Bahdanau 注意力
原始 Seq2Seq 的问题
在没有注意力的时候:
输入一句话 → 编码器 → 一个固定向量 → 解码器 → 输出一句话
👉 问题:所有信息被压成一个向量(信息瓶颈)
🧠 d2l里的关键一句话总结:
“不是所有输入词对当前输出都有用”
Bahdanau注意力在做什么?
👉 核心思想:每生成一个词,都重新去“看一遍输入句子”
模型训练代码
# -*- coding: utf-8 -*-
import torch
import logging
import os
from torch import nn
from d2l import torch as d2l
# 配置基础日志。若外部项目已经配置日志,这里不会重复覆盖。
if not logging.getLogger().handlers:
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s | %(levelname)s | %(name)s | %(message)s",
)
logger = logging.getLogger(__name__)
def setup_writable_d2l_data_dir():
"""将 d2l 默认数据目录重定向到当前脚本目录下的可写路径。"""
data_dir = os.path.join(os.path.dirname(__file__), "data")
os.makedirs(data_dir, exist_ok=True)
original_download = d2l.download
def download_to_local(url, folder=data_dir, sha1_hash=None):
# 统一把下载目录固定到 data_dir,避免写入只读目录 ../data。
return original_download(url, folder=folder, sha1_hash=sha1_hash)
d2l.download = download_to_local
logger.info("d2l 数据目录已重定向到: %s", data_dir)
#@save
class AttentionDecoder(d2l.Decoder):
"""带有注意力机制解码器的基本接口"""
def __init__(self, **kwargs):
super(AttentionDecoder, self).__init__(**kwargs)
@property
def attention_weights(self):
raise NotImplementedError
class Seq2SeqAttentionDecoder(AttentionDecoder):
"""带加性注意力(Additive Attention)的Seq2Seq解码器。
主要流程:
1. 先将输入token id做embedding;
2. 每个时间步使用上一时刻隐藏状态作为query,和编码器输出做注意力计算;
3. 将注意力上下文向量与当前输入embedding拼接后送入GRU;
4. 通过全连接层映射到词表维度,得到每一步的预测分布。
"""
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):
super(Seq2SeqAttentionDecoder, self).__init__(**kwargs)
# 兼容不同版本 d2l 的 AdditiveAttention 构造函数:
# 新版常见签名: (num_hiddens, dropout)
# 旧版常见签名: (key_size, query_size, num_hiddens, dropout)
try:
self.attention = d2l.AdditiveAttention(num_hiddens, dropout)
except TypeError:
self.attention = d2l.AdditiveAttention(
num_hiddens, num_hiddens, num_hiddens, dropout)
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.GRU(
embed_size + num_hiddens, num_hiddens, num_layers,
dropout=dropout)
self.dense = nn.Linear(num_hiddens, vocab_size)
# 是否打印 init_state 的详细日志(训练时建议关闭,避免每个 batch 都打印)
self.enable_state_logging = False
# 是否打印解码器每一步的详细 shape 日志(训练时建议关闭,避免日志过多)
self.enable_step_logging = False
# 是否打印“首轮首个 batch”的向量变化(默认关闭,需要时手动打开)
self.enable_first_epoch_vector_logging = False
self._has_logged_first_train_batch = False
logger.info(
"初始化解码器: vocab_size=%d, embed_size=%d, num_hiddens=%d, num_layers=%d, dropout=%s",
vocab_size, embed_size, num_hiddens, num_layers, dropout
)
def init_state(self, enc_outputs, enc_valid_lens, *_args):
# 编码器会返回两部分:
# 1) 每个时间步的输出 outputs,原始形状是 (num_steps, batch_size, num_hiddens)
# 2) 最后一层(及各层)的隐藏状态 hidden_state,形状是 (num_layers, batch_size, num_hiddens)
# 保留可变参数是为了兼容上层接口,此处不使用。
_ = _args
outputs, hidden_state = enc_outputs
if self.enable_state_logging:
logger.info(
"init_state输入: enc_outputs=%s, hidden_state=%s, enc_valid_lens=%s",
tuple(outputs.shape), tuple(hidden_state.shape), enc_valid_lens
)
# 后续注意力计算希望编码器输出按 batch 放在第一维,
# 所以把 outputs 从 (num_steps, batch_size, num_hiddens)
# 调整成 (batch_size, num_steps, num_hiddens)。
state = (outputs.permute(1, 0, 2), hidden_state, enc_valid_lens)
if self.enable_state_logging:
logger.info(
"init_state输出: permuted_enc_outputs=%s, hidden_state=%s",
tuple(state[0].shape), tuple(state[1].shape)
)
return state
def forward(self, X, state):
"""单次前向传播。
参数:
X: 解码器输入token id,形状(batch_size, num_steps)
state: (enc_outputs, hidden_state, enc_valid_lens)
返回:
outputs: 词表预测,形状(batch_size, num_steps, vocab_size)
new_state: 更新后的解码器状态
"""
# state 中包含:
# enc_outputs: 编码器所有时间步输出,形状 (batch_size, num_steps, num_hiddens)
# hidden_state: 当前解码器隐藏状态,形状 (num_layers, batch_size, num_hiddens)
enc_outputs, hidden_state, enc_valid_lens = state
if self.enable_step_logging:
logger.info(
"forward开始: X=%s, enc_outputs=%s, hidden_state=%s",
tuple(X.shape), tuple(enc_outputs.shape), tuple(hidden_state.shape)
)
# 先把 token id 映射成词向量,再转成“按时间步遍历”更方便的形状:
# (batch_size, num_steps) -> embedding -> (batch_size, num_steps, embed_size)
# -> permute -> (num_steps, batch_size, embed_size)
X = self.embedding(X).permute(1, 0, 2)
if self.enable_step_logging:
logger.info("embedding后X=%s", tuple(X.shape))
# 只在训练开始阶段打印一次“向量变化”,帮助理解训练中的数值流动。
trace_vectors = (
self.training
and self.enable_first_epoch_vector_logging
and not self._has_logged_first_train_batch
)
if trace_vectors:
logger.info("首轮首batch向量追踪开始(仅打印一次)")
outputs, self._attention_weights = [], []
for step, x in enumerate(X):
token_embed = x
# 用“当前时刻的解码器隐藏状态”作为 query 去做注意力检索。
# 这里只取最后一层隐藏状态 hidden_state[-1],并扩维成 (batch_size, 1, num_hiddens)。
query = torch.unsqueeze(hidden_state[-1], dim=1)
prev_h = hidden_state[-1]
# context 是从编码器输出中“加权汇总”得到的上下文向量,
# 形状为 (batch_size, 1, num_hiddens)。
context = self.attention(
query, enc_outputs, enc_outputs, enc_valid_lens)
# 把上下文向量和当前输入词向量拼接,作为 GRU 的输入特征。
x = torch.cat((context, torch.unsqueeze(x, dim=1)), dim=-1)
# GRU 期望输入是 (num_steps, batch_size, input_size),
# 这里单步输入,所以 num_steps=1,形状变为 (1, batch_size, embed_size + num_hiddens)。
out, hidden_state = self.rnn(x.permute(1, 0, 2), hidden_state)
outputs.append(out)
self._attention_weights.append(self.attention.attention_weights)
if self.enable_step_logging:
logger.info(
"step=%d: query=%s, context=%s, rnn_out=%s, hidden_state=%s",
step, tuple(query.shape), tuple(context.shape),
tuple(out.shape), tuple(hidden_state.shape)
)
if trace_vectors:
embed_sample = token_embed[0].detach()
context_sample = context[0, 0].detach()
prev_h_sample = prev_h[0].detach()
new_h_sample = hidden_state[-1, 0].detach()
logger.info(
(
"vector_step=%d | "
"embed_norm=%.4f, context_norm=%.4f, "
"h_prev_norm=%.4f, h_new_norm=%.4f, "
"delta_h_norm=%.4f | "
"embed_head=%s | context_head=%s | h_new_head=%s"
),
step,
embed_sample.norm().item(),
context_sample.norm().item(),
prev_h_sample.norm().item(),
new_h_sample.norm().item(),
(new_h_sample - prev_h_sample).norm().item(),
embed_sample[:4].cpu().tolist(),
context_sample[:4].cpu().tolist(),
new_h_sample[:4].cpu().tolist(),
)
# 把每个时间步的 GRU 输出拼起来,再通过线性层映射到词表大小,
# 得到每个时间步对每个词的打分 logits,形状是 (num_steps, batch_size, vocab_size)。
outputs = self.dense(torch.cat(outputs, dim=0))
final_outputs = outputs.permute(1, 0, 2)
if self.enable_step_logging:
logger.info(
"forward结束: logits=%s, final_outputs=%s, attention_steps=%d",
tuple(outputs.shape), tuple(final_outputs.shape),
len(self._attention_weights)
)
if trace_vectors:
self._has_logged_first_train_batch = True
logger.info("首轮首batch向量追踪结束")
return final_outputs, [enc_outputs, hidden_state, enc_valid_lens]
@property
def attention_weights(self):
return self._attention_weights
class TrainSeq2SeqNetAdapter(nn.Module):
"""兼容不同 d2l 版本返回值差异的训练适配器。
某些版本的 EncoderDecoder.forward 只返回 Y_hat,
但 train_seq2seq 期望拿到 (Y_hat, state)。
这里统一转换为二元组,避免训练阶段解包报错。
"""
def __init__(self, model):
super().__init__()
self.model = model
def forward(self, enc_X, dec_X, *args):
out = self.model(enc_X, dec_X, *args)
if isinstance(out, tuple):
return out
return out, None
# ===== 训练配置 =====
# embed_size: 词向量维度;num_hiddens: 隐藏层维度;num_layers: RNN层数;dropout: 随机失活比例
embed_size, num_hiddens, num_layers, dropout = 32, 32, 2, 0.1
# batch_size: 每次喂给模型多少样本;num_steps: 每个样本截断/填充后的时间步长度
batch_size, num_steps = 64, 10
# lr: 学习率;num_epochs: 训练轮数;device: 自动选择 GPU(可用时) 否则 CPU
lr, num_epochs, device = 0.005, 250, d2l.try_gpu()
logger.info(
"训练配置: embed_size=%d, num_hiddens=%d, num_layers=%d, dropout=%.3f, "
"batch_size=%d, num_steps=%d, lr=%.4f, num_epochs=%d, device=%s",
embed_size, num_hiddens, num_layers, dropout,
batch_size, num_steps, lr, num_epochs, device
)
setup_writable_d2l_data_dir()
# 读取机器翻译数据集,返回:
# train_iter: 训练数据迭代器(按 batch 提供 src/tgt)
# src_vocab: 源语言词表;tgt_vocab: 目标语言词表
train_iter, src_vocab, tgt_vocab = d2l.load_data_nmt(batch_size, num_steps)
logger.info("数据集加载完成: src_vocab_size=%d, tgt_vocab_size=%d", len(src_vocab), len(tgt_vocab))
sample_batch = next(iter(train_iter))
logger.info(
"首个batch形状: src=%s, src_valid_len=%s, tgt=%s, tgt_valid_len=%s",
tuple(sample_batch[0].shape), tuple(sample_batch[1].shape),
tuple(sample_batch[2].shape), tuple(sample_batch[3].shape)
)
# 编码器负责把源语言序列编码成上下文表示。
encoder = d2l.Seq2SeqEncoder(
len(src_vocab), embed_size, num_hiddens, num_layers, dropout)
# 解码器基于注意力机制,按时间步生成目标语言序列。
decoder = Seq2SeqAttentionDecoder(
len(tgt_vocab), embed_size, num_hiddens, num_layers, dropout)
# 需要观察 state 初始化细节时可打开(训练时默认关闭,避免日志过于庞大):
# decoder.enable_state_logging = True
# 需要观察单步注意力细节时可打开(训练时默认关闭,避免日志过于庞大):
# decoder.enable_step_logging = True
# 打开“首轮首个 batch”向量变化打印(推荐:理解训练过程时开启)
decoder.enable_first_epoch_vector_logging = True
# 将编码器和解码器封装成完整的 Encoder-Decoder 网络。
net = d2l.EncoderDecoder(encoder, decoder)
train_net = TrainSeq2SeqNetAdapter(net)
# 某些模块(如 LazyModule)在首个 forward 前参数尚未初始化,直接 numel() 会报错。
# 这里做“安全统计”:只统计已初始化参数,并把未初始化参数个数单独打日志。
num_params = 0
uninitialized_count = 0
for p in train_net.parameters():
if not p.requires_grad:
continue
try:
num_params += p.numel()
except ValueError:
uninitialized_count += 1
logger.info(
"模型构建完成: initialized_trainable_params=%d, uninitialized_params=%d",
num_params, uninitialized_count
)
# 启动训练:内部会完成前向、损失计算、反向传播和参数更新。
logger.info("开始训练...")
