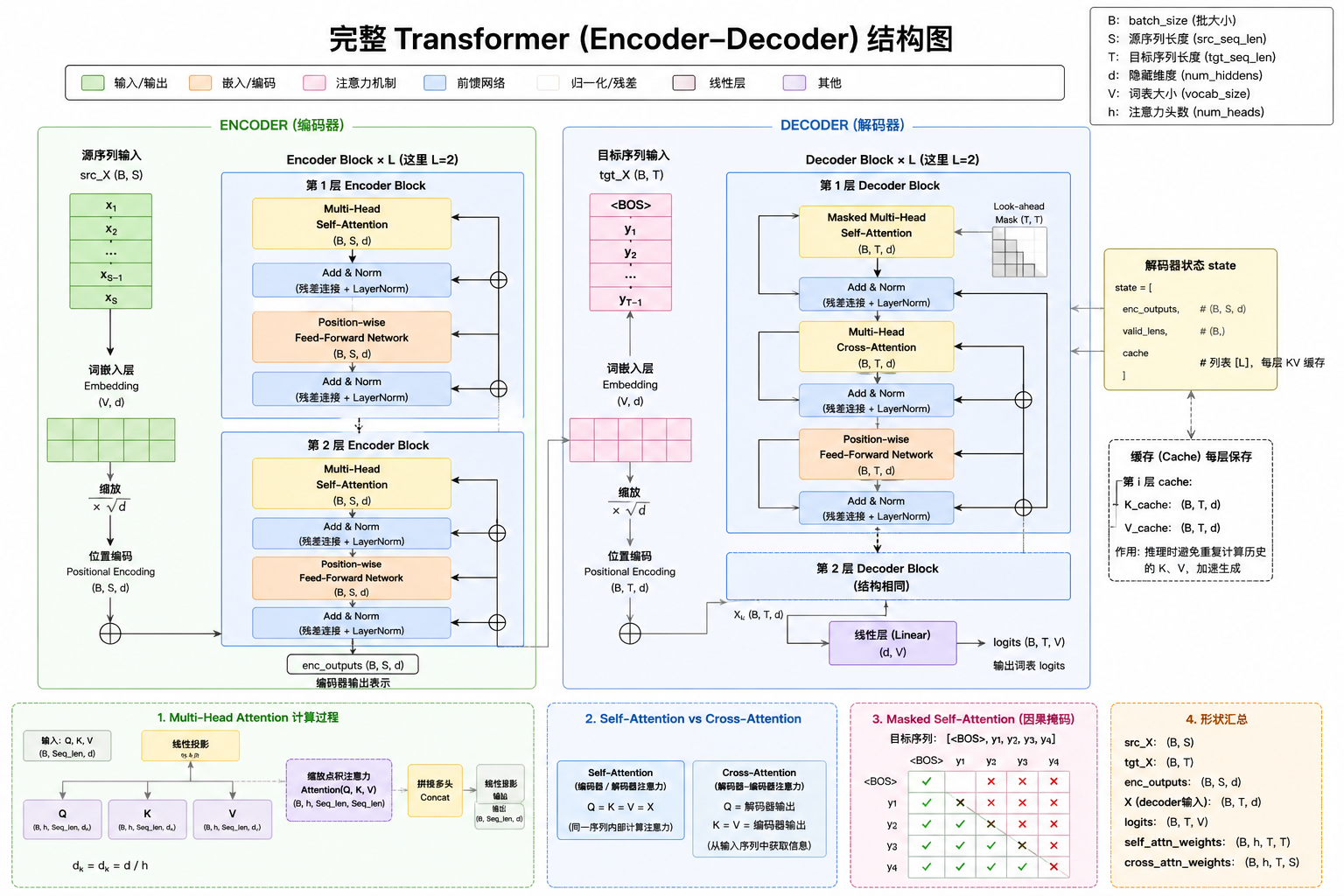
Transformer 架构
如果用一句工程化的话总结:
Transformer = “用矩阵并行计算的全局信息交互系统”
或者更直白: 它让每个 token 都能“瞬间看到全局”

基于位置的前馈网络
Position-wise Feed Forward Network(FFN)
import math
import pandas as pd
import torch
from torch import nn
from d2l import torch as d2l
def log_tensor_info(name, tensor):
"""统一打印张量信息:形状、dtype和完整张量。"""
print(f"[LOG] {name}: shape={tuple(tensor.shape)}, dtype={tensor.dtype}")
print(f"[LOG] {name} 完整内容:\n{tensor.detach().cpu()}")
#@save
class PositionWiseFFN(nn.Module):
"""基于位置的前馈网络"""
def __init__(self, ffn_num_input, ffn_num_hiddens, ffn_num_outputs,
**kwargs):
super(PositionWiseFFN, self).__init__(**kwargs)
# 第1层线性变换:把每个位置的特征从输入维映射到隐藏维
# 输入最后一维: ffn_num_input -> 输出最后一维: ffn_num_hiddens
self.dense1 = nn.Linear(ffn_num_input, ffn_num_hiddens)
# 非线性激活:为网络引入非线性表达能力
self.relu = nn.ReLU()
# 第2层线性变换:把隐藏维映射到目标输出维
# ffn_num_hiddens -> ffn_num_outputs
self.dense2 = nn.Linear(ffn_num_hiddens, ffn_num_outputs)
# 初始化日志,帮助理解网络结构
print("[LOG] PositionWiseFFN 初始化完成")
print(
f"[LOG] 输入维={ffn_num_input}, 隐藏维={ffn_num_hiddens}, 输出维={ffn_num_outputs}"
)
def forward(self, X):
# X 常见形状: (batch_size, num_steps, d_model)
# 注意“PositionWise”的含义:
# - 不同位置之间不会在FFN里混合(没有跨位置计算)
# - 仅对每个位置的向量独立执行“线性->ReLU->线性”
print("\n[LOG] ===== 进入 PositionWiseFFN.forward =====")
log_tensor_info("输入X", X)
h1 = self.dense1(X)
log_tensor_info("dense1(X)", h1)
h2 = self.relu(h1)
log_tensor_info("ReLU后", h2)
out = self.dense2(h2)
log_tensor_info("dense2输出", out)
print("[LOG] ===== 退出 PositionWiseFFN.forward =====\n")
return out
# 示例:输入维=4,隐藏维=4,输出维=8
ffn = PositionWiseFFN(4, 4, 8)
# 设为推理模式,确保输出可复现(该模块本身虽无dropout,依然是良好习惯)
ffn.eval()
# 构造输入:
# batch_size=2, num_steps=3, d_model=4
X = torch.ones((2, 3, 4))
log_tensor_info("示例输入X", X)
# 运行前馈网络
Y = ffn(X)
log_tensor_info("示例输出Y", Y)
# 打印第0个样本在所有位置上的输出(形状: 3x8)
print("[LOG] Y[0] =")
print(Y[0])
数据输入
[LOG] 输入X: shape=(2, 3, 4), dtype=torch.float32
[LOG] 示例输入X 完整内容:
tensor([[[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]],
[[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]]])
| 维度 | 含义 |
|---|---|
| 2 | batch_size(2个样本) |
| 3 | seq_len(每个样本3个token) |
| 4 | d_model(每个token 4维特征) |
进入 forward
Step 1:dense1(第一层线性变换)
h1 = self.dense1(X)
📌 本质计算
对每一个 token:
h1 = X @ W1^T + b1
📐 维度变化
输入: (2, 3, 4)
权重: (4 → 4)
输出: (2, 3, 4)
👉 注意:
PyTorch 的 nn.Linear(in, out) 实际权重是 (out, in)
自动对最后一维做矩阵乘法
[LOG] dense1 参数
[LOG] dense1.weight: shape=(4, 4), dtype=torch.float32
[LOG] dense1.weight 完整内容:
tensor([[ 0.0336, 0.1130, -0.3063, 0.4771],
[-0.2043, 0.2148, -0.2774, 0.2155],
[-0.1847, 0.0449, -0.3454, -0.3507],
[ 0.1168, 0.2330, -0.1549, 0.2228]])
[LOG] dense1.bias: shape=(4,), dtype=torch.float32
[LOG] dense1.bias 完整内容:
tensor([ 0.3793, 0.3294, -0.1541, 0.0368])
计算公式: h1 = X @ W1^T + b1
[LOG] dense1(X): shape=(2, 3, 4), dtype=torch.float32
[LOG] dense1(X) 完整内容:
tensor([[[ 0.6967, 0.2780, -0.9898, 0.4545],
[ 0.6967, 0.2780, -0.9898, 0.4545],
[ 0.6967, 0.2780, -0.9898, 0.4545]],
[[ 0.6967, 0.2780, -0.9898, 0.4545],
[ 0.6967, 0.2780, -0.9898, 0.4545],
[ 0.6967, 0.2780, -0.9898, 0.4545]]])
Step 2:ReLU(非线性激活)
h2 = self.relu(h1)
📌 本质计算
ReLU(x) = max(0, x)
🧠 实际作用
把负数变成0
保留正数
🔥 为什么必须有它?
如果没有 ReLU:
dense2(dense1(X)) = 一个大线性层
👉 整个网络就退化成:
❌ 线性模型(表达能力很差)
✅ 加了 ReLU 后:
👉 可以表示:
非线性关系
条件激活(类似“开关”)
[LOG] ReLU后: shape=(2, 3, 4), dtype=torch.float32
[LOG] ReLU后 完整内容:
tensor([[[0.6967, 0.2780, 0.0000, 0.4545],
[0.6967, 0.2780, 0.0000, 0.4545],
[0.6967, 0.2780, 0.0000, 0.4545]],
[[0.6967, 0.2780, 0.0000, 0.4545],
[0.6967, 0.2780, 0.0000, 0.4545],
[0.6967, 0.2780, 0.0000, 0.4545]]])
Step 3:dense2(第二层线性变换)
out = self.dense2(h2)
📌 本质计算
out = h2 @ W2^T + b2
📐 维度变化
输入: (2, 3, 4)
权重: (4 → 8)
输出: (2, 3, 8)
🧠 实际作用
👉 把“激活后的特征”投影到更高维空间:
4维 → 8维
🔥 直观理解
这一层在做:
重新编码信息(feature projection)
[LOG] dense2 参数
[LOG] dense2.weight: shape=(8, 4), dtype=torch.float32
[LOG] dense2.weight 完整内容:
tensor([[-3.5300e-01, -3.9332e-01, 2.8701e-01, -3.4535e-02],
[ 3.8852e-01, -3.8515e-01, -3.9982e-01, -6.5256e-02],
[-4.0756e-01, -1.3083e-04, 1.9923e-01, 2.6752e-01],
[-9.9782e-02, 5.5980e-02, -4.2391e-01, -4.8913e-02],
[-5.7005e-02, 2.1488e-01, 2.4811e-01, -3.3240e-01],
[ 6.8557e-02, -4.1339e-01, -3.3388e-01, -2.0628e-01],
[-2.1272e-01, 5.8841e-02, -1.2252e-01, -4.8725e-02],
[ 4.8711e-01, -3.8770e-02, 3.9174e-01, 4.7053e-01]])
[LOG] dense2.bias: shape=(8,), dtype=torch.float32
[LOG] dense2.bias 完整内容:
tensor([-0.3661, -0.3997, -0.1815, -0.2088, 0.2070, 0.1019, -0.4531, -0.0070])
[LOG] dense2输出: shape=(2, 3, 8), dtype=torch.float32
[LOG] dense2输出 完整内容:
tensor([[[-0.7371, -0.2657, -0.3439, -0.2850, 0.0760, -0.0590, -0.6071, 0.5354],
[-0.7371, -0.2657, -0.3439, -0.2850, 0.0760, -0.0590, -0.6071, 0.5354],
[-0.7371, -0.2657, -0.3439, -0.2850, 0.0760, -0.0590, -0.6071, 0.5354]],
[[-0.7371, -0.2657, -0.3439, -0.2850, 0.0760, -0.0590, -0.6071, 0.5354],
[-0.7371, -0.2657, -0.3439, -0.2850, 0.0760, -0.0590, -0.6071, 0.5354],
[-0.7371, -0.2657, -0.3439, -0.2850, 0.0760, -0.0590, -0.6071, 0.5354]]])
[LOG] ===== 退出 PositionWiseFFN.forward =====
FFN 架构
Position-wise Feed Forward Network(FFN)的作用
在 Transformer 里,FFN 常被一句话概括:对每个 token 独立做的两层 MLP,用来增强表示能力(非线性特征变换)
输入 token 向量 x (4维)
│
▼
┌─────────────────────┐
│ Linear (dense1) │
│ W1: 4 → 4 │
└─────────────────────┘
│
▼
中间特征 h1
│
▼
┌─────────────────────┐
│ ReLU 激活 │
└─────────────────────┘
│
▼
激活特征 h2
│
▼
┌─────────────────────┐
│ Linear (dense2) │
│ W2: 4 → 8 │
└─────────────────────┘
│
▼
输出向量 y (8维)
关键结构特点(图中最重要的点)
1️⃣ “逐位置”处理(核心)
batch 0:
token1 ──► FFN ──► y1
token2 ──► FFN ──► y2
token3 ──► FFN ──► y3
batch 1:
token1 ──► FFN ──► y1
token2 ──► FFN ──► y2
token3 ──► FFN ──► y3
👉 每个 token:
完全独立
共享同一套权重
2️⃣ 不跨 token(非常重要)
token1 ❌ 不会看到 token2
token2 ❌ 不会看到 token3
👉 所以它不是“序列建模层”
残差连接和层规范化
第一部分代码解析
# LayerNorm 与 BatchNorm 对比示例
# - LayerNorm: 对“每个样本自身的特征维”做归一化(与batch大小无关)
# - BatchNorm1d: 对“一个batch同一特征维”做归一化(依赖batch统计量)
ln = nn.LayerNorm(2)
bn = nn.BatchNorm1d(2)
X = torch.tensor([[1, 2], [2, 3]], dtype=torch.float32)
# 在训练模式下计算X的均值和方差
print("\n[LOG] ===== LayerNorm vs BatchNorm 示例 =====")
log_tensor_info("输入X", X)
ln_out = ln(X)
bn_out = bn(X)
log_tensor_info("LayerNorm输出", ln_out)
log_tensor_info("BatchNorm输出", bn_out)
print("[LOG] ===== 结束 LayerNorm vs BatchNorm 示例 =====\n")
数据输入
[LOG] ===== LayerNorm vs BatchNorm 示例 =====
[LOG] 输入X: shape=(2, 2), dtype=torch.float32
[LOG] 输入X 完整内容:
tensor([[1., 2.],
[2., 3.]])
