模型训练
# Transformer主干超参数:隐藏维、层数、dropout,以及数据批处理设置
num_hiddens, num_layers, dropout, batch_size, num_steps = 32, 2, 0.1, 64, 10
# 优化与训练轮次配置;设备优先使用GPU
lr, num_epochs, device = 0.005, 10, d2l.try_gpu()
# 前馈网络与多头注意力配置
ffn_num_input, ffn_num_hiddens, num_heads = 32, 64, 4
# Q/K/V投影维度(当前实现保持一致)
key_size, query_size, value_size = 32, 32, 32
# LayerNorm归一化维度
norm_shape = [32]
# 加载NMT训练数据与词表
train_iter, src_vocab, tgt_vocab = d2l.load_data_nmt(batch_size, num_steps)
# 根据TRAIN_LOG_CFG决定是否启用“终端+文件”双写日志
enable_file_logging_if_needed()
# 构建编码器与解码器
encoder = TransformerEncoder(
len(src_vocab), key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,
num_layers, dropout)
decoder = TransformerDecoder(
len(tgt_vocab), key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,
num_layers, dropout)
# 组装Seq2Seq整体模型(Encoder-Decoder)
net = d2l.EncoderDecoder(encoder, decoder)
# 执行训练(内部含分层训练日志)
train_seq2seq_with_planned_logs(
net, train_iter, lr, num_epochs, src_vocab, tgt_vocab, device)
实现了一个 带完整可观测日志的 Transformer Seq2Seq(机器翻译模型)
整体训练流程(首轮)
======================== 训练开始(Epoch 1 / Batch 1) ========================
【输入数据】
src (源语言token id) tgt (目标语言token id)
(64, 10) (64, 10)
│ │
│ └──► 右移 + <bos>
│ (作用:构造Decoder输入,
│ 实现Teacher Forcing)
│
▼
======================== Encoder(语义理解) ========================
Embedding
│
├──► (64,10) → (64,10,32)
│ (作用:把离散token映射到连续向量空间)
│
▼
× √d_model
│
