图像增广 Image Augmentation
通过“随机改造”训练图片,让模型学会真正理解目标,而不是死记硬背训练集。
翻转和裁减
import torch
import torchvision
from torch import nn
from d2l import torch as d2l
d2l.set_figsize()
# 打开图像
# 这里我们使用了d2l库中的Image类来打开图像文件。你需要确保在当前目录下有一个名为'img'的文件夹,并且里面有一张名为'cat1.jpg'的图片。
# 打开图像后,我们可以使用d2l.plt.imshow()函数来显示图像,并使用d2l.plt.show()函数来展示图像窗口。
img = d2l.Image.open('./img/cat1.jpg')
# d2l.plt.imshow(img);
# d2l.plt.show()
# 定义一个函数来展示增强后的图像
# 参数img是输入图像,aug是图像增强方法,num_rows和num_cols分别指定展示的行数和列数,scale指定图像的缩放比例。
def apply(img, aug, num_rows=2, num_cols=4, scale=1.5):
Y = [aug(img) for _ in range(num_rows * num_cols)]
d2l.show_images(Y, num_rows, num_cols, scale=scale)
# 下面我们将使用不同的图像增强方法来处理图像,并展示增强后的结果。
# 首先,我们使用torchvision.transforms.RandomHorizontalFlip()方法来随机水平翻转图像。
# 这个方法会以一定的概率(默认是0.5)将图像水平翻转。
apply(img, torchvision.transforms.RandomHorizontalFlip())
# 接下来,我们使用torchvision.transforms.RandomVerticalFlip()方法来随机垂直翻转图像。
# 这个方法会以一定的概率(默认是0.5)将图像垂直翻转。
apply(img, torchvision.transforms.RandomVerticalFlip())
# 最后,我们使用torchvision.transforms.RandomResizedCrop()方法来随机裁剪图像并调整大小。
# 这个方法会随机裁剪图像的一部分,并将其调整为指定的大小。
# 在这个例子中,我们将图像裁剪为200x200像素,并且裁剪的区域的面积占原图的比例在0.1到1之间,宽高比在0.5到2之间。
shape_aug = torchvision.transforms.RandomResizedCrop(
(200, 200), scale=(0.1, 1), ratio=(0.5, 2))
apply(img, shape_aug)
d2l.plt.show()
图像裁减后的显示

改变颜色
# 最后,我们使用torchvision.transforms.ColorJitter()方法来随机改变图像的亮度、对比度、饱和度和色调。
# 在这个例子中,我们将亮度调整范围设置为0.5,对比度、饱和度和色调的调整范围设置为0。
# 8张图像中,每张图像的亮度都会在原图的基础上随机调整,调整范围为原图亮度的0.5倍到1.5倍之间。
apply(img, torchvision.transforms.ColorJitter(
brightness=0.5, contrast=0, saturation=0, hue=0))
# 8张图像中,每张图像的色调都会在原图的基础上随机调整,调整范围为原图色调的-0.5到0.5之间。
apply(img, torchvision.transforms.ColorJitter(
brightness=0, contrast=0, saturation=0, hue=0.5))
# 8张图像中,每张图像的亮度、对比度、饱和度和色调都会在原图的基础上随机调整,调整范围为原图的0.5倍到1.5倍之间。
color_aug = torchvision.transforms.ColorJitter(
brightness=0.5, contrast=0.5, saturation=0.5, hue=0.5)
apply(img, color_aug)
结合多种图像增广方法
# 最后,我们将随机水平翻转、随机裁剪和颜色抖动这三种图像增强方法组合在一起,来同时增强图像的形状和颜色。
augs = torchvision.transforms.Compose([
torchvision.transforms.RandomHorizontalFlip(), color_aug, shape_aug])
apply(img, augs)
使用图像增广训练
数据准备
# 下面我们将使用CIFAR-10数据集来展示图像增强的效果。
# CIFAR-10数据集包含了10个类别的60000张32x32像素的彩色图像,其中50000张用于训练,10000张用于测试。
# 这里我们使用torchvision.datasets.CIFAR10()函数来加载CIFAR-10数据集,并将train参数设置为True来获取训练集。
all_images = torchvision.datasets.CIFAR10(train=True, root="../data",
download=False)
# 加载完成后,我们可以使用d2l.show_images()函数来展示前32张图像,并将它们排列成4行8列的格式。
d2l.show_images([all_images[i][0] for i in range(32)], 4, 8, scale=0.8);
d2l.plt.show()

训练代码
# 定义一个函数来加载CIFAR-10数据集,并应用指定的图像增强方法。
def load_cifar10(is_train, augs, batch_size):
dataset = torchvision.datasets.CIFAR10(root="../data", train=is_train,
transform=augs, download=False)
dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size,
shuffle=is_train, num_workers=d2l.get_dataloader_workers())
return dataloader
#@save
def train_batch_ch13(net, X, y, loss, trainer, devices):
"""
用多GPU进行小批量训练
参数:
net: 神经网络模型(可能已封装为DataParallel以支持多GPU)
X: 输入数据(可以是Tensor或Tensor列表,BERT等模型可能为列表)
y: 标签
loss: 损失函数
trainer: 优化器
devices: 设备列表(如[GPU0, GPU1,...])