LayerNorm 逐样本计算
[LOG] LayerNorm输出: shape=(2, 2), dtype=torch.float32
[LOG] LayerNorm输出 完整内容:
tensor([[-1.0000, 1.0000],
[-1.0000, 1.0000]])
👉 每个样本内部被“拉成零均值、单位方差”
BatchNorm1d 逐通道计算
[LOG] BatchNorm输出: shape=(2, 2), dtype=torch.float32
[LOG] BatchNorm输出 完整内容:
tensor([[-1.0000, -1.0000],
[ 1.0000, 1.0000]])
| 方法 | 归一化方向 |
|---|---|
| LayerNorm | 每一行(样本内部) |
| BatchNorm | 每一列(跨 batch) |
第二部分代码解析
#@save
class AddNorm(nn.Module):
"""残差连接后进行层规范化"""
def __init__(self, normalized_shape, dropout, **kwargs):
super(AddNorm, self).__init__(**kwargs)
# dropout作用于子层输出Y,再与残差X相加,最后做LayerNorm。
self.dropout = nn.Dropout(dropout)
self.ln = nn.LayerNorm(normalized_shape)
print("[LOG] AddNorm 初始化完成")
print(f"[LOG] normalized_shape={normalized_shape}, dropout={dropout}")
def forward(self, X, Y):
print("\n[LOG] ===== 进入 AddNorm.forward =====")
log_tensor_info("残差输入X", X)
log_tensor_info("子层输出Y", Y)
y_drop = self.dropout(Y)
log_tensor_info("dropout(Y)", y_drop)
added = y_drop + X
log_tensor_info("残差相加结果(Y_drop + X)", added)
out = self.ln(added)
log_tensor_info("LayerNorm后输出", out)
print("[LOG] ===== 退出 AddNorm.forward =====\n")
return out
add_norm = AddNorm([3, 4], 0.5)
add_norm.eval()
addnorm_out = add_norm(torch.ones((2, 3, 4)), torch.ones((2, 3, 4)))
log_tensor_info("AddNorm示例输出", addnorm_out)
print(f"[LOG] AddNorm示例输出形状: {tuple(addnorm_out.shape)}")
Step 1: 数据输入
[LOG] ===== 进入 AddNorm.forward =====
[LOG] 残差输入X: shape=(2, 3, 4), dtype=torch.float32
[LOG] 残差输入X 完整内容:
tensor([[[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]],
[[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]]])
[LOG] 子层输出Y: shape=(2, 3, 4), dtype=torch.float32
[LOG] 子层输出Y 完整内容:
tensor([[[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]],
[[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]]])
Step 2:Dropout
add_norm.eval()
👉 eval 模式:
dropout 关闭
所以:
y_drop = Y
[LOG] dropout(Y): shape=(2, 3, 4), dtype=torch.float32
[LOG] dropout(Y) 完整内容:
tensor([[[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]],
[[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]]])
Step 3:残差相加
[LOG] 残差相加结果(Y_drop + X): shape=(2, 3, 4), dtype=torch.float32
[LOG] 残差相加结果(Y_drop + X) 完整内容:
tensor([[[2., 2., 2., 2.],
[2., 2., 2., 2.],
[2., 2., 2., 2.]],
[[2., 2., 2., 2.],
[2., 2., 2., 2.],
[2., 2., 2., 2.]]])
Step 4:LayerNorm(核心)
[LOG] LayerNorm后输出: shape=(2, 3, 4), dtype=torch.float32
[LOG] LayerNorm后输出 完整内容:
tensor([[[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]],
[[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]]])
为什么是全 0?
因为:所有值完全一样 → 方差=0 → 全部归一化为0
AddNorm 结构图
X(残差输入)
│
│
│ Y(子层输出)
│ │
│ ▼
│ Dropout(训练才生效)
│ │
│ ▼
└──────► 加法 ◄──────┘
│
▼
LayerNorm
│
▼
输出
1️⃣ 残差连接 X + Y
作用:
- 防止梯度消失
- 保留原始信息
- 允许“微调而不是重写”
2️⃣ LayerNorm
作用:
- 控制数值范围
- 稳定训练
- 加速收敛
3️⃣ Dropout
作用:防止过拟合(训练时)
编码器
第一部分代码理解
#@save
class EncoderBlock(nn.Module):
"""Transformer编码器块
结构:
输入X
│
├──► 多头自注意力(Q=K=V=X) ──► AddNorm(残差+LayerNorm) ──► Y
│ │
└───────────────────────────────────────────────────────── ┘
│
┌──────────────────────────────────────────────────────────┘
│
├──► PositionWiseFFN(Y) ──► AddNorm(残差+LayerNorm) ──► 输出
│ │
└──────────────────────────────────────────────────────────┘
"""
def __init__(self, key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,
dropout, use_bias=False, **kwargs):
super(EncoderBlock, self).__init__(**kwargs)
# 子层1:多头自注意力
# Q、K、V 均来自同一输入X(自注意力),输出维度为 num_hiddens
# 新版 d2l.MultiHeadAttention 签名: (num_hiddens, num_heads, dropout, bias)
# 不再需要单独传 key_size/query_size/value_size
self.attention = d2l.MultiHeadAttention(
num_hiddens, num_heads, dropout, use_bias)
# 子层1 后的残差连接 + 层归一化
self.addnorm1 = AddNorm(norm_shape, dropout)
# 子层2:逐位置前馈网络,对每个位置独立做非线性变换
self.ffn = PositionWiseFFN(
ffn_num_input, ffn_num_hiddens, num_hiddens)
# 子层2 后的残差连接 + 层归一化
self.addnorm2 = AddNorm(norm_shape, dropout)
print("[LOG] EncoderBlock 初始化完成")
print(f"[LOG] num_hiddens={num_hiddens}, num_heads={num_heads}, "
f"ffn_num_hiddens={ffn_num_hiddens}, dropout={dropout}")
def forward(self, X, valid_lens):
"""
参数:
X : (batch_size, num_steps, num_hiddens) 编码器输入
valid_lens : (batch_size,) 或 None,用于屏蔽填充位置
返回:
与X形状相同的编码输出
"""
print("\n[LOG] ========== 进入 EncoderBlock.forward ==========")
log_tensor_info("输入X", X)
print(f"[LOG] valid_lens={valid_lens}")
# --- 子层1:多头自注意力 ---
# Q=K=V=X,让每个位置都能关注序列中所有位置(受valid_lens限制)
attn_out = self.attention(X, X, X, valid_lens)
log_tensor_info("多头自注意力输出 attn_out", attn_out)
# 残差连接 + LayerNorm:attn_out经dropout后与X相加,再归一化
Y = self.addnorm1(X, attn_out)
log_tensor_info("AddNorm1后输出Y", Y)
# --- 子层2:逐位置前馈网络 ---
ffn_out = self.ffn(Y)
log_tensor_info("FFN输出 ffn_out", ffn_out)
# 残差连接 + LayerNorm:ffn_out经dropout后与Y相加,再归一化
out = self.addnorm2(Y, ffn_out)
log_tensor_info("AddNorm2后输出(EncoderBlock最终输出)", out)
print("[LOG] ========== 退出 EncoderBlock.forward ==========\n")
return out
print("\n[LOG] ===== 编码器块测试 =====")
# 构造测试输入:batch_size=2, num_steps=100, num_hiddens=24
X = torch.ones((2, 100, 24))
log_tensor_info("测试输入X", X)
# valid_lens: 第0个样本只看前3个位置,第1个样本只看前2个位置
valid_lens = torch.tensor([3, 2])
print(f"[LOG] valid_lens={valid_lens}")
# 初始化编码器块
# key/query/value_size=24, num_hiddens=24, norm_shape=[100,24]
# ffn_num_input=24, ffn_num_hiddens=48, num_heads=8, dropout=0.5
encoder_blk = EncoderBlock(24, 24, 24, 24, [100, 24], 24, 48, 8, 0.5)
encoder_blk.eval() # 推理模式,dropout不生效,结果可复现
output = encoder_blk(X, valid_lens)
print(f"[LOG] EncoderBlock输出形状: {tuple(output.shape)}")
print("[LOG] ===== 编码器块测试结束 =====\n")
架构
X
│
├── Self-Attention
│ ↓
├── Add & Norm (残差1)
│ ↓
├── FFN
│ ↓
└── Add & Norm (残差2)
↓
输出
数据输入
X.shape = (2, 100, 24)
[LOG] 测试输入X: shape=(2, 100, 24), dtype=torch.float32
[LOG] 测试输入X 完整内容:
tensor([[[1., 1., 1., ..., 1., 1., 1.],
[1., 1., 1., ..., 1., 1., 1.],
[1., 1., 1., ..., 1., 1., 1.],
...,
[1., 1., 1., ..., 1., 1., 1.],
[1., 1., 1., ..., 1., 1., 1.],
[1., 1., 1., ..., 1., 1., 1.]],
[[1., 1., 1., ..., 1., 1., 1.],
[1., 1., 1., ..., 1., 1., 1.],
[1., 1., 1., ..., 1., 1., 1.],
...,
[1., 1., 1., ..., 1., 1., 1.],
[1., 1., 1., ..., 1., 1., 1.],
[1., 1., 1., ..., 1., 1., 1.]]])