├──► (作用:放大embedding数值,
│ 防止位置编码被“淹没”)
│
▼
+ Positional Encoding
│
├──► (作用:注入位置信息,
│ 否则模型不知道词序)
│
▼
X0(带语义+位置的信息表示)
│
▼
-------------------- Encoder Block 0 --------------------
Multi-Head Self Attention(自注意力)
│
├──► Q = XWq, K = XWk, V = XWv
│ (作用:把输入投影到“查询/键/值”空间)
│
├──► QK^T / √d
│ (作用:计算“相关性/相似度”)
│
├──► softmax
│ (作用:变成概率分布=注意力权重)
│
├──► attention_weights @ V
│ (作用:加权汇总全局信息)
│
▼
attn_out(融合上下文后的表示)
AddNorm1(残差 + 归一化)
│
├──► X + attn_out
│ (作用:保留原信息,避免信息丢失)
│
├──► LayerNorm
│ (作用:稳定训练,防止梯度爆炸)
│
▼
Y
FFN(前馈网络)
│
├──► dense1 → ReLU → dense2
│ (作用:引入非线性,提高表达能力)
│
▼
ffn_out
AddNorm2
│
├──► Y + ffn_out
│ (作用:再次融合 & 稳定)
│
▼
X1(Block0输出)
-------------------- Encoder Block 1 --------------------
(作用完全相同,但语义更抽象、更高级)
X1 → Self-Attn → AddNorm → FFN → AddNorm → X2
│
▼
X_enc(Encoder最终输出)
(作用:整句的“上下文语义表示”)
==================================================================
======================== Decoder(逐词生成) ========================
Decoder 输入(右移后的tgt)
│
▼
Embedding → √d → +位置编码
│
▼
D0
-------------------- Decoder Block 0 --------------------
Masked Self Attention(带mask的自注意力)
│
├──► 只能看过去(下三角mask)
│ (作用:防止“偷看未来词”)
│
▼
AddNorm1
│
▼
Cross Attention(编码器-解码器注意力)🔥关键
│
├──► Query = Decoder当前状态
├──► Key/Value = Encoder输出
│
├──► (作用:在“源句子”中找当前词对应的信息)
│
▼
AddNorm2
FFN
│
├──► (作用:非线性变换,增强表达)
│
▼
AddNorm3
│
▼
D1
-------------------- Decoder Block 1 --------------------
(同上,进一步 refinement)
