下载和缓存数据集
import hashlib
import os
import tarfile
import zipfile
import requests
# 数据集元信息字典:键是数据集名,值是 (下载链接, 文件sha1校验值)
#@save
DATA_HUB = dict()
# 数据集默认下载地址前缀
DATA_URL = 'http://d2l-data.s3-accelerate.amazonaws.com/'
def download(name, cache_dir=os.path.join('..', 'data')):
"""Download a file inserted into DATA_HUB, return the local filename."""
# 1) 先确认请求的数据集名称已在 DATA_HUB 中注册
assert name in DATA_HUB, f"{name} does not exist in {DATA_HUB}."
# 2) 取出该数据集的下载链接和对应的 sha1 摘要(用于完整性校验)
url, sha1_hash = DATA_HUB[name]
# 3) 确保缓存目录存在;如果不存在则自动创建
os.makedirs(cache_dir, exist_ok=True)
# 4) 根据 URL 的最后一段生成本地文件名
fname = os.path.join(cache_dir, url.split('/')[-1])
# 5) 若本地已存在同名文件,先做 sha1 校验,避免重复下载
if os.path.exists(fname):
sha1 = hashlib.sha1()
with open(fname, 'rb') as f:
while True:
# 每次读取 1MB,避免一次性读入大文件造成内存压力
data = f.read(1048576)
if not data:
break
sha1.update(data)
# 校验通过则直接返回本地路径
if sha1.hexdigest() == sha1_hash:
return fname
# 6) 本地无文件或校验失败时,重新下载
print(f'Downloading {url} to {fname}...')
# stream=True 表示启用流式响应;这里仍通过 r.content 一次性写入
r = requests.get(url, stream=True)
with open(fname, 'wb') as f:
f.write(r.content)
# 7) 返回下载到本地后的文件路径
return fname
def download_extract(name, folder=None):
"""Download a file inserted into DATA_HUB, extract it, and return the
extracted folder name."""
# 1) 先确保压缩包已下载到本地(若已缓存且校验通过则直接复用)
fname = download(name)
# 2) base_dir:压缩包所在目录;data_dir:去掉扩展名后的路径
# 例如 ../data/train.zip -> base_dir=../data, data_dir=../data/train
base_dir = os.path.dirname(fname)
data_dir, ext = os.path.splitext(fname)
# 3) 根据扩展名选择解压方式
if ext == '.zip':
fp = zipfile.ZipFile(fname, 'r')
elif ext in ('.tar', '.gz'):
fp = tarfile.open(fname, 'r')
else:
# 非 zip/tar/gz 文件不支持解压
assert False, 'Only zip/tar files can be extracted.'
# 4) 解压到压缩包所在目录
fp.extractall(base_dir)
# 5) 返回解压后的目录路径:
# - 若显式传入 folder,则返回 base_dir/folder
# - 否则默认返回去掉扩展名后的路径 data_dir
return os.path.join(base_dir, folder) if folder else data_dir
def download_all():
"""Download all files in the DATA_HUB."""
# 依次下载 DATA_HUB 里注册的所有数据集
for name in DATA_HUB:
download(name)
Kaggle
Kaggle 是一个全球知名的数据科学与机器学习平台,被 Google 收购并运营。它主要为数据科学家、AI工程师、学生提供:
- 📊 数据集
- 🏆 数据竞赛
- 📓 在线编程环境(Notebook)
- 📚 学习课程
- 🤝 社区交流
访问和读取数据集
import numpy as np
import torch
import pandas as pd
from torch import nn
from d2l import torch as d2l
DATA_HUB['kaggle_house_train'] = (
DATA_URL + 'kaggle_house_pred_train.csv', '585e9cc93e70b39160e7921475cb0a887b1ce1')
DATA_HUB['kaggle_house_test'] = (
DATA_URL + 'kaggle_house_pred_test.csv', 'fa19780a7b011eabfdbf1c71eb2a93e9d8b39')
# 下载训练和测试数据集
# pd : pandas 的常用别名,提供了强大的数据处理和分析功能
train_data = pd.read_csv(download('kaggle_house_train'))
test_data = pd.read_csv(download('kaggle_house_test'))
print(train_data.shape)
print(test_data.shape)
print('训练数据集第一条数据:')
print(train_data.iloc[0])
print('测试数据集第一条数据:')
print(test_data.iloc[0])
运行结果
(1460, 81)
(1459, 80)
训练数据集第一条数据:
Id 1
MSSubClass 60
MSZoning RL
LotFrontage 65.0
LotArea 8450
...
