优化和深度学习
优化的目标
| 概念 | 目标 |
|---|---|
| 优化(Optimization) | 降低训练误差 |
| 深度学习(ML目标) | 降低泛化误差 |
为什么深度学习必须用“数值优化”
现实情况:
- 深度学习模型参数:上百万甚至上亿
- 损失函数:高度非线性
👉 结果:
- 没有解析解(不能直接算)
- 只能靠迭代逼近
训练误差和泛化误差
泛化误差
↑
| ● 过拟合模型(训练误差低,但泛化差)
|
|
| ● 理想模型(泛化最好)
|
|
|● 欠拟合模型
+--------------------→ 训练误差(经验风险)
深度学习中的优化挑战
局部最小值(Local Minimum)
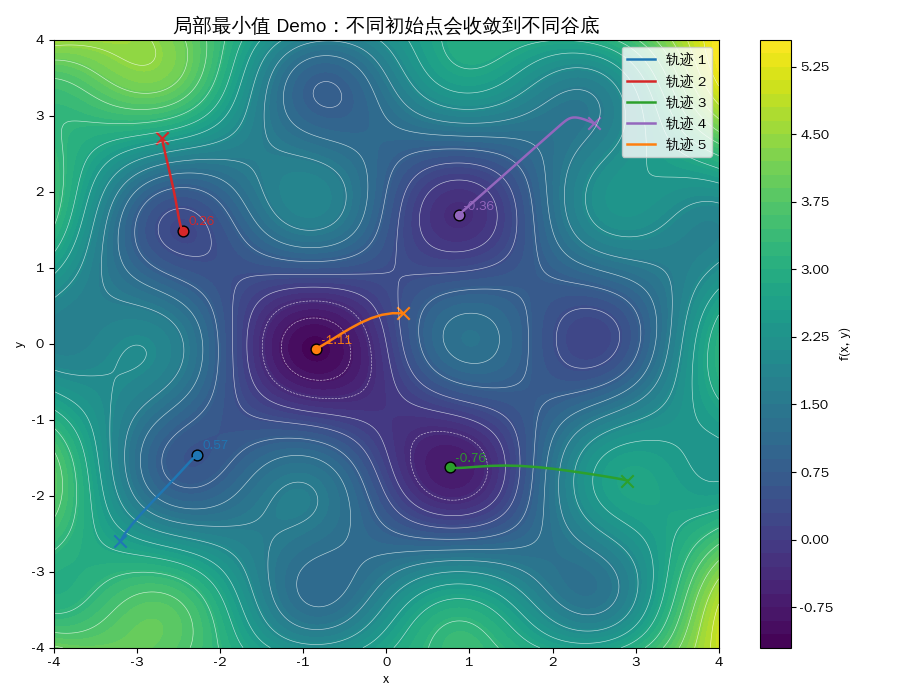
在深度学习中,局部最小值其实没那么可怕
在高维参数空间(比如 Transformer):
- 局部最小值很少
- 鞍点更多(更大的问题)
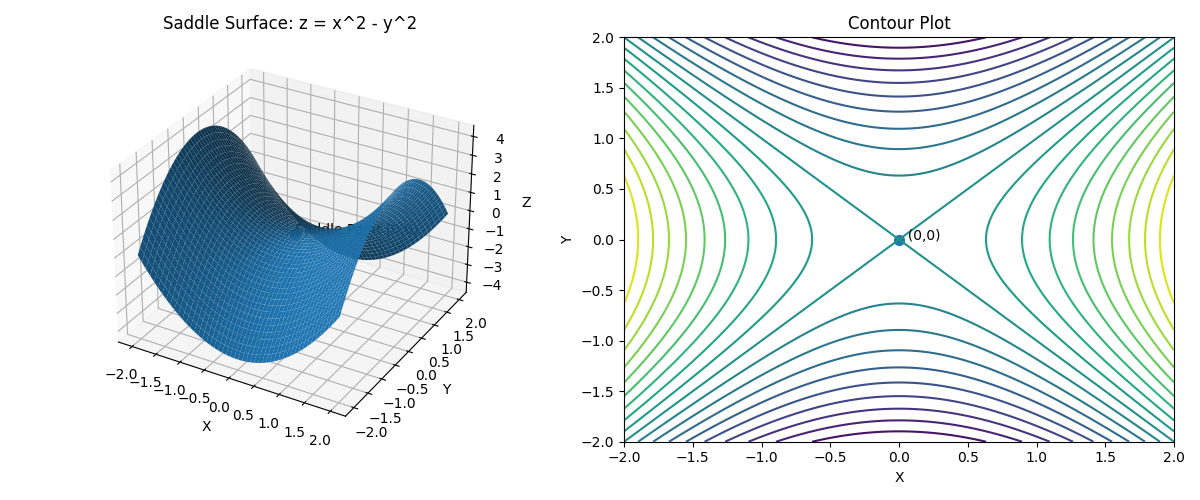
鞍点 (Saddle Point)
鞍点 = 梯度为 0,但其实还有路可以走的地方
| 特点 | 局部最小值 | 鞍点 |
|---|---|---|
| 梯度 | 0 | 0 |
| 是否最小 | 是(局部) | ❌ 不是 |
| 是否可继续下降 | ❌ 不行 | ✅ 可以 |
| 在深度学习中 | 较少 | 🔥 非常多 |
梯度消失
梯度消失就是:反向传播时信号在层层传递中不断变弱,最终导致前面网络“学不到东西”。
凸性
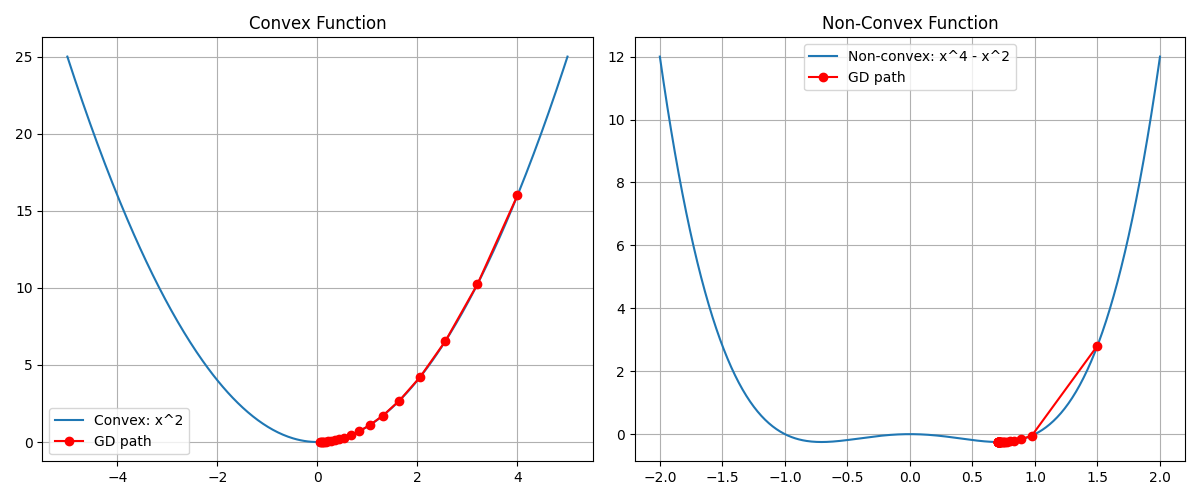
凸函数:
- 梯度下降 → 直接收敛到最低点
-
路径平滑稳定 非凸函数:
- 可能掉进“局部最小值”
- 甚至停在某个坑里不动
| 情况 | 结果 |
|---|---|
| 凸函数 | 平均值 ≥ 中间值(安全) |
| 非凸函数 | 平均可能更差(有坑) |
凸性 = 没有坑的地形;优化问题如果是凸的,梯度下降几乎就是“自动找到最优解”
约束优化
凸优化里最核心的思想之一:约束优化(constrained optimization)
如果约束是凸的,那么可行域也是“没有坑”的结构
✔ 凸约束的好处
- 任意两点连线仍在区域内
- 不会出现“断裂/坑洞”
👉 优化不会被困住
投影法(Projection)
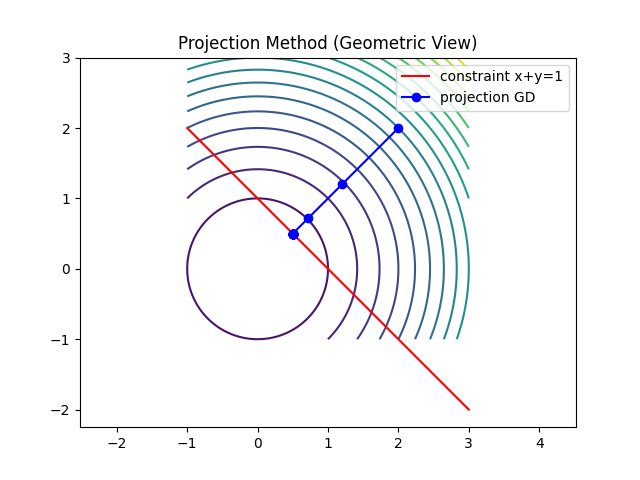
轨迹:
- 在区域内自由下降
- 一旦越界 → 直角“弹回”
拉格朗日法(Lagrangian)——“加一个隐形力场”
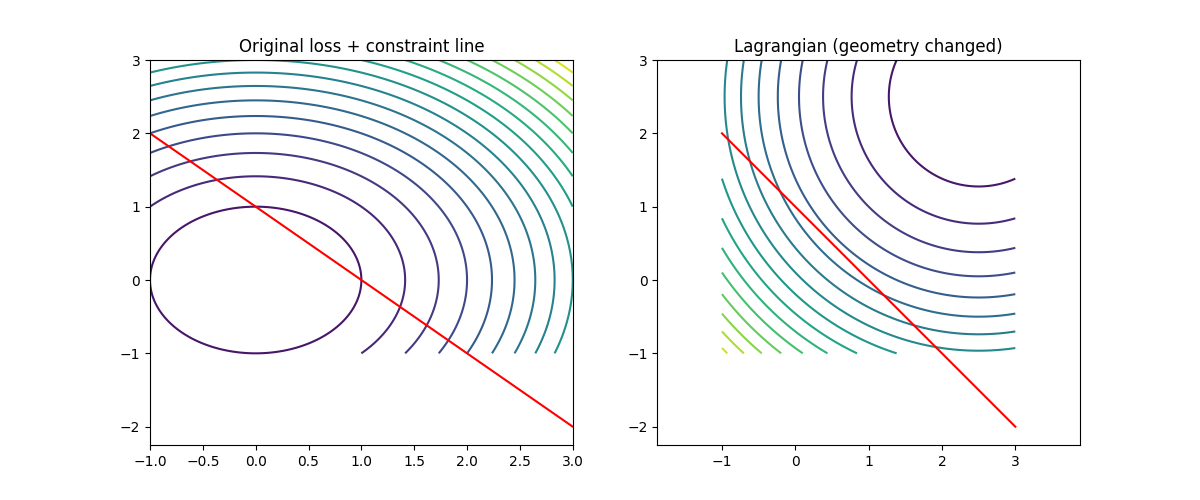
📌 几何效果
目标函数 + 约束变成“新地形” 最优点 = 梯度为0的点(含约束影响)