D1 → MaskedAttn → CrossAttn → FFN → D2
│
▼
======================== 输出层 ========================
Linear(全连接)
│
├──► (64,10,32) → (64,10,vocab_size)
│
├──► (作用:映射到词表空间,得到每个词的概率)
│
▼
logits
Softmax + Loss
│
├──► MaskedSoftmaxCELoss
│
├──► (作用:计算预测与真实token的差异)
│
▼
loss
==================================================================
======================== 反向传播 ========================
loss
│
├──► 反向传播梯度
│
├──► 更新:
│ - embedding
│ - attention权重
│ - FFN参数
│
▼
模型参数更新(学习完成一步)
==================================================================
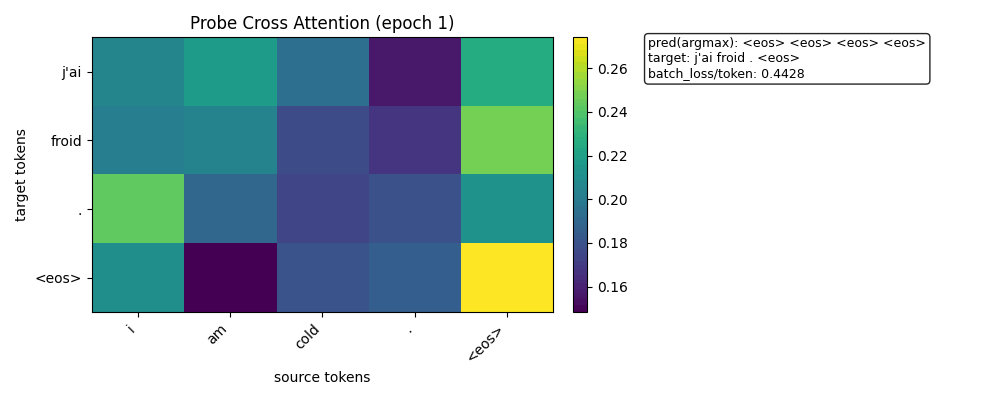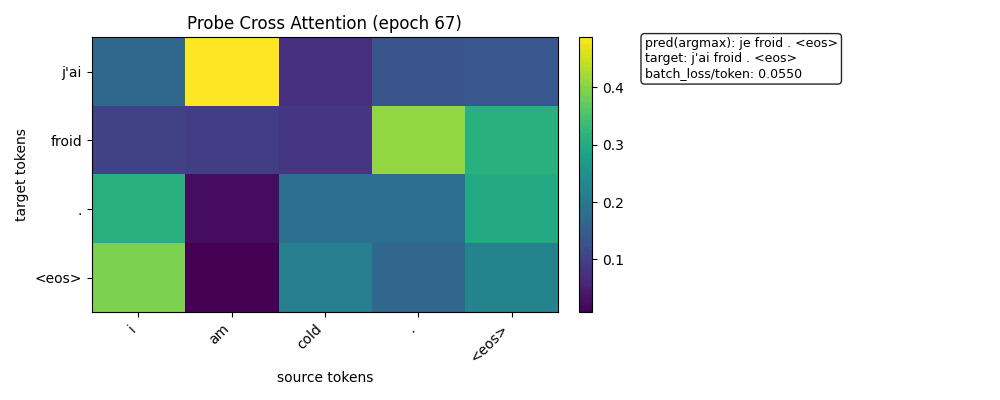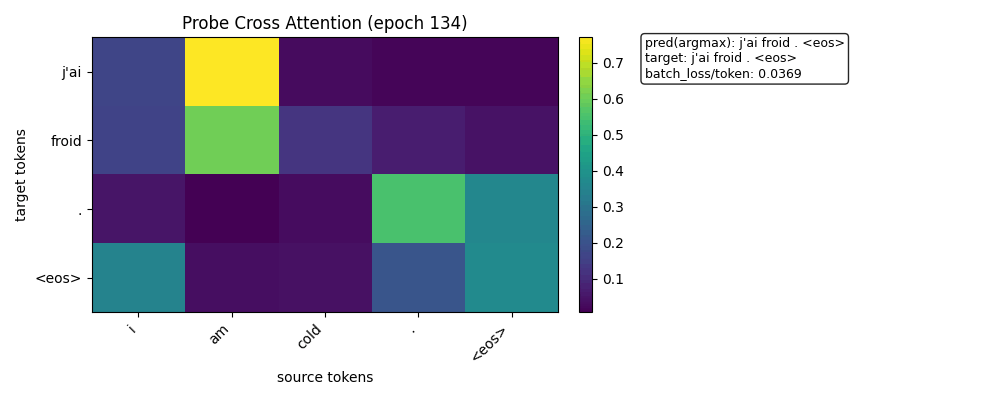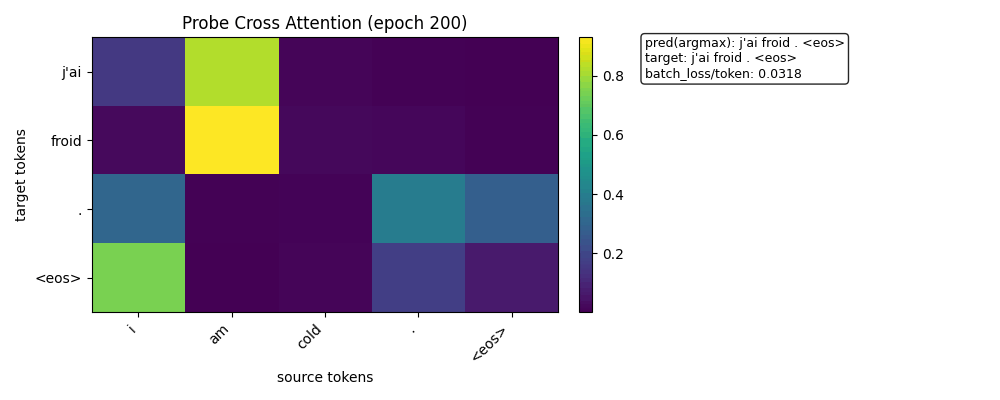
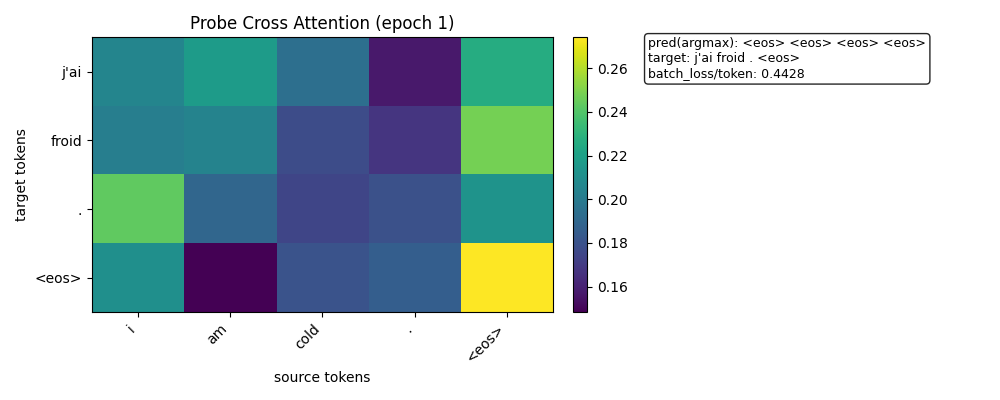
热力图
训练开始时的热力图
训练结束时的热力图
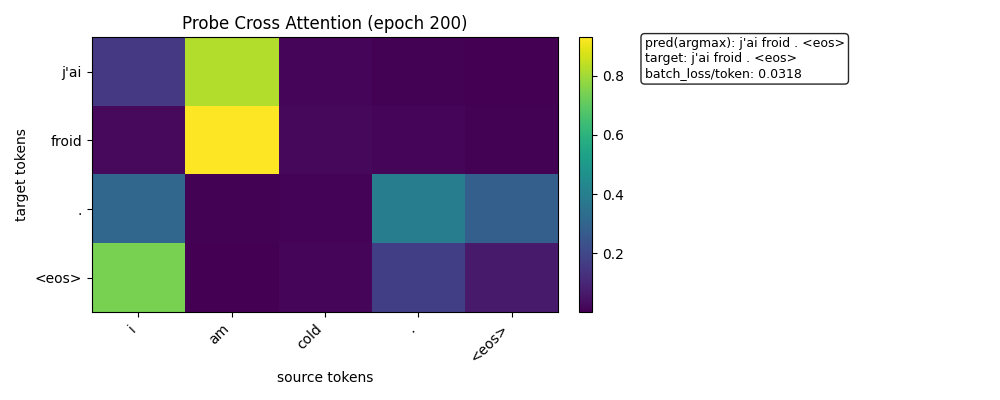
预测结果已经完全正确
pred: j'ai froid . <eos>
target: j'ai froid . <eos>
loss: 0.0318
👉 说明:
✔ translation 已收敛 ✔ sequence-level correct ✔ EOS 处理稳定
attention 变“更尖锐”
“froid”这一行:
几乎完全指向 “am”
权重非常集中(接近 one-hot)
👉 说明:
模型已经从“分布式对齐” → “确定性对齐”
attention ≠ reasoning
❗ attention ≠ reasoning
你现在看到:
attention 很漂亮
对齐很稳定
loss 很低
但本质是:
模型在做 lookup table,而不是理解语言
其他曲线
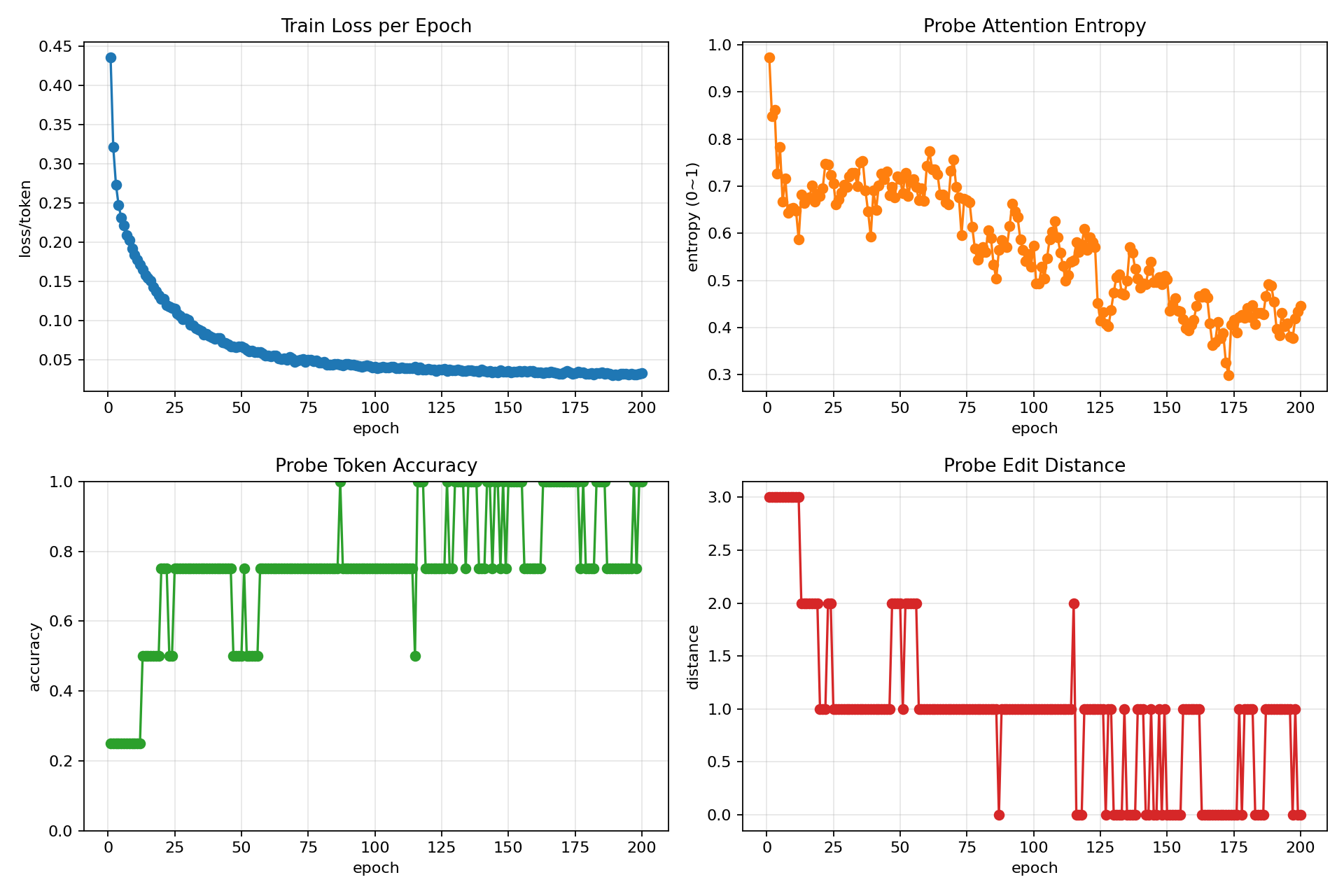
左上图:Train Loss per Epoch
- 纵轴:loss/token(每个 token 的平均损失)
- 含义:整体训练效果的第一指标。如果曲线持续下降,说明模型正在学习;如果进入平台期或反弹,说明可能过拟合或学习卡住了。
- 理想状态:单调下降(越陡越好),最后趋于平缓且稳定。
右上图:Probe Attention Entropy
- 纵轴:entropy(0~1)
