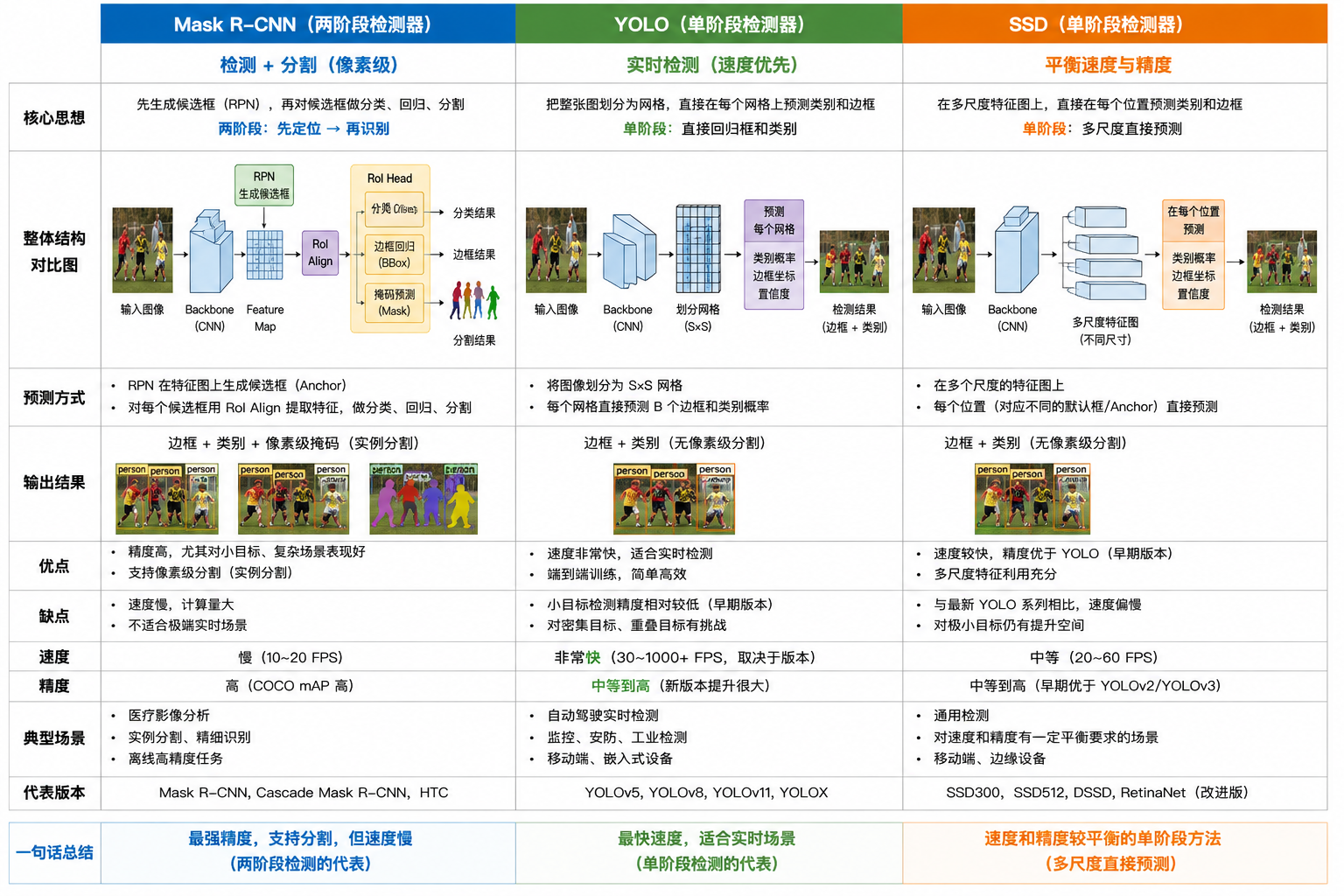
单发多框检测
经典目标检测模型 SSD(Single Shot MultiBox Detector,单发多框检测)
输入图像
│
▼
Backbone(VGG16)
│
├──────── Conv4_3 ──┬─ cls conv
│ └─ bbox conv
│
├──────── Conv7 ────┬─ cls conv
│ └─ bbox conv
│
├──────── Conv8_2 ──┬─ cls conv
│ └─ bbox conv
│
├──────── Conv9_2 ──┬─ cls conv
│ └─ bbox conv
│
├──────── Conv10_2 ─┬─ cls conv
│ └─ bbox conv
│
└──────── Conv11_2 ─┬─ cls conv
└─ bbox conv
所有输出拼接
│
▼
NMS去重
│
▼
最终检测框
| 层 | 尺寸 | 通道 |
|---|---|---|
| Conv4_3 | 38×38 | 512 |
| Conv7 | 19×19 | 1024 |
| Conv8_2 | 10×10 | 512 |
| Conv9_2 | 5×5 | 256 |
| Conv10_2 | 3×3 | 256 |
| Conv11_2 | 1×1 | 256 |
区域卷积神经网络(R-CNN)系列
R-CNN
🔧 流程
- 用 Selective Search 生成 ~2000 个候选区域(ROI)
- 每个 ROI 单独裁剪 → 单独过 CNN
- 提特征
- 两个模型:
- SVM 做分类
- 回归器做框修正
❌ 问题(关键)
- 🚨 重复计算严重(每个框都跑 CNN)
- 🚨 非端到端(CNN + SVM + 回归分离)
- 🚨 极慢(工业不可用)
👉 本质: “暴力滑窗 + 深度学习特征”
Fast R-CNN:共享卷积
🔧 核心改进
👉 整张图只做一次 CNN
流程:
- 整图 → CNN → feature map
- ROI 在 feature map 上取区域
- 用 RoI Pooling
- 全连接层输出:
- 分类(softmax)
- bbox 回归
🚀 关键提升
- ✔ CNN 计算共享(大幅加速)
- ✔ 端到端训练(不用 SVM)
- ✔ 精度提升
❗ 仍然的问题
- Proposal(候选框)还是 Selective Search(非学习)
- ROI Pooling 有量化误差(后面 Mask R-CNN 才解决)
Faster R-CNN:引入“神经网络提框”
- Selective Search = 人工规则“拼拼图找目标”
- RPN = 让神经网络自己学会“哪里可能有物体”
| 维度 | Selective Search | RPN |
|---|---|---|
| 思想 | 人工规则 | 深度学习 |
| 是否学习 | ❌ 否 | ✅ 是 |
| 速度 | 慢 | 快 |
| 是否理解语义 | ❌ 不理解 | ✅ 理解 |
| 生成方式 | 逐步合并区域 | anchor预测 |
| 可优化性 | 不可 | 可训练 |
输入图像
↓
Backbone CNN(一次)
↓
Feature Map
↓
┌───────────────┐
│ RPN │ ← 先运行
│ 生成 proposals │
└───────┬───────┘