返回:
train_loss_sum: 当前批次的总损失
train_acc_sum: 当前批次的总准确率
"""
# 如果输入是列表(如BERT等模型),将每个输入都搬到主设备(devices[0])
if isinstance(X, list):
# 微调BERT等模型时,输入通常为多个Tensor
X = [x.to(devices[0]) for x in X]
else:
# 普通情况,直接将输入搬到主设备
X = X.to(devices[0])
# 标签也搬到主设备
y = y.to(devices[0])
# 设置模型为训练模式(启用Dropout/BN等)
net.train()
# 梯度清零,防止梯度累加
trainer.zero_grad()
# 前向传播,获得预测结果
pred = net(X)
# 计算损失(返回每个样本的损失)
l = loss(pred, y)
# 反向传播,计算梯度(对所有样本损失求和后反传)
l.sum().backward()
# 优化器更新参数
trainer.step()
# 统计本批次总损失
train_loss_sum = l.sum()
# 统计本批次准确率
train_acc_sum = d2l.accuracy(pred, y)
return train_loss_sum, train_acc_sum
#@save
def train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs,
devices=d2l.try_all_gpus()):
"""用多GPU进行模型训练"""
timer, num_batches = d2l.Timer(), len(train_iter)
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0, 1],
legend=['train loss', 'train acc', 'test acc'])
# 将模型封装为DataParallel以支持多GPU训练,并将模型搬到主设备
net = nn.DataParallel(net, device_ids=devices).to(devices[0])
# 训练多个epoch
for epoch in range(num_epochs):
# 4个维度:储存训练损失,训练准确度,实例数,特点数
metric = d2l.Accumulator(4)
for i, (features, labels) in enumerate(train_iter):
timer.start()
l, acc = train_batch_ch13(
net, features, labels, loss, trainer, devices)
metric.add(l, acc, labels.shape[0], labels.numel())
timer.stop()
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(metric[0] / metric[2], metric[1] / metric[3],
None))
test_acc = d2l.evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
print(f'loss {metric[0] / metric[2]:.3f}, train acc '
f'{metric[1] / metric[3]:.3f}, test acc {test_acc:.3f}')
print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec on '
f'{str(devices)}')
batch_size, devices, net = 256, d2l.try_all_gpus(), d2l.resnet18(10, 3)
# 初始化模型参数
def init_weights(m):
if type(m) in [nn.Linear, nn.Conv2d]:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
def train_with_data_aug(train_augs, test_augs, net, lr=0.001):
train_iter = load_cifar10(True, train_augs, batch_size)
test_iter = load_cifar10(False, test_augs, batch_size)
loss = nn.CrossEntropyLoss(reduction="none")
trainer = torch.optim.Adam(net.parameters(), lr=lr)
train_ch13(net, train_iter, test_iter, loss, trainer, 10, devices)
train_with_data_aug(train_augs, test_augs, net)
训练过程
原始图像
↓
数据增强(augmentation)
↓
Dataset
↓
DataLoader
↓
ResNet18
↓
forward
↓
loss
↓
backward
↓
Adam 更新参数
↓
test accuracy
神经网络图
输入图像 32×32×3
↓
卷积层 Conv
↓
残差块 Block1
↓
残差块 Block2
↓
残差块 Block3
↓
残差块 Block4
↓
全局平均池化 GAP
↓
全连接层 FC
↓
10分类输出
微调

源码
import os
import torch
import torchvision
from torch import nn
from d2l import torch as d2l
# 本案例演示如何使用预训练的ResNet-18模型进行迁移学习(微调),用于二分类(热狗/非热狗)任务。
#@save
d2l.DATA_HUB['hotdog'] = (d2l.DATA_URL + 'hotdog.zip',
'fba480ffa8aa7e0febbb511d181409f899b9baa5')
data_dir = d2l.download_extract('hotdog')
# 加载训练集和测试集图片,数据集结构需为ImageFolder格式(train/、test/子文件夹分别存放类别图片)。
train_imgs = torchvision.datasets.ImageFolder(os.path.join(data_dir, 'train'))