- 含义:固定”I am cold”样本的 cross-attention 熵。熵越小,说明模型对这个样本的注意力越集中;熵越大,说明注意力分散。
- 理想状态:从高向低递减。早期模型不知道看哪儿,注意力很平均(熵大);训练后逐渐学会集中关注(熵小)。
- 提示:与 loss 曲线要相关。如果 loss 下降但熵没下降,说明模型是靠”死记”一些高频词;如果熵下降但 loss 反弹,说明”过度集中”导致泛化变差。
左下图:Probe Token Accuracy
- 纵轴:accuracy(0~1)
- 含义:固定样本在每个 epoch 的逐 token 命中率(预测=真实标签 的比例)。
- 理想状态:从 0 上升到接近 1。这是最直观的翻译质量指标。
- 提示:这条线通常在整个图中涨幅最明显。如果它一直在低位,说明模型可能无法很好地学会这个具体翻译对。
右下图:Probe Edit Distance
- 纵轴:distance(编辑距离,取值为整数)
- 含义:预测序列与真实序列的 Levenshtein 距离(最少需要多少次插入/删除/替换才能把预测改成真实)。
- 理想状态:从高向低递减,最后降到 0(预测 = 真实)。
- 提示:这比逐 token 准确率更宽松:允许位置偏移、少个几个词等,但整体衡量句子级别差距。
模型保存
| 文件/内容 | 是否必须 | 文件形式示例 | 作用 | 推理阶段用在哪 | 备注 |
|---|---|---|---|---|---|
| 模型权重(state_dict) | ⭐⭐⭐⭐⭐ 必须 | model_weights.pth |
存储所有层参数 | load_state_dict() |
不能缺 |
| 模型结构配置(hparams) | ⭐⭐⭐⭐⭐ 必须 | dict / json | 重建模型结构 | 初始化 Encoder/Decoder | 层数/hidden/head |
| 源语言词表(src_vocab) | ⭐⭐⭐⭐⭐ 必须 | pickle / torch | 文本 → token id | 输入编码 | 不可缺 |
| 目标语言词表(tgt_vocab) | ⭐⭐⭐⭐⭐ 必须 | pickle / torch | token id → 文本 | 输出解码 | 不可缺 |
| tokenizer规则 | ⭐⭐⭐⭐ 建议 | json | 分词规则 | 文本预处理 | 你现在是简单split |
| 特殊token定义 | ⭐⭐⭐⭐ 建议 | json | <bos>/<eos>/<pad> |
编码/解码控制 | 很重要 |
| 完整checkpoint | ⭐⭐⭐⭐⭐ 推荐 | xxx_inference_ckpt.pth |
一次性打包所有内容 | 一步加载 | 你已经实现 👍 |
| ONNX模型 | ⭐⭐⭐(部署) | model.onnx |
跨平台推理 | 嵌入式/加速 | RK3568用 |
| 推理脚本 | ⭐⭐⭐⭐ 建议 | infer.py |
串起整个流程 | 实际调用 | 工程必须 |
模型推理
import argparse
from pathlib import Path
import torch
from d2l import torch as d2l