👉 你可以理解为:
“地形被改造了”
惩罚法(Penalty Method)——“违规就变贵”
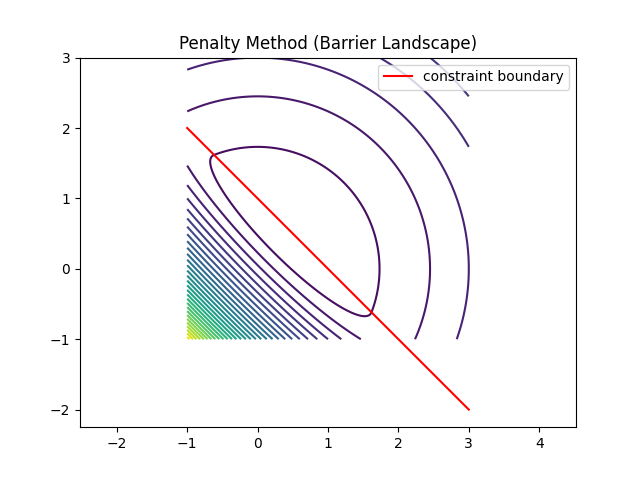
🎯 几何理解
不是改规则,而是:
❗ 违反约束 → loss 变大
📌 几何效果 可行域外:地形突然变高(惩罚墙) 优化器自动远离
总结
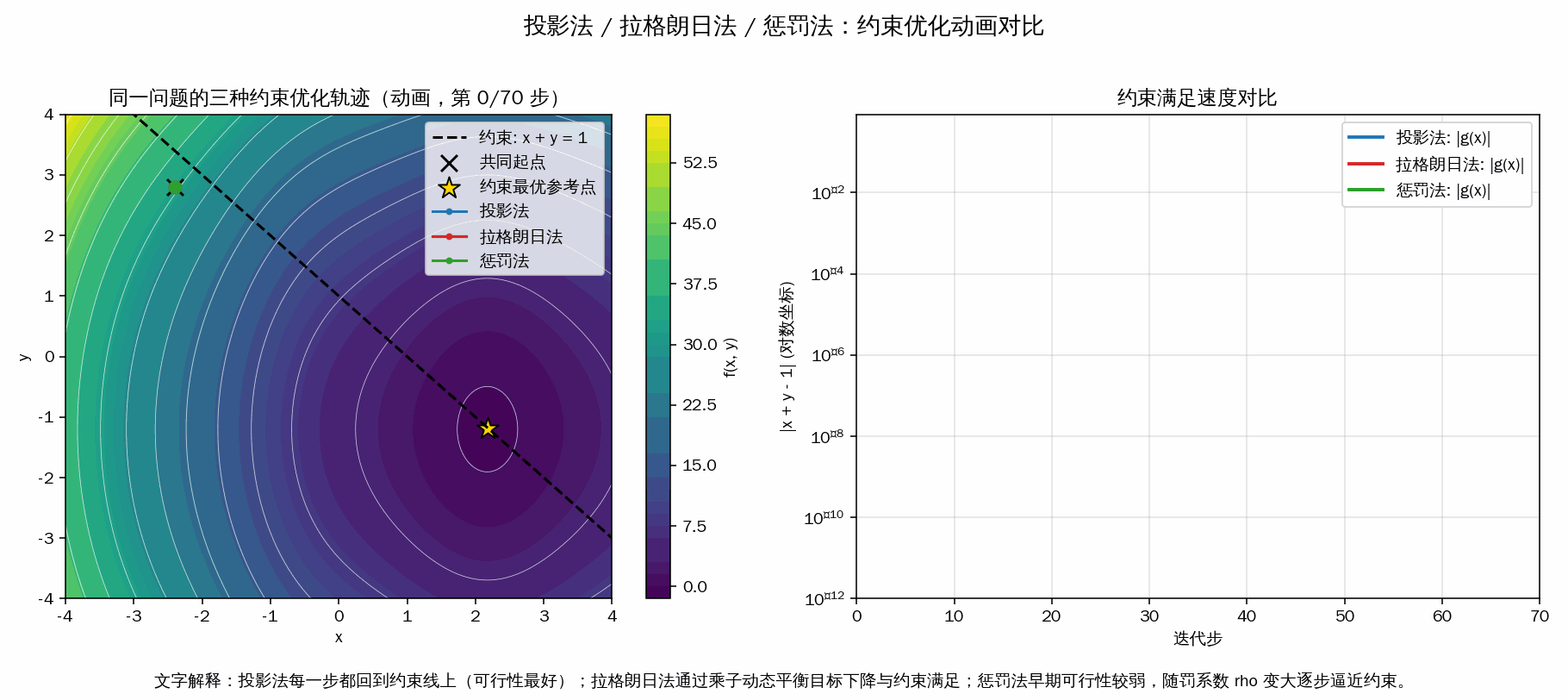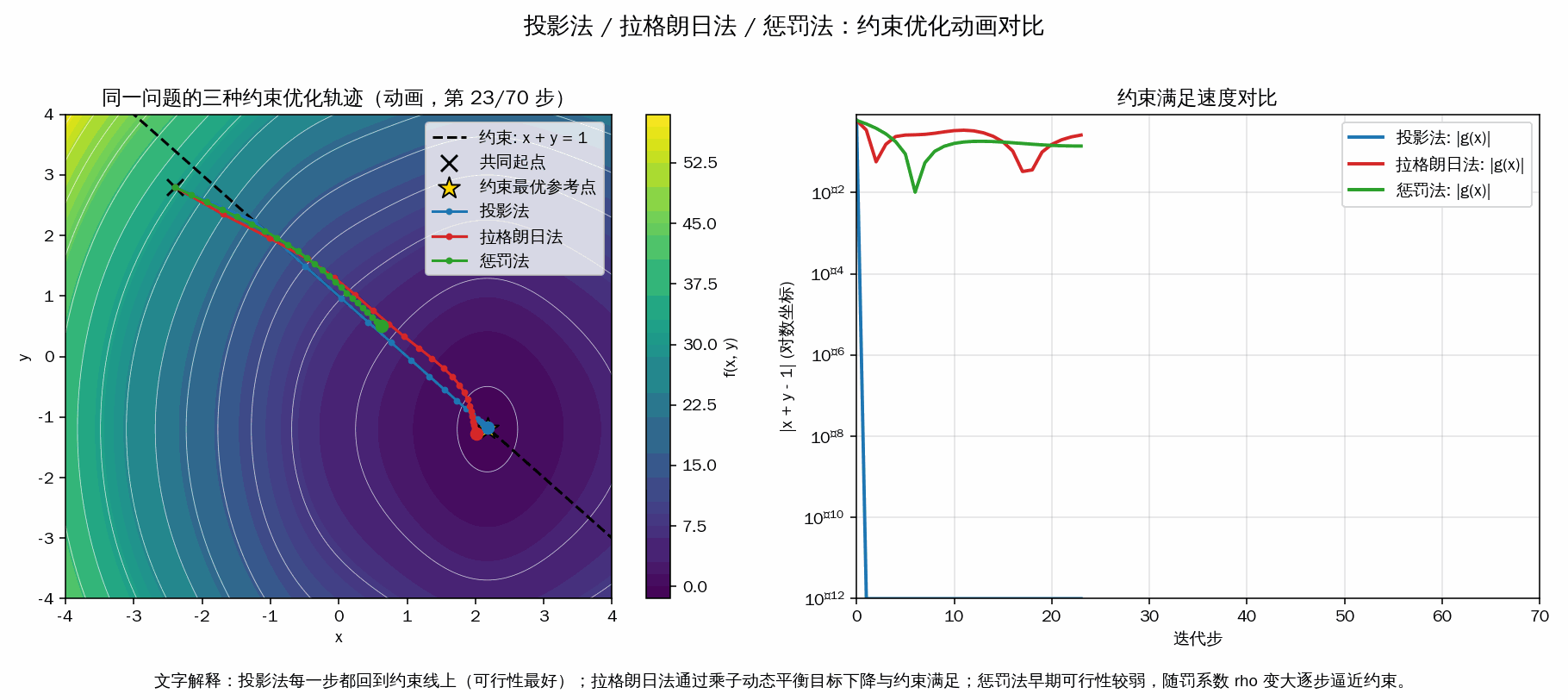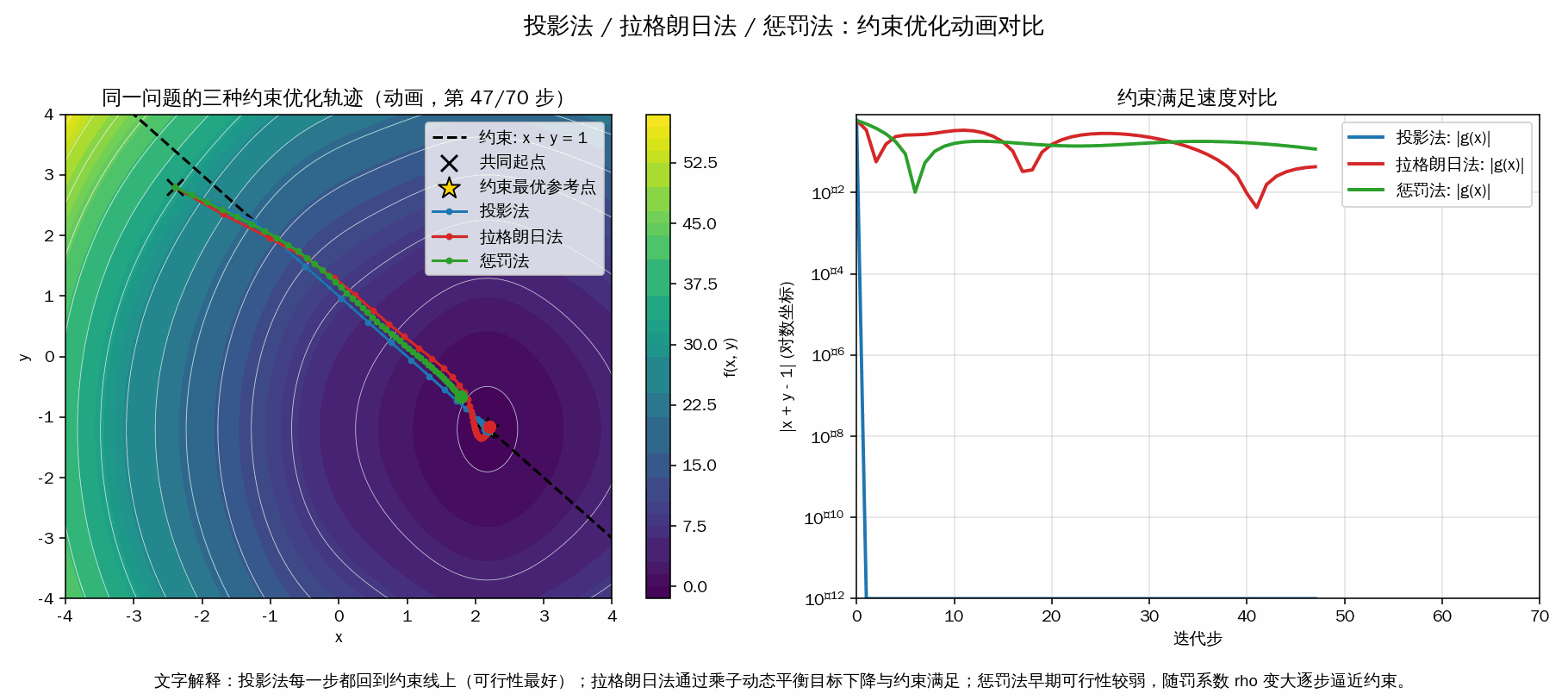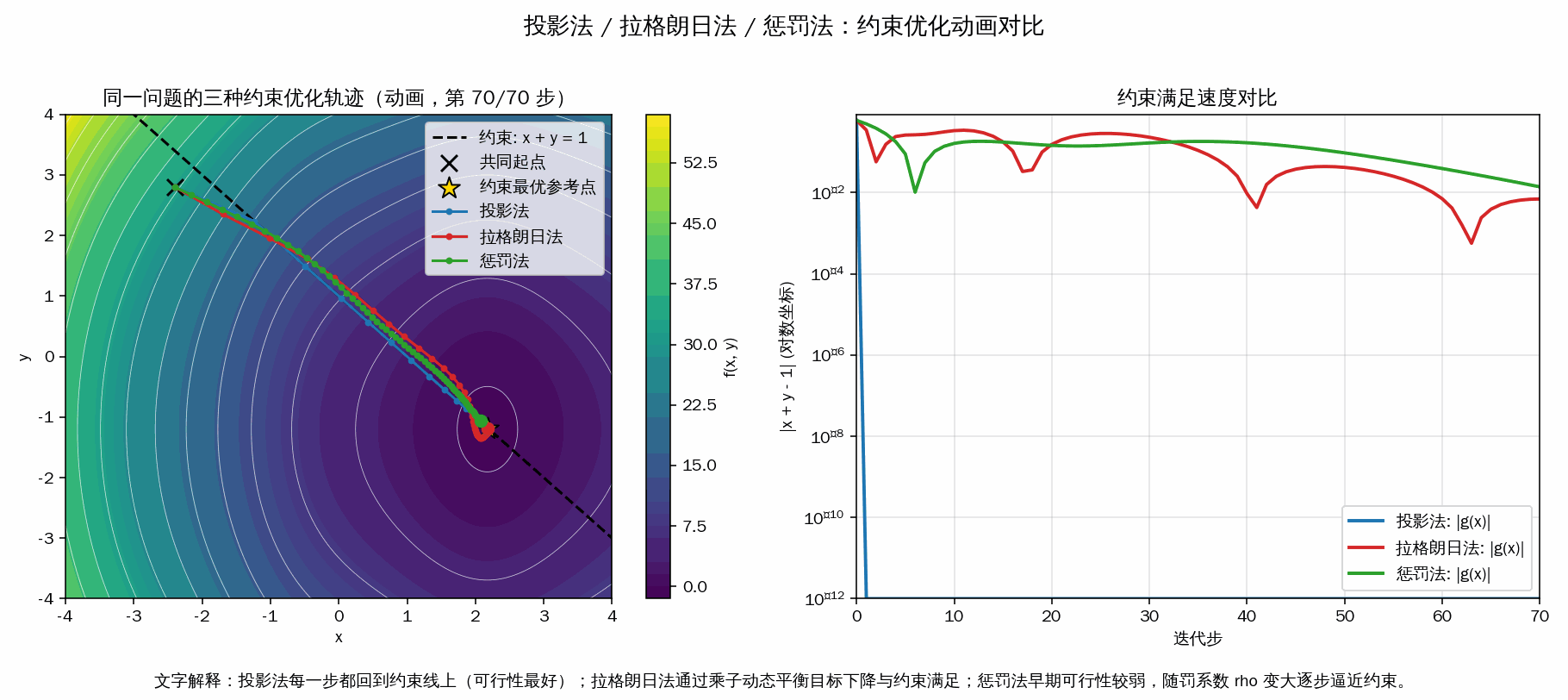
- 投影法:每一步梯度更新后都“投影回约束线”,所以可行性最好, |g(x)| 基本立刻很小。
- 拉格朗日法:通过乘子 λ 动态调节“目标下降”和“满足约束”的平衡,轨迹通常靠近约束并逐步收敛。
- 惩罚法:把约束违反写进目标函数,早期可能偏离约束,随着罚系数 ρ 增大才更强地逼近可行域。
- 右图对数曲线 |x+y-1| 用来直观看“谁更快满足约束”。
| 方法 | 几何理解 | 核心直觉 |
|---|---|---|
| 投影法 | 走出去再拉回来 | “强制回到合法区域” |
| 拉格朗日 | 改造地形 | “约束变成力场” |
| 惩罚法 | 加高墙 | “违规成本无限大” |
梯度下降
学习率
| 学习率 | 结果 |
|---|---|
| 太大 | 发散 ❌ |
| 太小 | 收敛慢 ❌ |
| 合适 | 稳定下降 ✅ |
多元梯度下降
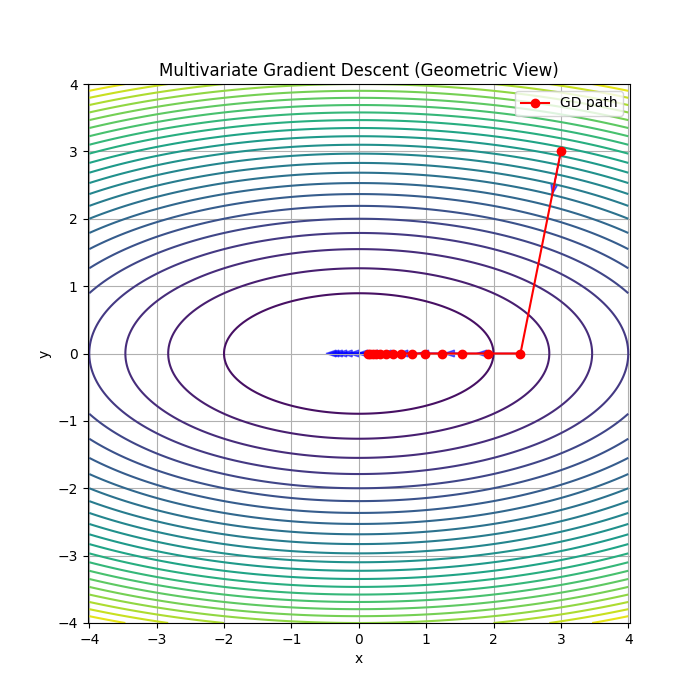
1️⃣ 等高线(背景)
- 每条线 = 同一高度
- 你可以理解为“山的地图”
2️⃣ 红色点轨迹
- 每一步参数更新
- 就是优化路径
3️⃣ 蓝色箭头(重点!!!)
👉 每一步梯度方向:指向“上坡最快方向”, 反方向就是下降方向
🔵 1. zigzag(之字形)
原因:
- x方向坡度小
- y方向坡度大
👉 导致来回震荡
🔵 2. 逐渐进入“谷底”
- 远处走得快
- 近处变慢
🔵 3. 最终收敛
→ (0, 0)
自适应方法-牛顿法
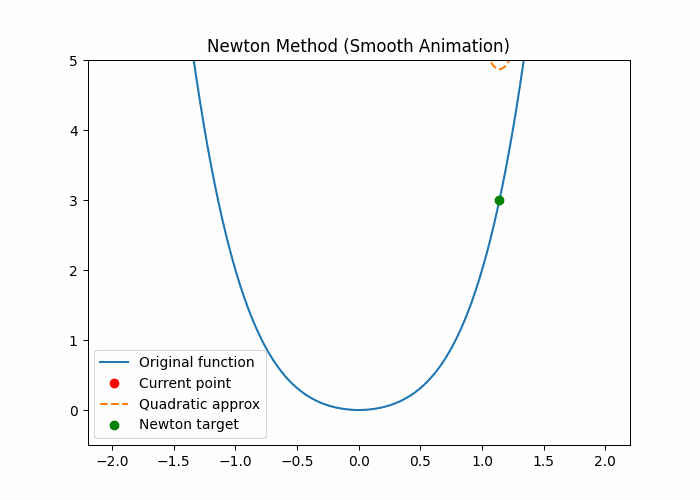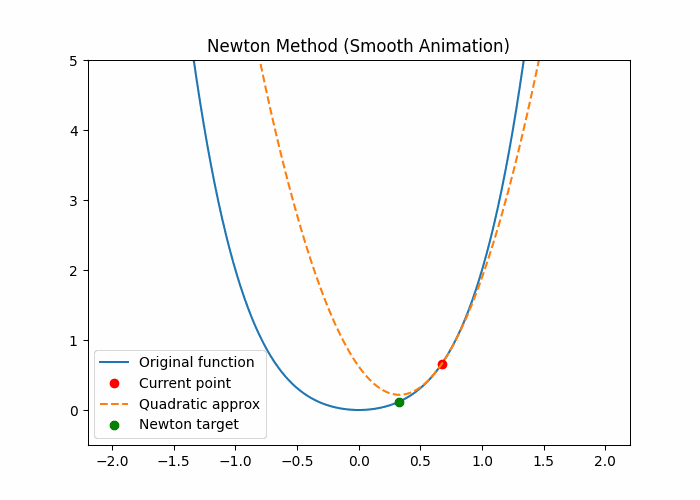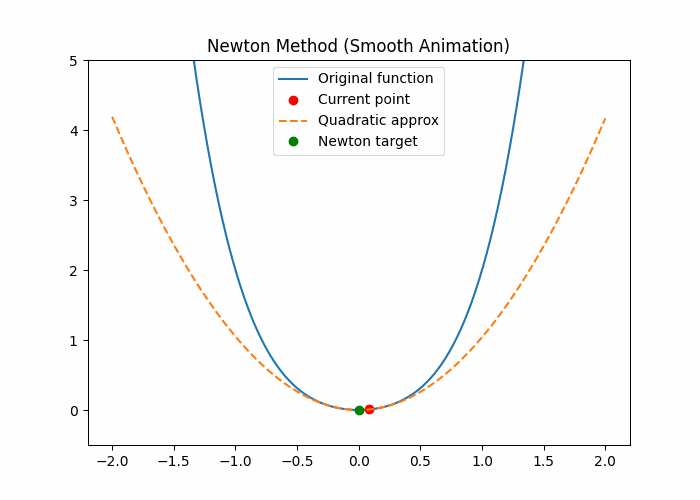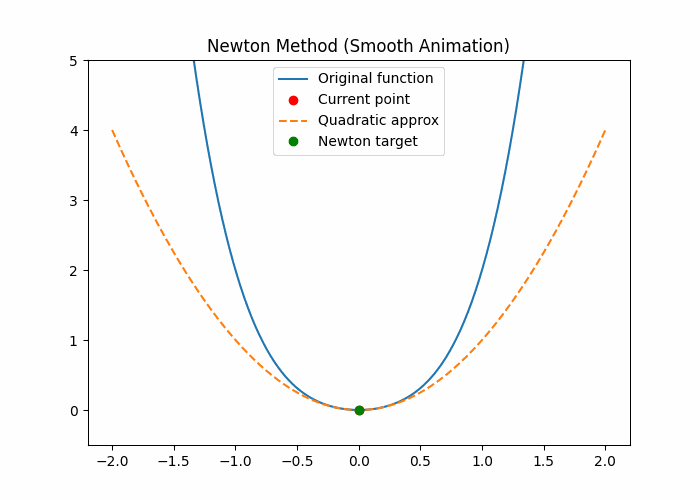
任何光滑函数,在足够小范围内都“像一个二次函数”
几何直觉(最关键)
想象你在山上:
🟥 梯度下降
我不知道前面地形
→ 先试一步
→ 再试一步
🟦 牛顿法
我看脚下这块地:
- 斜率是多少?
