概念
卷积神经网络(convolutional neural network,CNN)是一类强大的、为处理图像数据而设计的神经网络。 基于卷积神经网络架构的模型在计算机视觉领域中已经占主导地位,当今几乎所有的图像识别、目标检测或语义分割相关的学术竞赛和商业应用都以这种方法为基础。
平移不变性
不管检测对象出现在图像中的哪个位置,神经网络的前面几层应该对相同的图像区域具有相似的反应,即为“平移不变性”
局部性
神经网络的前面几层应该只探索输入图像中的局部区域,而不过度在意图像中相隔较远区域的关系,这就是“局部性”原则。最终,可以聚合这些局部特征,以在整个图像级别进行预测
多层感知机的限制
用 1920×1080 的彩色图像来具体说明多层感知机(MLP)处理图像的局限
参数太多

忽略空间结构
多层感知机 MLP 对每个像素都是平等对待,没有考虑“邻近像素可能属于同一个物体”这一空间关系
无法提取局部特征
多层感知机 MLP 直接看整张 1920×1080 的图 → 每个神经元同时处理全图信息,无法专注局部细节
卷积
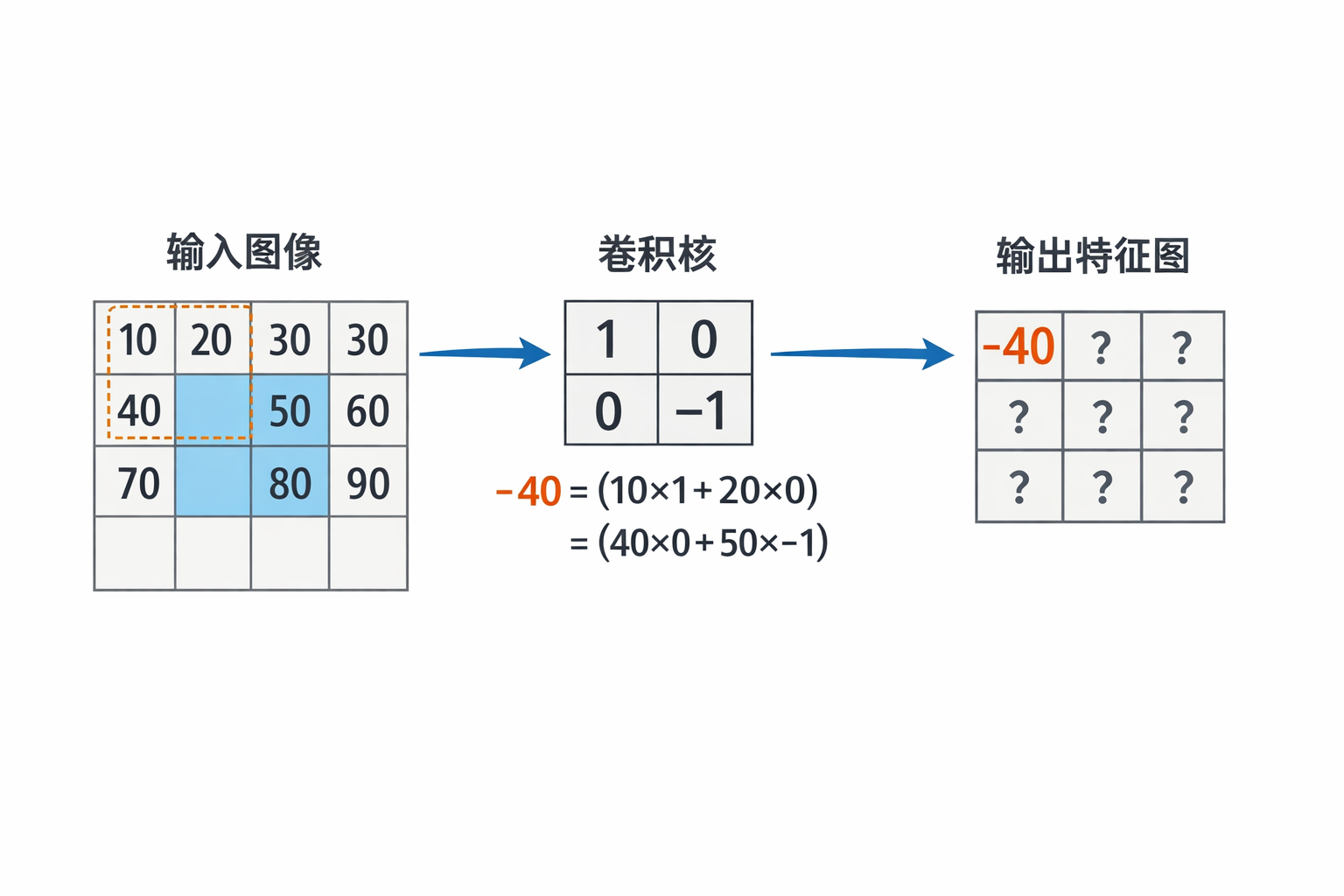
案例理解
图像:
[10 20 30]
[40 50 60]
[70 80 90]
卷积核:
[1 0]
[0 -1]
- 把卷积核放在图像左上角的 2×2 区域
- 做加权求和:
(10*1 + 20*0 + 40*0 + 50*(-1)) = 10 - 50 = -40
- 然后滑动卷积核到下一步位置,重复同样操作 → 得到输出特征图(feature map)
多角度理解
- 算子逻辑:它就是一个“滑动加权求和”器
- 物理直觉:它是一把“特征形状的模具”
- 数学本质:局部特征的聚合
为什么要叫“卷积”?
