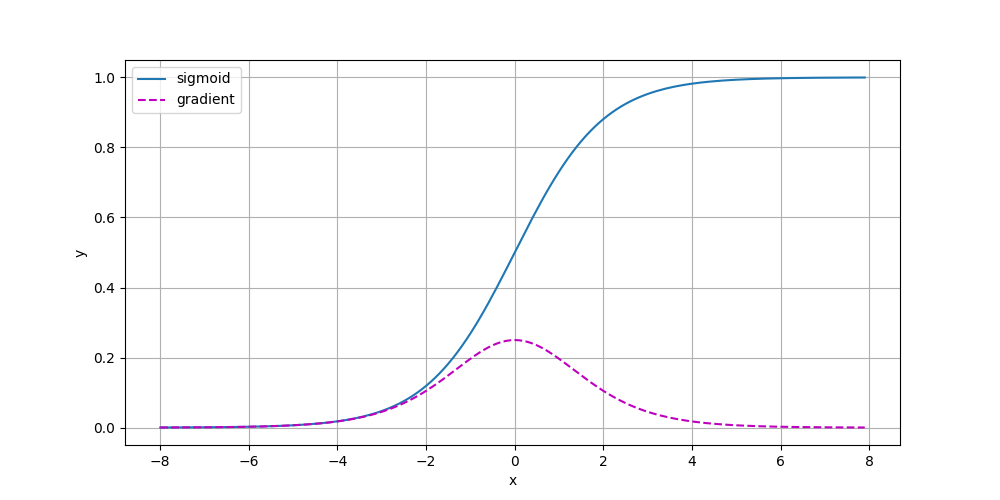
梯度消失(Gradient Vanishing) 就是在深度神经网络的反向传播过程中,由于层数太深,传回到前面层数的“评价波浪”(梯度)变得极小,甚至接近于 0
梯度消失主要由以下两个因素引起:
A. 激活函数的问题(如 Sigmoid)
早期的神经网络常用 Sigmoid 函数。它的导数最大值只有 $0.25$。 如果网络有 20 层,那么梯度传到第一层时会乘以 $0.25^{20}$,这个数极其微小,梯度直接“消失”了。
B. 权重初始化不当
如果初始权重 $W$ 的数值都非常小(比如都小于 1),在矩阵相乘的连乘效应下,梯度也会迅速萎缩。
梯度爆炸
import torch
# 生成一个 4x4 的随机矩阵 M。
# torch.normal(0, 1, shape) 表示从均值为 0、标准差为 1 的正态分布中采样。
M = torch.normal(0, 1, (4, 4))
print("原始矩阵 M:")
print(M)
# 重复做 100 次矩阵乘法:
# 每一次都用当前 M 去右乘一个新的随机 4x4 矩阵。
# 这个过程常用于演示:多次线性变换后,数值可能迅速变大或变小(数值不稳定)。
for i in range(100):
M = torch.mm(M, torch.normal(0, 1, (4, 4)))
# 打印连续矩阵乘法后的结果。
print("\n经过 100 次矩阵乘法后的 M:")
print(M)
运行结果
原始矩阵 M:
tensor([[ 0.0681, -0.6179, -0.5096, 0.5227],
[ 1.9192, -1.8429, -1.7132, -0.5520],
[-1.3791, 0.5473, -0.2430, 0.3095],
[ 2.0127, -2.3047, 0.0566, -0.5243]])
经过 100 次矩阵乘法后的 M:
tensor([[-9.3757e+22, -1.2646e+22, 2.8984e+22, -1.7041e+23],
[-3.8894e+23, -5.2460e+22, 1.2024e+23, -7.0691e+23],
[ 1.9522e+22, 2.6331e+21, -6.0350e+21, 3.5481e+22],
[-6.1256e+22, -8.2621e+21, 1.8937e+22, -1.1133e+23]])
在反向传播过程中,梯度在每一层连乘后呈指数级增长,最终变成巨大的数值,甚至溢出变成 NaN(Not a Number)。
以下是几种最容易触发梯度爆炸的典型场景:
- 循环神经网络 (RNN) 中的长序列处理
- 深度网络中权重初始化过大
- 缺乏归一化层 (Normalization)
- 学习率 (Learning Rate) 设得太高