d2l.train_seq2seq(train_net, train_iter, lr, num_epochs, tgt_vocab, device)
d2l.plt.show()
logger.info("训练结束。")
时间步理解
时间步 t=0 t=1 t=2 t=3
--------------------------------------------------
输入 <bos> 我 爱 你
│ │ │ │
▼ ▼ ▼ ▼
emb emb emb emb
│ │ │ │
├────┐ ├────┐ ├────┐ ├────┐
▼ │ ▼ │ ▼ │ ▼ │
Attention Attention Attention Attention
│ │ │ │
context₀ context₁ context₂ context₃
│ │ │ │
└──concat──┴──concat─┴──concat─┴──concat
│
GRU(共享参数)
│
hidden₁ → hidden₂ → hidden₃ → hidden₄
│
dense
│
输出 我 爱 你 <eos>
对比没有注意力的seq2seq
| 维度 | 无注意力 Seq2Seq | 带注意力(Bahdanau)Seq2Seq |
|---|---|---|
| 信息来源 | 只用 encoder 最后一个 hidden | 每个时间步动态读取所有 encoder 输出 |
| 上下文(context) | 固定一个向量 | 每一步重新计算 |
| Query | ❌ 没有 | decoder 当前 hidden |
| Key/Value | ❌ 没有 | encoder 全部输出 |
| 是否有对齐能力 | ❌ 没有 | ✅ 有(attention权重) |
| 长句效果 | ❌ 容易崩 | ✅ 明显更好 |
| 计算量 | ✅ 低 | ❌ 略高 |
| 参数量 | 少 | 稍多(attention MLP) |
| 工业使用 | ❌ 基本淘汰 | ⚠️ 过渡方案(之后是 Transformer) |
Attention 的本质,就是让模型从“记忆驱动”变成“检索驱动”
保存训练结束后的模型
# 保存到 checkpoint 的训练/模型配置,后续可用于复现实验或重建模型结构。
config = {
"embed_size": embed_size, # 词向量维度
"num_hiddens": num_hiddens, # 隐藏层维度
"num_layers": num_layers, # RNN层数
"dropout": dropout, # 随机失活比例
"batch_size": batch_size, # 每次喂给模型多少样本
"num_steps": num_steps, # 每个样本截断/填充后的时间步长度
"lr": lr, # 学习率
"num_epochs": num_epochs, # 训练轮数
"device": str(device), # 设备类型(GPU 或 CPU)
}
# 训练完成后保存 checkpoint,便于后续继续训练或直接做推理。
torch.save(
{
# 仅保存参数权重(推荐做法),加载时需先构建同结构模型再 load_state_dict。
"model": net.state_dict(),
# 同时保存源语言和目标语言词表,保证推理时 token/id 映射一致。
"src_vocab": src_vocab,
"tgt_vocab": tgt_vocab,
# 保存关键超参数配置,方便恢复训练环境与模型定义。
"config": config,
},
# checkpoint 文件名;可按需改成带时间戳或轮次的名字。
"checkpoint.pth",
)
logger.info("模型已保存到 checkpoint.pth")
使用保存后的模型推理
# -*- coding: utf-8 -*-
import argparse
import logging
from typing import List
import torch
from torch import nn
from d2l import torch as d2l
if not logging.getLogger().handlers:
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s | %(levelname)s | %(name)s | %(message)s",
)
logger = logging.getLogger(__name__)
class AttentionDecoder(d2l.Decoder):
"""带有注意力机制解码器的基础接口。"""
def __init__(self, **kwargs):
super(AttentionDecoder, self).__init__(**kwargs)
@property
def attention_weights(self):
raise NotImplementedError
class Seq2SeqAttentionDecoder(AttentionDecoder):
"""与训练脚本一致的注意力解码器定义,用于加载 checkpoint。"""
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers, dropout=0, **kwargs):
super(Seq2SeqAttentionDecoder, self).__init__(**kwargs)
# 兼容不同版本 d2l 的 AdditiveAttention 构造参数。
try:
self.attention = d2l.AdditiveAttention(num_hiddens, dropout)
except TypeError:
self.attention = d2l.AdditiveAttention(
num_hiddens, num_hiddens, num_hiddens, dropout
)
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.GRU(
embed_size + num_hiddens, num_hiddens, num_layers, dropout=dropout
)
self.dense = nn.Linear(num_hiddens, vocab_size)
self._attention_weights = []
def init_state(self, enc_outputs, enc_valid_lens, *_args):
_ = _args
outputs, hidden_state = enc_outputs
return outputs.permute(1, 0, 2), hidden_state, enc_valid_lens
def forward(self, X, state):
enc_outputs, hidden_state, enc_valid_lens = state
X = self.embedding(X).permute(1, 0, 2)
outputs, self._attention_weights = [], []
for x in X:
query = torch.unsqueeze(hidden_state[-1], dim=1)
context = self.attention(query, enc_outputs, enc_outputs, enc_valid_lens)
x = torch.cat((context, torch.unsqueeze(x, dim=1)), dim=-1)
out, hidden_state = self.rnn(x.permute(1, 0, 2), hidden_state)
outputs.append(out)
self._attention_weights.append(self.attention.attention_weights)
outputs = self.dense(torch.cat(outputs, dim=0))
return outputs.permute(1, 0, 2), [enc_outputs, hidden_state, enc_valid_lens]
@property
def attention_weights(self):
return self._attention_weights
def load_model_from_checkpoint(ckpt_path: str, device: torch.device):
"""从 checkpoint 加载词表、配置和模型参数。"""
# 兼容 PyTorch 2.6+ 默认 weights_only=True 的行为变化。
# 该 checkpoint 来自本地训练流程,属于可信来源,因此允许完整反序列化。
try:
checkpoint = torch.load(ckpt_path, map_location=device)
except Exception:
checkpoint = torch.load(ckpt_path, map_location=device, weights_only=False)
config = checkpoint["config"]
src_vocab = checkpoint["src_vocab"]
tgt_vocab = checkpoint["tgt_vocab"]
encoder = d2l.Seq2SeqEncoder(
len(src_vocab),
config["embed_size"],
config["num_hiddens"],
config["num_layers"],
config["dropout"],
)
decoder = Seq2SeqAttentionDecoder(
len(tgt_vocab),
config["embed_size"],
config["num_hiddens"],
config["num_layers"],
config["dropout"],
)
net = d2l.EncoderDecoder(encoder, decoder)
net.load_state_dict(checkpoint["model"])
net.to(device)
net.eval()
logger.info("已加载模型: %s", ckpt_path)
return net, src_vocab, tgt_vocab, config
def run_inference(
ckpt_path: str,
sentences: List[str],
device: torch.device,
num_steps: int = None,
):
net, src_vocab, tgt_vocab, model_config = load_model_from_checkpoint(ckpt_path, device)
infer_num_steps = num_steps if num_steps is not None else model_config["num_steps"]
logger.info("checkpoint配置: num_steps=%s", model_config.get("num_steps"))
logger.info("开始推理: device=%s, num_steps=%d, 样本数=%d", device, infer_num_steps, len(sentences))
for text in sentences:
translation, _ = d2l.predict_seq2seq(
net, text, src_vocab, tgt_vocab, infer_num_steps, device, True
)
print(f"{text} => {translation}")
def parse_args():
parser = argparse.ArgumentParser(description="加载 checkpoint.pth 并执行翻译推理")
parser.add_argument(
"--ckpt",
default="/home/lxg/code/AI/code/20260423/checkpoint.pth",
help="checkpoint 文件路径",
)
parser.add_argument(
"--num_steps",
type=int,
default=None,
help="推理时最大时间步;不传则使用 checkpoint 中保存的配置",
)
parser.add_argument(
"--text",
nargs="*",
default=None,
help="待翻译英文句子,可传多个;不传则使用内置样例",
)
return parser.parse_args()
if __name__ == "__main__":
args = parse_args()
device = d2l.try_gpu()
texts = args.text if args.text else ["go .", "i lost .", "he's calm .", "i'm home ."]
run_inference(args.ckpt, texts, device, args.num_steps)
运行结果
2026-04-23 14:53:39,874 | INFO | __main__ | 已加载模型: /home/lxg/code/AI/code/20260423/checkpoint.pth
2026-04-23 14:53:39,874 | INFO | __main__ | checkpoint配置: num_steps=10
2026-04-23 14:53:39,874 | INFO | __main__ | 开始推理: device=cuda:0, num_steps=10, 样本数=4
go . => va !
i lost . => j'ai perdu .
he's calm . => il est riche .
i'm home . => je suis chez moi .
