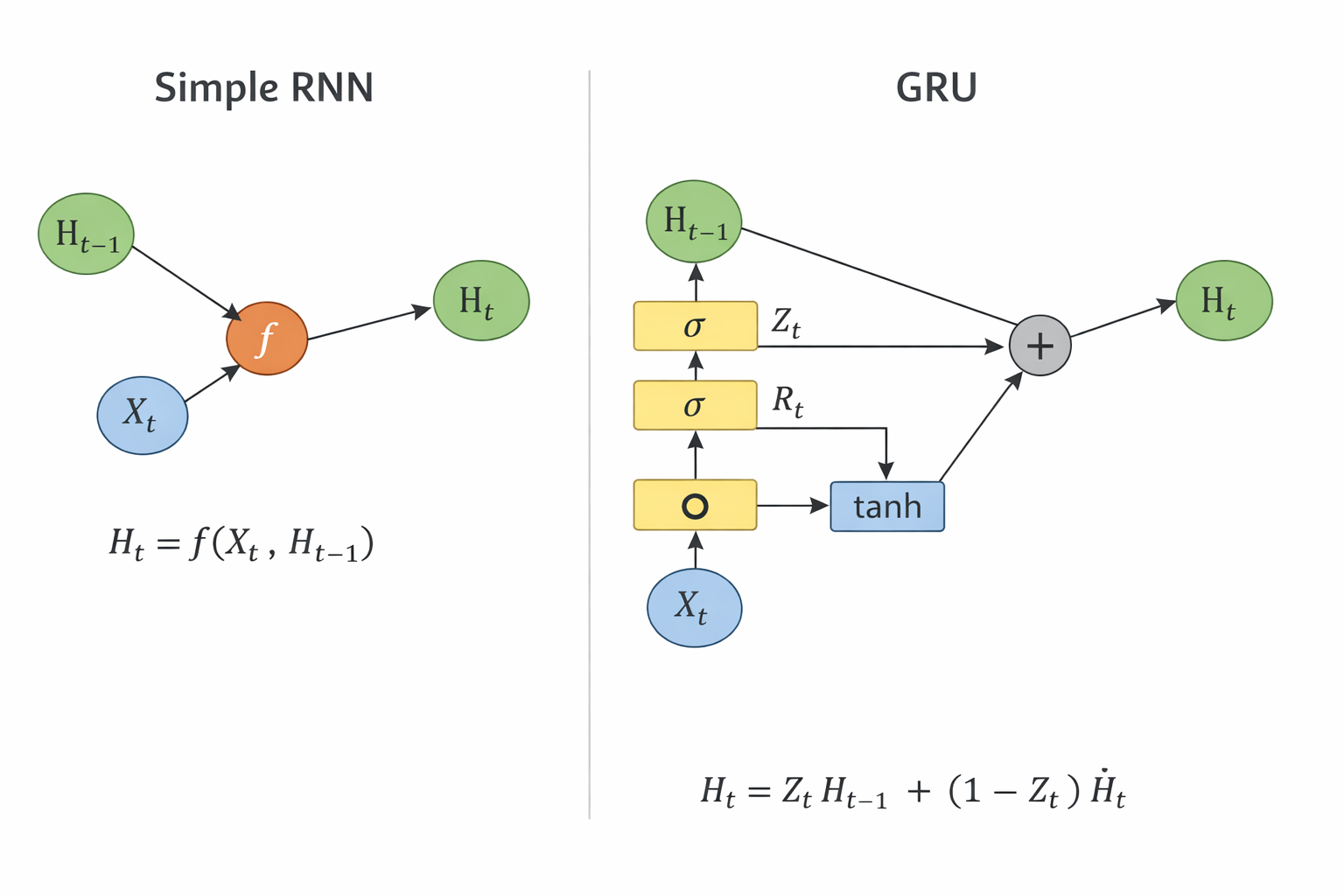
门控隐状态
门控循环单元(gated recurrent unit,GRU)
GRU 的核心思想(重点)
GRU 做了一件事:
给“隐状态 H”加了两个开关(门)
也就是:
- 更新门(Update Gate):要不要“继承过去”
- 重置门(Reset Gate):要不要“忘掉过去”
核心公式
| 符号 | 含义 |
|---|---|
| (X_t) | 当前输入 |
| (H_{t-1}) | 上一时刻隐状态 |
| (H_t) | 当前隐状态 |
| (Z_t) | 更新门 |
| (R_t) | 重置门 |
| (\tilde{H}_t) | 候选状态 |
| (\sigma) | sigmoid(输出 0~1) |
| (\odot) | 按元素乘(Hadamard) |
上方路径(旧记忆直通)
H_{t-1} ───────────────► (+) ─► H_t
▲
│ Z_t
👉 这条路径表示:旧状态可以直接传到下一步
下方路径(新信息生成)
X_t ─► ○ ─► tanh ─► (+)
▲
│ R_t ⊙ H_{t-1}
中间融合(最关键)
H_{t-1}
│
▼
(+) ──► H_t
▲
│
H~_t
加深理解
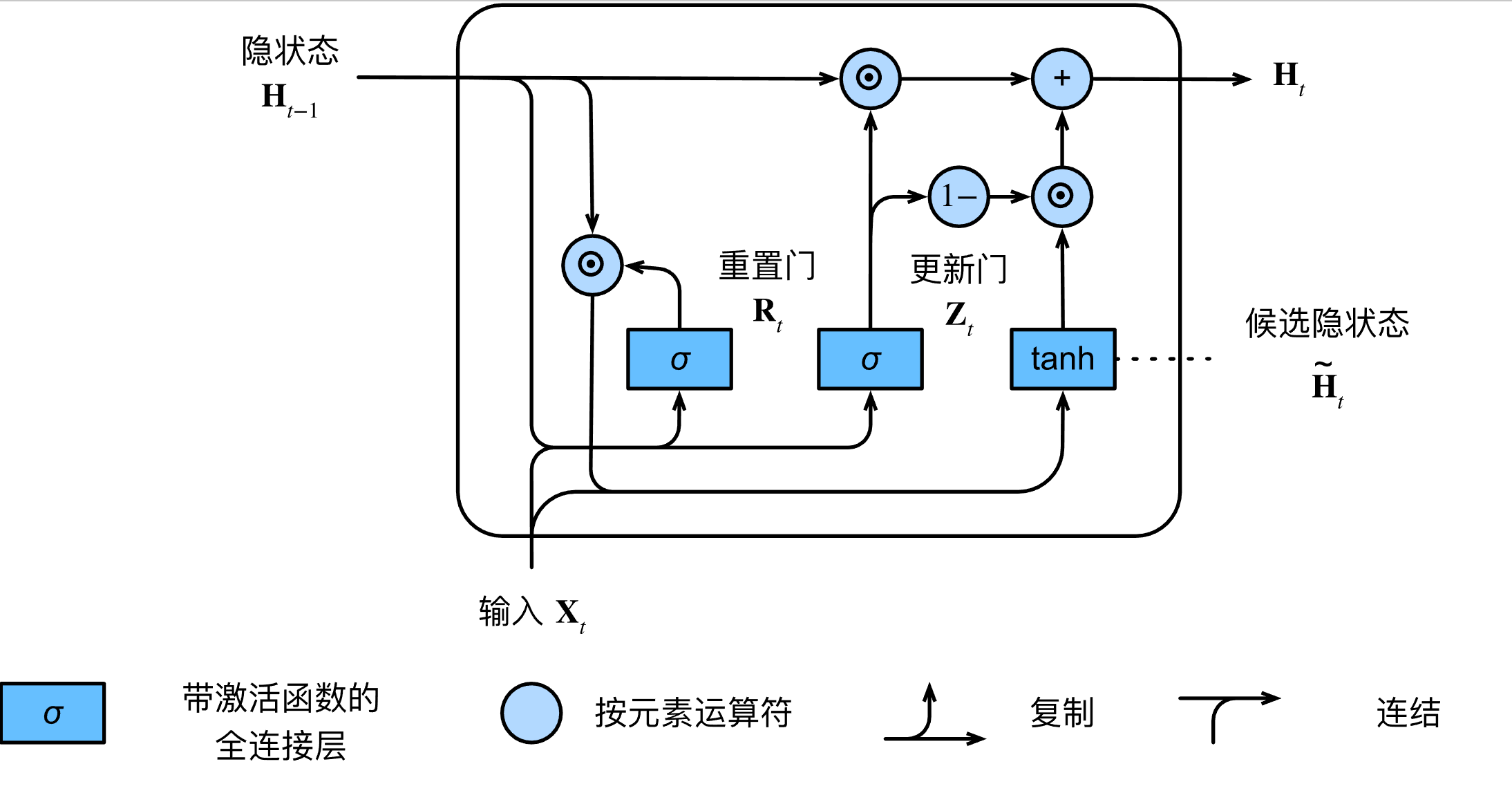
更新门(Update Gate)
决定有多少“旧记忆”直接流向未来:
\[Z_t = \sigma(X_t W_z + H_{t-1} U_z + b_z)\]- 如果 $Z_t$ 接近 $1$,说明旧记忆非常重要,几乎原封不动保留。
- 如果 $Z_t$ 接近 $0$,说明我们需要大量吸收今天的新知识。
重置门(Reset Gate)
\[R_t = \sigma(X_t W_r + H_{t-1} U_r + b_r)\]比如你今天学物理,重置门会让你回想昨天的数学公式;如果你今天改学画画了,重置门就会让昨天的数学公式“失效”,免得干扰新知识。
候选隐状态(Candidate Hidden State)
\[\tilde{H}_t = \tanh(X_t W_h + (R_t \odot H_{t-1}) U_h + b_h)\]最终隐状态(Final Hidden State)
\[H_t = Z_t \odot H_{t-1} + (1 - Z_t) \odot \tilde{H}_t\]天平效应:$Z_t$ 和 $(1 - Z_t)$ 构成了一个天平。如果你想保留 80% 的昨天 ($Z_t = 0.8$),那么你只能吸收 20% 的今天。
在传统的 RNN 中,信息每经过一步都会被强行乘以一个系数,导致传着传着就没了(梯度消失)。但在 GRU 里,如果 $Z_t$ 设为 $1$,信息可以毫无损耗地流向未来,这让它具备了处理长序列的能力。
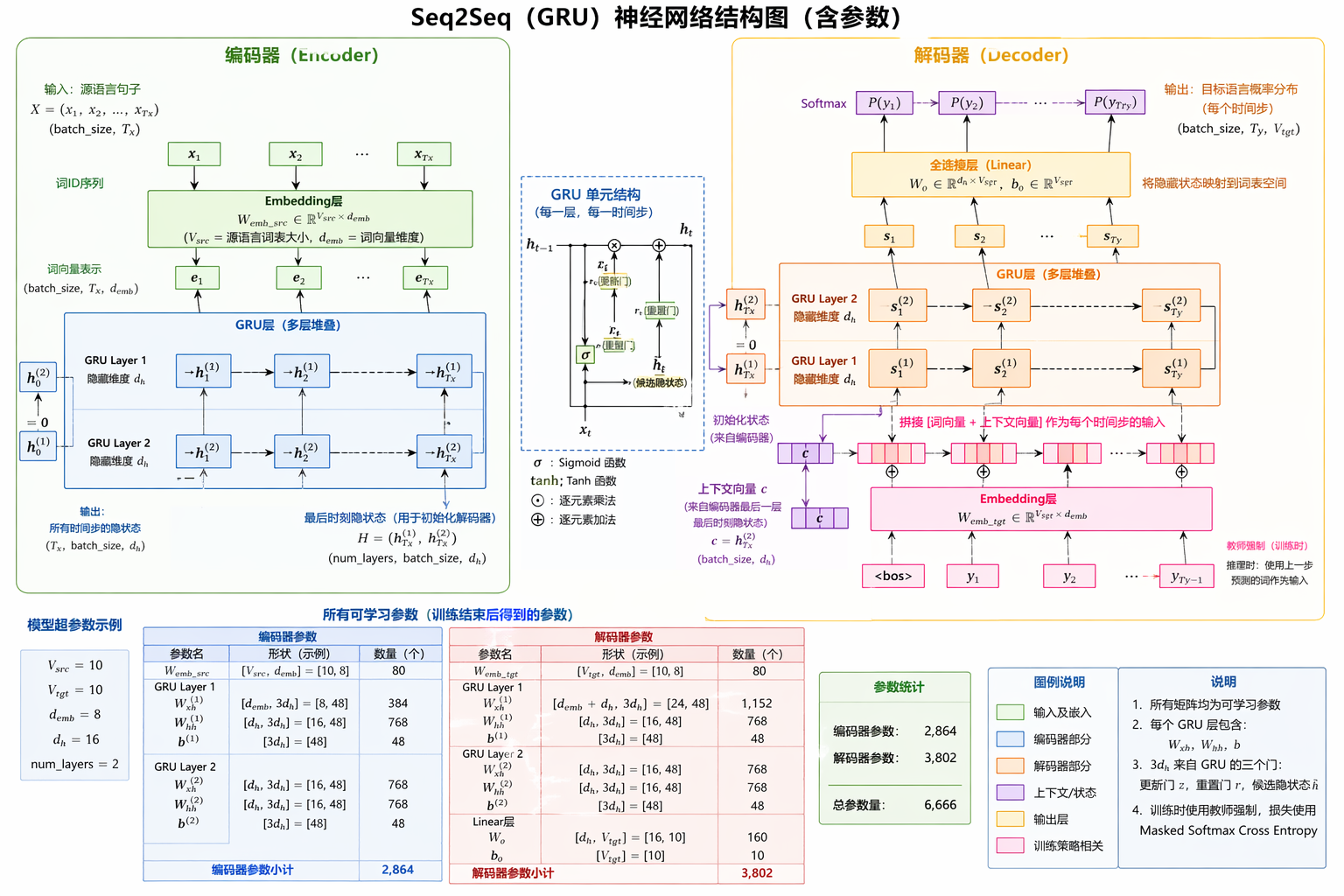
模型最终需要获取的参数
Z_t = σ(X_t W_z + H_{t-1} U_z + b_z)
R_t = σ(X_t W_r + H_{t-1} U_r + b_r)
H~_t = tanh(X_t W_h + (R_t ⊙ H_{t-1}) U_h + b_h)
👉 所以最终保存:
{W_z, U_z, b_z,
W_r, U_r, b_r,
W_h, U_h, b_h}
训练源码
# -*- coding: utf-8 -*-
import torch
from torch import nn
from d2l import torch as d2l
import my_d2l
batch_size, num_steps = 32, 35
train_iter, vocab = my_d2l.load_data_time_machine(batch_size, num_steps)
def get_params(vocab_size, num_hiddens, device):
"""
初始化 GRU(从零实现)所需的全部可训练参数。
这里做的是“字符级语言模型”常见设定:
- 输入 X_t 是 one-hot(长度 = vocab_size)
- 隐状态 H_t 维度 = num_hiddens
- 输出 Y_t 维度 = vocab_size(预测下一个字符的分类 logits)
记号约定(按时间步 t):
- X_t: (batch_size, vocab_size)
- H_{t-1}: (batch_size, num_hiddens)
- Z_t: 更新门 (batch_size, num_hiddens)
- R_t: 重置门 (batch_size, num_hiddens)
- H~_t: 候选隐状态 (batch_size, num_hiddens)
- H_t: 新隐状态 (batch_size, num_hiddens)
- Y_t: 输出 logits (batch_size, vocab_size)
"""
num_inputs = num_outputs = vocab_size
def normal(shape):
return torch.randn(size=shape, device=device)*0.01
def three():
"""
生成一组“输入->隐藏、隐藏->隐藏、偏置”的参数 (W_x*, W_h*, b_*)。
- W_x*: (num_inputs=vocab_size, num_hiddens)
- W_h*: (num_hiddens, num_hiddens)
- b_*: (num_hiddens,) 会在 batch 维自动广播成 (batch_size, num_hiddens)
"""
return (normal((num_inputs, num_hiddens)),
normal((num_hiddens, num_hiddens)),
torch.zeros(num_hiddens, device=device))
W_xz, W_hz, b_z = three() # 更新门 Z_t 的参数
W_xr, W_hr, b_r = three() # 重置门 R_t 的参数
W_xh, W_hh, b_h = three() # 候选隐状态 H~_t 的参数(注意:这里也用到了 R_t)
# 输出层参数:隐藏状态 -> 词表 logits
W_hq = normal((num_hiddens, num_outputs))
b_q = torch.zeros(num_outputs, device=device)
# 将全部参数收集起来,后续训练时统一做梯度更新
params = [W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q]
for param in params:
param.requires_grad_(True)
return params
def init_gru_state(batch_size, num_hiddens, device):
"""
初始化 GRU 的隐藏状态。
GRU 只有一个隐藏状态 H(不像 LSTM 还有记忆单元 C),因此返回单元素元组:
- H_0: (batch_size, num_hiddens)
"""
return (torch.zeros((batch_size, num_hiddens), device=device), )
def gru(inputs, state, params):
"""
GRU 的前向计算(从零实现,按时间步循环)。