test_imgs = torchvision.datasets.ImageFolder(os.path.join(data_dir, 'test'))
# 数据增强与标准化:
# 训练集:随机裁剪为224x224、随机水平翻转、转为Tensor、标准化
# 测试集:缩放到256x256、中心裁剪224x224、转为Tensor、标准化
# 使用RGB通道的均值和标准差,以标准化每个通道
normalize = torchvision.transforms.Normalize(
[0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
# 下面我们将使用不同的图像增强方法来处理图像,并展示增强后的结果。
train_augs = torchvision.transforms.Compose([
torchvision.transforms.RandomResizedCrop(224),
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.ToTensor(),
normalize])
#
test_augs = torchvision.transforms.Compose([
torchvision.transforms.Resize([256, 256]),
torchvision.transforms.CenterCrop(224),
torchvision.transforms.ToTensor(),
normalize])
#
pretrained_net = torchvision.models.resnet18(pretrained=True)
# 加载预训练的ResNet-18模型,并将最后的全连接层(fc)替换为2分类输出(热狗/非热狗)
finetune_net = torchvision.models.resnet18(pretrained=True)
finetune_net.fc = nn.Linear(finetune_net.fc.in_features, 2) # 输出类别数为2
nn.init.xavier_uniform_(finetune_net.fc.weight); # 用Xavier初始化新全连接层参数
# 如果param_group=True,输出层中的模型参数将使用十倍的学习率
def train_fine_tuning(net, learning_rate, batch_size=128, num_epochs=5,
param_group=True):
# 构建训练集和测试集的DataLoader,应用对应的数据增强
train_iter = torch.utils.data.DataLoader(
torchvision.datasets.ImageFolder(os.path.join(data_dir, 'train'), transform=train_augs),
batch_size=batch_size, shuffle=True)
test_iter = torch.utils.data.DataLoader(
torchvision.datasets.ImageFolder(os.path.join(data_dir, 'test'), transform=test_augs),
batch_size=batch_size)
# 自动检测可用GPU设备
devices = d2l.try_all_gpus()
# 使用交叉熵损失
loss = nn.CrossEntropyLoss(reduction="none")
# 优化器参数分组:
# 预训练层使用较小学习率,最后新加的全连接层使用10倍学习率,加速收敛
if param_group:
params_1x = [param for name, param in net.named_parameters()
if name not in ["fc.weight", "fc.bias"]]
trainer = torch.optim.SGD([
{'params': params_1x}, # 预训练层参数
{'params': net.fc.parameters(), 'lr': learning_rate * 10} # 新增层参数
], lr=learning_rate, weight_decay=0.001)
else:
# 所有参数同一学习率
trainer = torch.optim.SGD(net.parameters(), lr=learning_rate, weight_decay=0.001)
# 调用d2l实现的多GPU训练主循环
d2l.train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs, devices)
# 调用训练函数,进行微调。learning_rate=5e-5,最后一层学习率为5e-4。
train_fine_tuning(finetune_net, 5e-5)
训练流程
┌────────────────────┐
│ 热狗训练图片 │
└────────────────────┘
│
▼
┌────────────────────┐
│ 数据增强(DataAug) │
│ 随机裁剪/翻转/归一化 │
└────────────────────┘
│
▼
┌────────────────────┐
│ 预训练ResNet18 │
│ (ImageNet学好的) │
└────────────────────┘
│
┌────────────────┴────────────────┐
▼ ▼
┌──────────────────┐ ┌──────────────────┐
│ 前面卷积层 │ │ 最后全连接层(fc) │
│ 保留已有知识 │ │ 换成新的2分类层 │
└──────────────────┘ └──────────────────┘
│ │
│ 小学习率 │ 大学习率
│ 慢慢调整 │ 快速学习
▼ ▼
┌────────────────────┐
│ 输出分类结果 │
│ hotdog / nothotdog │
└────────────────────┘
学习率不同解释
ImageNet预训练模型
↓
已有视觉能力
↓
替换最后分类层
↓
小学习率保护原知识
大学习率训练新层
↓
逐渐适应热狗任务
↓
得到专用分类器
学习率本质: 参数每次更新的步长