MoSold 2
YrSold 2008
SaleType WD
SaleCondition Normal
SalePrice 208500
Name: 0, Length: 81, dtype: object
测试数据集第一条数据:
Id 1461
MSSubClass 20
MSZoning RH
LotFrontage 80.0
LotArea 11622
...
MiscVal 0
MoSold 6
YrSold 2010
SaleType WD
SaleCondition Normal
Name: 0, Length: 80, dtype: object
数据预处理
下载 Kaggle 房价数据 → 做特征工程 → 转成 PyTorch 可训练数据
# -------------------- 数据预处理 --------------------
# 1) 拼接训练集和测试集的特征列(去掉 Id 和训练集标签 SalePrice)
all_features = pd.concat((train_data.iloc[:, 1:-1], test_data.iloc[:, 1:]))
# 2) 对数值特征做标准化:(x - mean) / std
# object 类型通常是类别特征,不在这一步处理
numeric_features = all_features.dtypes[all_features.dtypes != 'object'].index
all_features[numeric_features] = all_features[numeric_features].apply(
lambda x: (x - x.mean()) / x.std()
)
# 3) 标准化后数值列仍可能有缺失值,统一填充为 0
all_features[numeric_features] = all_features[numeric_features].fillna(0)
# 4) 对类别特征做独热编码,dummy_na=True 会把缺失值也当作一个类别
# dtype=np.float32 便于后续直接转为 torch.float32
all_features = pd.get_dummies(all_features, dummy_na=True, dtype=np.float32)
# 5) 按训练集行数切分回训练特征和测试特征,并转换为张量
n_train = train_data.shape[0]
train_features = torch.tensor(all_features[:n_train].to_numpy(), dtype=torch.float32)
test_features = torch.tensor(all_features[n_train:].to_numpy(), dtype=torch.float32)
# 6) 提取训练标签并转成二维张量,形状为 (样本数, 1)
train_labels = torch.tensor(
train_data['SalePrice'].to_numpy().reshape(-1, 1),
dtype=torch.float32
)
print('预处理后训练特征形状:', train_features.shape)
print('预处理后测试特征形状:', test_features.shape)
print('训练标签形状:', train_labels.shape)
运行结果
训练集shape : (1460, 81)
测试集shape : (1459, 80)
预处理后训练特征形状: torch.Size([1460, 330])
预处理后测试特征形状: torch.Size([1459, 330])
训练标签形状: torch.Size([1460, 1])
原始数据
| 数据 | 行数 | 列数 |
|---|---|---|
| 训练集 | 1460 | 81 |
| 测试集 | 1459 | 80 |
为什么 train 比 test 多 1 列?
- train 有标签:SalePrice
- test 没有标签
实际结构
train(81列):
Id + 79个特征 + SalePrice
test(80列):
Id + 79个特征
特征拼接
all_features = pd.concat((train_data.iloc[:, 1:-1], test_data.iloc[:, 1:]))
| 操作 | 含义 |
|---|---|
| 去掉第0列 | 去掉 Id |
| 去掉最后一列 | 去掉 SalePrice |
结果
train → 79列特征
test → 79列特征
1460 + 1459 = 2919 行
79 列
最关键问题:为什么变成 330 维?
核心原因:One-Hot 编码爆炸
举个真实例子
Neighborhood(社区)
NAmes, CollgCr, OldTown, Edwards, ...
假设有 25 种.
One-Hot 后:25列
| 字段 | 类别数 |
|---|---|
| Neighborhood | 25 |
| Exterior1st | 15 |
| RoofStyle | 6 |
| GarageType | 6 |
| … | … |
独热编码后: 79列 → 330列
完整过程
原始特征:79列
↓
数值特征:保持不变(比如 40列)
类别特征:One-Hot(比如 39列 → 290列)
↓
总特征:≈ 330列
标签 shape 为什么是 (1460, 1)
原始标签: [500, 300, 400, ...] # 一维
reshape 后:
[[500],
[300],
[400]]
大模型预处理爆炸
| 维度 | Kaggle表格 | 大模型 |
|---|---|---|
| 数据类型 | 表格 | 文本/代码 |
| 数据量 | MB级 | TB~PB级 |
| 预处理复杂度 | ⭐⭐ | ⭐⭐⭐⭐⭐ |
| 核心操作 | One-Hot | Tokenization |
| 清洗难度 | 低 | 极高 |
| 自动化程度 | 高 | 复杂 |
👉 在很多公司:
- ❌ 写模型的人:10%
- ✅ 做数据的人:60%
记不住这么多API怎么办
记住模板
# 1. 读数据
train = pd.read_csv(...)