from demo_04 import TransformerEncoder, TransformerDecoder
def resolve_ckpt_path(user_ckpt_arg):
"""解析checkpoint路径:优先用户指定,其次脚本目录与当前目录兜底。
路径优先级:
1) --ckpt 显式传入的路径(最优先)
2) 推理脚本同目录下的 demo_04_inference_ckpt.pth
3) 当前工作目录下的 demo_04_inference_ckpt.pth
"""
if user_ckpt_arg:
return Path(user_ckpt_arg)
candidates = [
Path(__file__).with_name("demo_04_inference_ckpt.pth"),
Path.cwd() / "demo_04_inference_ckpt.pth",
]
for p in candidates:
if p.exists():
return p
return candidates[0]
def build_model_from_hparams(src_vocab, tgt_vocab, hparams):
"""按checkpoint中的超参数重建网络结构。
hparams 字段逐项说明(与训练侧保持一致):
- key_size: 注意力中 Key 的投影维度
- query_size: 注意力中 Query 的投影维度
- value_size: 注意力中 Value 的投影维度
- num_hiddens: Transformer隐藏维度(embedding和各层主通道维度)
- norm_shape: LayerNorm 的归一化维度,通常是 [num_hiddens]
- ffn_num_input: PositionWiseFFN 输入维度(一般与 num_hiddens 一致)
- ffn_num_hiddens: PositionWiseFFN 中间隐藏层维度
- num_heads: 多头注意力头数
- num_layers: 编码器/解码器堆叠层数
- dropout: dropout 概率(推理时虽然eval会关闭dropout,但结构需一致)
"""
# 1) 构建编码器:超参数必须与训练时一致,否则权重shape无法匹配
encoder = TransformerEncoder(
len(src_vocab),
hparams["key_size"],
hparams["query_size"],
hparams["value_size"],
hparams["num_hiddens"],
hparams["norm_shape"],
hparams["ffn_num_input"],
hparams["ffn_num_hiddens"],
hparams["num_heads"],
hparams["num_layers"],
hparams["dropout"],
)
# 2) 构建解码器:同样要求结构完全一致
decoder = TransformerDecoder(
len(tgt_vocab),
hparams["key_size"],