“卷”和“积”这两个字其实非常形象:
积:乘积、累加(就是对应位置相乘加起来)。卷:在信号处理中,这涉及函数的翻转。但在深度学习中,它更多指代这种“滑动遍历”的过程,即将一个局部窗口在全局空间上不断地翻卷、移动。
通道
理解“通道”(Channel)是深度学习从二维图像迈向高维特征提取的关键
输入层的通道:数据的“颜色分量”
一张 1080p 的图片在 Android 内存中通常是 [1080, 1920, 3] 的张量
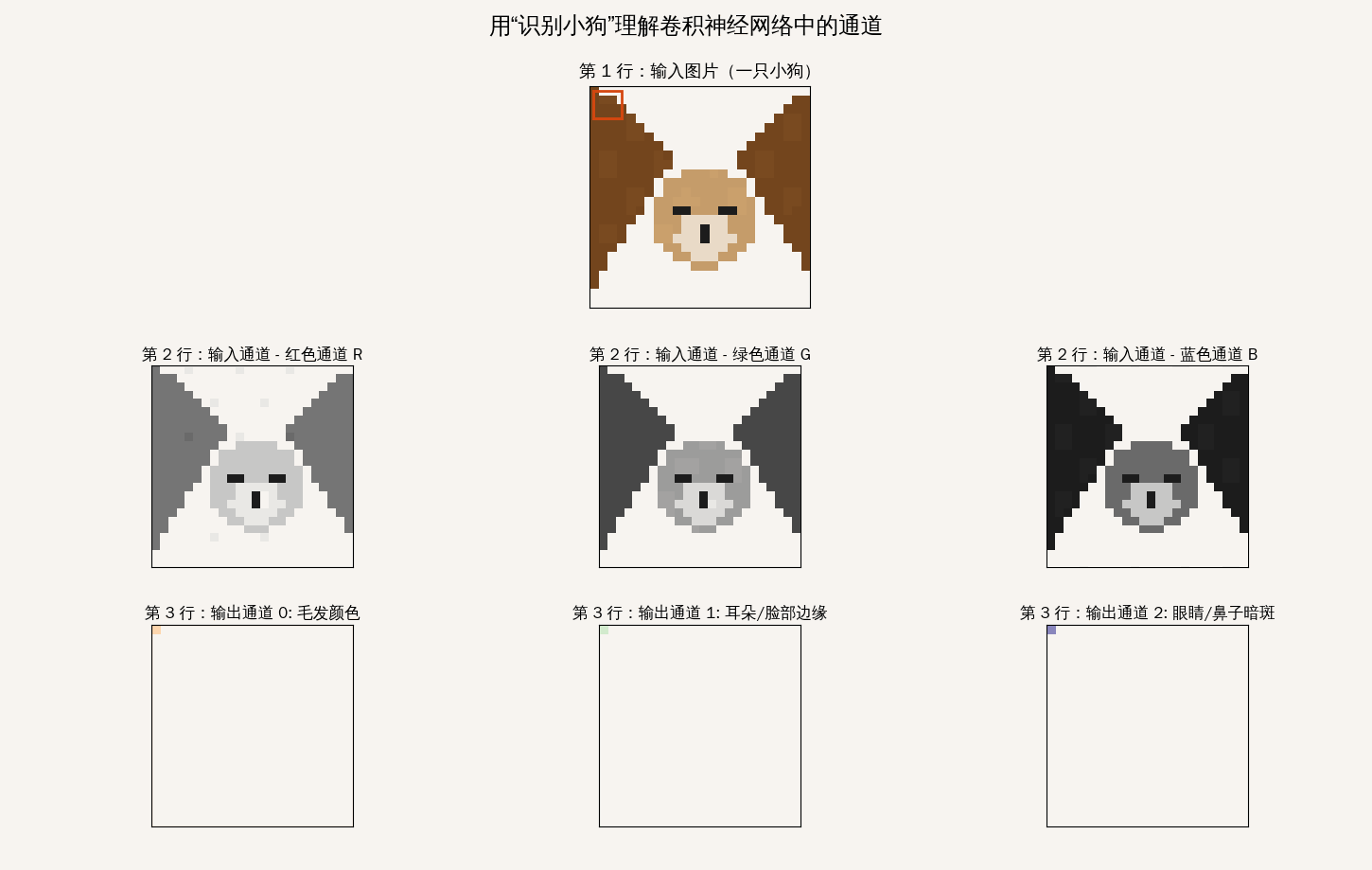