# 2. 拼接
all = pd.concat(...)
# 3. 数值处理
all[numeric] = (all[numeric] - mean) / std
# 4. 填NaN
all = all.fillna(0)
# 5. One-hot
all = pd.get_dummies(all)
# 6. 转Tensor
torch.tensor(...)
训练
# 定义训练使用的损失函数:均方误差(回归任务常用)
loss = nn.MSELoss()
# 输入特征维度,后续用于定义线性层输入大小
in_features = train_features.shape[1]
def get_net():
# 这里使用最简单的线性回归模型:y = Wx + b
# nn.Sequential 便于后续需要时扩展更多层
net = nn.Sequential(
nn.Linear(in_features, 1)
)
return net
def log_rmse(net, features, labels):
# 评估指标:对数均方根误差(Kaggle 房价常用)
# 只做前向计算,不需要梯度,使用 no_grad 可减少显存/内存开销
with torch.no_grad():
# 将预测值限制在 1 以上,避免对数函数输入无效
clipped_preds = torch.clamp(net(features), 1, float('inf'))
# RMSE = sqrt(MSE(log(pred), log(label)))
rmse = torch.sqrt(loss(torch.log(clipped_preds), torch.log(labels)))
# 返回 Python 标量,便于记录与打印
return rmse.item()
def train(net, train_features, train_labels, test_features, test_labels,
num_epochs, learning_rate, weight_decay, batch_size):
# train_ls: 每个 epoch 的训练集 log_rmse
# test_ls: 每个 epoch 的验证/测试集 log_rmse
train_ls, test_ls = [], []
# 将特征和标签打包成 TensorDataset,供 DataLoader 按批次读取
dataset = torch.utils.data.TensorDataset(train_features, train_labels)
# shuffle=True: 每轮训练前打乱样本顺序,有助于随机梯度下降效果
train_iter = torch.utils.data.DataLoader(dataset, batch_size, shuffle=True)
# 优化器使用 Adam:对学习率较鲁棒,通常收敛更快
# weight_decay 相当于 L2 正则化系数,用于抑制过拟合
optimizer = torch.optim.Adam(net.parameters(), lr=learning_rate,
weight_decay=weight_decay)
# 外层循环:epoch(完整遍历训练集一次)
for epoch in range(num_epochs):
# 内层循环:mini-batch 训练
for X, y in train_iter:
# 清空上一批次的梯度,避免梯度累加
optimizer.zero_grad()
# 前向传播:计算当前批次预测与损失
l = loss(net(X), y)
# 反向传播:自动计算各参数梯度
l.backward()
# 参数更新:按优化器规则更新网络权重
optimizer.step()
# 每个 epoch 结束后记录一次整体训练误差
train_ls.append(log_rmse(net, train_features, train_labels))
# 若提供了验证/测试标签,则同步记录对应误差
if test_labels is not None:
test_ls.append(log_rmse(net, test_features, test_labels))
# 返回完整训练曲线,便于后续画图或比较超参数
return train_ls, test_ls