| 维度 | 说明 |
|---|---|
| 2 | batch |
| 100 | 序列长度 |
| 24 | embedding维度 |
valid_lens = [3, 2]
👉 作用:
第1个样本:只允许看前3个 token
第2个样本:只允许看前2个 token
👉 后面的 token 会被 mask 掉
PositionWiseFFN
[LOG] PositionWiseFFN 初始化完成
[LOG] 输入维=24, 隐藏维=48, 输出维=24
[LOG] dense1 参数
[LOG] dense1.weight: shape=(48, 24), dtype=torch.float32
[LOG] dense1.weight 完整内容:
tensor([[-0.0627, 0.1583, 0.0363, ..., -0.1293, -0.1403, 0.0511],
[-0.1481, 0.0495, -0.0628, ..., -0.0917, -0.1495, -0.0644],
[-0.0271, -0.1870, -0.0948, ..., -0.1679, -0.1096, 0.0957],
...,
[-0.0276, 0.1536, 0.0568, ..., -0.1469, -0.0915, -0.0856],
[ 0.1135, -0.0184, 0.0330, ..., 0.0470, 0.2012, -0.0248],
[ 0.0607, 0.0418, -0.1447, ..., 0.0322, -0.0400, -0.0710]])
[LOG] dense1.bias: shape=(48,), dtype=torch.float32
[LOG] dense1.bias 完整内容:
tensor([ 0.1649, 0.1784, -0.0196, -0.0276, 0.0587, -0.1541, -0.1756, -0.1351,
0.1887, -0.1075, -0.0332, -0.0600, -0.1659, -0.1472, -0.1123, -0.1028,
0.0076, 0.0641, 0.1130, 0.0777, -0.0257, -0.0656, -0.0449, -0.1324,
-0.0187, -0.1960, -0.1980, -0.1332, -0.1313, -0.1265, 0.1737, -0.0182,
-0.0558, -0.0620, -0.1547, 0.0924, -0.0586, -0.1146, 0.1801, -0.0604,
-0.1654, -0.1518, 0.1121, 0.1409, 0.0836, -0.0488, -0.1851, -0.0886])
[LOG] dense2 参数
[LOG] dense2.weight: shape=(24, 48), dtype=torch.float32
[LOG] dense2.weight 完整内容:
tensor([[ 0.0248, -0.1010, 0.0445, ..., -0.1299, 0.1192, -0.1108],
[ 0.0041, -0.1158, 0.1042, ..., 0.0748, 0.0463, 0.0654],
[-0.0787, -0.0308, -0.1035, ..., 0.0877, 0.1203, -0.1250],
...,
[-0.0394, -0.0815, 0.0370, ..., -0.1113, -0.0425, 0.0554],
[ 0.1180, -0.1212, 0.0735, ..., -0.0208, -0.1322, -0.0840],
[ 0.1339, 0.0996, 0.0584, ..., -0.0632, -0.0570, -0.0192]])
[LOG] dense2.bias: shape=(24,), dtype=torch.float32
[LOG] dense2.bias 完整内容:
tensor([-0.0400, 0.0554, 0.0028, -0.1291, -0.0754, 0.1313, -0.0341, 0.1149,
0.0035, -0.1052, 0.0067, -0.0261, -0.0183, -0.0008, 0.0731, 0.0730,
0.1362, 0.1111, -0.0523, -0.1191, -0.1024, -0.1101, 0.1146, -0.1102])
Step 1:多头自注意力(Self-Attention)
attn_out = self.attention(X, X, X, valid_lens)
📌 本质
Q = X
K = X
V = X
👉 每个 token:
“去看整个序列(但受 valid_lens 限制)”
📐 输出形状
attn_out.shape = (2, 100, 24)
🔥 关键理解
这一层负责:token之间的信息交互
[LOG] 多头自注意力输出 attn_out: shape=(2, 100, 24), dtype=torch.float32
[LOG] 多头自注意力输出 attn_out 完整内容:
tensor([[[ 0.4831, -0.0471, -0.7931, ..., 0.2540, 0.2923, -0.1334],
[ 0.4831, -0.0471, -0.7931, ..., 0.2540, 0.2923, -0.1334],
[ 0.4831, -0.0471, -0.7931, ..., 0.2540, 0.2923, -0.1334],
...,
[ 0.4831, -0.0471, -0.7931, ..., 0.2540, 0.2923, -0.1334],
[ 0.4831, -0.0471, -0.7931, ..., 0.2540, 0.2923, -0.1334],
[ 0.4831, -0.0471, -0.7931, ..., 0.2540, 0.2923, -0.1334]],
[[ 0.4831, -0.0471, -0.7931, ..., 0.2540, 0.2923, -0.1334],
[ 0.4831, -0.0471, -0.7931, ..., 0.2540, 0.2923, -0.1334],
[ 0.4831, -0.0471, -0.7931, ..., 0.2540, 0.2923, -0.1334],
...,
[ 0.4831, -0.0471, -0.7931, ..., 0.2540, 0.2923, -0.1334],
[ 0.4831, -0.0471, -0.7931, ..., 0.2540, 0.2923, -0.1334],
[ 0.4831, -0.0471, -0.7931, ..., 0.2540, 0.2923, -0.1334]]])
Step 2:AddNorm1(残差 + LayerNorm)
Y = self.addnorm1(X, attn_out)
作用
1️⃣ 残差
X + attn_out
👉 保留原始信息
2️⃣ LayerNorm
👉 稳定数值分布
📐 输出
Y.shape = (2, 100, 24)
[LOG] 子层输出Y: shape=(2, 100, 24), dtype=torch.float32
[LOG] 子层输出Y 完整内容:
tensor([[[ 0.4831, -0.0471, -0.7931, ..., 0.2540, 0.2923, -0.1334],
[ 0.4831, -0.0471, -0.7931, ..., 0.2540, 0.2923, -0.1334],
[ 0.4831, -0.0471, -0.7931, ..., 0.2540, 0.2923, -0.1334],
...,
[ 0.4831, -0.0471, -0.7931, ..., 0.2540, 0.2923, -0.1334],
[ 0.4831, -0.0471, -0.7931, ..., 0.2540, 0.2923, -0.1334],
[ 0.4831, -0.0471, -0.7931, ..., 0.2540, 0.2923, -0.1334]],
[[ 0.4831, -0.0471, -0.7931, ..., 0.2540, 0.2923, -0.1334],
[ 0.4831, -0.0471, -0.7931, ..., 0.2540, 0.2923, -0.1334],
[ 0.4831, -0.0471, -0.7931, ..., 0.2540, 0.2923, -0.1334],
...,
[ 0.4831, -0.0471, -0.7931, ..., 0.2540, 0.2923, -0.1334],
[ 0.4831, -0.0471, -0.7931, ..., 0.2540, 0.2923, -0.1334],
[ 0.4831, -0.0471, -0.7931, ..., 0.2540, 0.2923, -0.1334]]])
[LOG] 残差相加结果(Y_drop + X): shape=(2, 100, 24), dtype=torch.float32
[LOG] 残差相加结果(Y_drop + X) 完整内容:
tensor([[[1.4831, 0.9529, 0.2069, ..., 1.2540, 1.2923, 0.8666],
[1.4831, 0.9529, 0.2069, ..., 1.2540, 1.2923, 0.8666],
[1.4831, 0.9529, 0.2069, ..., 1.2540, 1.2923, 0.8666],
...,
[1.4831, 0.9529, 0.2069, ..., 1.2540, 1.2923, 0.8666],
[1.4831, 0.9529, 0.2069, ..., 1.2540, 1.2923, 0.8666],
[1.4831, 0.9529, 0.2069, ..., 1.2540, 1.2923, 0.8666]],
[[1.4831, 0.9529, 0.2069, ..., 1.2540, 1.2923, 0.8666],
[1.4831, 0.9529, 0.2069, ..., 1.2540, 1.2923, 0.8666],
[1.4831, 0.9529, 0.2069, ..., 1.2540, 1.2923, 0.8666],
...,
[1.4831, 0.9529, 0.2069, ..., 1.2540, 1.2923, 0.8666],
[1.4831, 0.9529, 0.2069, ..., 1.2540, 1.2923, 0.8666],
[1.4831, 0.9529, 0.2069, ..., 1.2540, 1.2923, 0.8666]]])
# 归一化
[LOG] LayerNorm后输出: shape=(2, 100, 24), dtype=torch.float32
[LOG] LayerNorm后输出 完整内容:
tensor([[[ 1.2714, -0.0241, -1.8467, ..., 0.7115, 0.8052, -0.2350],
[ 1.2714, -0.0241, -1.8467, ..., 0.7115, 0.8052, -0.2350],
[ 1.2714, -0.0241, -1.8467, ..., 0.7115, 0.8052, -0.2350],
...,
[ 1.2714, -0.0241, -1.8467, ..., 0.7115, 0.8052, -0.2350],
[ 1.2714, -0.0241, -1.8467, ..., 0.7115, 0.8052, -0.2350],
[ 1.2714, -0.0241, -1.8467, ..., 0.7115, 0.8052, -0.2350]],
[[ 1.2714, -0.0241, -1.8467, ..., 0.7115, 0.8052, -0.2350],
[ 1.2714, -0.0241, -1.8467, ..., 0.7115, 0.8052, -0.2350],
[ 1.2714, -0.0241, -1.8467, ..., 0.7115, 0.8052, -0.2350],
...,
[ 1.2714, -0.0241, -1.8467, ..., 0.7115, 0.8052, -0.2350],
[ 1.2714, -0.0241, -1.8467, ..., 0.7115, 0.8052, -0.2350],
[ 1.2714, -0.0241, -1.8467, ..., 0.7115, 0.8052, -0.2350]]])
[LOG] ===== 退出 AddNorm.forward =====
Step 3:FFN(逐位置前馈网络)
ffn_out = self.ffn(Y)
📌 本质
对每个 token:
y → Linear(24→48) → ReLU → Linear(48→24)
🔥 特点
不跨 token
每个位置独立
参数共享
📐 输出
ffn_out.shape = (2, 100, 24)
🔥 作用
对每个 token 做“非线性特征加工”
[LOG] dense1(X): shape=(2, 100, 48), dtype=torch.float32
[LOG] dense1(X) 完整内容:
tensor([[[ 0.5987, 0.1660, 0.3433, ..., 0.3329, -0.4658, -0.0718],
[ 0.5987, 0.1660, 0.3433, ..., 0.3329, -0.4658, -0.0718],
[ 0.5987, 0.1660, 0.3433, ..., 0.3329, -0.4658, -0.0718],
...,
[ 0.5987, 0.1660, 0.3433, ..., 0.3329, -0.4658, -0.0718],
[ 0.5987, 0.1660, 0.3433, ..., 0.3329, -0.4658, -0.0718],
[ 0.5987, 0.1660, 0.3433, ..., 0.3329, -0.4658, -0.0718]],
[[ 0.5987, 0.1660, 0.3433, ..., 0.3329, -0.4658, -0.0718],
[ 0.5987, 0.1660, 0.3433, ..., 0.3329, -0.4658, -0.0718],
[ 0.5987, 0.1660, 0.3433, ..., 0.3329, -0.4658, -0.0718],
...,
[ 0.5987, 0.1660, 0.3433, ..., 0.3329, -0.4658, -0.0718],
[ 0.5987, 0.1660, 0.3433, ..., 0.3329, -0.4658, -0.0718],
[ 0.5987, 0.1660, 0.3433, ..., 0.3329, -0.4658, -0.0718]]])
[LOG] ReLU后: shape=(2, 100, 48), dtype=torch.float32
[LOG] ReLU后 完整内容:
tensor([[[0.5987, 0.1660, 0.3433, ..., 0.3329, 0.0000, 0.0000],
[0.5987, 0.1660, 0.3433, ..., 0.3329, 0.0000, 0.0000],
[0.5987, 0.1660, 0.3433, ..., 0.3329, 0.0000, 0.0000],
