循环神经网路
循环神经网络(Recurrent Neural Network,简称 RNN)是一种专门用来处理序列数据的人工智能模型。
| 阶段 | 时间 | 代表人物/模型 | 核心思想 | 解决的问题 | 存在问题 | 工程地位 |
|---|---|---|---|---|---|---|
| 🧪 萌芽期 | 1980s–1990s | John Hopfield | 引入“网络记忆” | 神经网络开始有状态 | 无法训练 | 基础理论 |
| 🔁 BPTT | 1990s | Paul Werbos | 时间反向传播 | RNN可以训练 | 梯度消失/爆炸 | 可用但受限 |
| 🧠 LSTM | 1997 | Sepp Hochreiter / Jürgen Schmidhuber | 门控机制 | 长期依赖问题 | 结构复杂 | ⭐ 主流(曾经) |
| ⚡ GRU | 2014 | Kyunghyun Cho | 简化门控 | 降低计算量 | 表达能力略弱 | ⭐ 工程常用 |
| 🏆 黄金时代 | 2010–2017 | LSTM / GRU | 序列建模 | NLP/语音爆发 | 训练慢 | ⭐⭐⭐ 主流 |
| 💥 Transformer | 2017 | Attention Is All You Need | Attention机制 | 并行 + 长依赖 | 计算量大 | 🚀 主导 |
| 🤖 现代阶段 | 2018–现在 | Transformer / Mamba | 非递归建模 | 大规模训练 | 资源要求高 | 🚀 主流 |
序列模型
因果关系(最本质)
↑
├── 马尔可夫模型(强简化)
↑
└── 自回归模型(统计拟合)
自回归模型
自回归模型(Autoregressive Model,简称 AR 模型)是一种非常直观的统计和机器学习模型。简单来说,它的核心思想是:用“过去”的自己,来预测“未来”的自己
马尔可夫模型
马尔可夫模型(Markov Model)是一种描述状态转换的数学模型。它的核心思想极其简单:未来仅取决于现在,而与过去无关
模型训练
训练代码
# -*- coding: utf-8 -*-
import torch
from torch import nn
from d2l import torch as d2l
import os
T = 1000
# 生成时间索引(1 ~ T)
time = torch.arange(1, T+1, dtype=torch.float32)
# 生成带噪声的正弦时间序列:
# x(t) = sin(0.01t) + 高斯噪声
# 其中 torch.normal(0, 0.2, (T,)) 表示均值为 0、标准差为 0.2 的噪声
x = torch.sin(0.01 * time) + torch.normal(0, 0.2, (T,))
# 绘制时间序列 x
d2l.plot(time, x, 'time', 'x', xlim=[1, T], figsize=(6, 3))
# 保存图像到本地,便于在非交互式环境(如脚本运行)中查看结果
fig_path = '/home/lxg/code/AI/code/20260414/time_series.png'
d2l.plt.savefig(fig_path, dpi=150)
print(f'时间序列图已保存到: {fig_path}')
d2l.plt.show()
# tau 表示“滞后步数”(look-back window)
# 用前 tau 个时刻的值来预测下一时刻的值
tau = 4
# 构造监督学习输入特征矩阵:
# 形状为 (样本数, tau) = (T-tau, tau)
# 每一行是长度为 tau 的时间窗口
features = torch.zeros((T-tau, tau))
for i in range(tau):
# 第 i 列对应窗口中第 i 个时间步的值
# 例如 tau=4 时,一行特征是 [x_t, x_{t+1}, x_{t+2}, x_{t+3}]
features[:, i] = x[i:T-tau+i]
# 标签是每个窗口后面的下一个点:
# y = x_{t+tau},并 reshape 为二维列向量,便于后续训练
labels = x[tau:].reshape(-1, 1)
# batch_size:每个小批量样本数
# n_train:用于训练的样本数量(从前面的时间片段中截取)
batch_size, n_train = 16, 600
# d2l.load_array 将张量封装成 DataLoader:
# - 只取前 n_train 条作为训练集
# - is_train=True 表示按小批量打乱后迭代
train_iter = d2l.load_array((features[:n_train], labels[:n_train]),
batch_size, is_train=True)
# 初始化网络权重的函数
def init_weights(m):
# 仅对线性层进行 Xavier 均匀初始化,有助于保持前向/反向传播数值稳定
if type(m) == nn.Linear:
nn.init.xavier_uniform_(m.weight)
# 一个简单的多层感知机
def get_net():
# 输入维度为 4(即 tau=4 的时间窗口特征)
# 隐藏层 10 个神经元,输出 1 个值(预测下一时刻)
net = nn.Sequential(nn.Linear(4, 10),
nn.ReLU(),
nn.Linear(10, 1))
# 应用自定义初始化
net.apply(init_weights)
return net
# 平方损失。注意:MSELoss计算平方误差时不带系数1/2
# reduction='none' 表示先保留每个样本的损失值,后续可手动做 sum/mean
loss = nn.MSELoss(reduction='none')
# 训练函数
# net:待训练模型
# train_iter:训练数据迭代器
# loss:损失函数
# epochs:训练轮数
# lr:学习率
def train(net, train_iter, loss, epochs, lr):
# 使用 Adam 优化器,lr 控制参数更新步长
trainer = torch.optim.Adam(net.parameters(), lr)
for epoch in range(epochs):
# 遍历一个 epoch 内的所有小批量
for X, y in train_iter:
# 清空上一轮迭代累积的梯度
trainer.zero_grad()
# 前向传播并计算逐样本损失
l = loss(net(X), y)
# 反向传播:这里用 sum 聚合一个批量内的损失
l.sum().backward()
# 根据梯度更新参数
trainer.step()
# 每个 epoch 结束后,输出当前训练集平均损失
print(f'epoch {epoch + 1}, '
f'loss: {d2l.evaluate_loss(net, train_iter, loss):f}')
# 实例化网络并启动训练(训练 5 轮,学习率 0.01)
net = get_net()
train(net, train_iter, loss, 5, 0.01)
| 模块 | 作用 | 本质 |
|---|---|---|
| 数据生成 | 正弦 + 噪声 | 时间序列 |
| 特征构造 | 滑动窗口 | 自回归(AR) |
| 模型 | MLP | 非线性拟合 |
| 训练 | MSE + Adam | 回归问题 |
训练数据
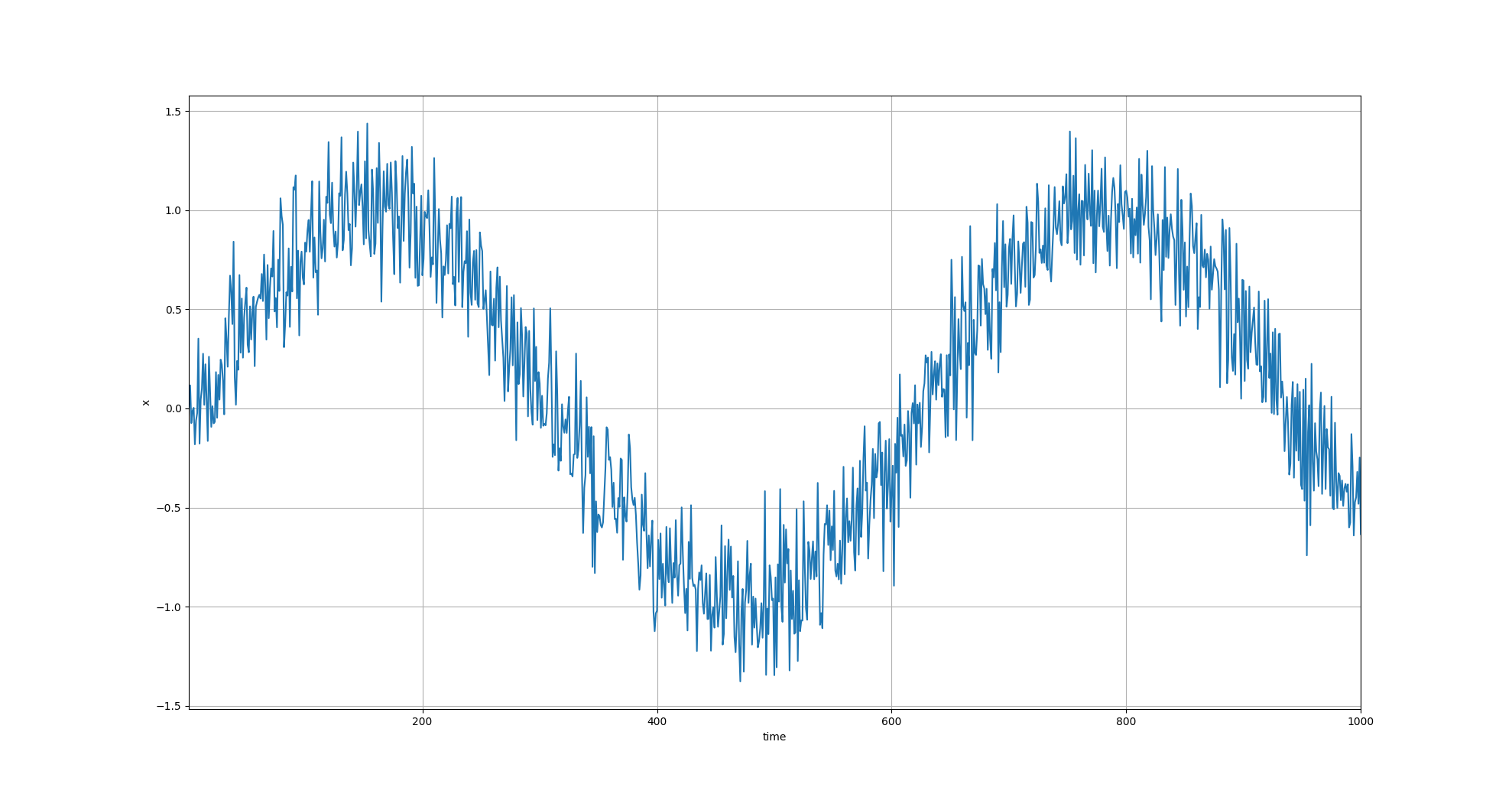
原始训练数据
一条时间序列(长度 = 1000)
时间 t: 1 2 3 4 5 6 7 ...
x(t): 0.1 0.2 0.15 0.3 0.28 0.35 0.4 ...
转换成训练数据
神经网络不能直接用“序列”,必须变成:(输入, 标签)
滑动窗口
用过去 4 个点预测未来 1 个点
最终训练数据
输入
X:
[
[x1, x2, x3, x4],
[x2, x3, x4, x5],
[x3, x4, x5, x6],
...
]
标签
Y:
[
x5,
x6,
x7,
...
]
原始数据只有一条“时间曲线”,但你把它切成了很多“监督学习样本”
神经网络从来不理解“时间”,是你用数据构造让它“看起来像理解时间”
神经网络
公式
\[\hat{y} = \mathbf{W}_2 \cdot \text{ReLU}(\mathbf{W}_1 \cdot \mathbf{x} + \mathbf{b}_1) + b_2\]输入向量 $\mathbf{x}$
\[\mathbf{x} = \begin{bmatrix} x_{t-4} \\ x_{t-3} \\ x_{t-2} \\ x_{t-1} \end{bmatrix}\]
时间序列 x(t)
│
▼
┌────────────────────┐
│ 滑动窗口 (tau=4) │
└─────────┬──────────┘
│
▼
┌────────────────────┐
│ 特征向量 (4维) │
│ [x(t-3),...,x(t)] │
└─────────┬──────────┘
│
▼
┌────────────────────┐
│ MLP网络 │
│ 4 → 10 → ReLU → 1 │
└─────────┬──────────┘
│
▼
┌────────────────────┐
│ 预测 x(t+1) │
└────────────────────┘
另一种表达方式
输入层(4维) 隐藏层(10维) 输出层(1维)
x ∈ R⁴ h ∈ R¹⁰ y ∈ R¹
[x(t-3) x(t-2) x(t-1) x(t)]
│
│ W1(10×4), b1(10)
▼
┌───────────────────────────┐
│ Linear (4 → 10) │
│ h1 = W1·x + b1 │
└────────────┬──────────────┘
│
▼
┌─────────────┐
│ ReLU │
│ h = max(0,h1)│
└─────┬───────┘
│
│ W2(1×10), b2(1)
▼
┌───────────────────────────┐
│ Linear (10 → 1) │
│ y = W2·h + b2 │
└────────────┬──────────────┘
│
▼
输出:x(t+1) 预测值
运行结果
时间序列前10个样本 x[:10]:
tensor([ 0.0191, -0.0410, 0.2230, -0.0893, 0.2611, 0.0617, 0.0285, 0.0990,
0.1299, 0.1268])
前3条特征样本 features[:3]:
tensor([[ 0.0191, -0.0410, 0.2230, -0.0893],
[-0.0410, 0.2230, -0.0893, 0.2611],
[ 0.2230, -0.0893, 0.2611, 0.0617]])
前3条标签样本 labels[:3]:
tensor([[0.2611],
[0.0617],
[0.0285]])
epoch 1, loss: 0.063770
epoch 2, loss: 0.055237
epoch 3, loss: 0.053854
epoch 4, loss: 0.050292
epoch 5, loss: 0.049958
训练结束后的网络参数:
0.weight: shape=(10, 4)
tensor([[ 0.2064, -0.1180, -0.3870, -0.6084],
[-0.4354, -0.1771, 0.2434, 0.4540],
[ 0.0958, -0.7451, -0.4837, 0.5666],
[-0.1508, 0.1834, -0.3236, -0.1264],
[-0.5104, -0.0195, -0.0404, -0.5549],
[ 0.4225, 0.4396, -0.1184, -0.4481],
[-0.4899, 0.3496, 0.2188, -0.3381],
[ 0.2001, 0.3041, -0.4797, -0.4473],
[ 0.5696, -0.0919, -0.3950, -0.3123],
[ 0.4894, 0.6765, 0.5430, -0.1530]])
0.bias: shape=(10,)
tensor([-0.0626, -0.3571, -0.2440, 0.0755, 0.4215, -0.1087, -0.0127, 0.2421,
-0.1977, 0.2435])
2.weight: shape=(1, 10)
tensor([[-0.5276, 0.4976, -0.3318, -0.0713, -0.2041, -0.5537, -0.1441, -0.0123,
0.5392, 0.5843]])
2.bias: shape=(1,)
tensor([-0.0476])
模型预测