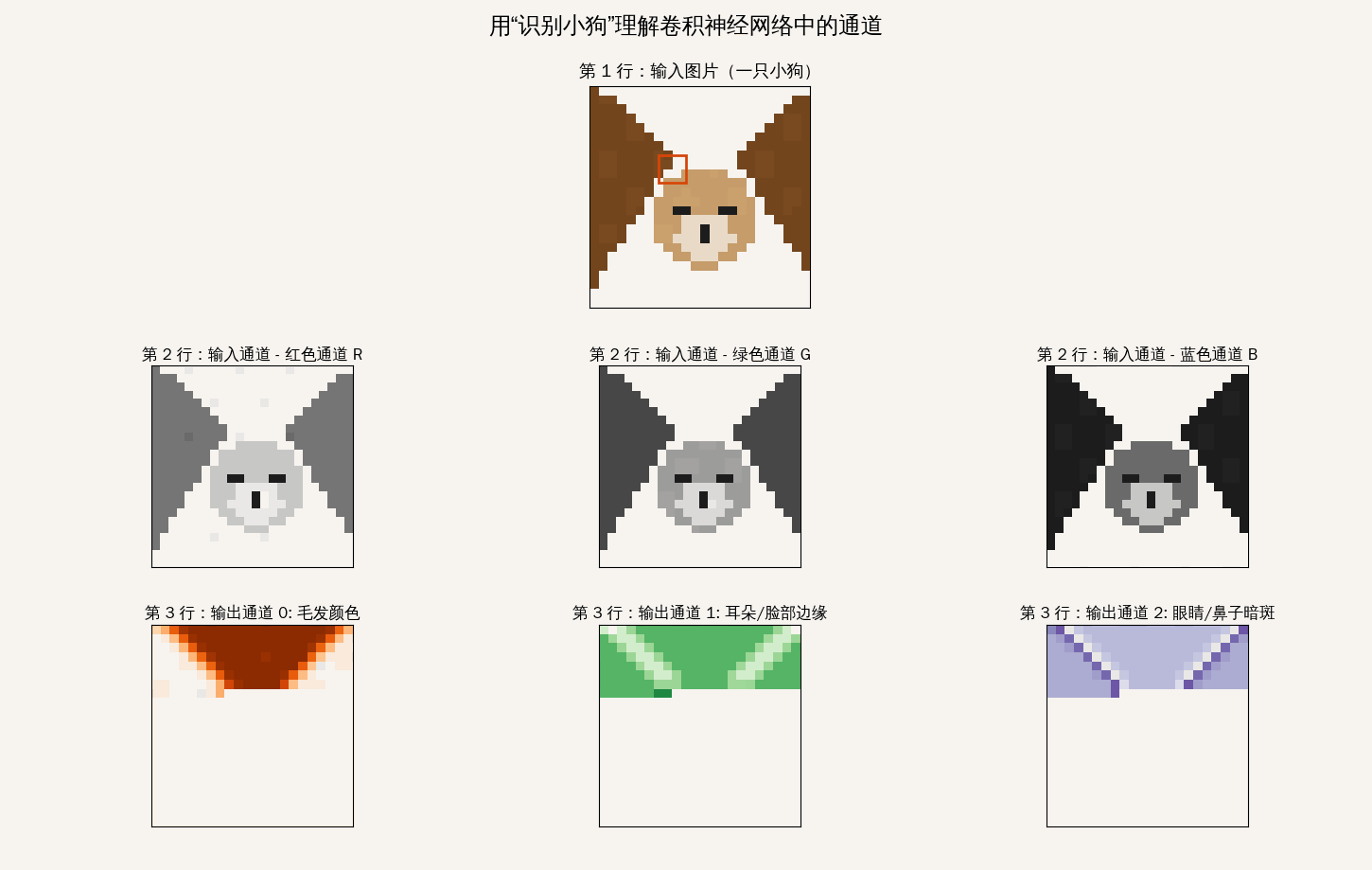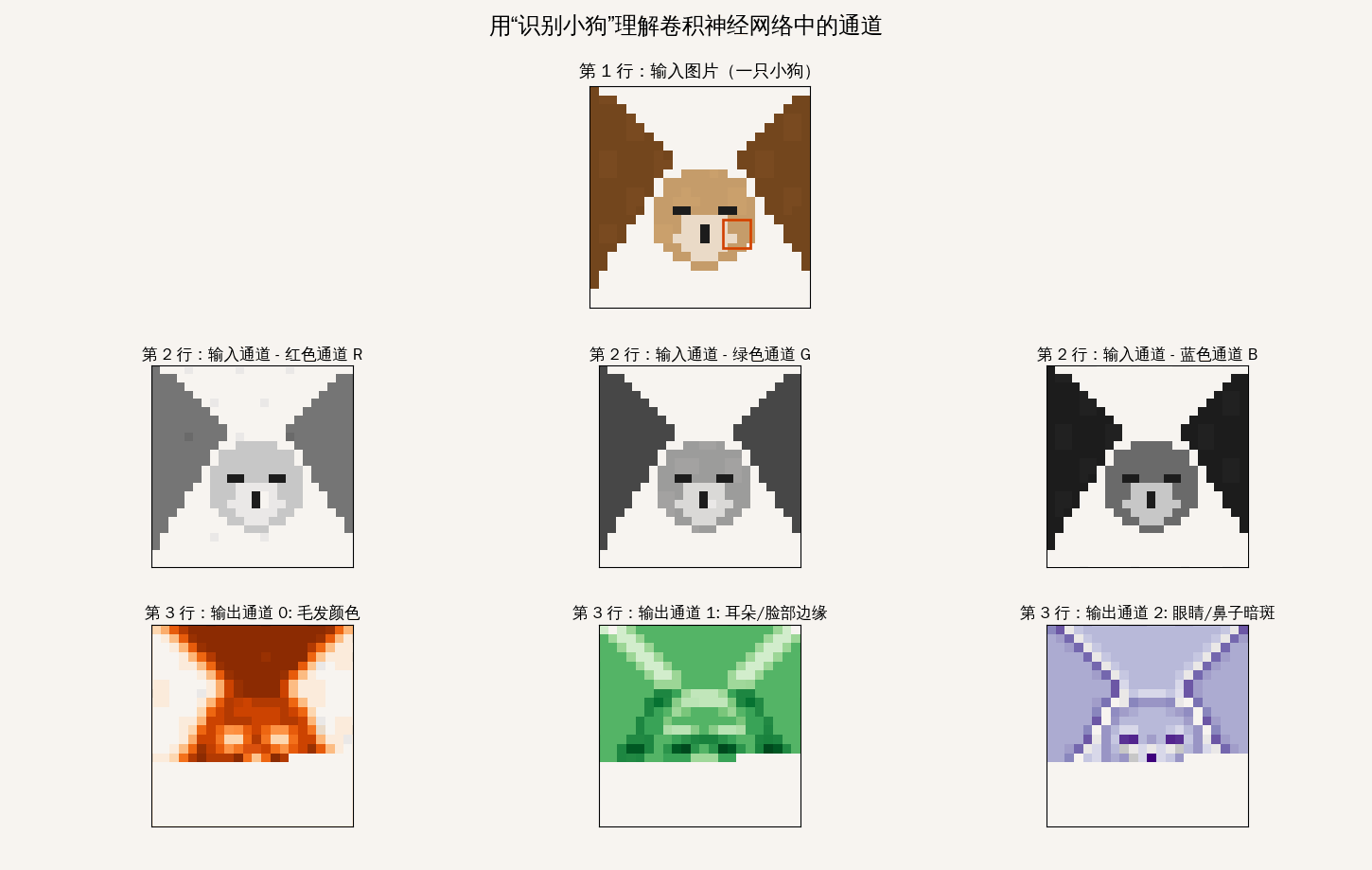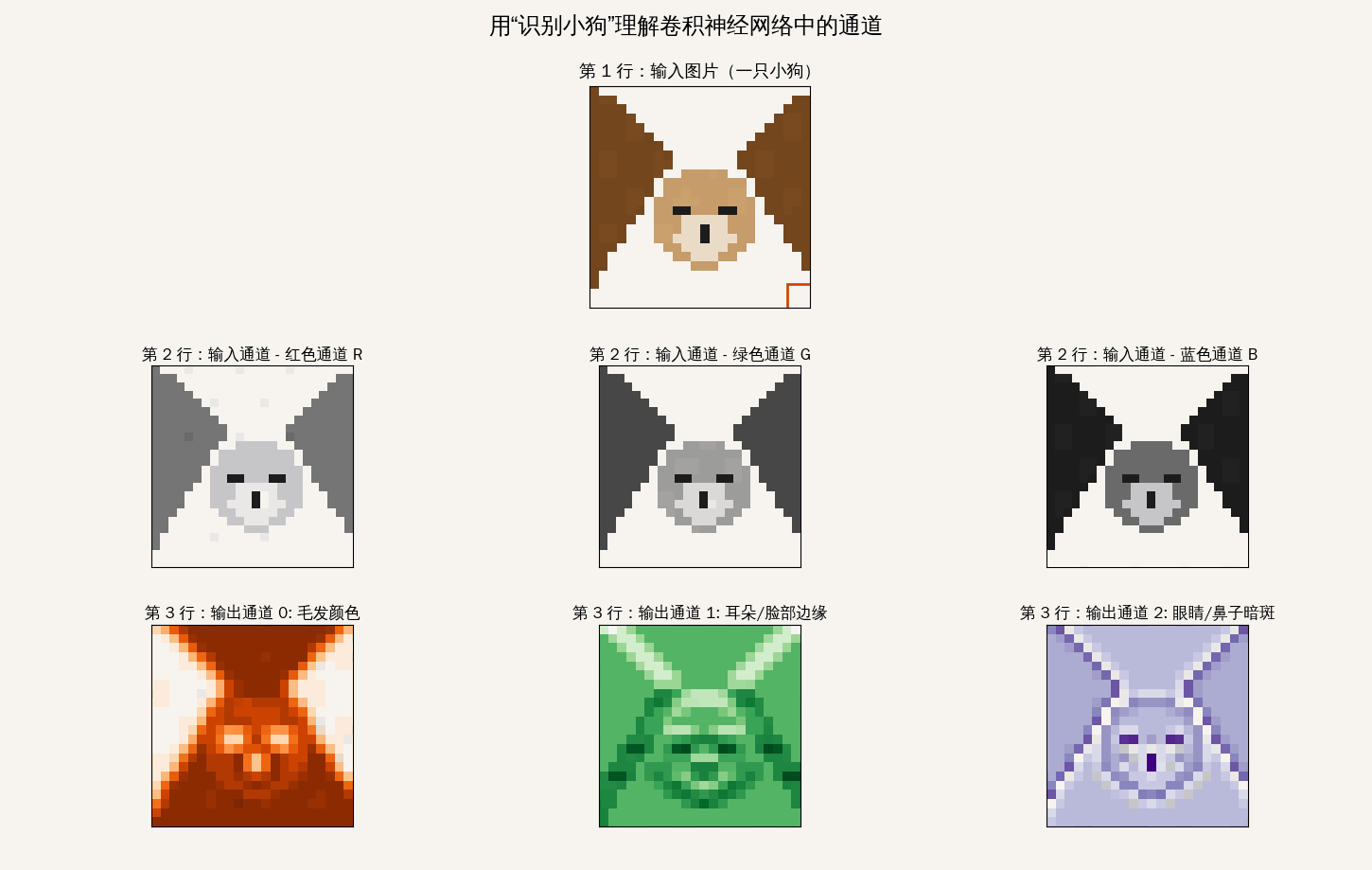
运算逻辑:它是如何“同时”扫描的?