inputs: one-hot 后的输入序列(时间步优先)
- 形状: (num_steps, batch_size, vocab_size)
- 迭代 for X in inputs 时,每个 X 就是一个时间步 X_t,形状为 (batch_size, vocab_size)
state:
- (H_{t-1},) 其中 H_{t-1} 形状为 (batch_size, num_hiddens)
返回:
- outputs: 把每个时间步的 Y_t 沿着 batch 维拼接后得到
形状: (num_steps * batch_size, vocab_size)
这么做是为了和训练时的标签 y = Y.T.reshape(-1) 对齐(同样会展平成一维)
- (H_t,): 最后一个时间步的隐藏状态
"""
W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q = params
H, = state
outputs = []
for X in inputs:
# 1) 更新门 Z_t:控制“保留多少旧信息、写入多少新信息”
# Z_t = σ(X_t W_xz + H_{t-1} W_hz + b_z)
Z = torch.sigmoid((X @ W_xz) + (H @ W_hz) + b_z)
# 2) 重置门 R_t:控制“在计算候选隐状态时,过去信息参与多少”
# R_t = σ(X_t W_xr + H_{t-1} W_hr + b_r)
R = torch.sigmoid((X @ W_xr) + (H @ W_hr) + b_r)
# 3) 候选隐状态 H~_t:先用 R_t 对旧隐状态做“过滤”,再融合当前输入
# H~_t = tanh(X_t W_xh + (R_t ⊙ H_{t-1}) W_hh + b_h)
# 这里的 (R * H) 是逐元素乘法 ⊙,形状仍为 (batch_size, num_hiddens)
H_tilda = torch.tanh((X @ W_xh) + ((R * H) @ W_hh) + b_h)
# 4) 最终隐状态 H_t:在“旧隐状态”和“候选隐状态”之间做插值
# H_t = Z_t ⊙ H_{t-1} + (1 - Z_t) ⊙ H~_t
# - Z_t 越接近 1:越倾向于复制旧状态(更强的记忆/更少更新)
# - Z_t 越接近 0:越倾向于采用候选状态(更强的更新/更少保留)
H = Z * H + (1 - Z) * H_tilda
# 5) 输出层:用当前隐藏状态产生对“下一个字符”的预测 logits
# 训练时会把所有时间步的 logits 拼起来送入 CrossEntropyLoss
Y = H @ W_hq + b_q
outputs.append(Y)
return torch.cat(outputs, dim=0), (H,)
vocab_size, num_hiddens, device = len(vocab), 256, d2l.try_gpu()
num_epochs, lr = 500, 1
model = my_d2l.RNNModelScratch(len(vocab), num_hiddens, device, get_params,
init_gru_state, gru)
my_d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)
param_names = [
"W_xz(更新门:输入->隐藏)",
"W_hz(更新门:隐藏->隐藏)",
"b_z(更新门偏置)",
"W_xr(重置门:输入->隐藏)",
"W_hr(重置门:隐藏->隐藏)",
"b_r(重置门偏置)",
"W_xh(候选态:输入->隐藏)",
"W_hh(候选态:隐藏->隐藏)",
"b_h(候选态偏置)",
"W_hq(输出层:隐藏->输出)",
"b_q(输出层偏置)",
]
print("\n===== 训练结束:参数统计 =====")
with torch.no_grad():
for name, p in zip(param_names, model.params):
t = p.detach().float().cpu()
flat = t.reshape(-1)
preview_len = min(8, flat.numel())
preview = ", ".join("{:.6f}".format(v) for v in flat[:preview_len].tolist())
print(
"{} | shape={} | mean={:.6f} std={:.6f} min={:.6f} max={:.6f} norm={:.6f}".format(
name,
tuple(t.shape),
t.mean().item(),
t.std(unbiased=False).item(),
t.min().item(),
t.max().item(),
t.norm().item(),
)
)
print(" 前{}个元素: [{}]".format(preview_len, preview))
运行结果
===== 训练结束:参数统计 =====
W_xz(更新门:输入->隐藏) | shape=(28, 256)
前8个元素: [-0.003627, -0.019985, 0.008601, 0.004355, -0.001498, 0.006224, 0.003091, -0.019064]
W_hz(更新门:隐藏->隐藏) | shape=(256, 256)
前8个元素: [-0.140070, 0.075508, -0.021602, -0.371345, -0.034835, 0.064259, 0.025994, 0.008877]
b_z(更新门偏置) | shape=(256,)
前8个元素: [-0.134403, -0.104673, -0.241793, -0.073889, -0.154346, -0.170450, -0.243588, -0.037774]
W_xr(重置门:输入->隐藏) | shape=(28, 256)
前8个元素: [0.002454, -0.003423, 0.001818, 0.005756, -0.012555, 0.002879, 0.002133, 0.005670]
W_hr(重置门:隐藏->隐藏) | shape=(256, 256)
前8个元素: [0.117054, 0.037085, 0.019455, 0.069125, -0.033068, 0.007181, -0.074164, -0.022631]
b_r(重置门偏置) | shape=(256,)
前8个元素: [0.122728, 0.110268, 0.008240, 0.168649, 0.092461, 0.077959, 0.158600, 0.016080]
W_xh(候选态:输入->隐藏) | shape=(28, 256)
前8个元素: [-0.012011, 0.000462, -0.006277, -0.016342, 0.007313, -0.006342, -0.009204, -0.000668]
W_hh(候选态:隐藏->隐藏) | shape=(256, 256)
前8个元素: [0.167800, 0.013950, -0.083931, -0.234347, -0.090358, -0.251816, 0.433758, -0.041111]