单步预测
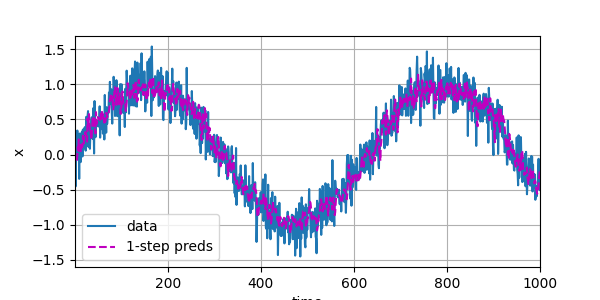
# 一步预测(1-step prediction):
# 这里对每个时间点都使用“真实历史观测值”构造输入窗口,
# 因此误差不会在时间上累积,通常曲线会与原始数据更接近。
onestep_preds = net(features)
d2l.plot([time, time[tau:]],
[x.detach().numpy(), onestep_preds.detach().numpy()], 'time',
'x', legend=['data', '1-step preds'], xlim=[1, 1000],
figsize=(6, 3))
核心问题:误差传播
第1步误差:ε1
第2步误差:ε2 + ε1
第3步误差:ε3 + ε2 + ε1
多步递归预测
# 多步递归预测(multi-step recursive prediction):
# 思路:先使用一段真实历史作为起点,随后每一步都把“模型上一步预测值”
# 再喂回输入窗口继续预测,因此随着步数增加,误差会逐步累积。
multistep_preds = torch.zeros(T)
# 前 n_train+tau 个点直接使用真实值,作为递归预测的初始上下文
multistep_preds[: n_train + tau] = x[: n_train + tau]
for i in range(n_train + tau, T):
# 取最近 tau 个值(其中后期可能已包含模型预测值)来预测下一个点
multistep_preds[i] = net(
multistep_preds[i - tau:i].reshape((1, -1)))
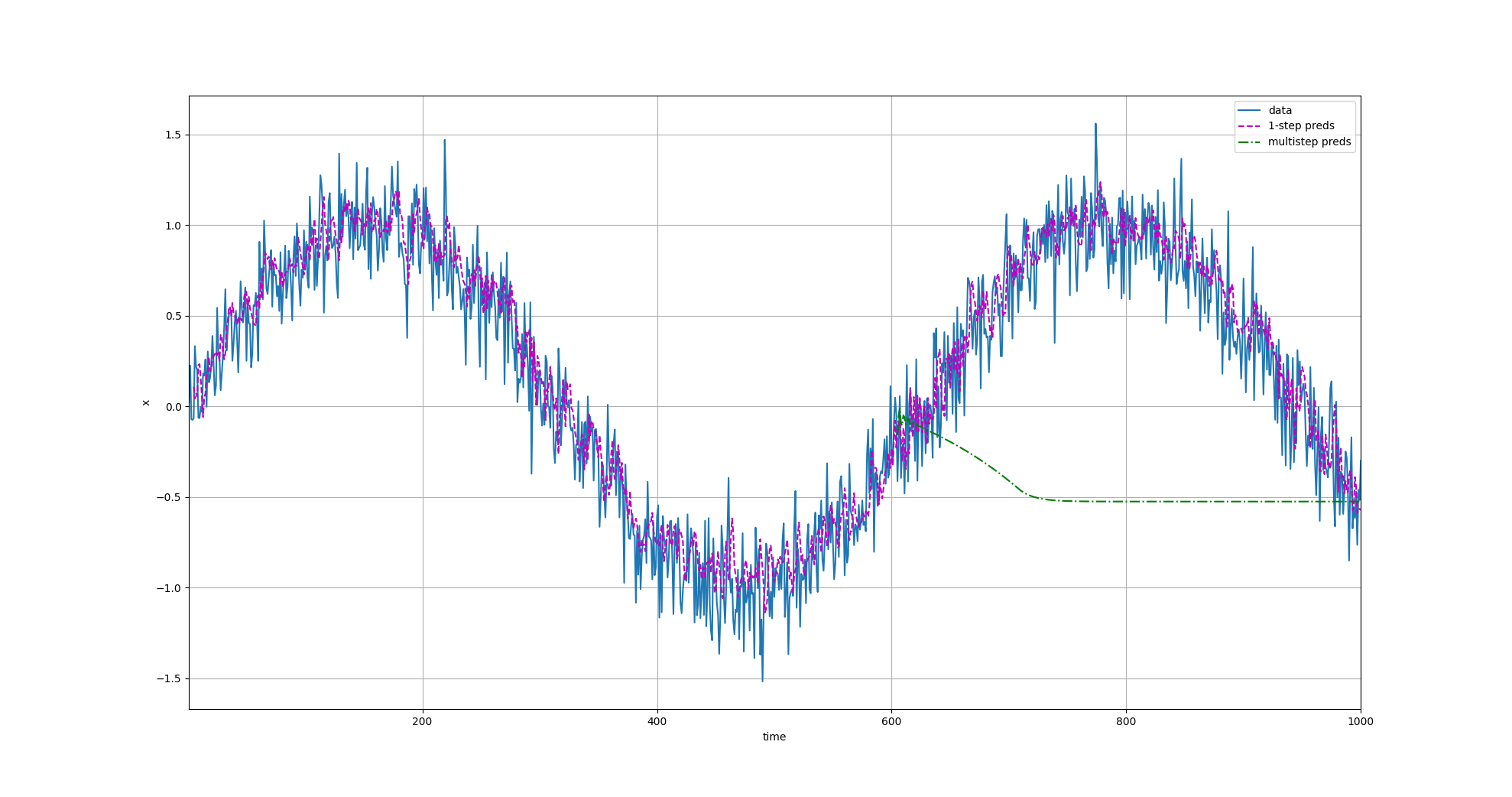
多步预测
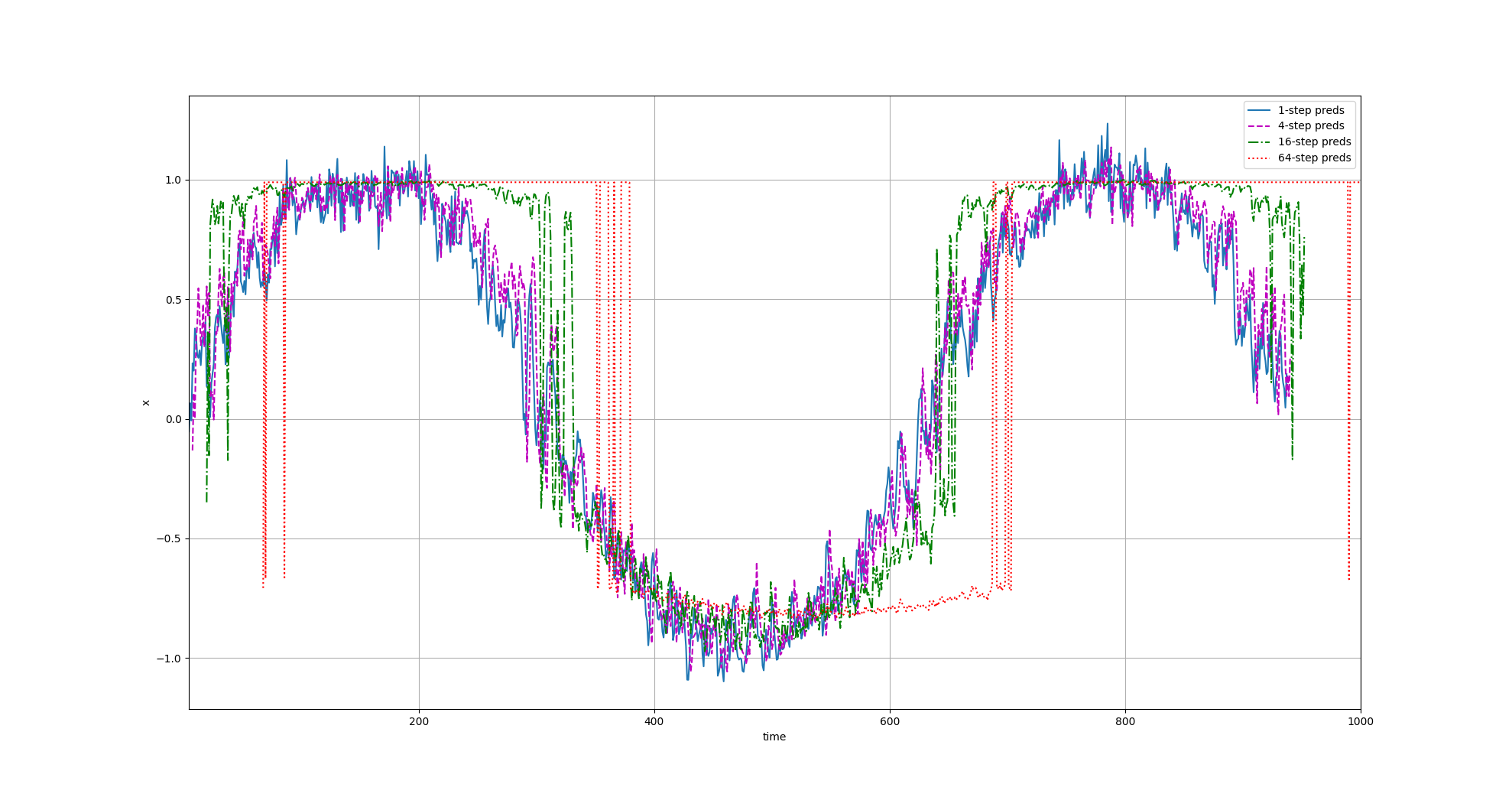
# 最大预测步长:用于观察“预测步数越长,误差越大”的现象
max_steps = 64
# 这里重新构造一个更宽的特征矩阵:
# - 行数:可用于滚动预测的起点数
# - 列数:tau 个已知观测 + max_steps 个不同步长的预测值
features = torch.zeros((T - tau - max_steps + 1, tau + max_steps))
# 列i(i<tau)是来自x的观测,其时间步从(i)到(i+T-tau-max_steps+1)
for i in range(tau):
features[:, i] = x[i: i + T - tau - max_steps + 1]
# 列i(i>=tau)是来自(i-tau+1)步的预测,其时间步从(i)到(i+T-tau-max_steps+1)
for i in range(tau, tau + max_steps):
# 每次使用前 tau 列(可能部分为预测值)作为输入,逐列向右递推
features[:, i] = net(features[:, i - tau:i]).reshape(-1)
# 选取不同预测步长进行可视化比较:
# 1-step、4-step、16-step、64-step 越往后通常偏差越明显
steps = (1, 4, 16, 64)
d2l.plot([time[tau + i - 1: T - max_steps + i] for i in steps],
[features[:, (tau + i - 1)].detach().numpy() for i in steps], 'time', 'x',
legend=[f'{i}-step preds' for i in steps], xlim=[5, 1000],
figsize=(6, 3))
比如tau = 4, max_steps = 4 的数据流, 图中紫色线
已知真实值 预测值(递推生成)
列: 0 1 2 3 | 4 5 6 7
------------------------------------------------
行1: x1 x2 x3 x4 | x̂5 x̂6 x̂7 x̂8
行2: x2 x3 x4 x5 | x̂6 x̂7 x̂8 x̂9
行3: x3 x4 x5 x6 | x̂7 x̂8 x̂9 x̂10
...
这个数据流的本质是:在一个矩阵里“横向滚动窗口 + 递归预测”,一次性模拟所有时间点的多步预测过程。
对比不同步长的预测
| 类型 | 含义 | 说明什么 |
|---|---|---|
| 1-step | 只预测一步 | 几乎完美 |
| 4-step | 连续预测4步 | 开始偏 |
| 16-step | 更远未来 | 明显漂移 |
| 64-step | 长期预测 | 完全失真 |
文本预处理
原始文本
↓
清洗(去符号 + 小写)
↓
分词(word / char)
↓
统计词频
↓
构建词表(Vocab)
↓
文本 → 数字索引
读取数据集
import collections
import re
from d2l import torch as d2l
# 在 d2l 的数据集注册表中登记《时间机器》数据集:
# - 第一个元素是下载地址
# - 第二个元素是文件校验哈希(用于完整性校验)
d2l.DATA_HUB['time_machine'] = (d2l.DATA_URL + 'timemachine.txt',
'090b5e7e70c295757f55df93cb0a180b9691891a')
def read_time_machine():
"""读取时间机器数据集"""
# d2l.download 会在本地缓存数据文件,若不存在则自动下载
with open(d2l.download('time_machine'), 'r') as f:
# 逐行读取原始文本(每个元素是一行字符串)
lines = f.readlines()
# 文本预处理:
# 1) 用正则把非字母字符替换为空格
# 2) 去掉首尾空白
# 3) 全部转小写,降低词表稀疏性
return [re.sub('[^A-Za-z]+', ' ', line).strip().lower() for line in lines]
# 读取并预处理后的文本行列表
lines = read_time_machine()
# 打印数据集总行数与示例行,便于快速确认读取结果
print(f'# 文本总行数: {len(lines)}')
print(lines[0])
print(lines[10])
运行结果