当这个 $3 \times 3 \times 3$ 的绿色小方块(卷积核)扣在图像的某个位置时,它会执行以下动作:
- 分层对齐:核的 R 层对准图像的 R 层,G 对 G,B 对 B。
- 局部乘法:每个通道内的 9 个像素点分别与核内对应的 9 个权重相乘。
- 跨通道累加:这是最核心的一步! 系统会将 R、G、B 三个通道算出来的结果全部加在一起,再加上一个偏置项(Bias)。
- 输出单值:最终只吐出一个数值。
结论:卷积核在滑动时,是一次性“吃”掉了纵向深度的所有通道信息,然后把它们“压缩”成了一个特征点。
图像卷积
互相关运算
import torch
from torch import nn
from d2l import torch as d2l
# 卷积核
def corr2d(X, K):
# X: 输入图像,K: 卷积核
h, w = K.shape # 卷积核的高和宽
Y = torch.zeros((X.shape[0] - h + 1, X.shape[1] - w + 1)) # 输出图像的高和宽
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
Y[i, j] = (X[i:i+h, j:j+w] * K).sum() # 卷积操作:对应元素相乘后求和
return Y
X = torch.tensor([[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]])
K = torch.tensor([[0.0, 1.0], [2.0, 3.0]])
print(corr2d(X, K))
运行结果
tensor([[19., 25.],
[37., 43.]])
卷积层
class Conv2D(nn.Module):
def __init__(self, kernel_size):
super().__init__()
self.weight = nn.Parameter(torch.rand(kernel_size)) # 卷积核权重
self.bias = nn.Parameter(torch.zeros(1)) # 卷积核偏置
def forward(self, x):
return corr2d(x, self.weight) + self.bias # 卷积操作加上偏置
卷积层(Convolutional Layer)的核心任务是扫描输入数据,寻找特定的模式(Pattern)
图像中目标的边缘检测
X = torch.ones((6, 8)) # 输入图像
X[:, 2:6] = 0 # 中间部分为0,形成一个白色矩形
K = torch.tensor([[1.0, -1.0]]) # 卷积核,检测水平边缘
Y = corr2d(X, K) # 卷积操作
print("原始图像X:")
print(X)
print("卷积结果Y:")
print(Y)
运行结果
原始图像在视觉上就像一张黑纸中间贴了一块白色矩形。
原始图像X:
tensor([[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.]])
卷积结果Y:
tensor([[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.]])
- $Y$ 的内容:大部分是 0,但在原本 $X$ 的颜色交界处,会出现一列 1 和一列 -1。
- 结论:卷积层成功地把“像素”变成了“边缘特征”。 神经网络后续层不再关心像素是黑是白,只关心“哪里有边界”。
学习卷积核
X = torch.ones((6, 8)) # 输入图像
X[:, 2:6] = 0 # 中间部分为0,形成一个白色矩形
Y = corr2d(X, K) # 卷积操作
print("原始图像X:")
print(X)
print("卷积结果Y:")
print(Y)
conv2d = nn.Conv2d(1, 1, kernel_size=(1,2), bias = False) # 卷积层,输入通道数为1,输出通道数为1,卷积核大小为1x2
X = X.reshape((1, 1, 6, 8)) # 将输入图像调整为4D张量,形状为(批量大小, 输入通道数, 高度, 宽度)
Y = Y.reshape((1, 1, 6, 7)) # 将卷积结果调整为4D张量,形状为(批量大小, 输出通道数, 高度, 宽度)
lr = 3e-2 # 学习率
for i in range(10):
Y_hat = conv2d(X) # 卷积层的前向传播,得到预测结果Y_hat
l = (Y_hat - Y) ** 2 # 计算损失,使用均方误差损失函数
conv2d.zero_grad() # 清除卷积层的梯度,以便进行反向传播
l.sum().backward() # 反向传播,计算卷积层权重的梯度
# 迭代卷积核
conv2d.weight.data[:] -= lr * conv2d.weight.grad
if (i + 1) % 2 == 0:
print(f'epoch {i+1}, loss {l.sum():.3f}')
J = conv2d.weight.data.reshape((1, 2)) # 将卷积核权重调整为2D张量,形状为(1, 2)
print('学习到的卷积核权重:')
print(J)
运行结果
原始图像X:
tensor([[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.]])
卷积结果Y:
tensor([[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.]])
epoch 2, loss 9.599
epoch 4, loss 1.777
epoch 6, loss 0.366
epoch 8, loss 0.089
epoch 10, loss 0.026
学习到的卷积核权重:
tensor([[ 0.9701, -0.9988]])
我们只需要给模型成千上万张 $X$(原图)和对应的 $Y$(标签),模型就能自动在几十个卷积层中,学出成千上万个极其复杂的卷积核,这些核能捕捉到人类甚至无法理解的深层特征。
如果“不知道 Y”怎么办?
让模型自己去观察 100 万张图,它可能会发现某些像素经常一起出现,从而自己归纳出“边缘”的概念。但这种学习效率在目前的工程应用中远不如监督学习
卷积核维度的标准公式
一个标准卷积核的维度通常是一个 4D 张量,表示为:
\[[Out\_Channels, In\_Channels, Kernel\_H, Kernel\_W]\]在 PyTorch 中,当你调用 nn.Conv2d(in_channels, out_channels, kernel_size) 时,系统会自动帮你初始化这个 4D 权重矩阵
- 输入通道数 ($In_Channels$): 卷积核的“深度”必须等于输入的“深度”, 如果你处理的是 1080p 的 RGB 图像(3 通道),那么你的每一个卷积核必须有 3 层
- 输出通道数 ($Out_Channels$): 你想提取多少种特征,就初始化多少个“立体”卷积核, 你想同时检测“垂直边缘”、“水平边缘”和“颜色突变”,那么你就初始化 3 个卷积核
- 卷积核尺寸 ($Kernel_Size$): 在移动端(边缘 AI),$3 \times 3$ 是最常用的,因为现代芯片(如高通骁龙的 Hexagon DSP)对 $3 \times 3$ 的卷积运算有专门的硬件指令集优化
从现实世界到张量 Y
第一步:原始采集 (Raw Data)
你拿着安卓手机拍了 1000 张小狗的照片。这些是原始的 Bitmap 或 JPEG,对应张量 $X$。
第二步:人工标注 (Manual Labeling)
人类使用标注工具(如 LabelImg, CVAT, 或者华为/阿里的标注平台)对图片进行处理:
- 分类任务:标注员点击“狗”这个按钮。
- 检测任务:标注员用鼠标在小狗位置画一个矩形框。
- 分割任务:标注员用多边形把小狗的轮廓抠出来。
第三步:数字化转化 (Vectorization)
这一步由脚本完成,将人工的操作转化为数学张量 $Y$
做边缘 AI 时,会发现最难的不是写卷积层,而是获取高质量的 $Y$
特征映射和感受野
特征映射 (Feature Map) —— “处理后的图层”
卷积层的输出不再是原始像素,而是经过卷积核“过滤”后生成的二维数组。因为它映射了输入图像中某些特定特征(如边缘、颜色、纹理)出现的位置,所以叫“特征映射”。
输出的那个 $6 \times 7$ 的矩阵 $Y$ 就是特征映射。它上面的数值(1 或 -1)告诉下一层:“嘿,我在这个坐标点发现了垂直边缘!”