AI 大模型微调(Fine-tuning)到底是什么?
GPT-4
↓
继续训练
↓
变成:
法律助手
医疗助手
代码助手
金融助手
因为预训练模型太通用, 现实任务往往很专业
| 场景 | 需要什么 |
|---|---|
| 医疗AI | 医学知识 |
| 金融AI | 金融术语 |
| 客服AI | 公司业务 |
| 编程AI | 代码风格 |
| Android助手 | Framework知识 |
为什么会突然出现几十家大模型公司
Llama/Qwen 开源 -> 行业门槛大降 -> 中国AI公司爆发
为什么 DeepSeek 会震动行业?
- 因为它证明:高性能AI不一定需要OpenAI级资金
- 过去行业默认:只有几千亿美元资本, 才能做AGI
生态图
┌──────────────────────┐
│ 算力基础设施 │
│ NVIDIA / AMD / 云厂商 │
└──────────────────────┘
▲
│
│ GPU/集群/云服务
│
────────────────────────────────────────────────────
┌──────────────────────┐
│ 基础模型层 │
│ Foundation Models │
└──────────────────────┘
┌──────────────┬──────────────┬──────────────┐
▼ ▼ ▼
闭源路线 开源路线 中国路线
┌────────────┐ ┌────────────┐ ┌────────────┐
│ OpenAI │ │ Llama │ │ Qwen │
│ Claude │ │ Mistral │ │ DeepSeek │
│ Gemini │ │ Gemma │ │ GLM │
└────────────┘ └────────────┘ └────────────┘
────────────────────────────────────────────────────
┌──────────────────────┐
│ 后训练/微调层 │
│ SFT / RLHF / LoRA │
└──────────────────────┘
┌──────────────┬──────────────┬──────────────┐
▼ ▼ ▼
医疗AI 金融AI 工业AI
法律AI 教育AI 政务AI
────────────────────────────────────────────────────
┌──────────────────────┐
│ Agent工作流层 │
│ Tool Use / RAG / MCP │
└──────────────────────┘
┌───────────────────────────┐
│ AI开始调用真实世界工具 │
│ │
│ 搜索 / SQL / IDE / 浏览器 │
│ ERP / CRM / API系统 │
└───────────────────────────┘
────────────────────────────────────────────────────
┌──────────────────────┐
│ 应用层 │
│ AI Native Apps │
└──────────────────────┘
┌──────────┬──────────┬──────────┬──────────┐
▼ ▼ ▼ ▼
AI编程 AI客服 AI办公 AI搜索
AI设计 AI医疗 AI投顾 AI机器人
利润流向图
AI产业利润金字塔(2026)
▲
│
│ 利润率最高
│
┌────────────────────┐
│ GPU/云厂商 │
│ NVIDIA / 云计算 │
└────────────────────┘
│
│ 所有人都要买算力
▼
┌────────────────────┐
│ 基础模型公司 │
│ OpenAI/Anthropic │
└────────────────────┘
│
│ 高研发投入
│ 高推理成本
▼
┌────────────────────┐
│ AI Agent/平台层 │
│ 自动化工作流 │
└────────────────────┘
│
│ 开始出现SaaS利润
▼
┌────────────────────┐
│ 行业应用层 │
│ 医疗/教育/办公AI │
└────────────────────┘
│
│ 最卷
▼
┌────────────────────┐
│ 普通AI套壳应用 │
│ Chat Wrapper │
└────────────────────┘
大模型厂商的护城河
AI技术壁垒金字塔
▲
│
│ 最难
│
┌────────────────────┐
│ 超大规模预训练 │
│ 分布式训练/算力 │
└────────────────────┘
▼
┌────────────────────┐
│ RLHF / 后训练 │
│ 对齐 / 推理能力 │
└────────────────────┘
▼
┌────────────────────┐
│ 高质量行业数据 │
│ 企业私有知识 │
└────────────────────┘
▼
┌────────────────────┐
│ Agent工作流系统 │
│ Tool Use / MCP │
└────────────────────┘
▼
┌────────────────────┐
│ 工程优化能力 │
│ CUDA / 推理加速 │
└────────────────────┘
▼
┌────────────────────┐
│ UI套壳 │
│ 最容易复制 │
└────────────────────┘
OpenAI 对比 DeepSeek
| 项目 | OpenAI GPT-4时代 | DeepSeek V3/R1时代 |
|---|---|---|
| 模型路线 | 闭源 Dense | 开源 MoE |
| 训练方式 | 超大规模暴力堆算力 | 强工程优化 |
| 训练成本 | ~$1亿+ | ~$500万级(公开估算) |
| GPU规模 | 数万张A100/H100 | 几千张H800 |
| 激活参数 | 大量全部激活 | 只激活部分专家 |
| 推理成本 | 很高 | 极低 |
| API价格 | 高 | 极低 |
| 开源 | 否 | 是 |
| 主要优势 | 顶级综合能力 | 超高性价比 |
| 最大壁垒 | Frontier Research | 工程优化+效率 |
Anthropic 多模态
