概念
LingBot-Map 是蚂蚁灵波科技开源的流式三维重建模型,普通 RGB 摄像头可在视频采集过程中实时完成相机位姿估计与场景三维结构重建。模型以纯自回归式建模为核心,基于几何上下文 Transformer 架构,在 Oxford Spires 等权威基准上实现轨迹精度较此前最优流式方法提升约 2.8 倍,填补实时空间感知领域关键技术空白。
- 实时流式重建:边看边理解,逐帧处理当前及历史画面,持续输出相机位姿和深度信息。
- 长序列稳定运行:支持 10,000+ 帧长视频连续推理,长序列运行精度几乎无衰减。
- 纯视觉空间感知:无需复杂硬件,单颗普通摄像头可实现实时三维建图。
- 相机轨迹估计:支持精准估计相机在三维空间中的运动轨迹(位姿估计)。
环境准备
conda create -n lingbot-map python=3.10 -y
pip install torch==2.9.1 torchvision==0.24.1 --index-url https://download.pytorch.org/whl/cu128
git clone https://github.com/robbyant/lingbot-map.git
cd lingbot-map/
pip install -e .
pip install -e ".[vis]"
pip install modelscope
modelscope download --model Robbyant/lingbot-map --local_dir ./models
下载skyseg
curl -sSfL https://hf.co/git-xet/install.sh | sh
git clone https://huggingface.co/JianyuanWang/skyseg
这一个 ONNX 模型:
- 文件:skyseg.onnx
- 来源:HuggingFace
- 功能:识别图像里的“天空区域”
🎯 作用
- 把天空区域从点云里过滤掉
因为:
- 天空没有真实深度
- SLAM / 重建容易产生“漂浮点”
- 会污染点云质量
测试目录
(lingbot-map) xt@xt-2288H-V5:~/lixiaogang/lingbot-map$ tree -L 2
.
├── lingbot-map
│ ├── assets
│ ├── demo.py
│ ├── example
│ ├── gct_profile.py
│ ├── LICENSE.txt
│ ├── lingbot_map
│ ├── lingbot_map.egg-info
│ ├── lingbot-map_paper.pdf
│ ├── pyproject.toml
│ └── README.md
├── models
│ ├── assets
│ ├── configuration.json
│ ├── lingbot-map
│ ├── lingbot-map-long.pt
│ ├── lingbot-map.pt
│ ├── lingbot-map-stage1.pt
│ ├── README.md
│ └── strip_checkpoint.py
└── skyseg
├── README.md
└── skyseg.onnx
模型测试命令
(lingbot-map) xt@xt-2288H-V5:~/lixiaogang/lingbot-map/lingbot-map$ python demo.py --model_path ../models/lingbot-map.pt --image_folder example/university --use_sdpa --mask_sky
========== LingBot-MAP Demo ==========
[配置] 输入模式: 图片集
[配置] 推理模式: streaming
[配置] 模型路径: ../models/lingbot-map.pt
[配置] 图片目录: example/university
[配置] SkySeg模型: /home/xt/lixiaogang/lingbot-map/skyseg/skyseg.onnx
======================================
[阶段] 开始加载数据与模型...
正在加载 324 张图像...
原始图像分辨率(首帧): 518x294
Loading images: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 324/324 [00:01<00:00, 279.68it/s]
图像预处理完成: 尺寸=518x294, 模式=canonical crop
flashinfer not available
torchtitan not available for ulysses cp
正在构建模型...
pretrained_path:
Failed to load pretrained weights: [Errno 2] No such file or directory: ''
正在加载权重文件: ../models/lingbot-map.pt
缺失参数键数量: 62
权重加载完成。
[耗时] 数据与模型加载完成: 17.4s
正在将 aggregator 转为 torch.bfloat16 (heads 保持 fp32)
[输入] 帧数: 324, 张量形状: (324, 3, 294, 518)
[输入] 当前模式: streaming
加载后 GPU 显存: alloc=3.54 GB, reserved=3.57 GB
[阶段] 开始模型推理 (mode=streaming, dtype=torch.bfloat16)...
Streaming inference: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 324/324 [01:48<00:00, 2.92it/s]
[耗时] 模型推理完成: 110.38s
[统计] 平均单帧耗时: 340.67 ms
[统计] 推理吞吐: 2.94 FPS
推理阶段 GPU 峰值显存: 13.03 GB (reserved 峰值 13.97 GB)
[阶段] 开始后处理...