# 文本总行数: 3221
# 文本前10行示例:
the time machine by h g wells
i
the time traveller for so it will be convenient to speak of him
was expounding a recondite matter to us his grey eyes shone and
| 操作 | 目的 |
|---|---|
| 去掉标点 | 减少噪声 |
| 统一小写 | 减少词表大小 |
| strip() | 去空格 |
词元化
def tokenize(lines, token='word'): #@save
"""将文本行拆分为单词或字符词元"""
# 按“单词”级别切分:
# 例如 "time traveller" -> ["time", "traveller"]
if token == 'word':
return [line.split() for line in lines]
# 按“字符”级别切分:
# 例如 "time" -> ["t", "i", "m", "e"]
elif token == 'char':
return [list(line) for line in lines]
else:
# 若传入未知 token 类型,给出提示信息
print('错误:未知词元类型:' + token)
# 默认使用单词粒度进行分词(可改为 token='char' 观察字符级分词效果)
tokens = tokenize(lines)
# 打印前 11 行分词结果,便于检查分词是否符合预期
for i in range(11):
# 每一行输出的是一个词元列表(token list)
print(tokens[i])
运行结果
['the', 'time', 'machine', 'by', 'h', 'g', 'wells']
[]
[]
[]
[]
['i']
[]
[]
['the', 'time', 'traveller', 'for', 'so', 'it', 'will', 'be', 'convenient', 'to', 'speak', 'of', 'him']
['was', 'expounding', 'a', 'recondite', 'matter', 'to', 'us', 'his', 'grey', 'eyes', 'shone', 'and']
['twinkled', 'and', 'his', 'usually', 'pale', 'face', 'was', 'flushed', 'and', 'animated', 'the']
词表
词元的类型是字符串,而模型需要的输入是数字,因此这种类型不方便模型使用。 现在,让我们构建一个字典,通常也叫做词表(vocabulary), 用来将字符串类型的词元映射到从0开始的数字索引中
class Vocab: #@save
"""文本词表"""
# tokens:分词后的语料(1D 或 2D 列表)
# min_freq:最小词频阈值,低于该频次的词元会被过滤
# reserved_tokens:保留词元列表(如 <pad>、<bos>、<eos> 等)
def __init__(self, tokens=None, min_freq=0, reserved_tokens=None):
if tokens is None:
tokens = []
if reserved_tokens is None:
reserved_tokens = []
# 按出现频率排序
counter = count_corpus(tokens)
self._token_freqs = sorted(counter.items(), key=lambda x: x[1],
reverse=True)
# 词表结构采用“双向映射”:
# 1) idx_to_token:索引 -> 词元(列表)
# 2) token_to_idx:词元 -> 索引(字典)
# 其中未知词元 <unk> 固定放在索引 0
self.idx_to_token = ['<unk>'] + reserved_tokens
self.token_to_idx = {token: idx
for idx, token in enumerate(self.idx_to_token)}
# 按词频从高到低把词元加入词表
for token, freq in self._token_freqs:
# 遇到低于最小词频阈值的词元后可提前终止(后续词频只会更低)
if freq < min_freq:
break
if token not in self.token_to_idx:
self.idx_to_token.append(token)
self.token_to_idx[token] = len(self.idx_to_token) - 1
def __len__(self):
# 返回词表大小(总词元数)
return len(self.idx_to_token)
def __getitem__(self, tokens):
# 支持“词元 -> 索引”的两种输入:
# 1) 单个词元(字符串) -> 单个索引(int)
# 2) 词元列表(list/tuple) -> 索引列表
if not isinstance(tokens, (list, tuple)):
# 若词元不存在于词表,返回 unk 索引(0)
return self.token_to_idx.get(tokens, self.unk)
return [self.__getitem__(token) for token in tokens]
def to_tokens(self, indices):
# 支持“索引 -> 词元”的两种输入:
# 1) 单个索引(int) -> 单个词元(str)
# 2) 索引列表(list/tuple) -> 词元列表
if not isinstance(indices, (list, tuple)):
return self.idx_to_token[indices]
return [self.idx_to_token[index] for index in indices]
@property
def unk(self): # 未知词元的索引为0
return 0
@property
def token_freqs(self):
return self._token_freqs
def count_corpus(tokens): #@save
"""统计词元的频率"""
