分布偏移
Distribution Shift(分布偏移)
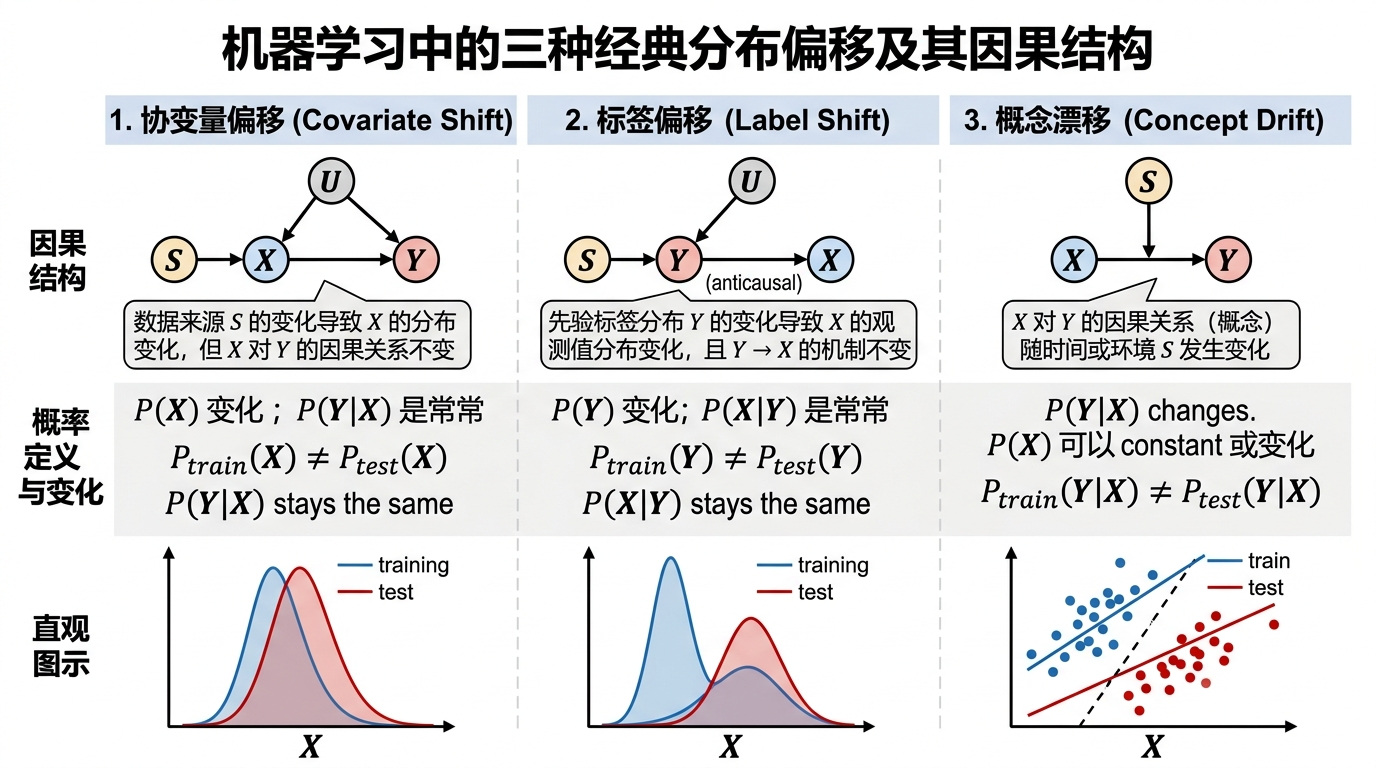
协变量偏移(Covariate Shift)
训练数据
| 图片来源 | 特征 |
|---|---|
| 互联网图片 | 高清、光线好 |
测试数据
| 图片来源 | 特征 |
|---|---|
| 手机监控 | 模糊、光线差 |
为什么叫“协变量偏移”
| 名词 | 含义 |
|---|---|
| 变量 | 数据中的量 |
| 因变量 | 预测目标 (y) |
| 协变量 | 输入特征 (x) |
协变量偏移 = 特征分布改变
为什么这种情况最常见
| 场景 | 变化 |
|---|---|
| 推荐系统 | 用户群变化 |
| 自动驾驶 | 天气变化 |
| 医疗模型 | 医院设备不同 |
| 电商 | 新用户涌入 |
标签偏移(Label Shift)
训练数据
| 疾病 | 比例 |
|---|---|
| 流感 | 20% |
| 普通感冒 | 80% |
几年后测试数据
| 疾病 | 比例 |
|---|---|
| 流感 | 60% |
| 普通感冒 | 40% |
概念漂移(Concept Drift)
| 地区 | 含义 |
|---|---|
| 加州 | 可口可乐 |
| 德州 | 碳酸饮料 |
为什么概念偏移最难处理
模型学到的规律失效,模型必须:重新训练
分布偏移示例
医学诊断
真正的问题:训练分布和真实分布完全不同
自动驾驶汽车
机器学习最大的风险不是模型能力,而是数据中的隐藏偏差
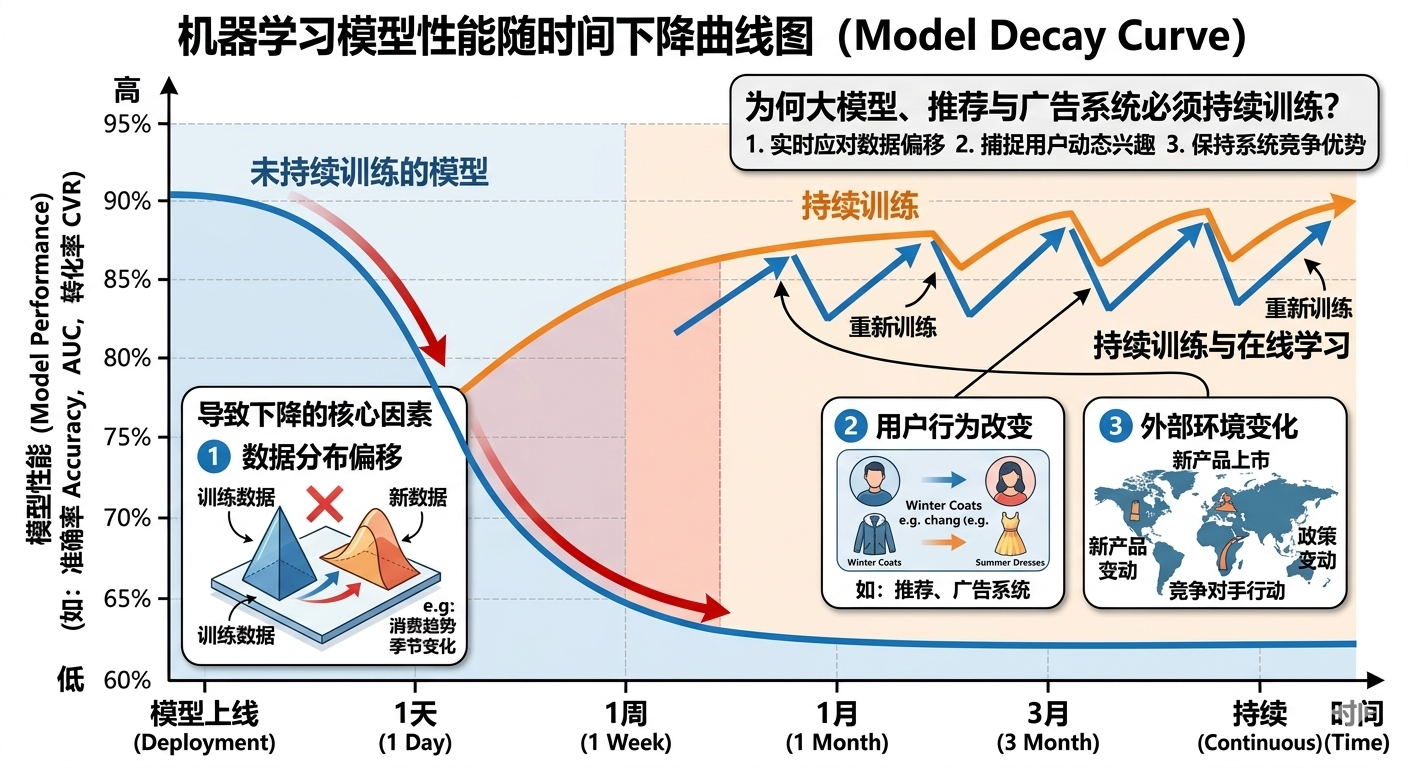
非平稳分布(Nonstationary Distribution)
数据分布在随时间慢慢变化,但模型没有及时更新
现实世界的经典现象