正在将结果移动到 CPU...
[耗时] 后处理完成: 0.02s
2026-04-20 11:34:10.944001979 [W:onnxruntime:Default, device_discovery.cc:164 DiscoverDevicesForPlatform] GPU device discovery failed: device_discovery.cc:89 ReadFileContents Failed to open file: "/sys/class/drm/card0/device/vendor"
╭────── viser (listening *:8080) ───────╮
│ ╷ │
│ HTTP │ http://localhost:8080 │
│ Websocket │ ws://localhost:8080 │
│ ╵ │
╰───────────────────────────────────────╯
Generating sky masks from image array...
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 324/324 [01:10<00:00, 4.60it/s]
Sky segmentation applied successfully
[阶段] 可视化服务已启动: http://localhost:8080
(viser) Connection opened (0, 1 total), 4278 persistent messages
(viser) Connection opened (1, 2 total), 4278 persistent messages
(viser) Connection closed (0, 1 total)

模型输出
- 输入:RGB 图像序列
- 输出:相机轨迹 + 稠密3D点云 + 深度信息
相机位姿(Camera Pose)
predictions["extrinsic"]
predictions["intrinsic"]
| 项目 | 说明 |
|---|---|
| extrinsic | 相机在世界坐标的位置(位姿) |
| intrinsic | 相机内参 |
👉 本质就是:每一帧摄像头在哪、朝哪看
3D点云(核心输出)
predictions["world_points"]
predictions["world_points_conf"]
| 项目 | 说明 |
|---|---|
| world_points | 每个像素对应的3D坐标 |
| world_points_conf | 置信度 |
👉 本质:2D图像 → 3D世界坐标
深度图(Depth)
predictions["depth"]
predictions["depth_conf"]
| 项目 | 说明 |
|---|---|
| depth | 每个像素的深度 |
| depth_conf | 深度置信度 |
👉 类似:单目 → 深度估计
改成Video视频推理
fps 30视频推理
平均单帧耗时: 641.97 ms
(lingbot-map) xt@xt-2288H-V5:~/lixiaogang/lingbot-map/lingbot-map$ CUDA_VISIBLE_DEVICES=1 python demo.py --model_path ../models/lingbot-map.pt --video_path video.mp4 --fps 30 --use_sdpa
========== LingBot-MAP Demo ==========
[配置] 输入模式: 视频
[配置] 推理模式: streaming
[配置] 模型路径: ../models/lingbot-map.pt
[配置] 视频路径: video.mp4 (采样FPS=30)
======================================
[阶段] 开始加载数据与模型...
Extracting frames: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 708/708 [00:03<00:00, 219.41frame/s]
从视频抽取完成: 708 帧 (总帧数=708, 抽帧间隔=1)
正在加载 708 张图像...
原始图像分辨率(首帧): 720x1280
Loading images: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 708/708 [00:02<00:00, 311.66it/s]
图像预处理完成: 尺寸=518x518, 模式=canonical crop
正在构建模型...
正在加载权重文件: ../models/lingbot-map.pt
缺失参数键数量: 62
权重加载完成。
[耗时] 数据与模型加载完成: 22.2s
正在将 aggregator 转为 torch.bfloat16 (heads 保持 fp32)
[输入] 帧数: 708, 张量形状: (708, 3, 518, 518)
[输入] 当前模式: streaming
加载后 GPU 显存: alloc=5.22 GB, reserved=5.27 GB
[阶段] 开始模型推理 (mode=streaming, dtype=torch.bfloat16)...
Streaming inference: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 708/708 [07:30<00:00, 1.56it/s]
[耗时] 模型推理完成: 454.52s
[统计] 平均单帧耗时: 641.97 ms
[统计] 推理吞吐: 1.56 FPS
推理阶段 GPU 峰值显存: 22.11 GB (reserved 峰值 22.63 GB)
[阶段] 开始后处理...
正在将结果移动到 CPU...