战略核心不同:他们押的是“可靠性”,不是“能力广度”
Anthropic 的主线是:安全 + 可控 + 可解释 + 推理能力
多模态 = 工程复杂度暴增,但收益不一定线性增长
多模态意味着:
文本 + 图像 + 音频 + 视频 + 时序
会带来:
数据对齐难度上升
训练成本暴涨
评估体系复杂
错误类型更多
Claude 系列在企业端的优势非常明确:
稳定性 > 炫技能力
- 法律总结错一条条款
- 金融分析幻觉一个数字
- 代码生成引入隐性 bug
👉 成本是直接可量化的。
长文本能力 = 企业刚需
- 可以读完整合同
- 可以分析整份财报
- 可以理解整套代码仓库
- 可以做审计级分析
企业愿意为“可靠性”付溢价
企业级“安全AI基础设施”
目标检测和边界框
import torch
from d2l import torch as d2l
d2l.set_figsize()
img = d2l.plt.imread('../img/catdog.jpg')
# d2l.plt.imshow(img);
# d2l.plt.show()
#@save
def box_corner_to_center(boxes):
"""从(左上,右下)转换到(中间,宽度,高度)"""
x1, y1, x2, y2 = boxes[:, 0], boxes[:, 1], boxes[:, 2], boxes[:, 3]
cx = (x1 + x2) / 2
cy = (y1 + y2) / 2
w = x2 - x1
h = y2 - y1
boxes = torch.stack((cx, cy, w, h), axis=-1)
return boxes
#@save
def box_center_to_corner(boxes):
"""从(中间,宽度,高度)转换到(左上,右下)"""
cx, cy, w, h = boxes[:, 0], boxes[:, 1], boxes[:, 2], boxes[:, 3]
x1 = cx - 0.5 * w
y1 = cy - 0.5 * h
x2 = cx + 0.5 * w
y2 = cy + 0.5 * h
boxes = torch.stack((x1, y1, x2, y2), axis=-1)
return boxes
# bbox是边界框的英文缩写
dog_bbox, cat_bbox = [60.0, 45.0, 378.0, 516.0], [400.0, 112.0, 655.0, 493.0]
#@save
def bbox_to_rect(bbox, color):
# 将边界框(左上x,左上y,右下x,右下y)格式转换成matplotlib格式:
# ((左上x,左上y),宽,高)
return d2l.plt.Rectangle(
xy=(bbox[0], bbox[1]), width=bbox[2]-bbox[0], height=bbox[3]-bbox[1],
fill=False, edgecolor=color, linewidth=2)
fig = d2l.plt.imshow(img)
fig.axes.add_patch(bbox_to_rect(dog_bbox, 'blue'))
fig.axes.add_patch(bbox_to_rect(cat_bbox, 'red'));
d2l.plt.show()
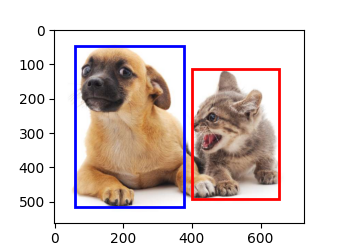
锚框
目标检测算法通常会在输入图像中采样大量的区域,然后判断这些区域中是否包含我们感兴趣的目标,并调整区域边界从而更准确地预测目标的真实边界框(ground-truth bounding box)
不同的模型使用的区域采样方法可能不同。 这里我们介绍其中的一种方法:以每个像素为中心,生成多个缩放比和宽高比(aspect ratio)不同的边界框。 这些边界框被称为锚框(anchor box)
“先在图片上预设大量候选框(锚框),再让神经网络判断哪些框里有目标,并微调框的位置。
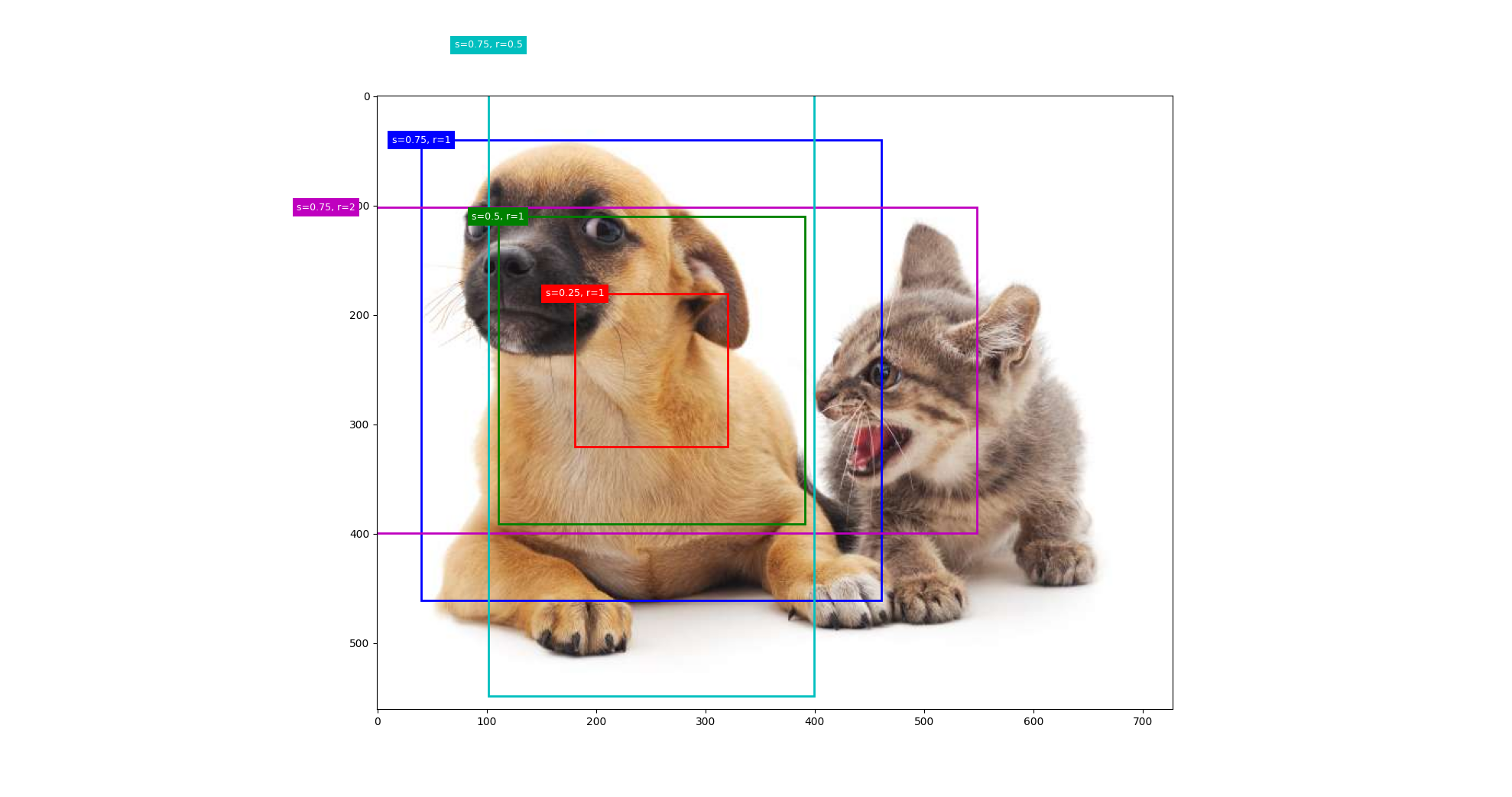
Anchor 的思想
提前在图像上:
- 放很多不同大小
- 不同长宽比
- 不同位置
的候选框。
为什么每个像素都生成锚框?
因为:
目标可能出现在任意位置。
所以:
每个像素中心
↓
生成多个候选框
最终:
特征图 H×W×K 个 anchors
数量巨大。
例如:
38×38×4 = 5776
这也是目标检测计算量大的原因之一。
IoU(交并比)
衡量:两个框有多像

| IoU | 意义 |
|---|---|
| >0.5 | 匹配较好 |
| >0.7 | 很好 |
| <0.3 | 很差 |
IoU 在哪里用?
1. 训练阶段
决定:
哪个 anchor 负责哪个目标。
例如:
anchor 和 狗 的 IoU 最大
那么:
这个 anchor 负责检测狗
2. 推理阶段
用于:
NMS(非极大值抑制)
删除重复框。
目标检测 = 分类 + 回归
- 分类: 框里是什么?
- 回归: 框的位置怎么调?
Anchor 有很多问题:
- 超参数太多
- 正负样本不平衡
- 计算量大
- 需要调 sizes/ratios
Anchor 思想依然是理解目标检测的基础
流程图
输入图片
↓
CNN特征图
↓
每个像素生成多个Anchor
↓
预测:
1. 类别
2. offset
↓
根据offset修正框
↓
得到大量预测框
↓
NMS去重
↓
最终检测结果
目标检测训练之前,必须先人工标注(label)目标框和类别
一个完整标注长这样
例如:
图片:street.jpg
目标1:
类别:person
框:[120, 80, 300, 600]
目标2:
类别:car
框:[500, 400, 900, 700]
目标检测的人工数据标注成本远高于分类
训练过程
┌─────────────────────────────────────┐
│ 人工标注训练数据 │
│ │
│ image.jpg │
│ ├─ cat [100,100,300,300] │
│ └─ dog [400,200,700,600] │
└─────────────────────────────────────┘
│
▼
┌─────────────────────────────────────┐
│ 输入训练图片 │
└─────────────────────────────────────┘
│
▼
┌─────────────────────────────────────┐