| 系统 | 模型寿命 |
|---|---|
| 广告模型 | 几天 |
| 推荐系统 | 几周 |
| 金融交易 | 几小时 |
| 语音识别 | 几年 |
机器学习模型不是一次训练就永远有效。
分布偏移纠正
经验风险最小化(ERM)
机器学习的基本策略就是:最小化训练集损失,希望它接近真实风险
| 项目 | 协变量偏移纠正 | 标签偏移纠正 |
|---|---|---|
| 改变 | (P(x)) | (P(y)) |
| 不变 | (P(y \mid x)) | (P(x \mid y)) |
| 纠正方法 | 样本权重(importance weighting) | 概率校正(posterior correction) |
| 训练时处理 | ✅ 是 | ❌ 否 |
| 预测时处理 | ❌ 否 | ✅ 是 |
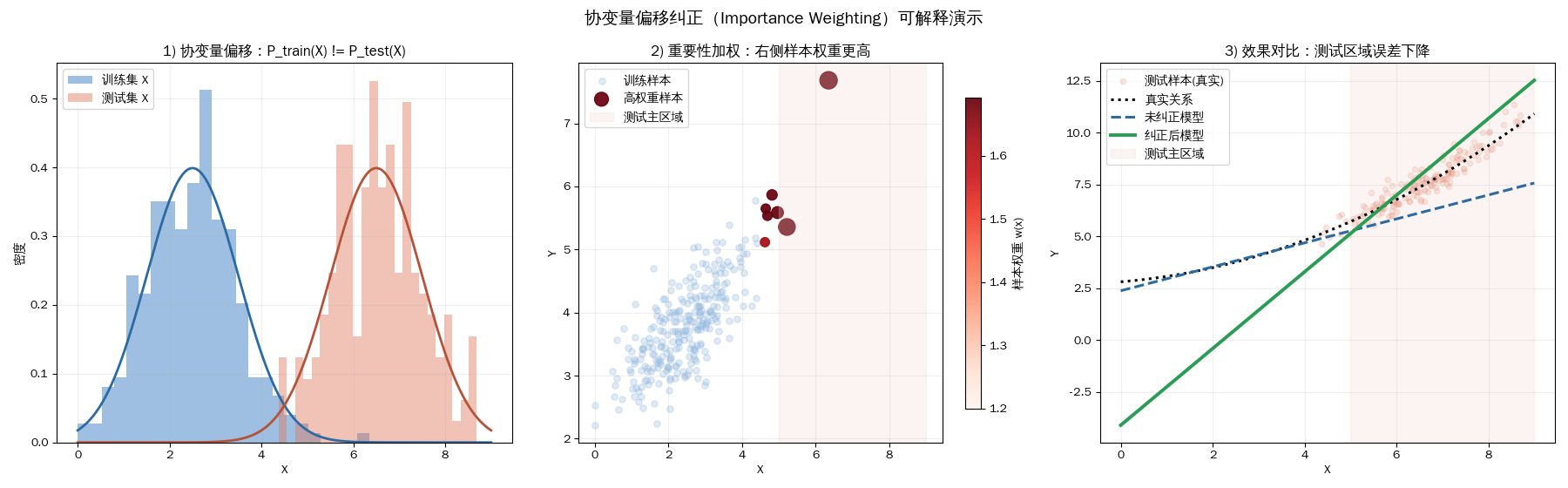
协变量偏移纠正
协变量偏移纠正(Covariate Shift Correction) 是一种用于解决模型在“训练集”和“测试集”上数据分布不一致(但预测机制不变)问题的统计与机器学习技术
重要性权重(Importance Weight)
最经典的方法是 重要性采样(Importance Sampling)。通过给每一个训练样本 $(x_i, y_i)$ 赋予一个权重 $w(x_i)$,使得加权后的训练分布在统计上趋近于测试分布。
训练流程
训练数据 (x,y) ───────┐
│
│
测试数据 (x) ──► 密度比估计
│
│
得到 w(x)
│
▼
加权训练模型
w(x)*loss(x,y)
│
▼
最终模型 f(x)
标签偏移纠正
在标签偏移中,因果链条发生了反转:我们假设是 标签 $Y$ 导致了特征 $X$(这被称为反因果结构,Anticausal)。