# 这里的tokens是1D列表或2D列表
if len(tokens) == 0 or isinstance(tokens[0], list):
# 将词元列表展平成一个列表
tokens = [token for line in tokens for token in line]
# Counter 会返回类似 {'time': 42, 'the': 2261, ...} 的词频统计结果
return collections.Counter(tokens)
# 基于分词结果构建词表(默认不过滤低频词)
vocab = Vocab(tokens)
# 打印词元到索引映射的前 10 项,便于观察词表内容
print(list(vocab.token_to_idx.items())[:10])
# 展示“文本词元列表 -> 索引列表”的映射示例
for i in [0, 10]:
print('文本:', tokens[i])
print('索引:', vocab[tokens[i]])
运行结果
# 出现频率前10的词元
[('<unk>', 0), ('the', 1), ('i', 2), ('and', 3), ('of', 4), ('a', 5), ('to', 6), ('was', 7), ('in', 8), ('that', 9)]
文本: ['the', 'time', 'machine', 'by', 'h', 'g', 'wells']
索引: [1, 19, 50, 40, 2183, 2184, 400]
文本: ['twinkled', 'and', 'his', 'usually', 'pale', 'face', 'was', 'flushed', 'and', 'animated', 'the']
索引: [2186, 3, 25, 1044, 362, 113, 7, 1421, 3, 1045, 1]
使用字符实现词元化
def load_corpus_time_machine(max_tokens=-1): #@save
"""返回时光机器数据集的词元索引列表和词表"""
lines = read_time_machine()
tokens = tokenize(lines, 'char')
vocab = Vocab(tokens)
# 因为时光机器数据集中的每个文本行不一定是一个句子或一个段落,
# 所以将所有文本行展平到一个列表中
corpus = [vocab[token] for line in tokens for token in line]
if max_tokens > 0:
corpus = corpus[:max_tokens]
return corpus, vocab
corpus, vocab = load_corpus_time_machine()
print(f'# 时光机器数据集总词元数: {len(corpus)}')
print(f'# 时光机器数据集总词表大小: {len(vocab)}')
print(f'# 时光机器数据集前10个词元索引示例:')
for i in range(30):
print(corpus[i])
print(f'# 时光机器数据集前10个词元示例:')
for i in range(30):
print(vocab.to_tokens(corpus[i]))
运行结果
# 时光机器数据集总词元数: 170580
# 时光机器数据集总词表大小: 28
# 时光机器数据集前30个词元索引示例:
3
9
2
1
3
5
13
2
1
13
4
15
9
5
6
2
1
21
19
1
9
1
18
1
17
2
12
12
8
5
# 时光机器数据集前30个词元示例:
t
h
e
t
i
m
e
m
a
c
h
i
n
e
b
y
h
g
w
e
l
l
s
i
为什么28个
a-z(26个) + 空格(1个) +
语言模型和数据集
自然语言统计
import random
import torch
import re
from d2l import torch as d2l
# 在 d2l 的数据集注册表中登记《时间机器》数据集:
# - 第一个元素是下载地址
# - 第二个元素是文件校验哈希(用于完整性校验)
d2l.DATA_HUB['time_machine'] = (d2l.DATA_URL + 'timemachine.txt',
'090b5e7e70c295757f55df93cb0a180b9691891a')
def read_time_machine():
"""读取时间机器数据集"""
# d2l.download 会在本地缓存数据文件,若不存在则自动下载
with open(d2l.download('time_machine'), 'r') as f:
# 逐行读取原始文本(每个元素是一行字符串)
lines = f.readlines()
# 文本预处理:
# 1) 用正则把非字母字符替换为空格
# 2) 去掉首尾空白
# 3) 全部转小写,降低词表稀疏性
return [re.sub('[^A-Za-z]+', ' ', line).strip().lower() for line in lines]
tokens = d2l.tokenize(read_time_machine())
# 因为每个文本行不一定是一个句子或一个段落,因此我们把所有文本行拼接到一起
corpus = [token for line in tokens for token in line]
vocab = d2l.Vocab(corpus)
print(vocab.token_freqs[:10])
freqs = [freq for token, freq in vocab.token_freqs]
d2l.plot(freqs, xlabel='token: x', ylabel='frequency: n(x)',
xscale='log', yscale='log')
运行结果
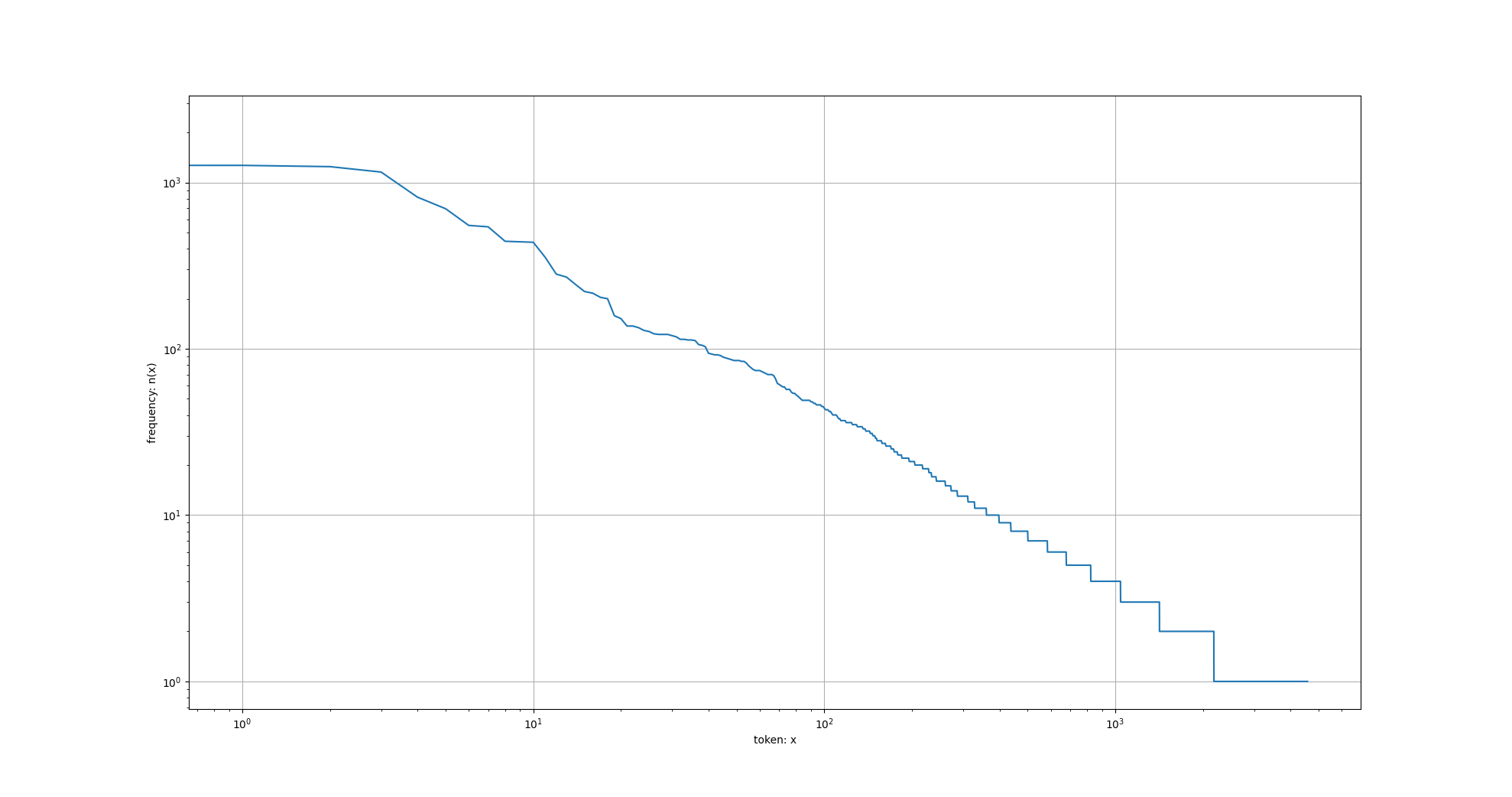
[('the', 2261), ('i', 1267), ('and', 1245), ('of', 1155), ('a', 816), ('to', 695), ('was', 552), ('in', 541), ('that', 443), ('my', 440)]
通过此图我们可以发现:词频以一种明确的方式迅速衰减。 将前几个单词作为例外消除后,剩余的所有单词大致遵循双对数坐标图上的一条直线。 这意味着单词的频率满足齐普夫定律(Zipf’s law)
多元词汇统计