│ CNN 提取特征图 │
│ │
│ ResNet / MobileNet / VGG │
│ │
│ image │
│ ↓ │
│ Feature Map │
└─────────────────────────────────────┘
│
▼
┌─────────────────────────────────────┐
│ 生成大量 Anchor │
│ │
│ 每个特征点生成多个框: │
│ │
│ ▢ ▭ ▯ │
│ │
│ 总数量可能: │
│ 32×32×9 = 9216 │
└─────────────────────────────────────┘
│
▼
┌─────────────────────────────────────┐
│ Anchor 与 GT 计算 IoU │
│ │
│ A1 → 0.1 │
│ A2 → 0.8 │
│ A3 → 0.2 │
└─────────────────────────────────────┘
│
▼
┌─────────────────────────────────────┐
│ 给 Anchor 打标签 │
│ │
│ Positive: │
│ class = cat │
│ offset = Δx Δy Δw Δh │
│ │
│ Negative: │
│ background │
└─────────────────────────────────────┘
│
▼
┌─────────────────────────────────────┐
│ 神经网络开始预测 │
│ │
│ 对每个 Anchor 输出: │
│ │
│ 1. 分类概率 │
│ 2. bbox offset │
│ │
│ 例如: │
│ cat: 0.92 │
│ dog: 0.01 │
│ bg : 0.07 │
└─────────────────────────────────────┘
│
▼
┌─────────────────────────────────────┐
│ 计算 Loss │
│ │
│ L = 分类损失 + bbox损失 │
│ │
│ 分类错了? │
│ 框偏了? │
└─────────────────────────────────────┘
│
▼
┌─────────────────────────────────────┐
│ 反向传播 Backprop │
│ │
│ 自动计算梯度 │
│ 调整卷积核参数 │
└─────────────────────────────────────┘
│
▼
┌─────────────────────────────────────┐
│ 更新网络参数 │
│ │
│ SGD / Adam │
│ │
│ 让 Loss 更小 │
└─────────────────────────────────────┘
│
│
┌─────────┴─────────┐
│ │
│ 下一批训练数据 │
│ (Next Batch) │
│ │
└─────────┬─────────┘
│
│
▼
╭───────────────────╮
│ │
│ 重复几十万次 │
│ │
│ Forward │
│ ↓ │
│ Loss │
│ ↓ │
│ Backprop │
│ ↓ │
│ Update Weights │
│ │
╰────────┬──────────╯
│
│
└──────────────────────┐
│
▼
┌─────────────────────┐
│ CNN继续学习特征 │
│ │
│ 什么像猫? │
│ 什么像狗? │
│ 框怎么调整? │
└─────────────────────┘
│
▼
┌─────────────────────┐
│ 最终训练完成 │
│ │
│ 得到目标检测模型 │
└─────────────────────┘
推理过程
┌─────────────────────────────────────┐
│ 新输入图片 │
│ │
│ test.jpg │
│ │
│ (注意:这里已经没有GT真实框) │
└─────────────────────────────────────┘
│
▼
┌─────────────────────────────────────┐
│ 图像预处理 Preprocess │
│ │
│ 1. resize │
│ 2. normalize │
│ 3. RGB转换 │
│ 4. tensor化 │
└─────────────────────────────────────┘
│
▼
┌─────────────────────────────────────┐
│ 输入神经网络 CNN │
│ │
│ ResNet / MobileNet / CSPDarknet │
│ │
│ 提取高级特征 │
└─────────────────────────────────────┘
│
▼
┌─────────────────────────────────────┐
│ 生成 Feature Map │
│ │
│ 例如: │
│ │
│ 640×640 image │
│ ↓ │
│ 80×80 feature map │
└─────────────────────────────────────┘
│
▼
┌─────────────────────────────────────┐
│ 生成大量 Anchor │
│ │
│ 每个特征点生成多个框: │
│ │
│ ▢ ▭ ▯ │
│ │
│ 小目标框 │
│ 大目标框 │
│ 长方形框 │
│ │
│ 总数可能: │
│ 80×80×3 = 19200 │
└─────────────────────────────────────┘
│
▼
┌─────────────────────────────────────┐
│ 网络对每个 Anchor 做预测 │
│ │
│ 输出: │
│ │
│ 1. 分类概率 │
│ 2. bbox offset │
│ 3. confidence │
└─────────────────────────────────────┘
│
▼
┌─────────────────────────────────────┐
│ 分类概率输出示例 │
│ │
│ Anchor#15231 │
│ │
│ cat : 0.92 │
│ dog : 0.03 │
│ car : 0.01 │
│ bg : 0.04 │
└─────────────────────────────────────┘