↓
候选框 proposals
↓
┌───────────────┐
│ RoI Head │ ← 后运行
│ 分类 + 回归 │
└───────────────┘
Mask R-CNN:进入像素级任务
┌──────────────────────┐
│ 输入图像 │
└─────────┬────────────┘
│
▼
┌─────────────────────────────────────┐
│ Backbone CNN(ResNet等) │
│ 提取 feature map(一次计算) │
└─────────────────────────────────────┘
│
▼
┌────────────────┐
│ Feature Map │
└───────┬────────┘
│
┌────────────────┼────────────────┐
│ │
▼ ▼
┌────────────────────┐ ┌──────────────────────┐
│ RPN │ │ RoI Align │
│ 生成候选框 proposals │ │(精确对齐特征裁剪) │
└─────────┬──────────┘ └─────────┬────────────┘
│ │
▼ ▼
┌──────────────────┐ ┌────────────────────────┐
│ proposals boxes │──────▶│ RoI features │
└──────────────────┘ └──────────┬─────────────┘
│
▼
┌──────────────────────────┐
│ RoI Head(共享) │
│ 分类 + bbox回归 + mask │
└──────────┬──────────────┘
│
┌────────────────────────────┼────────────────────────────┐
│ │ │
▼ ▼ ▼
┌────────────────┐ ┌────────────────────┐ ┌────────────────────┐
│ Classification │ │ bbox Regression │ │ Mask Branch │
│ softmax类别 │ │ 框精修 │ │ 像素级分割图 │
└────────────────┘ └────────────────────┘ └────────────────────┘
│
▼
┌────────────────────────┐
│ K×m×m mask(每类一张) │
└────────────────────────┘
Mask R-CNN 在 Faster R-CNN 基础上,引入 RoI Align 保证特征对齐,并增加 mask 分支,实现目标检测与像素级实例分割的统一框架。
对比
| 模型 | 输入 | 输出 | 核心任务 |
|---|---|---|---|
| YOLO / SSD | image | bbox + class | 检测 |
| Faster R-CNN | image | bbox + class | 两阶段检测 |
| Mask R-CNN | image | bbox + mask | 实例分割 |
| SAM3 | image + prompt | mask | 交互式分割 |
语义分割和数据集
语义分割在做什么?