# 将二元词组从元组转为字符串,避免 d2l.Vocab 内部排序时报 tuple/str 类型冲突
bigram_tokens = [' '.join(pair) for pair in zip(corpus[:-1], corpus[1:])]
bigram_vocab = d2l.Vocab(bigram_tokens)
print(bigram_vocab.token_freqs[:10])
# 将三元词组从元组转为字符串,确保词表构建时词元类型一致
trigram_tokens = [' '.join(triple) for triple in zip(
corpus[:-2], corpus[1:-1], corpus[2:])]
trigram_vocab = d2l.Vocab(trigram_tokens)
print(trigram_vocab.token_freqs[:10])
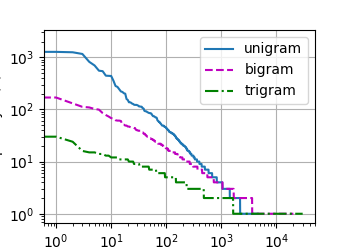
bigram_freqs = [freq for token, freq in bigram_vocab.token_freqs]
trigram_freqs = [freq for token, freq in trigram_vocab.token_freqs]
d2l.plot([freqs, bigram_freqs, trigram_freqs], xlabel='token: x',
ylabel='frequency: n(x)', xscale='log', yscale='log',
legend=['unigram', 'bigram', 'trigram'])
d2l.plt.show()
运行结果
[(('of', 'the'), 309),
(('in', 'the'), 169),
(('i', 'had'), 130),
(('i', 'was'), 112),
(('and', 'the'), 109),
(('the', 'time'), 102),
(('it', 'was'), 99),
(('to', 'the'), 85),
(('as', 'i'), 78),
(('of', 'a'), 73)]
[(('the', 'time', 'traveller'), 59),
(('the', 'time', 'machine'), 30),
(('the', 'medical', 'man'), 24),
(('it', 'seemed', 'to'), 16),
(('it', 'was', 'a'), 15),
(('here', 'and', 'there'), 15),
(('seemed', 'to', 'me'), 14),
(('i', 'did', 'not'), 14),
(('i', 'saw', 'the'), 13),
(('i', 'began', 'to'), 13)]
读取长序列数据
- 👉 把一个超长文本,切成很多“固定长度的小序列”
- 👉 每个序列做“下一个词预测”训练
- 👉 随机偏移可以让模型看到更多可能性
随机采样
def seq_data_iter_random(corpus, batch_size, num_steps): #@save
"""使用随机抽样生成一个小批量子序列"""
# 从随机偏移量开始对序列进行分区,随机范围包括num_steps-1
corpus = corpus[random.randint(0, num_steps - 1):]
# 减去1,是因为我们需要考虑标签
num_subseqs = (len(corpus) - 1) // num_steps
# 长度为num_steps的子序列的起始索引
initial_indices = list(range(0, num_subseqs * num_steps, num_steps))
# 在随机抽样的迭代过程中,
# 来自两个相邻的、随机的、小批量中的子序列不一定在原始序列上相邻
random.shuffle(initial_indices)
def data(pos):
# 返回从pos位置开始的长度为num_steps的序列
return corpus[pos: pos + num_steps]
num_batches = num_subseqs // batch_size
for i in range(0, batch_size * num_batches, batch_size):
# 在这里,initial_indices包含子序列的随机起始索引
initial_indices_per_batch = initial_indices[i: i + batch_size]
X = [data(j) for j in initial_indices_per_batch]
Y = [data(j + 1) for j in initial_indices_per_batch]
yield torch.tensor(X), torch.tensor(Y)
my_seq = list(range(35))
for X, Y in seq_data_iter_random(my_seq, batch_size=2, num_steps=5):
print('X: ', X, '\nY:', Y)
运行结果
X: tensor([[14, 15, 16, 17, 18],
[ 4, 5, 6, 7, 8]])
Y: tensor([[15, 16, 17, 18, 19],
[ 5, 6, 7, 8, 9]])
X: tensor([[ 9, 10, 11, 12, 13],
[19, 20, 21, 22, 23]])
Y: tensor([[10, 11, 12, 13, 14],
[20, 21, 22, 23, 24]])
X: tensor([[24, 25, 26, 27, 28],
[29, 30, 31, 32, 33]])
Y: tensor([[25, 26, 27, 28, 29],
[30, 31, 32, 33, 34]])
顺序分区
def seq_data_iter_sequential(corpus, batch_size, num_steps): #@save
"""使用顺序分区生成一个小批量子序列"""
# 从随机偏移量开始划分序列
offset = random.randint(0, num_steps)
num_tokens = ((len(corpus) - offset - 1) // batch_size) * batch_size