b_h(候选态偏置) | shape=(256,)
前8个元素: [0.027821, 0.036024, -0.095355, -0.556497, -0.129998, -0.325916, -0.022622, -0.120154]
W_hq(输出层:隐藏->输出) | shape=(256, 28)
前8个元素: [0.068355, -0.521657, 0.596986, -0.049636, 0.038591, 0.534536, -0.566960, -0.296156]
b_q(输出层偏置) | shape=(28,)
前8个元素: [-1.392680, 0.812380, 0.891642, 0.421197, 0.805844, 0.678492, 0.166851, 0.691935]
文字结构图
GRU 多时间步计算图
┌───────────────┐
X_{t-1} ─►│ │
│ GRU Cell │
H_{t-2} ─►│ │
└──────┬────────┘
│
H_{t-1}
│
▼
┌───────────────┐
X_t ───►│ │
│ GRU Cell │
H_{t-1} ─►│ │
└──────┬────────┘
│
H_t
│
▼
┌───────────────┐
X_{t+1} ─►│ │
│ GRU Cell │
H_t ───►│ │
└──────┬────────┘
│
H_{t+1}
单个 GRU Cell 公式
Z = sigmoid(X @ W_xz + H @ W_hz + b_z)
R = sigmoid(X @ W_xr + H @ W_hr + b_r)
H_tilda = tanh(X @ W_xh + (R * H) @ W_hh + b_h)
H = Z * H + (1 - Z) * H_tilda
单个 GRU Cell 结构图
H_{t-1}
│
┌──────────┼──────────┐
│ │ │
▼ ▼ ▼
W_hz W_hr W_hh
│ │ │
│ │ (× R_t)
│ │ ▲
│ │ │
│ ▼ │
│ sigmoid │
│ │ │
│ R_t │
│ │
▼ │
W_xz │
▲ │
│ │
X_t ────┼────► W_xr ─────────┘
│
└────► W_xh ──► tanh ──► H~_t
Z_t = sigmoid(...) ◄───────────────
最终融合:
H_t = Z_t ⊙ H_{t-1} + (1 - Z_t) ⊙ H~_t
模型参数对比普通RNN
| 维度 | RNN | GRU |
|---|---|---|
| 门控 | ❌ 无 | ✅ 有(2个门) |
| 参数量 | 1x | 3x |
| 表达能力 | 弱 | 强 |
| 长期依赖 | 差 | 好 |
| 训练难度 | 高(梯度消失) | 更稳定 |
相比普通 RNN,GRU 引入了更新门和重置门,因此需要三组权重矩阵和偏置,参数量约为普通 RNN 的三倍,但换来了更强的长期依赖建模能力和更稳定的训练过程。
LSTM
长短期存储器(long short-term memory,LSTM)
GRU 是 LSTM 的简化版本,将记忆单元和隐藏状态合并,通过更新门和重置门实现信息控制,参数更少、计算更快;而 LSTM 通过独立的细胞状态和三种门实现更精细的长期依赖建模,但代价是更高的计算和存储开销。
| 维度 | GRU | LSTM |
|---|---|---|
| 状态结构 | 仅隐藏状态 (H_t) | 隐藏状态 (H_t) + 细胞状态 (C_t) |
| 门结构 | 2 个门:更新门 (Z_t)、重置门 (R_t) | 3 个门:输入门 (i_t)、遗忘门 (f_t)、输出门 (o_t) |
| 核心思想 | 新旧信息加权融合 | 显式长期记忆 + 短期输出分离 |
| 核心更新 | (H_t = Z_t H_{t-1} + (1-Z_t)\tilde{H}_t) | (C_t = f_t C_{t-1} + i_t \tilde{C}_t) |
| 长期记忆机制 | 隐式(通过 Z 门) | 显式(通过 C 状态) |
| 参数量 | (3(dh + h^2 + h)) | (4(dh + h^2 + h)) |
| 计算量 | 较低(3 次矩阵乘) | 较高(4 次矩阵乘) |
| 训练稳定性 | 好 | 更好 |
| 长期依赖能力 | 强 | 更强 |
| 收敛速度 | 通常更快 | 略慢 |
| 过拟合风险 | 较低 | 较高(参数多) |
| 推理速度 | 更快 | 更慢 |
| 模型大小 | 更小 | 更大 |
| 实现复杂度 | 简单 | 复杂 |
| 嵌入式适配 | 更容易(推荐) | 较难 |
| 典型应用 | 实时系统、边缘设备 | 语音识别、长文本建模 |
| 工程默认选择 | ✅ 推荐优先使用 | ❗ 需要更强能力时再用 |
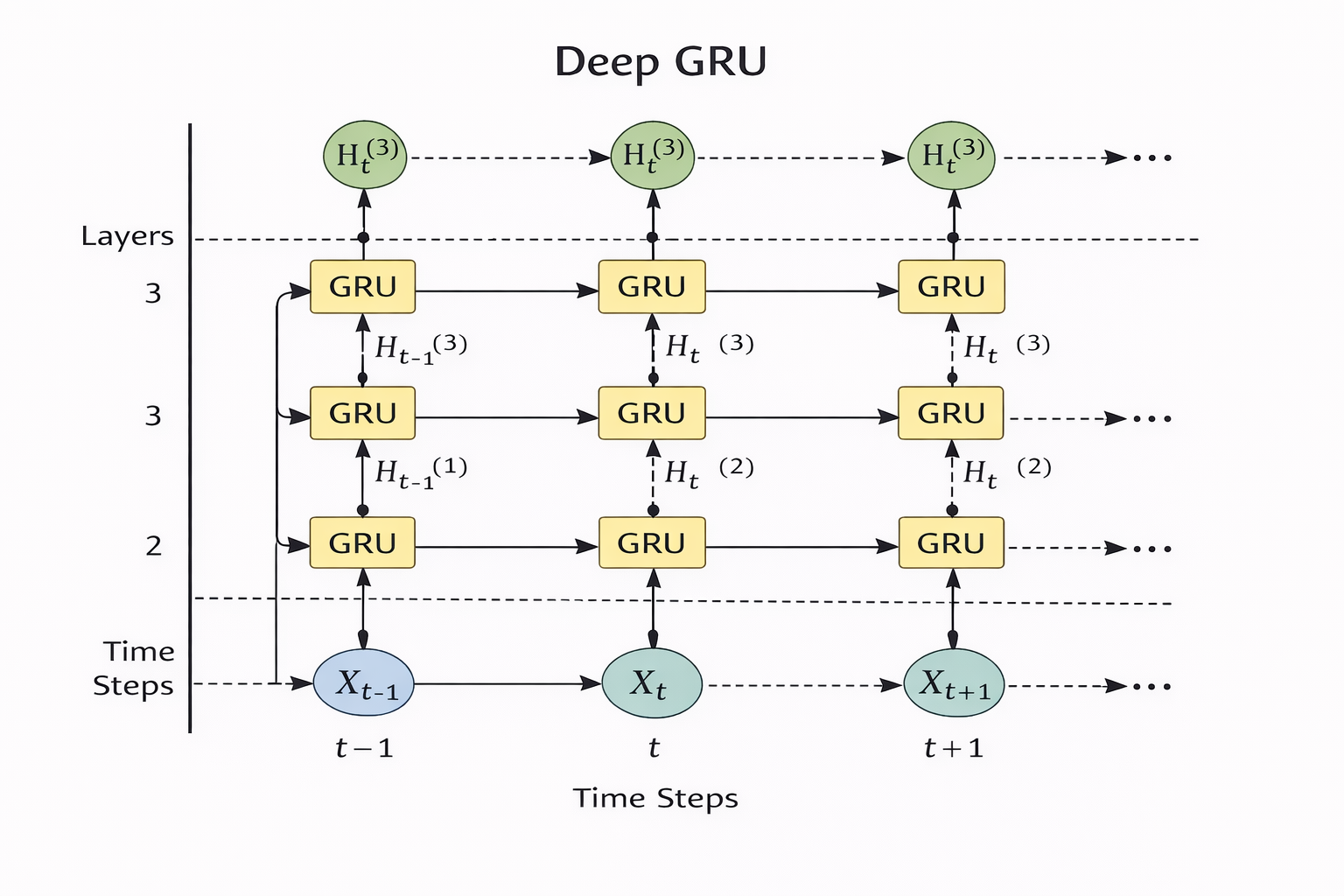
深度循环神经网络
Deep RNN = 在时间维度 + 空间维度同时“加深”的 RNN
双向循环神经网络
双向循环神经网络通过同时建模序列的前向和后向信息,使每个时间步的表示包含完整上下文信息,从而显著提升序列理解能力,但由于依赖未来数据,不适用于实时预测任务。
机器翻译和数据集
原始文本
↓
预处理(清洗)
↓
分词(tokenize)
↓
构建词表(vocab)
↓
词 → index
↓
补齐长度(pad / truncate)
↓
构建 batch
下载和预处理数据集
import os
import torch
from d2l import torch as d2l
#@save
d2l.DATA_HUB['fra-eng'] = (d2l.DATA_URL + 'fra-eng.zip',
'94646ad1522d915e7b0f9296181140edcf86a4f5')
#@save
def read_data_nmt():
"""载入“英语-法语”数据集"""
data_dir = d2l.download_extract('fra-eng')
with open(os.path.join(data_dir, 'fra.txt'), 'r',
encoding='utf-8') as f:
return f.read()
raw_text = read_data_nmt()
print(raw_text[:75])
#@save
def preprocess_nmt(text):
"""预处理“英语-法语”数据集"""
def no_space(char, prev_char):
return char in set(',.!?') and prev_char != ' '
# 使用空格替换不间断空格
# 使用小写字母替换大写字母
text = text.replace('\u202f', ' ').replace('\xa0', ' ').lower()
# 在单词和标点符号之间插入空格
out = [' ' + char if i > 0 and no_space(char, text[i - 1]) else char
for i, char in enumerate(text)]
return ''.join(out)
text = preprocess_nmt(raw_text)
print(text[:80])
运行结果
go . va !
hi . salut !
run ! cours !
run ! courez !
who ? qui ?
wow ! ça alors !