...,
[0.5987, 0.1660, 0.3433, ..., 0.3329, 0.0000, 0.0000],
[0.5987, 0.1660, 0.3433, ..., 0.3329, 0.0000, 0.0000],
[0.5987, 0.1660, 0.3433, ..., 0.3329, 0.0000, 0.0000]],
[[0.5987, 0.1660, 0.3433, ..., 0.3329, 0.0000, 0.0000],
[0.5987, 0.1660, 0.3433, ..., 0.3329, 0.0000, 0.0000],
[0.5987, 0.1660, 0.3433, ..., 0.3329, 0.0000, 0.0000],
...,
[0.5987, 0.1660, 0.3433, ..., 0.3329, 0.0000, 0.0000],
[0.5987, 0.1660, 0.3433, ..., 0.3329, 0.0000, 0.0000],
[0.5987, 0.1660, 0.3433, ..., 0.3329, 0.0000, 0.0000]]])
[LOG] dense2输出: shape=(2, 100, 24), dtype=torch.float32
[LOG] dense2输出 完整内容:
tensor([[[ 0.1860, 0.0345, 0.1935, ..., -0.1780, -0.1262, -0.2303],
[ 0.1860, 0.0345, 0.1935, ..., -0.1780, -0.1262, -0.2303],
[ 0.1860, 0.0345, 0.1935, ..., -0.1780, -0.1262, -0.2303],
...,
[ 0.1860, 0.0345, 0.1935, ..., -0.1780, -0.1262, -0.2303],
[ 0.1860, 0.0345, 0.1935, ..., -0.1780, -0.1262, -0.2303],
[ 0.1860, 0.0345, 0.1935, ..., -0.1780, -0.1262, -0.2303]],
[[ 0.1860, 0.0345, 0.1935, ..., -0.1780, -0.1262, -0.2303],
[ 0.1860, 0.0345, 0.1935, ..., -0.1780, -0.1262, -0.2303],
[ 0.1860, 0.0345, 0.1935, ..., -0.1780, -0.1262, -0.2303],
...,
[ 0.1860, 0.0345, 0.1935, ..., -0.1780, -0.1262, -0.2303],
[ 0.1860, 0.0345, 0.1935, ..., -0.1780, -0.1262, -0.2303],
[ 0.1860, 0.0345, 0.1935, ..., -0.1780, -0.1262, -0.2303]]])
[LOG] ===== 退出 PositionWiseFFN.forward =====
Step 4:AddNorm2(第二次残差)
[LOG] AddNorm2后输出(EncoderBlock最终输出): shape=(2, 100, 24), dtype=torch.float32
[LOG] AddNorm2后输出(EncoderBlock最终输出) 完整内容:
tensor([[[ 1.3459, 0.0299, -1.4830, ..., 0.5057, 0.6380, -0.4027],
[ 1.3459, 0.0299, -1.4830, ..., 0.5057, 0.6380, -0.4027],
[ 1.3459, 0.0299, -1.4830, ..., 0.5057, 0.6380, -0.4027],
...,
[ 1.3459, 0.0299, -1.4830, ..., 0.5057, 0.6380, -0.4027],
[ 1.3459, 0.0299, -1.4830, ..., 0.5057, 0.6380, -0.4027],
[ 1.3459, 0.0299, -1.4830, ..., 0.5057, 0.6380, -0.4027]],
[[ 1.3459, 0.0299, -1.4830, ..., 0.5057, 0.6380, -0.4027],
[ 1.3459, 0.0299, -1.4830, ..., 0.5057, 0.6380, -0.4027],
[ 1.3459, 0.0299, -1.4830, ..., 0.5057, 0.6380, -0.4027],
...,
[ 1.3459, 0.0299, -1.4830, ..., 0.5057, 0.6380, -0.4027],
[ 1.3459, 0.0299, -1.4830, ..., 0.5057, 0.6380, -0.4027],
[ 1.3459, 0.0299, -1.4830, ..., 0.5057, 0.6380, -0.4027]]])
架构总结
输入 X (2,100,24)
│
▼
┌────────────────────┐
│ Multi-HeadAttention│
└────────────────────┘
│
▼
┌────────────────────┐
│ AddNorm (X + attn) │
└────────────────────┘
│
▼
Y
│
▼
┌────────────────────┐
│ PositionWise FFN │
└────────────────────┘
│
▼
┌────────────────────┐
│ AddNorm (Y + ffn) │
└────────────────────┘
│
▼
输出 out
1️⃣ Attention vs FFN 分工
| 模块 | 作用 |
|---|---|
| Attention | token之间通信 |
| FFN | token内部加工 |
2️⃣ 残差的作用
X + 子层输出
👉 防止:
- 梯度消失
- 信息丢失 3️⃣ LayerNorm 的作用
👉 保证:
- 数值稳定
- 训练收敛
完整编码器代码
#@save
class TransformerEncoder(d2l.Encoder):
"""Transformer编码器"""
def __init__(self, vocab_size, key_size, query_size, value_size,
num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens,
num_heads, num_layers, dropout, use_bias=False, **kwargs):
super(TransformerEncoder, self).__init__(**kwargs)
# 保存隐藏维度,后续在embedding缩放时使用
self.num_hiddens = num_hiddens
# 词嵌入:把离散token id映射到连续向量
self.embedding = nn.Embedding(vocab_size, num_hiddens)
# 位置编码:为序列注入位置信息
self.pos_encoding = d2l.PositionalEncoding(num_hiddens, dropout)
# 编码器块堆叠容器
self.blks = nn.Sequential()
for i in range(num_layers):
# 逐层添加编码器块,形成深层特征提取
self.blks.add_module("block"+str(i),
EncoderBlock(key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens,
num_heads, dropout, use_bias))
print("[LOG] TransformerEncoder 初始化完成")
print(f"[LOG] vocab_size={vocab_size}, num_hiddens={num_hiddens}, "
f"num_heads={num_heads}, num_layers={num_layers}, dropout={dropout}")
print(f"[LOG] norm_shape={norm_shape}, ffn_num_input={ffn_num_input}, "
f"ffn_num_hiddens={ffn_num_hiddens}")
def forward(self, X, valid_lens, *args):
print("\n[LOG] ========= 进入 TransformerEncoder.forward =========")
log_tensor_info("TransformerEncoder输入token索引X", X)
print(f"[LOG] valid_lens={valid_lens}")
# 因为位置编码值在-1和1之间,
# 因此嵌入值乘以嵌入维度的平方根进行缩放,
# 然后再与位置编码相加。
emb = self.embedding(X)
log_tensor_info("词嵌入输出 embedding(X)", emb)
scaled_emb = emb * math.sqrt(self.num_hiddens)
log_tensor_info("缩放后的词嵌入 scaled_emb", scaled_emb)
X = self.pos_encoding(scaled_emb)
log_tensor_info("加入位置编码后的输入", X)
self.attention_weights = [None] * len(self.blks)
for i, blk in enumerate(self.blks):
print(f"[LOG] ---- 进入编码器块 block{i} ----")
X = blk(X, valid_lens)
log_tensor_info(f"block{i} 输出", X)
self.attention_weights[
i] = blk.attention.attention.attention_weights
log_tensor_info(f"block{i} 注意力权重", self.attention_weights[i])
print(f"[LOG] ---- 退出编码器块 block{i} ----")
print("[LOG] ========= 退出 TransformerEncoder.forward =========\n")
return X
print("\n[LOG] ===== 完整TransformerEncoder测试 =====")
encoder = TransformerEncoder(
200, 24, 24, 24, 24, [100, 24], 24, 48, 8, 2, 0.5)
encoder.eval()
enc_input = torch.ones((2, 100), dtype=torch.long)
log_tensor_info("完整编码器测试输入 enc_input", enc_input)
enc_output = encoder(enc_input, valid_lens)
print(f"[LOG] 完整编码器输出形状: {tuple(enc_output.shape)}")
log_tensor_info("完整编码器输出 enc_output", enc_output)
print("[LOG] ===== 完整TransformerEncoder测试结束 =====\n")
全局视角
token id
│
▼
Embedding(词向量)
│
▼
缩放(√d_model)
│
▼
位置编码(Positional Encoding)
│
▼
EncoderBlock × N(你这里是2层)
│
▼
输出特征
输入数据
| 维度 | 说明 |
|---|---|
| 2 | batch |
| 100 | 序列长度 |
| 值=1 | 每个 token id 都是 1 |
enc_input = torch.ones((2, 100), dtype=torch.long)
👉 这点非常关键:
⚠️ 所有 token 是同一个词
[LOG] 完整编码器测试输入 enc_input: shape=(2, 100), dtype=torch.int64
[LOG] 完整编码器测试输入 enc_input 完整内容:
tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1]])
Step 1:Embedding(词嵌入)
emb = self.embedding(X)
📌 本质
token id → 查表 → 向量
📐 形状变化
(2,100) → (2,100,24)
🔥 关键现象
因为:
所有 token id = 1
👉 所以:
embedding 每一行完全一样
🧠 此时状态
序列中所有 token:
内容一样 ❌
位置未知 ❌
[LOG] 词嵌入输出 embedding(X): shape=(2, 100, 24), dtype=torch.float32
[LOG] 词嵌入输出 embedding(X) 完整内容:
tensor([[[ 1.1125, -0.0217, 0.2430, ..., 0.4983, -0.5469, -0.2665],
[ 1.1125, -0.0217, 0.2430, ..., 0.4983, -0.5469, -0.2665],
[ 1.1125, -0.0217, 0.2430, ..., 0.4983, -0.5469, -0.2665],
...,
[ 1.1125, -0.0217, 0.2430, ..., 0.4983, -0.5469, -0.2665],
[ 1.1125, -0.0217, 0.2430, ..., 0.4983, -0.5469, -0.2665],
[ 1.1125, -0.0217, 0.2430, ..., 0.4983, -0.5469, -0.2665]],
[[ 1.1125, -0.0217, 0.2430, ..., 0.4983, -0.5469, -0.2665],
[ 1.1125, -0.0217, 0.2430, ..., 0.4983, -0.5469, -0.2665],
[ 1.1125, -0.0217, 0.2430, ..., 0.4983, -0.5469, -0.2665],
...,
[ 1.1125, -0.0217, 0.2430, ..., 0.4983, -0.5469, -0.2665],
[ 1.1125, -0.0217, 0.2430, ..., 0.4983, -0.5469, -0.2665],
[ 1.1125, -0.0217, 0.2430, ..., 0.4983, -0.5469, -0.2665]]])
👉 本质一句话: 把“离散的 token id”变成“连续的向量表示”
token id: 1 5 10
│ │ │
▼ ▼ ▼
Embedding:
[v1] [v5] [v10]
│ │ │
▼ ▼ ▼
变成连续向量(可以计算相似度)
Step 2:缩放(重要细节)
scaled_emb = emb * sqrt(24)
📌 为什么要乘 √d_model?