[耗时] 后处理完成: 0.06s
fps 10视频推理
(lingbot-map) xt@xt-2288H-V5:~/lixiaogang/lingbot-map/lingbot-map$ CUDA_VISIBLE_DEVICES=1 python demo.py --model_path ../models/lingbot-map.pt --video_path video.mp4 --fps 10 --use_sdpa
========== LingBot-MAP Demo ==========
[配置] 输入模式: 视频
[配置] 推理模式: streaming
[配置] 模型路径: ../models/lingbot-map.pt
[配置] 视频路径: video.mp4 (采样FPS=10)
======================================
[阶段] 开始加载数据与模型...
Extracting frames: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 708/708 [00:01<00:00, 406.82frame/s]
从视频抽取完成: 236 帧 (总帧数=708, 抽帧间隔=3)
正在加载 236 张图像...
原始图像分辨率(首帧): 720x1280
Loading images: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 236/236 [00:00<00:00, 296.29it/s]
图像预处理完成: 尺寸=518x518, 模式=canonical crop
正在构建模型...
正在加载权重文件: ../models/lingbot-map.pt
缺失参数键数量: 62
权重加载完成。
[耗时] 数据与模型加载完成: 18.8s
正在将 aggregator 转为 torch.bfloat16 (heads 保持 fp32)
[输入] 帧数: 236, 张量形状: (236, 3, 518, 518)
[输入] 当前模式: streaming
加载后 GPU 显存: alloc=3.70 GB, reserved=3.74 GB
[阶段] 开始模型推理 (mode=streaming, dtype=torch.bfloat16)...
Streaming inference: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 236/236 [02:14<00:00, 1.70it/s]
[耗时] 模型推理完成: 136.94s
[统计] 平均单帧耗时: 580.25 ms
[统计] 推理吞吐: 1.72 FPS
推理阶段 GPU 峰值显存: 20.02 GB (reserved 峰值 21.58 GB)
[阶段] 开始后处理...
正在将结果移动到 CPU...
[耗时] 后处理完成: 0.02s

对比
| 设置 | 帧数 | 单帧耗时 | FPS | 显存峰值 |
|---|---|---|---|---|
| 30 FPS | 708 | 642 ms | 1.56 | 22.1 GB |
| 10 FPS | 236 | 580 ms | 1.72 | 20.0 GB |
帧数减少 3倍
但单帧耗时几乎没变(642ms → 580ms)
👉 这说明:
性能瓶颈 ≠ 帧数
而是“每一帧的计算本身”
更换GPU能提升吗
| GPU | 架构 | 相对3090 | 预期单帧耗时 |
|---|---|---|---|
| 3090 | Ampere | 1x | ~600 ms |
| A100 | Ampere | 1.3~1.6x | ~400–500 ms |
| H100 | Hopper | 2~3x | ~200–300 ms |
| RTX 4090 | Ada | 1.5~2x | ~300–400 ms |
为什么很难到几十毫秒?
你现在这个模型本质是:
Transformer + 多帧 Attention + 3D 重建
计算复杂度决定了上限:
1️⃣ Attention(核心瓶颈)
每帧都要和历史帧交互(KV cache)
👉 即使优化:
仍然是高复杂度
2️⃣ 图像编码(ViT / CNN)
518×518 输入 → 很重
3️⃣ 3D Head(深度 + 点云)
逐像素计算(非常吃算力)
👉 所以:
这不是“推理优化问题”
而是“模型规模问题”
分辨率降低
| 维度 | 518×518(默认) | 384×384(推荐) | 256×256(极限性能) |
|---|---|---|---|
| 单帧耗时 | ~600 ms | ~350–400 ms | ~180–250 ms |
| 推理FPS | ~1.5 FPS | ~2.5–3 FPS | ~4–5 FPS |
| 显存占用 | ~20–22 GB | ~12–16 GB | ~8–12 GB |
| Token数量(≈) | ~1369 | ~729 | ~324 |
| Attention计算量 | 1x | ~0.3x | ~0.06x |
| 点云密度 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐ |
| 几何细节(边缘/结构) | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐ |
| 深度精度 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐ |
| 相机位姿稳定性 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ |
| 小目标保留(电线/人等) | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐ |
| 长视频稳定性(不OOM) | ⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| 适用场景 | 高精度重建(离线) | 工程平衡(推荐) | 实时尝试/粗建图 |
分辨率降低后的缺点
点云变“糙”
像素少 → 点少 → 点云稀疏
👉 表现:
细节丢失(窗框、栏杆)
边缘锯齿
小物体消失
深度精度下降
低分辨率 → 深度估计更粗
👉 影响:
远处更模糊
平面不平整
相机位姿略变差
特征少 → 匹配弱 → pose 抖动
👉 特别是在:
纹理少 / 重复纹理 场景
小目标直接消失
比如:
电线 / 树枝 / 人 / 标志牌
👉 在 256 分辨率下:
可能直接没了 ❗
分辨率选择
| 分辨率 | 是否可用 | 原因 |
|---|---|---|
| 518 | ✅ | 官方默认 |
| 392 | ✅ | 28×14 |
| 280 | ✅ | 20×14 |
| 224 | ✅ | 16×14 |
| 384 | ❌ | 不能整除14 |
| 256 | ❌ | 同样问题 |
分辨率518x518
(lingbot-map) xt@xt-2288H-V5:~/lixiaogang/lingbot-map/lingbot-map$ CUDA_VISIBLE_DEVICES=1 python demo.py --model_path ../models/lingbot-map.pt --video_path video_long.mp4 --fps 10 --use_sdpa
========== LingBot-MAP Demo ==========
[配置] 输入模式: 视频
[配置] 推理模式: streaming
[配置] 模型路径: ../models/lingbot-map.pt
[配置] 视频路径: video_long.mp4 (采样FPS=10)
======================================
[阶段] 开始加载数据与模型...
Extracting frames: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1599/1599 [00:03<00:00, 428.16frame/s]
从视频抽取完成: 533 帧 (总帧数=1599, 抽帧间隔=3)
正在加载 533 张图像...
原始图像分辨率(首帧): 720x1280
Loading images: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 533/533 [00:01<00:00, 298.19it/s]
图像预处理完成: 尺寸=518x518, 模式=canonical crop
正在构建模型...
正在加载权重文件: ../models/lingbot-map.pt
缺失参数键数量: 62
权重加载完成。
[耗时] 数据与模型加载完成: 21.6s
正在将 aggregator 转为 torch.bfloat16 (heads 保持 fp32)
[输入] 帧数: 533, 张量形状: (533, 3, 518, 518)
[输入] 当前模式: streaming
加载后 GPU 显存: alloc=4.66 GB, reserved=4.71 GB
[阶段] 开始模型推理 (mode=streaming, dtype=torch.bfloat16)...
Streaming inference: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 533/533 [05:26<00:00, 1.61it/s]
[耗时] 模型推理完成: 329.82s
[统计] 平均单帧耗时: 618.81 ms
[统计] 推理吞吐: 1.62 FPS
推理阶段 GPU 峰值显存: 21.33 GB (reserved 峰值 21.85 GB)
[阶段] 开始后处理...
正在将结果移动到 CPU...
[耗时] 后处理完成: 0.04s
分辨率384x384
(lingbot-map) xt@xt-2288H-V5:~/lixiaogang/lingbot-map/lingbot-map$ CUDA_VISIBLE_DEVICES=1 python demo.py --model_path ../models/lingbot-map.pt --video_path video_long.mp4 --fps 10 --use_sdpa --image_size 392
========== LingBot-MAP Demo ==========
[配置] 输入模式: 视频
[配置] 推理模式: streaming
[配置] 模型路径: ../models/lingbot-map.pt
[配置] 视频路径: video_long.mp4 (采样FPS=10)
======================================
[阶段] 开始加载数据与模型...
Extracting frames: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1599/1599 [00:03<00:00, 424.41frame/s]
从视频抽取完成: 533 帧 (总帧数=1599, 抽帧间隔=3)
正在加载 533 张图像...
原始图像分辨率(首帧): 720x1280
Loading images: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 533/533 [00:01<00:00, 291.61it/s]
图像预处理完成: 尺寸=392x392, 模式=canonical crop
正在构建模型...
正在加载权重文件: ../models/lingbot-map.pt
检测到位置编码尺寸不匹配,正在插值: torch.Size([1, 1370, 1024]) -> torch.Size([1, 785, 1024])
缺失参数键数量: 62
权重加载完成。
[耗时] 数据与模型加载完成: 22.7s
正在将 aggregator 转为 torch.bfloat16 (heads 保持 fp32)
[输入] 帧数: 533, 张量形状: (533, 3, 392, 392)
[输入] 当前模式: streaming
加载后 GPU 显存: alloc=3.93 GB, reserved=3.97 GB
[阶段] 开始模型推理 (mode=streaming, dtype=torch.bfloat16)...