语义分割的目标是:给图像中的每一个像素分配一个类别标签
比如:
- 人
- 汽车
- 背景
- 树
- 道路
| 任务 | 输出 |
|---|---|
| 分类 | 一个类别 |
| 检测 | 框 + 类别 |
| 语义分割 | 每个像素的类别 |
📌 本质:👉 “从 object-level → pixel-level 理解”
语义分割 vs 实例分割
语义分割(Semantic Segmentation)
- 同一类别的所有目标 不区分个体
- 例如:两个人 → 都标成 “person”
- 输出:每个像素一个 class id
实例分割(Instance Segmentation)
- 不仅分类别,还区分“个体”
- 例如:person1 / person2 / person3
👉 Mask R-CNN 属于实例分割方向
不同任务对比
| 任务 | label 类比 |
|---|---|
| 分类 | 一张图一个答案(考试打分) |
| 检测 | 每个物体一个框(圈重点) |
| 分割 | 每个像素都要批改(逐字批改作文) |
主流语义分割模型
| 模型 | 类型 | 优点 | 缺点 |
|---|---|---|---|
| FCN | CNN | 简单 | 粗糙 |
| U-Net | CNN | 边界好 | 计算重 |
| DeepLabv3+ | CNN | 多尺度强 | 复杂 |
| BiSeNet | CNN | 实时 | 精度略低 |
| SegFormer | Transformer | 强泛化 | 新体系 |
| Mask2Former | Transformer | 最强统一框架 | 复杂 |
运营商IDC 和 云厂商差异
应用层(Agent / AI SaaS)
↓
云厂商(AWS / 阿里云)
┌─────────────────────────┐
│ 计算调度 / GPU池 / API │
└─────────────────────────┘
↓
运营商IDC(联通等)
┌─────────────────────────┐
│ 机房 / 电力 / 网络 │
└─────────────────────────┘
↓
电力系统
运营商不是不想做云,而是:他们的商业模型、组织结构、技术基因决定了“更适合卖管道,不适合做操作系统”。
运营商现在都有:
- 云计算公司(天翼云等)
- IDC云化平台
- 政务云
但问题是: 他们做的是“云服务”,不是“云操作系统”
托管(Colocation / IDC托管)
✔️ 自己买服务器 ✔️ 放进联通/电信机房 ✔️ 付机柜、电力、带宽费用
转置卷积
- 普通卷积: 输入大图 → 卷积核滑动 → 输出小特征图 👉 信息被“压缩”
- 转置卷积: 输入小特征图 → “扩散/铺开” → 输出大特征图 👉 信息被“展开”
对比
| 维度 | 🟦 普通卷积(Convolution) | 🟧 转置卷积(Transposed Conv) |
|---|---|---|
| 核心作用 | 提取特征 / 压缩空间 | 放大特征 / 还原空间 |
| 输入输出 | 大图 → 小图 | 小图 → 大图 |
| 空间变化 | ↓ 下采样 | ↑ 上采样 |
| 参数学习 | ✔ 可学习卷积核 | ✔ 可学习上采样方式 |
| 信息变化 | 信息压缩(更抽象) | 信息展开(更空间化) |
| 计算本质 | 滑动窗口加权求和 | “扩散 + 叠加”的反向映射 |