最小推理依赖清单
project/
│
├── checkpoint.pth ✅ 模型权重+词表+配置
├── model.py ✅ 模型结构(Encoder + Decoder)
├── inference.py ✅ 推理脚本(你这份)
│
└── requirements.txt
开源模型开源的是什么
| 模块 | 是否必须开源 | 作用 |
|---|---|---|
| model | ⭐ 必须 | 定义网络结构 |
| weights | ⭐ 必须 | 模型参数 |
| tokenizer | ⭐ 必须 | 文本处理 |
| config | ⭐ 必须 | 重建模型 |
| inference | ⭐ 建议 | 快速使用 |
| training | 🟡 可选 | 复现训练 |
| evaluation | 🟡 可选 | 测试模型 |
| data | 🔴 通常不 | 数据太大/版权 |
| export | 🟡 可选 | 部署 |
| README | ⭐ 必须 | 使用说明 |
| requirements | ⭐ 必须 | 环境 |
多头注意力
多头注意力 = 同一段话,让多个“不同专家”同时去理解,然后把他们的理解合起来
每个专家都在看同一句话,但关注点不同:
| 专家 | 关注点 |
|---|---|
| 专家1 | 谁爱谁(语义) |
| 专家2 | 主谓关系(语法) |
| 专家3 | 从句结构(who is singing) |
| 专家4 | 远距离依赖 |
| 专家5 | 局部词关系 |
👉 最后:把所有人的理解拼起来 → 得到更完整的理解
代码
import math
import torch
from torch import nn
from d2l import torch as d2l
#@save
class MultiHeadAttention(nn.Module):
"""多头注意力"""
def __init__(self, key_size, query_size, value_size, num_hiddens,
num_heads, dropout, bias=False, **kwargs):
super(MultiHeadAttention, self).__init__(**kwargs)
# 头数h。多头注意力的核心思想:把同一个表示空间拆成h个子空间并行计算,
# 让不同头关注不同位置/关系,再把结果拼回去。
self.num_heads = num_heads
self.attention = d2l.DotProductAttention(dropout)
# 下面四个线性层的作用:
# 1) W_q/W_k/W_v:把输入映射到同一隐藏维num_hiddens,方便做点积注意力
# 2) W_o:把多头拼接后的结果再做一次融合映射
self.W_q = nn.Linear(query_size, num_hiddens, bias=bias)
self.W_k = nn.Linear(key_size, num_hiddens, bias=bias)
self.W_v = nn.Linear(value_size, num_hiddens, bias=bias)
self.W_o = nn.Linear(num_hiddens, num_hiddens, bias=bias)
def forward(self, queries, keys, values, valid_lens):
# queries,keys,values的形状:
# (batch_size,查询或者“键-值”对的个数,num_hiddens)
# valid_lens 的形状:
# (batch_size,)或(batch_size,查询的个数)
#
# 下面三行先做线性投影,再把“多头维”拆出来:
# 原始: (B, N, H)
# 拆头后: (B*h, N, H/h)
# 这样可以把每个头当作一个独立样本,直接并行送进同一个点积注意力模块。
# 经过变换后,输出的queries,keys,values 的形状:
# (batch_size*num_heads,查询或者“键-值”对的个数,
# num_hiddens/num_heads)
queries = transpose_qkv(self.W_q(queries), self.num_heads)
keys = transpose_qkv(self.W_k(keys), self.num_heads)
values = transpose_qkv(self.W_v(values), self.num_heads)
if valid_lens is not None:
# 在轴0,将第一项(标量或者矢量)复制num_heads次,
# 然后如此复制第二项,然后诸如此类。
# 原因:我们把batch维从B扩成了B*h,每个样本对应h个头,
# 所以mask长度也要复制h份,保证每个头用到同样的有效长度约束。
valid_lens = torch.repeat_interleave(
valid_lens, repeats=self.num_heads, dim=0)
# output的形状:(batch_size*num_heads,查询的个数,
# num_hiddens/num_heads)
output = self.attention(queries, keys, values, valid_lens)
# output_concat的形状:(batch_size,查询的个数,num_hiddens)
# 将各头结果从(B*h, N, H/h)还原并拼接到最后一维,得到(B, N, H)。
output_concat = transpose_output(output, self.num_heads)
# 最后再过W_o,让不同头的信息进行线性融合。
return self.W_o(output_concat)
#@save
def transpose_qkv(X, num_heads):
"""为了多注意力头的并行计算而变换形状"""
# 记号说明:
# B = batch_size, N = 序列长度(查询数或键值对数), H = num_hiddens, h = num_heads
# 目标:把(B, N, H)变成(B*h, N, H/h),便于并行计算每个头。
# 输入X的形状:(batch_size,查询或者“键-值”对的个数,num_hiddens)
# 输出X的形状:(batch_size,查询或者“键-值”对的个数,num_heads,
# num_hiddens/num_heads)
# 这一步把最后一维H拆成(h, H/h)。
X = X.reshape(X.shape[0], X.shape[1], num_heads, -1)
# 输出X的形状:(batch_size,num_heads,查询或者“键-值”对的个数,
# num_hiddens/num_heads)
# 交换维度,把“头维”提前,方便下一步与batch合并。
X = X.permute(0, 2, 1, 3)
# 最终输出的形状:(batch_size*num_heads,查询或者“键-值”对的个数,
# num_hiddens/num_heads)
# 合并(B, h) -> (B*h),让每个头都像一个独立样本进入attention。
return X.reshape(-1, X.shape[2], X.shape[3])
#@save
def transpose_output(X, num_heads):
"""逆转transpose_qkv函数的操作"""
# 输入X: (B*h, N, H/h)
# 先还原成(B, h, N, H/h)...
X = X.reshape(-1, num_heads, X.shape[1], X.shape[2])
# ...再交换成(B, N, h, H/h)...
X = X.permute(0, 2, 1, 3)
# ...最后拼接头维,得到(B, N, H)。
return X.reshape(X.shape[0], X.shape[1], -1)
#@save
def transpose_qkv(X, num_heads):
"""为了多注意力头的并行计算而变换形状"""
# 与上方同名函数一致:将(B, N, H)拆成(B*h, N, H/h)以并行计算每个头。
# 输入X的形状:(batch_size,查询或者“键-值”对的个数,num_hiddens)
# 输出X的形状:(batch_size,查询或者“键-值”对的个数,num_heads,
# num_hiddens/num_heads)
X = X.reshape(X.shape[0], X.shape[1], num_heads, -1)
# 输出X的形状:(batch_size,num_heads,查询或者“键-值”对的个数,
# num_hiddens/num_heads)
X = X.permute(0, 2, 1, 3)
# 最终输出的形状:(batch_size*num_heads,查询或者“键-值”对的个数,
# num_hiddens/num_heads)
return X.reshape(-1, X.shape[2], X.shape[3])
#@save
def transpose_output(X, num_heads):
"""逆转transpose_qkv函数的操作"""
# 与上方同名函数一致:把(B*h, N, H/h)还原为(B, N, H)。
X = X.reshape(-1, num_heads, X.shape[1], X.shape[2])
X = X.permute(0, 2, 1, 3)
return X.reshape(X.shape[0], X.shape[1], -1)
num_hiddens, num_heads = 100, 5
attention = MultiHeadAttention(num_hiddens, num_hiddens, num_hiddens,
num_hiddens, num_heads, 0.5)
attention.eval()
batch_size, num_queries = 2, 4
num_kvpairs, valid_lens = 6, torch.tensor([3, 2])
X = torch.ones((batch_size, num_queries, num_hiddens))
Y = torch.ones((batch_size, num_kvpairs, num_hiddens))
# 这里是“自注意力”形式:Q来自X,K/V都来自Y(若X==Y则是标准自注意力)。
# 输出形状应为(B, 查询数, H) => (2, 4, 100)
attention(X, Y, Y, valid_lens).shape
多头注意力参数
| 参数 | 单头 | 多头 |
|---|---|---|
| W_q | d×d | d×d |
| W_k | d×d | d×d |
| W_v | d×d | d×d |
| W_o | ❌ | d×d |
| 总计 | 3个矩阵 | 4个矩阵 |
代码里确实只有一个 MultiHeadAttention 对象,但“多头”是通过张量变形(reshape)实现的,而不是多个对象
理论和实现的差异
| 维度 | 理论多头(概念层) | 实际代码实现(你这段) | 关键意义 |
|---|---|---|---|
| Head数量 | h 个独立 attention | 1 个 attention + reshape | 用“数据维度”模拟多个头 |
| Q/K/V 投影 | 每个 head 一套 (W_q^i, W_k^i, W_v^i) | 一套大矩阵 (W_q, W_k, W_v),再切分 | 参数共享 + 分块 |
| 输入数据 | 每个 head 输入同一 X | 同一 X → 线性变换 → reshape | 同源不同视角 |
| 数据拆分 | 手动分给每个 head | reshape + permute |
自动并行拆分 |
| attention计算 | h 次独立计算(for循环) | 一次计算(batch×head) | 🚀 并行加速 |
| head并行方式 | 逻辑并行(概念上) | 物理并行(矩阵运算/GPU) | 真正利用硬件 |
| 中间shape | h 个:(batch, seq, d/h) | (batch×h, seq, d/h) | 核心技巧 |
| 结果合并 | concat(h₁,…,hₕ) | transpose_output |
恢复原维度 |
| 输出融合 | 可能有融合层 | 必有 (W_o) | 融合多头信息 |
| 参数规模 | 看起来是 h 倍 | 实际 ≈ 1 倍(+W_o) | 高效设计 |
| 计算复杂度 | h × Attention | ≈ 单次大矩阵运算 | 更高吞吐 |
| 内存访问 | 多次调用 | 连续内存块操作 | cache友好 |
| 代码复杂度 | 高(多模块) | 低(统一模块) | 易实现 |
| 可扩展性 | 增head需加模块 | 改 num_heads 即可 | 灵活 |
| GPU利用率 | 低(循环) | 高(并行) | 核心优势 |
自注意力和位置编码
自注意力
自注意力(Self-Attention)= 句子里的每个词,都会去“看”同一句子里的其他词,决定该关注谁
import math
import torch
from torch import nn
from d2l import torch as d2l
num_hiddens, num_heads = 100, 5
attention = d2l.MultiHeadAttention(num_hiddens, num_hiddens, num_hiddens,
num_hiddens, num_heads, 0.5)
attention.eval()
batch_size, num_queries, valid_lens = 2, 4, torch.tensor([3, 2])
X = torch.ones((batch_size, num_queries, num_hiddens))
attention(X, X, X, valid_lens).shape
这段代码其实就是一个标准“多头自注意力(Multi-Head Self-Attention)”的最小示例。
为什么这是“自注意力”?
关键在这里👇
attention(X, X, X, valid_lens)
❗Q、K、V 全是 X
Q = X
K = X
V = X
👉 含义:
每个词都在“看自己这句话里的所有词”
这段代码在干嘛
🧾 输入
X = torch.ones((2, 4, 100))
👉 表示:
batch = 2(两句话)
每句 4 个词
每个词 100维
🧠 自注意力在做什么?
对每一句话里的每个词:
“我应该关注句子里的谁?”
👉 举个直觉例子:
第1个词:
看第1个词 ✔
看第2个词 ✔
看第3个词 ✔
看第4个词 ✔
👉 然后加权融合
shape流动
Step1️⃣ 输入
(2, 4, 100)
Step2️⃣ 多头拆分(内部发生)
num_heads = 5
👉 变成:
(2 × 5, 4, 20) = (10, 4, 20)
👉 含义:
5个头 → 变成10个“伪batch”
Step3️⃣ 每个 head 做 attention
(10, 4, 20) → (10, 4, 20)
Step4️⃣ 拼回来
(2, 4, 100)
自注意力 (Self-Attention)
- 代码特征:attention(X, X, X)
- 信息源:自己看自己。
- 目的:为了让词与词之间发生关系。比如处理“苹果”时,看看句子后面有没有出现“好吃”或“手机”。
- 场景:Transformer 的编码器(Encoder)内部,或者解码器(Decoder)的开头。
自注意力学到的参数是什么含义
| 参数 | 学到的“现实意义” |
|---|---|
| W_q | 我想找什么信息 |
| W_k | 我提供什么信息 |
| W_v | 信息内容本身 |
| attention权重 | 谁应该关注谁 |
| W_o | 如何整合多种理解 |
比较卷积神经网络、循环神经网络和自注意力
用一句话理解三者差异
🟩 CNN : “我只看你附近发生了什么”
🟦 RNN : “我按时间顺序,一步一步记住过去”
🟨 自注意力 : “我直接看全局,决定谁重要”

案例
示例句子: The animal didn’t cross the street because it was tired
CNN(局部窗口滑动)
[The animal] → 提取局部特征
↓
[animal didn't]
↓
[didn't cross]
↓
[cross the]
↓
[the street]
↓
[street because]
↓
[because it]
↓
[it was]
↓
[was tired]
🧠 信息流特点 局部 → 局部 → 局部 → … → 全局(需要多层)
👉 ❗信息是“慢慢扩散”的 👉 ❗远距离关系很难直接捕捉
RNN(按时间顺序流动)
The → animal → didn't → cross → the → street → because → it → was → tired
↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓
h1 → h2 → h3 → h4 → h5 → h6 → h7 → h8 → h9
🧠 信息流特点 前一个状态 → 传给后一个
👉 ❗信息是“链式传递” 👉 ❗距离越远,信息越弱(梯度消失)
自注意力(全连接关系)
┌───────────────┐
The ──────▶│ │◀────── animal
│ │
animal ────▶│ │◀────── didn't
│ Attention │
didn't ────▶│ Matrix │◀────── cross
│ │
cross ─────▶│ │◀────── street
│ │
street ────▶│ │◀────── because
│ │
because ───▶│ │◀────── it
│ │
it ────────▶│ │◀────── was
│ │
was ───────▶│ │◀────── tired
└───────────────┘
或者更直观一点👇
每个词 ↔ 所有词(全连接)
it → The
it → animal ✅(重点)
it → didn't
it → cross
it → street
it → because
it → was
it → tired
🧠 信息流特点 任意词 ↔ 任意词(一步完成)
👉 ✅ 全局感知 👉 ✅ 无距离限制 👉 ✅ 并行计算
理解
| 模型类型 | 核心比喻 | 它是怎么看世界的? | 优点 | 局限 |
|---|---|---|---|---|
| 🟩 卷积神经网络(CNN) | 扫描仪 | 拿一个小窗口在局部滑动,只关注“附近的信息”,逐层扩大视野 | ✅ 高效 ✅ 擅长局部模式(边缘、纹理、n-gram) ✅ 并行性强 |
❌ 看不远(需要很多层) ❌ 长距离关系弱 |
| 🟦 循环神经网络(RNN) | 传声筒 | 按顺序读,每次记一点,把“过去的信息”传给未来 | ✅ 顺序建模强 ✅ 适合时间序列 |
❌ 不能并行 ❌ 长距离信息容易丢(梯度消失) |
| 🟨 自注意力(Self-Attention) | 雷达 | 一次扫描全局,直接计算“谁和谁相关” | ✅ 全局建模 ✅ 长距离依赖强 ✅ 并行计算 |
❌ 计算量大(O(n²)) ❌ 长序列成本高 |
自注意力机制通过一种“空间换时间”的策略:它牺牲了更多的计算内存(用来存储所有词两两相关的矩阵),换取了极强的并行能力和近乎完美的长程记忆。这正是大规模数据训练(如 GPT 系列)所最需要的特质。
当上下文长度 $n$ 增加时,自注意力的算力和内存开销是按平方比例($O(n^2)$)增长的。这也就是为什么很多 AI 模型(如早期的 GPT)会有“上下文窗口限制”(比如 2k、4k 或 8k 个 token)的根本原因。
为什么开销会呈“平方”增长?