- 弯曲程度是多少?
👉 假设这附近是个“碗”
👉 直接算出碗底在哪
优缺点
⭐ 牛顿法适合:
- ✔ 光滑函数
- ✔ 凸问题
- ✔ 已经接近最优解
- ✔ 维度不高、
❌ 牛顿法不适合:
- 非凸(深度学习)
- 高维(神经网络)
- 噪声梯度(SGD场景)
- 非光滑函数
预处理
计算和存储完整的Hessian非常昂贵,而改善这个问题的一种方法是“预处理”
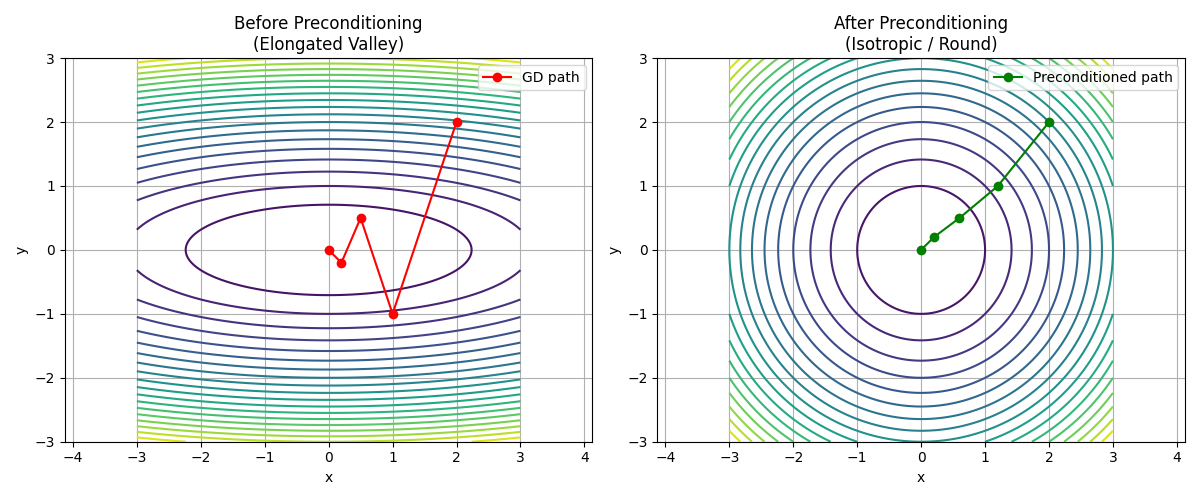
🟥 左图(没预处理)
你会看到:
等高线是“细长椭圆”
路径来回折(zigzag)
👉 本质:
x方向快,y方向慢 → 震荡
🟩 右图(预处理后)
你会看到:
等高线变“圆”
路径更直
👉 本质:
各方向尺度统一了
🔥 核心理解(非常重要)
❗ 预处理做了什么?
不是改函数:
❌ f(x,y) 没变
而是:把“椭圆地形”拉成“圆地形”
👉 坐标变换
🎯 一句话本质 : 预处理 = 改坐标系,让优化问题从“拉伸空间”变成“均匀空间”
线搜索
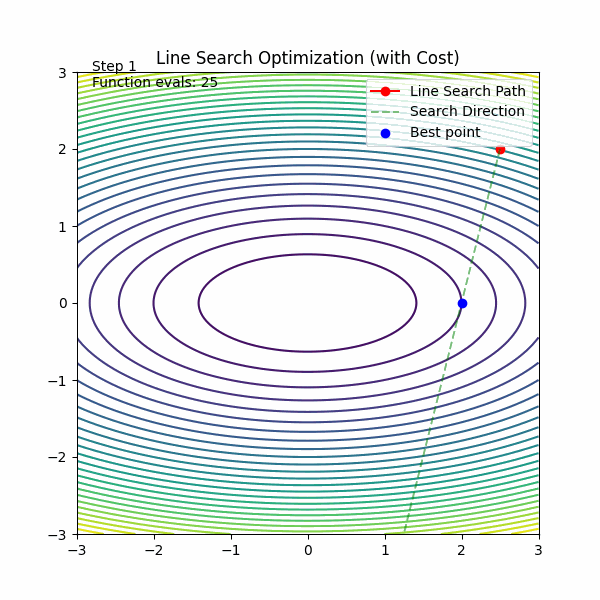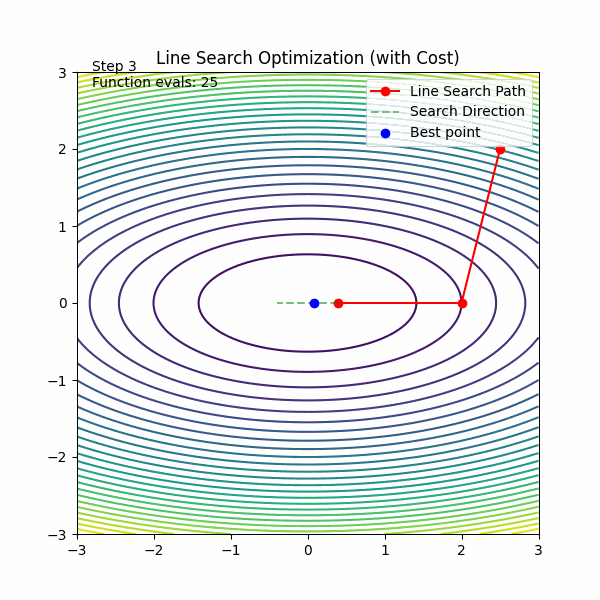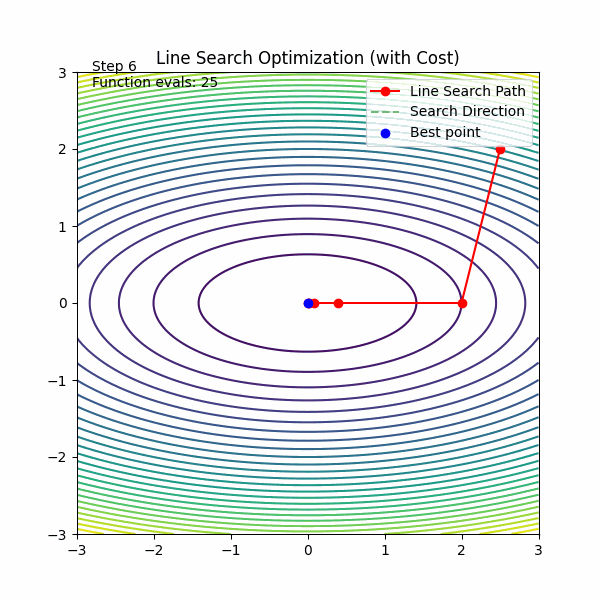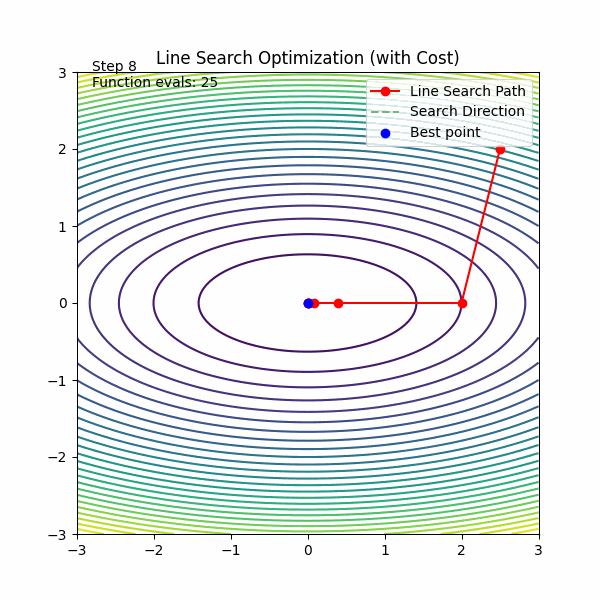
🟥 普通 GD
走一步 → 看情况 → 再调整
🟦 线搜索 GD
每一步:
在这条方向上“试很多步”
找到最优点再走
线搜索的思想是“每一步都走最优距离”,但在深度学习中,这个“最优”太贵了,所以我们用便宜的近似方法替代它。
随机梯度下降
随机梯度更新
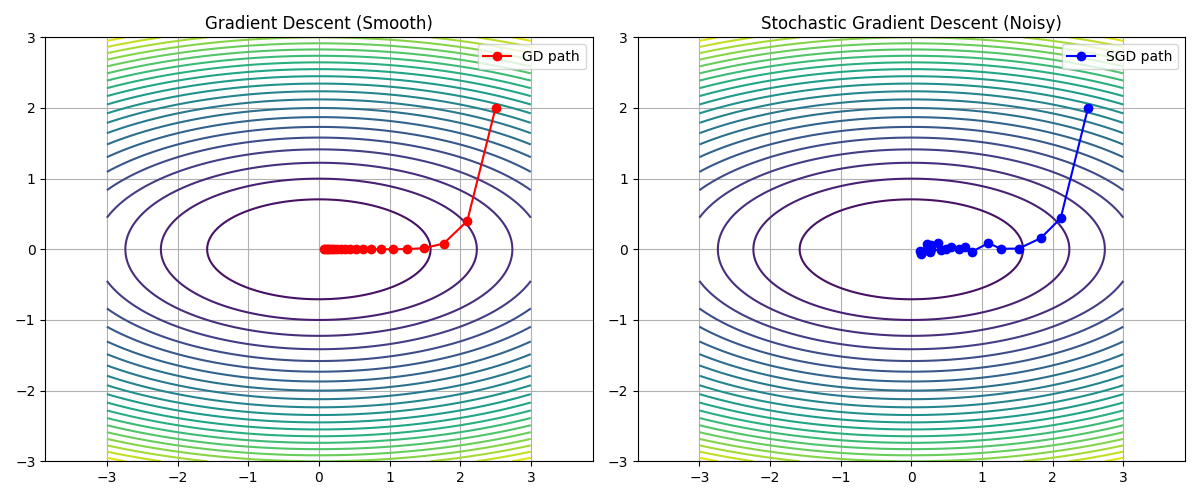
🟥 1. GD(左图)
👉 特点:
- 路径稳定
- 方向一致
- 但可能“慢”
🟦 2. SGD(右图)
👉 特点:
- 每一步方向抖动
- 有点“乱走”
- 但整体在下降
为什么要加入噪声
噪声 = 用更少计算,换取“探索能力 + 泛化能力 + 跳出坏点能力”
🎯 噪声的三大价值:
1️⃣ 探索能力
→ 跳出鞍点 / 局部最优
2️⃣ 泛化能力
→ 偏向平坦解
3️⃣ 计算效率
→ 用小批量代替全量
动画理解
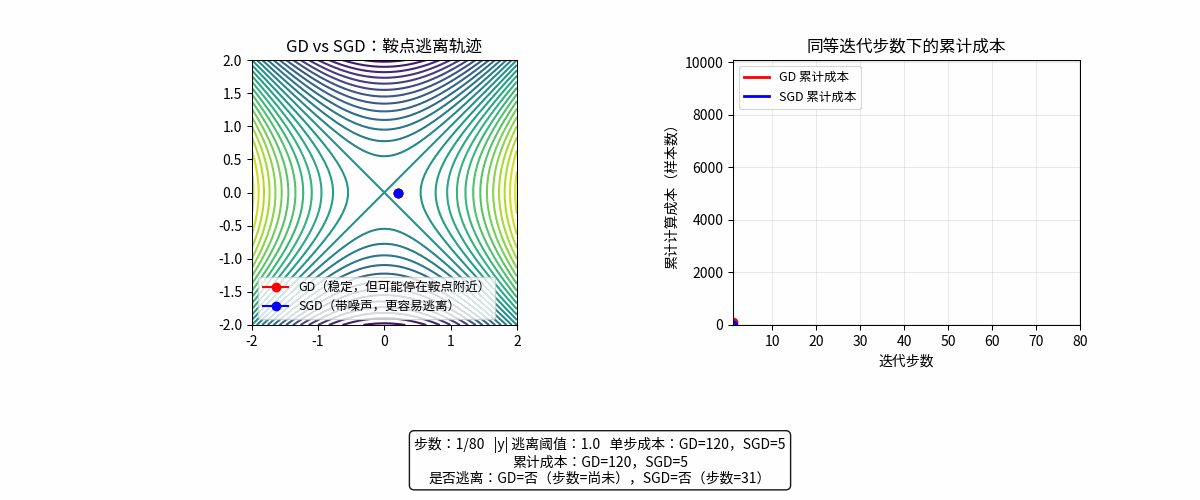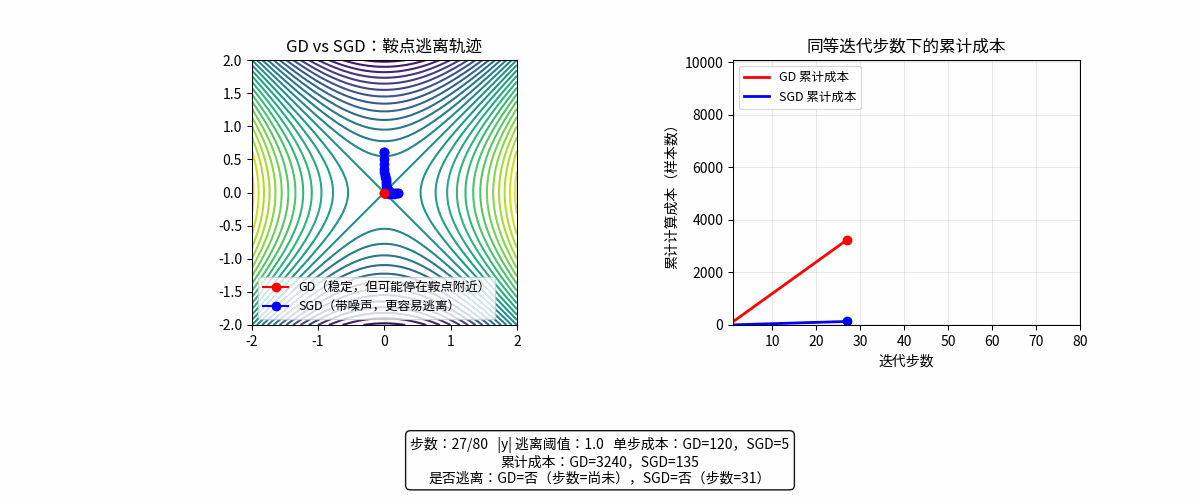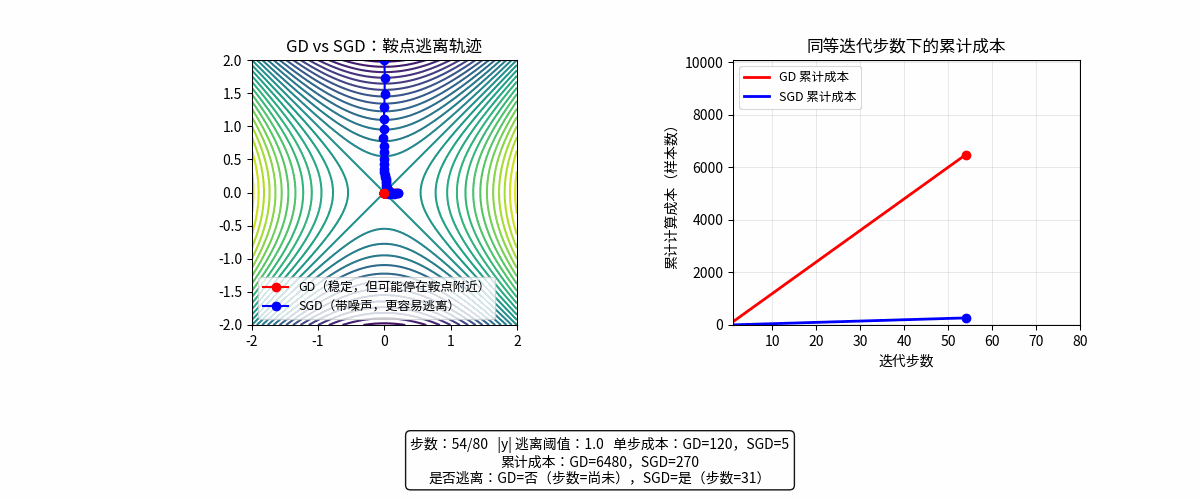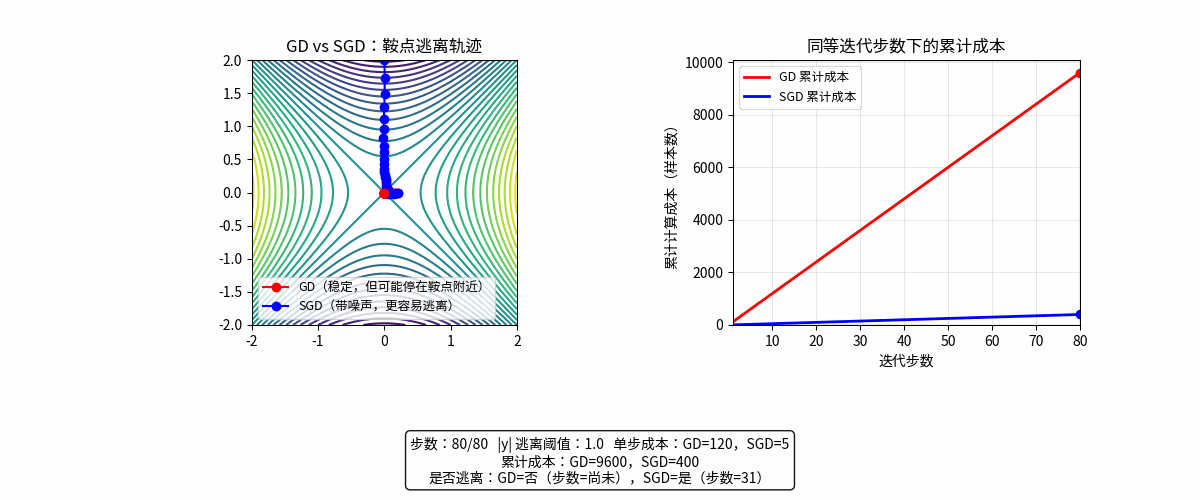