👉 防止:
embedding 太小,被位置编码淹没
🔥 本质
让 embedding 和 positional encoding 在同一量级
[LOG] 缩放后的词嵌入 scaled_emb: shape=(2, 100, 24), dtype=torch.float32
[LOG] 缩放后的词嵌入 scaled_emb 完整内容:
tensor([[[ 5.4503, -0.1061, 1.1904, ..., 2.4411, -2.6792, -1.3057],
[ 5.4503, -0.1061, 1.1904, ..., 2.4411, -2.6792, -1.3057],
[ 5.4503, -0.1061, 1.1904, ..., 2.4411, -2.6792, -1.3057],
...,
[ 5.4503, -0.1061, 1.1904, ..., 2.4411, -2.6792, -1.3057],
[ 5.4503, -0.1061, 1.1904, ..., 2.4411, -2.6792, -1.3057],
[ 5.4503, -0.1061, 1.1904, ..., 2.4411, -2.6792, -1.3057]],
[[ 5.4503, -0.1061, 1.1904, ..., 2.4411, -2.6792, -1.3057],
[ 5.4503, -0.1061, 1.1904, ..., 2.4411, -2.6792, -1.3057],
[ 5.4503, -0.1061, 1.1904, ..., 2.4411, -2.6792, -1.3057],
...,
[ 5.4503, -0.1061, 1.1904, ..., 2.4411, -2.6792, -1.3057],
[ 5.4503, -0.1061, 1.1904, ..., 2.4411, -2.6792, -1.3057],
[ 5.4503, -0.1061, 1.1904, ..., 2.4411, -2.6792, -1.3057]]])
Step 3:位置编码(关键突破)
X = self.pos_encoding(scaled_emb)
📌 本质
X = embedding + position_encoding
🔥 作用(非常关键)
👉 给每个 token 加“位置差异”
🧠 举个直观例子
token0 → embedding + pos(0)
token1 → embedding + pos(1)
token2 → embedding + pos(2)
🎯 结果
👉 虽然:
token内容一样
但:
最终向量 ≠ 一样
[LOG] 加入位置编码后的输入: shape=(2, 100, 24), dtype=torch.float32
[LOG] 加入位置编码后的输入 完整内容:
tensor([[[ 5.4503, 0.8939, 1.1904, ..., 3.4411, -2.6792, -0.3057],
[ 6.2918, 0.4342, 1.6380, ..., 3.4411, -2.6789, -0.3057],
[ 6.3596, -0.5223, 1.9910, ..., 3.4411, -2.6787, -0.3057],
...,
[ 5.8299, -1.0313, 2.0533, ..., 3.4401, -2.6583, -0.3059],
[ 4.8770, -0.9254, 2.1882, ..., 3.4401, -2.6580, -0.3059],
[ 4.4511, -0.0663, 2.1119, ..., 3.4401, -2.6578, -0.3059]],
[[ 5.4503, 0.8939, 1.1904, ..., 3.4411, -2.6792, -0.3057],
[ 6.2918, 0.4342, 1.6380, ..., 3.4411, -2.6789, -0.3057],
[ 6.3596, -0.5223, 1.9910, ..., 3.4411, -2.6787, -0.3057],
...,
[ 5.8299, -1.0313, 2.0533, ..., 3.4401, -2.6583, -0.3059],
[ 4.8770, -0.9254, 2.1882, ..., 3.4401, -2.6580, -0.3059],
[ 4.4511, -0.0663, 2.1119, ..., 3.4401, -2.6578, -0.3059]]])
Step 4:进入 EncoderBlock(循环)
for i, blk in enumerate(self.blks):
X = blk(X, valid_lens)
你这里:
num_layers = 2
👉 会执行:
block0 → block1
block0
[LOG] block0 输出: shape=(2, 100, 24), dtype=torch.float32
[LOG] block0 输出 完整内容:
tensor([[[ 1.3703, 0.3976, 0.2605, ..., 1.5080, -0.5639, -0.1134],
[ 1.5673, 0.3092, 0.3691, ..., 1.5192, -0.5570, -0.1067],
[ 1.5783, 0.1033, 0.4716, ..., 1.5373, -0.5553, -0.1022],
...,
[ 1.4608, 0.0285, 0.4712, ..., 1.5040, -0.6001, -0.1518],
[ 1.2321, 0.0456, 0.5011, ..., 1.5086, -0.6077, -0.1597],
[ 1.1312, 0.2147, 0.4753, ..., 1.5047, -0.5998, -0.1663]],
[[ 1.3797, 0.3918, 0.2551, ..., 1.5219, -0.5632, -0.1195],
[ 1.5769, 0.3033, 0.3638, ..., 1.5330, -0.5562, -0.1128],
[ 1.5878, 0.0973, 0.4663, ..., 1.5512, -0.5544, -0.1084],
...,
[ 1.4708, 0.0216, 0.4664, ..., 1.5181, -0.5991, -0.1568],
[ 1.2421, 0.0383, 0.4963, ..., 1.5232, -0.6076, -0.1645],
[ 1.1413, 0.2074, 0.4706, ..., 1.5192, -0.5997, -0.1710]]])
[LOG] ---- 退出编码器块 block0 ----
block1
[LOG] block1 输出: shape=(2, 100, 24), dtype=torch.float32
[LOG] block1 输出 完整内容:
tensor([[[ 1.8015, 0.0294, 0.2230, ..., 1.4384, -1.0806, -0.3897],
[ 1.9988, -0.0460, 0.3466, ..., 1.4391, -1.0542, -0.3975],
[ 2.0112, -0.2198, 0.4557, ..., 1.4599, -1.0405, -0.4251],
...,
[ 1.8576, -0.2355, 0.4971, ..., 1.4461, -1.1070, -0.4749],
[ 1.6374, -0.2058, 0.5191, ..., 1.4544, -1.1267, -0.4890],
[ 1.5407, -0.0497, 0.4826, ..., 1.4481, -1.1297, -0.4755]],
[[ 1.8135, 0.0225, 0.2285, ..., 1.4585, -1.0721, -0.3998],
[ 2.0110, -0.0528, 0.3524, ..., 1.4586, -1.0452, -0.4077],
[ 2.0234, -0.2268, 0.4614, ..., 1.4795, -1.0315, -0.4353],
...,
[ 1.8688, -0.2437, 0.5032, ..., 1.4652, -1.0981, -0.4842],
[ 1.6486, -0.2145, 0.5251, ..., 1.4740, -1.1187, -0.4980],
[ 1.5521, -0.0584, 0.4887, ..., 1.4675, -1.1217, -0.4844]]])
[LOG] ---- 退出编码器块 block1 ----
每个 block 内部发生什么(复习强化)
每个 block = 一次“全局信息融合 + 局部特征加工 + 稳定更新”
token 表示
│
▼
┌────────────────┐
│ Self-Attention │ ← 信息交流
└────────────────┘
│
▼
Add & Norm
│
▼
┌────────────────┐
│ FFN │ ← 信息加工
└────────────────┘
│
▼
Add & Norm
│
▼
更强表示
| 层数 | 作用 |
|---|---|
| block0 | 基础语义关系 |
| block1 | 更高层抽象 |
| blockN | 深层语义 / 推理能力 |
attention_weights 保存
self.attention_weights[i] = blk.attention.attention.attention_weights
📌 作用
👉 保存每一层的注意力矩阵:
shape ≈ (batch, heads, seq, seq)
🔥 可以用来做:
可视化注意力
分析模型关注点
block0
[LOG] block0 注意力权重: shape=(16, 100, 100), dtype=torch.float32
tensor([[[0.3146, 0.3766, 0.3088, ..., 0.0000, 0.0000, 0.0000],
[0.3127, 0.3777, 0.3096, ..., 0.0000, 0.0000, 0.0000],
[0.3107, 0.3761, 0.3132, ..., 0.0000, 0.0000, 0.0000],
...,
[0.3032, 0.3818, 0.3151, ..., 0.0000, 0.0000, 0.0000],
[0.3031, 0.3805, 0.3164, ..., 0.0000, 0.0000, 0.0000],
[0.3035, 0.3818, 0.3148, ..., 0.0000, 0.0000, 0.0000]],
[[0.3847, 0.2943, 0.3210, ..., 0.0000, 0.0000, 0.0000],
[0.3868, 0.2923, 0.3209, ..., 0.0000, 0.0000, 0.0000],
[0.3883, 0.2909, 0.3209, ..., 0.0000, 0.0000, 0.0000],
...,
[0.3890, 0.2887, 0.3223, ..., 0.0000, 0.0000, 0.0000],
[0.3895, 0.2891, 0.3214, ..., 0.0000, 0.0000, 0.0000],
[0.3903, 0.2895, 0.3203, ..., 0.0000, 0.0000, 0.0000]],
[[0.2770, 0.3312, 0.3917, ..., 0.0000, 0.0000, 0.0000],
[0.2777, 0.3305, 0.3918, ..., 0.0000, 0.0000, 0.0000],
[0.2801, 0.3319, 0.3880, ..., 0.0000, 0.0000, 0.0000],
...,
[0.2881, 0.3383, 0.3737, ..., 0.0000, 0.0000, 0.0000],
[0.2906, 0.3403, 0.3692, ..., 0.0000, 0.0000, 0.0000],
[0.2908, 0.3404, 0.3688, ..., 0.0000, 0.0000, 0.0000]],
...,
[[0.4926, 0.5074, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.4922, 0.5078, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.4919, 0.5081, 0.0000, ..., 0.0000, 0.0000, 0.0000],
...,
[0.4905, 0.5095, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.4915, 0.5085, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.4927, 0.5073, 0.0000, ..., 0.0000, 0.0000, 0.0000]],
[[0.4938, 0.5062, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.4911, 0.5089, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.4904, 0.5096, 0.0000, ..., 0.0000, 0.0000, 0.0000],
...,
[0.4954, 0.5046, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.4975, 0.5025, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.4977, 0.5023, 0.0000, ..., 0.0000, 0.0000, 0.0000]],
[[0.5312, 0.4688, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.5317, 0.4683, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.5338, 0.4662, 0.0000, ..., 0.0000, 0.0000, 0.0000],
...,
[0.5346, 0.4654, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.5341, 0.4659, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.5326, 0.4674, 0.0000, ..., 0.0000, 0.0000, 0.0000]]])
block1
[LOG] block1 注意力权重: shape=(16, 100, 100), dtype=torch.float32
[LOG] block1 注意力权重 完整内容:
tensor([[[0.3344, 0.3326, 0.3330, ..., 0.0000, 0.0000, 0.0000],
[0.3344, 0.3326, 0.3330, ..., 0.0000, 0.0000, 0.0000],
[0.3343, 0.3326, 0.3330, ..., 0.0000, 0.0000, 0.0000],
...,
[0.3343, 0.3327, 0.3330, ..., 0.0000, 0.0000, 0.0000],
[0.3343, 0.3327, 0.3330, ..., 0.0000, 0.0000, 0.0000],
[0.3342, 0.3327, 0.3330, ..., 0.0000, 0.0000, 0.0000]],
[[0.3332, 0.3316, 0.3352, ..., 0.0000, 0.0000, 0.0000],
[0.3330, 0.3316, 0.3353, ..., 0.0000, 0.0000, 0.0000],
[0.3328, 0.3316, 0.3355, ..., 0.0000, 0.0000, 0.0000],
...,
[0.3321, 0.3312, 0.3368, ..., 0.0000, 0.0000, 0.0000],
[0.3322, 0.3311, 0.3367, ..., 0.0000, 0.0000, 0.0000],
[0.3323, 0.3311, 0.3366, ..., 0.0000, 0.0000, 0.0000]],
[[0.3324, 0.3322, 0.3354, ..., 0.0000, 0.0000, 0.0000],
[0.3324, 0.3323, 0.3354, ..., 0.0000, 0.0000, 0.0000],
[0.3323, 0.3323, 0.3354, ..., 0.0000, 0.0000, 0.0000],
...,
[0.3321, 0.3321, 0.3358, ..., 0.0000, 0.0000, 0.0000],
[0.3321, 0.3321, 0.3357, ..., 0.0000, 0.0000, 0.0000],
[0.3322, 0.3321, 0.3357, ..., 0.0000, 0.0000, 0.0000]],
...,
[[0.4932, 0.5068, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.4930, 0.5070, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.4928, 0.5072, 0.0000, ..., 0.0000, 0.0000, 0.0000],
...,
[0.4938, 0.5062, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.4939, 0.5061, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.4939, 0.5061, 0.0000, ..., 0.0000, 0.0000, 0.0000]],