│
▼
┌─────────────────────────────────────┐
│ bbox offset 输出 │
│ │
│ Δx = +0.12 │
│ Δy = -0.08 │
│ Δw = +0.05 │
│ Δh = -0.03 │
│ │
│ 意思: │
│ 向右移动一点 │
│ 向上移动一点 │
│ 宽一点 │
│ 矮一点 │
└─────────────────────────────────────┘
│
▼
┌─────────────────────────────────────┐
│ 使用 offset 修正 Anchor │
│ │
│ Anchor │
│ [90,90,290,310] │
│ │
│ + offset │
│ │
│ Final Box │
│ [100,100,300,300] │
└─────────────────────────────────────┘
│
▼
┌─────────────────────────────────────┐
│ 得到大量预测框 │
│ │
│ Box1: cat 0.95 │
│ Box2: cat 0.93 │
│ Box3: cat 0.91 │
│ Box4: dog 0.88 │
│ ... │
│ │
│ (大量重复框) │
└─────────────────────────────────────┘
│
▼
┌─────────────────────────────────────┐
│ 置信度过滤 Confidence Filter │
│ │
│ 删除低分框: │
│ │
│ score < 0.5 │
│ │
│ 例如: │
│ │
│ cat 0.12 → 删除 │
│ dog 0.08 → 删除 │
└─────────────────────────────────────┘
│
▼
┌─────────────────────────────────────┐
│ NMS 非极大值抑制 │
│ │
│ 目的: │
│ 删除重复框 │
│ │
│ Step1: │
│ 按score排序 │
│ │
│ 0.95 │
│ 0.93 │
│ 0.91 │
│ │
│ Step2: │
│ 保留最高分框 │
│ │
│ Step3: │
│ 计算IoU │
│ │
│ IoU太高 → 删除重复框 │
└─────────────────────────────────────┘
│
▼
┌─────────────────────────────────────┐
│ 最终检测结果输出 │
│ │
│ cat 0.95 │
│ bbox:[100,100,300,300] │
│ │
│ dog 0.88 │
│ bbox:[400,200,700,600] │
└─────────────────────────────────────┘
│
▼
┌─────────────────────────────────────┐
│ 绘制检测框 │
│ │
│ 在图像上画出: │
│ │
│ ┌──────────┐ │
│ │ cat │ │
│ └──────────┘ │
│ │
│ 显示类别 + 分数 │
└─────────────────────────────────────┘
│
▼
┌─────────────────────────────────────┐
│ 推理结束 │
│ │
│ 输出最终目标: │
│ │
│ “图中有猫和狗” │
└─────────────────────────────────────┘
YOLO
You Only Look Once
输入图片
↓
CNN提取特征
↓
直接输出:
1. 类别
2. bbox
3. confidence
↓
NMS
↓
最终结果
YOLOv5 对比 YOLOv8
| 项目 | YOLOv5 | YOLOv8 |
|---|---|---|
| 检测范式 | Anchor-based | Anchor-free |
| Head | Coupled | Decoupled |
| 样本分配 | 静态IoU | 动态TaskAligned |
| Backbone | CSP | C2f |
| Loss | CIoU | DFL + IoU |
| 后处理 | 简单 | 更复杂 |
| 工程成熟度 | 极高 | 高 |
| RKNN支持 | 极成熟 | 中高 |
| 小目标 | 中 | 更强 |
| 泛化能力 | 强 | 更强 |
| 部署难度 | 低 | 中 |
| 实时性 | 极强 | 强 |
| Transformer思想 | 少 | 更多 |
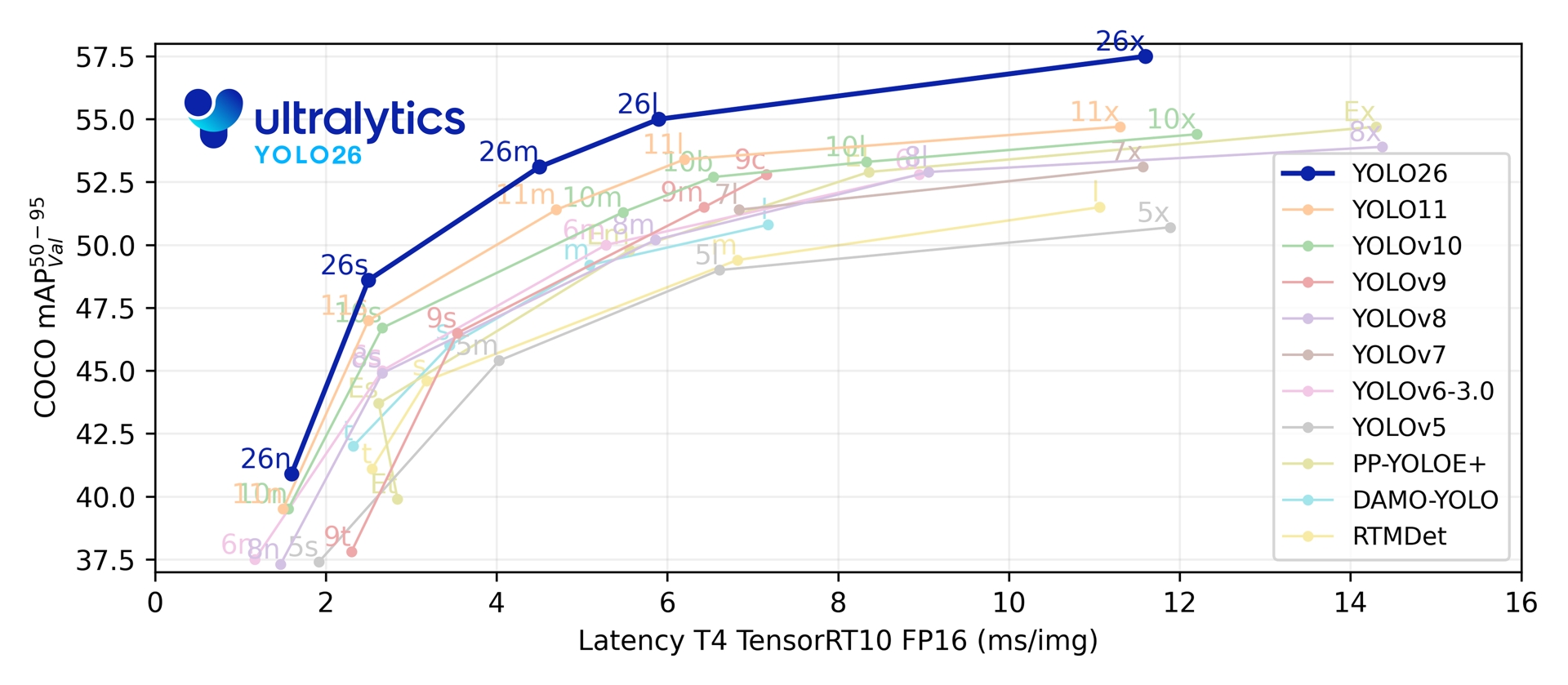
Ultralytics YOLO26
Ultralytics YOLO26 是 YOLO 系列实时对象检测器的最新演进,从头开始专为边缘和低功耗设备而设计。它引入了简化的设计,消除了不必要的复杂性,同时集成了有针对性的创新,以实现更快、更轻、更易于访问的部署。
SAM3
| 项目 | YOLO | SAM3.x |
|---|---|---|
| 核心 | Dense Detection | Scene Understanding |
| Backbone | CNN为主 | Transformer为主 |
| 时序Memory | 很少 | 很强 |
| Tracking | 弱 | 强 |
| Segmentation | 可选 | 核心 |
| 视频理解 | 一般 | 强 |
| NPU友好 | 极强 | 一般 |
| Attention占比 | 少 | 很高 |
| 全局语义 | 中 | 很强 |
多尺度目标检测
Input Image
│
▼
CNN Backbone
│
├────────► P3 (80×80)
│ │
│ └──► 小目标检测
│
├────────► P4 (40×40)
│ │
│ └──► 中目标检测
│
└────────► P5 (20×20)
│
└──► 大目标检测
▼
Merge All Predictions
▼
NMS / End-to-End
▼
Final Detection Result
目标检测数据集
标准训练过程
训练 Train
↓
训练完整个训练集(1个epoch)
↓
验证 Validation
↓
记录指标
↓
继续下一轮epoch
epoch含义解释
Epoch 1
│
├── Batch1 Train
├── Batch2 Train
├── Batch3 Train
└── ...