感受野 (Receptive Field)—— “视野范围”
在卷积神经网络中,输出特征图上的某一个像素点,是由输入层中多大面积的区域计算出来的?这个区域的大小就是感受野。
填充
在应用多层卷积时,我们常常丢失边缘像素。 由于我们通常使用小卷积核,因此对于任何单个卷积,我们可能只会丢失几个像素。 但随着我们应用许多连续卷积层,累积丢失的像素数就多了。 解决这个问题的简单方法即为填充(padding):在输入图像的边界填充元素0
| 层数 | 尺寸变化(无padding) |
|---|---|
| 输入 | 28×28 |
| Conv1 | 26×26 |
| Conv2 | 24×24 |
| Conv3 | 22×22 |
| … | 越来越小 |
为什么卷积核通常为奇数
卷积核通常用奇数,是为了有“中心点”,让卷积对齐简单、对称、稳定。
| 维度 | 奇数卷积核(3×3 / 5×5) | 偶数卷积核(2×2 / 4×4) | 影响 |
|---|---|---|---|
| 🎯 中心点 | ✅ 有唯一中心 | ❌ 没有中心 | 决定卷积对齐方式 |
| ⚖️ 对称性 | ✅ 完全对称 | ❌ 不对称 | 影响特征提取稳定性 |
| 📐 Padding | ✅ 可完全对称 | ❌ 必须不对称 | 导致图像偏移 |
| 🧭 特征对齐 | ✅ 不偏移 | ❌ 易产生 shift | 深层网络误差累积 |
| 🔁 平移不变性 | ✅ 强 | ❌ 弱 | CNN核心性质受影响 |
| 🏗️ 工程使用 | ✅ 主流标准 | ❌ 几乎不用 | 框架默认选择 |
| 🔬 信号处理 | ✅ 对称滤波器 | ❌ 非标准结构 | 不符合经典滤波设计 |
常见卷积核选择
| 卷积核 | 用途 | 使用频率 |
|---|---|---|
| 1×1 | 通道变换(降维/升维) | ⭐⭐⭐⭐⭐ |
| 3×3 | 主力特征提取 | ⭐⭐⭐⭐⭐ |
| 5×5 | 大感受野(较少) | ⭐⭐ |
| 7×7 | 初始层(如ResNet) | ⭐ |
| 偶数核 | 特殊算子 | 🚫 基本不用 |
案例
import torch
from torch import nn
def comp_conv2d(conv2d, X):
# 计算卷积层conv2d的输出
X = X.reshape((1, 1) + X.shape) # 将输入图像调整为4D张量,形状为(批量大小, 输入通道数, 高度, 宽度)
Y = conv2d(X) # 卷积层的前向传播,得到输出Y
return Y.reshape(Y.shape[2:]) # 将输出调整为2D张量,形状为(高度, 宽度)
# 卷积层,输入通道数为1,输出通道数为1,卷积核大小为3x3,使用padding保持输入输出尺寸相同
# 注意:在实际使用中,卷积层的权重是随机初始化的,因此每次运行代码时,卷积核权重和输出结果都会不同。
# 这里我们只是为了演示卷积操作,所以不需要对卷积核权重进行训练或调整。
# 如果需要固定卷积核权重,可以手动设置conv2d.weight.data的值,例如:
# conv2d.weight.data = torch.tensor([[[[0.0, 1.0, 0.0], [1.0, 1.0, 1.0], [0.0, 1.0, 0.0]]]]) # 设置卷积核权重为一个简单的边缘检测器
# 但在这里我们使用随机初始化的卷积核权重来演示卷积操作的效果。
conv2d = nn.Conv2d(1, 1, kernel_size=3, padding=1)
print("卷积核权重:")
print(conv2d.weight.data.reshape((3, 3))) # 打印卷积核权重,调整为3x3的形状
X = torch.rand((8, 8)) # 输入图像,随机生成一个8x8的图像
print("输入图像X:")
print(X)
Y = comp_conv2d(conv2d, X) # 计算卷积层的输出
print("卷积层输出Y:")
print(Y)
运行结果
卷积核权重:
tensor([[-0.0626, 0.2164, 0.1151],
[ 0.1596, 0.1754, -0.2650],
[-0.1399, -0.1523, 0.0862]])
输入图像X:
tensor([[0.4310, 0.7946, 0.2852, 0.8261, 0.1463, 0.9506, 0.6869, 0.6543],
[0.8802, 0.5667, 0.4798, 0.3409, 0.9920, 0.7184, 0.6024, 0.2259],
[0.0977, 0.8119, 0.1145, 0.3076, 0.9099, 0.2143, 0.1530, 0.8907],
[0.6361, 0.9120, 0.3525, 0.3611, 0.3281, 0.3711, 0.5176, 0.1686],
[0.4952, 0.4593, 0.6222, 0.3693, 0.6319, 0.0018, 0.5868, 0.6898],
[0.7671, 0.1171, 0.5071, 0.2130, 0.1705, 0.1413, 0.3398, 0.4162],
[0.0294, 0.3152, 0.5884, 0.1371, 0.7087, 0.7662, 0.8536, 0.5025],
[0.7775, 0.6400, 0.3915, 0.4022, 0.3251, 0.5856, 0.5264, 0.1908]])