- 激活函数选择不当
打破对称性
如果我们将神经元的权重初始化为完全相同的常数(比如全 0 或全 1),网络就会陷入一种“步调一致”的死循环
前向传播: 两个隐藏单元输入一样,权重一样 → 输出激活完全一样反向传播: 输出单元对隐藏单元的梯度完全一样 → 更新后两个隐藏单元仍然相同结果:每次迭代更新的权重都保持相同 → 对称性永远不会被破坏
网络隐藏层的行为等价于只有一个单元 → 表达能力大幅下降
破坏对称性的方法
| 方法 | 原理 |
|---|---|
| 随机权重初始化 | 通过随机化每个隐藏单元的权重,保证每个单元初始状态不同 → 对称性被破坏 |
| 暂退法(Dropout) | 每次前向传播随机屏蔽一部分隐藏单元 → 同样的输入产生不同激活 → 打破步调一致性 |
| 小噪声或扰动 | 在权重初始化后加入微小随机扰动,也能破坏对称性 |
参数初始化
| 初始化方法 | 核心公式(方差) | 适用激活函数 | 核心逻辑 |
|---|---|---|---|
| 全零 / 常数 | 0 | 根本不行 | 无法打破对称性,所有隐藏单元学习相同特征 |
| 普通随机 | 固定较小值(如 0.01) | 极浅网络 | 简单随机,容易梯度消失,深层网络效果差 |
| Xavier / Glorot | ( \frac{2}{n_\text{in} + n_\text{out}} ) | Tanh / Sigmoid | 保持前向输出和反向梯度方差平衡,防止梯度消失/爆炸 |
| He / Kaiming | ( \frac{2}{n_\text{in}} ) | ReLU / Leaky ReLU | 补偿 ReLU 激活导致输出能量减半,保持梯度稳定 |
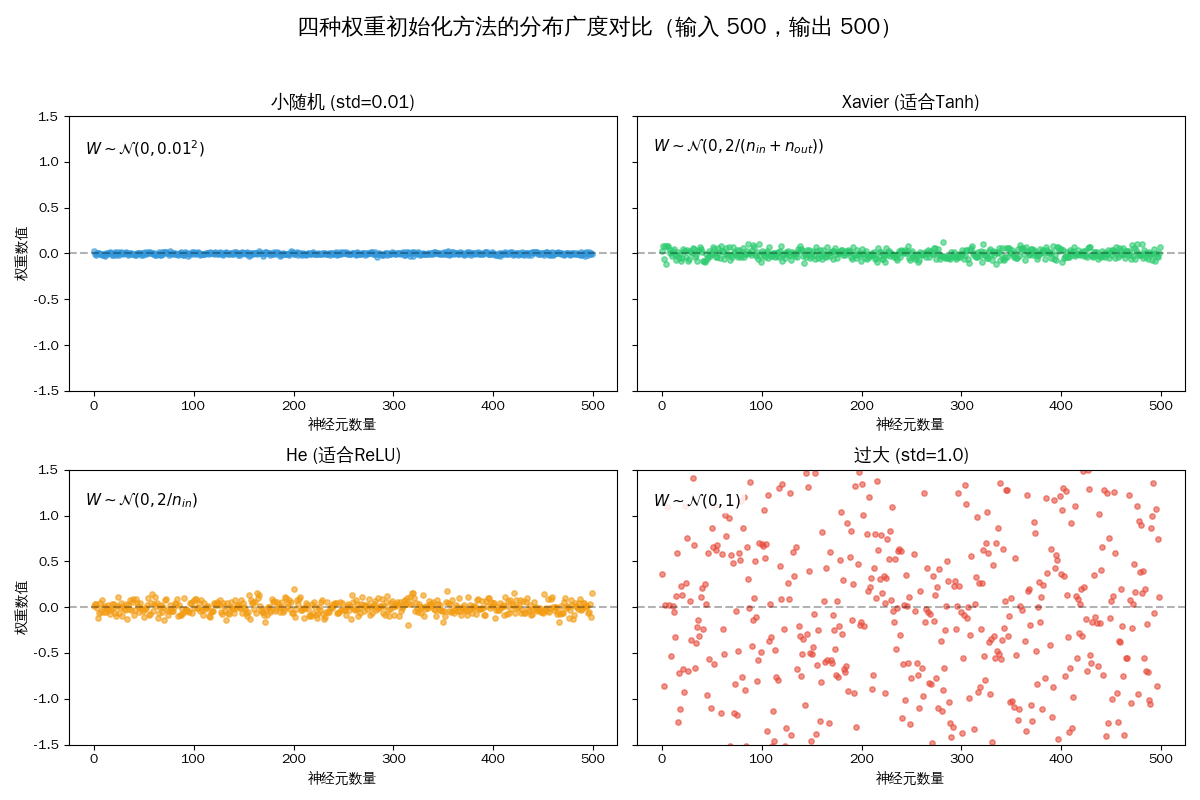
Xavier 初始化
Xavier 初始化(又叫 Glorot 初始化) 是神经网络中一种常用的权重初始化方法,主要目的是 打破对称性 并 保持前向传播和反向传播中的信号方差稳定,避免梯度消失或爆炸。
Xavier 初始化的直观想法是:如果我们能让信号在穿过每一层时,强度(方差)保持不变,那么网络就可以变得很深。
为了保证前向和后向的方差一致,Xavier 设计了一个取决于输入神经元数量 ($n_{in}$) 和 输出神经元数量 ($n_{out}$) 的分布
A. 如果使用正态分布
\[W \sim \mathcal{N}\left(0, \sigma^2\right), \quad \sigma = \sqrt{\frac{2}{n_{in} + n_{out}}}\]B. 如果使用均匀分布
\[W \sim U\left(-\sqrt{\frac{6}{n_{in} + n_{out}}}, \sqrt{\frac{6}{n_{in} + n_{out}}}\right)\]