整个Train结束
↓
Validation
↓
计算mAP
↓
保存best.pt
进入Epoch2
源码
import os
import pandas as pd
import torch
import torchvision
from d2l import torch as d2l
#@save
d2l.DATA_HUB['banana-detection'] = (
d2l.DATA_URL + 'banana-detection.zip',
'5de26c8fce5ccdea9f91267273464dc968d20d72')
# 目标检测数据集说明:
# 该数据集用于香蕉目标检测,结构如下:
# - bananas_train/ 训练集目录
# - images/ 训练图片
# - label.csv 每张图片的标注信息
# - bananas_val/ 验证集目录
# - images/ 验证图片
# - label.csv 每张图片的标注信息
#
# label.csv 文件内容:
# img_name,class,xmin,ymin,xmax,ymax
# 其中:
# img_name:图片文件名
# class:类别编号(本例中均为0,表示香蕉)
# xmin, ymin:目标左上角坐标
# xmax, ymax:目标右下角坐标
#
# 每张图片可能有一个或多个目标(本例均为1个香蕉)。
#@save
def read_data_bananas(is_train=True):
"""
读取香蕉检测数据集中的图像和标签
返回:
images: 图像数据列表,每个元素为Tensor,形状[C,H,W]
targets: 目标信息Tensor,形状[N,1,5],每行为[class,xmin,ymin,xmax,ymax],坐标已归一化到[0,1]
"""
data_dir = d2l.download_extract('banana-detection')
# 选择训练或验证集的标注文件
csv_fname = os.path.join(data_dir, 'bananas_train' if is_train else 'bananas_val', 'label.csv')
csv_data = pd.read_csv(csv_fname)
csv_data = csv_data.set_index('img_name')
images, targets = [], []
for img_name, target in csv_data.iterrows():
# 读取图片
images.append(torchvision.io.read_image(
os.path.join(data_dir, 'bananas_train' if is_train else 'bananas_val', 'images', f'{img_name}')))
# 读取目标信息:[类别, xmin, ymin, xmax, ymax]
# 本例类别恒为0,坐标为像素值,需归一化到[0,1](除以256)
targets.append(list(target))
# 返回图像列表和归一化后的目标信息
return images, torch.tensor(targets).unsqueeze(1) / 256
#@save
class BananasDataset(torch.utils.data.Dataset):
"""
一个用于加载香蕉检测数据集的自定义数据集
每个样本返回:(图像Tensor, 目标信息Tensor)
目标信息格式:[类别, xmin, ymin, xmax, ymax],坐标已归一化
"""
def __init__(self, is_train):
# 读取所有图片和标签
self.features, self.labels = read_data_bananas(is_train)
print('read ' + str(len(self.features)) + (f' training examples' if is_train else f' validation examples'))
def __getitem__(self, idx):
# 返回第idx个样本:(图像, 目标信息)
return (self.features[idx].float(), self.labels[idx])
def __len__(self):
# 返回数据集样本数
return len(self.features)
#@save
def load_data_bananas(batch_size):
"""加载香蕉检测数据集"""
train_iter = torch.utils.data.DataLoader(BananasDataset(is_train=True),
batch_size, shuffle=True)
val_iter = torch.utils.data.DataLoader(BananasDataset(is_train=False),
batch_size)
return train_iter, val_iter
batch_size, edge_size = 32, 256
train_iter, _ = load_data_bananas(batch_size)
batch = next(iter(train_iter))
batch[0].shape, batch[1].shape
imgs = (batch[0][0:10].permute(0, 2, 3, 1)) / 255
axes = d2l.show_images(imgs, 2, 5, scale=2)
for ax, label in zip(axes, batch[1][0:10]):
d2l.show_bboxes(ax, [label[0][1:5] * edge_size], colors=['w'])
d2l.plt.show()
代码流程图
banana-detection.zip
│
▼
读取 label.csv
│
▼
读取 image
│
▼
读取 bbox
│
▼
归一化坐标
│
▼
构造 Dataset
│
▼
DataLoader 组成 Batch
│
▼
送入神经网络
label.csv 是什么?
img_name,label,xmin,ymin,xmax,ymax
0.png,0,104,20,143,58
1.png,0,68,175,118,223
2.png,0,163,173,218,239
3.png,0,48,157,84,201
4.png,0,32,34,90,86
5.png,0,69,201,120,245
6.png,0,167,99,212,135
7.png,0,157,67,197,108
8.png,0,131,157,189,219
9.png,0,163,93,217,158
10.png,0,94,15,153,71
| 字段 | 含义 |
|---|---|
| img_name | 图片名 |
| class | 类别 |
| xmin,ymin | 左上角 |
| xmax,ymax | 右下角 |