卷积层输出Y:
tensor([[-0.1970, -0.0123, -0.1418, 0.1414, -0.2080, -0.1650, -0.0507, 0.1290],
[ 0.2672, 0.1864, 0.1101, 0.0901, -0.0125, 0.2769, 0.3717, 0.1006],
[ 0.0626, 0.0762, 0.0489, -0.0637, 0.3827, 0.2705, -0.1565, 0.1170],
[-0.0281, 0.2885, 0.0172, 0.1312, 0.0947, -0.0274, 0.2206, 0.1315],
[ 0.1242, 0.1347, 0.0934, 0.0251, 0.2401, 0.0722, 0.0162, 0.1311],
[ 0.3095, 0.1705, 0.1009, 0.1680, 0.1025, -0.1287, 0.0075, 0.0671],
[ 0.0611, -0.2095, 0.1529, -0.1006, -0.0491, 0.0143, 0.1290, 0.2138],
[ 0.0326, 0.2899, 0.2109, 0.1446, 0.2222, 0.2581, 0.3531, 0.1961]],
grad_fn=<ViewBackward0>)
正常训练流程
- 初始化卷积核(随机)
- 前向传播
- 计算 loss
- 反向传播(backprop)
- 更新权重(SGD / Adam)
👉 多次迭代后:
卷积核才“学会”提取特征(边缘、纹理等)
步幅
步幅(stride)= 卷积核每次移动的“步子大小”
计算公式(包含 Padding 和 Stride)当你把 输入尺寸 ($n$)、卷积核大小 ($k$)、填充 ($p$) 和 步幅 ($s$) 全部整合在一起时,输出尺寸 ($o$) 的计算公式是边缘 AI 工程师必须背下来的“金律”:
\[o = \lfloor \frac{n + 2p - k}{s} \rfloor + 1\]| 符号 | 含义 |
|---|---|
| ( n ) | 输入尺寸 |
| ( p ) | padding |
| ( k ) | 卷积核大小 |
| ( s ) | stride |
案例
| 参数 | 数值 |
|---|---|
| 输入 | 8×8 |
| kernel | 3×3 |
| padding | 1 |
步幅(stride)为 1
(8 + 2×1 - 3)/1 + 1 = 8
步幅(stride)为 2
(8 + 2×1 - 3)/2 + 1 = 4
stride 的作用总结
| 作用 | 解释 |
|---|---|
| 📉 降采样 | 减小特征图尺寸 |
| ⚡ 提高计算效率 | 少算很多位置 |
| 🧠 扩大感受野 | 间接扩大 |
| 🧹 提取粗特征 | 忽略细节 |
stride 的代价
| 问题 | 原因 |
|---|---|
| ❌ 信息丢失 | 跳过像素 |
| ❌ 精度下降 | 特征不细致 |
| ❌ 小目标检测差 | YOLO里很明显 |
conv2d = nn.Conv2d(1, 1, kernel_size=3, padding=1, stride=2)
print("卷积核权重:")
print(conv2d.weight.data.reshape((3, 3))) # 打印卷积核权重,调整为3x3的形状
X = torch.rand((8, 8)) # 输入图像,随机生成一个8x8的图像
print("输入图像X:")
print(X)
Y = comp_conv2d(conv2d, X) # 计算卷积层的输出
print("卷积层输出Y:")
print(Y)
运行结果
卷积层输出Y:
tensor([[0.2706, 0.0957, 0.1677, 0.1079],
[0.6081, 0.3156, 0.3279, 0.2736],
[0.6496, 0.6177, 0.7421, 0.9332],
[0.4267, 0.2278, 0.3566, 0.6257]], grad_fn=<ViewBackward0>)
多输入和输出通道
多输入通道
import torch
from d2l import torch as d2l
def corr2d_multi_in(X, K):
# 多输入通道的卷积操作
# 对每个输入通道和对应的卷积核进行卷积操作,并将结果相加
return sum(d2l.corr2d(x, k) for x, k in zip(X, K))
# 输入图像,包含两个通道
X = torch.tensor([[[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]],
[[1.0, 2.0, 3.0], [4.0, 5.0, 6.0], [7.0, 8.0, 9.0]]])
# 卷积核,包含两个通道,每个通道的卷积核相同
K = torch.tensor([[[0.0, 1.0], [2.0, 3.0]], [[1.0, 2.0], [3.0, 4.0]]])
# 输出卷积结果,形状为(2, 2),每个元素是两个通道卷积结果的和
print(corr2d_multi_in(X, K))
运行结果
tensor([[ 56., 72.],
[104., 120.]])