| 是否可逆 | ❌ 不可逆 | ❌ 也不是严格逆运算 |
| 典型用途 | 分类 / 检测 backbone | 分割 / 生成 / 超分辨率 |
| 优点 | - 特征提取强 - 计算高效 - 参数共享 |
- 可学习上采样 - 保留语义结构 - 端到端训练 |
| 缺点 | - 丢空间信息 | - 易产生棋盘格 artifact - 结构不稳定 |
| 常见替代 | — | bilinear+conv / PixelShuffle |
| 工业使用频率 | ⭐⭐⭐⭐⭐(必备) | ⭐⭐⭐(谨慎使用) |
全卷积网络
FCN = 用“纯卷积网络 + 上采样”,实现像素级分类(语义分割)
输入图像
↓
卷积网络(VGG/ResNet)
↓
低分辨率语义特征图
↓
1×1卷积(分类)
↓
转置卷积(上采样)
↓
像素级分类结果(输出分割图)
| 维度 | 🟢 优点 | 🔴 缺点 |
|---|---|---|
| 架构思想 | 首个“全卷积化”端到端分割模型 | 结构较早期,设计较粗糙 |
| 输入灵活性 | ✔ 可接受任意尺寸输入 | — |
| 输出能力 | ✔ 像素级预测(dense prediction) | — |
| 训练方式 | ✔ 端到端训练(输入图→输出mask) | — |
| 上采样方式 | ✔ 使用转置卷积恢复分辨率 | ❌ 容易产生棋盘格 artifacts |
| 语义能力 | ✔ 深层特征具备较强语义信息 | ❌ 边界细节恢复较差 |
| 多尺度信息 | ✔ FCN-8s 引入 skip connection | ❌ 融合方式较简单 |
| 计算复杂度 | ✔ 相对简单、易实现 | ❌ 上采样阶段计算开销较大 |
| 精度表现 | ✔ 相比分类网络大幅提升 | ❌ 不如后续 U-Net / DeepLab |
| 工业实用性 | ✔ 奠定语义分割基础 | ❌ 已逐步被更优架构替代 |
风格迁移


【输入阶段】
内容图 + 风格图
↓
选择预训练CNN(VGG-19)
↓
冻结网络参数(不训练模型)
────────────────────────────
【初始化】
生成图 x(通常 = 内容图 / 或噪声)
↓
x = 可优化变量(image parameter)
────────────────────────────
【前向传播】
内容图 ─────────→ CNN → 内容特征(高层)
风格图 ─────────→ CNN → 多层风格特征
生成图 x ───────→ CNN → 当前特征
────────────────────────────
【损失计算】
① 内容损失(Content Loss)
|| F_gen^high - F_content^high ||²
👉 保结构(人/物/场景)
────────────────────────────
② 风格损失(Style Loss)
Gram(F_gen^l) vs Gram(F_style^l)
Gram(F) = F · Fᵀ
👉 保纹理 / 笔触 / 风格统计
────────────────────────────
③ 平滑损失(TV Loss)
邻域像素差异
👉 去噪 / 防棋盘纹理
────────────────────────────
【总损失函数】
L = α·Content + β·Style + γ·TV
────────────────────────────