GD 每一步很准但很贵;SGD 每一步很便宜但带噪声,因此在“单位时间/单位算力”下,SGD 往往更高效。
| 方法 | 类比 |
|---|---|
| GD | 用高清地图,但每走一步都要重新打印地图 |
| SGD | 用模糊指南针,但可以快速不断试错 |
计算量对比
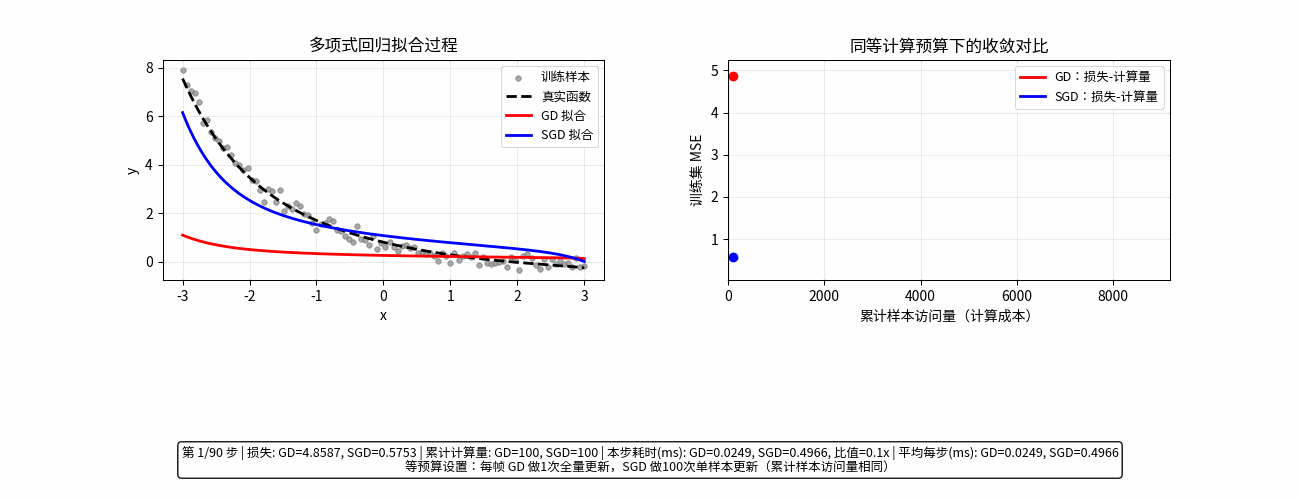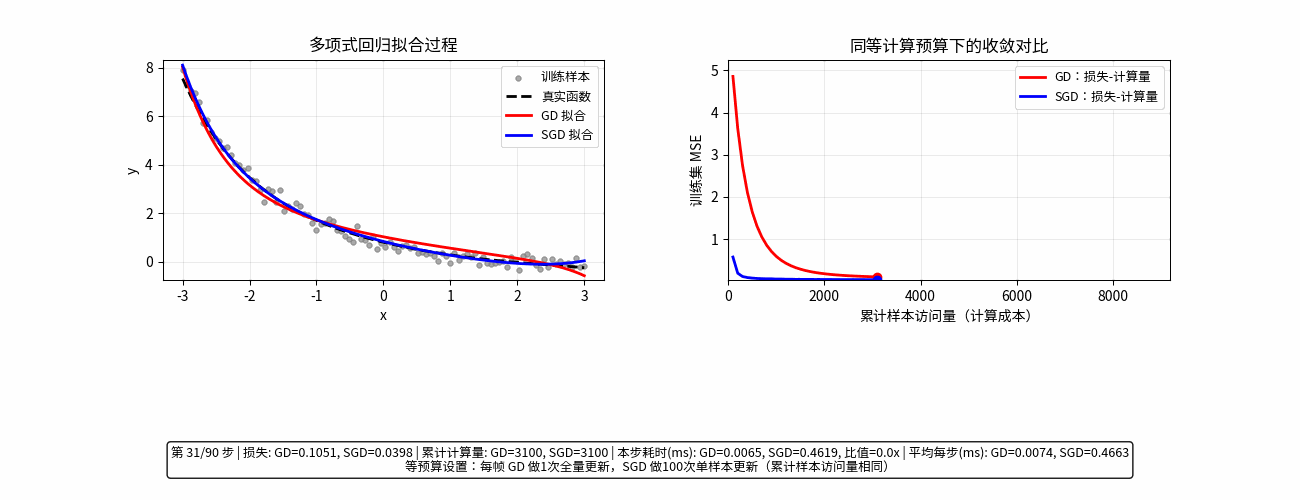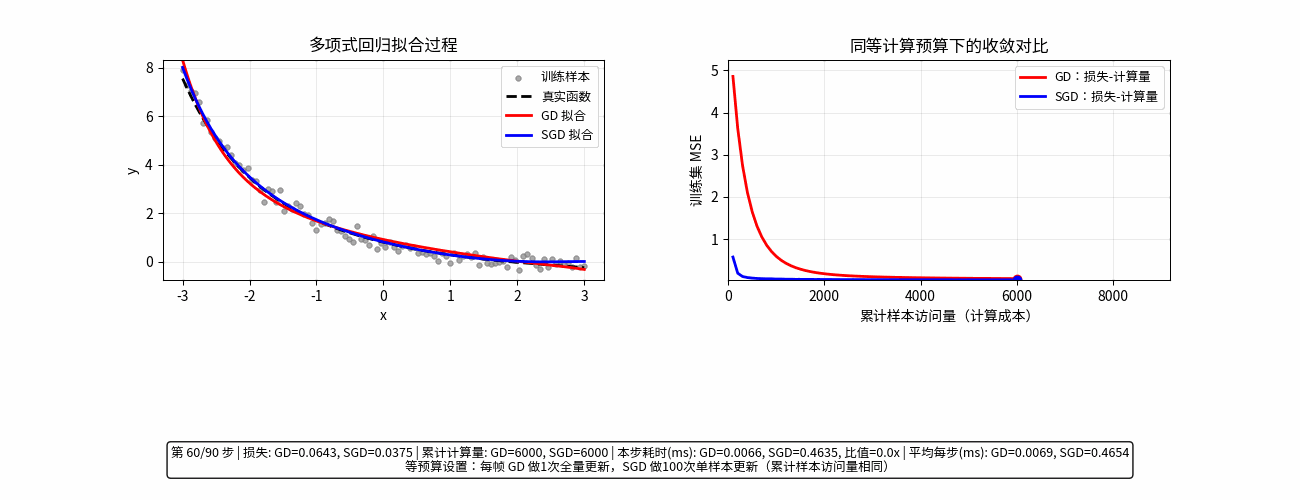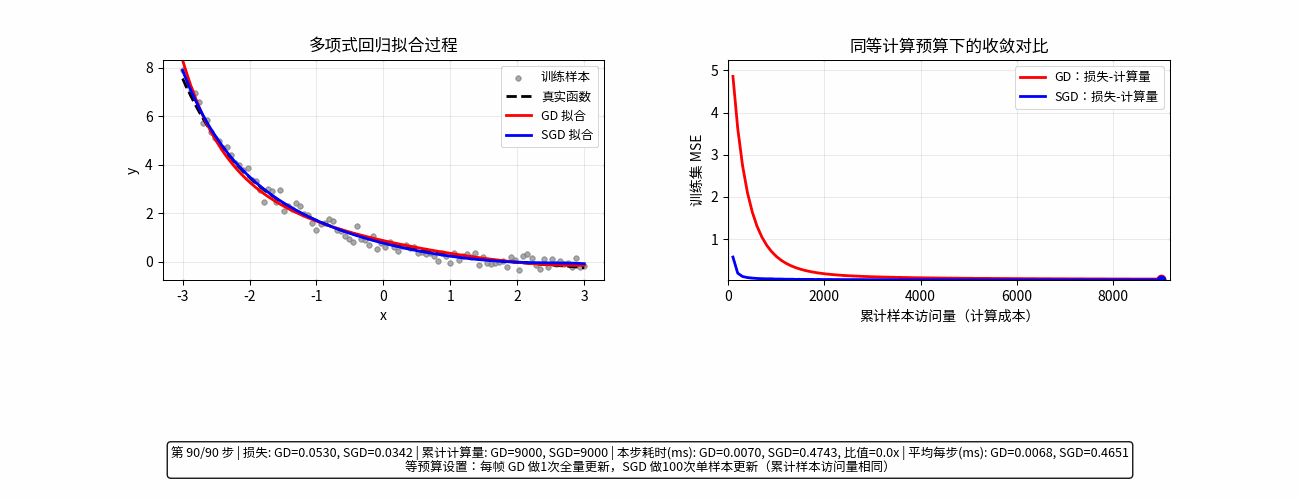
通俗易懂理解随机梯度
GD (Gradient Descent):梯度下降
形象比喻: 稳扎稳打的“完美主义者”。
在下山之前,你必须站在原地,仔细测量四周每一个方向的坡度,计算出最精确的“下山最快路径”,然后迈出一小步。
操作方式: 每次更新模型,都要把全部数据看一遍。
优点: 走得很稳,方向非常准确,几乎总是朝着山谷前进。
缺点: 极慢。如果你有 1 亿条数据,每走一小步都要算 1 亿次,电脑会累瘫。
########################################
SGD (Stochastic Gradient Descent):随机梯度下降
形象比喻: 追求效率的“急性子”。
你不再测量所有方向,而是随手抓起一条数据(或者一小波数据),瞄一眼大致方向,立马就迈步。
操作方式: 每次更新模型,只看一条(或一小部分)数据。
优点: 极快。模型更新频率高,能够迅速开始“下山”。
缺点: 走得歪歪扭扭。因为只看局部数据,有时会走错路,甚至往山上跑,但大体趋势还是向下的。
| 特性 | GD(批量梯度下降) | SGD(随机梯度下降) |
|---|---|---|
| 数据使用方式 | 每次用全部样本平均梯度 | 每次用单个样本梯度近似 |
| 梯度本质 | 真实梯度 ( \nabla L ) | 随机估计梯度 ( \nabla L_i \approx \nabla L ) |
| 方向稳定性 | 非常稳定(低方差) | 抖动(高方差) |
| 收敛轨迹 | 平滑下降 | 锯齿状下降 |
| 收敛速度(单步) | 慢但稳 | 快但不稳定 |
| 计算开销 | O(N) 每步都扫全数据 | O(1) 每步只算一个样本 |
| 内存需求 | 需要加载全部数据 | 只需一个样本 |
