残差网络
# -*- coding: utf-8 -*-
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
# 定义 ResNet 的基础残差块(Residual Block)
# 该模块核心思想:学习“残差映射” F(X),最终输出为 F(X) + X
# 这样可以缓解深层网络训练中的梯度消失问题。
class Residual(nn.Module): #@save
# input_channels:输入通道数
# num_channels:主分支输出通道数
# use_1x1conv:是否使用 1x1 卷积调整捷径分支(shortcut)形状
# strides:主分支第一层卷积步幅(也会用于 1x1 卷积)
def __init__(self, input_channels, num_channels,
use_1x1conv=False, strides=1):
super().__init__()
# 主分支第一层:3x3 卷积,可通过 strides 控制是否下采样
self.conv1 = nn.Conv2d(input_channels, num_channels,
kernel_size=3, padding=1, stride=strides)
# 主分支第二层:3x3 卷积,步幅固定为 1,保持特征图尺寸
self.conv2 = nn.Conv2d(num_channels, num_channels,
kernel_size=3, padding=1)
if use_1x1conv:
# 捷径分支:使用 1x1 卷积将输入 X 的通道数/尺寸映射到可相加的形状
self.conv3 = nn.Conv2d(input_channels, num_channels,
kernel_size=1, stride=strides)
else:
# 形状已经一致时,不做额外映射,直接恒等连接
self.conv3 = None
# 两个批量归一化层,帮助训练更稳定、收敛更快
self.bn1 = nn.BatchNorm2d(num_channels)
self.bn2 = nn.BatchNorm2d(num_channels)
def forward(self, X):
# 主分支:Conv -> BN -> ReLU
Y = F.relu(self.bn1(self.conv1(X)))
# 主分支:Conv -> BN(此处先不激活,先与捷径分支相加)
Y = self.bn2(self.conv2(Y))
if self.conv3:
# 当形状不一致时,对输入 X 做 1x1 卷积映射
X = self.conv3(X)
# 残差连接:主分支输出与捷径分支相加
Y += X
# 相加后再做 ReLU 激活,得到最终输出
return F.relu(Y)
# 下面先做一个最小示例,验证残差块前向传播是否正常
# 输入:batch=4,通道=3,高宽=6x6
blk = Residual(3,3)
X = torch.rand(4, 3, 6, 6)
Y = blk(X)
print("输入张量 X 的形状:", X.shape)
print("输出张量 Y 的形状:", Y.shape)
print("输出张量 Y(第1个样本,第1个通道):")
print(Y[0, 0])
# b1:ResNet 的首个阶段(Stem)
# - 7x7 卷积 + BN + ReLU:快速提取低层特征
# - 最大池化:降低分辨率,减少后续计算量
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
# 用于批量构建某个 stage 的残差块
# input_channels:进入该 stage 的输入通道数
# num_channels:该 stage 输出通道数
# num_residuals:该 stage 堆叠的残差块个数
# first_block:是否是整个网络中的第一个残差 stage(第一个 stage 不做下采样)
def resnet_block(input_channels, num_channels, num_residuals,
first_block=False):
blk = []
for i in range(num_residuals):
# 对于非首个 stage 的第一个残差块:
# 1) 通道数通常变化
# 2) 用 stride=2 下采样
# 3) 用 1x1 卷积匹配捷径分支形状
if i == 0 and not first_block:
blk.append(Residual(input_channels, num_channels,
use_1x1conv=True, strides=2))
else:
# 其余残差块保持通道与尺寸不变
blk.append(Residual(num_channels, num_channels))
return blk
# b2~b5:四个残差 stage,通道数逐步增大
# 其中 b3/b4/b5 的首块会下采样,使特征图尺寸逐步减小
b2 = nn.Sequential(*resnet_block(64, 64, 2, first_block=True))
b3 = nn.Sequential(*resnet_block(64, 128, 2))
b4 = nn.Sequential(*resnet_block(128, 256, 2))
b5 = nn.Sequential(*resnet_block(256, 512, 2))
# 组装完整 ResNet:
# b1~b5 特征提取 -> 全局平均池化 -> 展平 -> 线性分类层(10 类)
net = nn.Sequential(b1, b2, b3, b4, b5,
nn.AdaptiveAvgPool2d((1,1)),
nn.Flatten(), nn.Linear(512, 10))
# 用随机输入查看每个大模块输出形状,便于核对网络结构
X = torch.rand(size=(1, 1, 224, 224))
for layer in net:
X = layer(X)
print(layer.__class__.__name__,'output shape:\t', X.shape)
# 训练超参数说明:
# lr:学习率,控制参数更新步长
# num_epochs:训练轮数,表示完整遍历训练集次数
# batch_size:批量大小,每次迭代使用样本数
lr, num_epochs, batch_size = 0.05, 10, 256
# 加载 Fashion-MNIST,并缩放到 96x96 与当前网络输入设定匹配
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96)
# 调用 d2l 封装训练函数,自动选择可用 GPU(若无则退回 CPU)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
运行结果
Sequential output shape: torch.Size([1, 64, 56, 56])
Sequential output shape: torch.Size([1, 64, 56, 56])
Sequential output shape: torch.Size([1, 128, 28, 28])
Sequential output shape: torch.Size([1, 256, 14, 14])
Sequential output shape: torch.Size([1, 512, 7, 7])
AdaptiveAvgPool2d output shape: torch.Size([1, 512, 1, 1])
Flatten output shape: torch.Size([1, 512])
Linear output shape: torch.Size([1, 10])
training on cuda:0
单个 Residual Block
输入 X
│
├─── 主分支 ────────────────────────┐
│ 3×3 Conv │
│ ↓ │
│ BN + ReLU │
│ ↓ │
│ 3×3 Conv │
│ ↓ │
│ BN │
│ │
├─── Shortcut 分支 ───────────────┐ │
│ (可选) 1×1 Conv │ │
│ │ │
└─────────────── 相加 (+) ◄──────┘ │
↓
ReLU
↓
输出
全局网络
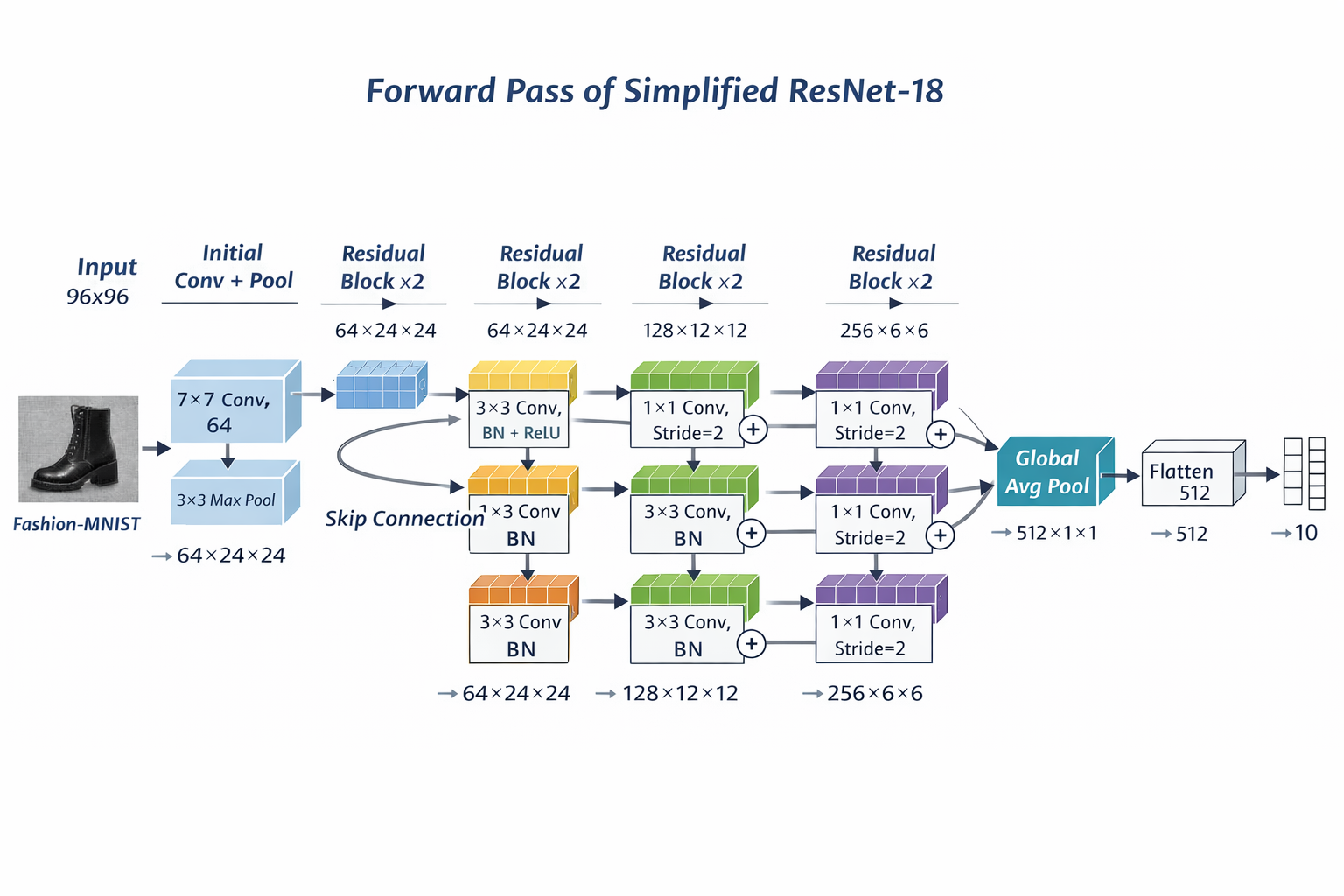
输入
→ 卷积降采样
→ 4个残差stage(64→128→256→512)
→ 全局池化
→ 分类
参数数量
b1 = 3,328
b2 = 148,224
b3 = 525,440
b4 = 2,099,200
b5 = 8,392,704
FC = 5,130
-----------------------
Total ≈ 11,174,026
0
次点赞