【反向传播】
固定CNN参数
↓
计算 ∂L/∂x
↓
更新生成图 x(梯度下降)
────────────────────────────
【迭代优化】
x₀ → x₁ → x₂ → ... → xₙ
↓
内容越来越稳定
风格越来越明显
噪声逐渐减少
────────────────────────────
【输出结果】
生成图像:
✔ 内容结构保持
✔ 风格纹理迁移
✔ 艺术化融合完成
神经风格迁移 = 把一张“白纸”,不断修改,直到它同时像两张图
| 维度 | 🟦 训练出的模型(Task-specific) | 🟧 预训练模型(Feature extractor) |
|---|---|---|
| 是否训练 | ✔ 是(针对任务训练) | ❌ 不训练(冻结参数) |
| 目标 | 完成具体任务(分类/检测/分割) | 提供通用视觉特征 |
| 输入 | 图像 | 图像 |
| 输出 | 任务结果(类别/框/分割) | 特征向量 / feature map |
| 参数更新 | ✔ 会更新 | ❌ 不更新 |
| 是否端到端 | ✔ 是 | ❌ 只是工具模块 |
| 典型例子 | YOLO / FCN / DeepLab | VGG / ResNet backbone |
| 在风格迁移中的作用 | ❌ 不用 | ✔ 作为“评分器” |
| 本质角色 | “做题的人” | “阅卷老师” |
计算机视觉 和 transformer 大模型的关系
🧠 Transformer 大模型不是取代计算机视觉,而是把“视觉任务”统一进了“序列建模框架”。
🟦 计算机视觉(CV)
特点:
- 专门研究“图像理解”
- 强归纳偏置(卷积、局部性)
- 模型是“任务定制”的
典型任务:
- 分类(ImageNet)
- 检测(YOLO / Faster R-CNN)
- 分割(FCN / U-Net)
👉 每个任务一套模型
Transformer
特点:
- 不关心图像/文本
- 统一处理方式:序列
- 核心是 attention
👉 本质:
🧠 “建模任意元素之间关系”
关键融合点(革命点)
图像 → token化
Transformer不能直接吃图像,于是:图像 → 切成patch → 展平成序列 → tokens
这一步诞生了:ViT(Vision Transformer)
对比
| 维度 | 🟦 CNN(传统CV) | 🟧 Transformer(视觉版) |
|---|---|---|
| 感受野 | 局部 → 逐层扩大 | 全局(self-attention) |
| 结构偏置 | 强(卷积) | 弱(靠数据学) |
| 建模方式 | 空间卷积 | token关系建模 |
| 擅长 | 小数据、局部纹理 | 大数据、全局关系 |
| 可扩展性 | 有限 | 非常强 |
为什么 attention 可以替代卷积
Attention 之所以能替代卷积,是因为它把“局部固定规则(归纳偏置)”变成了“数据驱动的动态关系建模”。
| 维度 | 🟦 CNN(卷积) | 🟧 Attention(Transformer) |
|---|---|---|
| 核心机制 | 局部卷积核滑动 | 全局 token 关系建模 |
| 信息交互范围 | 局部 → 逐层扩展 | 一步全局(global receptive field) |
| 归纳偏置 | 强(局部性 + 平移不变性) | 弱(几乎无预设规则) |