词元化
def tokenize_nmt(text, num_examples=None):
"""词元化“英语-法语”数据数据集"""
source, target = [], []
for i, line in enumerate(text.split('\n')):
if num_examples and i > num_examples:
break
parts = line.split('\t')
if len(parts) == 2:
source.append(parts[0].split(' '))
target.append(parts[1].split(' '))
return source, target
source, target = tokenize_nmt(text)
source[:6], target[:6]
print(source[:6], target[:6])
运行结果
([['go', '.'],
['hi', '.'],
['run', '!'],
['run', '!'],
['who', '?'],
['wow', '!']],
[['va', '!'],
['salut', '!'],
['cours', '!'],
['courez', '!'],
['qui', '?'],
['ça', 'alors', '!']])
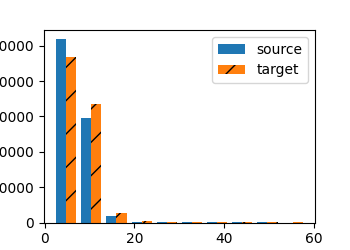
这个直方图在统计并对比“每个句子(序列)有多少个词元(token)”。
- 横轴 # tokens per sequence :一句话里词元的数量(也就是 len(l) )。
- 纵轴 count :有多少句话的长度落在对应的区间里(出现次数)。
- 两组柱子分别对应:
- source :英文句子长度分布( xlist=source )
- target :法文句子长度分布( ylist=target )
在这个简单的“英-法”数据集中,大多数文本序列的词元数量少于20个
词表
src_vocab = d2l.Vocab(source, min_freq=2,
reserved_tokens=['<pad>', '<bos>', '<eos>'])
print("词表大小:", len(src_vocab))
print('前20高频率词元(source):')
for token, freq in src_vocab.token_freqs[:20]:
print(f'{token}\t{freq}')
运行结果
词表大小: 10012
前20高频率词元(source):
. 139392
i 45611
you 43192
to 36718
the 33263
? 27619
a 23973
is 16829
tom 13990
that 12651
he 12209
do 11292
of 11287
it 11025
this 10385
in 10317
me 10165
have 9698
don't 9636
, 9318
加载数据集
#@save
def truncate_pad(line, num_steps, padding_token):
"""截断或填充文本序列"""
# 句子过长则截断,保证所有样本长度一致。
if len(line) > num_steps:
return line[:num_steps] # 截断
# 句子过短则补 <pad> 到固定长度。
return line + [padding_token] * (num_steps - len(line)) # 填充
# 演示:将第一条源句映射成索引后,再截断/填充到长度 10。
print(truncate_pad(src_vocab[source[0]], 10, src_vocab['<pad>']))
运行结果
[3919, 80, 208, 208, 208, 208, 208, 208, 208, 208]
👉 含义:
[go, .,
训练模型
#@save
def build_array_nmt(lines, vocab, num_steps):
"""将机器翻译的文本序列转换成小批量"""
# 1) 文本词元 -> 词表索引
lines = [vocab[l] for l in lines]
# 2) 每个序列末尾追加 <eos>,显式标记结束位置
lines = [l + [vocab['<eos>']] for l in lines]
# 3) 统一长度并打包成张量,形状约为 (样本数, num_steps)
array = torch.tensor([truncate_pad(
l, num_steps, vocab['<pad>']) for l in lines])
# 4) 统计每个样本的有效长度(非 <pad> 的元素个数)
valid_len = (array != vocab['<pad>']).type(torch.int32).sum(1)
return array, valid_len
#@save
def load_data_nmt(batch_size, num_steps, num_examples=600):
"""返回翻译数据集的迭代器和词表"""
# 读取并预处理文本
text = preprocess_nmt(read_data_nmt())
# 分词并截取部分样本用于训练/演示
source, target = tokenize_nmt(text, num_examples)
# 分别构建源语言与目标语言词表
src_vocab = d2l.Vocab(source, min_freq=2,
reserved_tokens=['<pad>', '<bos>', '<eos>'])
tgt_vocab = d2l.Vocab(target, min_freq=2,
reserved_tokens=['<pad>', '<bos>', '<eos>'])
# 将句子列表转换为定长索引张量与有效长度
src_array, src_valid_len = build_array_nmt(source, src_vocab, num_steps)
tgt_array, tgt_valid_len = build_array_nmt(target, tgt_vocab, num_steps)
# 训练时模型会同时使用:源序列、源有效长度、目标序列、目标有效长度
data_arrays = (src_array, src_valid_len, tgt_array, tgt_valid_len)
# 打包成可迭代的小批量数据迭代器
data_iter = d2l.load_array(data_arrays, batch_size)
return data_iter, src_vocab, tgt_vocab
# 将一条索引序列按有效长度还原为可读句子(词元字符串)。
def ids_to_sentence(ids_tensor, valid_len, vocab):
token_ids = ids_tensor[:int(valid_len)].tolist()
return ' '.join(vocab.to_tokens(token_ids))
# 取一个 batch 打印,便于确认数据形状与有效长度是否正确。
train_iter, src_vocab, tgt_vocab = load_data_nmt(batch_size=2, num_steps=8)
for X, X_valid_len, Y, Y_valid_len in train_iter:
print('X:', X.type(torch.int32))
print('X的有效长度:', X_valid_len)
print('Y:', Y.type(torch.int32))
print('Y的有效长度:', Y_valid_len)
for i in range(X.shape[0]):
x_sentence = ids_to_sentence(X[i], X_valid_len[i], src_vocab)
y_sentence = ids_to_sentence(Y[i], Y_valid_len[i], tgt_vocab)
print(f'样本{i} - X句子: {x_sentence}')
print(f'样本{i} - Y句子: {y_sentence}')
break
第一种随机运行结果
X: tensor([[ 58, 38, 2, 4, 5, 5, 5, 5],
[148, 88, 2, 4, 5, 5, 5, 5]], dtype=torch.int32)
X的有效长度: tensor([4, 4])
Y: tensor([[6, 0, 4, 5, 5, 5, 5, 5],
[6, 0, 4, 5, 5, 5, 5, 5]], dtype=torch.int32)
Y的有效长度: tensor([3, 3])
样本0 - X句子: get down . <eos>
样本0 - Y句子: <unk> ! <eos>
样本1 - X句子: take it . <eos>
样本1 - Y句子: <unk> ! <eos>
为什么 X 正常,Y 不正常?
因为:
英文词频高
法文更稀疏
👉 所以:
target 更容易变 <unk>
第二种随机测试结果
X: tensor([[ 81, 25, 126, 2, 4, 5, 5, 5],
[ 26, 158, 2, 4, 5, 5, 5, 5]], dtype=torch.int32)
X的有效长度: tensor([5, 4])
Y: tensor([[100, 163, 6, 2, 4, 5, 5, 5],
[ 22, 179, 2, 4, 5, 5, 5, 5]], dtype=torch.int32)
Y的有效长度: tensor([5, 4])
样本0 - X句子: i can run . <eos>
样本0 - Y句子: je sais <unk> . <eos>
样本1 - X句子: catch tom . <eos>
样本1 - Y句子: attrapez tom . <eos>
数据解释表(batch=2)
🧩 样本 0
| 项目 | 内容 |
|---|---|
| X(index) | [81, 25, 126, 2, 4, 5, 5, 5] |
| X(句子) | i can run . <eos> <pad> <pad> <pad> |
| X_valid_len | 5 |
| Y(index) | [100, 163, 6, 2, 4, 5, 5, 5] |
| Y(句子) | je sais <unk> . <eos> <pad> <pad> <pad> |
| Y_valid_len | 5 |
| 真实含义 | i can run . → je sais courir .(被 <unk> 截断) |
🧩 样本 1
| 项目 | 内容 |
|---|---|
| X(index) | [26, 158, 2, 4, 5, 5, 5, 5] |
| X(句子) | catch tom . <eos> <pad> <pad> <pad> <pad> |
| X_valid_len | 4 |
| Y(index) | [22, 179, 2, 4, 5, 5, 5, 5] |
| Y(句子) | attrapez tom . <eos> <pad> <pad> <pad> <pad> |
| Y_valid_len | 4 |
| 真实含义 | catch tom . → attrapez tom . |
🔑 特殊 token 说明
| token | 作用 |
|---|---|
<eos> |
句子结束 |
<pad> |
填充(补齐长度) |
<unk> |
未登录词(低频词) |
编码器-解码器架构
英文句子 X
↓
[ Encoder ]
↓
语义表示(context / state)
↓
[ Decoder ]
↓
法文句子 Y
序列到序列学习
Seq2Seq = 学习一个函数:把“一个序列”映射成“另一个序列”
编码器
import collections
import math
import torch
from torch import nn
from d2l import torch as d2l
#@save
class Seq2SeqEncoder(d2l.Encoder):
"""用于序列到序列(Seq2Seq)任务的 GRU 编码器。
这个编码器的职责:
1. 把离散词 ID 先映射成连续向量(embedding);
2. 按时间步送入多层 GRU,提取上下文语义;
3. 输出所有时间步的隐状态 output,以及最后时刻(按层)的 state,
供解码器继续使用。
"""
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, debug=False, **kwargs):
super(Seq2SeqEncoder, self).__init__(**kwargs)
# debug=True 时会在 forward 中打印关键中间信息,方便学习和排查
self.debug = debug
# 词嵌入层:
# 输入是 token 的整数索引,范围 [0, vocab_size-1]。
# 输出是稠密向量,维度为 embed_size。
# 例如:输入形状 (batch_size, num_steps) ->
# 输出形状 (batch_size, num_steps, embed_size)
self.embedding = nn.Embedding(vocab_size, embed_size)
# 多层 GRU:
# input_size=embed_size:每个时间步的输入向量维度
# hidden_size=num_hiddens:GRU 隐状态维度
# num_layers:堆叠的 GRU 层数
# dropout:仅在层与层之间生效(单层时通常不起作用)
self.rnn = nn.GRU(embed_size, num_hiddens, num_layers,
dropout=dropout)
def forward(self, X, *args):
# X: 词 ID 张量,形状 (batch_size, num_steps)
# batch_size 表示一批句子的数量
# num_steps 表示每个句子的时间步(长度,通常已做 padding)
#
if self.debug:
print(f"[Encoder] 输入 X.shape={tuple(X.shape)}, dtype={X.dtype}")
# 经过 embedding 后:
# X 的形状变为 (batch_size, num_steps, embed_size)
X = self.embedding(X)
if self.debug:
print(f"[Encoder] embedding 后 X.shape={tuple(X.shape)}")
# PyTorch 的 RNN/GRU 默认期望输入形状为
# (num_steps, batch_size, input_size),即“时间步在第 0 维”。
# 所以这里需要把维度从
# (batch_size, num_steps, embed_size)
# 变换成
# (num_steps, batch_size, embed_size)
X = X.permute(1, 0, 2)
if self.debug:
print(f"[Encoder] permute 后 X.shape={tuple(X.shape)}")
# 不显式传入初始隐状态 h0 时,GRU 会自动用全 0 初始化。
#
# output: 每个时间步、最后一层 GRU 的输出
# 形状 (num_steps, batch_size, num_hiddens)
# state : 最后一个时间步、每一层 GRU 的隐状态
# 形状 (num_layers, batch_size, num_hiddens)
output, state = self.rnn(X)
if self.debug:
print(f"[Encoder] rnn 输出 output.shape={tuple(output.shape)}")
print(f"[Encoder] rnn 状态 state.shape={tuple(state.shape)}")
# 在 Seq2Seq 中的常见用法:
# - output 可用于注意力机制(若解码器需要看到全部时间步表示)
# - state 常作为解码器初始隐状态(把编码语义“传”给解码器)
return output, state
# ======== 下面是一个最小可运行示例(用于检查维度) ========
# 构造编码器:
# - 词表大小 10
# - 词向量维度 8
# - GRU 隐藏单元 16
# - GRU 层数 2
encoder = Seq2SeqEncoder(vocab_size=10, embed_size=8, num_hiddens=16,
num_layers=2, debug=True)
# 切到评估模式(关闭如 dropout 这类训练期行为)
encoder.eval()
# 构造一个全 0 的输入:
# 形状 (4, 7) 表示 batch_size=4, num_steps=7
# 元素类型必须是 long(因为 embedding 需要整数索引)
X = torch.zeros((4, 7), dtype=torch.long)
output, state = encoder(X)
# output 预期形状: (7, 4, 16)
# state 预期形状: (2, 4, 16)
output.shape
print(f"[Demo] output.shape={tuple(output.shape)}")
print(f"[Demo] state.shape={tuple(state.shape)}")
运行结果
[Encoder] 输入 X.shape=(4, 7), dtype=torch.int64
[Encoder] embedding 后 X.shape=(4, 7, 8)
[Encoder] permute 后 X.shape=(7, 4, 8)
[Encoder] rnn 输出 output.shape=(7, 4, 16)
[Encoder] rnn 状态 state.shape=(2, 4, 16)
[Demo] output.shape=(7, 4, 16)
[Demo] state.shape=(2, 4, 16)
编码器理解
输入 X (token id)
shape: (batch_size=4, seq_len=7)
│
▼
┌──────────────────────────┐
│ Embedding 层 │
│ nn.Embedding(10 → 8) │
└──────────────────────────┘
│
▼
shape: (4, 7, 8)
│
▼
┌──────────────────────────┐
│ 维度变换 permute │
│ (batch, seq, embed) │
│ → (seq, batch, embed) │
└──────────────────────────┘
│
▼
shape: (7, 4, 8)
│
▼
┌────────────────────────────────────┐
│ 2层 GRU │
│ nn.GRU(input=8, hidden=16, layers=2)│
└────────────────────────────────────┘
│
├───────────────► output(所有时间步)
│ shape: (7, 4, 16)
│
▼
state(最终隐藏状态)
shape: (2, 4, 16)
从时间角度理解
时间步 t=1 t=2 t=3 ... t=7
│ │ │ │
▼ ▼ ▼ ▼
[x1] → GRU → [h1]
[x2] → GRU → [h2]
[x3] → GRU → [h3]
...