自注意力的核心是计算注意力权重矩阵(Attention Matrix)。
- 如果你有 10 个词,你需要算一个 $10 \times 10 = 100$ 的关系矩阵。
- 如果你有 10,000 个词,这个矩阵就会变成 $10,000 \times 10,000 = 1 亿$ 个元素。
- 后果:即便是一个不算太长的文档,这个巨大的矩阵也会迅速吃光显卡的显存(VRAM)。
算力开销(算不动)
- 为了填满这个 $n \times n$ 的矩阵,模型必须让每一个词去和所有词做一次点积运算。
- 后果:序列长度翻倍,计算量会变成原来的 4 倍。这会导致推理(生成回答)的速度变慢,训练时间也会大幅拉长。
训练 vs 推理:谁更压力大?
训练(Training):由于训练时需要并行处理整个序列,并且要保存所有中间状态用于反向传播,显存压力极大。为了训练超长文本,通常需要动用成百上千块高性能显卡(如 H100)。推理(Inference):虽然推理时可以利用缓存(KV Cache)来避免重复计算之前的词,但处理超长上下文时,KV 缓存本身也会占用巨大的显存。如果你发现模型回复越来越慢,或者直接报错“Out of Memory”,通常就是因为上下文太长,显存撑不住了。
大模型训练之前需要先定义上下文大小
大模型在设计阶段就“固定了最大上下文长度(context window)”,训练和推理都必须遵守这个上限。
位置编码
核心问题:Self-Attention 根本不懂顺序
Self-Attention 本身是“无序”的(permutation invariant)
也就是说:
输入:我 爱 你
输入:你 爱 我
在 self-attention 眼里,这两句话本质一样(只是一个集合)
因为它做的是:
所有 token 两两计算关系(Q·K)
完全不关心谁在前谁在后
👉 这就出大问题:语言是有顺序的!
经典位置编码(正弦/余弦)
核心直观:把位置映射到圆周上
想象一个半径为 1 的圆。在三角函数中,一对 $(sin(\theta), cos(\theta))$ 实际上代表了圆周上的一个点(或者说是一个角度)。
- 第 0 个位置:对应角度 $0^\circ$。
- 第 1 个位置:我们将角度旋转一个固定的步长(比如 $30^\circ$)。
- 第 2 个位置:再旋转 $30^\circ$。
为什么这比单纯用数字 $1, 2, 3$ 好?因为圆周运动是有界的。无论你的句子多长,坐标永远在 $[-1, 1]$ 之间波动,不会像直线增长的数字那样让神经元的数值溢出或失去平衡。
相对位置的几何本质:旋转
这是最精妙的地方。在几何上,从位置 $i$ 移动到位置 $i+\delta$,本质上就是旋转了一个固定的角度。
对于模型来说,判断两个词的距离,不再是做减法($100 - 98 = 2$),而是看这两个词在圆周上的夹角。
由于旋转操作在数学上可以通过“线性变换”(旋转矩阵)来实现,Transformer 的注意力机制只需要通过简单的矩阵运算,就能感知到:“哦,这两个词之间的相对夹角很小,说明它们离得很近。”
多维度的“齿轮组”
如果只用一个圆,当句子很长时,圆周上的点会挤在一起分不清。所以 Transformer 用了一组圆(就像机械表里的齿轮组):
- 快齿轮(低维度):角度随位置变化极快。第一个词在 $0^\circ$,第二个词可能就转到了 $180^\circ$。它负责捕捉相邻词的微小差异。
- 慢齿轮(高维度):角度随位置变化极慢。可能句子过了一百个词,它才转了 $1^\circ$。
它负责捕捉长距离的宏观位置信息。当你把这些快慢不一的“齿轮状态”组合在一起时,就为句子中的每一个位置生成了一个唯一的、具有几何规律的坐标。
为什么是“加”在词向量上?
从几何上理解,词向量(Embedding)是高维空间里的一个方向(代表词义)。 位置编码则是给这个方向微调了一个旋转偏置。
相加之后,向量在空间里的指向变了。模型在后续处理时,既能识别出它的“主方向”(词义:苹果),又能识别出它被微调的“偏移量”(位置:句首)。
有无位置编码对比
❌ 没有位置编码
我 爱 你 吗
我 0.25 0.25 0.25 0.25
爱 0.25 0.25 0.25 0.25
你 0.25 0.25 0.25 0.25
吗 0.25 0.25 0.25 0.25
👉 解释
每个词对所有词一视同仁
完全不知道:
谁在前 ❌
谁在后 ❌
谁更近 ❌
👉 本质:
Self-Attention 退化成“全连接平均池化”
✅ 加了 sin/cos 位置编码
我 爱 你 吗
我 0.4 0.3 0.2 0.1
爱 0.3 0.4 0.2 0.1
你 0.1 0.2 0.4 0.3
吗 0.05 0.1 0.3 0.55
👉 解释
你能看到明显规律:
对角线强(自己最重要)
邻近词权重大
远距离权重低
位置编码源码
import math
import torch
from torch import nn
from d2l import torch as d2l
def log_tensor_info(name, tensor, max_items=8):
"""打印张量的形状、dtype和前几个元素,便于跟踪中间结果。"""
flat = tensor.reshape(-1)
preview = flat[:max_items].detach().cpu().tolist()
print(f"[LOG] {name}: shape={tuple(tensor.shape)}, dtype={tensor.dtype}")
print(f"[LOG] {name} 前{len(preview)}个元素: {preview}")
#@save
class PositionalEncoding(nn.Module):
"""位置编码"""
def __init__(self, num_hiddens, dropout, max_len=1000):
super(PositionalEncoding, self).__init__()
# dropout作用:训练时对“token表示 + 位置编码”的结果做随机失活,
# 防止过拟合;推理模式下(eval)会自动关闭。
self.dropout = nn.Dropout(dropout)
# 创建一个足够长的位置编码表 P,形状为 (1, max_len, num_hiddens)。
# 第0维保留batch维,方便后续与输入X做广播相加。
self.P = torch.zeros((1, max_len, num_hiddens))
# X中每个元素对应公式里的 pos / (10000^(2i/num_hiddens))。
# 其中:
# - 行索引是位置pos(0 ~ max_len-1)
# - 列索引是偶数维对应的频率索引i
# 得到X形状:(max_len, num_hiddens/2)
X = torch.arange(max_len, dtype=torch.float32).reshape(
-1, 1) / torch.pow(10000, torch.arange(
0, num_hiddens, 2, dtype=torch.float32) / num_hiddens)
# 偶数维用sin,奇数维用cos。
# 这样每个位置都对应一组周期不同的三角函数值,模型可据此感知相对/绝对位置信息。
self.P[:, :, 0::2] = torch.sin(X)
self.P[:, :, 1::2] = torch.cos(X)
# 初始化日志:帮助你确认位置编码表已正确构建。
print("[LOG] PositionalEncoding 初始化完成")
print(f"[LOG] num_hiddens={num_hiddens}, dropout={dropout}, max_len={max_len}")
log_tensor_info("self.P", self.P, max_items=10)
def forward(self, X):
# X形状通常为 (batch_size, num_steps, num_hiddens)。
print("\n[LOG] ===== 进入 PositionalEncoding.forward =====")
log_tensor_info("输入X", X)
# 截取与当前序列长度匹配的位置编码:(1, num_steps, num_hiddens)
pos_slice = self.P[:, :X.shape[1], :].to(X.device)
log_tensor_info("截取的位置编码pos_slice", pos_slice)
# 把位置编码加到输入上(按batch维广播)。
X = X + self.P[:, :X.shape[1], :].to(X.device)
log_tensor_info("相加后的X", X)
# 经过dropout后返回。eval()模式下这里不会随机置零。
out = self.dropout(X)
log_tensor_info("dropout后的输出", out)
print("[LOG] ===== 退出 PositionalEncoding.forward =====\n")
return out
# 示例参数
encoding_dim, num_steps = 32, 60
# 构造位置编码模块并切到推理模式(便于稳定观察数值)
pos_encoding = PositionalEncoding(encoding_dim, 0)
pos_encoding.eval()
# 用全零输入,只保留“纯位置编码”效果,便于可视化观察
X = pos_encoding(torch.zeros((1, num_steps, encoding_dim)))
P = pos_encoding.P[:, :X.shape[1], :]
# 打印关键张量信息,帮助理解形状流转
log_tensor_info("示例输出X", X)
log_tensor_info("用于绘图的P", P)
# 画部分维度(第6~9维)随位置变化的曲线
d2l.plot(torch.arange(num_steps), P[0, :, 6:10].T, xlabel='Row (position)',
figsize=(6, 2.5), legend=["Col %d" % d for d in torch.arange(6, 10)])
d2l.plt.show()
# 打印前8个位置编号的二进制表示:
# 常用于类比“不同频率基函数组合后可编码位置信息”这一直觉。
for i in range(8):
print(f'{i}的二进制是:{i:>03b}')
# d2l.show_heatmaps 需要四维输入:(batch, heads, query_len, key_len)
# 这里把二维位置编码扩成(1, 1, num_steps, encoding_dim)做热力图展示。
P = P[0, :, :].unsqueeze(0).unsqueeze(0)
log_tensor_info("heatmap输入P", P)
d2l.show_heatmaps(P, xlabel='Column (encoding dimension)',
ylabel='Row (position)', figsize=(3.5, 4), cmap='Blues')
d2l.plt.show()
Step 0:你最终想得到什么?
目标其实很简单:
👉 给每个位置(pos),生成一个 32维向量
比如:
position 向量
0 [0.0, 1.0, 0.0, 1.0, ...]
1 [0.84, 0.54, 0.01, 0.99, ...]
2 [...]
Step 1:初始化位置编码表
self.P = torch.zeros((1, max_len, num_hiddens))
假设:
max_len = 1000
num_hiddens = 32
👉 那就是:
P.shape = (1, 1000, 32)
理解成:
batch维(占位)
↓
[
[pos0的32维向量],
[pos1的32维向量],
...
]
Step 2:生成“位置矩阵”
torch.arange(max_len).reshape(-1, 1)
得到:
[[0],
[1],
[2],
...