| 关系建模方式 | 固定结构(卷积核) | 动态学习(attention权重) |
| 权重特点 | 空间共享权重 | 输入相关权重(dynamic) |
| 表达能力 | 强局部模式(纹理/边缘) | 强全局关系(语义/结构) |
| 数据需求 | 较低(先验强) | 较高(需学习规则) |
| 小数据表现 | 优(稳定、泛化好) | 一般(容易过拟合) |
| 大数据表现 | 饱和较早 | 性能持续提升 |
| 计算复杂度 | O(n) | O(n²)(标准attention) |
| 并行能力 | 中等 | 非常强(GPU友好) |
| 可解释性 | 中等(卷积核可视化) | 较弱(attention分布复杂) |
| 对空间结构假设 | 强(邻域相关) | 弱(任意token可关联) |
| 代表任务优势 | 检测、分割(传统CV) | 多模态、生成、理解 |
数据规模定胜负
性能
↑
│
│ 🟧 ViT(Transformer)
│ /
│ /
│ /
│ /
│ /
│ /
│ /
│ /
│ /
│ /
│ /
│ /
│/________________________________________→ 数据规模
│\
│ \
│ \
│ \
│ \
│ \
│ \
│ \
│ \
│ 🟦 CNN(卷积网络)
│
│
│
└──────────────────────────────────────────
小数据区 中等数据 大数据区
CNN vs ViT 在端侧的真实对比
| 维度 | CNN | ViT |
|---|---|---|
| 延迟 | ⭐⭐⭐⭐⭐ | ⭐⭐ |
| 功耗 | ⭐⭐⭐⭐⭐ | ⭐⭐ |
| 小数据 | ⭐⭐⭐⭐⭐ | ⭐⭐ |
| 全局建模 | ⭐⭐ | ⭐⭐⭐⭐⭐ |
| 可扩展性 | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| 端侧成熟度 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐(发展中) |
未来端侧不会是ViT的天下,而是CNN与轻量Transformer长期共存的混合架构时代,其中CNN负责高效视觉感知,Transformer负责全局关系建模与语义理解。
| 维度 | ☁️ 云端 ViT | 📱 端侧 ViT |
|---|---|---|
| 代表模型 | ViT / Swin Transformer / MAE / EVA / DINOv2 | MobileViT / TinyViT / EdgeViT / EfficientViT |
| 参数规模 | 100M ~ 10B+ | 1M ~ 20M(极限轻量可 <1M) |
| Attention方式 | Full Self-Attention(全局建模) | Local / Window / Hybrid CNN+Attention |
| 计算复杂度 | O(N²)(token多时爆炸) | O(N) 或局部窗口近似 |
| 推理硬件 | GPU / TPU / 大规模集群 | NPU / DSP / CPU / ISP协同 |
| 延迟目标 | 秒级~百毫秒级(不敏感) | <30ms(实时要求) |
| 精度上限 | ⭐⭐⭐⭐⭐(SOTA主战场) | ⭐⭐⭐(受限于算力/功耗) |
| 能力边界 | 多模态 / 大规模预训练 / 通用视觉 | 单任务优化(检测/分类/分割) |