[x7] → GRU → [h7]
最终:
output = [h1, h2, ..., h7]
state = 最后一层在 t=7 的隐藏状态(2层叠加)
输入张量
#tensor([[0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0]])
X = torch.zeros((4, 7), dtype=torch.long)
编码器结构
# 构造编码器:
# - 词表大小 10
# - 词向量维度 8
# - GRU 隐藏单元 16
# - GRU 层数 2
encoder = Seq2SeqEncoder(vocab_size=10, embed_size=8, num_hiddens=16,
num_layers=2, debug=True)
| 参数 | 含义 |
|---|---|
| embed_size | 每个 token 映射成 8 维向量 |
| num_hiddens | GRU 隐状态维度 = 16 |
| num_layers | 2 层 GRU |
前向传播流程
embedding
X = self.embedding(X)
打印结果: (4, 7) → (4, 7, 8)
[Encoder] embedding 后 X.shape=(4, 7, 8)
[Encoder] embedding 后 X=tensor([
[[ 0.4160, 1.1911, -0.9811, -0.3494, 1.4416, -0.9053, -1.8197, 0.3652],
[ 0.4160, 1.1911, -0.9811, -0.3494, 1.4416, -0.9053, -1.8197, 0.3652],
[ 0.4160, 1.1911, -0.9811, -0.3494, 1.4416, -0.9053, -1.8197, 0.3652],
[ 0.4160, 1.1911, -0.9811, -0.3494, 1.4416, -0.9053, -1.8197, 0.3652],
[ 0.4160, 1.1911, -0.9811, -0.3494, 1.4416, -0.9053, -1.8197, 0.3652],
[ 0.4160, 1.1911, -0.9811, -0.3494, 1.4416, -0.9053, -1.8197, 0.3652],
[ 0.4160, 1.1911, -0.9811, -0.3494, 1.4416, -0.9053, -1.8197, 0.3652]],
[[ 0.4160, 1.1911, -0.9811, -0.3494, 1.4416, -0.9053, -1.8197, 0.3652],
[ 0.4160, 1.1911, -0.9811, -0.3494, 1.4416, -0.9053, -1.8197, 0.3652],
[ 0.4160, 1.1911, -0.9811, -0.3494, 1.4416, -0.9053, -1.8197, 0.3652],
[ 0.4160, 1.1911, -0.9811, -0.3494, 1.4416, -0.9053, -1.8197, 0.3652],
[ 0.4160, 1.1911, -0.9811, -0.3494, 1.4416, -0.9053, -1.8197, 0.3652],
[ 0.4160, 1.1911, -0.9811, -0.3494, 1.4416, -0.9053, -1.8197, 0.3652],
[ 0.4160, 1.1911, -0.9811, -0.3494, 1.4416, -0.9053, -1.8197, 0.3652]],
[[ 0.4160, 1.1911, -0.9811, -0.3494, 1.4416, -0.9053, -1.8197, 0.3652],
[ 0.4160, 1.1911, -0.9811, -0.3494, 1.4416, -0.9053, -1.8197, 0.3652],
[ 0.4160, 1.1911, -0.9811, -0.3494, 1.4416, -0.9053, -1.8197, 0.3652],
[ 0.4160, 1.1911, -0.9811, -0.3494, 1.4416, -0.9053, -1.8197, 0.3652],
[ 0.4160, 1.1911, -0.9811, -0.3494, 1.4416, -0.9053, -1.8197, 0.3652],
[ 0.4160, 1.1911, -0.9811, -0.3494, 1.4416, -0.9053, -1.8197, 0.3652],
[ 0.4160, 1.1911, -0.9811, -0.3494, 1.4416, -0.9053, -1.8197, 0.3652]],
[[ 0.4160, 1.1911, -0.9811, -0.3494, 1.4416, -0.9053, -1.8197, 0.3652],
[ 0.4160, 1.1911, -0.9811, -0.3494, 1.4416, -0.9053, -1.8197, 0.3652],
[ 0.4160, 1.1911, -0.9811, -0.3494, 1.4416, -0.9053, -1.8197, 0.3652],
[ 0.4160, 1.1911, -0.9811, -0.3494, 1.4416, -0.9053, -1.8197, 0.3652],
[ 0.4160, 1.1911, -0.9811, -0.3494, 1.4416, -0.9053, -1.8197, 0.3652],
[ 0.4160, 1.1911, -0.9811, -0.3494, 1.4416, -0.9053, -1.8197, 0.3652],
[ 0.4160, 1.1911, -0.9811, -0.3494, 1.4416, -0.9053, -1.8197, 0.3652]],
], grad_fn=<EmbeddingBackward0>)
每一行就是一个词的向量
对比理解: Embedding ≠ One-hot
One-hot:
3 → [0,0,0,1,0,0,...] ❌ 稀疏、无语义
Embedding:
3 → [0.12, -0.7, ...] ✅ 稠密、有语义
Embedding = 用输入 token 的索引,从一个可学习矩阵中“取一行向量”
问题: Embedding 的“可学习矩阵”到底从哪来?