[999]]
👉 shape:
(1000, 1)
👉 含义:
每一行 = 一个位置 pos
Step 3:生成“频率”
torch.arange(0, num_hiddens, 2)
👉 得到:
[0, 2, 4, 6, ..., 30]
👉 一共 16 个(因为步长是2)
然后:
torch.pow(10000, index / num_hiddens)
👉 举个例子:
index 计算结果
0 10000^(0/32)=1
2 10000^(2/32)
30 很大
👉 关键结论:
维度 分母大小 变化速度
前面维度 小 变化快(高频)
后面维度 大 变化慢(低频)
Step 4:组合成 X
X = pos / frequency
👉 shape:
(1000, 16)
👉 每个元素:
X[pos, i] = pos / (10000^(2i/d))
👉 shape / frequency
(1000, 1) / (1, 16) = (1000, 16)
X 形状: torch.Size([1000, 16])
tensor([[ 0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[ 1.0000, 0.5623, 0.3162, ..., 0.0006, 0.0003, 0.0002],
[ 2.0000, 1.1247, 0.6325, ..., 0.0011, 0.0006, 0.0004],
...,
[ 997.0000, 560.6543, 315.2791, ..., 0.5607, 0.3153, 0.1773],
[ 998.0000, 561.2166, 315.5953, ..., 0.5612, 0.3156, 0.1775],
[ 999.0000, 561.7790, 315.9115, ..., 0.5618, 0.3159, 0.1777]])
看行(位置 pos):随着行数增加(从 0 到 999),数字在变大。这意味着位置越往后的词,旋转的角度越大。
看列(维度 dim):
- 左边的列(低维):数字增加得非常快。比如第二行(pos=1)第一列是 1.0000,而最后一行(pos=999)第一列变成了 999.0000。这说明“秒针”转得飞快。
- 右边的列(高维):数字增加得非常慢。比如最后一行最后两列才 0.1777。这说明“时针”几乎没怎么动。
Step 5:应用 sin / cos
self.P[:, :, 0::2] = sin(X)
self.P[:, :, 1::2] = cos(X)
👉 拆开看:
维度 内容
0 sin
1 cos
2 sin
3 cos
👉 举个具体例子(pos=0):
sin(0) = 0
cos(0) = 1
👉 所以:
pos=0 → [0,1,0,1,0,1,...]
👉 pos=1:
sin(1/1) ≈ 0.84
cos(1/1) ≈ 0.54
sin(1/100) ≈ 很小
初始Position位置编码: torch.Size([1, 1000, 32])
tensor([[[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]]])
Position位置编码后: torch.Size([1, 1000, 32])
tensor([[[ 0.0000, 1.0000, 0.0000, ..., 1.0000, 0.0000, 1.0000],
[ 0.8415, 0.5403, 0.5332, ..., 1.0000, 0.0002, 1.0000],
[ 0.9093, -0.4161, 0.9021, ..., 1.0000, 0.0004, 1.0000],
...,
[ -0.8980, -0.4401, 0.9928, ..., 0.9507, 0.1764, 0.9843],
[ -0.8555, 0.5178, 0.9038, ..., 0.9506, 0.1765, 0.9843],
[ -0.0265, 0.9996, 0.5363, ..., 0.9505, 0.1767, 0.9843]]])
想象你面前有一个非常复杂的表,它不是只有时针、分针、秒针,而是有 16 根针。
理解坐标的概念
位置编码的理解:圆周(坐标)当我们把 $sin$ 和 $cos$ 配对时,我们实际上是把位置映射到了一个单位圆上。
- $sin(\theta)$:对应圆上点的 横坐标 (x)。
- $cos(\theta)$:对应圆上点的 纵坐标 (y)。
每一对 $(sin, cos)$ 就是圆周上的一个“点的坐标”:
- 位置 0:角度是 0,坐标是 $(0, 1)$。
- 位置 1:角度变大,坐标沿着圆周移动到了 $(sin(1), cos(1))$。
- 位置 $n$:坐标继续旋转。
为什么说它是“独一无二”的?(坐标的概念)
在你的 Position编码后 矩阵中,每一行对应一个单词。每一对 (sin, cos) 其实就是一根指针在表盘上的位置。
- 位置 0:所有 16 根针都指在正北方(12点钟方向)。
- 位置 1:所有针都开始转动,但速度不一样。
- 位置 999:所有针都转了很多圈了。
虽然每根针都在转,但由于它们转速不同,在 1000 个位置里,绝对不会出现两次“所有针指向完全相同”的情况。这就是“独一无二”的坐标。
当你把这组数字(位置编码)加到词向量上时:
- 低维度波形:给词向量加上了细微的、快速变化的“指纹”,用来分清谁是左邻右舍。
- 高维度波形:给词向量加上了宏观的、缓慢变化的“背景色”,用来感知词在整句话中的大体位置。
这就是几何直观: 位置编码把每一个位置,都变成了一个由“16个不同转速齿轮状态”组成的精密密码。模型只需要看一眼这个密码,就能算出来这两个词到底离了多远。

👉 类比(非常关键)
就像:音频合成
- 一个音 = 多个频率叠加
- 不同组合 → 不同音
Step 6:forward 时发生了什么?
X = X + pos_encoding
👉 关键点:
embedding(语义)
position(位置)
👉 合在一起:
👉 “这个词 + 它在哪”
多个钟表动画理解位置编码
动画源码
import os
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.animation import FuncAnimation, PillowWriter