[[0.5011, 0.4989, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.5012, 0.4988, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.5011, 0.4989, 0.0000, ..., 0.0000, 0.0000, 0.0000],
...,
[0.4990, 0.5010, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.4984, 0.5016, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.4981, 0.5019, 0.0000, ..., 0.0000, 0.0000, 0.0000]],
[[0.5016, 0.4984, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.5017, 0.4983, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.5017, 0.4983, 0.0000, ..., 0.0000, 0.0000, 0.0000],
...,
[0.5020, 0.4980, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.5019, 0.4981, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.5018, 0.4982, 0.0000, ..., 0.0000, 0.0000, 0.0000]]])
TransformerEncoder.forward 做了三件事:
- 👉 把 token 变成向量(embedding)
- 👉 注入位置信息(pos encoding)
- 👉 用多层 EncoderBlock 提取上下文特征
编码器的权重数量
模型配置
vocab_size = 200
num_hiddens = 24
num_heads = 8
num_layers = 2
ffn_num_hiddens = 48
1️⃣ Embedding 层
nn.Embedding(200, 24)
👉 参数量:
200 × 24 = 4800
2️⃣ Positional Encoding
d2l.PositionalEncoding
👉 是:
sin/cos 固定函数 ❗
👉 参数量:
0
3️⃣ 一个 EncoderBlock 的参数
3.1 多头注意力(MultiHeadAttention)
在 d2l 实现中,本质是:
Wq, Wk, Wv, Wo
每个线性层:
(24 × 24) + 24 = 576 + 24 = 600
一共 4 个:600 × 4 = 2400
✅ Attention 总参数:2400
3.2 AddNorm(第一个)
LayerNorm([100,24])
👉 参数:
gamma:100×24
beta:100×24
= 2 × (100×24)
= 4800
3.3 FFN(前馈网络)
24 → 48 → 24
第一层:
24×48 + 48 = 1152 + 48 = 1200
第二层:
48×24 + 24 = 1152 + 24 = 1176
总计:
1200 + 1176 = 2376
3.4 AddNorm(第二个)
同上:
4800
✅ 一个 EncoderBlock 总参数
Attention = 2400
AddNorm1 = 4800
FFN = 2376
AddNorm2 = 4800
--------------------------------
合计 = 14376
2层 EncoderBlock
14376 × 2 = 28752
最终总参数量
Embedding = 4800
EncoderBlocks = 28752
--------------------------------
Total = 33552
解码器
解码器代码一
class DecoderBlock(nn.Module):
"""解码器中第i个块"""
def __init__(self, key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,
dropout, i, **kwargs):
super(DecoderBlock, self).__init__(**kwargs)
# 记录当前块编号,便于缓存state[2]中不同层的历史解码表示
self.i = i
# 子层1:Masked Self-Attention(解码器自注意力)
# 新版 d2l.MultiHeadAttention 签名: (num_hiddens, num_heads, dropout, bias=False)
self.attention1 = d2l.MultiHeadAttention(
num_hiddens, num_heads, dropout)
self.addnorm1 = AddNorm(norm_shape, dropout)
# 子层2:Encoder-Decoder Attention(跨注意力)
self.attention2 = d2l.MultiHeadAttention(
num_hiddens, num_heads, dropout)
self.addnorm2 = AddNorm(norm_shape, dropout)
# 子层3:逐位置前馈网络
self.ffn = PositionWiseFFN(ffn_num_input, ffn_num_hiddens,
num_hiddens)
self.addnorm3 = AddNorm(norm_shape, dropout)
print(f"[LOG] DecoderBlock 初始化完成: block_index={i}")
print(f"[LOG] num_hiddens={num_hiddens}, num_heads={num_heads}, "
f"ffn_num_hiddens={ffn_num_hiddens}, dropout={dropout}")
def forward(self, X, state):
print(f"\n[LOG] ===== 进入 DecoderBlock.forward (block {self.i}) =====")
log_tensor_info("DecoderBlock输入X", X)
enc_outputs, enc_valid_lens = state[0], state[1]
log_tensor_info("编码器输出 enc_outputs", enc_outputs)
print(f"[LOG] 编码器有效长度 enc_valid_lens={enc_valid_lens}")
# 训练阶段,输出序列的所有词元都在同一时间处理,
# 因此state[2][self.i]初始化为None。
# 预测阶段,输出序列是通过词元一个接着一个解码的,
# 因此state[2][self.i]包含着直到当前时间步第i个块解码的输出表示
if state[2][self.i] is None:
key_values = X
print(f"[LOG] block {self.i} 缓存为空,key_values 直接使用当前X")
else:
key_values = torch.cat((state[2][self.i], X), axis=1)
print(f"[LOG] block {self.i} 使用历史缓存拼接当前X")
state[2][self.i] = key_values
log_tensor_info("当前块缓存 key_values", key_values)
if self.training:
batch_size, num_steps, _ = X.shape
# dec_valid_lens的开头:(batch_size,num_steps),
# 其中每一行是[1,2,...,num_steps]
dec_valid_lens = torch.arange(
1, num_steps + 1, device=X.device).repeat(batch_size, 1)
log_tensor_info("训练阶段 dec_valid_lens", dec_valid_lens)
else:
dec_valid_lens = None
print("[LOG] 推理阶段 dec_valid_lens=None")
# 子层1:Masked Self-Attention + AddNorm
X2 = self.attention1(X, key_values, key_values, dec_valid_lens)
log_tensor_info("自注意力输出 X2", X2)
Y = self.addnorm1(X, X2)
log_tensor_info("AddNorm1输出 Y", Y)
# 编码器-解码器注意力。
# enc_outputs的开头:(batch_size,num_steps,num_hiddens)
# 子层2:Cross-Attention + AddNorm
Y2 = self.attention2(Y, enc_outputs, enc_outputs, enc_valid_lens)
log_tensor_info("跨注意力输出 Y2", Y2)
Z = self.addnorm2(Y, Y2)
log_tensor_info("AddNorm2输出 Z", Z)
# 子层3:FFN + AddNorm
ffn_out = self.ffn(Z)
log_tensor_info("FFN输出 ffn_out", ffn_out)
out = self.addnorm3(Z, ffn_out)
log_tensor_info("DecoderBlock最终输出 out", out)
print(f"[LOG] ===== 退出 DecoderBlock.forward (block {self.i}) =====\n")
return out, state
decoder_blk = DecoderBlock(24, 24, 24, 24, [100, 24], 24, 48, 8, 0.5, 0)
decoder_blk.eval()
X = torch.ones((2, 100, 24))
state = [encoder_blk(X, valid_lens), valid_lens, [None]]
print("\n[LOG] ===== 解码器块测试 =====")
log_tensor_info("解码器测试输入 X", X)
decoder_out, new_state = decoder_blk(X, state)
print(f"[LOG] DecoderBlock输出形状: {tuple(decoder_out.shape)}")
log_tensor_info("DecoderBlock输出 decoder_out", decoder_out)
print(f"[LOG] state缓存层数: {len(new_state[2])}")
print("[LOG] ===== 解码器块测试结束 =====")
整体结构
输入 X(当前已生成序列)
│
▼
1️⃣ Masked Self-Attention ← 只能看“过去”
│
▼
2️⃣ Cross Attention ← 看 Encoder(源句)
│
▼
3️⃣ FFN ← 非线性加工
创建 DecoderBlock
DecoderBlock(24, 24, 24, 24, [100, 24], 24, 48, 8, 0.5, 0)
| 参数 | 含义 |
|---|---|
| 24 | hidden size |
| 48 | FFN中间层 |
| 8 | 8头注意力 |
| [100,24] | LayerNorm维度 |
| i=0 | 第0层decoder |
输入数据
[LOG] 解码器测试输入 X: shape=(2, 100, 24), dtype=torch.float32
[LOG] 解码器测试输入 X 完整内容:
tensor([[[1., 1., 1., ..., 1., 1., 1.],
[1., 1., 1., ..., 1., 1., 1.],
[1., 1., 1., ..., 1., 1., 1.],
...,
[1., 1., 1., ..., 1., 1., 1.],
[1., 1., 1., ..., 1., 1., 1.],
[1., 1., 1., ..., 1., 1., 1.]],
[[1., 1., 1., ..., 1., 1., 1.],
[1., 1., 1., ..., 1., 1., 1.],
[1., 1., 1., ..., 1., 1., 1.],
...,
[1., 1., 1., ..., 1., 1., 1.],
[1., 1., 1., ..., 1., 1., 1.],
[1., 1., 1., ..., 1., 1., 1.]]])
state 构造
state = [encoder_blk(X, valid_lens), valid_lens, [None]]
结构
state = [
enc_outputs, # 编码器输出
valid_lens, # 编码mask
cache # decoder缓存
]
cache
[None]
👉 表示:
第0层 decoder 还没有历史缓存
# 编码器输出
tensor([[[-0.6796, 1.1780, -1.1474, ..., 2.4620, 0.2389, 0.1131],
[-0.6796, 1.1780, -1.1474, ..., 2.4620, 0.2389, 0.1131],
[-0.6796, 1.1780, -1.1474, ..., 2.4620, 0.2389, 0.1131],
...,
[-0.6796, 1.1780, -1.1474, ..., 2.4620, 0.2389, 0.1131],
[-0.6796, 1.1780, -1.1474, ..., 2.4620, 0.2389, 0.1131],
[-0.6796, 1.1780, -1.1474, ..., 2.4620, 0.2389, 0.1131]],
[[-0.6796, 1.1780, -1.1474, ..., 2.4620, 0.2389, 0.1131],
[-0.6796, 1.1780, -1.1474, ..., 2.4620, 0.2389, 0.1131],
[-0.6796, 1.1780, -1.1474, ..., 2.4620, 0.2389, 0.1131],
...,
[-0.6796, 1.1780, -1.1474, ..., 2.4620, 0.2389, 0.1131],
[-0.6796, 1.1780, -1.1474, ..., 2.4620, 0.2389, 0.1131],
[-0.6796, 1.1780, -1.1474, ..., 2.4620, 0.2389, 0.1131]]])
下面进入DecoderBlock.forward
Step 1:取出 encoder 信息
enc_outputs, enc_valid_lens = state[0], state[1]
结果
enc_outputs.shape = (2, 100, 24)
enc_valid_lens = [3, 2]
👉 含义:
每个样本只看前几个 token
[LOG] 编码器输出 enc_outputs: shape=(2, 100, 24), dtype=torch.float32
[LOG] 编码器输出 enc_outputs 完整内容:
tensor([[[-0.6796, 1.1780, -1.1474, ..., 2.4620, 0.2389, 0.1131],
[-0.6796, 1.1780, -1.1474, ..., 2.4620, 0.2389, 0.1131],
[-0.6796, 1.1780, -1.1474, ..., 2.4620, 0.2389, 0.1131],
...,
[-0.6796, 1.1780, -1.1474, ..., 2.4620, 0.2389, 0.1131],
[-0.6796, 1.1780, -1.1474, ..., 2.4620, 0.2389, 0.1131],
[-0.6796, 1.1780, -1.1474, ..., 2.4620, 0.2389, 0.1131]],
[[-0.6796, 1.1780, -1.1474, ..., 2.4620, 0.2389, 0.1131],
[-0.6796, 1.1780, -1.1474, ..., 2.4620, 0.2389, 0.1131],
[-0.6796, 1.1780, -1.1474, ..., 2.4620, 0.2389, 0.1131],
...,
[-0.6796, 1.1780, -1.1474, ..., 2.4620, 0.2389, 0.1131],
[-0.6796, 1.1780, -1.1474, ..., 2.4620, 0.2389, 0.1131],
[-0.6796, 1.1780, -1.1474, ..., 2.4620, 0.2389, 0.1131]]])
[LOG] 编码器有效长度 enc_valid_lens=tensor([3, 2])
[LOG] block 0 缓存为空,key_values 直接使用当前X
Step 2:构造 key_values(缓存机制)
if state[2][self.i] is None:
key_values = X
当前情况
state[2][0] = None
👉 所以:
key_values = X
更新缓存
state[2][self.i] = key_values
👉 cache 变成:
state[2] = [X]
🧠 解释
👉 这是“推理优化机制”的一部分:
但你现在:
一次性输入100个token(训练风格)
👉 所以缓存没有体现优势
Step 3:dec_valid_lens(mask)
if self.training:
...