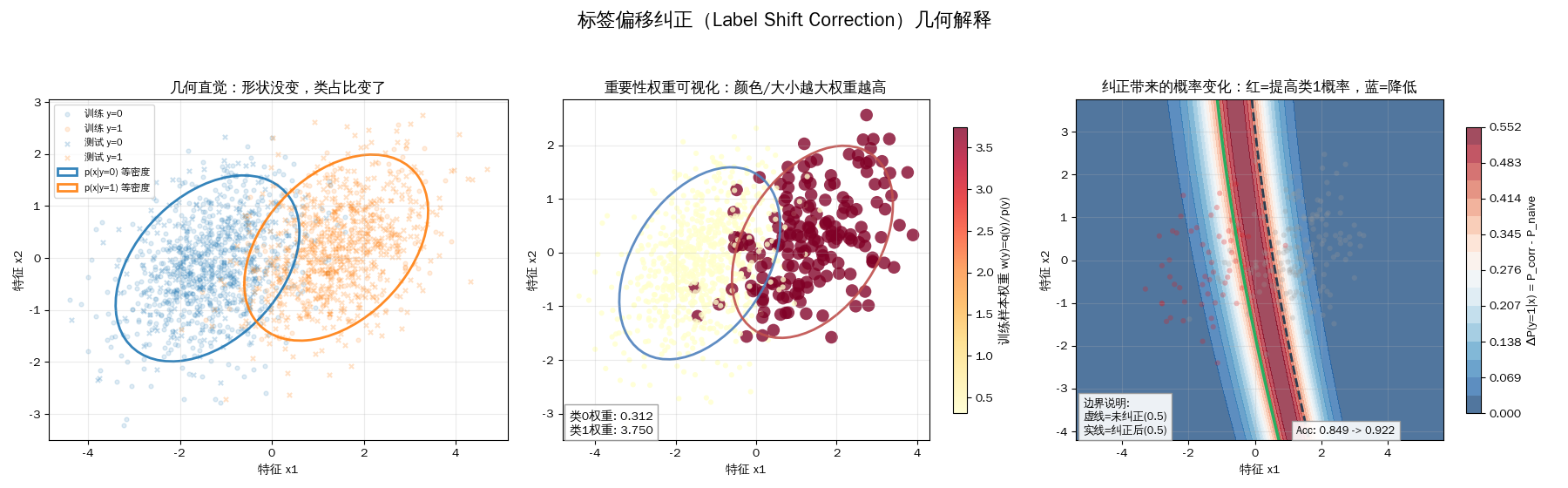
图1:Label Shift几何直觉
训练 vs 测试:
- 分布形状一样
- 但样本比例不同
视觉上蓝点比例变少,橙点比例变多
| 清晰地展示了 $p(x | y)$ 的形状在训练和测试阶段是完全重合的。改变的仅仅是散点的密度(即 $p(y)$)。 |
图2:样本权重可视化
由于测试集里类别 1 的占比大幅增加(20% -> 75%),所以类别 1 的样本被赋予了极大的权重(红色大点),而类别 0 被抑制
图3:决策边界漂移
虚线(Naive): 偏向于训练集的高频类(类别 0),导致在类别 1 密集的测试集中表现不佳。 实线(Corrected): 经过校正后,边界向类别 0 方向移动,从而更公平地对待在测试集中出现频率更高的类别 1。
标签偏移校正的本质就是: 剥离掉模型在训练阶段“被迫”吸收的陈旧先验分布 $P(y)$,并注入测试环境下的真实先验 $Q(y)$
训练流程
训练模型
↓
模型输出 p(y|x)
↓
估计测试先验 q(y)
↓
重新校正概率
↓
得到 q(y|x)
- 不用重新训练
- 计算成本极低
- 可以实时更新
学习问题的分类法
批量学习 Batch Learning
模型一次性使用完整训练数据进行训练,训练完成后部署,之后基本不再更新。
训练和预测是 两个完全分离的阶段。
| 特点 | 说明 |
|---|---|
| 训练方式 | 离线训练 |
| 数据使用 | 全量数据 |
| 模型更新 | 很少 |
| 部署模式 | 静态模型 |
| 适用场景 | 分布稳定 |
在线学习 Online Learning
在线学习(Online Learning) 是一种机器学习范式:
模型在数据持续到来的过程中不断更新,而不是一次性用全部数据训练完成。
| 优点 | 解释 |
|---|---|