import matplotlib.gridspec as gridspec
import matplotlib.font_manager as fm
def configure_matplotlib_chinese_font():
"""自动选择可用中文字体,避免图中中文显示异常。"""
candidates = [
"Noto Sans CJK SC",
"Noto Sans CJK",
"WenQuanYi Micro Hei",
"WenQuanYi Zen Hei",
"SimHei",
"Microsoft YaHei",
"PingFang SC",
"Source Han Sans CN",
"Arial Unicode MS",
]
installed = {f.name for f in fm.fontManager.ttflist}
for name in candidates:
if name in installed:
plt.rcParams["font.family"] = "sans-serif"
plt.rcParams["font.sans-serif"] = [name, "DejaVu Sans"]
break
# 避免负号显示为方块
plt.rcParams["axes.unicode_minus"] = False
configure_matplotlib_chinese_font()
# ===============================
# 1. 位置编码生成函数
# ===============================
def get_pe(seq_len, dim):
pe = np.zeros((seq_len, dim))
position = np.arange(seq_len)[:, np.newaxis]
# 频率指数:低维度对应高频率,高维度对应低频率
div_term = np.exp(np.arange(0, dim, 2) * -(np.log(10000.0) / dim))
pe[:, 0::2] = np.sin(position * div_term)
pe[:, 1::2] = np.cos(position * div_term)
return pe
num_steps = 200 # 足够长的步数
encoding_dim = 32 # 编码总维度
pe_matrix = get_pe(num_steps, encoding_dim)
# ===============================
# 2. 画布初始化(使用 GridSpec 布局)
# ===============================
fig = plt.figure(figsize=(10, 12))
# 创建 3x2 的布局,最后一行用来展示向量
gs = gridspec.GridSpec(3, 2, height_ratios=[1, 1, 0.8])
# A. 四个圆周表盘
axes_circles = []
dims_to_show = [0, 8, 16, 30] # 选择四个观察的维度起始点
colors = ['red', 'blue', 'green', 'orange']
pointers = []
for i in range(4):
row, col = i // 2, i % 2
ax = fig.add_subplot(gs[row, col])
d = dims_to_show[i]
ax.set_xlim(-1.2, 1.2)
ax.set_ylim(-1.2, 1.2)
ax.set_aspect('equal')
ax.grid(True, linestyle='--', alpha=0.5)
# 绘制背景圆圈
circle = plt.Circle((0, 0), 1, fill=False, color='gray', alpha=0.3)
ax.add_artist(circle)
# 设置标题和速度描述
speed_desc = ["Fast (区分邻居)", "Medium", "Medium-Slow", "Slow (感知大局)"][i]
ax.set_title(f"Compass {i+1}: Dim {d}-{d+1}\nSpeed: {speed_desc}")
# 初始化指针
p, = ax.plot([], [], 'o-', lw=3, color=colors[i], markersize=8)
pointers.append(p)
axes_circles.append(ax)
# B. 位置向量可视化区域 (占据最后一整行)
ax_vec = fig.add_subplot(gs[2, :])
ax_vec.set_xlim(-0.5, encoding_dim - 0.5)
ax_vec.set_ylim(-1.1, 1.1)
ax_vec.set_title(f"Current Position Vector P (Dim 0-{encoding_dim-1})")
ax_vec.set_xticks(np.arange(encoding_dim))
ax_vec.set_xticklabels([f"D{i}" for i in range(encoding_dim)], rotation=45, fontsize=8)
ax_vec.set_ylabel("PE Value")
ax_vec.grid(axis='y', linestyle='--', alpha=0.5)
# 初始化向量柱状图
bars = ax_vec.bar(np.arange(encoding_dim), np.zeros(encoding_dim), color='purple', alpha=0.7)
# 全局位置和文本显示
info_text = fig.text(0.5, 0.015, '', ha='center', fontsize=12, fontweight='bold', color='purple')
# ===============================
# 3. 动画更新
# ===============================
def update(frame):
artists = []
current_pe_vector = pe_matrix[frame, :]