模型公式
y = w1*x1 + w2*x2 + ... + wn*xn + b
输入:330维
输出:1个房价
| 项 | 含义 |
|---|---|
| in_features=330 | 输入特征 |
| 1 | 输出一个数(房价) |
| 参数 | W(330个) + b(1个) |
损失函数
loss = nn.MSELoss()
预测:400万
真实:500万
误差:(400-500)^2 = 10000
K 折交叉验证
# K 折交叉验证:将训练数据划分为 k 份,轮流使用其中一份作为验证集,其余 k-1 份作为训练集
def get_k_fold_data(k, i, X, y):
# 1) 计算每折的样本数
fold_size = X.shape[0] // k
# 2) 划分验证集:第 i 折
X_valid = X[i * fold_size: (i + 1) * fold_size]
y_valid = y[i * fold_size: (i + 1) * fold_size]
# 3) 划分训练集:剩余 k-1 折
X_train = torch.cat([X[:i * fold_size], X[(i + 1) * fold_size:]], dim=0)
y_train = torch.cat([y[:i * fold_size], y[(i + 1) * fold_size:]], dim=0)
return X_train, y_train, X_valid, y_valid
def k_fold(k, X, y, num_epochs, learning_rate, weight_decay, batch_size):
# 记录每折的训练误差和验证误差
train_l_sum, valid_l_sum = 0.0, 0.0
# 依次进行 k 折交叉验证
for i in range(k):
# 获取第 i 折的训练集和验证集
X_train, y_train, X_valid, y_valid = get_k_fold_data(k, i, X, y)
# 定义新的模型实例,确保每折使用独立模型
net = get_net()
# 训练当前折的模型,并获取训练曲线
train_ls, valid_ls = train(net, X_train, y_train, X_valid, y_valid,
num_epochs, learning_rate, weight_decay,
batch_size)
# 累加当前折的最终训练误差和验证误差
train_l_sum += train_ls[-1]
valid_l_sum += valid_ls[-1]
print(f'折 {i + 1}, 训练 log rmse {train_ls[-1]:f}, '
f'验证 log rmse {valid_ls[-1]:f}')
# 返回平均训练误差和平均验证误差
return train_l_sum / k, valid_l_sum / k
把训练数据轮流当“考试题”,看看模型是不是只会背答案
模型选择
k, num_epochs, learning_rate, weight_decay, batch_size = 5, 100, 5, 0, 64
# 先进行 K 折交叉验证,用于评估当前超参数配置
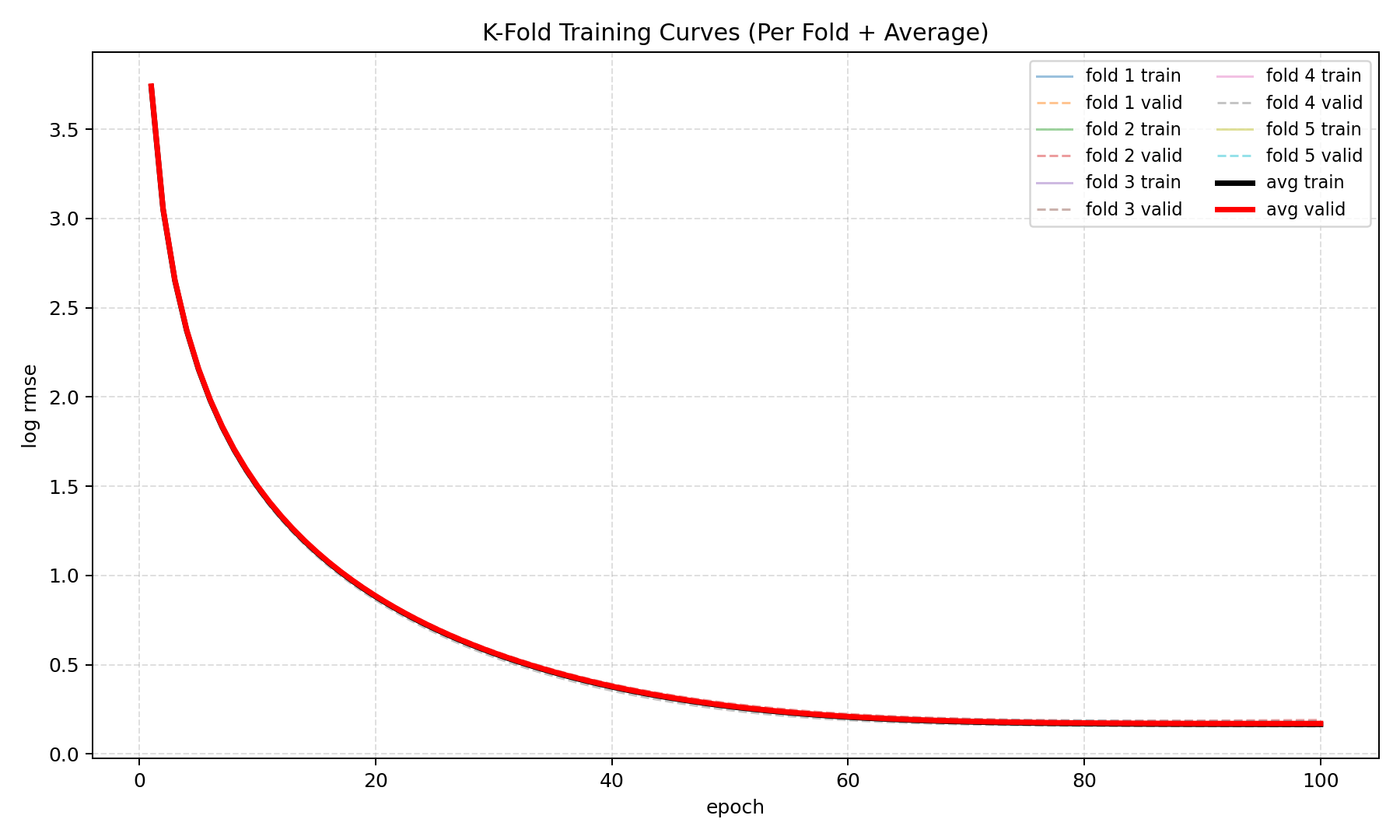
train_l, valid_l, train_curve, valid_curve = k_fold(
k, train_features, train_labels, num_epochs,
learning_rate, weight_decay, batch_size
)
print(f'{k}-折交叉验证: 平均训练 log rmse: {train_l:f}, 平均验证 log rmse: {valid_l:f}')
# 将曲线图保存到当前脚本同目录下
current_dir = os.path.dirname(os.path.abspath(__file__))
curve_path = os.path.join(current_dir, 'kfold_training_curve.png')