Xs = torch.tensor(corpus[offset: offset + num_tokens])
Ys = torch.tensor(corpus[offset + 1: offset + 1 + num_tokens])
Xs, Ys = Xs.reshape(batch_size, -1), Ys.reshape(batch_size, -1)
num_batches = Xs.shape[1] // num_steps
for i in range(0, num_steps * num_batches, num_steps):
X = Xs[:, i: i + num_steps]
Y = Ys[:, i: i + num_steps]
yield X, Y
for X, Y in seq_data_iter_sequential(my_seq, batch_size=2, num_steps=5):
print('X: ', X, '\nY:', Y)
运行结果
X: tensor([[ 0, 1, 2, 3, 4],
[17, 18, 19, 20, 21]])
Y: tensor([[ 1, 2, 3, 4, 5],
[18, 19, 20, 21, 22]])
X: tensor([[ 5, 6, 7, 8, 9],
[22, 23, 24, 25, 26]])
Y: tensor([[ 6, 7, 8, 9, 10],
[23, 24, 25, 26, 27]])
X: tensor([[10, 11, 12, 13, 14],
[27, 28, 29, 30, 31]])
Y: tensor([[11, 12, 13, 14, 15],
[28, 29, 30, 31, 32]])
| 维度 | 随机采样 | 顺序采样 |
|---|---|---|
| 数据顺序 | 打乱 | 连续 |
| hidden state | ❌ 不能复用 | ✅ 可以复用 |
| 泛化能力 | 强 | 一般 |
| 收敛稳定性 | 稍差 | 更稳定 |
封装
class SeqDataLoader: #@save
"""加载序列数据的迭代器"""
def __init__(self, batch_size, num_steps, use_random_iter, max_tokens):
if use_random_iter:
self.data_iter_fn = d2l.seq_data_iter_random
else:
self.data_iter_fn = d2l.seq_data_iter_sequential
self.corpus, self.vocab = d2l.load_corpus_time_machine(max_tokens)
self.batch_size, self.num_steps = batch_size, num_steps
def __iter__(self):
return self.data_iter_fn(self.corpus, self.batch_size, self.num_steps)
def load_data_time_machine(batch_size, num_steps, #@save
use_random_iter=False, max_tokens=10000):
"""返回时光机器数据集的迭代器和词表"""
data_iter = SeqDataLoader(
batch_size, num_steps, use_random_iter, max_tokens)
return data_iter, data_iter.vocab
循环神经网络
有隐状态的神经网络
什么是隐状态
| 时间 | 输入 | 隐状态 |
|---|---|---|
| t=1 | t | “t” |
| t=2 | i | “ti” |
| t=3 | m | “tim” |
| t=4 | e | “time” |
结构图
时间展开图(最重要🔥)
┌────────┐ ┌────────┐ ┌────────┐ ┌────────┐
x1 ───► │ RNN │ ───► │ RNN │ ───► │ RNN │ ───► │ RNN │
│ │ │ │ │ │ │ │
└───┬────┘ └───┬────┘ └───┬────┘ └───┬────┘
│ │ │ │
h1 h2 h3 h4
│ │ │ │
▼ ▼ ▼ ▼
y1 y2 y3 y4
代码
# -*- coding: utf-8 -*-
import torch
from d2l import torch as d2l
# 本示例用于说明:
# 在循环神经网络(RNN)中,
# X @ W_xh + H @ W_hh 这一计算,
# 可以等价改写为一次拼接后的矩阵乘法。
# X:当前时间步输入,形状 (batch_size, input_size) = (3, 1)
# W_xh:输入到隐藏层的权重,形状 (input_size, hidden_size) = (1, 4)
X, W_xh = torch.normal(0, 1, (3, 1)), torch.normal(0, 1, (1, 4))
# H:上一时间步隐藏状态,形状 (batch_size, hidden_size) = (3, 4)
# W_hh:隐藏状态到隐藏状态的权重,形状 (hidden_size, hidden_size) = (4, 4)
H, W_hh = torch.normal(0, 1, (3, 4)), torch.normal(0, 1, (4, 4))
# 方式一:分别做两次矩阵乘法,再相加
# 结果形状:(3, 4)
Y1 = torch.matmul(X, W_xh) + torch.matmul(H, W_hh)
# 打印方式一结果
print(Y1)
# 方式二:先拼接,再做一次矩阵乘法
# torch.cat((X, H), 1) -> 在特征维拼接,形状由 (3,1)+(3,4) 变为 (3,5)
# torch.cat((W_xh, W_hh),0) -> 在行维拼接,形状由 (1,4)+(4,4) 变为 (5,4)
# 相乘后结果仍为 (3,4),理论上与 Y1 完全相同
Y2 = torch.matmul(torch.cat((X, H), 1), torch.cat((W_xh, W_hh), 0))
# 打印方式二结果(应与 Y1 对应元素一致)
print(Y2)
# 额外验证:数值是否几乎完全一致(浮点误差范围内)
print("Y1 与 Y2 是否近似相等:", torch.allclose(Y1, Y2))
运行结果