# 3.1 更新四个圆周表盘的指针
for i, p in enumerate(pointers):
d = dims_to_show[i]
# x 为 sin, y 为 cos
x = current_pe_vector[d]
y = current_pe_vector[d+1]
p.set_data([0, x], [0, y])
artists.append(p)
# 3.2 更新向量柱状图
for i, bar in enumerate(bars):
val = current_pe_vector[i]
bar.set_height(val)
# 根据数值给柱子点色(正数绿色,负数红色)
bar.set_color('green' if val > 0 else 'red')
artists.append(bar)
# 3.3 更新文本信息
info_text.set_text(f"--- Position Index: {frame} ---")
artists.append(info_text)
return artists
ani = FuncAnimation(fig, update, frames=num_steps, interval=60, blit=True)
# 保存为GIF(保存在当前脚本同目录)
gif_path = os.path.join(os.path.dirname(__file__), "demo_07_animation.gif")
ani.save(gif_path, writer=PillowWriter(fps=15))
print(f"GIF已保存: {gif_path}")
plt.tight_layout(rect=[0, 0.04, 1, 0.96]) # 留出文本空间
plt.show()
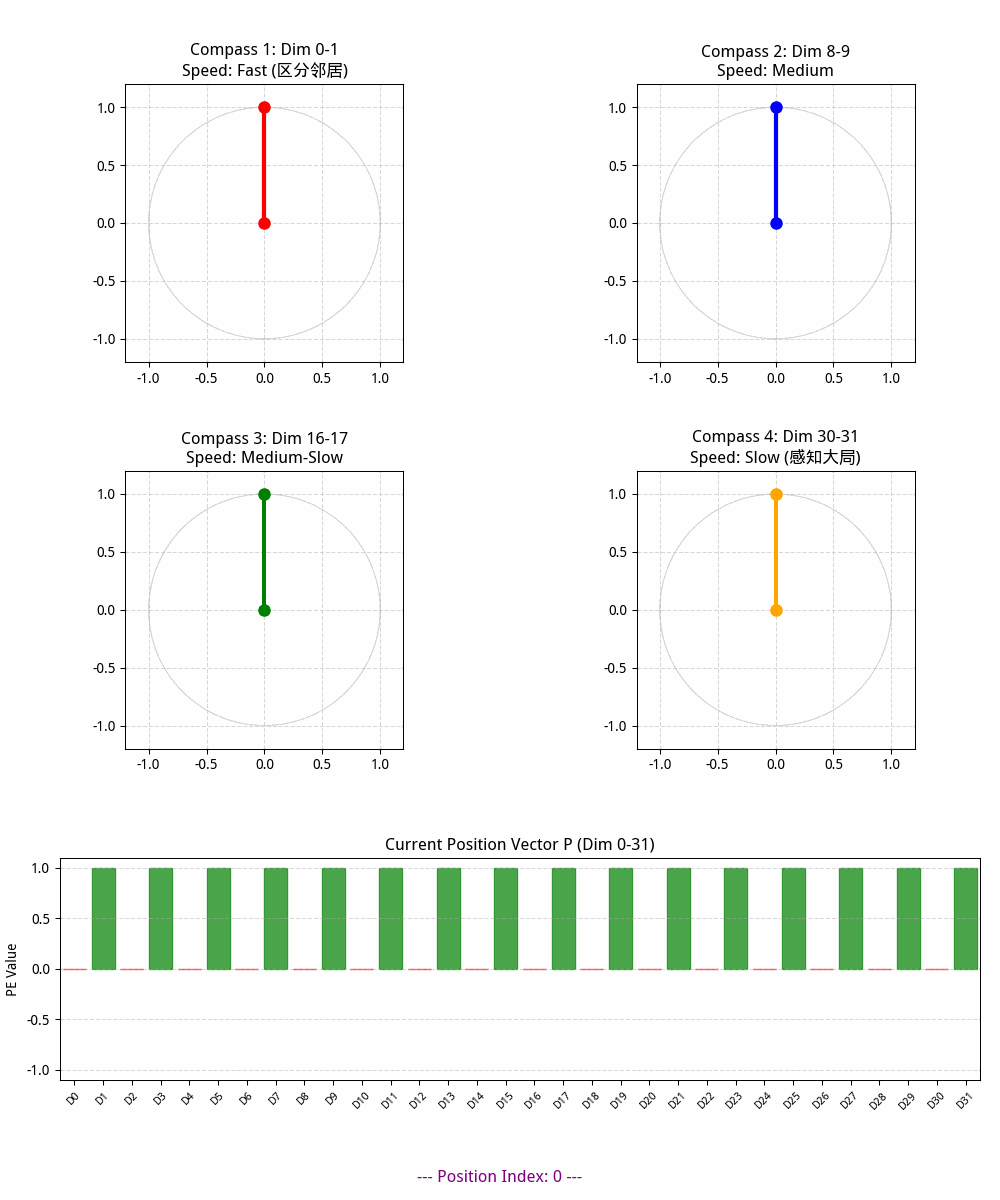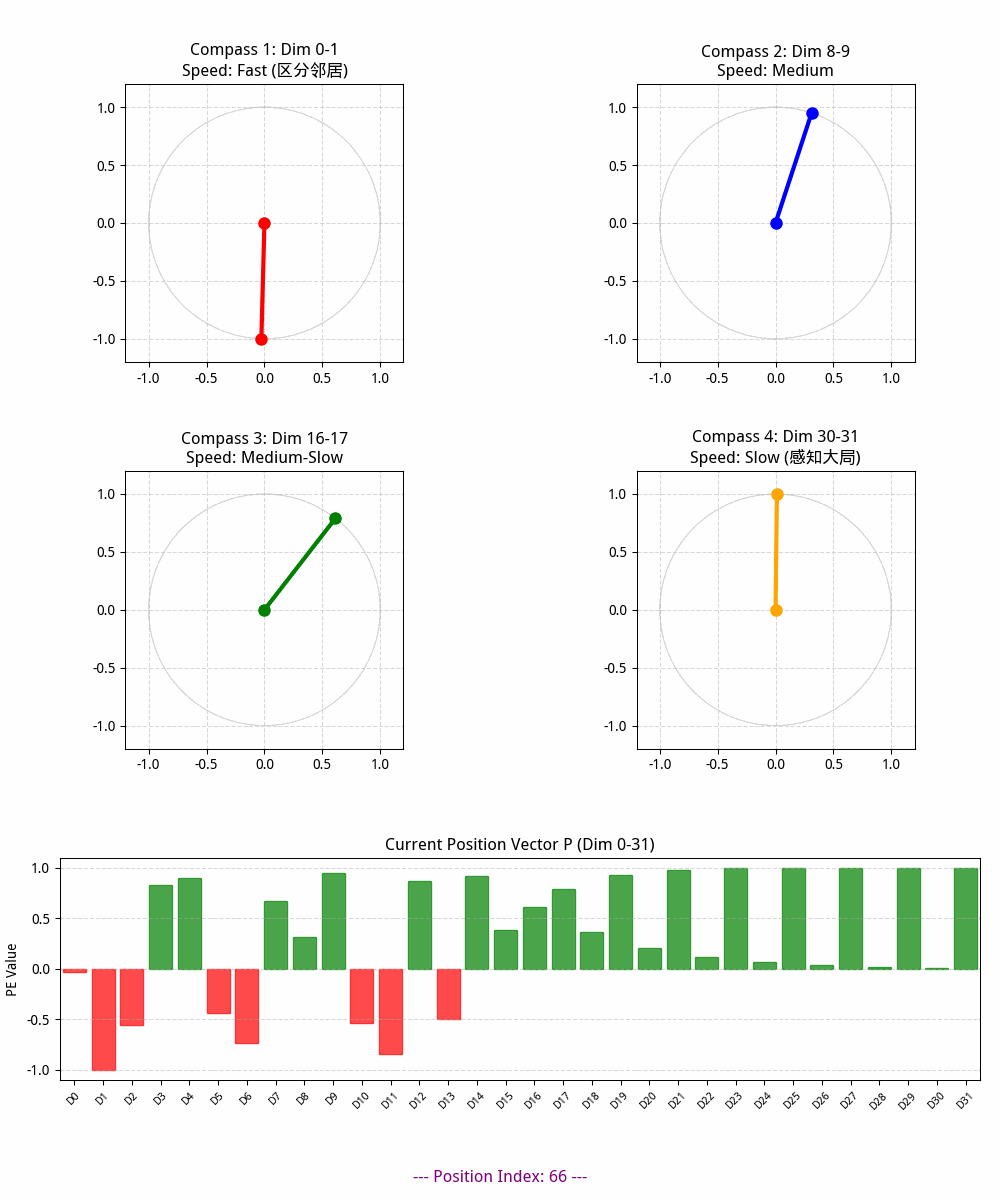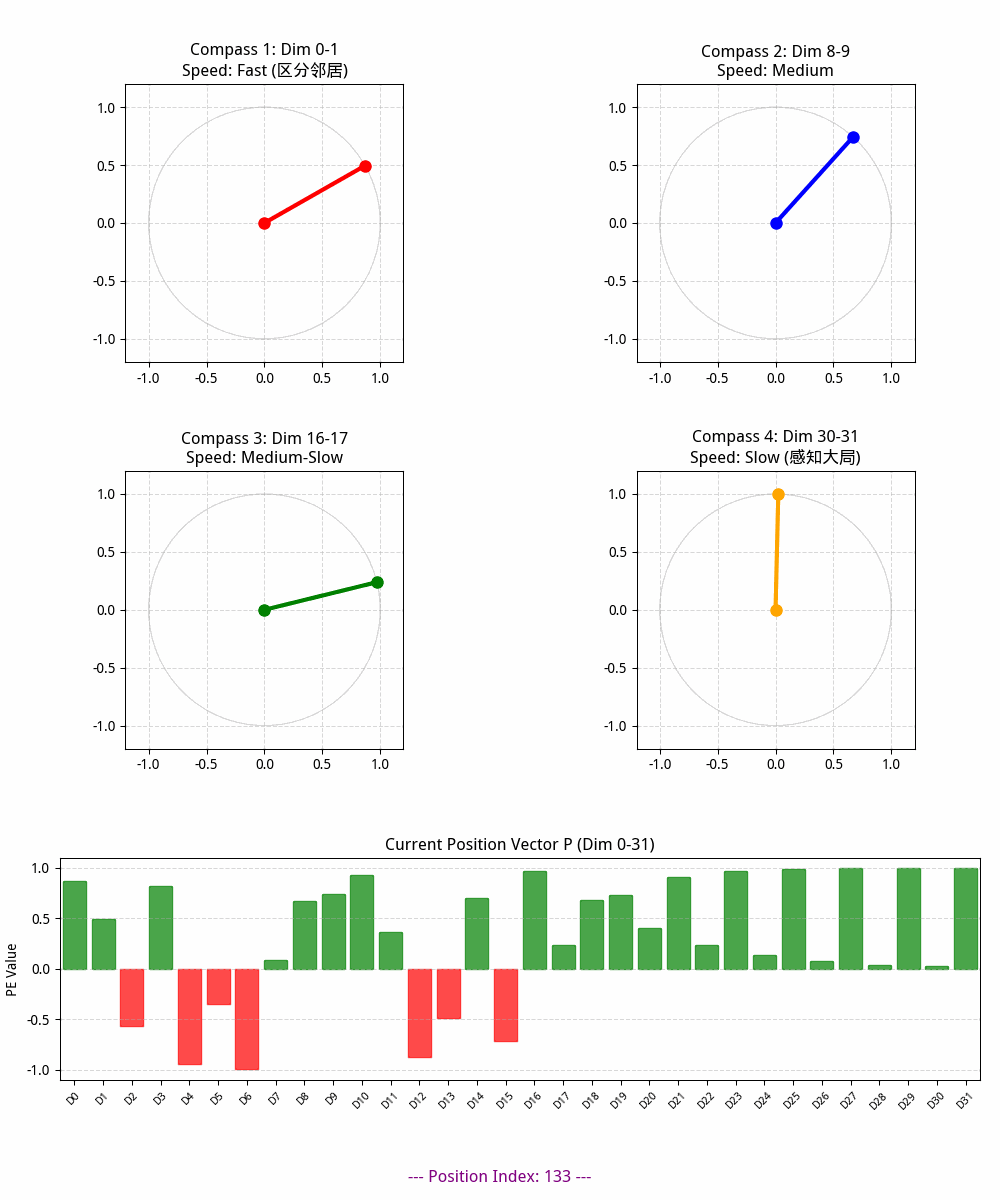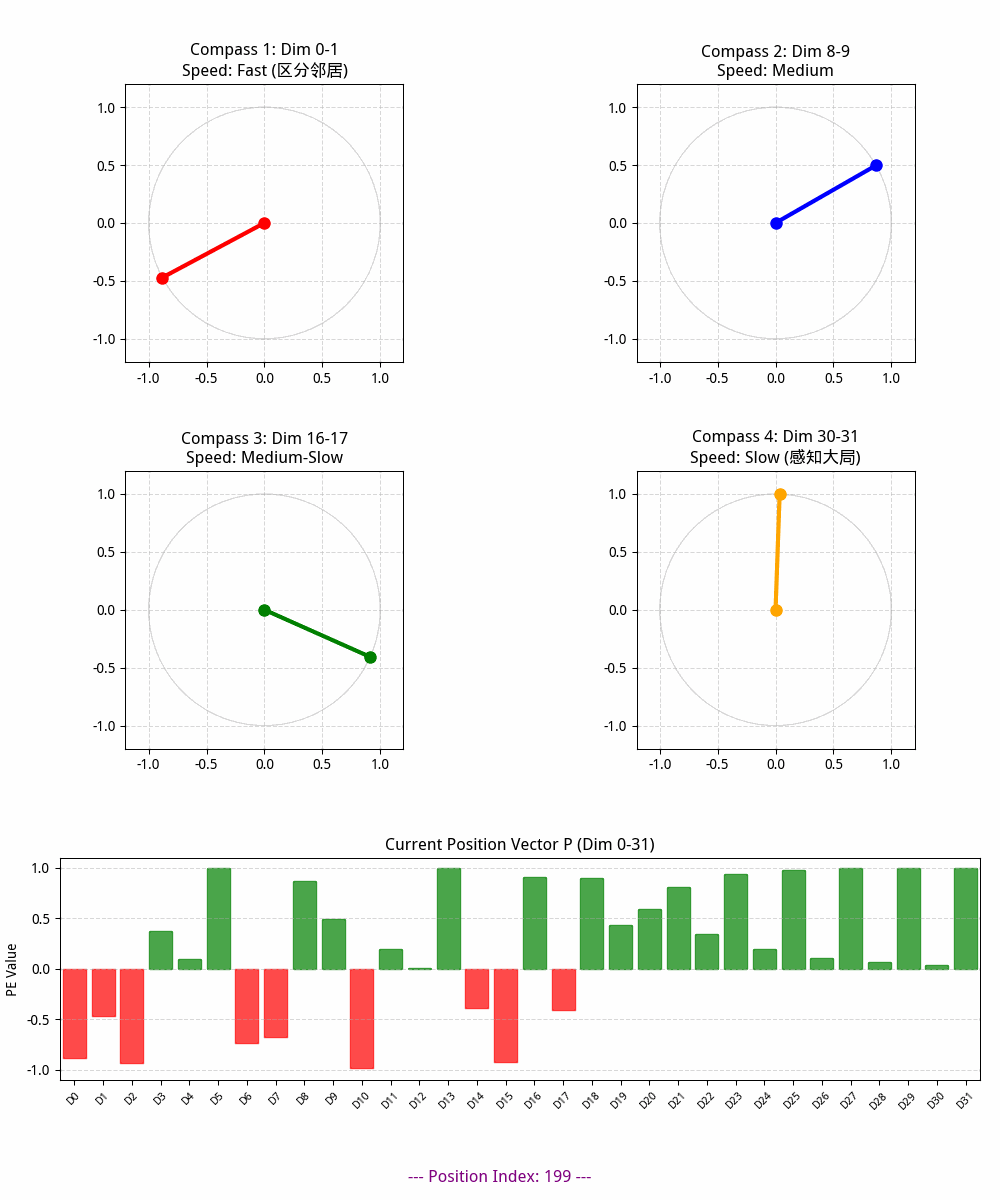
音频合成角度理解位置编码
源码
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.animation import FuncAnimation, PillowWriter
import matplotlib.font_manager as fm
import os
def configure_matplotlib_chinese_font():
"""自动选择可用中文字体,避免中文显示异常。"""
candidates = [
"Noto Sans CJK SC",
"Noto Sans CJK",
"WenQuanYi Micro Hei",
"WenQuanYi Zen Hei",
"SimHei",
"Microsoft YaHei",
"PingFang SC",
"Source Han Sans CN",
"Arial Unicode MS",
]
installed = {f.name for f in fm.fontManager.ttflist}
for name in candidates:
if name in installed:
plt.rcParams["font.family"] = "sans-serif"
plt.rcParams["font.sans-serif"] = [name, "DejaVu Sans"]
break
plt.rcParams["axes.unicode_minus"] = False
configure_matplotlib_chinese_font()
# ===============================
# 1. 模拟参数
# ===============================
num_positions = 100 # 序列长度(相当于时间轴)
dim = 32 # 向量维度(位置矩阵每行32维)
x_axis = np.linspace(0, 10, dim)
# 位置纹理由多个正弦分量叠加而成(可视化重点)
# 第3个分量频率不宜过高,否则在32个采样点下会出现“看起来不像正弦”的锯齿感。
frequencies = [1.0, 2.5, 4.0] # 不同频率(平滑且层次分明)
amplitude = 0.3 # 每个分量的振幅
# 模拟一个“词向量”:比如它是一个平滑的低频波
def get_word_vector():
# 模拟“猫”这个词的语义信号(相对稳定)
return 0.5 * np.sin(x_axis * 0.8) + 0.2 * np.cos(x_axis * 0.3)
# 模拟位置编码:随位置变化的三角函数
def get_pe_components(pos):
"""返回当前位置下的各正弦分量列表。"""
components = []
for f in frequencies:
# 相位随位置变化:位置越靠后,波形整体相位越向前推进
comp = amplitude * np.sin(x_axis * f + pos * (f / 5.0))
components.append(comp)
return components
def get_pe_signal(pos, dim):
# 位置纹理信号 = 多个正弦分量逐维相加
components = get_pe_components(pos)
return np.sum(components, axis=0)
word_vec = get_word_vector()
# ===============================
# 2. 画布初始化
# ===============================
fig, (ax1, ax2, ax3, ax4) = plt.subplots(
4, 1, figsize=(10, 14), gridspec_kw={"height_ratios": [1, 1, 1, 0.9]}
)
# 增加子图间距与底部留白,避免第2图图例与第3图重叠。
plt.subplots_adjust(hspace=0.72, bottom=0.10, top=0.95)