plot_training_curve(train_curve, valid_curve, curve_path)
# 使用全部训练集重新训练一个“最终模型”,用于后续真正预测测试集
final_net = get_net()
final_train_ls, _ = train(
final_net,
train_features,
train_labels,
None,
None,
num_epochs,
learning_rate,
weight_decay,
batch_size
)
print(f'最终模型训练完成,最后一个 epoch 的训练 log rmse: {final_train_ls[-1]:f}')
print_model_parameters(final_net, '最终模型参数:')
| 参数 | 含义 |
|---|---|
| k=5 | 5折交叉验证 |
| num_epochs=100 | 训练100轮 |
| learning_rate=5 | 学习率(⚠️ 非常关键) |
| weight_decay=0 | 没有正则化 |
| batch_size=64 | 每次训练64条 |
运行结果
折 1, 训练 log rmse 0.170435, 验证 log rmse 0.156715
第 1 折模型参数:
参数名: 0.weight, 形状: (1, 330), 前5个值: [-1928.2496 3270.9465 3226.0442 6016.519 940.08795]
参数名: 0.bias, 形状: (1,), 前5个值: [4216.395]
折 2, 训练 log rmse 0.162286, 验证 log rmse 0.191329
第 2 折模型参数:
参数名: 0.weight, 形状: (1, 330), 前5个值: [-2326.3728 3387.953 3279.3267 5928.1333 1328.5869]
参数名: 0.bias, 形状: (1,), 前5个值: [4211.6113]
折 3, 训练 log rmse 0.164126, 验证 log rmse 0.168309
第 3 折模型参数:
参数名: 0.weight, 形状: (1, 330), 前5个值: [-2397.008 3649.8237 3135.434 5950.8135 1031.8002]
参数名: 0.bias, 形状: (1,), 前5个值: [4198.4546]
折 4, 训练 log rmse 0.168370, 验证 log rmse 0.154671
第 4 折模型参数:
参数名: 0.weight, 形状: (1, 330), 前5个值: [-2055.231 3407.2402 3447.0017 5885.6133 949.78687]
参数名: 0.bias, 形状: (1,), 前5个值: [4231.5903]
折 5, 训练 log rmse 0.163068, 验证 log rmse 0.182890
第 5 折模型参数:
参数名: 0.weight, 形状: (1, 330), 前5个值: [-2087.5762 4176.7007 3496.465 5896.9854 718.92566]
参数名: 0.bias, 形状: (1,), 前5个值: [4222.353]
5-折交叉验证: 平均训练 log rmse: 0.165657, 平均验证 log rmse: 0.170783
最终模型训练完成,最后一个 epoch 的训练 log rmse: 0.162230
最终模型参数:
参数名: 0.weight, 形状: (1, 330), 前5个值: [-2436.3774 3523.7056 3477.2534 6635.6543 1962.126 ]
参数名: 0.bias, 形状: (1,), 前5个值: [4264.351]
| 折数 | train | valid | 结论 |
|---|---|---|---|
| 1 | 0.170 | 0.156 | 👍 |
| 2 | 0.162 | 0.191 | ⚠️ 偏高 |
| 3 | 0.164 | 0.168 | 👍 |
| 4 | 0.168 | 0.154 | 👍 |
| 5 | 0.163 | 0.182 | ⚠️ 偏高 |
0
次点赞