每次运行向量不一样,是因为 Embedding(以及 GRU)参数是随机初始化的,也是需要后续训练的参数的一部分
Embedding 向量 不是中间结果,而是最终结果的一部分
调整维度(RNN 要求 time-first)
X = X.permute(1, 0, 2)
变成:
(7, 4, 8)
👉 含义:
7 = 时间步
4 = batch
8 = embedding
[Encoder] permute 后 X.shape=(7, 4, 8)
[Encoder] permute 后 X=tensor([
[[ 0.4160, 1.1911, -0.9811, -0.3494, 1.4416, -0.9053, -1.8197, 0.3652],
[ 0.4160, 1.1911, -0.9811, -0.3494, 1.4416, -0.9053, -1.8197, 0.3652],
[ 0.4160, 1.1911, -0.9811, -0.3494, 1.4416, -0.9053, -1.8197, 0.3652],
[ 0.4160, 1.1911, -0.9811, -0.3494, 1.4416, -0.9053, -1.8197, 0.3652]],
[[ 0.4160, 1.1911, -0.9811, -0.3494, 1.4416, -0.9053, -1.8197, 0.3652],
[ 0.4160, 1.1911, -0.9811, -0.3494, 1.4416, -0.9053, -1.8197, 0.3652],
[ 0.4160, 1.1911, -0.9811, -0.3494, 1.4416, -0.9053, -1.8197, 0.3652],
[ 0.4160, 1.1911, -0.9811, -0.3494, 1.4416, -0.9053, -1.8197, 0.3652]],
[[ 0.4160, 1.1911, -0.9811, -0.3494, 1.4416, -0.9053, -1.8197, 0.3652],
[ 0.4160, 1.1911, -0.9811, -0.3494, 1.4416, -0.9053, -1.8197, 0.3652],
[ 0.4160, 1.1911, -0.9811, -0.3494, 1.4416, -0.9053, -1.8197, 0.3652],
[ 0.4160, 1.1911, -0.9811, -0.3494, 1.4416, -0.9053, -1.8197, 0.3652]],
[[ 0.4160, 1.1911, -0.9811, -0.3494, 1.4416, -0.9053, -1.8197, 0.3652],
[ 0.4160, 1.1911, -0.9811, -0.3494, 1.4416, -0.9053, -1.8197, 0.3652],
[ 0.4160, 1.1911, -0.9811, -0.3494, 1.4416, -0.9053, -1.8197, 0.3652],
[ 0.4160, 1.1911, -0.9811, -0.3494, 1.4416, -0.9053, -1.8197, 0.3652]],
[[ 0.4160, 1.1911, -0.9811, -0.3494, 1.4416, -0.9053, -1.8197, 0.3652],
[ 0.4160, 1.1911, -0.9811, -0.3494, 1.4416, -0.9053, -1.8197, 0.3652],
[ 0.4160, 1.1911, -0.9811, -0.3494, 1.4416, -0.9053, -1.8197, 0.3652],
[ 0.4160, 1.1911, -0.9811, -0.3494, 1.4416, -0.9053, -1.8197, 0.3652]],
[[ 0.4160, 1.1911, -0.9811, -0.3494, 1.4416, -0.9053, -1.8197, 0.3652],
[ 0.4160, 1.1911, -0.9811, -0.3494, 1.4416, -0.9053, -1.8197, 0.3652],
[ 0.4160, 1.1911, -0.9811, -0.3494, 1.4416, -0.9053, -1.8197, 0.3652],
[ 0.4160, 1.1911, -0.9811, -0.3494, 1.4416, -0.9053, -1.8197, 0.3652]],
[[ 0.4160, 1.1911, -0.9811, -0.3494, 1.4416, -0.9053, -1.8197, 0.3652],
[ 0.4160, 1.1911, -0.9811, -0.3494, 1.4416, -0.9053, -1.8197, 0.3652],
[ 0.4160, 1.1911, -0.9811, -0.3494, 1.4416, -0.9053, -1.8197, 0.3652],
[ 0.4160, 1.1911, -0.9811, -0.3494, 1.4416, -0.9053, -1.8197, 0.3652]],
], grad_fn=<PermuteBackward0>)
GRU 计算
output, state = self.rnn(X)
GRU 输出:
✅ output
(num_steps, batch_size, num_hiddens)
= (7, 4, 16)
✅ state
(num_layers, batch_size, num_hiddens)
= (2, 4, 16)
可以这样理解:
output:每个时间步的隐藏状态(给 decoder 用)state:最后时间步的隐藏状态(作为 decoder 初始状态)
output
[Encoder] rnn 输出 output.shape=(7, 4, 16)
[Demo] output=(tensor([
[-0.0236, 0.1877, 0.0662, -0.0647, -0.0482, -0.0511, 0.0052, 0.0800, -0.0745, -0.0314, 0.2072, 0.1498, 0.0800, 0.0179, -0.1044, -0.1116],
[-0.0236, 0.1877, 0.0662, -0.0647, -0.0482, -0.0511, 0.0052, 0.0800, -0.0745, -0.0314, 0.2072, 0.1498, 0.0800, 0.0179, -0.1044, -0.1116],
[-0.0236, 0.1877, 0.0662, -0.0647, -0.0482, -0.0511, 0.0052, 0.0800, -0.0745, -0.0314, 0.2072, 0.1498, 0.0800, 0.0179, -0.1044, -0.1116],
[-0.0236, 0.1877, 0.0662, -0.0647, -0.0482, -0.0511, 0.0052, 0.0800, -0.0745, -0.0314, 0.2072, 0.1498, 0.0800, 0.0179, -0.1044, -0.1116]],
grad_fn=<UnbindBackward0>), tensor([
[-0.0525, 0.2612, 0.1025, -0.1118, -0.0927, -0.0716, 0.0100, 0.1395, -0.1254, -0.0348, 0.3323, 0.2252, 0.1555, -0.0010, -0.1413, -0.1684],
[-0.0525, 0.2612, 0.1025, -0.1118, -0.0927, -0.0716, 0.0100, 0.1395, -0.1254, -0.0348, 0.3323, 0.2252, 0.1555, -0.0010, -0.1413, -0.1684],
[-0.0525, 0.2612, 0.1025, -0.1118, -0.0927, -0.0716, 0.0100, 0.1395, -0.1254, -0.0348, 0.3323, 0.2252, 0.1555, -0.0010, -0.1413, -0.1684],
[-0.0525, 0.2612, 0.1025, -0.1118, -0.0927, -0.0716, 0.0100, 0.1395, -0.1254, -0.0348, 0.3323, 0.2252, 0.1555, -0.0010, -0.1413, -0.1684]],
grad_fn=<UnbindBackward0>), tensor([
[-0.0795, 0.2863, 0.1141, -0.1420, -0.1259, -0.0823, 0.0195, 0.1781, -0.1524, -0.0294, 0.4067, 0.2605, 0.2116, -0.0260, -0.1516, -0.2031],
[-0.0795, 0.2863, 0.1141, -0.1420, -0.1259, -0.0823, 0.0195, 0.1781, -0.1524, -0.0294, 0.4067, 0.2605, 0.2116, -0.0260, -0.1516, -0.2031],
[-0.0795, 0.2863, 0.1141, -0.1420, -0.1259, -0.0823, 0.0195, 0.1781, -0.1524, -0.0294, 0.4067, 0.2605, 0.2116, -0.0260, -0.1516, -0.2031],
[-0.0795, 0.2863, 0.1141, -0.1420, -0.1259, -0.0823, 0.0195, 0.1781, -0.1524, -0.0294, 0.4067, 0.2605, 0.2116, -0.0260, -0.1516, -0.2031]],
grad_fn=<UnbindBackward0>), tensor([
[-0.1037, 0.2929, 0.1129, -0.1607, -0.1483, -0.0904, 0.0326, 0.1990, -0.1629, -0.0234, 0.4502, 0.2770, 0.2496, -0.0470, -0.1533, -0.2251],
[-0.1037, 0.2929, 0.1129, -0.1607, -0.1483, -0.0904, 0.0326, 0.1990, -0.1629, -0.0234, 0.4502, 0.2770, 0.2496, -0.0470, -0.1533, -0.2251],
[-0.1037, 0.2929, 0.1129, -0.1607, -0.1483, -0.0904, 0.0326, 0.1990, -0.1629, -0.0234, 0.4502, 0.2770, 0.2496, -0.0470, -0.1533, -0.2251],
[-0.1037, 0.2929, 0.1129, -0.1607, -0.1483, -0.0904, 0.0326, 0.1990, -0.1629, -0.0234, 0.4502, 0.2770, 0.2496, -0.0470, -0.1533, -0.2251]],
grad_fn=<UnbindBackward0>), tensor([
[-0.1250, 0.2933, 0.1068, -0.1719, -0.1626, -0.0976, 0.0470, 0.2073, -0.1638, -0.0191, 0.4752, 0.2857, 0.2739, -0.0617, -0.1531, -0.2384],
[-0.1250, 0.2933, 0.1068, -0.1719, -0.1626, -0.0976, 0.0470, 0.2073, -0.1638, -0.0191, 0.4752, 0.2857, 0.2739, -0.0617, -0.1531, -0.2384],
[-0.1250, 0.2933, 0.1068, -0.1719, -0.1626, -0.0976, 0.0470, 0.2073, -0.1638, -0.0191, 0.4752, 0.2857, 0.2739, -0.0617, -0.1531, -0.2384],
[-0.1250, 0.2933, 0.1068, -0.1719, -0.1626, -0.0976, 0.0470, 0.2073, -0.1638, -0.0191, 0.4752, 0.2857, 0.2739, -0.0617, -0.1531, -0.2384]],
grad_fn=<UnbindBackward0>), tensor([
[-0.1431, 0.2921, 0.0997, -0.1783, -0.1718, -0.1041, 0.0612, 0.2080, -0.1596, -0.0163, 0.4891, 0.2913, 0.2885, -0.0712, -0.1531, -0.2457],
[-0.1431, 0.2921, 0.0997, -0.1783, -0.1718, -0.1041, 0.0612, 0.2080, -0.1596, -0.0163, 0.4891, 0.2913, 0.2885, -0.0712, -0.1531, -0.2457],
[-0.1431, 0.2921, 0.0997, -0.1783, -0.1718, -0.1041, 0.0612, 0.2080, -0.1596, -0.0163, 0.4891, 0.2913, 0.2885, -0.0712, -0.1531, -0.2457],
[-0.1431, 0.2921, 0.0997, -0.1783, -0.1718, -0.1041, 0.0612, 0.2080, -0.1596, -0.0163, 0.4891, 0.2913, 0.2885, -0.0712, -0.1531, -0.2457]],
grad_fn=<UnbindBackward0>), tensor([
[-0.1580, 0.2910, 0.0932, -0.1819, -0.1776, -0.1098, 0.0743, 0.2047, -0.1532, -0.0147, 0.4968, 0.2957, 0.2969, -0.0769, -0.1538, -0.2490],
[-0.1580, 0.2910, 0.0932, -0.1819, -0.1776, -0.1098, 0.0743, 0.2047, -0.1532, -0.0147, 0.4968, 0.2957, 0.2969, -0.0769, -0.1538, -0.2490],
[-0.1580, 0.2910, 0.0932, -0.1819, -0.1776, -0.1098, 0.0743, 0.2047, -0.1532, -0.0147, 0.4968, 0.2957, 0.2969, -0.0769, -0.1538, -0.2490],
[-0.1580, 0.2910, 0.0932, -0.1819, -0.1776, -0.1098, 0.0743, 0.2047, -0.1532, -0.0147, 0.4968, 0.2957, 0.2969, -0.0769, -0.1538, -0.2490]],
grad_fn=<UnbindBackward0>))
state
[Encoder] rnn 状态 state.shape=(2, 4, 16)
[Demo] state=(tensor([
[-0.2154, 0.1165, -0.2751, 0.1667, 0.4371, 0.2799, -0.3493, 0.0275, 0.1770, 0.0970, 0.8201, 0.1360, 0.6204, 0.5961, -0.6999, -0.1018],
[-0.2154, 0.1165, -0.2751, 0.1667, 0.4371, 0.2799, -0.3493, 0.0275, 0.1770, 0.0970, 0.8201, 0.1360, 0.6204, 0.5961, -0.6999, -0.1018],