多输出通道
核心概念:特征的“多样性”
- 通道 1 可能在寻找水平边缘
- 通道 2 可能在寻找圆形轮廓
- 通道 3 可能在寻找皮肤的颜色纹理
def corr2d_multi_in_out(X, K):
# 多输入通道和多输出通道的卷积操作
# 对每个输出通道,计算所有输入通道与对应卷积核的卷积结果,并将结果相加
# K的形状为(输出通道数, 输入通道数, 卷积核高, 卷积核宽)
# 输出的形状为(输出通道数, 卷积结果高, 卷积结果宽)
return torch.stack([corr2d_multi_in(X, k) for k in K], 0)
print("多输入通道:")
print(X)
K = torch.stack([K, K + 1, K + 2], 0) # 创建三个输出通道的卷积核,每个通道的卷积核相同但数值不同
print("卷积核K的形状:")
print(K.shape) # 输出卷积核的形状,应该是(3, 2, 2, 2),表示3个输出通道,每个通道有2个输入通道,每个卷积核大小为2x2
print("卷积核K的数值:")
print(K) # 输出卷积核的数值
print("多输入通道和多输出通道的卷积结果:")
print(corr2d_multi_in_out(X, K))
运行结果
多输入通道:
tensor([[[0., 1., 2.],
[3., 4., 5.],
[6., 7., 8.]],
[[1., 2., 3.],
[4., 5., 6.],
[7., 8., 9.]]])
卷积核K的形状:
torch.Size([3, 2, 2, 2])
卷积核K的数值:
tensor([[[[0., 1.],
[2., 3.]],
[[1., 2.],
[3., 4.]]],
[[[1., 2.],
[3., 4.]],
[[2., 3.],
[4., 5.]]],
[[[2., 3.],
[4., 5.]],
[[3., 4.],
[5., 6.]]]])
多输入通道和多输出通道的卷积结果:
tensor([[[ 56., 72.],
[104., 120.]],
[[ 76., 100.],
[148., 172.]],
[[ 96., 128.],
[192., 224.]]])
1x1卷积层
1×1卷积 = 通道上的全连接层,用极低成本完成特征融合与维度控制
def corr2d_multi_in_out_1x1(X, K):
c_i, h, w = X.shape # 输入图像的通道数、高度和宽度
c_o = K.shape[0] # 输出通道数
X = X.reshape((c_i, h * w)) # 将输入图像调整为(c_i, h*w),每列是一个像素点的所有通道值
K = K.reshape((c_o, c_i)) # 将卷积核调整为(c_o, c_i),每行是一个输出通道的卷积核权重
Y = torch.matmul(K, X) # 进行矩阵乘法,得到形状为(c_o, h*w)的输出
return Y.reshape((c_o, h, w)) # 将输出调整为(c_o, h, w),每个输出通道对应一个卷积结果
X = torch.normal(0, 1, (3, 3, 3)) # 输入图像,包含3个通道,每个通道的大小为3x3
K = torch.normal(0, 1, (2, 3, 1, 1)) # 卷积核,包含2个输出通道,每个输出通道有3个输入通道,每个卷积核大小为1x1
print("输入图像X的形状:")
print(X.shape) # 输出输入图像的形状,应该是(3, 3, 3),表示3个通道,每个通道的大小为3x3\
print("输入图像X的数值:")
print(X) # 输出输入图像的数值
print("卷积核K的形状:")
print(K.shape) # 输出卷积核的形状,应该是(2, 3, 1, 1),表示2个输出通道,每个输出通道有3个输入通道,每个卷积核大小为1x1
print("卷积核K的数值:")
print(K) # 输出卷积核的数值
print("卷积结果:")
Y1 = corr2d_multi_in_out_1x1(X, K) # 计算卷积结果
print(Y1) # 输出卷积结果,形状为(2, 3, 3),表示2个输出通道,每个通道的大小为3x3
Y2 = corr2d_multi_in_out(X, K) # 计算卷积结果,使用多输入通道和多输出通道的卷积函数
print("使用多输入通道和多输出通道的卷积结果:")
print(Y2) # 输出卷积结果,形状为(2, 3, 3),表示2个输出通道,每个通道的大小为3x3
运行结果
输入图像X的形状:
torch.Size([3, 3, 3])
输入图像X的数值:
tensor([[[-1.4488, 1.8452, -0.2324],
[-0.5574, 1.0578, -0.8478],
[-0.3642, -0.1126, -1.4493]],
[[ 1.0187, 0.9153, -1.8285],
[-0.3135, -1.0638, 0.0807],
[-0.6447, -2.8693, -0.3409]],
[[-0.5591, 0.8153, -1.1109],
[-0.6639, -0.3866, 0.2516],
[-2.0620, -0.8572, 1.3227]]])
卷积核K的形状:
torch.Size([2, 3, 1, 1])
卷积核K的数值:
tensor([[[[ 0.0180]],
[[-0.8462]],
[[ 0.8041]]],
[[[-0.4792]],
[[ 1.3980]],
[[ 0.0470]]]])
卷积结果:
tensor([[[-1.3376, -0.0858, 0.6498],
[-0.2787, 0.6084, 0.1188],
[-1.1191, 1.7367, 1.3261]],
[[ 2.0920, 0.4336, -2.4971],
[-0.2023, -2.0123, 0.5309],
[-0.8237, -3.9976, 0.2801]]])
使用多输入通道和多输出通道的卷积结果:
tensor([[[-1.3376, -0.0858, 0.6498],
[-0.2787, 0.6084, 0.1188],
[-1.1191, 1.7367, 1.3261]],
[[ 2.0920, 0.4336, -2.4971],
[-0.2023, -2.0123, 0.5309],
[-0.8237, -3.9976, 0.2801]]])