| 泛化能力 | 容易过拟合局部最优路径 | 噪声帮助跳出局部最优 |
| 工程应用 | 小数据集 / 理论分析 | 大规模深度学习主流 |
动态学习率
在 AI 训练里,动态学习率(Dynamic Learning Rate)就是:让学习率在训练过程中“自动变化”,而不是固定不变。
| 阶段 | 最优策略 | 固定 LR 的问题 |
|---|---|---|
| 初期(离最优点远) | 大步快走 | 小 LR 太慢 |
| 后期(接近最优) | 小步微调 | 大 LR 会震荡 |
最常见的动态学习率策略
Step Decay(阶梯下降)
每隔一段时间,学习率乘一个系数(比如 0.1)
👉 举例:
epoch 0–30:0.1
epoch 30–60:0.01
epoch 60–90:0.001
✔ 优点:简单稳定
❌ 缺点:不够平滑
Exponential Decay(指数衰减)
👉 特点:
每一步都在变
比 step 更平滑
Cosine Annealing(余弦退火 ⭐常用)
非常流行(Transformer / CV 常用):
👉 形状像:
LR
│\
│ \
│ \__
│ \__
│ \____
└────────────── t
✔ 优点:
平滑下降
后期更稳定
常配合 warm restart
Warmup(预热 ⭐非常重要)
Transformer / 大模型几乎必用:
👉 一开始学习率从很小慢慢升高
LR
│ /\
│ / \
│ / \____
│ /
└────────────── t
👉 原因:
防止一开始梯度不稳定(特别是深网络)
避免训练直接崩
Warmup + Cosine(最常用组合 ⭐⭐⭐)
实际训练中最常见:
🔥 先 warmup → 再 cosine 衰减
流程:
阶段1:线性升高(warmup)
阶段2:平滑下降(cosine)
👉 这就是很多大模型的默认策略(如 Transformer)
自适应学习率(Adaptive LR)
不是“手动调度”,而是优化器自动调整:
代表算法:
Adam
RMSProp
Adagrad
👉 核心思想:
不同参数 → 用不同学习率
小批量随机梯度下降
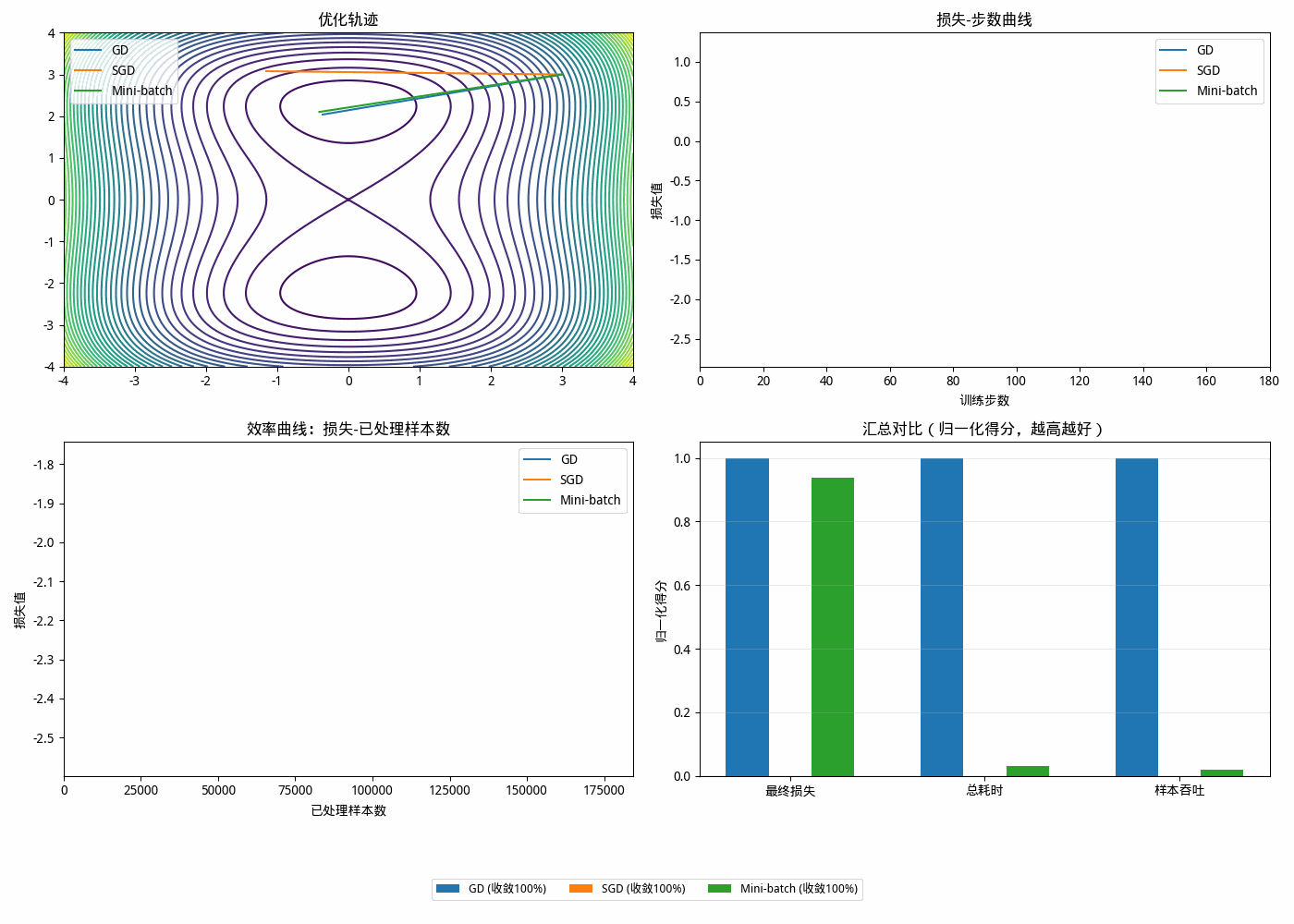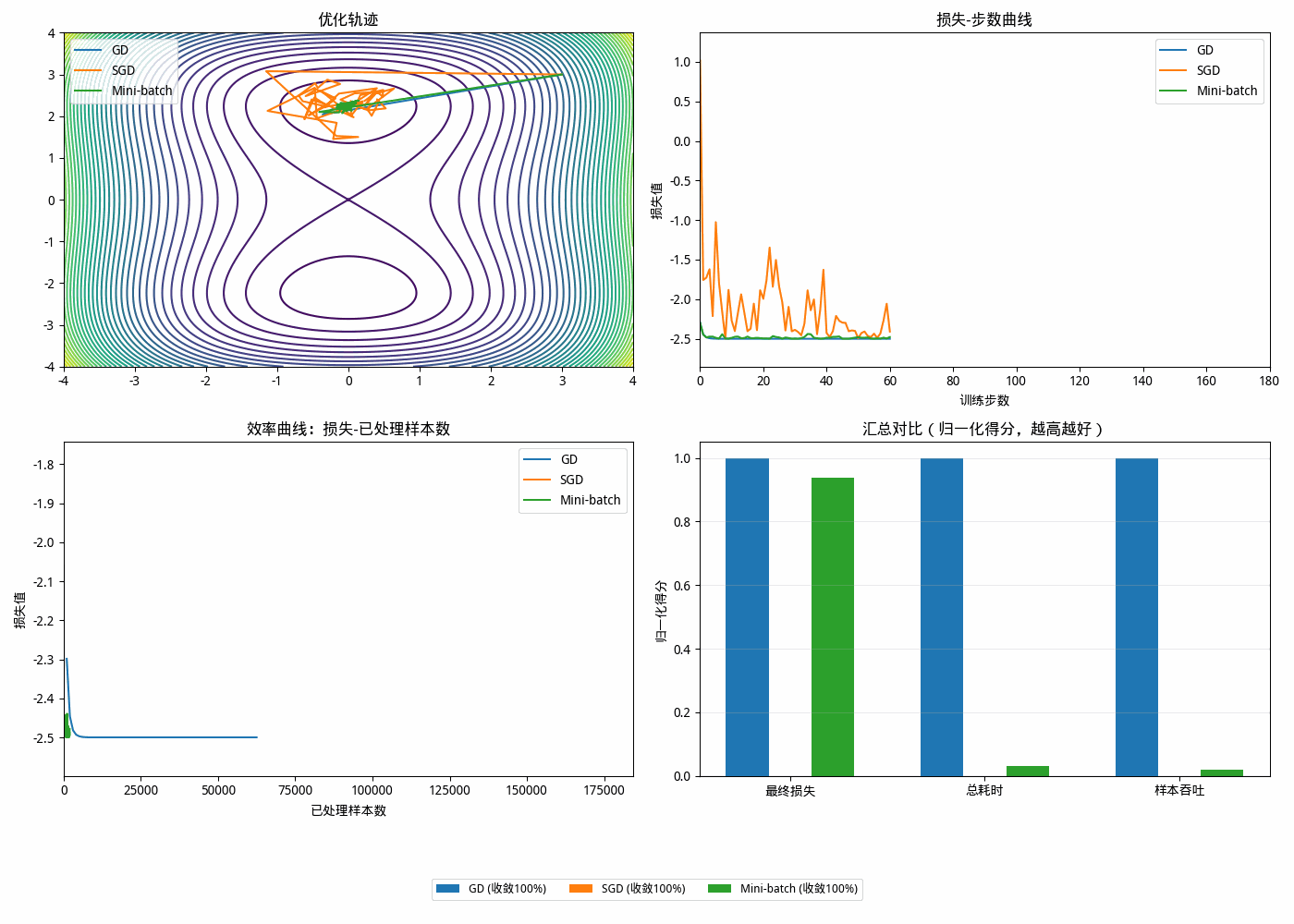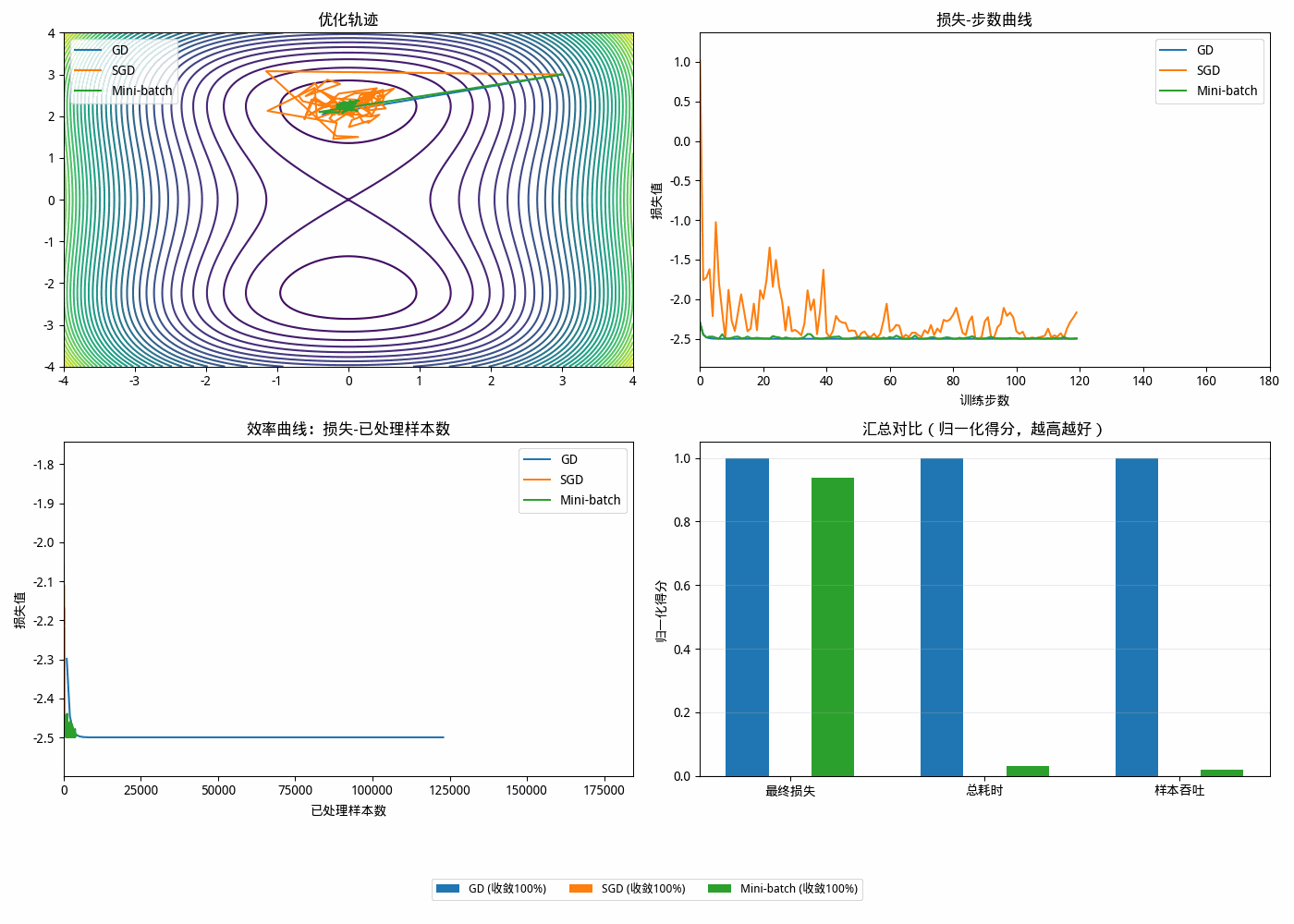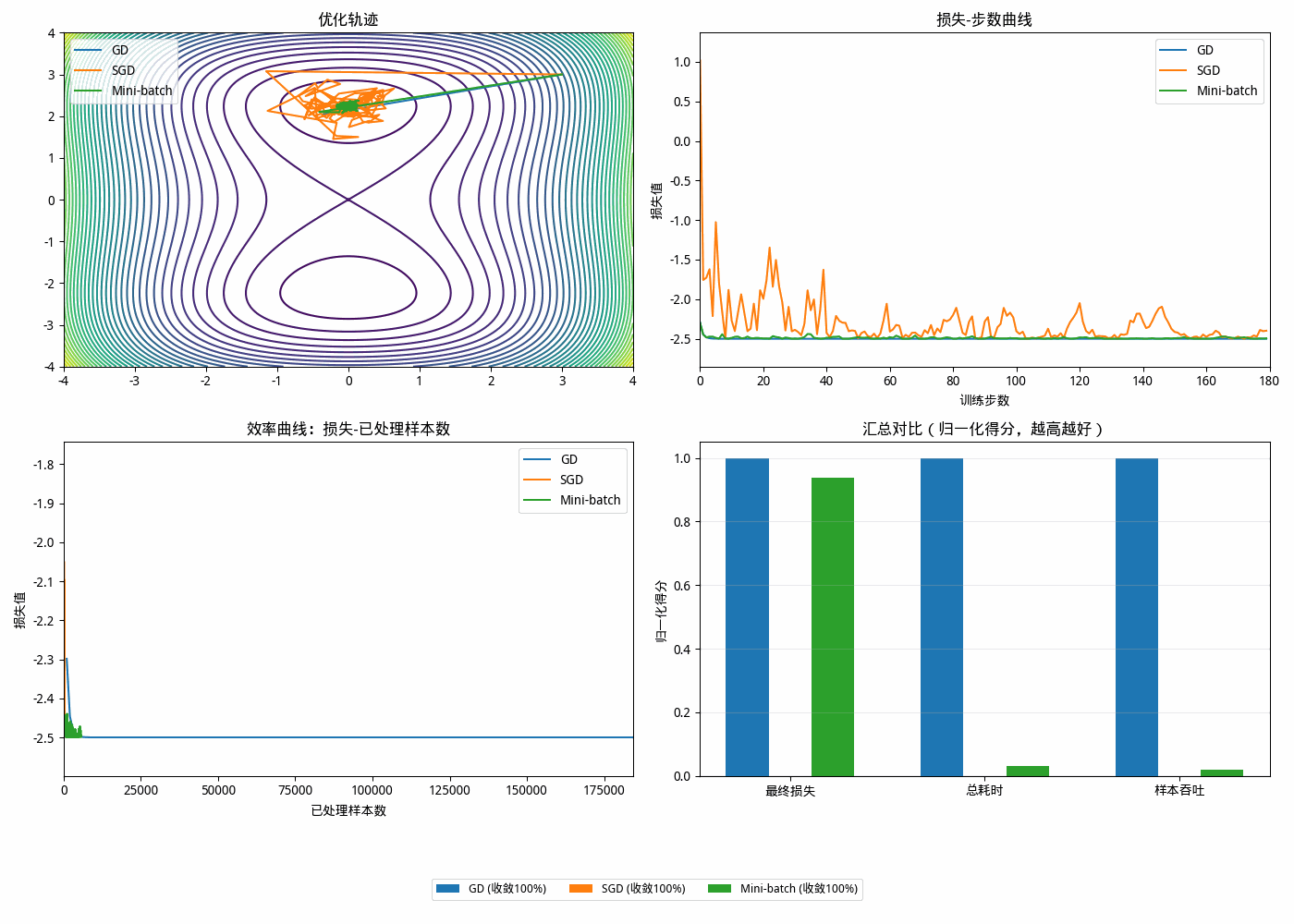
为什么需要 Mini-batch?