[-0.2154, 0.1165, -0.2751, 0.1667, 0.4371, 0.2799, -0.3493, 0.0275, 0.1770, 0.0970, 0.8201, 0.1360, 0.6204, 0.5961, -0.6999, -0.1018],
[-0.2154, 0.1165, -0.2751, 0.1667, 0.4371, 0.2799, -0.3493, 0.0275, 0.1770, 0.0970, 0.8201, 0.1360, 0.6204, 0.5961, -0.6999, -0.1018]],
grad_fn=<UnbindBackward0>), tensor([
[-0.1580, 0.2910, 0.0932, -0.1819, -0.1776, -0.1098, 0.0743, 0.2047, -0.1532, -0.0147, 0.4968, 0.2957, 0.2969, -0.0769, -0.1538, -0.2490],
[-0.1580, 0.2910, 0.0932, -0.1819, -0.1776, -0.1098, 0.0743, 0.2047, -0.1532, -0.0147, 0.4968, 0.2957, 0.2969, -0.0769, -0.1538, -0.2490],
[-0.1580, 0.2910, 0.0932, -0.1819, -0.1776, -0.1098, 0.0743, 0.2047, -0.1532, -0.0147, 0.4968, 0.2957, 0.2969, -0.0769, -0.1538, -0.2490],
[-0.1580, 0.2910, 0.0932, -0.1819, -0.1776, -0.1098, 0.0743, 0.2047, -0.1532, -0.0147, 0.4968, 0.2957, 0.2969, -0.0769, -0.1538, -0.2490]],
grad_fn=<UnbindBackward0>))
多层 GRU 内部(再拆一层)
第1层 GRU
x_t ───────────────► h_t^(1)
│
▼
第2层 GRU
───────► h_t^(2)
👉 所以:
- output = 最后一层(第2层)的所有时间步输出
- state = 每一层最后一个时间步的状态
state:
[
layer1_final (4,16),
layer2_final (4,16)
]
→ shape (2,4,16)
这个编码器就是做了一件事:
把一整个输入序列压缩成“时间序列特征 + 最终语义状态”
output 👉 保留每个时间步信息(给 attention 用) state 👉 压缩语义(给 decoder 初始化)
解码器
class Seq2SeqDecoder(d2l.Decoder):
"""用于序列到序列学习的循环神经网络解码器"""
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, debug=False, **kwargs):
super(Seq2SeqDecoder, self).__init__(**kwargs)
# debug=True 时打印解码阶段关键中间结果
self.debug = debug
# 词嵌入层:把解码器输入 token id 映射到 embed 向量
self.embedding = nn.Embedding(vocab_size, embed_size)
# 这里的 GRU 输入维度 = embed_size + num_hiddens
# 原因:每个时间步都把“当前输入词向量”和“编码器上下文向量”拼接后再送入 GRU
self.rnn = nn.GRU(embed_size + num_hiddens, num_hiddens, num_layers,
dropout=dropout)
# 把 GRU 隐状态投影到词表大小,得到每个词的打分(logits)
self.dense = nn.Linear(num_hiddens, vocab_size)
def init_state(self, enc_outputs, *args):
# enc_outputs = (encoder_output, encoder_state)
# 这里直接使用编码器最后时刻的各层隐状态作为解码器初始状态
if self.debug:
print(f"[Decoder] init_state: enc_output.shape={tuple(enc_outputs[0].shape)}")
print(f"[Decoder] init_state: enc_state.shape={tuple(enc_outputs[1].shape)}")
return enc_outputs[1]
def forward(self, X, state):
# X: 解码器输入 token id,形状 (batch_size, num_steps)
# state: 当前隐状态,形状 (num_layers, batch_size, num_hiddens)
if self.debug:
print(f"[Decoder] 输入 X.shape={tuple(X.shape)}, dtype={X.dtype}")
print(f"[Decoder] 输入 state.shape={tuple(state.shape)}")
# embedding + permute 后:
# (batch_size, num_steps, embed_size) -> (num_steps, batch_size, embed_size)
X = self.embedding(X).permute(1, 0, 2)
if self.debug:
print(f"[Decoder] embedding+permute 后 X.shape={tuple(X.shape)}")
print(f"[Decoder] embedding+permute 后 X={X}")
# 广播context,使其具有与X相同的num_steps
# state[-1] 取“最后一层”在当前时刻的隐状态,形状 (batch_size, num_hiddens)
# repeat 后变成 (num_steps, batch_size, num_hiddens),让每个时间步都能看到同一份上下文
context = state[-1].repeat(X.shape[0], 1, 1)
if self.debug:
print(f"[Decoder] context.shape={tuple(context.shape)}")
print(f"[Decoder] context={context}")
# 在特征维拼接:得到每个时间步输入 GRU 的最终向量
# 形状 (num_steps, batch_size, embed_size + num_hiddens)
X_and_context = torch.cat((X, context), 2)
if self.debug:
print(f"[Decoder] X_and_context.shape={tuple(X_and_context.shape)}")
# GRU 输出:
# output: (num_steps, batch_size, num_hiddens)
# state : (num_layers, batch_size, num_hiddens)
output, state = self.rnn(X_and_context, state)
if self.debug:
print(f"[Decoder] rnn 输出 output.shape={tuple(output.shape)}")
print(f"[Decoder] rnn 新 state.shape={tuple(state.shape)}")
# 线性层映射到词表维度,并转换回 batch_first
# (num_steps, batch_size, vocab_size) -> (batch_size, num_steps, vocab_size)
output = self.dense(output).permute(1, 0, 2)
if self.debug:
print(f"[Decoder] dense+permute 后 output.shape={tuple(output.shape)}")
print(f"[Decoder] dense+permute 后 output={output}")
# output的形状:(batch_size,num_steps,vocab_size)
# state的形状:(num_layers,batch_size,num_hiddens)
return output, state
decoder = Seq2SeqDecoder(vocab_size=10, embed_size=8, num_hiddens=16,
num_layers=2, debug=True)
decoder.eval()
state = decoder.init_state(encoder(X))
output, state = decoder(X, state)
output.shape, state.shape
print(f"[Demo-Decoder] output.shape={tuple(output.shape)}")
print(f"[Demo-Decoder] state.shape={tuple(state.shape)}")
解码器理解
Decoder 输入 X
(batch, steps)
│
▼
Embedding
│
▼
permute → (steps, batch, embed)
│
▼
拼接 context(来自 encoder)
│
▼
GRU
│
▼
Linear → vocab logits
│
▼
输出预测
初始化 state
state = decoder.init_state(encoder(X))
含义: 用 encoder 的“最终语义”作为 decoder 初始状态
Decoder 输入 X
output, state = decoder(X, state)
👉 这里你用了 同一个 X(全 0)作为 decoder 输入
Embedding + permute
X = self.embedding(X).permute(1, 0, 2)
向量打印
(4,7) → (4,7,8) → (7,4,8)
[Decoder] embedding+permute 后 X.shape=(7, 4, 8)
[Decoder] embedding+permute 后 X=tensor([
[[ 0.8416, 0.8881, 0.0107, 1.3648, 0.0850, 0.2285, 0.3195, -0.9791],
[ 0.8416, 0.8881, 0.0107, 1.3648, 0.0850, 0.2285, 0.3195, -0.9791],
[ 0.8416, 0.8881, 0.0107, 1.3648, 0.0850, 0.2285, 0.3195, -0.9791],
[ 0.8416, 0.8881, 0.0107, 1.3648, 0.0850, 0.2285, 0.3195, -0.9791]],
[[ 0.8416, 0.8881, 0.0107, 1.3648, 0.0850, 0.2285, 0.3195, -0.9791],
[ 0.8416, 0.8881, 0.0107, 1.3648, 0.0850, 0.2285, 0.3195, -0.9791],
[ 0.8416, 0.8881, 0.0107, 1.3648, 0.0850, 0.2285, 0.3195, -0.9791],
[ 0.8416, 0.8881, 0.0107, 1.3648, 0.0850, 0.2285, 0.3195, -0.9791]],
[[ 0.8416, 0.8881, 0.0107, 1.3648, 0.0850, 0.2285, 0.3195, -0.9791],
[ 0.8416, 0.8881, 0.0107, 1.3648, 0.0850, 0.2285, 0.3195, -0.9791],
[ 0.8416, 0.8881, 0.0107, 1.3648, 0.0850, 0.2285, 0.3195, -0.9791],
[ 0.8416, 0.8881, 0.0107, 1.3648, 0.0850, 0.2285, 0.3195, -0.9791]],
[[ 0.8416, 0.8881, 0.0107, 1.3648, 0.0850, 0.2285, 0.3195, -0.9791],
[ 0.8416, 0.8881, 0.0107, 1.3648, 0.0850, 0.2285, 0.3195, -0.9791],
[ 0.8416, 0.8881, 0.0107, 1.3648, 0.0850, 0.2285, 0.3195, -0.9791],
[ 0.8416, 0.8881, 0.0107, 1.3648, 0.0850, 0.2285, 0.3195, -0.9791]],
[[ 0.8416, 0.8881, 0.0107, 1.3648, 0.0850, 0.2285, 0.3195, -0.9791],
[ 0.8416, 0.8881, 0.0107, 1.3648, 0.0850, 0.2285, 0.3195, -0.9791],
[ 0.8416, 0.8881, 0.0107, 1.3648, 0.0850, 0.2285, 0.3195, -0.9791],
[ 0.8416, 0.8881, 0.0107, 1.3648, 0.0850, 0.2285, 0.3195, -0.9791]],
[[ 0.8416, 0.8881, 0.0107, 1.3648, 0.0850, 0.2285, 0.3195, -0.9791],
[ 0.8416, 0.8881, 0.0107, 1.3648, 0.0850, 0.2285, 0.3195, -0.9791],
[ 0.8416, 0.8881, 0.0107, 1.3648, 0.0850, 0.2285, 0.3195, -0.9791],
[ 0.8416, 0.8881, 0.0107, 1.3648, 0.0850, 0.2285, 0.3195, -0.9791]],
[[ 0.8416, 0.8881, 0.0107, 1.3648, 0.0850, 0.2285, 0.3195, -0.9791],
[ 0.8416, 0.8881, 0.0107, 1.3648, 0.0850, 0.2285, 0.3195, -0.9791],
[ 0.8416, 0.8881, 0.0107, 1.3648, 0.0850, 0.2285, 0.3195, -0.9791],
[ 0.8416, 0.8881, 0.0107, 1.3648, 0.0850, 0.2285, 0.3195, -0.9791]],
], grad_fn=<PermuteBackward0>)
构造 context(关键)
context = state[-1].repeat(X.shape[0], 1, 1)
理解
🧠 这一步非常重要
state[-1] → 最后一层隐藏状态
shape: (4,16)
repeat 后:
(7,4,16)
👉 含义:
每个时间步都能“看到整个句子的语义”
🔥 关键理解
这是经典 Seq2Seq 的设计:
👉 把 encoder 的信息“复制”给每个 decoder 时间步
拼接输入
X_and_context = torch.cat((X, context), 2)
理解
(7,4,8) + (7,4,16) → (7,4,24)
👉 每个时间步输入变成:
[当前词 embedding | 整句语义]
GRU
output, state = self.rnn(X_and_context, state)
👉 用上一时刻的“记忆”(state)和当前整段输入(X_and_context),逐时间步更新隐藏状态,并输出每一步的状态序列。
展开过程
t = 1:
输入: x1, 初始 state
→ 得到 s1
t = 2:
输入: x2, s1
→ 得到 s2
t = 3:
输入: x3, s2
→ 得到 s3
...
t = 7:
→ s7
output 是什么?