| 实时学习 | 数据到来就更新 |
| 内存小 | 不需要存所有数据 |
| 适合大数据 | 数据流训练 |
| 适应变化 | 能应对分布变化 |
持续学习 Continual Learning
Continual Learning(持续学习 / 终身学习) 是一种机器学习范式:
模型在不断接收新任务或新数据时持续学习,同时尽量不忘记之前学过的知识。
| 特性 | Batch Learning | Online Learning | Continual Learning |
|---|---|---|---|
| 训练方式 | 一次训练 | 数据流更新 | 任务序列学习 |
| 数据 | 静态数据 | 流数据 | 多任务 |
| 模型更新 | 很少 | 持续更新 | 持续更新 |
| 主要问题 | 分布偏移 | 噪声数据 | 灾难性遗忘 |
强化学习
智能体(Agent)通过与环境(Environment)交互,根据奖励(Reward)不断调整行为策略(Policy),从而最大化长期回报。
大模型厂商需要持续训练模型吗
增量预训练 (Incremental Pre-training)
为了解决模型对“2026年发生了什么”一无所知的问题。厂商会持续抓取互联网上的新数据(新闻、代码、论文),让模型在原有基础上继续跑。
挑战: 灾难性遗忘。如果只喂新数据,模型可能会记得“2026年的科技突破”,但忘了“二战是什么时候结束的”。做法: 厂商通常采用 混合训练(Data Mixing)。在喂新数据时,必须掺入一定比例的旧数据(回放,Replay),就像我们复习功课一样。
持续对齐与微调 (Continual SFT/RLHF)
模型最初可能很聪明但很鲁莽(会输出有害内容或胡说八道)。厂商需要根据用户反馈(RLHF)持续微调。