1️⃣ Batch Gradient Descent(全量)
每次用全部数据
一次只更新一次参数(每个 epoch)
✔ 优点:方向最准
❌ 缺点:
非常慢
不利用 GPU 并行
👉 实验现象:
收敛很慢,甚至“几步后就停滞”
2️⃣ SGD(单样本)
每次只用一个样本
更新非常频繁
✔ 优点:更新快
❌ 缺点:
计算效率低(无法向量化)
噪声大
👉 实验现象:
每个 epoch 时间更长(反而慢)
Mini-batch 的核心思想
本质: 用“一小部分数据”近似“全量梯度”
👉 计算机体系结构决定了 mini-batch 是最优选择
1️⃣ 向量化(Vectorization)
关键结论:
👉 矩阵运算比逐元素运算快几个数量级
实验里:
单元素:极慢
按列:一般
整体矩阵:极快
👉 因为:
GPU / CPU 擅长并行计算
一次处理越多数据 → 越高效
2️⃣ 缓存(Cache)和带宽
核心问题:
CPU/GPU 算力很强
但内存带宽跟不上
👉 解决方法:
👉 一次多处理数据(mini-batch),减少内存访问
3️⃣ 并行计算(多 GPU)
现实情况:
8 GPU × 16 机器
每个 GPU 至少要有数据
👉 batch size 不能太小
Mini-batch SGD 训练过程
┌───────────────────────────────┐
│ 数据集 Dataset │
│ (x₁,y₁), (x₂,y₂)...(xN,yN) │
└───────────────┬───────────────┘
│
▼
[1] 数据打乱(Shuffle)
👉 防止模型记住顺序,增强泛化
│
▼
[2] 划分 Mini-batch
👉 batch size = B(如 32 / 64)
│
▼
┌─────────────────────────┐
│ 对每个 mini-batch 循环 │
└─────────────┬───────────┘
│
▼
┌──────────────────────┐
│ [3] 前向传播 Forward │
│ y_pred = model(x) │
│ 👉 神经网络逐层计算 │
└─────────┬────────────┘
│
▼
┌──────────────────────┐
│ [4] 计算损失 Loss │
│ L = loss(y_pred, y) │
│ 👉 衡量预测误差 │
└─────────┬────────────┘
│
▼
┌────────────────────────────┐
│ [5] 反向传播 Backward │
│ 计算 ∂L/∂θ(梯度) │
│ 👉 链式法则逐层回传 │
└─────────┬──────────────────┘
│
▼
┌────────────────────────────┐
│ [6] 参数更新 Update │
│ θ = θ - η · g │
│ 👉 SGD / Adam / Momentum │
└─────────┬──────────────────┘
│
▼
┌────────────────────────────┐
│ [7] 清空梯度(重要!) │
│ grad = 0 │
│ 👉 防止梯度累积污染 │
└─────────┬──────────────────┘
│
▼
(继续下一个 batch)
动量法
Momentum = 对“历史梯度”做指数加权平均,再用它更新参数
把优化过程想象成:
👉 小球在山谷里滚
- GD:每一步只看当前坡度(容易左右晃)
- Momentum:带“惯性”,方向更稳定
公式
动量法主要由两个步骤组成:
第一步:更新速度(Velocity)
\[v_t = \gamma v_{t-1} + \eta \nabla_\theta J(\theta_t)\]第二步:更新参数(Parameters)
\[\theta_{t+1} = \theta_t - v_t\]参数含义
- $\theta_t$:第 $t$ 次迭代时的模型参数(权重)。
- $v_t$:第 $t$ 次迭代时的动量(速度)矢量,它代表了之前所有梯度的加权平均。
- $\eta$ (Eta):学习率,控制每一步前进的步长。
- $\nabla_\theta J(\theta_t)$:当前参数下的梯度,指明了损失函数上升最快的方向。
- $\gamma$ (Gamma):动量系数(通常取 0.9 左右)。它决定了“记忆”上次速度的程度:
- 如果 $\gamma = 0$,则退化为普通的梯度下降。
- $\gamma$ 越大,以往梯度的影响力越持久,惯性越强。
含义
- 抑制振荡:在坡度很陡但指向错误的维度上,正负梯度会相互抵消。动量项通过累加,使这些无效的来回振荡变小。
- 加速收敛:在指向目标的维度上,梯度方向一致。动量项会不断累积,使更新速度越来越快。
- 跳出局部最优:由于惯性的存在,算法有一定概率冲过平坦的局部最小值区域,寻找更优的全局解。
动画理解
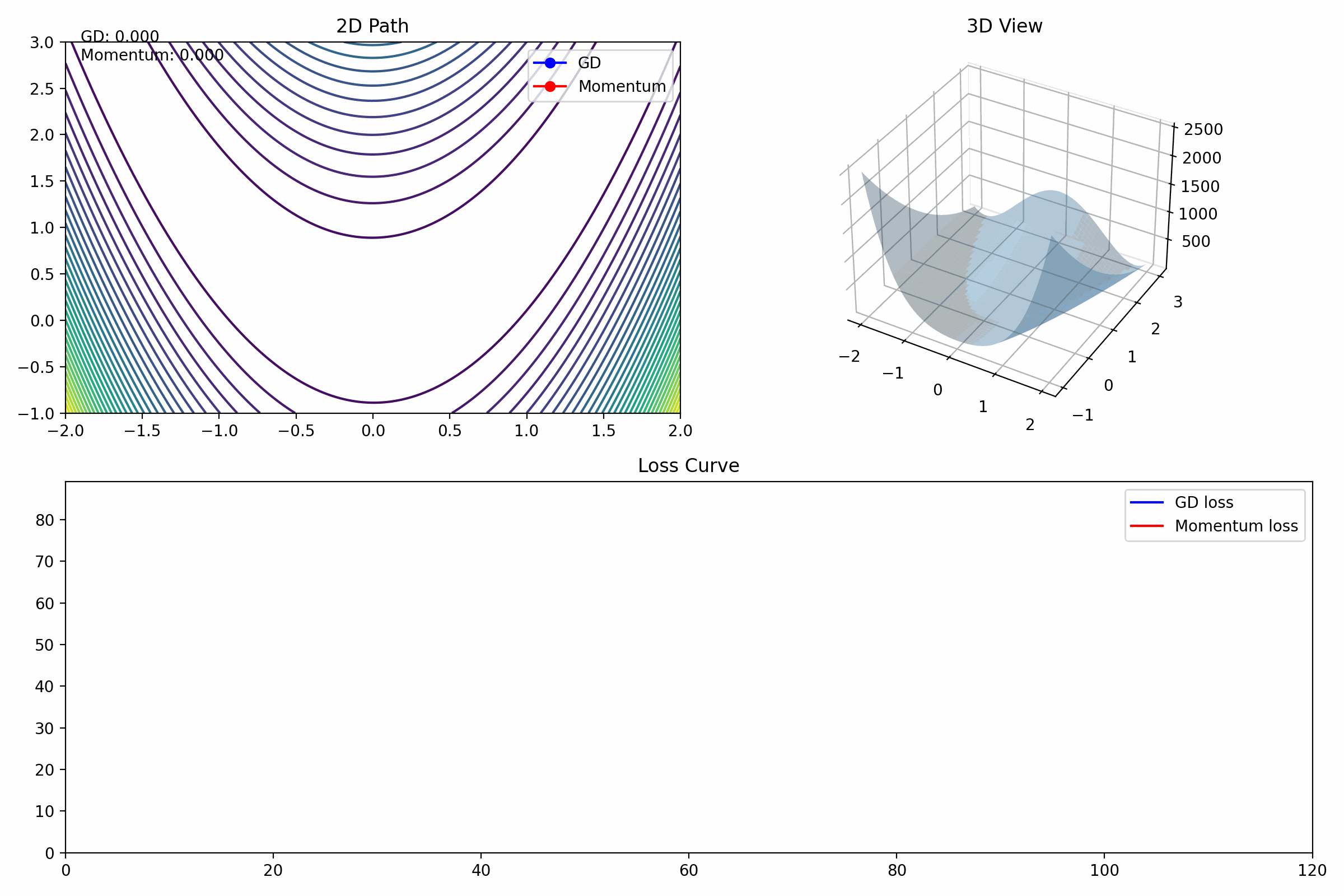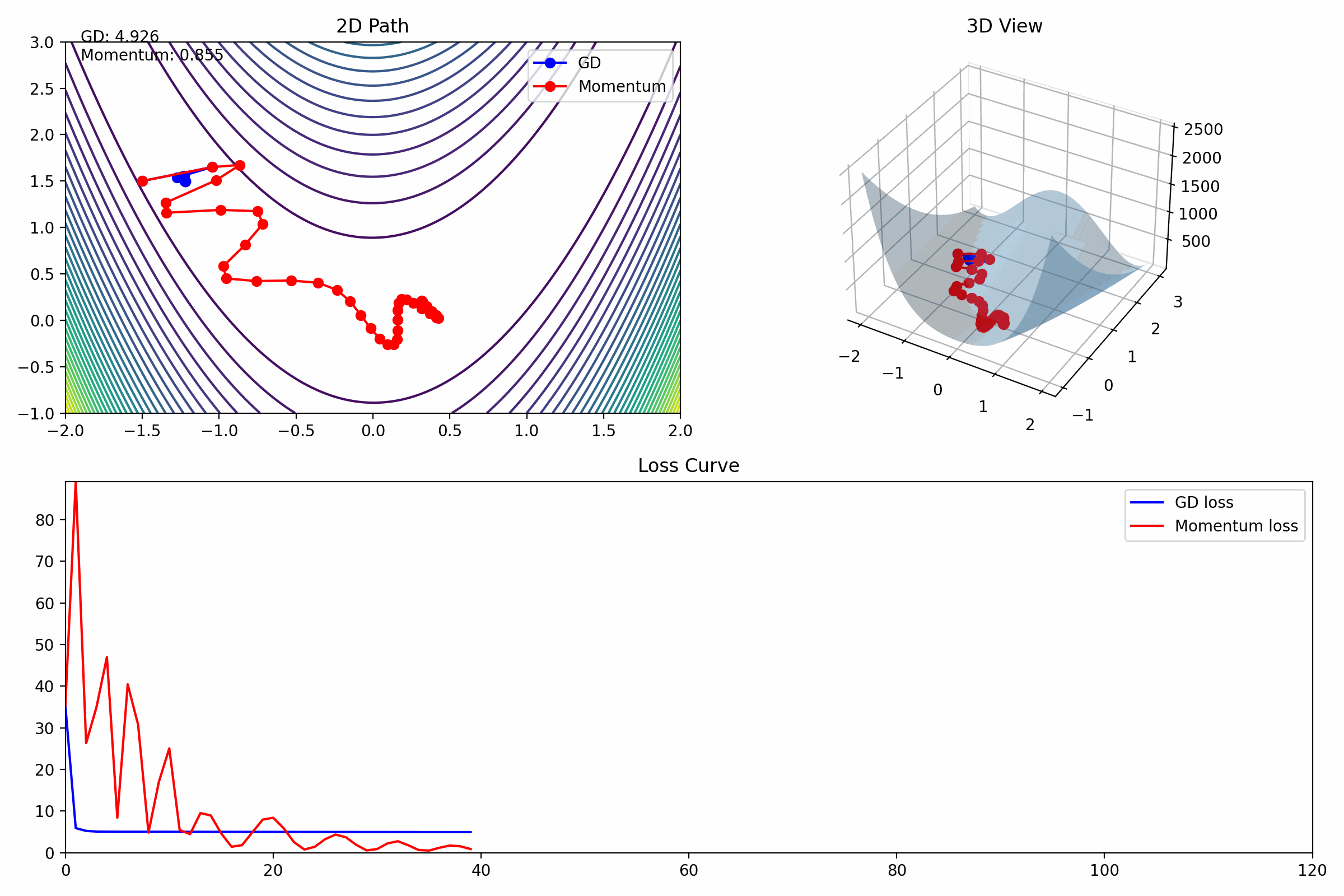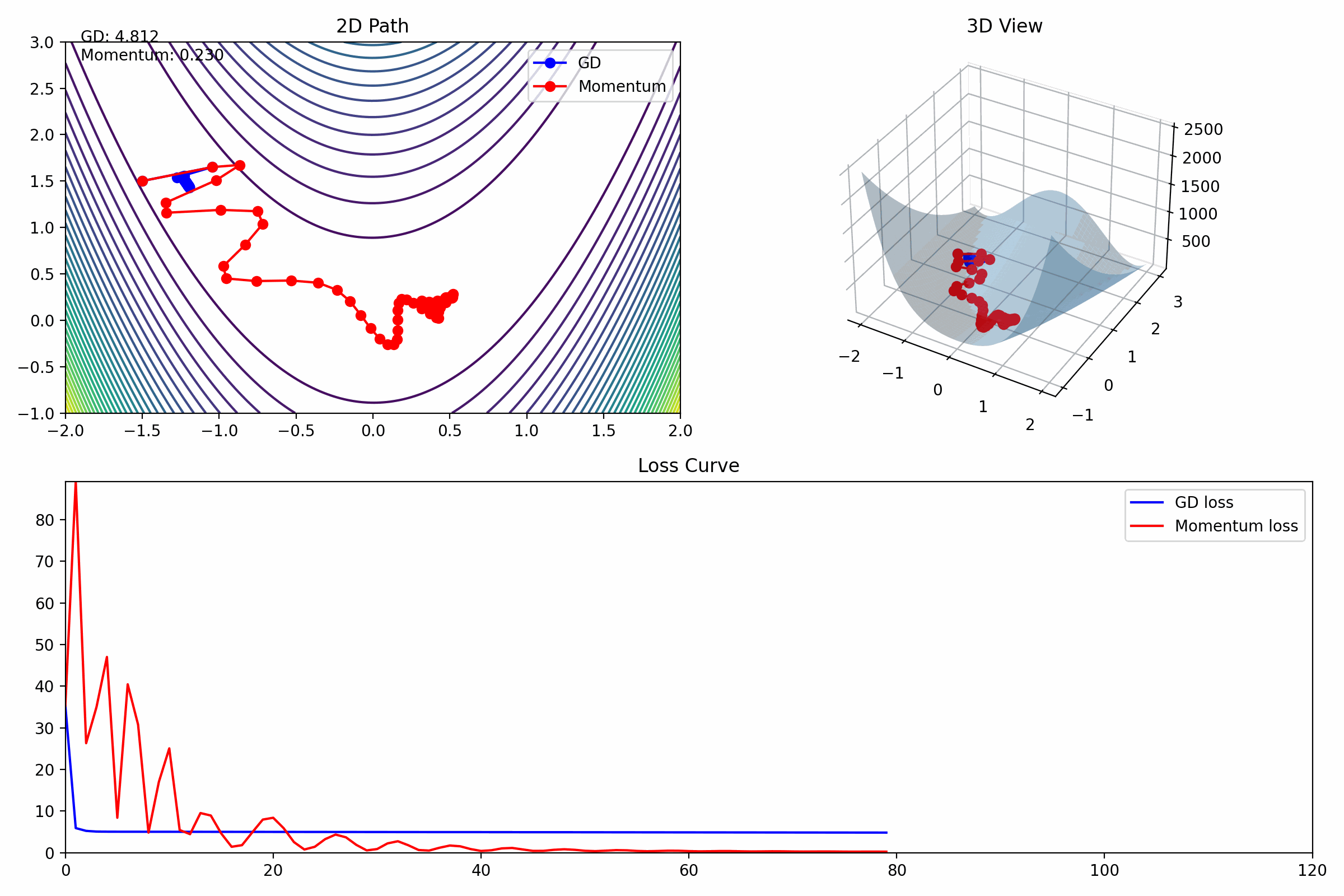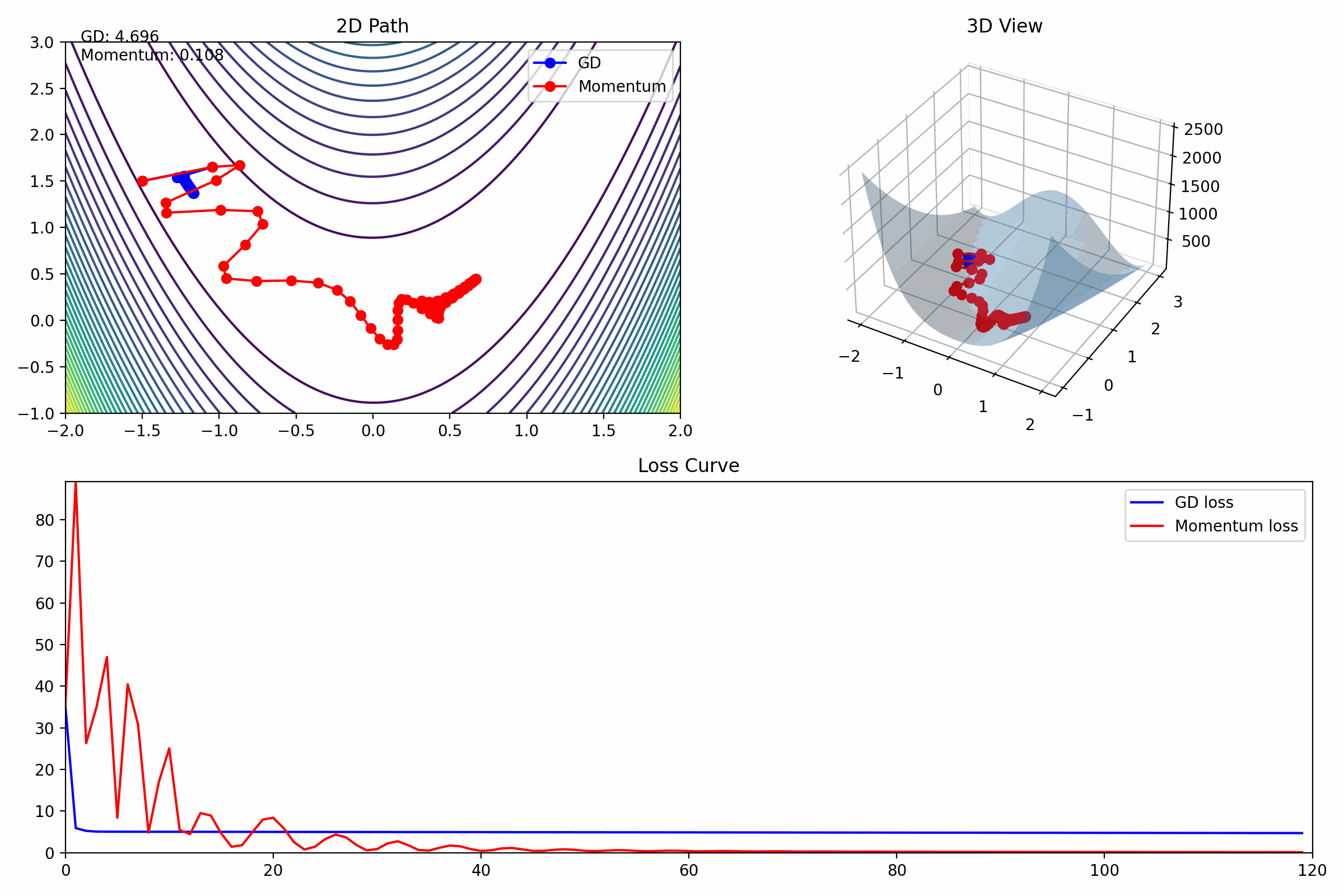
| 区域 | 作用 |
|---|---|
| 2D | 轨迹形状 |
| 3D | 空间下降过程 |
| loss | 收敛速度 |
AdaGrad算法
这一章在解决什么问题?