tensor([[ 0.9198, 4.4856, -1.1062, -2.5121],
[-0.3787, -1.9000, 0.9881, 1.2528],
[ 2.3979, -1.9294, 1.6074, -0.1341]])
tensor([[ 0.9198, 4.4856, -1.1062, -2.5121],
[-0.3787, -1.9000, 0.9881, 1.2528],
[ 2.3979, -1.9294, 1.6074, -0.1341]])
Y1 与 Y2 是否近似相等: True
“两个矩阵乘法的和,可以合并成一个矩阵乘法”
\[(X_t W_{xh} + H_{t-1} W_{hh}) = [X_t, H_{t-1}] \cdot \begin{bmatrix} W_{xh} \\ W_{hh} \end{bmatrix}\]如何理解记忆
这一章是深度学习中最具挑战性的转折点之一,因为它从“静态”的计算(如你之前学的自回归 MLP)跨越到了“动态”的记忆。
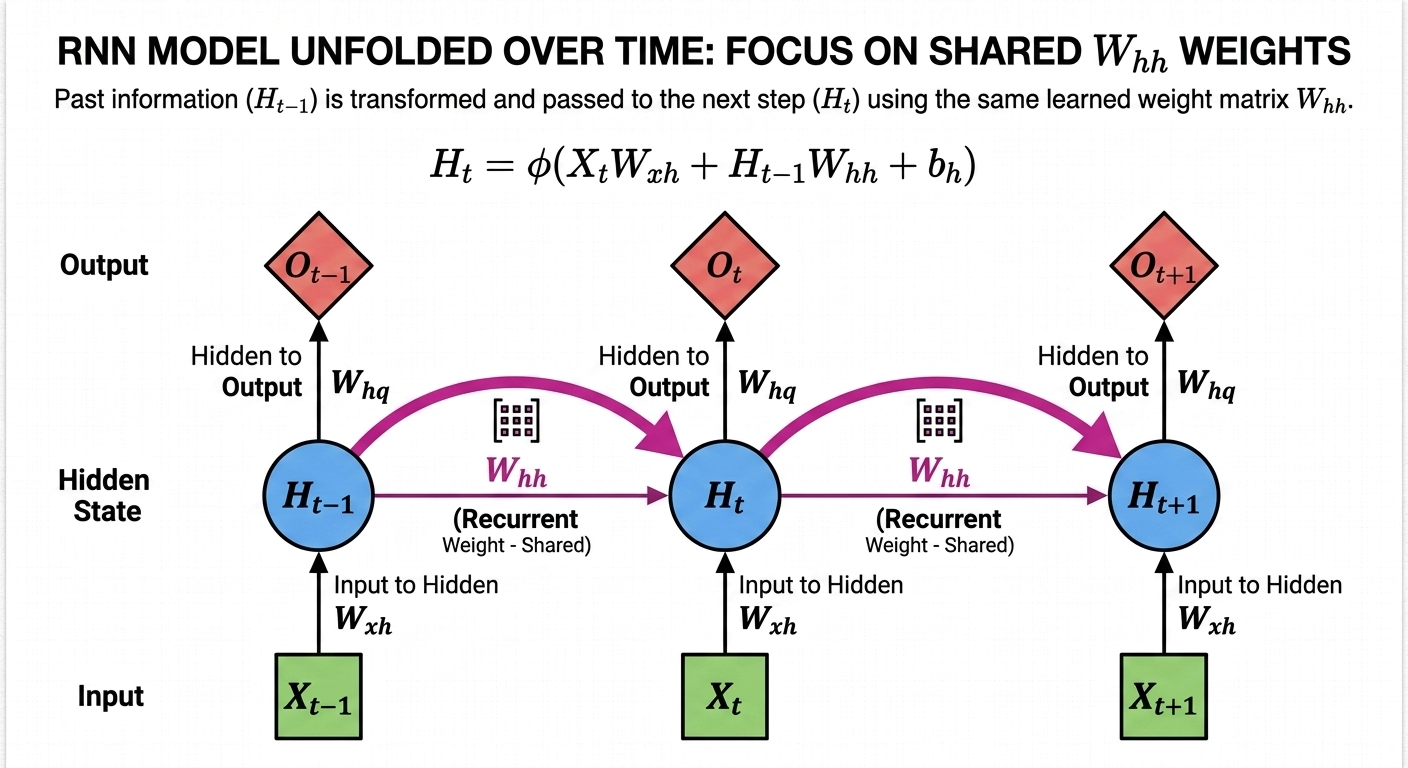
\[H_t = \phi(X_t W_{xh} + H_{t-1} W_{hh} + b_h)\]这里的 $H_t$ 就是时刻 $t$ 的“记忆”。请注意它和普通 MLP 的区别:
- $X_t W_{xh}$:这是当前看到的信息。
- $H_{t-1} W_{hh}$:这是过去留下的记忆。
关键点: 模型不仅仅看现在的输入 $X_t$,还会读取上一时刻存下来的 $H_{t-1}$。这两个信息通过各自的权重($W_{xh}$ 和 $W_{hh}$)相加,再套一个激活函数,就形成了这一刻的新记忆。
$W_{xh}$:输入到隐藏层的权重
- 作用:负责处理当前时刻的输入信号 $X_t$。
- 理解:它决定了当前的输入(比如当前这个词)对当前记忆的影响程度。
- 维度:(输入维度, 隐藏层维度)。
$W_{hh}$:隐藏层到隐藏层的权重(核心所在)
- 作用:负责处理上一时刻留下的记忆 $H_{t-1}$。
- 理解:这是 RNN 拥有“记忆”的关键。它决定了模型应该保留多少过去的经验,以及如何将旧记忆与新信息融合。
- 维度:(隐藏层维度, 隐藏层维度)。这是一个方阵,因为它在记忆空间内进行变换。
$b_h$:隐藏层的偏置项
- 作用:给神经元的激活提供一个基础偏移量。
- 维度:(1, 隐藏层维度)。
如何理解W_{hh}
- $H_{t-1}$ 存储的是过去的所有信息。
- $W_{hh}$ 的作用是:从旧记忆中提取出对当前时刻有意义的部分。
直观比喻
- $H_{t-1}$ 是你脑子里记住的语法和单词。
- 当你听到一个新的动词($X_t$)时,你的脑子不会把所有的英语知识都搬出来。
- $W_{hh}$ 就像是脑子里的一个“检索机制”,它通过加权,帮你找出与这个动词相关的时态规则,从而更新你现在的理解($H_t$)。
生成答案
完整的 RNN 逻辑由两个公式组成:
动作一:更新记忆(你看到的公式)
\[H_t = \phi(X_t W_{xh} + H_{t-1} W_{hh} + b_h)\]动作二:生成输出(答案就在这里)
\[O_t = H_t W_{hq} + b_q\]在一个标准的单层 RNN 中,训练最终是为了得到以下 5 个关键参数:
- 负责“处理当前”的权重:$W_{xh}$
- 负责“连接过去”的权重:$W_{hh}$
- 负责“提取答案”的权重:$W_{hq}$
- $b_h$:隐藏层的偏置,调节记忆生成的灵敏度。
- $b_q$:输出层的偏置,调节最终预测值的基准线。
| 参数 | 职责 | 更准确的类比 |
|---|---|---|
| Wxh | 处理当前输入 | 👀 观察力(怎么看新信息) |
| Whh | 处理过去记忆 | 🧠 理解/联想力(怎么解读已有印象) |
| Whq | 生成输出 | 🗣️ 表达力(怎么说出来) |
| bh, bq | 偏置调整 | 🎯 默认倾向 / 直觉偏好 |
理解状态$H_t$
在深度学习中,我们把 $H_{t-1}$ 和 $H_t$ 称为 “激活值” (Activations)。
| 类别 | 术语 | 形象比喻 | 训练结束后 |
|---|---|---|---|
| 权重(Wxh, Whh, Whq) | 参数(Parameters) | 🧬 大脑的“连接方式 / 思维习惯” | ✅ 保留(存入 .pth) |
| 状态(H_t, H_{t-1}) | 隐状态(Hidden State) | 💭 当前脑海里的“想法 / 上下文” | ⚠️ 通常丢弃,但也可以保留(推理时) |
在 RNN 的实际应用中,你提到的“最终状态”保留,通常分为两种情况:训练过程中的保留和推理(预测)时的保留。
训练过程中:为了“算账”必须保留
在点击“开始训练”后,模型处理完一整条序列,每一个时刻的 $H_t$ 都会被暂时存放在显存里。
- 原因:由于 RNN 的梯度是“顺着时间往回流”的(BPTT 算法),如果我们不保留中间的 $H_t$,模型在算梯度的时候就找不到路,无法更新 $W_{hh}$。
- 代价:这就是为什么 RNN 训练时很吃显存,序列越长,存的中间状态就越多。一旦这一轮训练(Backprop)结束,这些状态就会被清空。
预测(推理)时:为了“接龙”需要保留
当你训练完模型,拿它去写小说或对话时,最后一个时刻的状态 $H_{last}$ 确实需要保留。
- 场景:你问 AI“你是谁?”,AI 算出了一个隐藏状态 $H_{last}$。
- 作用:当你接着问“你多大了?”时,AI 需要把刚才那个 $H_{last}$ 作为初始状态喂给模型。
- 如果不保留:AI 就会瞬间失忆,不记得你刚才问过什么。
最后一次隐藏状态 $H_T$ 确实需要落盘(持久化存储)
| 维度 | 权重 W(Parameters) | 状态 Hlast(Hidden State) |
|---|---|---|
| 存储位置 | 💾 硬盘(.pth / .bin) | ⚡ 内存 / 显存(运行时) |
| 性质 | 🌐 通用规律(学到的模式) | 🧩 当前上下文(具体这段序列) |
| 持久性 | ♾️ 长期保存 | ⏱️ 临时存在(但可手动延续) |
| 作用范围 | 对所有输入通用 | 只对当前序列有效 |
| 是否训练得到 | ✅ 通过训练学习 | ❌ 运行时动态产生 |
| 是否可控保存 | ✅ 必须保存 | ⚠️ 可选择保存(如流式任务) |
总结
👀 输入
↓
Wxh(观察)
↓
当前信息理解
↓
+
↓
🧠 过去记忆
↓
Whh(思考)
↓
更新后的理解(H_t)
↓
Whq(表达)
↓
🗣️ 输出