# 词向量图
line1, = ax1.plot(x_axis, word_vec, lw=2, color='blue')
ax1.set_title("1. 原始语义信号 (Word Embedding: 'CAT')", fontsize=12)
ax1.set_ylim(-1.5, 1.5)
ax1.grid(True, alpha=0.3)
# 位置编码拆解图:多个正弦分量 + 总叠加曲线
component_colors = ['tab:blue', 'tab:green', 'tab:red']
component_lines = []
for idx, f in enumerate(frequencies):
comp_line, = ax2.plot(
x_axis,
np.zeros(dim),
lw=1.5,
color=component_colors[idx % len(component_colors)],
alpha=0.9,
linestyle='--',
label=f"分量{idx+1}: sin(freq={f})",
)
component_lines.append(comp_line)
line2, = ax2.plot(x_axis, np.zeros(dim), lw=2.6, color='orange', label="分量叠加结果")
ax2.set_title("2. 位置纹理信号拆解:多个正弦波叠加", fontsize=12)
ax2.set_ylim(-1.5, 1.5)
ax2.grid(True, alpha=0.3)
ax2.legend(loc='upper center', bbox_to_anchor=(0.5, -0.16), ncol=4, frameon=False, fontsize=8)
# 叠加结果图
line3, = ax3.plot(x_axis, np.zeros(dim), lw=3, color='purple')
ax3.set_title("3. 最终合成信号 (Embedding + PE)", fontsize=12)
ax3.set_ylim(-1.5, 1.5)
ax3.grid(True, alpha=0.3)
# 位置矩阵行向量图(参考 demo_07)
# 含义:在当前位置frame,取位置矩阵P的第frame行(即当前PE向量)并显示各维度数值。
ax4.set_title("4. 当前位置 PE 向量(位置矩阵的一行)", fontsize=12)
ax4.set_xlim(-0.5, dim - 0.5)
ax4.set_ylim(-1.5, 1.5)
ax4.set_ylabel("PE值")
ax4.set_xticks(np.arange(dim))
ax4.set_xticklabels([f"D{i}" for i in range(dim)], rotation=45, fontsize=8)
ax4.grid(axis='y', linestyle='--', alpha=0.3)
bars = ax4.bar(np.arange(dim), np.zeros(dim), color='purple', alpha=0.7)
# 文字提示(使用整张图坐标,而不是某个子图坐标)
pos_text = fig.text(0.5, 0.03, '', ha='center', fontsize=16, fontweight='bold', color='darkred')
# ===============================
# 3. 动画更新
# ===============================
def update(frame):
# 获取当前位置的PE信号
components = get_pe_components(frame)
current_pe = np.sum(components, axis=0)
# 更新PE拆解图(分量 + 总和)
for comp_line, comp in zip(component_lines, components):
comp_line.set_ydata(comp)
line2.set_ydata(current_pe)
# 更新叠加图(相加操作)
combined = word_vec + current_pe
line3.set_ydata(combined)
# 更新“当前位置PE向量”柱状图
for i, bar in enumerate(bars):
val = current_pe[i]
bar.set_height(val)
bar.set_color('green' if val > 0 else 'red')
pos_text.set_text(f"当前句子位置 (Position Index): {frame}")
return [*component_lines, line2, line3, pos_text, *bars]
ani = FuncAnimation(fig, update, frames=num_positions, interval=100, blit=True)
# 保存为GIF(保存在当前脚本同目录)
gif_path = os.path.join(os.path.dirname(__file__), "demo_08_animation.gif")
ani.save(gif_path, writer=PillowWriter(fps=10))
print(f"GIF已保存: {gif_path}")
plt.show()
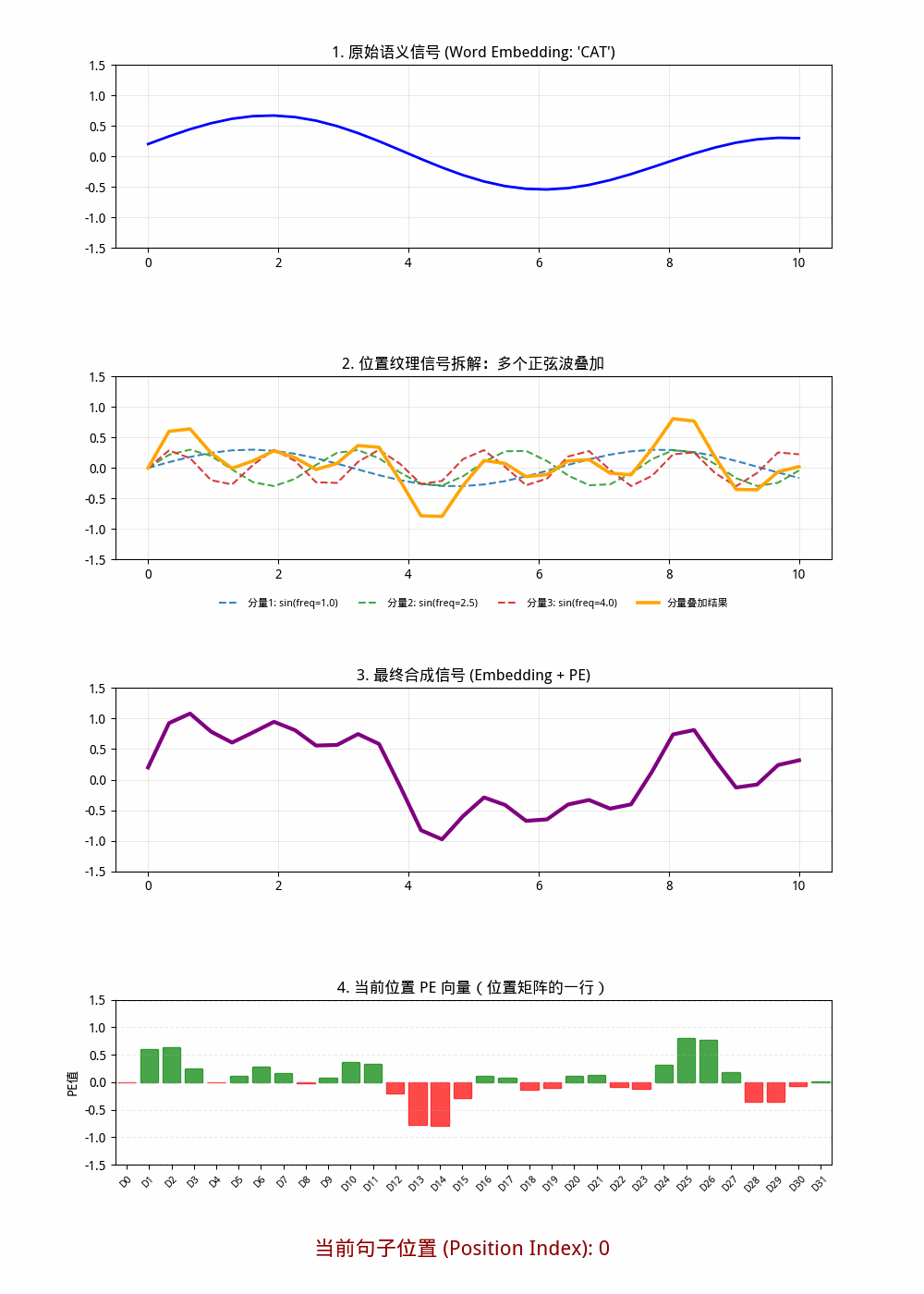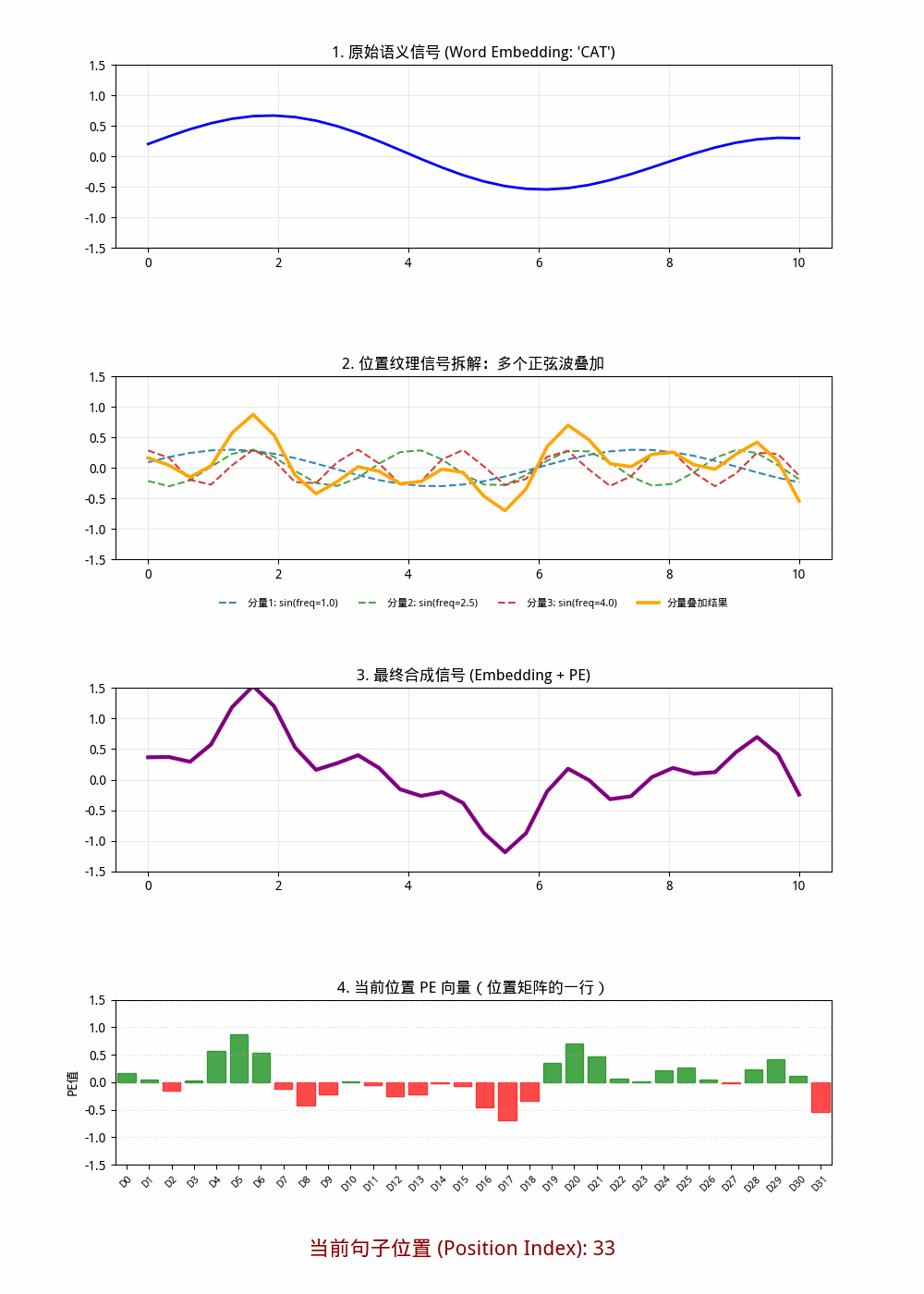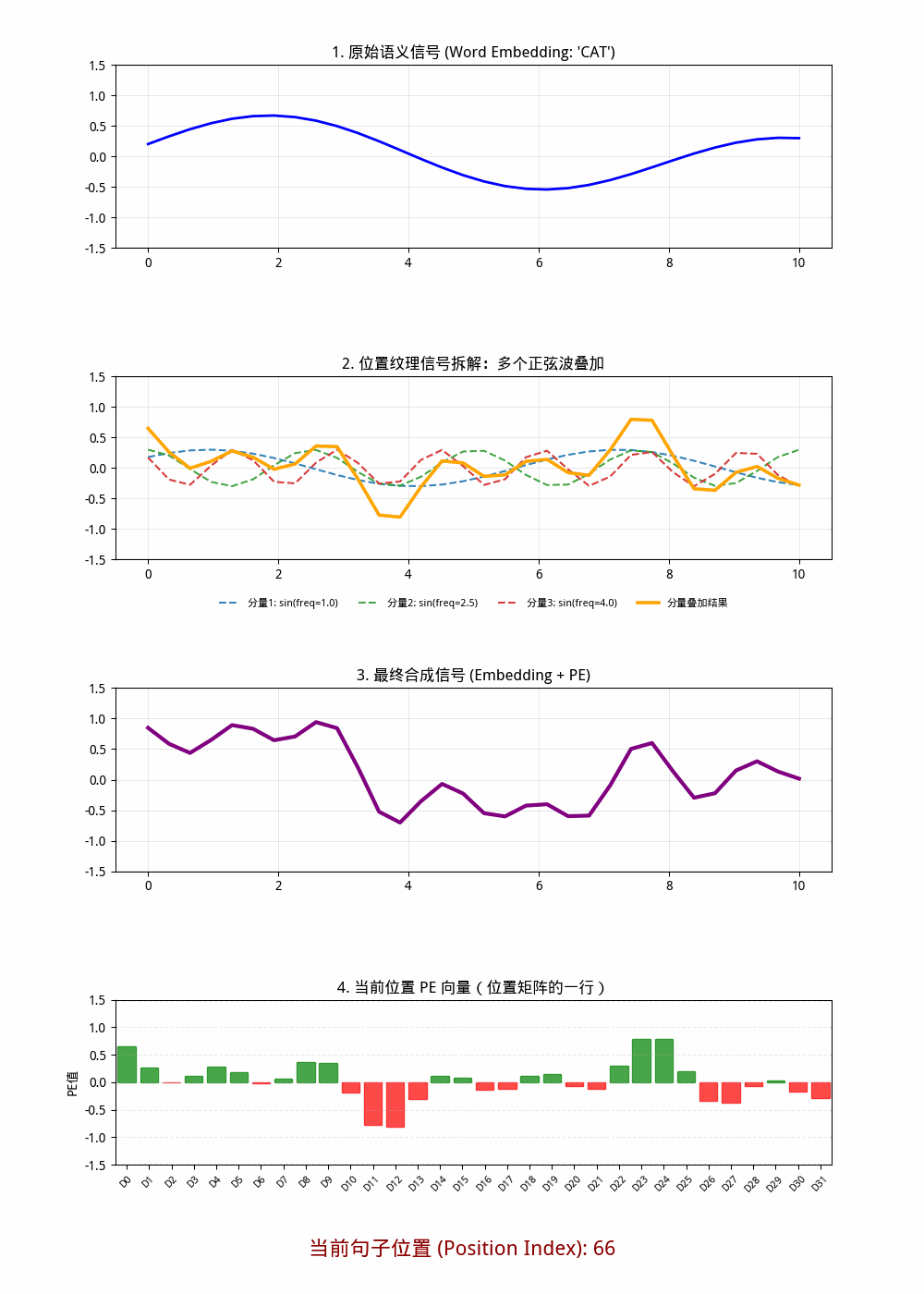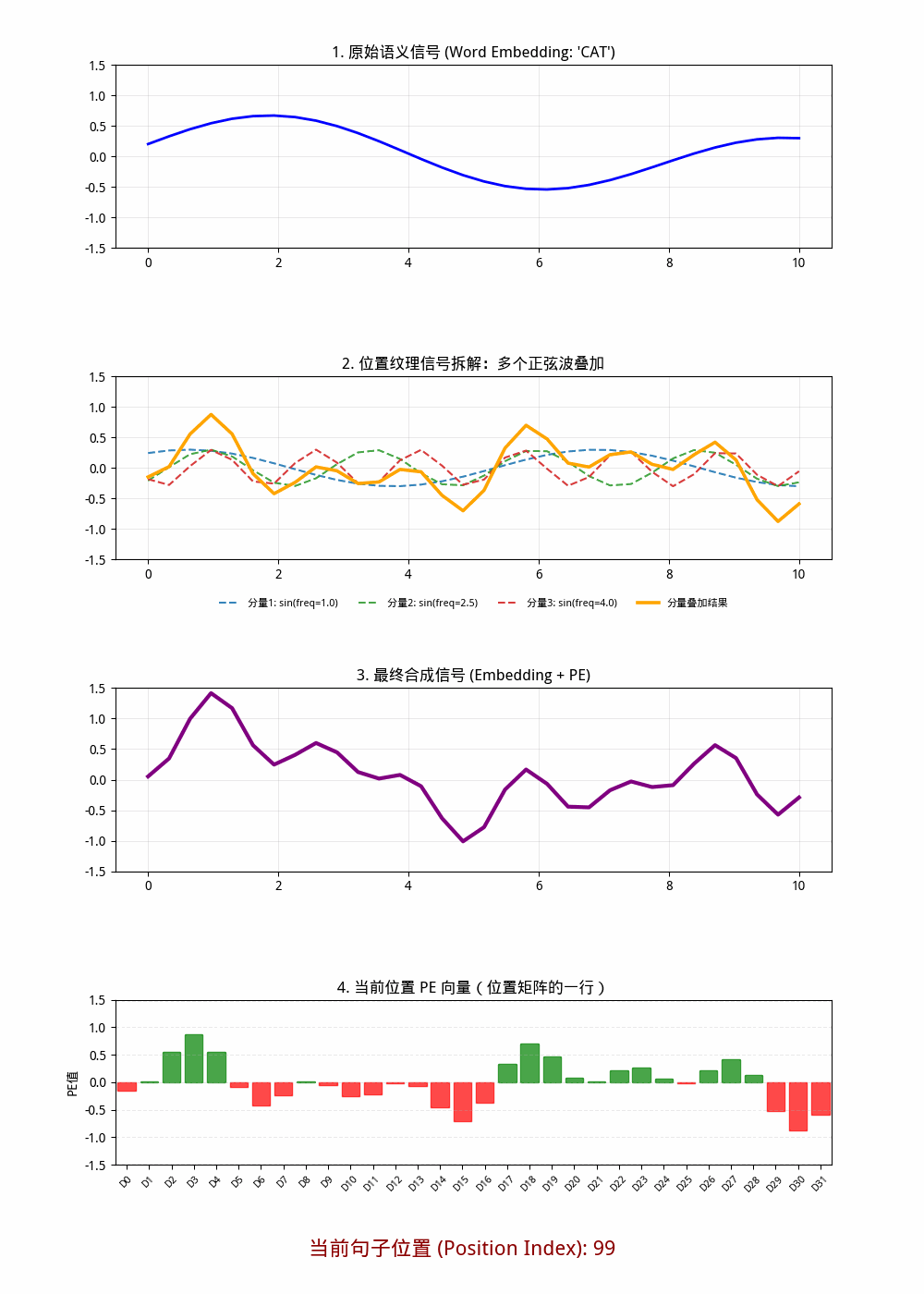
在 标准 Sin/Cos 位置编码 里:
- d_model = 32 时,一共是 32 个维度分量 。
- 其中按 (sin, cos) 成对出现,所以是 16 对 。
- 每一对对应一个频率尺度,因此可理解为 16 组频率分量 。
也就是说:
- 从“维度数”看: 32 个分量
- 从“频率对(sin/cos对)”看: 16 个分量组
图形2中只画出了三个频率分量,理论上有16个