本质: 这是在调整模型处理问题的“偏好”。成本: 虽然数据量比预训练小,但人力成本(标注员)极高。厂商需要成千上万的高质量人类反馈来告诉模型:“这个回答比那个好”。
在线学习与长时记忆 (Long-term Context/RAG)
这是大模型厂商在工程端最头疼的部分。模型能记住你上周教它的东西吗?
RAG (检索增强生成): 厂商并不真的修改模型参数,而是给模型外挂一个“图书馆”。长文本技术: 通过技术手段让模型能“读”完一本书,而不需要重新训练。
上下文窗口越大,模型思考需要更长时间
| 上下文长度 N | Transformer 架构 (GPT) | 线性/优化架构 (Gemini / Claude) | 用户体验 |
|---|---|---|---|
| 1,000 (1K) | (10^6) 次运算 | (10^3) 次运算 | 秒回,无感知 |
| 8,000 (8K) | (6.4 \times 10^7) 次运算 | (8 \times 10^3) 次运算 | 略有停顿 |
| 128,000 (128K) | (1.6 \times 10^{10}) 次运算 | (1.2 \times 10^5) 次运算 | 明显等待(30s+) |
典型大模型团队整体结构
AI负责人 / AI副总裁
│
┌───────────────────────┼───────────────────────┐
│ │ │
研究团队 模型工程团队 基础设施团队
(算法研究) (模型工程) (算力平台)
│ │ │
┌──────┼──────┐ ┌──────┼──────┐ ┌──────┼──────┐
│ │ │ │ │ │ │ │ │
预训练研究 对齐研究 模型评测 训练系统 推理系统 分布式系统 GPU/集群管理
(Pretrain) (RLHF) (Eval) (Training) (Inference) (Distributed) (Cluster)