hparams["query_size"],
hparams["value_size"],
hparams["num_hiddens"],
hparams["norm_shape"],
hparams["ffn_num_input"],
hparams["ffn_num_hiddens"],
hparams["num_heads"],
hparams["num_layers"],
hparams["dropout"],
)
# 3) 封装为 D2L 的 EncoderDecoder 总体模型
return d2l.EncoderDecoder(encoder, decoder)
def load_model_and_vocab(ckpt_path, device):
"""加载推理checkpoint,返回模型与词表。
返回值:
- net: 已加载权重并切到 eval() 的模型
- src_vocab: 源语言词表(英文)
- tgt_vocab: 目标语言词表(法文)
- hparams: 训练时保存的模型超参数
"""
# PyTorch 2.6 起 torch.load 默认 weights_only=True。
# 本地训练生成的checkpoint包含词表对象(如 d2l.Vocab),
# 推理时需要显式关闭 weights_only 才能反序列化完整内容。
try:
ckpt = torch.load(ckpt_path, map_location=device, weights_only=False)
except TypeError:
# 兼容旧版本PyTorch(没有 weights_only 参数)
ckpt = torch.load(ckpt_path, map_location=device)
src_vocab = ckpt["src_vocab"]
tgt_vocab = ckpt["tgt_vocab"]
hparams = ckpt["hparams"]
net = build_model_from_hparams(src_vocab, tgt_vocab, hparams)
net.load_state_dict(ckpt["model_state_dict"])
net.to(device)
net.eval()
return net, src_vocab, tgt_vocab, hparams
def run_d2l_demo(ckpt_path, device):
"""按D2L章节示例风格执行多句推理并计算BLEU。
说明:
- engs: 待翻译的英文句子(源语言)
- fras: 对应参考法语(用于计算BLEU,不参与模型推理)
- d2l.predict_seq2seq:
输入英文句子后,按自回归方式逐token生成法语结果
- d2l.bleu(..., k=2):
计算2-gram BLEU,数值越高表示与参考翻译越接近
"""
net, src_vocab, tgt_vocab, hparams = load_model_and_vocab(ckpt_path, device)
engs = ["go .", "i lost .", "he's calm .", "i'm home ."]