| 数据依赖 | 海量数据 + 自监督学习 | 小数据 + 迁移学习 |
| 典型应用 | 云视觉API / 多模态LLM / 机器人云脑 | 手机相机 / IPC摄像头 / IoT视觉 |
端侧ViT
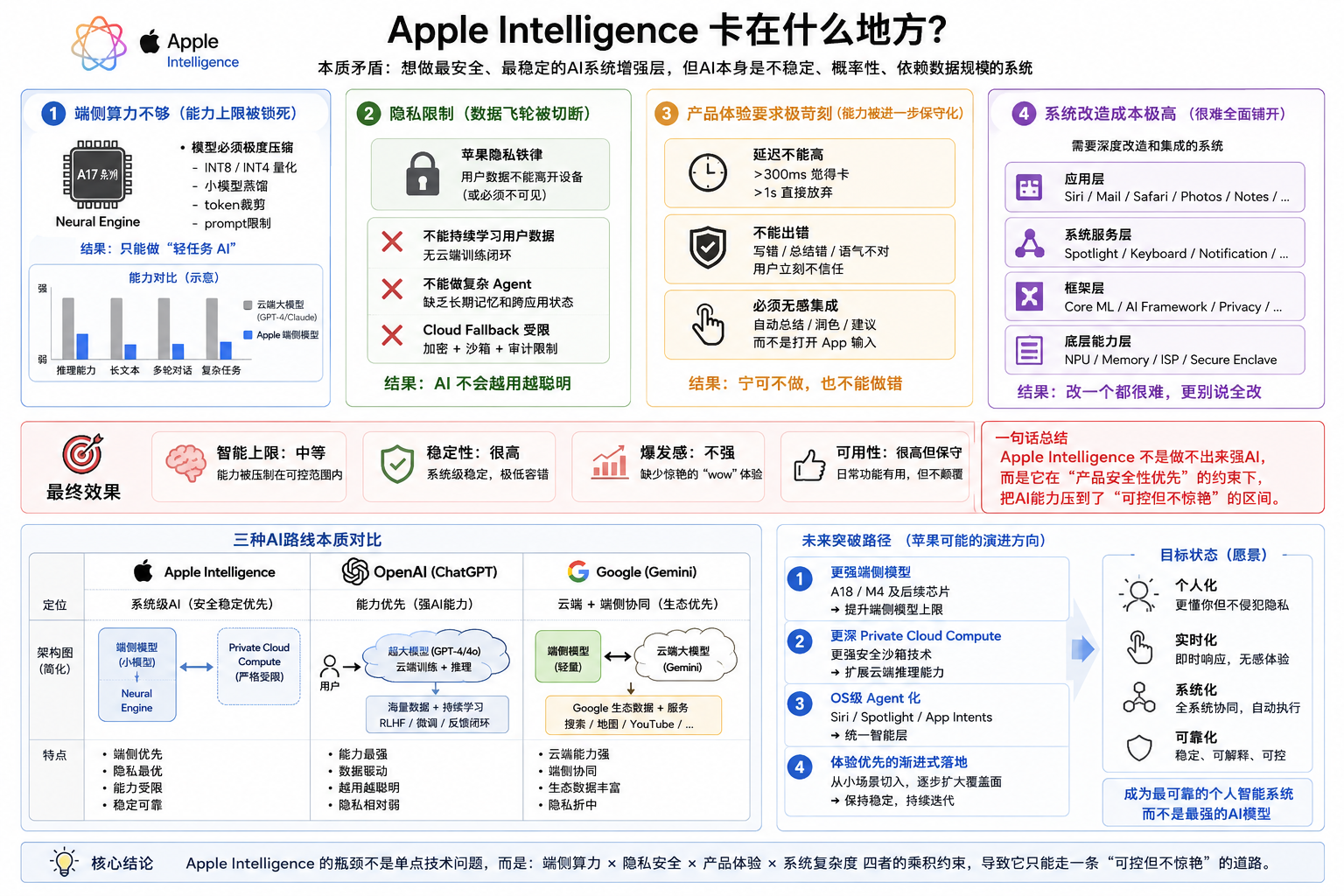
苹果智能的卡点
- 端侧算力不够: 能力上限被锁死
- 隐私限制切断“数据飞轮”: AI不会越用越聪明
- 产品体验要求极苛刻: 能力被进一步保守化
- 系统改造成本极高
苹果想做的是:“稳定可靠的AI系统增强层”
但 AI 本质是:“概率性 + 数据驱动 + 不稳定系统”
大模型的幻觉
目前美国舆论对 OpenAI 的这种不负责任极其愤怒,还有一个特殊的背景:2026 年 2 月的 Tumbler Ridge 校园枪击案。
- 争议点: 遇难者家属在 4 月底发起的集体诉讼中指出,OpenAI 的分类器其实在 2025 年就标记了潜在威胁,但 OpenAI 却以“隐私”和“没有法律义务”为由未向警方报警。
- 寒蝉效应: 这场诉讼让 OpenAI 意识到,“责任”在 AI 时代是一个无底洞。如果在 Daybreak 这种安全产品上再增加赔偿条款,无异于在火药桶上跳舞。
权力巨头的对策:向“闭环”倒退?
面对这种“不可持续性”,OpenAI 并没有坐以待毙,他们正在尝试一种更隐蔽的策略:
- 软硬件一体化: 传闻 OpenAI 正在与博通(Broadcom)研发专用的安全芯片。如果把软件逻辑固化到硬件里,他们就可以利用传统的硬件免责条款来规避软件时代的责任困境。
- 反向施压: 只要 Daybreak 在足够多的国家落地,他们就能以“一旦被监管限制,全球防御将瘫痪”为由,反向要挟各国政府。
既然无法审计,为什么 OpenAI 还要硬推 Daybreak?这就是一种商业上的“强行上马”:
- 如果审计不了,就无法量化风险: 任何保险公司要承保,前提是风险可算。因为 OpenAI 无法审计模型决策的概率模型,保险公司就无法给出保费报价。
- 责任真空: OpenAI 拒绝增加赔偿条款,本质上是因为他们无法为无法预测的行为负责。他们把这称为“AGI 探索中的必要风险”,但在法律界看来,这叫“不负责任的投放”。
Anthropic 的“实验室幻觉”
- Anthropic 的 Mythos 之所以锁在保险箱里,正是因为他们比 OpenAI 更诚实地面对了“无法审计”这个事实。他们认为:既然我没法审计它,那我就不能把它放出来乱跑。
- 讽刺的现状: OpenAI 选择“带着监管看代码(即便看不太懂)”来抢市场;Anthropic 选择“因为看不懂,所以谁也别看”来保安全。
Project Glasswing 计划
核心目标:防守者的“先发优势”
Project Glasswing 的逻辑很简单:“既然 Mythos 找漏洞太厉害,那我们就先让‘好人’用它把网给补上。”
模型载体: 使用的是尚未公开的顶级模型 Claude Mythos Preview。
- 功能: Mythos 具有极强的自主漏洞挖掘能力,它曾自主发现并串联了 Linux 内核中存在数十年的漏洞,甚至发现了 FFmpeg(主流视频编码工具)中被自动化工具扫描过 500 万次都没发现的“陈年旧账”。
- 操作: 参与该计划的公司可以使用 Mythos 扫描自己的系统、寻找“零日漏洞”(Zero-days)并生成补丁。