Streaming inference: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 533/533 [03:05<00:00, 2.82it/s]
[耗时] 模型推理完成: 188.24s
[统计] 平均单帧耗时: 353.17 ms
[统计] 推理吞吐: 2.83 FPS
推理阶段 GPU 峰值显存: 13.75 GB (reserved 峰值 14.20 GB)
[阶段] 开始后处理...
正在将结果移动到 CPU...
[耗时] 后处理完成: 0.03s
分辨率对比
| 指标 | 518×518 | 392×392 | 提升 |
|---|---|---|---|
| 单帧耗时 | 618.8 ms | 353.2 ms | 🚀 -43% |
| FPS | 1.62 | 2.83 | 🚀 +75% |
| 显存峰值 | 21.33 GB | 13.75 GB | 🚀 -35% |
| 总推理时间 | 329 s | 188 s | 🚀 -43% |
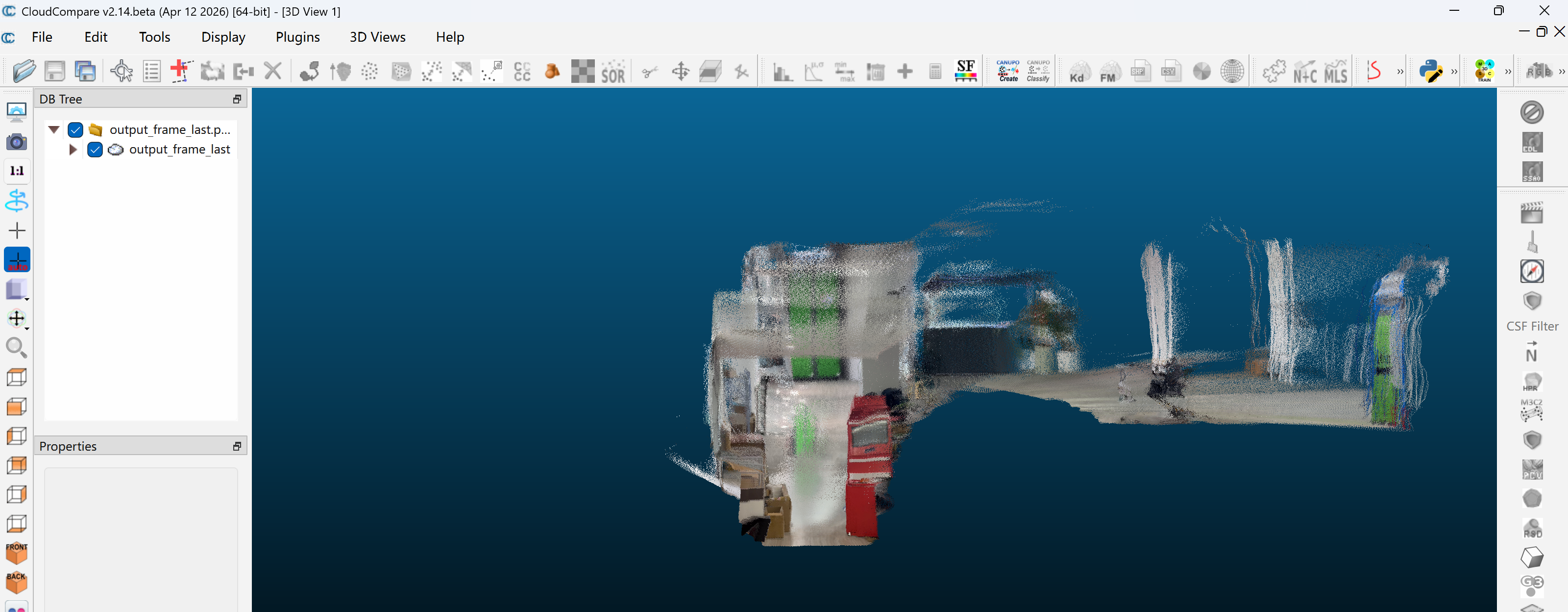
导出PCD格式的点云文件
0
次点赞