else:
dec_valid_lens = None
当前是 eval 模式
dec_valid_lens = None
👉 意味着:
没有mask ❗
⚠️ 重要
这意味着:
token可以看到未来 ❗
👉 这其实不符合“真正Decoder推理”
Step 4:Masked Self-Attention
X2 = self.attention1(X, key_values, key_values, dec_valid_lens)
实际变成
Q = X
K = X
V = X
👉 因为:
key_values = X
⚠️ 且没有mask
👉 实际效果:
= 普通 Self-Attention(和 Encoder 一样)
⚠️ 再叠加
X 全是1
👉 所以:
所有位置 attention 结果几乎一样
[LOG] 自注意力输出 X2: shape=(2, 100, 24), dtype=torch.float32
[LOG] 自注意力输出 X2 完整内容:
tensor([[[-0.1445, 0.3495, 0.0163, ..., -0.2074, -0.1041, -0.3527],
[-0.1445, 0.3495, 0.0163, ..., -0.2074, -0.1041, -0.3527],
[-0.1445, 0.3495, 0.0163, ..., -0.2074, -0.1041, -0.3527],
...,
[-0.1445, 0.3495, 0.0163, ..., -0.2074, -0.1041, -0.3527],
[-0.1445, 0.3495, 0.0163, ..., -0.2074, -0.1041, -0.3527],
[-0.1445, 0.3495, 0.0163, ..., -0.2074, -0.1041, -0.3527]],
[[-0.1445, 0.3495, 0.0163, ..., -0.2074, -0.1041, -0.3527],
[-0.1445, 0.3495, 0.0163, ..., -0.2074, -0.1041, -0.3527],
[-0.1445, 0.3495, 0.0163, ..., -0.2074, -0.1041, -0.3527],
...,
[-0.1445, 0.3495, 0.0163, ..., -0.2074, -0.1041, -0.3527],
[-0.1445, 0.3495, 0.0163, ..., -0.2074, -0.1041, -0.3527],
[-0.1445, 0.3495, 0.0163, ..., -0.2074, -0.1041, -0.3527]]])
Step 5:AddNorm1
Y = self.addnorm1(X, X2)
计算
Y = LayerNorm(X + X2)
👉 输出:
shape = (2, 100, 24)
[LOG] AddNorm1输出 Y: shape=(2, 100, 24), dtype=torch.float32
[LOG] AddNorm1输出 Y 完整内容:
tensor([[[-0.5387, 0.8173, -0.0974, ..., -0.7115, -0.4280, -1.1104],
[-0.5387, 0.8173, -0.0974, ..., -0.7115, -0.4280, -1.1104],
[-0.5387, 0.8173, -0.0974, ..., -0.7115, -0.4280, -1.1104],
...,
[-0.5387, 0.8173, -0.0974, ..., -0.7115, -0.4280, -1.1104],
[-0.5387, 0.8173, -0.0974, ..., -0.7115, -0.4280, -1.1104],
[-0.5387, 0.8173, -0.0974, ..., -0.7115, -0.4280, -1.1104]],
[[-0.5387, 0.8173, -0.0974, ..., -0.7115, -0.4280, -1.1104],
[-0.5387, 0.8173, -0.0974, ..., -0.7115, -0.4280, -1.1104],
[-0.5387, 0.8173, -0.0974, ..., -0.7115, -0.4280, -1.1104],
...,
[-0.5387, 0.8173, -0.0974, ..., -0.7115, -0.4280, -1.1104],
[-0.5387, 0.8173, -0.0974, ..., -0.7115, -0.4280, -1.1104],
[-0.5387, 0.8173, -0.0974, ..., -0.7115, -0.4280, -1.1104]]])
AddNorm1 = 把“原始信息 + 上下文信息”融合,并保证数值稳定
Step 6:Cross-Attention
2 = self.attention2(Y, enc_outputs, enc_outputs, enc_valid_lens)
展开就是:
Q = Y
K = enc_outputs
V = enc_outputs
[LOG] 跨注意力输出 Y2: shape=(2, 100, 24), dtype=torch.float32
[LOG] 跨注意力输出 Y2 完整内容:
tensor([[[ 0.5185, 0.3513, -0.2478, ..., 0.0662, -0.2986, -0.0262],
[ 0.5185, 0.3513, -0.2478, ..., 0.0662, -0.2986, -0.0262],
[ 0.5185, 0.3513, -0.2478, ..., 0.0662, -0.2986, -0.0262],
...,
[ 0.5185, 0.3513, -0.2478, ..., 0.0662, -0.2986, -0.0262],
[ 0.5185, 0.3513, -0.2478, ..., 0.0662, -0.2986, -0.0262],
[ 0.5185, 0.3513, -0.2478, ..., 0.0662, -0.2986, -0.0262]],
[[ 0.5185, 0.3513, -0.2478, ..., 0.0662, -0.2986, -0.0262],
[ 0.5185, 0.3513, -0.2478, ..., 0.0662, -0.2986, -0.0262],
[ 0.5185, 0.3513, -0.2478, ..., 0.0662, -0.2986, -0.0262],
...,
[ 0.5185, 0.3513, -0.2478, ..., 0.0662, -0.2986, -0.0262],
[ 0.5185, 0.3513, -0.2478, ..., 0.0662, -0.2986, -0.0262],
[ 0.5185, 0.3513, -0.2478, ..., 0.0662, -0.2986, -0.0262]]])
Cross-Attention = 用“当前生成状态”去“查询输入句子的信息”
| 类型 | Q | K | V | 作用 |
|---|---|---|---|---|
| Self-Attention | 当前序列 | 当前序列 | 当前序列 | 内部信息融合 |
| Cross-Attention | Decoder | Encoder | Encoder | 读取输入信息 |
Step 7:AddNorm2
[LOG] AddNorm2输出 Z: shape=(2, 100, 24), dtype=torch.float32
[LOG] AddNorm2输出 Z 完整内容:
tensor([[[-0.0642, 1.0724, -0.3748, ..., -0.6618, -0.7396, -1.1315],
[-0.0642, 1.0724, -0.3748, ..., -0.6618, -0.7396, -1.1315],
[-0.0642, 1.0724, -0.3748, ..., -0.6618, -0.7396, -1.1315],
...,
[-0.0642, 1.0724, -0.3748, ..., -0.6618, -0.7396, -1.1315],
[-0.0642, 1.0724, -0.3748, ..., -0.6618, -0.7396, -1.1315],
[-0.0642, 1.0724, -0.3748, ..., -0.6618, -0.7396, -1.1315]],
[[-0.0642, 1.0724, -0.3748, ..., -0.6618, -0.7396, -1.1315],
[-0.0642, 1.0724, -0.3748, ..., -0.6618, -0.7396, -1.1315],
[-0.0642, 1.0724, -0.3748, ..., -0.6618, -0.7396, -1.1315],
...,
[-0.0642, 1.0724, -0.3748, ..., -0.6618, -0.7396, -1.1315],
[-0.0642, 1.0724, -0.3748, ..., -0.6618, -0.7396, -1.1315],
[-0.0642, 1.0724, -0.3748, ..., -0.6618, -0.7396, -1.1315]]])
Step 8:FFN
[LOG] FFN输出 ffn_out: shape=(2, 100, 24), dtype=torch.float32
[LOG] FFN输出 ffn_out 完整内容:
tensor([[[-0.3130, -0.1238, -0.2373, ..., -0.1869, 0.0442, 0.1742],
[-0.3130, -0.1238, -0.2373, ..., -0.1869, 0.0442, 0.1742],
[-0.3130, -0.1238, -0.2373, ..., -0.1869, 0.0442, 0.1742],
...,
[-0.3130, -0.1238, -0.2373, ..., -0.1869, 0.0442, 0.1742],
[-0.3130, -0.1238, -0.2373, ..., -0.1869, 0.0442, 0.1742],
[-0.3130, -0.1238, -0.2373, ..., -0.1869, 0.0442, 0.1742]],
[[-0.3130, -0.1238, -0.2373, ..., -0.1869, 0.0442, 0.1742],
[-0.3130, -0.1238, -0.2373, ..., -0.1869, 0.0442, 0.1742],
[-0.3130, -0.1238, -0.2373, ..., -0.1869, 0.0442, 0.1742],
...,
[-0.3130, -0.1238, -0.2373, ..., -0.1869, 0.0442, 0.1742],
[-0.3130, -0.1238, -0.2373, ..., -0.1869, 0.0442, 0.1742],
[-0.3130, -0.1238, -0.2373, ..., -0.1869, 0.0442, 0.1742]]])
AddNorm3 (最终输出)
[LOG] DecoderBlock最终输出 out: shape=(2, 100, 24), dtype=torch.float32
[LOG] DecoderBlock最终输出 out 完整内容:
tensor([[[-0.3319, 0.9702, -0.5628, ..., -0.7952, -0.6445, -0.9018],
[-0.3319, 0.9702, -0.5628, ..., -0.7952, -0.6445, -0.9018],
[-0.3319, 0.9702, -0.5628, ..., -0.7952, -0.6445, -0.9018],
...,
[-0.3319, 0.9702, -0.5628, ..., -0.7952, -0.6445, -0.9018],
[-0.3319, 0.9702, -0.5628, ..., -0.7952, -0.6445, -0.9018],
[-0.3319, 0.9702, -0.5628, ..., -0.7952, -0.6445, -0.9018]],
[[-0.3319, 0.9702, -0.5628, ..., -0.7952, -0.6445, -0.9018],
[-0.3319, 0.9702, -0.5628, ..., -0.7952, -0.6445, -0.9018],
[-0.3319, 0.9702, -0.5628, ..., -0.7952, -0.6445, -0.9018],
...,
[-0.3319, 0.9702, -0.5628, ..., -0.7952, -0.6445, -0.9018],
[-0.3319, 0.9702, -0.5628, ..., -0.7952, -0.6445, -0.9018],
[-0.3319, 0.9702, -0.5628, ..., -0.7952, -0.6445, -0.9018]]])
[LOG] ===== 退出 DecoderBlock.forward (block 0) =====
这次运行“本质发生了什么”
👉 因为你的设置:
❗ 特殊点1
X 全是1
👉 → 所有token一样
❗ 特殊点2
eval模式 → 没有mask
👉 → 可以看未来
❗ 特殊点3
一次性输入100个token
👉 → KV cache没发挥作用
🔥 最终效果
👉 你的 DecoderBlock 实际变成:
≈ EncoderBlock + CrossAttention
TransformerDecoder 解码器
class TransformerDecoder(d2l.AttentionDecoder):
"""Transformer解码器
结构:
输入token_ids (batch_size, target_seq_len)
│
├──► 词嵌入 ──► 缩放 ──► 位置编码 ──► X0
│
├──► [循环通过num_layers个解码器块]
│ ├── block 0: Masked Self-Attn + Cross-Attn + FFN ──► X1
│ ├── block 1: Masked Self-Attn + Cross-Attn + FFN ──► X2
│ └── ...