fras = ["va !", "j'ai perdu .", "il est calme .", "je suis chez moi ."]
for eng, fra in zip(engs, fras):
translation, _ = d2l.predict_seq2seq(
net,
eng,
src_vocab,
tgt_vocab,
hparams["num_steps"],
device,
save_attention_weights=True,
)
print(f"{eng} => {translation}, bleu {d2l.bleu(translation, fra, k=2):.3f}")
def print_hparams_guide(hparams):
"""把checkpoint中的超参数逐项打印,便于理解推理模型配置。"""
desc = {
"num_hiddens": "隐藏维度/主通道维度(embedding与Transformer内部特征维)",
"num_layers": "编码器层数与解码器层数(均为该值)",
"dropout": "dropout概率(训练中生效,推理eval后自动关闭)",
"batch_size": "训练时batch大小(推理单句时不强依赖)",
"num_steps": "最大时间步/最大序列长度(推理解码上限)",
"lr": "训练学习率(仅记录,不影响推理)",
"num_epochs": "训练轮数(仅记录,不影响推理)",
"ffn_num_input": "前馈网络输入维度",
"ffn_num_hiddens": "前馈网络隐藏层维度",
"num_heads": "多头注意力头数",
"key_size": "注意力Key投影维度",
"query_size": "注意力Query投影维度",
"value_size": "注意力Value投影维度",
"norm_shape": "LayerNorm归一化维度",
}
print("[INFER] ====== checkpoint 超参数说明 ======")
for k, v in hparams.items():
meaning = desc.get(k, "(未定义说明)")
print(f"[INFER] {k} = {v} # {meaning}")
print("[INFER] =================================")
def main():
parser = argparse.ArgumentParser(description="demo_04 推理脚本")
parser.add_argument(
"--ckpt",
type=str,
default=None,
help="推理checkpoint路径",
)
parser.add_argument(
"--text",
type=str,
default="i am cold .",
help="待翻译英文句子(建议按训练数据风格:小写+空格分词)",
)
parser.add_argument(
"--demo",
action="store_true",
help="使用D2L示例句批量推理并输出BLEU",
)
parser.add_argument(
"--show-hparams",
action="store_true",
help="启动时打印checkpoint中的超参数及中文解释",
)
args = parser.parse_args()
ckpt_path = resolve_ckpt_path(args.ckpt)
if not ckpt_path.exists():
raise FileNotFoundError(
f"checkpoint不存在: {ckpt_path};请用 --ckpt 指定,例如 "
f"/home/lxg/code/AI/code/20260425/demo_04_inference_ckpt.pth"
)
device = d2l.try_gpu()
print(f"[INFER] 使用设备: {device}")
print(f"[INFER] 加载checkpoint: {ckpt_path}")
# 可选:先打印超参数说明,帮助理解当前推理模型的配置
if args.show_hparams:
_, _, _, hparams = load_model_and_vocab(str(ckpt_path), device)
print_hparams_guide(hparams)
run_d2l_demo(str(ckpt_path), device)
if __name__ == "__main__":
main()
模型推理过程
┌──────────────────────────────────────────────┐
│ 输入英文句子 │
│ "i am cold ." │
└──────────────────────────────────────────────┘
│
▼
┌──────────────────────────────────────────────┐
│ 文本预处理(tokenizer) │
│ lower + split → ["i","am","cold","."] │
│ + <eos> → ["i","am","cold",".","<eos>"] │
└──────────────────────────────────────────────┘
│
▼
┌──────────────────────────────────────────────┐
│ token → id(src_vocab) │
│ ["i","am","cold","."] │
│ ↓ │
│ [17, 25, 98, 4, 2] │
└──────────────────────────────────────────────┘
│
▼