核心一句话:
👉 SGD 每个参数用同一个学习率,不合理
问题来源:
❗1. 不同参数“重要性不同”
有些参数梯度大(变化快)
有些参数梯度小(变化慢)
👉 但 SGD:一视同仁
❗2. 稀疏特征问题(重点)
比如 NLP:
“the” → 经常出现
“preconditioning” → 很少出现
👉 SGD 会:
高频词更新太多
低频词几乎学不到
AdaGrad 的核心思想
👉 每个参数用自己的学习率,并且自动衰减
👉 历史梯度平方累积 → 自动缩小学习率
✔ 1. 自动调学习率
不用手动 decay
✔ 2. 适合稀疏数据
NLP / 推荐系统特别好
✔ 3. 稳定
不用调太多超参
对比动量法
| 方法 | 核心思想 | 解决问题 |
|---|---|---|
| Momentum | 累积“方向” | 解决“震荡问题” |
| AdaGrad | 累积“幅度” | 解决“学习率分配问题” |
AdaGrad 因为学习率单调衰减过快,导致后期训练失效,被 RMSProp / Adam 取代
RMSProp算法
一句话: 别累加历史梯度,用“近期记忆”替代
| 项目 | AdaGrad | RMSProp |
|---|---|---|
| 历史处理 | 累加 | 指数衰减 |
| 学习率 | 越来越小 | 稳定 |
| 后期训练 | 停滞 | 可继续学习 |
| 适合深度学习 | ❌ 不太适合 | ✅ 很适合 |
Adam算法
这一章在解决什么问题?
| 方法 | 问题 |
|---|---|
| SGD | 收敛慢、震荡 |
| Momentum | 只解决“方向”,不管尺度 |
| AdaGrad | 学习率衰减过快 |
| RMSProp | 解决 AdaGrad,但无“动量” |
Adam 的核心思想
动量(Momentum) + 自适应学习率(RMSProp)结合
优化器对比
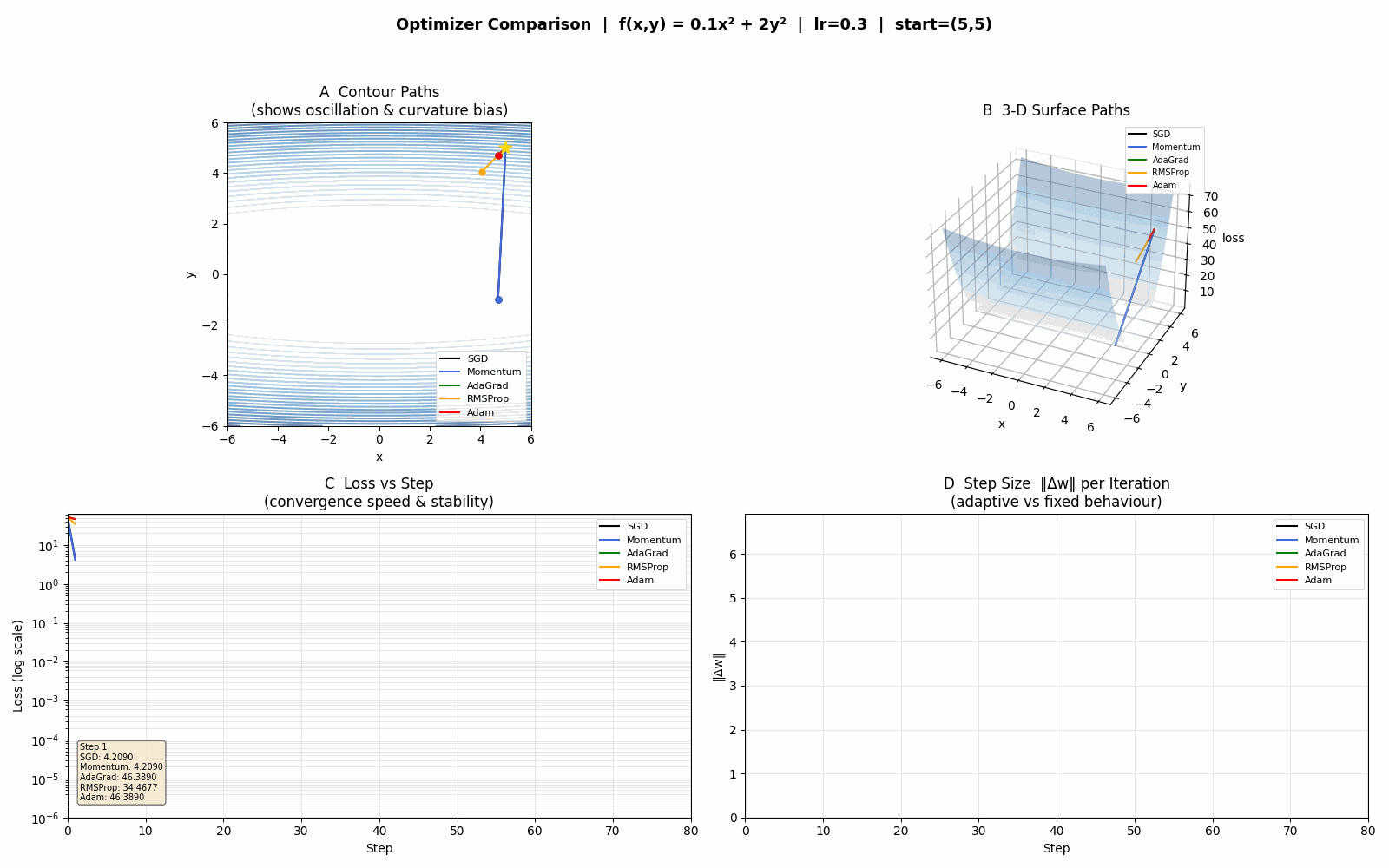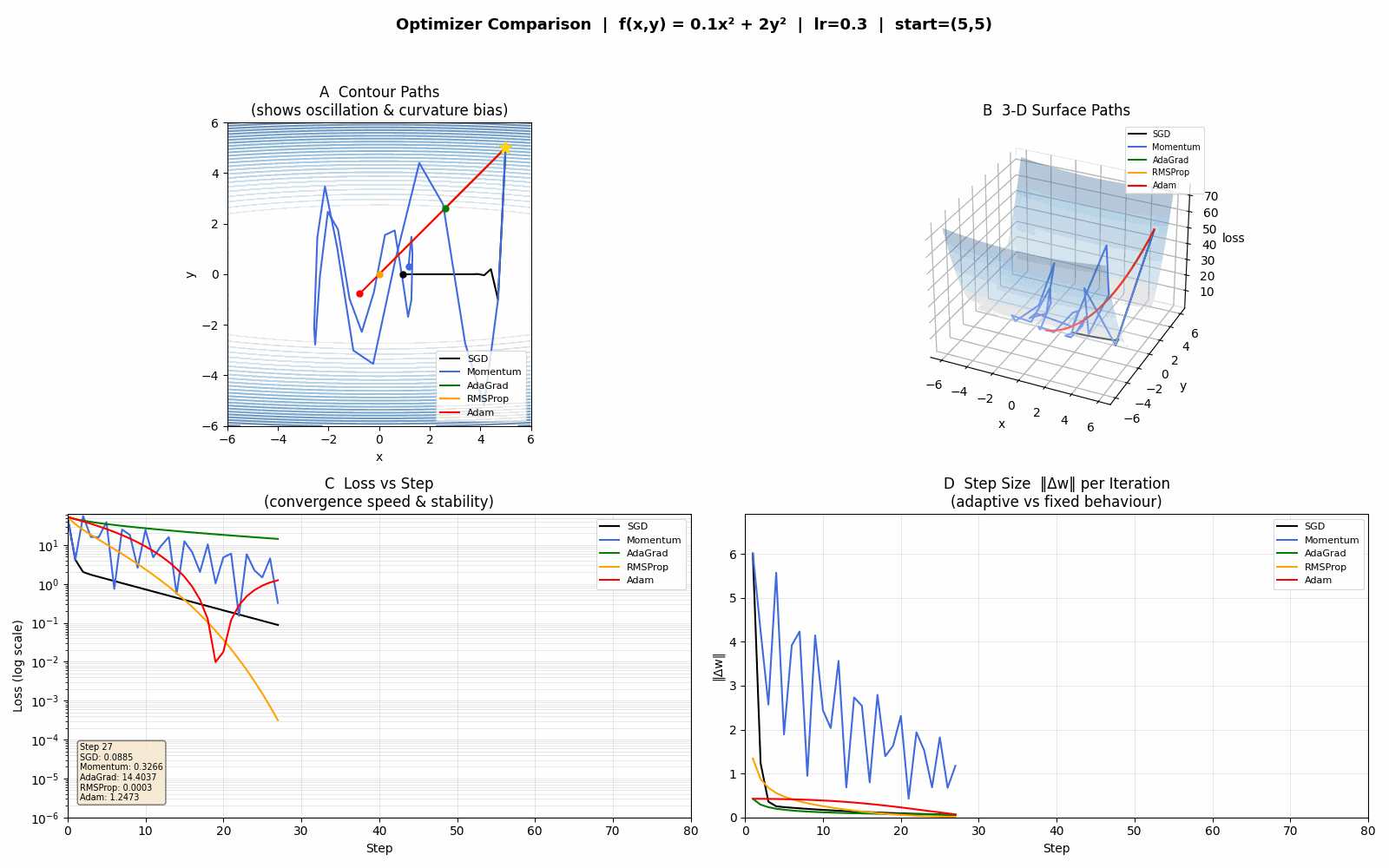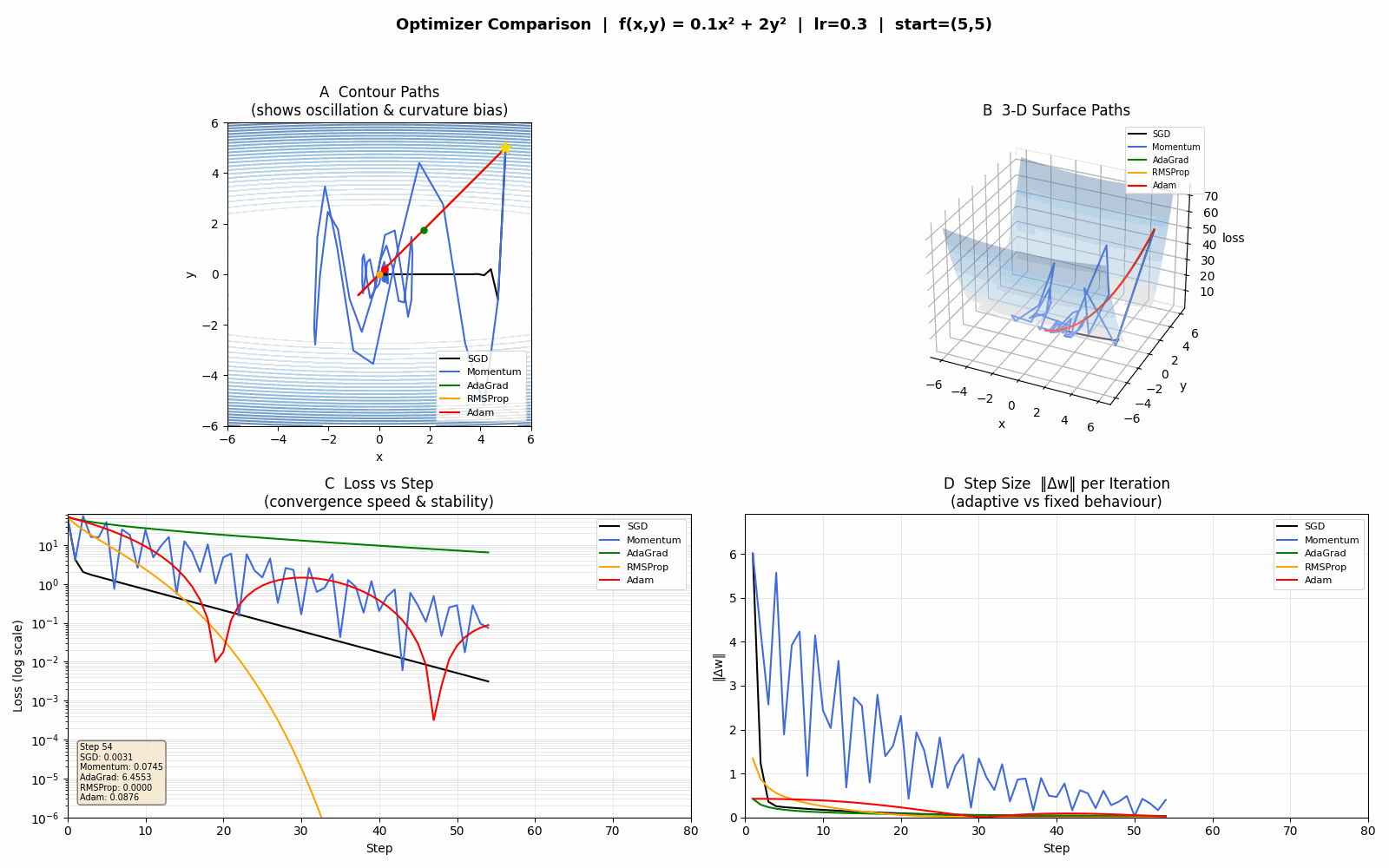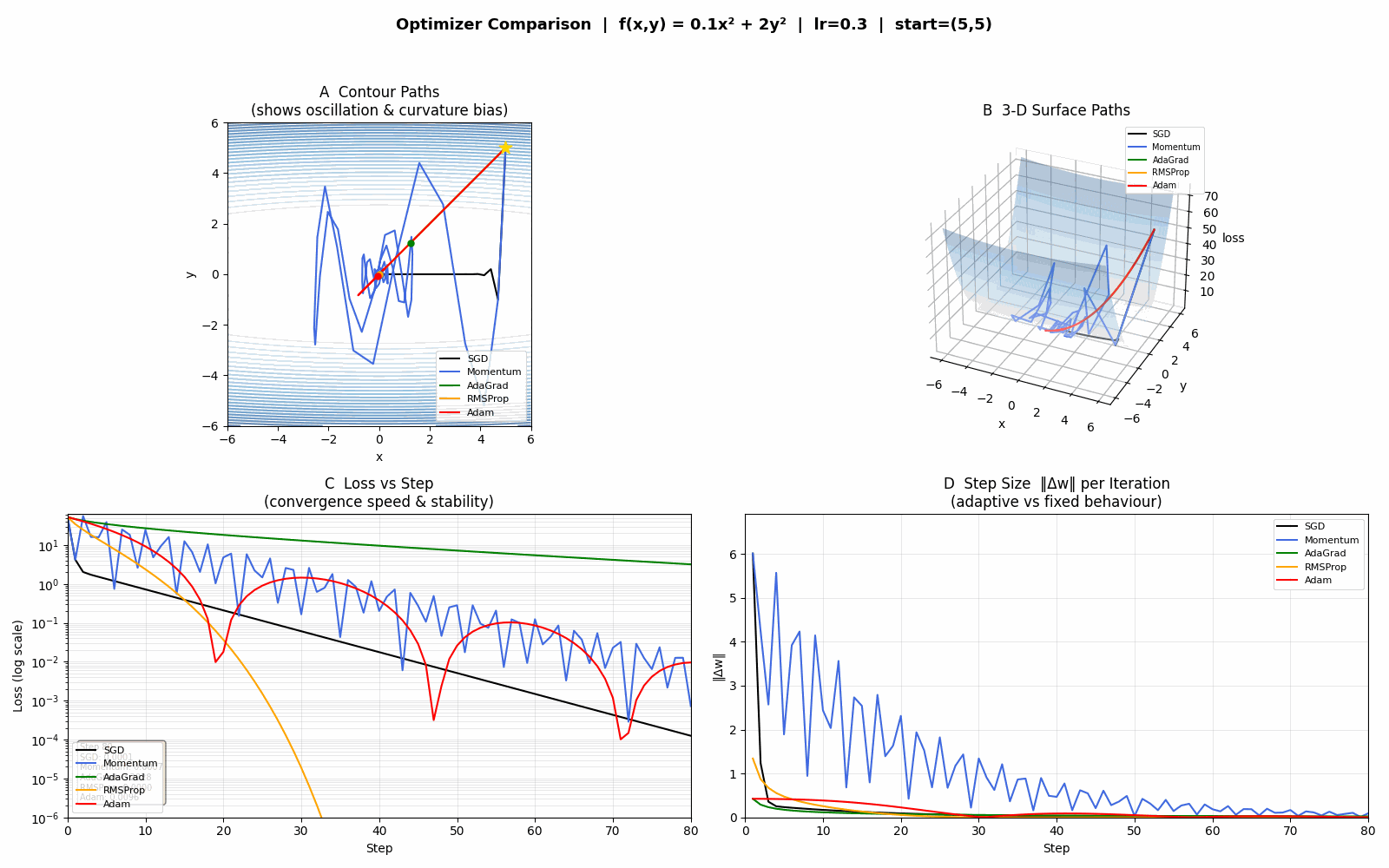
四个面板
A — 等高线路径(最直观)
看路径形状:
SGD(黑):在 y 方向来回弹跳,x 方向缓慢推进,呈典型"锯齿"形
Momentum(蓝):速度积累让 x 方向更快,但 y 方向的惯性使震荡幅度更大
AdaGrad(绿):y 方向梯度大 → 累积平方和大 → 步长迅速缩小 → 震荡快速消失,但后期路径几乎停滞(步长趋近 0)
RMSProp(橙):与 AdaGrad 类似但不停滞,路径更平滑、收敛更稳
Adam(红):路径最直、最快到达原点,同时兼顾速度和稳定性
B — 3D 曲面路径
同样的轨迹叠在曲面上,可以感受下降的高度——Adam/RMSProp 一开始就急速下降,SGD 则在高处来回抖动。
C — Loss 曲线(对数坐标)
看收敛速度:
SGD/Momentum 前期 loss 震荡,下降缓慢
AdaGrad 初期快,后期曲线变平(停滞)
RMSProp/Adam loss 曲线最陡,最终值最小
对数坐标让后期微小差异也清晰可见。
D — 步长 ‖Δw‖
看自适应效果:
SGD/Momentum 步长基本恒定(固定 lr)
AdaGrad 步长单调递减,最终接近 0——这就是它停滞的原因
RMSProp/Adam 步长在初期大、后期自动收缩但不归零,自动适应梯度规模