│ └── block (L-1): ... ──► XL
│
└──► 线性投影(num_hiddens -> vocab_size) ──► 输出logits
"""
def __init__(self, vocab_size, key_size, query_size, value_size,
num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens,
num_heads, num_layers, dropout, **kwargs):
super(TransformerDecoder, self).__init__(**kwargs)
# 保存关键超参
self.num_hiddens = num_hiddens
self.num_layers = num_layers
# 目标端词嵌入:把目标语言token id映射到连续向量
self.embedding = nn.Embedding(vocab_size, num_hiddens)
# 位置编码:为目标序列注入位置信息
self.pos_encoding = d2l.PositionalEncoding(num_hiddens, dropout)
# 解码器块堆叠容器
self.blks = nn.Sequential()
for i in range(num_layers):
# 逐层添加解码器块,每块包含3个子层:
# 1. Masked Self-Attention(仅能看当前及之前的位置)
# 2. Cross-Attention(注意编码器输出)
# 3. Position-wise FFN
self.blks.add_module("block"+str(i),
DecoderBlock(key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens,
num_heads, dropout, i))
# 最终投影层:把隐藏维度映射回词表大小,用于生成输出token概率
self.dense = nn.Linear(num_hiddens, vocab_size)
print("[LOG] TransformerDecoder 初始化完成")
print(f"[LOG] vocab_size={vocab_size}, num_hiddens={num_hiddens}, "
f"num_heads={num_heads}, num_layers={num_layers}, dropout={dropout}")
print(f"[LOG] norm_shape={norm_shape}, ffn_num_input={ffn_num_input}, "
f"ffn_num_hiddens={ffn_num_hiddens}")
def init_state(self, enc_outputs, enc_valid_lens, *args):
"""初始化解码器状态
状态结构 state:
[0]: enc_outputs - 编码器的输出表示,用于Cross-Attention
[1]: enc_valid_lens - 编码端有效长度掩码
[2]: [None] * num_layers - 各解码器块的缓存(推理时用于增量解码)
"""
print("\n[LOG] ===== TransformerDecoder.init_state 初始化解码器状态 =====")
log_tensor_info("编码器输出 enc_outputs", enc_outputs)
print(f"[LOG] 编码器有效长度 enc_valid_lens={enc_valid_lens}")
state = [enc_outputs, enc_valid_lens, [None] * self.num_layers]
print(f"[LOG] 初始化 {self.num_layers} 层解码器块缓存")
print("[LOG] ===== 状态初始化完成 =====\n")
return state
def forward(self, X, state):
"""前向传播:解码生成目标序列表示
参数:
X: (batch_size, target_seq_len) 目标序列token索引
state: [enc_outputs, enc_valid_lens, decoder_cache]
返回:
logits: (batch_size, target_seq_len, vocab_size)
state: 更新后的解码器状态
"""
print("\n[LOG] ========= 进入 TransformerDecoder.forward ==========")
log_tensor_info("目标序列输入 X", X)
# 词嵌入
emb = self.embedding(X)
log_tensor_info("目标序列词嵌入 embedding(X)", emb)
# 缩放
scaled_emb = emb * math.sqrt(self.num_hiddens)
log_tensor_info("缩放后的词嵌入 scaled_emb", scaled_emb)
# 加入位置编码
X = self.pos_encoding(scaled_emb)
log_tensor_info("加入位置编码后的输入", X)
# 初始化注意力权重存储(用于后续可视化)
# [0]: 解码器自注意力权重,[1]: 跨注意力权重
self._attention_weights = [[None] * len(self.blks) for _ in range(2)]
# 通过num_layers个解码器块
for i, blk in enumerate(self.blks):
print(f"[LOG] ---- 进入解码器块 block{i} ----")
X, state = blk(X, state)
log_tensor_info(f"block{i} 输出", X)
# 保存该层的自注意力权重
self._attention_weights[0][i] = blk.attention1.attention.attention_weights
log_tensor_info(f"block{i} 自注意力权重", self._attention_weights[0][i])
# 保存该层的跨注意力权重(编码器-解码器注意力)
self._attention_weights[1][i] = blk.attention2.attention.attention_weights
log_tensor_info(f"block{i} 跨注意力权重", self._attention_weights[1][i])
print(f"[LOG] ---- 退出解码器块 block{i} ----")
# 最终线性投影:映射到词表大小,得到logits
logits = self.dense(X)
log_tensor_info("最终输出logits (dense层后)", logits)
print(f"[LOG] 输出logits形状: {tuple(logits.shape)}")
print("[LOG] ========= 退出 TransformerDecoder.forward ==========\n")
return logits, state
@property
def attention_weights(self):
"""返回所有层的注意力权重
返回:
[[self_attn_weights_layer0, ..., self_attn_weights_layer_L],
[cross_attn_weights_layer0, ..., cross_attn_weights_layer_L]]
"""
return self._attention_weights
整个 Decoder 的信息流
输入token
↓
Embedding + PE
↓
┌──────────────────┐
│ Masked Self-Attn │ ← 看历史
└──────────────────┘
↓
┌──────────────────┐
│ Cross Attention │ ← 看输入
└──────────────────┘
↓
┌──────────────────┐
│ FFN │ ← 加工特征
└──────────────────┘
↓
多层重复
↓
Linear
↓
logits
编码器-解码器测试代码
# valid_lens: 第0个样本只看前3个位置,第1个样本只看前2个位置
valid_lens = torch.tensor([3, 2])
print(f"[LOG] valid_lens={valid_lens}")
print("\n[LOG] ============= 完整TransformerDecoder测试 =============")
# 初始化完整解码器
# vocab_size=200, num_hiddens=24, num_heads=8, num_layers=2
decoder = TransformerDecoder(
200, 24, 24, 24, 24, [100, 24], 24, 48, 8, 2, 0.5)
decoder.eval() # 推理模式
print("[LOG] ---- 第1步:使用编码器处理源语言 ----")
# 源语言序列
src_X = torch.ones((2, 100), dtype=torch.long)
log_tensor_info("源序列输入 src_X", src_X)
# 编码
encoder = TransformerEncoder(200, 24, 24, 24, 24, [100, 24], 24, 48, 8, 2, 0.5)
encoder.eval()
enc_outputs = encoder(src_X, valid_lens)
log_tensor_info("编码器输出 enc_outputs", enc_outputs)
print(f"[LOG] 编码器输出形状: {tuple(enc_outputs.shape)}")
print("\n[LOG] ---- 第2步:初始化解码器状态 ----")
# 初始化解码器状态
state = decoder.init_state(enc_outputs, valid_lens)
print(f"[LOG] state[0] (enc_outputs) 形状: {tuple(state[0].shape)}")
print(f"[LOG] state[1] (enc_valid_lens): {state[1]}")
print(f"[LOG] state[2] (decoder_cache) 层数: {len(state[2])}")
print("\n[LOG] ---- 第3步:目标端解码 ----")
# 目标语言序列(通常在预测时逐步生成)
# 注意:目标序列长度需与 norm_shape 的第一个维度匹配(这里为100)
tgt_X = torch.ones((2, 100), dtype=torch.long) # 目标序列长度100
log_tensor_info("目标序列输入 tgt_X", tgt_X)
# 解码
logits, state_updated = decoder(tgt_X, state)
log_tensor_info("解码器输出logits", logits)
print(f"[LOG] 解码器输出logits形状: {tuple(logits.shape)}")
print(f"[LOG] 预期形状: (batch_size=2, tgt_seq_len=100, vocab_size=200)")
print("\n[LOG] ---- 第4步:查看注意力权重 ----")
attn_weights = decoder.attention_weights
print(f"[LOG] 解码器自注意力权重 (Masked Self-Attention) 层数: {len(attn_weights[0])}")
print(f"[LOG] 跨注意力权重 (Cross-Attention) 层数: {len(attn_weights[1])}")
for i in range(len(attn_weights[0])):
if attn_weights[0][i] is not None:
print(f"[LOG] 第{i}层 自注意力权重形状: {tuple(attn_weights[0][i].shape)}")
if attn_weights[1][i] is not None:
print(f"[LOG] 第{i}层 跨注意力权重形状: {tuple(attn_weights[1][i].shape)}")
print("\n[LOG] ---- 第5步:解码器cache状态 ----")
print(f"[LOG] 更新后state[2] (decoder_cache) 缓存块数: {len(state_updated[2])}")
for i in range(len(state_updated[2])):
if state_updated[2][i] is not None:
print(f"[LOG] block{i} 缓存形状: {tuple(state_updated[2][i].shape)}")
else:
print(f"[LOG] block{i} 缓存: None")
print("\n[LOG] ============= 完整TransformerDecoder测试结束 =============\n")
架构
源序列 src_X (B,S)
│
▼
┌─────────────── Encoder ───────────────┐
│ Embedding → Scale → PosEncoding │
│ │ │
│ ▼ │
│ [EncoderBlock × L] │
│ Self-Attn → AddNorm → FFN → AddNorm │
│ │ │
└──────▼─────────────────────────────────┘
enc_outputs (B,S,d)
│
▼
state = [enc_outputs, valid_lens, cache]
│
▼
目标序列 tgt_X (B,T)
│
▼
┌─────────────── Decoder ───────────────┐
│ Embedding → Scale → PosEncoding │
│ │ │
│ ▼ │
│ [DecoderBlock × L] │
│ ① Masked Self-Attn │
│ ② Cross-Attn │
│ ③ FFN │
│ + 每步 AddNorm │
│ │ │
└──────▼─────────────────────────────────┘
X_L (B,T,d)
│
▼
Linear → logits (B,T,V)
Step 1:Encoder 详细流程
src_X (B,S)
│ token_id(离散)
▼
Embedding
│ (B,S) → (B,S,d)
│ 每个token变向量
▼
Scale (×√d)
│ 放大embedding
▼
PosEncoding
│ 注入位置信息
▼
X0 (B,S,d)
EncoderBlock(重复 L 次)
输入:X (B,S,d)
│
├─► Self-Attention
│ Q=K=V=X
│ ↓
│ 融合“全局上下文”
│
├─► AddNorm
│ X + Attn(X)
│ ↓
│ 稳定训练 + 保留原信息
│
├─► FFN
│ 每个token独立:
│ d → 4d → d
│
└─► AddNorm
再次稳定
Encoder 输出
enc_outputs (B,S,d)
含义:
每个 token → “带上下文的语义表示”
Step 2:初始化 Decoder 状态
state = [
enc_outputs, # 输入语义
valid_lens, # mask
[None, None, ...] # cache(每层一个)
]
🧠 cache 的意义
cache[i] = 第 i 层已经算过的 K/V
推理时:
避免重复计算历史token
Step 3:Decoder 输入处理
tgt_X (B,T)
│
▼
Embedding
│ (B,T) → (B,T,d)
▼
Scale
▼
PosEncoding
▼
X0 (B,T,d)
Step 4:DecoderBlock(核心)
输入:X (B,T,d)
┌──────────────────────────────┐
│ ① Masked Self-Attention │
│ Q = 当前token │
│ K,V = 历史+当前 │
│ │
│ 作用: │
│ 只能看“过去” │
└───────────────┬──────────────┘
▼
AddNorm1
│
▼
┌──────────────────────────────┐
│ ② Cross-Attention │
│ Q = decoder状态 │
│ K,V = enc_outputs │
│ │
│ 作用: │
│ 从输入句子“取信息” │
└───────────────┬──────────────┘
▼
AddNorm2
│
▼
┌──────────────────────────────┐
│ ③ FFN │
│ 每个token独立 │
│ 非线性变换 │
└───────────────┬──────────────┘
▼
AddNorm3
│
▼
输出 X (B,T,d)
Step 6:Linear 输出层
X (B,T,d)
│
▼
Linear(d → vocab_size)
│
▼
logits (B,T,V)
🎯 含义
每个位置:一个“词表概率分布”
训练和推理的区别
| 特性 | 训练(Training) | 推理(Inference) |
|---|---|---|
| 模式 | model.train() |
model.eval() |
| Dropout | ✅ 开启(防过拟合) | ❌ 关闭(稳定输出) |
| 梯度计算 | ✅ 计算 + 反向传播 | ❌ torch.no_grad() |
| 参数更新 | ✅ 更新权重 | ❌ 不更新 |
| 输入方式 | 并行(整句输入) | 自回归(逐token) |
| Mask机制 | causal mask + padding mask | 主要是 causal mask |
| Self-Attention | 全序列并行计算 | 只算当前token + cache |
| KV Cache | ❌ 不使用 | ✅ 必须使用 |
| 计算复杂度 | O(n²)(每层) | O(n)(有cache) |
| 显存占用 | 高(存梯度) | 低(仅前向) |
| 输出 | logits(用于loss) | token(用于生成) |
| 目标 | 学习参数 | 生成结果 |
| 是否知道未来 | ✅(teacher forcing) | ❌(只能看历史) |
| 速度瓶颈 | 反向传播 | 自回归串行(latency) |
| 并行性 | 高(GPU友好) | 低(逐步生成) |