┌──────────────────────────────────────────────┐
│ padding + 截断 │
│ → 固定长度 num_steps (如10) │
│ [17,25,98,4,2,0,0,0,0,0] │
│ valid_len = 5 │
└──────────────────────────────────────────────┘
│
▼
==================== Encoder ====================
┌──────────────────────────────────────────────┐
│ Embedding(词嵌入) │
│ (1,10) → (1,10,32) │
│ 每个token变成向量 │
└──────────────────────────────────────────────┘
│
▼
┌──────────────────────────────────────────────┐
│ 加位置编码 PositionalEncoding │
│ 加入位置信息(顺序感) │
└──────────────────────────────────────────────┘
│
▼
┌──────────────────────────────────────────────┐
│ Encoder Block × N(比如2层) │
│ │
│ 每一层: │
│ 1️⃣ 自注意力(Self-Attention) │
│ 👉 每个词看所有词 │
│ 2️⃣ Add & Norm │
│ 3️⃣ FFN(逐位置MLP) │
│ 4️⃣ Add & Norm │
└──────────────────────────────────────────────┘
│
▼
┌──────────────────────────────────────────────┐
│ Encoder输出 enc_outputs │
│ shape: (1,10,32) │
└──────────────────────────────────────────────┘
==================== Decoder ====================
初始输入:
┌──────────────────────────────────────────────┐
│ dec_input = ["<bos>"] │
└──────────────────────────────────────────────┘
│
▼
🔁 逐token生成(循环 num_steps 次)
┌──────────────────────────────────────────────┐
│ Embedding + 位置编码 │
└──────────────────────────────────────────────┘
│
▼
┌──────────────────────────────────────────────┐
│ Decoder Block × N │
│ │
│ 每一层: │
│ │
│ 1️⃣ Masked Self-Attention │
│ 👉 只能看“已经生成的词” │
│ │
│ 2️⃣ Cross Attention(重点!) │
│ 👉 decoder 看 encoder 输出 │
│ 👉 学习翻译对齐关系 │
│ │
│ 3️⃣ FFN │
└──────────────────────────────────────────────┘
│
▼
┌──────────────────────────────────────────────┐
│ 线性层(投影到词表) │
│ (1, t, 32) → (1, t, vocab_size) │
└──────────────────────────────────────────────┘
│
▼
┌──────────────────────────────────────────────┐
│ Softmax + argmax │
│ 选出概率最大token │
└──────────────────────────────────────────────┘
│
▼
┌──────────────────────────────────────────────┐
│ 输出一个token(例如 "j'") │
└──────────────────────────────────────────────┘
│
▼
┌──────────────────────────────────────────────┐
│ 拼接到输入 → ["<bos>", "j'"] │
│ 继续下一轮生成 │
└──────────────────────────────────────────────┘
🔁 重复直到:
┌──────────────────────────────────────────────┐
│ 遇到 <eos> 或 达到最大长度 │
└──────────────────────────────────────────────┘
==================== 输出 ====================
┌──────────────────────────────────────────────┐
│ token id → 文本(tgt_vocab) │
│ [5, 88, 23, 2] → "j'ai froid ." │
└──────────────────────────────────────────────┘
│
▼
┌──────────────────────────────────────────────┐
│ 最终翻译输出 │
│ "j'ai froid ." │
└──────────────────────────────────────────────┘
0
次点赞