| 优化器 | 关键特征 | 本质作用 | 主要缺点 |
|---|---|---|---|
| SGD | 无记忆、固定学习率 | 最基础的梯度下降 | 在病态曲面上震荡严重、收敛慢 |
| Momentum | 累积历史梯度(动量) | 平滑更新方向,加速一致方向 | 在陡峭方向可能“冲过头” |
| AdaGrad | 累积梯度平方,自适应步长 | 高频参数减速、低频加速 | 学习率单调衰减,后期停滞 |
| RMSProp | 指数滑动平均梯度平方 | 修复 AdaGrad 的“停滞问题” | γ 需要调参,缺少动量机制 |
| Adam | Momentum + RMSProp + bias correction | 同时解决方向 + 尺度 + 稳定性 | 某些任务泛化略弱于 SGD+Momentum |
学习率调度器
Step Decay(阶梯衰减)
👉 每隔一段时间降低学习率
特点:
- 简单
- 工业常用
Exponential Decay(指数衰减)
特点:
- 平滑下降
- 越来越保守
Cosine Decay(余弦退火)
学习率像“余弦曲线”下降
特点:
- 前快后慢
- 很适合深度学习
Warmup(预热)
👉 训练初期:
- 从小 lr 开始
- 慢慢升到目标 lr
特点:
- 防止初期不稳定
- Transformer 必备
Reduce on Plateau(自适应)
👉 loss 不下降 → 自动降低 lr
特点:
- 不需要预设时间点
- 更智能
真实训练时各种调度器的表现
在完全相同的模型、数据、初始化条件下,只改变 learning rate scheduler,观察训练动力学差异
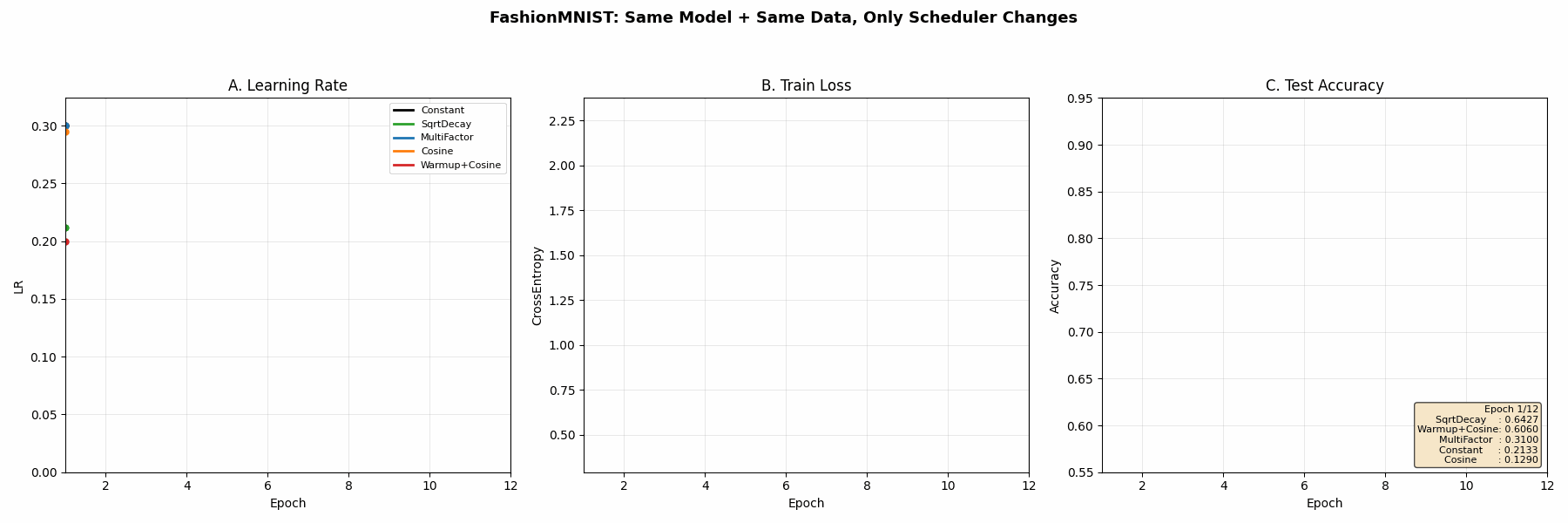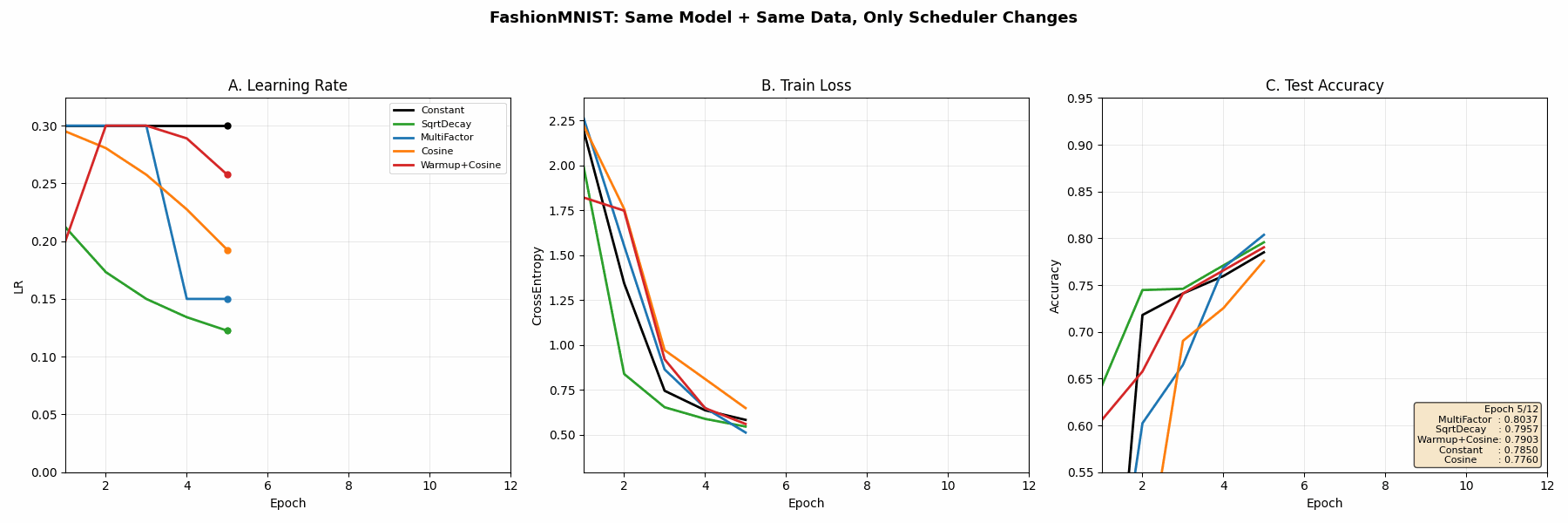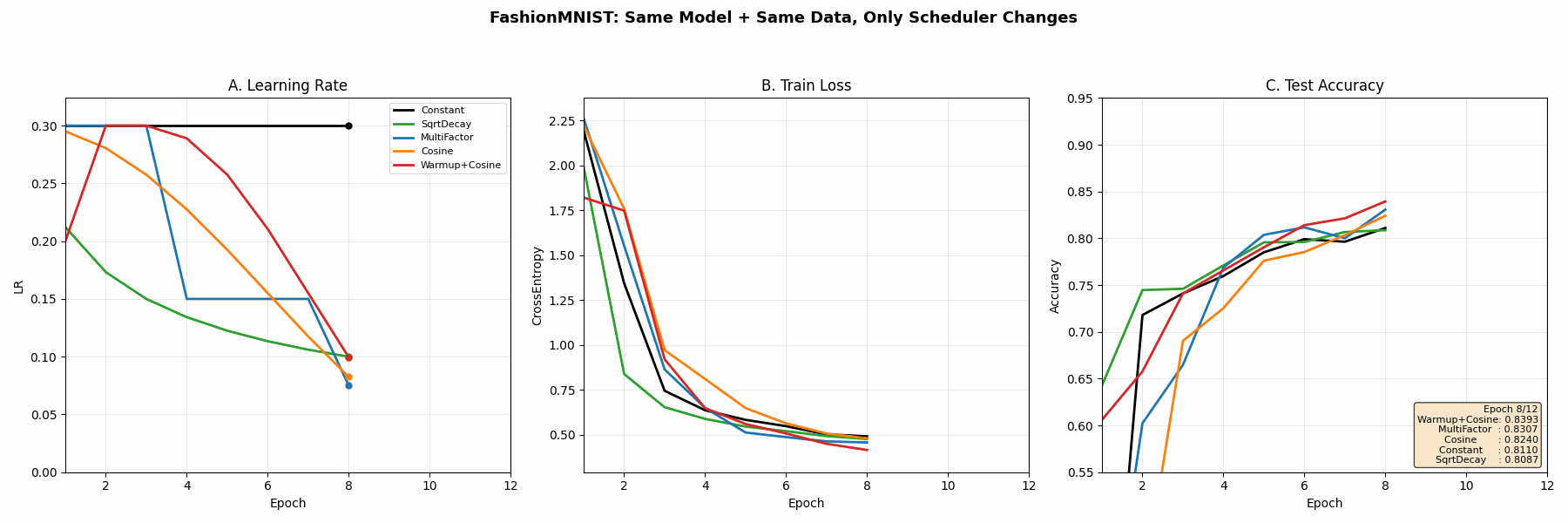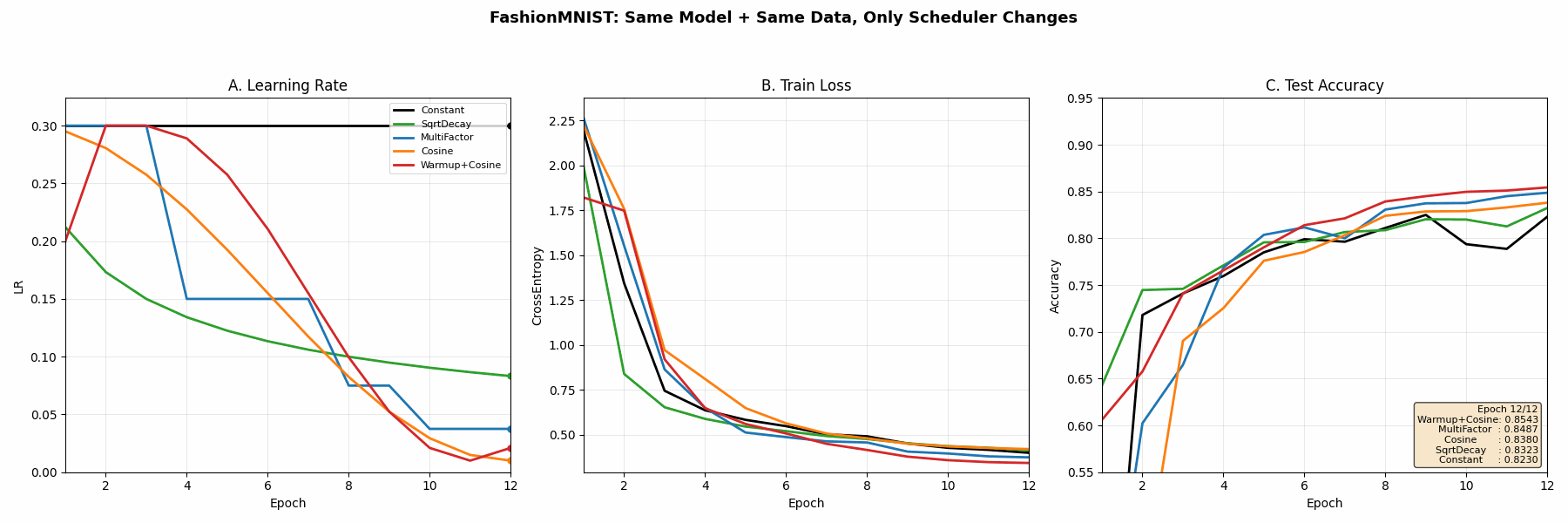
动画三个面板分别对应:
- A 学习率曲线形状(公式可视化)
- B 训练 Loss(收敛速度与稳定性)
- C 测试准确率(泛化与过拟合的差异)
结论
| Scheduler | 最终 test_acc | 核心行为 | 章节结论 |
|---|---|---|---|
| Constant | 0.823 | 学习率固定 | 学习率过大 → 后期震荡明显,收敛不稳定 |
| SqrtDecay | 0.832 | 平滑逐步衰减(~1/√t) | 收敛稳定,但衰减过早,后期学习能力不足 |
| MultiFactor | 0.849 | 分阶段阶梯下降 | 等待loss平台期再降lr,收敛效果较好 |
| Cosine | 0.838 | 余弦式平滑下降 | 学习率变化平滑,训练过程最“连续” |
| Warmup + Cosine | 0.854 | 先升后降 | 前期稳定 + 后期精细收敛,综合最优 |
🔵 结论 1:Constant 不稳定
本质:
学习率不变 → 无法适配训练阶段变化
表现:
前期慢
后期震荡
🔵 结论 2:Step / MultiFactor 最实用
本质:
“等模型稳定后再降低学习率”
特点:
工业最常用
不依赖连续函数假设
🔵 结论 3:Warmup + Cosine 最优
本质:
👉 “前期避免梯度爆炸 + 后期平滑收敛”
这是 Transformer 标配