👉 含义: 每个时间步的“最终语义状态”
[Decoder] dense+permute 后 output.shape=(4, 7, 10)
[Decoder] dense+permute 后 output=tensor([
[[-0.0059, 0.2296, 0.1367, -0.0776, 0.1346, -0.2336, 0.1670, -0.1333, 0.3361, 0.0579],
[ 0.0417, 0.1731, 0.0774, -0.1337, 0.1210, -0.2458, 0.2758, -0.0720, 0.1629, -0.0412],
[ 0.0535, 0.1417, 0.0127, -0.1620, 0.1283, -0.2714, 0.3254, -0.0415, 0.0802, -0.0883],
[ 0.0534, 0.1221, -0.0391, -0.1761, 0.1368, -0.2950, 0.3468, -0.0263, 0.0412, -0.1094],
[ 0.0498, 0.1091, -0.0764, -0.1820, 0.1434, -0.3133, 0.3557, -0.0191, 0.0240, -0.1184],
[ 0.0459, 0.1003, -0.1018, -0.1834, 0.1483, -0.3266, 0.3592, -0.0163, 0.0180, -0.1221],
[ 0.0426, 0.0944, -0.1186, -0.1828, 0.1518, -0.3359, 0.3605, -0.0157, 0.0173, -0.1235]],
[[-0.0059, 0.2296, 0.1367, -0.0776, 0.1346, -0.2336, 0.1670, -0.1333, 0.3361, 0.0579],
[ 0.0417, 0.1731, 0.0774, -0.1337, 0.1210, -0.2458, 0.2758, -0.0720, 0.1629, -0.0412],
[ 0.0535, 0.1417, 0.0127, -0.1620, 0.1283, -0.2714, 0.3254, -0.0415, 0.0802, -0.0883],
[ 0.0534, 0.1221, -0.0391, -0.1761, 0.1368, -0.2950, 0.3468, -0.0263, 0.0412, -0.1094],
[ 0.0498, 0.1091, -0.0764, -0.1820, 0.1434, -0.3133, 0.3557, -0.0191, 0.0240, -0.1184],
[ 0.0459, 0.1003, -0.1018, -0.1834, 0.1483, -0.3266, 0.3592, -0.0163, 0.0180, -0.1221],
[ 0.0426, 0.0944, -0.1186, -0.1828, 0.1518, -0.3359, 0.3605, -0.0157, 0.0173, -0.1235]],
[[-0.0059, 0.2296, 0.1367, -0.0776, 0.1346, -0.2336, 0.1670, -0.1333, 0.3361, 0.0579],
[ 0.0417, 0.1731, 0.0774, -0.1337, 0.1210, -0.2458, 0.2758, -0.0720, 0.1629, -0.0412],
[ 0.0535, 0.1417, 0.0127, -0.1620, 0.1283, -0.2714, 0.3254, -0.0415, 0.0802, -0.0883],
[ 0.0534, 0.1221, -0.0391, -0.1761, 0.1368, -0.2950, 0.3468, -0.0263, 0.0412, -0.1094],
[ 0.0498, 0.1091, -0.0764, -0.1820, 0.1434, -0.3133, 0.3557, -0.0191, 0.0240, -0.1184],
[ 0.0459, 0.1003, -0.1018, -0.1834, 0.1483, -0.3266, 0.3592, -0.0163, 0.0180, -0.1221],
[ 0.0426, 0.0944, -0.1186, -0.1828, 0.1518, -0.3359, 0.3605, -0.0157, 0.0173, -0.1235]],
[[-0.0059, 0.2296, 0.1367, -0.0776, 0.1346, -0.2336, 0.1670, -0.1333, 0.3361, 0.0579],
[ 0.0417, 0.1731, 0.0774, -0.1337, 0.1210, -0.2458, 0.2758, -0.0720, 0.1629, -0.0412],
[ 0.0535, 0.1417, 0.0127, -0.1620, 0.1283, -0.2714, 0.3254, -0.0415, 0.0802, -0.0883],
[ 0.0534, 0.1221, -0.0391, -0.1761, 0.1368, -0.2950, 0.3468, -0.0263, 0.0412, -0.1094],
[ 0.0498, 0.1091, -0.0764, -0.1820, 0.1434, -0.3133, 0.3557, -0.0191, 0.0240, -0.1184],
[ 0.0459, 0.1003, -0.1018, -0.1834, 0.1483, -0.3266, 0.3592, -0.0163, 0.0180, -0.1221],
[ 0.0426, 0.0944, -0.1186, -0.1828, 0.1518, -0.3359, 0.3605, -0.0157, 0.0173, -0.1235]],
], grad_fn=<PermuteBackward0>)
state 是什么?
👉 含义:每一层在最后一个时间步的状态
展开:
state = [
第1层在 t=7 的状态,
第2层在 t=7 的状态
]
总结
这版模型的核心特点(非常重要)
context = 固定(state[-1])
所以:
所有时间步都用同一个“全局语义”
👉 这就是:
❗经典 Seq2Seq(无 Attention)
损失函数
X = torch.tensor([[1, 2, 3], [4, 5, 6]])
sequence_mask(X, torch.tensor([1, 2]))
#@save
class MaskedSoftmaxCELoss(nn.CrossEntropyLoss):
"""带遮蔽的softmax交叉熵损失函数"""
# pred的形状:(batch_size,num_steps,vocab_size)
# label的形状:(batch_size,num_steps)
# valid_len的形状:(batch_size,)
def forward(self, pred, label, valid_len):
weights = torch.ones_like(label)
weights = sequence_mask(weights, valid_len)
self.reduction='none'
unweighted_loss = super(MaskedSoftmaxCELoss, self).forward(
pred.permute(0, 2, 1), label)
weighted_loss = (unweighted_loss * weights).mean(dim=1)
return weighted_loss
loss = MaskedSoftmaxCELoss()
loss(torch.ones(3, 4, 10), torch.ones((3, 4), dtype=torch.long),
torch.tensor([4, 2, 0]))
👉 MaskedSoftmaxCELoss = 只对“真实 token”计算交叉熵损失
训练
# ======== 下面是训练函数的实现 ========
#@save
def train_seq2seq(net, data_iter, lr, num_epochs, tgt_vocab, device):
"""训练序列到序列模型"""
def xavier_init_weights(m):
# 线性层使用 Xavier 均匀初始化,帮助稳定前期训练
if type(m) == nn.Linear:
nn.init.xavier_uniform_(m.weight)
# GRU 内部包含多组权重参数,这里逐一做 Xavier 初始化
if type(m) == nn.GRU:
for param in m._flat_weights_names:
if "weight" in param:
nn.init.xavier_uniform_(m._parameters[param])
# 参数初始化 + 放到目标设备(CPU/GPU)
net.apply(xavier_init_weights)
net.to(device)
# Adam 优化器
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
# 使用“带 mask 的交叉熵”,避免 padding 干扰训练
loss = MaskedSoftmaxCELoss()
# 进入训练模式(启用 dropout 等训练时行为)
net.train()
# 可视化训练损失曲线
animator = d2l.Animator(xlabel='epoch', ylabel='loss',
xlim=[10, num_epochs])
for epoch in range(num_epochs):
# 计时器:统计本轮吞吐量
timer = d2l.Timer()
metric = d2l.Accumulator(2) # 训练损失总和,词元数量
for batch in data_iter:
# 清空上一步的梯度,避免梯度累积
optimizer.zero_grad()
# batch 解包并搬运到 device
# X: 源语言输入
# X_valid_len: 源语言有效长度
# Y: 目标语言标签
# Y_valid_len: 目标语言有效长度
X, X_valid_len, Y, Y_valid_len = [x.to(device) for x in batch]
# 构造解码器输入序列(教师强制):
# 在每条目标序列最前面拼接 <bos>,并去掉最后一个 token
bos = torch.tensor([tgt_vocab['<bos>']] * Y.shape[0],
device=device).reshape(-1, 1)
dec_input = torch.cat([bos, Y[:, :-1]], 1) # 强制教学
# 前向传播:得到每个时间步在词表上的预测分布
Y_hat, _ = net(X, dec_input, X_valid_len)
# 计算每个样本损失(已对 padding 做 mask)
l = loss(Y_hat, Y, Y_valid_len)
# 反向传播需要标量,这里把 batch 内样本损失求和
l.sum().backward() # 损失函数的标量进行“反向传播”
# 梯度裁剪,防止 RNN 中梯度爆炸
d2l.grad_clipping(net, 1)
# 本批次有效 token 数(用于后续算平均损失)
num_tokens = Y_valid_len.sum()
# 参数更新
optimizer.step()
with torch.no_grad():
# 累加“总损失”和“总 token 数”
metric.add(l.sum(), num_tokens)
# 每 10 轮更新一次损失曲线
if (epoch + 1) % 10 == 0:
animator.add(epoch + 1, (metric[0] / metric[1],))
# 打印最终平均损失与吞吐量(tokens/sec)
print(f'loss {metric[0] / metric[1]:.3f}, {metric[1] / timer.stop():.1f} '
f'tokens/sec on {str(device)}')
embed_size, num_hiddens, num_layers, dropout = 32, 32, 2, 0.1
batch_size, num_steps = 64, 10
lr, num_epochs, device = 0.005, 300, d2l.try_gpu()
train_iter, src_vocab, tgt_vocab = d2l.load_data_nmt(batch_size, num_steps)
encoder = Seq2SeqEncoder(len(src_vocab), embed_size, num_hiddens, num_layers,
dropout)
decoder = Seq2SeqDecoder(len(tgt_vocab), embed_size, num_hiddens, num_layers,
dropout)
net = d2l.EncoderDecoder(encoder, decoder)
train_seq2seq(net, train_iter, lr, num_epochs, tgt_vocab, device)
训练流程
一批数据 (X, Y)
│
▼
Encoder(理解原句)
│
▼
Decoder(逐词生成预测 Y_hat)
│
▼
Loss(对比 Y_hat 和真实 Y)
│
▼
Backward(算梯度)
│
▼
Optimizer(更新参数)
训练完成后参数结构图
┌──────────────────────────┐
│ Encoder │
└──────────────────────────┘
X (src sentence tokens)
│
▼
┌──────────────────────┐
│ Embedding (10 → 8) │
│ W_emb: [10 × 8] │ ← 参数①
└──────────────────────┘
│
▼
┌────────────────────────────────────────────┐
│ GRU Layer 1 │
│ W_xh: [8 × 3×16] │ ← 参数②
│ W_hh: [16 × 3×16] │
│ b: [3×16] │
├────────────────────────────────────────────┤
│ GRU Layer 2 │
│ W_xh: [16 × 3×16] │ ← 参数③
│ W_hh: [16 × 3×16] │
│ b: [3×16] │
└────────────────────────────────────────────┘
│
▼
Encoder State (context)
shape: [2 layers × batch × 16]
====================================================
┌──────────────────────────┐
│ Decoder │
└──────────────────────────┘
Y shifted (<bos> + previous tokens)
│
▼
┌──────────────────────┐
│ Embedding (10 → 8) │
│ W_emb: [10 × 8] │ ← 参数④
└──────────────────────┘
│
▼
concat(context from encoder)
│
▼
┌────────────────────────────────────────────┐
│ GRU Layer 1 │
│ input: 8 + 16 = 24 │
│ W_xh: [24 × 3×16] │ ← 参数⑤
│ W_hh: [16 × 3×16] │
│ b: [3×16] │
├────────────────────────────────────────────┤
│ GRU Layer 2 │
│ W_xh: [16 × 3×16] │ ← 参数⑥
│ W_hh: [16 × 3×16] │
│ b: [3×16] │
└────────────────────────────────────────────┘
│
▼
┌──────────────────────┐
│ Linear Layer │
│ W: [16 × 10] │ ← 参数⑦
│ b: [10] │
└──────────────────────┘
│
▼
Vocabulary distribution (softmax)
| 模块 | 参数 | 作用 |
|---|---|---|
| Encoder Embedding | 10×8 | 词语语义向量 |
| Encoder GRU | 多组矩阵 | 编码句子结构 |
| Decoder Embedding | 10×8 | 目标语言词向量 |
| Decoder GRU | 多组矩阵 | 生成句子逻辑 |
| Linear | 16×10 + 10 | 选词概率 |
神经网络图